Persistent Disk a livello regionale e Hyperdisk bilanciato ad alta affidabilità sono opzioni di archiviazione che ti consentono di implementare servizi ad alta affidabilità (HA) in Compute Engine. Persistent Disk a livello regionale e Hyperdisk bilanciato ad alta affidabilità replicano in modo sincrono i dati tra due zone nella stessa regione e garantiscono l'alta affidabilità per i dati del disco in caso di un massimo di un errore circoscritto a una zona.
Creazione di servizi ad alta affidabilità con dischi a livello regionale
Questa sezione spiega come creare servizi ad alta affidabilità con Persistent Disk a livello regionaleo Hyperdisk bilanciato ad alta affidabilità.
Considerazioni sulla progettazione
Prima di iniziare a progettare un servizio ad alta affidabilità, comprendi le caratteristiche dell'applicazione, del file system e del sistema operativo. Queste caratteristiche sono la base della progettazione e possono escludere vari approcci. Ad esempio, se un'applicazione non supporta la replica a livello di applicazione, alcune opzioni di progettazione corrispondenti non sono applicabili.
Analogamente, se l'applicazione, il file system o il sistema operativo non tollerano un arresto anomalo, l'utilizzo di Persistent Disk a livello regionalee Hyperdisk bilanciato ad alta affidabilitào anche di snapshot dei dischi a livello di zona potrebbe non essere un'opzione. La tolleranza agli arresti anomali è definita come la capacità di recupero da un'interruzione non prevista senza perdere o danneggiare i dati di cui già è stato eseguito il commit su un disco prima dell'arresto anomalo.
Quando progetti in termini di alta affidabilità, tieni presente quanto segue:
- L'effetto sull'applicazione dell'utilizzo di Hyperdisk bilanciato ad alta affidabilità, Persistent Disk a livello regionale o altre soluzioni.
- Prestazioni di scrittura sul disco.
- Recovery Time Objective (RTO): la rapidità con cui il servizio deve riprendersi da un'interruzione di zona e i requisiti dell'SLA.
- Il costo per creare un'architettura di servizio resiliente e affidabile.
- Per saperne di più sulle considerazioni specifiche per le regioni, consulta Area geografica e regioni.
In termini di costi, utilizza le seguenti opzioni per la replica delle applicazioni sincrona e asincrona:
Utilizza due istanze del database e della VM. In questo caso, il costo totale è determinato dai seguenti elementi:
- Costi delle istanze VM
- Costi di Persistent Disko Hyperdisk
- Costi di gestione della replica delle applicazioni
Utilizza una singola VM con dischi replicati in modo sincrono. Per ottenere un'alta affidabilità con un Persistent Disk a livello regionale o un disco Hyperdisk bilanciato ad alta affidabilità , utilizza la stessa istanza VM e gli stessi componenti del disco dell'opzione precedente, ma includi anche un disco sottoposto a replica sincrona.I Persistent Disk a livello regionale e i dischi Hyperdisk bilanciati ad alta affidabilità hanno un costo per byte doppio rispetto ai dischi a livello di zona perché vengono replicati in due zone.
Tuttavia, l'utilizzo di dischi con replica sincrona potrebbe ridurre il costo di manutenzione perché i dati vengono scritti automaticamente in due repliche senza che sia necessario mantenere la replica dell'applicazione.
Non avviare la VM secondaria finché non è necessario il failover. Puoi ridurre ulteriormente i costi dell'host avviando la VM secondaria solo on demand durante il failover anziché mantenerla come VM di riserva attiva.
Confronta costi, prestazioni e resilienza
La tabella seguente mette in evidenza i compromessi in termini di costi, prestazioni e resilienza per le diverse architetture di servizio.
| Architettura di servizio ad alta affidabilità |
Snapshot dei dischi a livello di zona |
Livello di applicazione sincrono |
Livello di applicazione asincrono |
Dischi regionali |
|---|---|---|---|---|
| Protegge da errori di applicazioni, VM e zone* | ||||
| Mitigazione della corruzione delle applicazioni (esempio: non tolleranza degli arresti anomali dell'applicazione) | † | † | ||
| Costo | $ |
$$
|
$$
|
$1,5x - $$
|
| Prestazioni delle applicazioni |
|
|
|
|
| Adatta per applicazioni con requisiti RPO ridotti (tolleranza molto bassa alla perdita di dati) |
|
|
|
|
| Tempo di recupero dello spazio di archiviazione dopo un disastro# |
|
|
|
|
* L'utilizzo di snapshot o dischi a livello regionale non è sufficiente per proteggere da errori e danneggiamenti e per mitigarli. L'applicazione, il file system ed eventualmente altri componenti software devono essere coerenti in caso di arresto anomalo o utilizzare una sorta di quiescenza.
† La replica di alcune applicazioni consente di mitigare alcuni problemi di corruzione delle applicazioni. Ad esempio, la corruzione dell'applicazione MySQL principale non causa la corruzione anche delle istanze VM di replica. Per maggiori dettagli, consulta la documentazione dell'applicazione.
‡ Per perdita di dati si intende la perdita non recuperabile di dati di cui è stato eseguito il commit nell'archiviazione permanente. Tutti i dati non sottoposti a commit andranno persi.
# Le prestazioni del failover non includono il controllo del file system, il recupero e il caricamento delle applicazioni dopo il failover.
Creazione di servizi di database ad alta affidabilità utilizzando dischi a livello regionale
Questa sezione illustra concetti di alto livello per la creazione di soluzioni ad alta affidabilità per servizi di database stateful (MySQL, Postgres ecc.) che utilizzano Compute Engine con Persistent Disk a livello regionalee Hyperdisk bilanciato ad alta affidabilità .
Se si verificano interruzioni generali in Google Cloud, ad esempio se un'intera regione diventa non disponibile, la tua applicazione potrebbe non essere disponibile. A seconda delle tue esigenze, valuta le tecniche di replica tra regioni o la replica asincrona per un'affidabilità ancora maggiore.
Le configurazioni ad alta affidabilità del database hanno in genere almeno due istanze VM. È preferibile che queste istanze VM facciano parte di uno o più gruppi di istanze gestite:
- Un'istanza VM principale nella zona principale
- Un'istanza VM di riserva in una zona secondaria
Un'istanza VM principale ha almeno due dischi: un disco di avvio e un disco regionale. Il disco regionale contiene i dati del database e qualsiasi altro dato mutabile che deve essere conservato in un'altra zona in caso di interruzione del servizio.
Un'istanza VM di riserva richiede un disco di avvio separato per poter recuperare da interruzioni correlate alla configurazione, ad esempio a seguito di un upgrade del sistema operativo. Inoltre, non puoi forzare il collegamento di un disco di avvio a un'altra VM durante un failover.
Le istanze VM principali e di riserva sono configurate per utilizzare un bilanciatore del carico con il traffico indirizzato alla VM principale in base agli indicatori dei controlli di integrità. Lo scenario di disaster recovery dei dati descrive altre configurazioni di failover, che potrebbero essere più appropriate per il tuo scenario.
Problemi con la replica del database
La tabella seguente elenca alcune difficoltà comuni con la configurazione e la gestione della replica sincrona o semi-sincrona delle applicazioni (come MySQL) e il loro confronto con la replica sincrona dei dischi con Persistent Disk a livello regionalee Hyperdisk bilanciato ad alta affidabilità .
| Sfide | Replica sincrona o semi-sincrona dell'applicazione |
Replica sincrona dei dischi |
|---|---|---|
| Mantenimento di una replica stabile tra la replica principale e quella di failover. | Esistono diversi fattori che possono causare un errore e la conseguente uscita di un'istanza VM dalla modalità ad alta affidabilità:
|
Gli errori di archiviazione vengono gestiti da Persistent Disk a livello regionale e Hyperdisk bilanciato ad alta affidabilità . Questo avviene in modo trasparente per l'applicazione, tranne per una possibile fluttuazione delle prestazioni del disco. Devono essere presenti controlli di integrità definiti dall'utente per rilevare eventuali problemi relativi all'applicazione o alla VM e attivare il failover. |
| Il tempo di failover end-to-end è più lungo del previsto. | Il tempo necessario per l'operazione di failover non ha un limite superiore. L'attesa del replay di tutte le transazioni (passaggio 2 sopra) potrebbe richiedere un tempo arbitrariamente lungo, a seconda dello schema e del carico sul database. | I dischi Persistent Disk a livello regionalee Hyperdisk bilanciato ad alta affidabilità forniscono la replica sincrona, pertanto il tempo di failover è limitato dalla somma delle seguenti latenze:
|
| Split-brain | Per evitare lo split-brain, entrambi gli approcci richiedono delle disposizioni per garantire che sia presente un solo account principale alla volta. | |
Sequenza di operazioni di lettura e scrittura sui dischi
Per determinare le sequenze di lettura e scrittura o l'ordine in cui i dati vengono letti e scritti sul disco, la maggior parte del lavoro viene eseguita dal driver del disco nella tua VM. In qualità di utente, non devi occuparti della semantica della replica e puoi interagire con il file system come di consueto. Il driver sottostante gestisce la sequenza per la lettura e la scrittura.
Per impostazione predefinita, una VM Compute Engine con Persistent Disk a livello regionaleo Hyperdisk bilanciato ad alta affidabilitàopera in modalità di replica completa, in cui le richieste di lettura o scrittura dal disco vengono inviate a entrambe le repliche.
In modalità di replica completa, si verifica quanto segue:
- Durante la scrittura, una richiesta di scrittura tenta di scrivere in entrambe le repliche e conferma quando entrambe le scritture vanno a buon fine.
- Durante la lettura, la VM invia una richiesta di lettura a entrambe le repliche e restituisce i risultati di quella che va a buon fine. Se la richiesta di lettura scade con timeout, viene inviata un'altra richiesta di lettura.
Se una replica non è aggiornata o non riesce a inviare la conferma del completamento delle richieste di lettura o scrittura, lo stato della replica viene aggiornato.
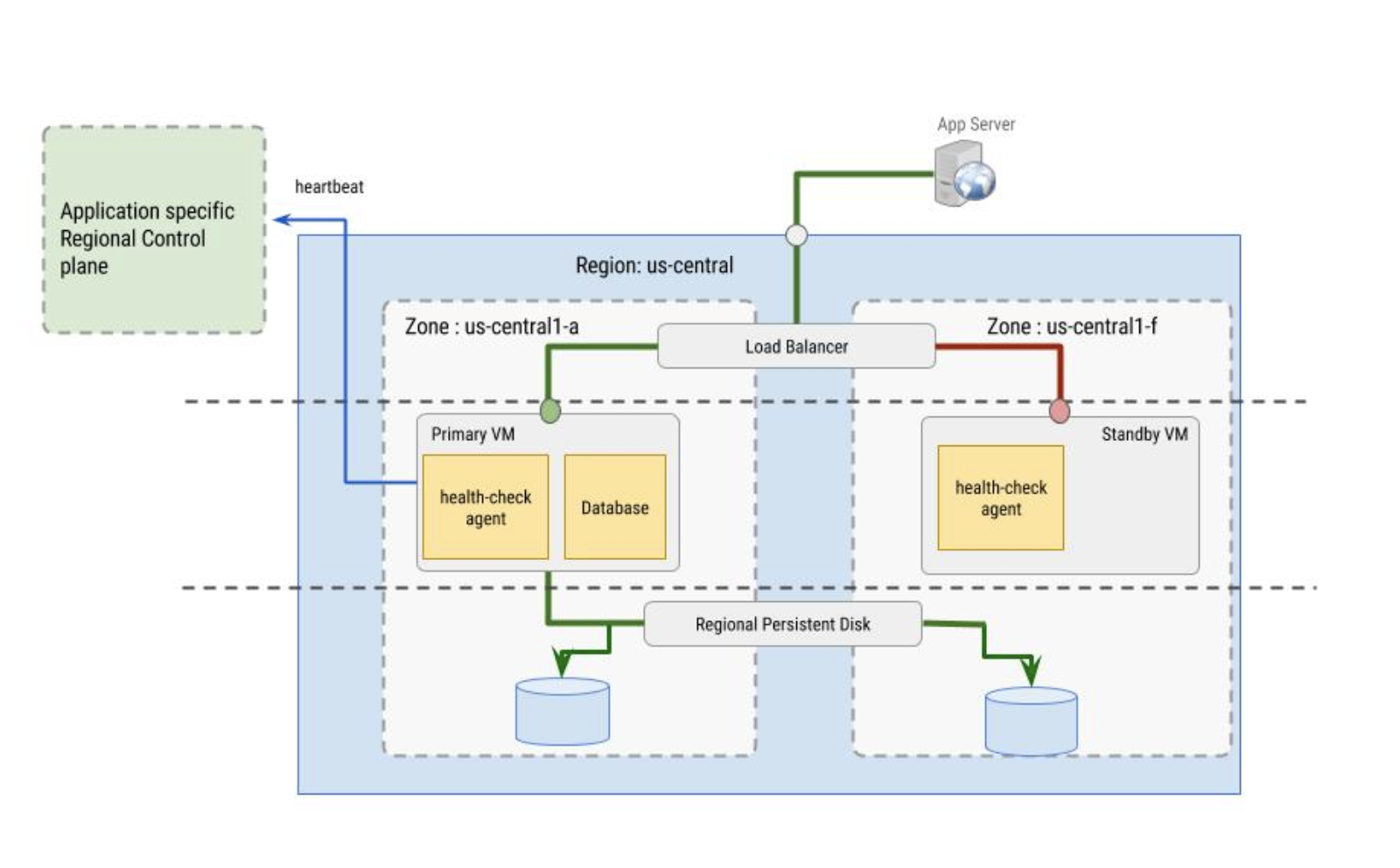
Controlli di integrità
I controlli di integrità utilizzati dal bilanciatore del carico vengono implementati dall'agente di controllo di integrità. L'agente di controllo di integrità ha due scopi:
- L'agente di controllo di integrità si trova nelle VM principali e secondarie per monitorare le istanze VM e comunicare con il bilanciatore del carico per indirizzare il traffico. Questo approccio offre risultati ottimali se configurato con gruppi di istanze.
- L'agente di controllo di integrità si sincronizza con il control plane regionale specifico dell'applicazione e prende decisioni di failover in base al comportamento del control plane. Il control plane deve trovarsi in una zona diversa dall'istanza VM di cui sta monitorando l'integrità.
L'agente di controllo di integrità stesso deve essere a tolleranza di errore. Ad esempio, occorre notare che nell'immagine seguente, il control plane è separato dall'istanza VM
principale, che si trova nella zona us-central1-a, mentre la VM di riserva si trova nella zona us-central1-f.
Passaggi successivi
- Scopri come creare e gestire i dischi regionali.
- Scopri di più sulla replica asincrona.
- Scopri come configurare un'istanza del cluster di failover SQL Server per i dischi in modalità multi-autore.
- Scopri come creare applicazioni web scalabili e resilienti su Google Cloud.
- Consulta la guida alla pianificazione del disaster recovery.