Crear servicios de alta disponibilidad con discos regionales
En esta sección se explica cómo puedes crear servicios de alta disponibilidad condiscos persistentes regionaleso con discos Hyperdisk Balanced High Availability.
Factores del diseño
Antes de empezar a diseñar un servicio de alta disponibilidad, debes conocer las características de la aplicación, el sistema de archivos y el sistema operativo. Estas características son la base del diseño y pueden descartar varios enfoques. Por ejemplo, si una aplicación no admite la replicación a nivel de aplicación, algunas opciones de diseño correspondientes no se pueden aplicar.
Del mismo modo, si la aplicación, el sistema de archivos o el sistema operativo no son tolerantes a fallos, puede que no sea una opción usar discos persistentes regionales o discos Hyperdisk Balanced de alta disponibilidad, ni siquiera instantáneas de discos zonales.La tolerancia a fallos se define como la capacidad de recuperarse de una finalización abrupta sin perder ni dañar los datos que ya se habían escrito en un disco antes del fallo.
Ten en cuenta lo siguiente al diseñar un sistema de alta disponibilidad:
- El efecto en la aplicación de usar Hyperdisk Balanced High Availability, discos persistentes regionales u otras soluciones.
- Rendimiento de escritura en disco.
- El objetivo de tiempo de recuperación del servicio: la rapidez con la que tu servicio debe recuperarse de una interrupción zonal y los requisitos del SLA.
- El coste de crear una arquitectura de servicio resiliente y fiable.
- Para obtener más información sobre las consideraciones específicas de cada región, consulta el artículo sobre geografía y regiones.
En cuanto al coste, utiliza las siguientes opciones para la replicación de aplicaciones síncrona y asíncrona:
Usa dos instancias de la base de datos y de la VM. En este caso, los siguientes elementos determinan el coste total:
- Costes de las instancias de VM
- Costes de Persistent Disk oHyperdisk
- Costes de mantenimiento de la replicación de aplicaciones
Usa una sola VM con discos replicados de forma síncrona. Para conseguir una alta disponibilidad con undisco persistente regional o un disco de alta disponibilidad equilibrado de Hyperdisk, usa los mismos componentes de instancia de máquina virtual y de disco que en la opción anterior, pero incluye también un disco replicado de forma síncrona.Los discos persistentes regionales y los discos de alta disponibilidad balanceados de hiperdisco cuestan el doble por byte que los discos de zona, ya que se replican en dos zonas.
Sin embargo, usar discos replicados de forma síncrona puede reducir el coste de mantenimiento, ya que los datos se escriben automáticamente en dos réplicas sin necesidad de mantener la réplica de la aplicación.
No inicies la VM secundaria hasta que sea necesario realizar una conmutación por error. Puedes reducir aún más los costes del host iniciando la VM secundaria solo cuando sea necesario durante la conmutación por error, en lugar de mantener la VM como una VM de reserva activa.
Comparar costes, rendimiento y resiliencia
En la siguiente tabla se destacan las ventajas y desventajas en cuanto a coste, rendimiento y resiliencia de las diferentes arquitecturas de servicio.
| Arquitectura del servicio de alta disponibilidad |
Capturas de discos de zona |
Nivel de aplicación síncrono |
Nivel de aplicación asíncrono |
Discos regionales |
|---|---|---|---|---|
| Protección frente a fallos de aplicaciones, máquinas virtuales y zonas* | ||||
| Mitigación contra la corrupción de aplicaciones (por ejemplo, tolerancia a fallos de aplicaciones) | † | † | ||
| Coste | $ |
$$
|
$$
|
1,5 veces - $$
|
| Rendimiento de aplicaciones |
|
|
|
|
| Adecuado para aplicaciones con requisitos de RPO bajos (tolerancia muy baja a la pérdida de datos) |
|
|
|
|
| Tiempo de recuperación del almacenamiento tras un desastre# |
|
|
|
|
* Usar discos o capturas regionales no es suficiente para protegerse y mitigar los fallos y las corrupciones. Tu aplicación, sistema de archivos y, posiblemente, otros componentes de software deben ser coherentes en caso de fallo o usar algún tipo de quiescencia.
† La replicación de algunas aplicaciones proporciona mitigación contra algunas corrupciones de aplicaciones. Por ejemplo, si se daña la aplicación principal de MySQL, no se dañarán las instancias de VM de réplica. Consulta la documentación de tu aplicación para obtener más información.
‡ La pérdida de datos significa la pérdida irrecuperable de datos almacenados de forma persistente. Los datos que no se hayan confirmado se perderán.
# El rendimiento de la conmutación por error no incluye la comprobación del sistema de archivos, la recuperación de la aplicación ni la carga después de la conmutación por error.
Crear servicios de bases de datos de alta disponibilidad con discos regionales
En esta sección se explican los conceptos generales para crear soluciones de alta disponibilidad para servicios de bases de datos con estado (MySQL, PostgreSQL, etc.) mediante Compute Engine con discos persistentes regionales y discos de alta disponibilidad Hyperdisk Balanced.
Si hay interrupciones generalizadas en Google Cloud, por ejemplo, si una región entera deja de estar disponible, es posible que tu aplicación deje de estarlo también. En función de tus necesidades, puedes usar técnicas de replicación entre regiones o replicación asíncrona para conseguir una disponibilidad aún mayor.
Las configuraciones de alta disponibilidad de bases de datos suelen tener al menos dos instancias de VM. Preferiblemente, estas instancias de VM deben formar parte de uno o varios grupos de instancias gestionados:
- Una instancia de VM principal en la zona principal
- Una instancia de VM de reserva en una zona secundaria
Una instancia de VM principal tiene al menos dos discos: un disco de arranque y un disco regional. El disco regional contiene datos de la base de datos y otros datos mutables que deben conservarse en otra zona en caso de interrupción.
Una instancia de VM de reserva requiere un disco de arranque independiente para poder recuperarse de las interrupciones relacionadas con la configuración, que podrían deberse a una actualización del sistema operativo, por ejemplo. Además, no puedes forzar la conexión de un disco de arranque a otra máquina virtual durante una conmutación por error.
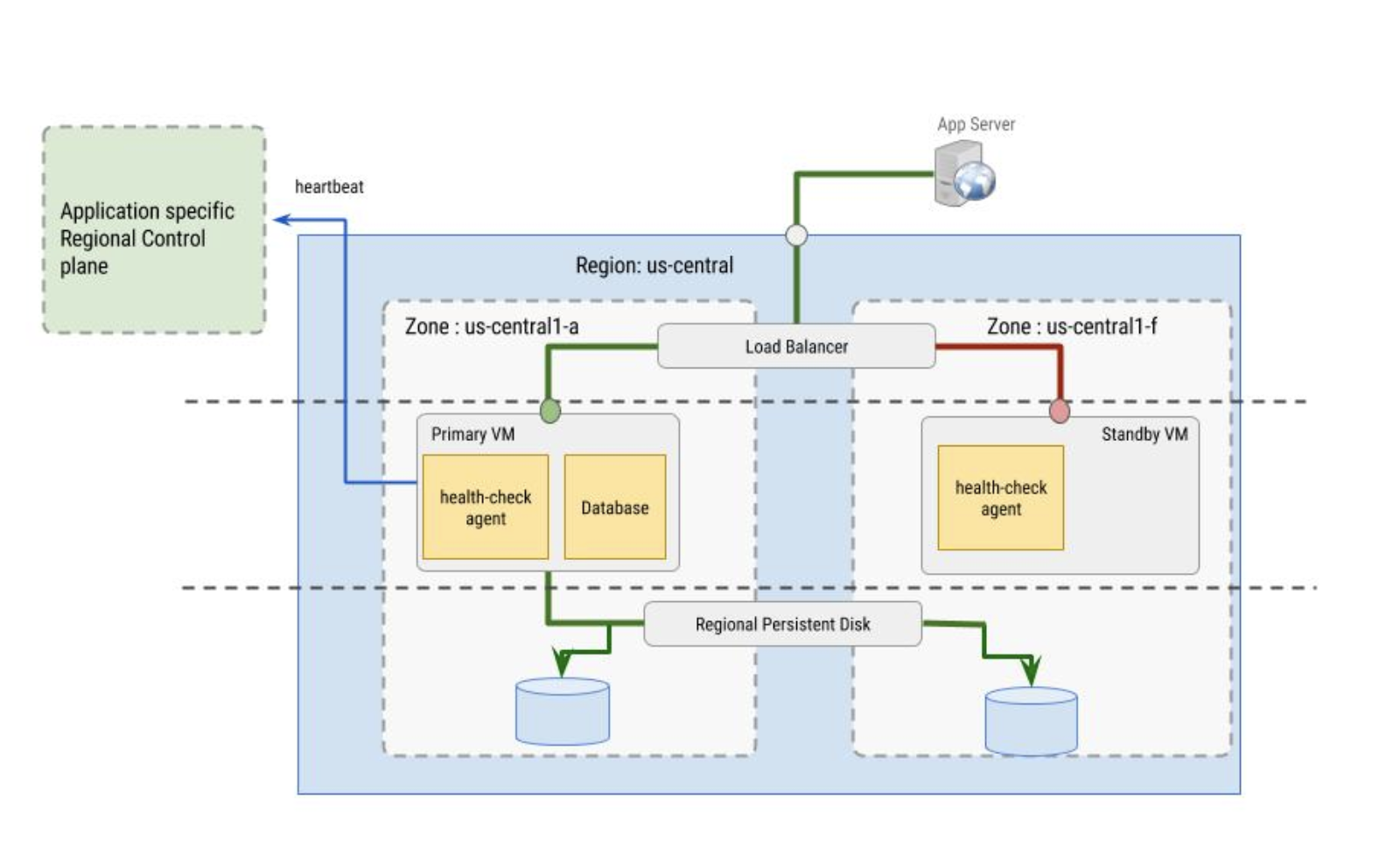
Las instancias de VM principal y de espera se configuran para usar un balanceador de carga con el tráfico dirigido a la VM principal en función de las señales de comprobación del estado. En el caso de recuperación tras fallos con los datos se describen otras configuraciones de conmutación por error que pueden ser más adecuadas para tu situación.
Problemas con la replicación de bases de datos
En la siguiente tabla se enumeran algunos de los problemas habituales que se producen al configurar y gestionar la replicación síncrona o semisíncrona de aplicaciones (como MySQL) y se compara con la replicación síncrona de discos condiscos persistentes regionales y discos de alta disponibilidad equilibrados de Hyperdisk.
| Retos | Replicación síncrona o semisíncrona de aplicaciones |
Replicación síncrona de discos |
|---|---|---|
| Mantener una replicación estable entre la réplica principal y la de conmutación por error. | Hay varios motivos por los que una instancia de VM puede dejar de estar en modo de alta disponibilidad:
|
Los errores de almacenamiento se gestionan mediante discos persistentes regionales y discos de alta disponibilidad balanceados de hiperdisco. Esto ocurre de forma transparente para la aplicación, excepto por una posible fluctuación en el rendimiento del disco. Debe haber comprobaciones de estado definidas por el usuario para detectar cualquier problema de la aplicación o de la VM y activar la conmutación por error. |
| El tiempo de conmutación por error de extremo a extremo es más largo de lo esperado. | El tiempo que se tarda en realizar la operación de conmutación por error no tiene un límite superior. Esperar a que se repitan todas las transacciones (paso 2 anterior) puede llevar un tiempo arbitrariamente largo, en función del esquema y la carga de la base de datos. | Losdiscos persistentes regionales y los discos Hyperdisk Balanced High Availability proporcionan replicación síncrona, por lo que el tiempo de conmutación por error está limitado por la suma de las siguientes latencias:
|
| Cerebro dividido | Para evitar el cerebro dividido, ambos enfoques requieren medidas para asegurar que solo haya un elemento principal a la vez. | |
Secuencia de operaciones de lectura y escritura en discos.
La mayor parte del trabajo para determinar las secuencias de lectura y escritura, o el orden en el que se leen y escriben los datos en el disco, lo realiza el controlador del disco de tu VM. Como usuario, no tienes que preocuparte por la semántica de la réplica y puedes interactuar con el sistema de archivos como de costumbre. El controlador subyacente gestiona la secuencia de lectura y escritura.
De forma predeterminada, una VM de Compute Engine con un Persistent Disk regional o Hyperdisk Balanced de alta disponibilidad funciona en modo de replicación completa, en el que las solicitudes para leer o escribir en el disco se envían a ambas réplicas.
En el modo de replicación completa, ocurre lo siguiente:
- Al escribir, una solicitud de escritura intenta escribir en ambas réplicas y confirma cuando ambas escrituras se realizan correctamente.
- Al leer, la VM envía una solicitud de lectura a ambas réplicas y devuelve los resultados de la que se complete correctamente. Si se agota el tiempo de espera de la solicitud de lectura, se envía otra solicitud de lectura.
Si una réplica se retrasa o no confirma que se han completado las solicitudes de lectura o escritura, se actualiza el estado de la réplica.
Comprobaciones del estado
El agente de comprobación del estado implementa las comprobaciones del estado que usa el balanceador de carga. El agente de comprobación del estado tiene dos finalidades:
- El agente de comprobación del estado reside en las VMs principales y secundarias para monitorizar las instancias de VM y comunicarse con el balanceador de carga para dirigir el tráfico. Esta opción funciona mejor cuando se configura con grupos de instancias.
- El agente de comprobación del estado se sincroniza con el plano de control regional específico de la aplicación y toma decisiones de conmutación por error en función del comportamiento del plano de control. El plano de control debe estar en una zona diferente a la de la instancia de VM cuyo estado monitoriza.
El propio agente de comprobación del estado debe ser tolerante a fallos. Por ejemplo, en la imagen siguiente, el plano de control está separado de la instancia de VM principal, que se encuentra en la zona us-central1-a, mientras que la VM de reserva se encuentra en la zona us-central1-f.
Siguientes pasos
- Consulta cómo crear y gestionar discos regionales.
- Consulta información sobre la replicación asíncrona.
- Consulta cómo configurar una instancia de clúster de conmutación por error de SQL Server para discos en el modo de escritura múltiple.
- Consulta cómo crear aplicaciones web escalables y resilientes en Google Cloud.
- Consulta la guía de planificación para la recuperación tras fallos.