Hochverfügbarkeitsdienste mit regionalen Laufwerken erstellen
In diesem Abschnitt wird erläutert, wie Sie Hochverfügbarkeitsdienste mitregionalem nichtflüchtigen Speicher oderHyperdisk mit ausgeglichenem Hochverfügbarkeitslaufwerken erstellen.
Designaspekte
Bevor Sie die Entwicklung eines Hochverfügbarkeitsdienstes in Angriff nehmen, sollten Sie sich mit den Merkmalen der Anwendung, des Dateisystems und des Betriebssystems vertraut machen. Diese Merkmale sind die Grundlage für das Design und können verschiedene Ansätze ausschließen. Wenn eine Anwendung beispielsweise Replikation auf Anwendungsebene nicht unterstützt, sind bestimmte entsprechende Designoptionen nicht anwendbar.
Wenn die Anwendung, das Dateisystem oder das Betriebssystem nicht absturztolerant sind, ist die Verwendung von regionalem nichtflüchtigen SpeicheroderHyperdisk mit ausgeglichenen Hochverfügbarkeitslaufwerken oder sogar von zonalen Disk-Snapshots möglicherweise keine Option. Absturztoleranz wird als die Fähigkeit definiert, ein System oder eine Anwendung nach einer abrupten Beendigung ohne den Verlust oder die Beschädigung von Daten wiederherzustellen, die bereits vor dem Absturz per Commit in einen Speicher übertragen wurden.
Berücksichtigen Sie beim Planen der Hochverfügbarkeit Folgendes:
- Die Auswirkungen auf die Anwendung der Verwendung von Hyperdisk mit ausgeglichener Hochverfügbarkeit, regionalem nichtflüchtigen Speicher oder anderen Lösungen.
- Schreibleistung des Laufwerks.
- Das Recovery Time Objective des Dienstes – wie schnell Ihr Dienst nach einem zonalen Ausfall wiederhergestellt werden muss, sowie die SLA-Anforderungen.
- Die Kosten für die Erstellung einer stabilen und zuverlässigen Dienstarchitektur.
- Weitere Informationen zu regionsspezifischen Aspekten finden Sie unter Geografie und Regionen.
In Bezug auf die Kosten haben Sie folgende Möglichkeiten für eine synchrone oder asynchrone Anwendungsreplikation:
Die Verwendung von jeweils zwei Instanzen der Datenbank und der VM: In diesem Fall hängen die Gesamtkosten von den folgenden Faktoren ab:
- Kosten für VM-Instanz
- Kosten für Persistent Disk oderHyperdisk
- Kosten für die Verwaltung der Anwendungsreplikation
Einzelne VM mit synchron replizierten Laufwerken verwenden: Wenn Sie Hochverfügbarkeit mit einemregionalen Persistent Disk- oder Hyperdisk mit ausgeglichenem Hochverfügbarkeits-Laufwerk erreichen möchten, verwenden Sie dieselbe VM-Instanz und dieselben Laufwerkskomponenten wie die vorherige Option, aber Außerdem enthält er ein synchron repliziertes Laufwerk. Regionale Persistent Disks und Hyperdisk mit ausgeglichenen Hochverfügbarkeit-Laufwerke sind im Vergleich zu zonalen Laufwerken doppelt so teuer wie zonale Laufwerke, da sie in zwei Zonen repliziert werden.
Die Verwendung von synchron replizierten Laufwerken kann jedoch zu niedrigeren Wartungskosten führen, weil die Daten automatisch in zwei Replikate geschrieben werden, ohne dass Sie die Anwendungsreplikation verwalten müssen.
Starten Sie die sekundäre VM erst, wenn ein Failover erforderlich ist. Sie können die Hostkosten zusätzlich senken, indem Sie die sekundäre VM nur bei Bedarf während des Failovers starten, anstatt sie als aktive Standby-VM beizubehalten.
Kosten, Leistung und Ausfallsicherheit verwalten
Die folgende Tabelle veranschaulicht die Vor- und Nachteile der unterschiedlichen Dienstarchitekturen im Hinblick auf Kosten, Leistung und Ausfallsicherheit.
| Hochverfügbarkeits- Architektur |
Snapshots zonaler Laufwerke |
Anwendungsebene synchron |
Anwendungsebene asynchron |
Regionale Laufwerke |
|---|---|---|---|---|
| Schützt vor Anwendungs-, VM- und Zonenausfall* | ||||
| Minderung der Anwendungsbeschädigung (Beispiel: Intoleranz gegen Anwendungsabsturz) | † | † | ||
| Kosten | $ |
$$
|
$$
|
1,5 x $ – $$
|
| Anwendungsleistung |
|
|
|
|
| Geeignet für Anwendungen mit niedriger RPO-Anforderung (sehr geringe Toleranz gegenüber Datenverlust) |
|
|
|
|
| Speicherwiederherstellung nach einem Ausfall# |
|
|
|
|
* Die Verwendung regionaler Speicher oder Snapshots reicht nicht aus, um Ausfälle und Beschädigungen zu verhindern oder zu mindern. Ihre Anwendung, das Dateisystem und möglicherweise andere Softwarekomponenten müssen absturzsicher sein oder eine Art von Stilllegung verwenden.
† Durch die Replikation einiger Anwendungen können manche Anwendungsfehler vermieden werden. Beispielsweise führt eine Beschädigung der primären MySQL-Anwendung nicht dazu, dass die VM-Instanzen ebenfalls beschädigt werden. Weitere Informationen finden Sie in der Dokumentation zu Ihrer Anwendung.
‡ Datenverlust bezieht sich auf den nicht wiederherstellbaren Verlust von Daten, die per Commit in den nichtflüchtigen Speicher übertragen wurden. Alle nicht per Commit übertragenen Daten gehen verloren.
# Die Failover-Leistung umfasst keine Dateisystemprüfung und Anwendungswiederherstellung sowie kein Laden nach einem Failover.
Hochverfügbarkeits-Datenbankdienste mit regionalen Speichern erstellen
In diesem Abschnitt werden allgemeine Konzepte zum Erstellen von Hochverfügbarkeitslösungen für zustandsorientierte Datenbankdienste (MySQL, Postgres usw.) unter Verwendung von Compute Engine mitregionalen nichtflüchtigen Speichern und Hyperdisk mit ausgeglichenen Hochverfügbarkeits-Laufwerken behandelt.
Bei großen Ausfällen in Google Cloud, z. B. wenn eine ganze Region nicht mehr verfügbar ist, ist Ihre Anwendung möglicherweise nicht mehr verfügbar. Je nach Ihren Anforderungen sollten Sieregionenübergreifende Replikationstechniken oder asynchrone Replikation für eine noch höhere Verfügbarkeit in Betracht ziehen.
Hochverfügbarkeitskonfigurationen für Datenbanken haben in der Regel mindestens zwei VM-Instanzen. Vorzugsweise sind diese VM-Instanzen Teil einer oder mehrerer verwalteter Instanzgruppen:
- eine primäre VM-Instanz in der primären Zone
- eine Standby-VM-Instanz in einer sekundären Zone
Eine primäre VM-Instanz hat mindestens zwei Laufwerke: ein Bootlaufwerk und ein regionales Laufwerk. Der regionale Speicher enthält Datenbankdaten und andere änderbare Daten, die bei einem Ausfall in einer anderen Zone erhalten bleiben sollen.
Eine Standby-VM-Instanz benötigt ein separates Bootlaufwerk, um eine Wiederherstellung bei konfigurationsbedingten Ausfällen zu ermöglichen, die beispielsweise durch ein Betriebssystem-Upgrade verursacht wurden. Außerdem können Sie das Anhängen eines Bootlaufwerks an eine andere VM während eines Failovers nicht erzwingen.
Die primäre Instanz und die Standby-VM-Instanz sind für die Verwendung eines Load-Balancers konfiguriert, wobei der Traffic anhand von Signalen der Systemdiagnose an die primäre VM weitergeleitet wird. Das Notfallwiederherstellungsszenario für Daten beschreibt andere Failover-Konfigurationen, die für Ihr Szenario möglicherweise geeigneter sind.
Herausforderungen bei der Datenbankreplikation
In der folgenden Tabelle sind einige häufige Herausforderungen bei der Einrichtung und Verwaltung der synchronen oder halbsynchronen Replikation von Anwendungen (wie MySQL) aufgeführt und wie sie mit der synchronen Laufwerksreplikation mitregionalen nichtflüchtigen Speicher und Hyperdisk mit ausgeglichenen Hochverfügbarkeits-Laufwerken verglichen werden.
| Herausforderungen | Anwendung synchron oder halb-synchrone Replikation |
Synchrone Laufwerksreplikation |
|---|---|---|
| Stabile Replikation zwischen Primär- und Failover-Replikat aufrechterhalten | Es können eine Reihe von Problemen auftreten, die dazu führen können, dass eine VM-Instanz den Hochverfügbarkeitsmodus nicht mehr gewährleistet:
|
Speicherfehler werden von regionalen nichtflüchtigen Speicher und Hyperdisk mit ausgeglichenen Hochverfügbarkeits-Laufwerken verarbeitet. Dies geschieht transparent für die Anwendung, mit Ausnahme einer möglichen Fluktuation in der Leistung des Speichers. Es müssen benutzerdefinierte Systemdiagnosen vorhanden sein, um Anwendungs- oder VM-Probleme aufzudecken und Failover auszulösen. |
| End-to-End-Failover-Zeit ist länger als erwartet. | Die für den Failover-Vorgang benötigte Zeit hat keine Obergrenze. Das Warten auf die Wiederholung aller Transaktionen kann je nach Schema und Auslastung der Datenbank beliebig lange dauern. | Regionaler nichtflüchtiger Speicher und Hyperdisk mit ausgeglichenen Hochverfügbarkeits-Laufwerken bieten eine synchrone Replikation, sodass die Failover-Zeit durch die Summe der folgenden Latenzen begrenzt wird:
|
| Split-Brain | Beide Ansätze erfordern Maßnahmen, die dafür sorgen, dass jeweils nur eine primäre Instanz vorhanden ist, um Split-Brain zu vermeiden. | |
Sequenz von Lese- und Schreibvorgängen auf Laufwerken
Beim Festlegen der Lese- und Schreibsequenzen oder der Reihenfolge, in der Daten von dem Laufwerk gelesen und auf das Laufwerk geschrieben werden, wird der Großteil der Arbeit vom Laufwerktreiber in der VM ausgeführt. Als Nutzer müssen Sie sich nicht mit der Replikationssemantik befassen und können wie gewohnt mit dem Dateisystem interagieren. Der zugrunde liegende Treiber übernimmt die Sequenz für Lese- und Schreibvorgänge.
Standardmäßig arbeitet eine Compute Engine-VM mitregionalem nichtflüchtigen Speicher oderHyperdisk mit ausgeglichener Hochverfügbarkeit im vollständigen Replikationsmodus, wobei gilt: Anfragen zum Lesen oder Schreiben von beiden Laufwerken werden an beide Replikate gesendet.
Im vollständigen Replikationsmodus geschieht Folgendes:
- Beim Schreiben versucht eine Schreibanfrage, in beide Replikate zu schreiben, und bestätigt, dass beide Schreibvorgänge erfolgreich sind.
- Beim Lesen sendet die VM eine Leseanfrage an beide Replikate und gibt die Ergebnisse von dem Replikat zurück, das erfolgreich ist. Wenn bei der Leseanfrage eine Zeitüberschreitung auftritt, wird eine weitere Leseanfrage gesendet.
Wenn ein Replikat zurückfällt oder nicht bestätigt, dass die Lese- oder Schreibanfragen abgeschlossen wurden, wird der Replikatstatus aktualisiert.
Systemdiagnosen
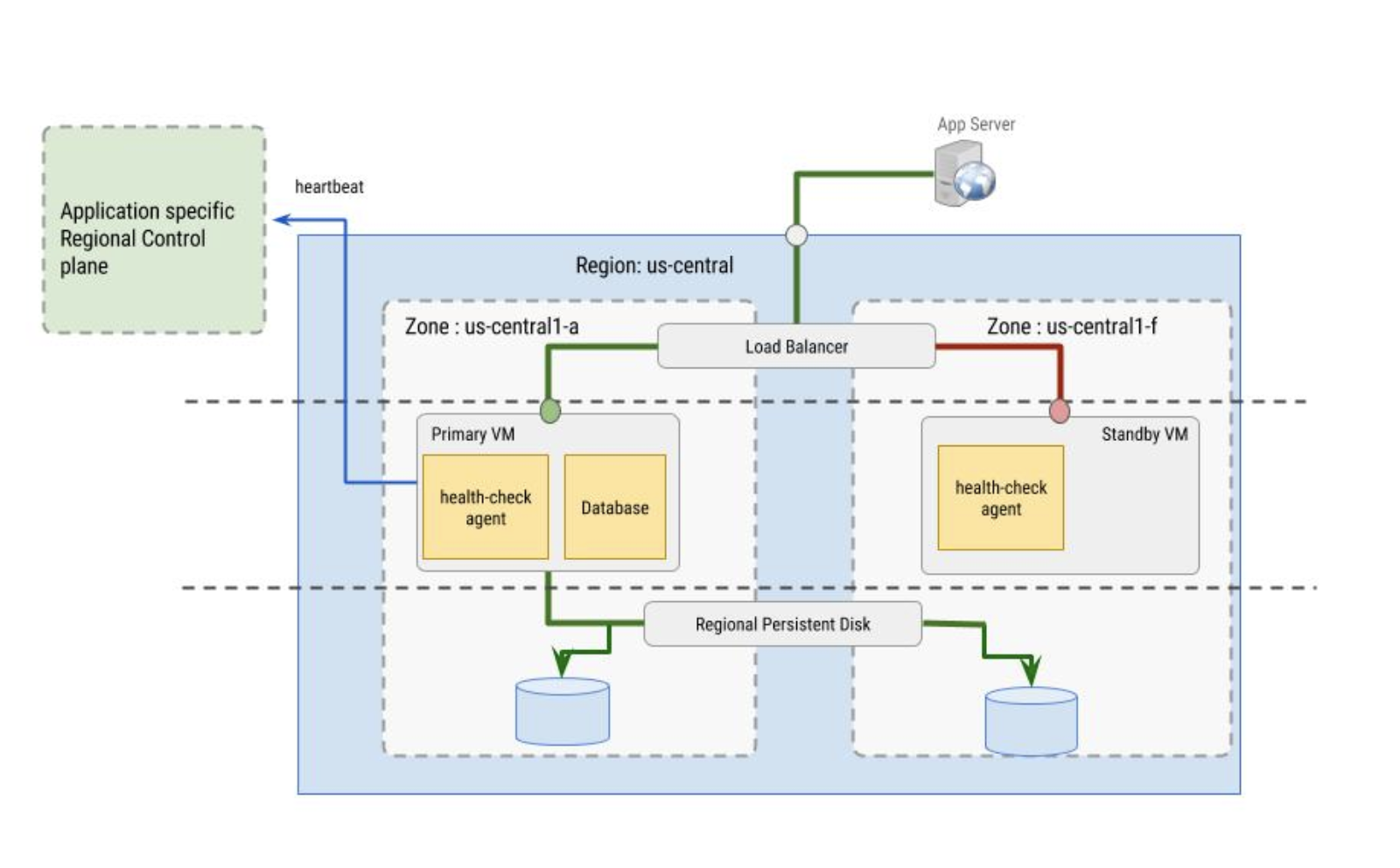
Die vom Load Balancer verwendeten Systemdiagnosen werden vom Systemdiagnose-Agent implementiert. Der Systemdiagnose-Agent hat zwei Aufgaben:
- Der Systemdiagnose-Agent befindet sich innerhalb der primären VM und der sekundären VM, um die VM-Instanzen zu überwachen und mit dem Load-Balancer bezüglich der Weiterleitung von Traffic zu kommunizieren. Diese Vorgehensweise funktioniert am besten in Verbindung mit Instanzgruppen.
- Der Systemdiagnose-Agent wird mit der anwendungsspezifischen regionalen Steuerungsebene synchronisiert und trifft Failover-Entscheidungen, die auf dem Verhalten der Steuerungsebene basieren. Die Steuerungsebene muss sich in einer anderen Zone als die VM-Instanz befinden, deren Status überwacht wird.
Der Systemdiagnose-Agent selbst muss fehlertolerant sein. Beachten Sie beispielsweise in der folgenden Abbildung, dass die Steuerungsebene von der primären VM-Instanz getrennt ist, die sich in der Zone us-central1-a befindet, während sich die Standby-VM in der Zone us-central1-f befindet.
Nächste Schritte
- Regionale Laufwerke erstellen und verwalten.
- Weitere Informationen zur asynchronen Replikation
- Informationen zum Konfigurieren einer SQL Server-Failovercluster-Instanz für Laufwerke im Modus für mehrere Autoren
- Skalierbare und robuste Webanwendungen auf Google Cloud erstellen
- Leitfaden zur Planung der Notfallwiederherstellung