使用区域级磁盘构建高可用性服务
本部分介绍如何使用区域级 Persistent Disk 或Hyperdisk Balanced 高可用性磁盘构建高可用性服务。
设计考虑事项
在开始设计高可用性服务之前,请先了解应用、文件系统和操作系统的特性。这些特性是设计的基础,有助于排除各种不适合的方法。例如,如果应用不支持应用级层复制,则某些对应的设计选项不适用。
同样,如果应用、文件系统或操作系统无法容忍崩溃,则可能无法选择使用区域级永久性磁盘或Hyperdisk Balanced 高可用性磁盘甚至可用区级磁盘快照。崩溃容忍度是指从突然终止中恢复的能力,不会丢失或破坏崩溃前已提交到磁盘的数据。
在设计高可用性时考虑以下因素:
- 对使用 Hyperdisk Balanced 高可用性、区域级永久性磁盘 或其他解决方案的应用的影响。
- 磁盘写入性能
- 服务恢复时间目标:您的服务必须从可用区级服务中断恢复的速度以及服务等级协议 (SLA) 要求
- 构建灵活可靠的服务架构的费用。
- 如需详细了解特定于区域的注意事项,请参阅地理位置和区域。
就费用而言,请使用以下选项进行同步和异步应用复制:
使用两个数据库和虚拟机实例。在这种情况下,总费用由以下几项决定:
- 虚拟机实例费用
- Persistent Disk 或Hyperdisk 费用
- 维护应用复制的费用
使用具有同步复制磁盘的单个虚拟机。如需使用区域级 Persistent Disk 或 Hyperdisk Balanced 高可用性磁盘实现高可用性,请使用与上述选项相同的虚拟机实例和磁盘组件,但还包括一个同步复制磁盘。 区域级 Persistent Disk 和 Hyperdisk Balanced 高可用性磁盘每个字节的费用是可用区级磁盘的两倍,因为它们会在两个可用区中复制。
但是,使用同步复制磁盘可能会降低维护费用,因为数据会自动写入到两个副本,而无需维护应用复制。
在需要故障切换之前,请勿启动次要虚拟机。 如果您只在故障切换期间按需启动次要虚拟机,而不是将虚拟机维持为活跃备用虚拟机,还可进一步降低主机费用。
比较费用、性能和弹性
下表着重介绍了不同服务架构在费用、性能和弹性方面的权衡取舍。
| HA 服务 架构 |
可用区级磁盘 快照 |
应用级层 同步 |
应用级层 异步 |
区域级磁盘 |
|---|---|---|---|---|
| 防范应用、虚拟机、可用区故障* | ||||
| 针对应用损坏的缓解措施(示例:应用的崩溃容忍度) | † | † | ||
| 费用 | $ |
$$
|
$$
|
$1.5x - $$
|
| 应用性能 |
|
|
|
|
| 适用于要求低 RPO 的应用(对数据丢失容忍度极低) |
|
|
|
|
| 灾难发生后的存储恢复时间# |
|
|
|
|
*使用区域级磁盘或快照不足以防范和缓解故障及崩溃。 您的应用、文件系统以及可能的其他软件组件必须具备崩溃一致性,或使用某种静默方法。
† 复制某些应用可以减轻特定应用崩溃的影响。例如,MySQL 主应用崩溃不会导致其副本虚拟机实例也遭到损坏。如需了解详情,请查看您的应用文档。
‡ 数据丢失意味着提交到永久性存储空间的数据丢失且不可恢复。任何未提交的数据仍会丢失。
# 故障切换性能不包括文件系统检查和故障切换后的应用恢复及加载。
使用区域级磁盘构建高可用性数据库服务
本部分介绍了使用具有区域级永久性磁盘和 Hyperdisk Balanced 高可用性磁盘的 Compute Engine 为有状态数据库服务(MySQL、Postgres 等)构建高可用性解决方案的主要概念。
如果 Google Cloud发生广泛中断,例如整个区域变得不可用,您的应用可能变得不可用。根据您的需求,请考虑使用跨区域复制技术或异步复制 来实现更高的可用性。
数据库 HA 配置通常至少包含两个虚拟机实例。这些虚拟机实例最好属于一个或多个代管式实例组:
- 主可用区中的主虚拟机实例
- 辅助可用区中的备用虚拟机实例
主虚拟机实例至少有两个磁盘:一个启动磁盘和一个区域级磁盘。区域级磁盘包含数据库数据以及在发生服务中断时应保留到其他可用区的其他任何可变数据。
例如,备用虚拟机实例需要单独的启动磁盘才能从与配置相关的服务中断(可能由操作系统升级引起)中恢复。此外,在故障切换过程中,您无法将启动磁盘强制挂接到其他虚拟机。
主虚拟机实例和备用虚拟机实例配置为根据健康检查信号将负载均衡器与定向到主虚拟机的流量结合使用。数据的灾难恢复场景简要介绍了其他故障切换配置,这些配置可能更适合您的使用场景。
数据库复制面临的挑战
下表列出了设置和管理应用同步或半同步复制(如 MySQL)的一些常见挑战,以及它们与使用区域级永久性磁盘和 Hyperdisk Balanced 高可用性磁盘的同步磁盘复制的比较。
| 挑战 | 应用同步 或半同步复制 |
同步磁盘复制 |
|---|---|---|
| 在主实例和故障切换副本之间保持稳定复制。 | 可能会发生多种问题,并导致虚拟机实例脱离高可用性模式:
|
存储故障由 区域级 Persistent Disk 和 Hyperdisk Balanced 高可用性磁盘处理。这对应用而言是透明的,除了磁盘性能可能出现波动。 必须通过用户定义的健康检查来发现应用或虚拟机问题并触发故障切换。 |
| 端到端的故障切换时间比预期要长。 | 故障切换操作所花费的时间没有上限。等待所有事务执行完成(上述步骤 2)所需的时间并不固定,具体取决于数据库的架构和负载。 | 区域级 Persistent Disk 和 Hyperdisk Balanced 高可用性磁盘提供同步复制功能,因此故障切换时间受以下延迟时间总和的限制:
|
| 脑裂 | 为避免出现脑裂情况,这两种方法都需要通过预配来确保一次只有一个主实例。 | |
磁盘的读写操作序列
在确定读取/写入序列或者从磁盘读取数据/将数据写入磁盘的顺序时,大部分工作由虚拟机中的磁盘驱动程序完成。作为用户,您不必处理复制语义,并且可以照常与文件系统进行交互。底层驱动程序会处理读取和写入序列。
默认情况下,具有区域级永久性磁盘或Hyperdisk Balanced 高可用性的 Compute Engine 虚拟机以完全复制模式运行,即从磁盘读取或写入磁盘的请求将发送到两个副本。
在完全复制模式下,会发生以下情况:
- 写入时,写入请求会尝试写入两个副本,并在两个写入都成功时确认。
- 读取时,虚拟机会向两个副本发送读取请求,并从成功的副本中返回结果。如果读取请求超时,则发送另一个读取请求。
如果副本落后或未能确认读取或写入请求已完成,则副本状态会更新。
健康检查
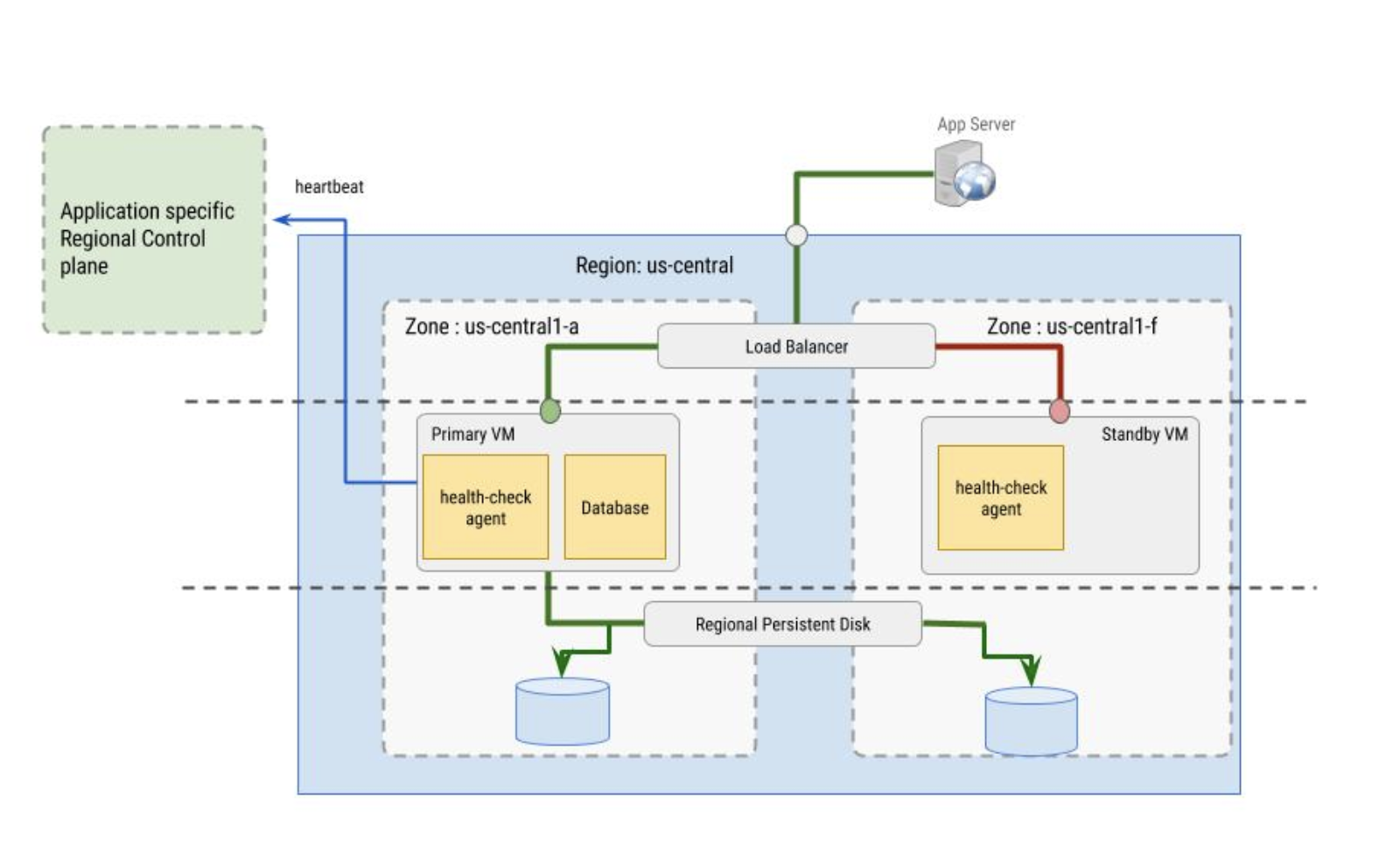
负载均衡器使用的健康检查由健康检查代理实现。健康检查代理用于实现以下两个目的:
- 健康检查代理位于主虚拟机和辅助虚拟机中,用于监控虚拟机实例并与负载均衡器通信以定向流量。配置了实例组时,此方法效果最佳。
- 健康检查代理会与特定于应用的区域控制平面同步,并根据控制平面行为做出故障切换决策。控制平面必须与健康状况受监控的虚拟机实例位于不同可用区。
健康检查代理本身必须具有容错性。例如,请注意在下图中,控制平面与主虚拟机实例是彼此独立的,主虚拟机实例位于 us-central1-a 可用区,而备用虚拟机位于 us-central1-f 可用区。
后续步骤
- 了解如何创建和管理区域级磁盘。
- 了解异步复制。
- 了解如何为多写入者模式下的磁盘配置 SQL Server 故障切换集群实例。
- 了解如何在 Google Cloud上构建可扩缩、弹性佳的 Web 应用。
- 查看灾难恢复计划指南。