Como criar serviços de alta disponibilidade com discos regionais
Nesta seção, explicamos como criar serviços de alta disponibilidade com os discos do Persistent Disk regional ou Alta disponibilidade do hiperdisco equilibrada.
Considerações sobre o design
Antes de começar a projetar um serviço de HA, você precisa entender as características do aplicativo, do sistema de arquivos e do sistema operacional. Elas são a base do design e servem para você determinar as abordagens apropriadas. Por exemplo, se um aplicativo não é compatível com a replicação no nível dele, algumas opções de design correspondentes não serão aplicáveis.
Da mesma forma, se o aplicativo, o sistema de arquivos ou o sistema operacional não estiverem tolerantes a falhas, usar o Persistent Disk regional ou a Alta disponibilidade do hiperdisco equilibrada ou até mesmo snapshots de discos zonais pode não ser uma opção. A tolerância a falhas é definida como a capacidade de se recuperar após uma interrupção repentina sem perder ou corromper dados que já foram confirmados em um disco antes da falha.
Considere o seguinte ao projetar para alta disponibilidade:
- O efeito do uso da Alta disponibilidade do hiperdisco equilibrada, um Persistent Disk regional ou outras soluções.
- Desempenho de gravação do disco.
- O objetivo do tempo de recuperação do serviço, ou seja, a rapidez com que o serviço se recupera de uma interrupção zonal e os requisitos de SLA.
- O custo para criar uma arquitetura de serviço resiliente e confiável.
- Para mais informações sobre considerações específicas de cada região, consulte Geografia e regiões.
Em termos de custo, use as seguintes opções para replicação de aplicativos síncrona e assíncrona:
Usar duas instâncias do banco de dados e da VM. Nesse caso, o custo total é determinado pelos itens a seguir:
- Custos da instância de VM
- Persistent Disk ou Custos do hiperdisco
- Custos de manutenção da replicação de aplicativos
Usar uma única VM com discos replicados de forma síncrona. Para alcançar a alta disponibilidade com um Persistent Disk regional ou disco de alta disponibilidade do hiperdisco equilibrada, use a mesma instância de VM e de disco como a opção anterior, mas também inclua um disco replicado sincronizadamente. Os Persistent Disks regionais e discos de alta disponibilidade do hiperdisco equilibrada têm o dobro do custo por byte em comparação com os discos zonais, porque eles são replicados em duas zonas de controle.
No entanto, usar discos replicados de forma síncrona pode reduzir o custo de manutenção, já que os dados são gravados automaticamente em duas réplicas sem a necessidade de manter a replicação do aplicativo.
Não inicie a VM secundária até que o failover seja necessário. É possível reduzir os custos de host ainda mais, iniciando a VM secundária apenas sob demanda durante o failover em vez de manter a VM como uma VM em espera ativa.
Comparar custo, desempenho e resiliência
Veja na tabela a seguir comparações relacionadas ao custo, desempenho e resiliência de diferentes arquiteturas de serviço.
| Arquitetura de serviço de HA |
Snapshots de disco zonal |
Replicação síncrona no nível do aplicativo |
Replicação assíncrona no nível do aplicativo |
Discos regionais |
|---|---|---|---|---|
| Proteção contra falhas de aplicativos, VMs e zonas* | ||||
| Mitigação contra corrupção dos aplicativos (por exemplo: intolerância a falhas) | † | † | ||
| Custo | $ |
$$
|
$$
|
$1,5x - $$
|
| Desempenho dos aplicativos |
|
|
|
|
| Adequado para aplicativos com poucos requisitos de RPO (tolerância muito baixa para perda de dados) |
|
|
|
|
| Tempo de recuperação de desastres do armazenamento# |
|
|
|
|
* O uso de discos ou snapshots regionais não é suficiente para evitar e mitigar falhas e dados corrompidos. O aplicativo, o sistema de arquivos e, possivelmente, outros componentes de software precisam ser consistentes nas falhas ou usar algum tipo de encerramento.
† A replicação de alguns aplicativos fornece mitigação contra algumas corrupções de aplicativos. Por exemplo, a corrupção principal do aplicativo MySQL não faz com que as instâncias da VM de réplica também sejam corrompidas. Consulte a documentação do seu aplicativo para mais detalhes.
‡ A perda de dados é a perda irreversível de dados confirmados no armazenamento permanente. Todos os dados não confirmados ainda serão perdidos.
# O desempenho do failover não inclui a verificação do sistema de arquivos e a recuperação e o carregamento do aplicativo após o failover.
Como criar serviços de banco de dados de alta disponibilidade usando discos regionais
Esta seção aborda conceitos de alto nível para a criação de soluções de alta disponibilidade para serviços de banco de dados com estado (MySQL, Postgres etc.) usando o Compute Engine com Persistent Disks regionais e discos de Alta disponibilidade do hiperdisco equilibrada.
Se houver grandes interrupções no Google Cloud, por exemplo, se uma região inteira ficar indisponível, o aplicativo poderá ficar indisponível. Dependendo das suas necessidades, considere técnicas de replicação entre regiões ou replicação assíncrona para ter uma disponibilidade ainda maior.
Geralmente, as configurações de HA do banco de dados têm pelo menos duas instâncias de VM. De preferência, essas instâncias de VM fazem parte de um ou mais grupos gerenciados de instâncias:
- Uma instância de VM principal na zona primária
- Uma instância de VM em espera em uma zona secundária
Uma instância de VM principal tem pelo menos dois discos: um de inicialização e um disco regional. O disco regional contém dados do banco de dados e outros dados mutáveis que precisam ser preservados em uma zona diferente no caso de interrupção.
Uma instância de VM em espera requer um disco de inicialização separado para poder se recuperar de interrupções relacionadas à configuração. Por exemplo, como resultado de um upgrade do sistema operacional. Além disso, não é possível forçar a anexação de um disco de inicialização a outro durante um failover.
As instâncias de VM principal e em espera são configuradas para usar um balanceador de carga com o tráfego direcionado à VM primária, com base nos sinais da verificação de integridade. Em "Cenário de recuperação de desastres para dados", há uma descrição de outras configurações de failover que podem ser mais apropriadas para seu caso.
Desafios da replicação do banco de dados
A tabela a seguir lista alguns desafios comuns de configurar e gerenciar a replicação síncrona ou semissíncrona do aplicativo (como MySQL) e como elas se comparam com a replicação síncrona de disco com o Persistent Disk regional e discos de Alta disponibilidade do hiperdisco equilibrada.
| Desafios | Replicação síncrona ou semissíncrona do aplicativo |
Replicação síncrona do disco |
|---|---|---|
| Manter a estabilidade entre a réplica primária e de failover. | Muitas coisas podem dar errado e fazer uma instância de VM
sair do modo de HA:
|
As falhas de armazenamento são resolvidas pelo Persistent Disk regional e discos de Alta disponibilidade do hiperdisco equilibrada. Isso acontece com transparência no aplicativo, exceto se ocorrer uma possível flutuação no desempenho do disco. É necessário ter verificações de integridade definidas pelo usuário para revelar problemas no aplicativo ou na VM e acionar o failover. |
| O tempo total do failover é maior do que o esperado. | O tempo necessário para a operação de failover não tem um limite superior. Aguardar a repetição de todas as transações (etapa 2 acima) pode demorar bastante dependendo do esquema e da carga no banco de dados. | Persistent Disk regional e discos de Alta disponibilidade do hiperdisco equilibrada fornecem replicação síncrona, de modo que o tempo de failover seja limitado pela soma das seguintes latências:
|
| Dupla personalidade | Para evitar dupla personalidade (em inglês), as duas abordagens requerem ações para garantir que haja apenas um primário por vez. | |
Sequência de operações de leitura e gravação em discos
Para determinar as sequências de leitura e gravação ou a ordem em que os dados são lidos e gravados no disco, a maior parte do trabalho é feita pelo driver de disco da VM. Como usuário, você não precisa lidar com a semântica de replicação e pode interagir com o sistema de arquivos normalmente. O driver subjacente processa a sequência de leitura e gravação.
Por padrão, uma VM do Compute Engine com o Persistent Disk regional ou a Alta disponibilidade do hiperdisco equilibrada opera no modo de replicação completa, em que as solicitações para ler ou gravar no disco são enviadas a ambas as réplicas.
No modo de replicação completa, ocorre o seguinte:
- Durante a gravação, uma solicitação de gravação tenta fazer a gravação nas duas réplicas e confirma quando isso é feito com êxito.
- Durante a leitura, a VM envia uma solicitação de leitura às duas réplicas e apresenta os resultados daquela que foi bem sucedida. Se a solicitação de leitura expirar, outra solicitação de leitura será enviada.
Se uma réplica ficar para trás ou não reconhecer que as solicitações de leitura ou gravação foram concluídas, o status da réplica será atualizado.
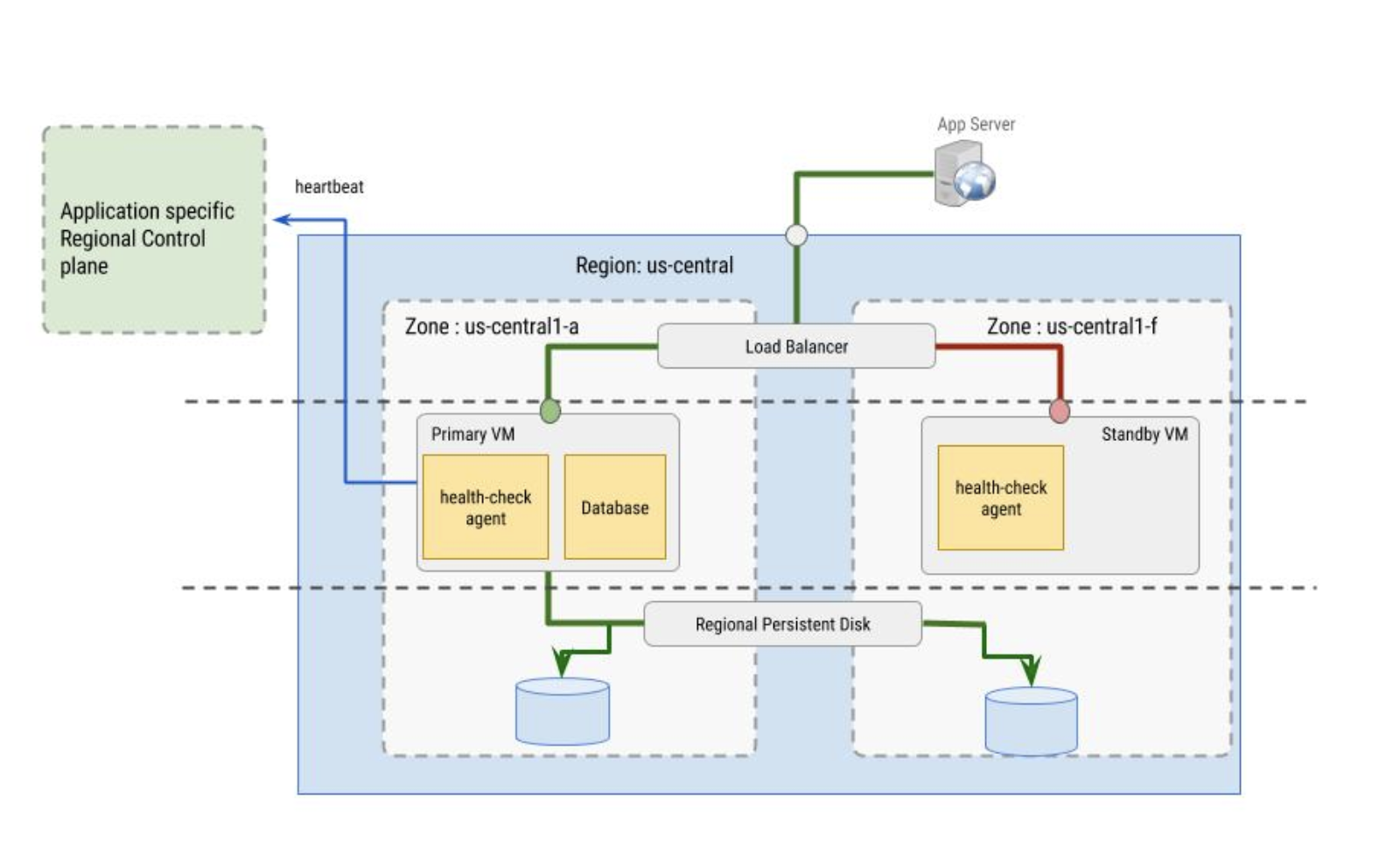
Verificações de integridade
As verificações de integridade usadas pelo balanceador de carga são implementadas pelo agente. O agente de verificação de integridade tem estas duas finalidades:
- O agente de verificação de integridade está localizado nas VMs primária e secundária. Ele monitora as instâncias de VM e se comunica com o balanceador de carga para direcionar o tráfego. Isso funciona melhor quando configurado com grupos de instâncias.
- O agente de verificação de integridade é sincronizado com o plano de controle regional específico do aplicativo. Ele toma decisões de failover com base no comportamento desse plano de controle, que precisa estar em uma zona diferente da instância de VM que está tendo a integridade verificada.
O próprio agente de verificação de integridade precisa ser tolerante a falhas. Por exemplo, veja na imagem a seguir que o plano de controle está separado da instância de VM primária. Essa instância está na zona us-central1-a, enquanto a VM em espera está na zona us-central1-f.
A seguir
- Saiba como criar e gerenciar discos regionais.
- Saiba mais sobre a replicação assíncrona.
- Saiba como configurar uma instância de cluster de failover do SQL Server para discos no modo de vários gravadores.
- Saiba como criar aplicativos da Web escalonáveis e resilientes no Google Cloud.
- Consulte o guia de planejamento de recuperação de desastres.