Ce document explique comment faire évoluer un groupe d'instances géré (MIG) en fonction de la capacité de diffusion d'un équilibreur de charge d'application externe ou interne. Cela signifie que l'autoscaling ajoute ou supprime des instances de VM dans le groupe lorsque l'équilibreur de charge indique que le groupe a atteint une fraction configurable de son utilisation maximale, où l'utilisation maximale est définie par la capacité cible du mode d'équilibrage sélectionné pour le groupe d'instances backend.
Vous pouvez également faire évoluer un groupe d'instances géré en fonction de son utilisation du processeur ou des métriques Cloud Monitoring.
Limites
Vous pouvez procéder à un autoscaling sur un groupe d'instances géré en fonction de la capacité de diffusion d'un Équilibreur de charge d'application externe et d'un Équilibreur de charge d'application interne. Les autres types d'équilibreurs de charge ne sont pas compatibles.
Avant de commencer
- Examinez les limites de l'autoscaler.
- Découvrez les principes de base de l'autoscaler.
-
Si ce n'est pas déjà fait, configurez l'authentification.
L'authentification permet de valider votre identité pour accéder aux services et aux API Google Cloud . Pour exécuter du code ou des exemples depuis un environnement de développement local, vous pouvez vous authentifier auprès de Compute Engine en sélectionnant l'une des options suivantes :
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Installez la Google Cloud CLI. Une fois l'installation terminée, initialisez la Google Cloud CLI en exécutant la commande suivante :
gcloud initSi vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
- Set a default region and zone.
REST
Pour utiliser les exemples API REST de cette page dans un environnement de développement local, vous devez utiliser les identifiants que vous fournissez à la gcloud CLI.
Installez la Google Cloud CLI. Une fois l'installation terminée, initialisez la Google Cloud CLI en exécutant la commande suivante :
gcloud initSi vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
Pour en savoir plus, consultez la section S'authentifier pour utiliser REST dans la documentation sur l'authentification Google Cloud .
Scaling basé sur la capacité de diffusion de l'équilibrage de charge HTTP(S)
Compute Engine est compatible avec l'équilibrage de charge au sein de vos groupes d'instances. Vous pouvez utiliser l'autoscaling en conjonction avec l'équilibrage de charge en configurant un autoscaler dont le fonctionnement est basé sur la charge de vos instances.
Un équilibreur de charge HTTP(S) externe ou interne répartit les requêtes entre les différents services de backend en fonction de son mappage d'URL. L'équilibreur de charge peut avoir un ou plusieurs services de backend, chacun acceptant des backends de groupes d'instances ou de groupes de points de terminaison du réseau. Lorsque les backends sont des groupes d'instances, l'équilibreur de charge HTTP(S) propose deux modes d'équilibrage :
UTILIZATIONetRATE. AvecUTILIZATION, vous pouvez spécifier une cible maximale pour l'utilisation moyenne du backend d'instances de ce groupe d'instances. AvecRATE, vous devez spécifier un nombre cible de requêtes par seconde, par instance ou par groupe. Notez que seuls les groupes d'instances zonaux permettent de spécifier un débit maximal pour l'ensemble du groupe. Les groupes d'instances gérés régionaux ne sont pas compatibles avec la définition d'un débit maximal par groupe.Le mode d'équilibrage et la capacité cible que vous spécifiez définissent les conditions dans lesquelles Google Cloud détermine le moment auquel une VM de backend est à pleine capacité. Google Cloud tente d'envoyer le trafic vers des VM saines qui n'ont pas atteint leur capacité maximale. Si toutes les VM sont déjà saturées, la cible maximale d'utilisation ou de débit est dépassée.
Lorsque vous associez un autoscaler à un backend de groupe d'instances d'un équilibreur de charge HTTP(S), l'autoscaler fait évoluer le groupe d'instances géré pour maintenir une fraction de la capacité de diffusion de l'équilibrage de charge.
Supposons par exemple que la capacité de diffusion de l'équilibrage de charge d'un groupe d'instances géré soit définie sur 100 RPS par instance. Si vous créez un autoscaler avec la règle d'équilibrage HTTP(S) et que vous définissez un niveau d'utilisation cible de 0,8 ou 80 %, l'autoscaler ajoute ou supprime des instances du groupe d'instances géré afin de maintenir la capacité de diffusion à 80 % de sa capacité totale, soit 80 RPS par instance.
Le schéma suivant illustre l'interaction de l'autoscaler avec un groupe d'instances géré et un service backend :
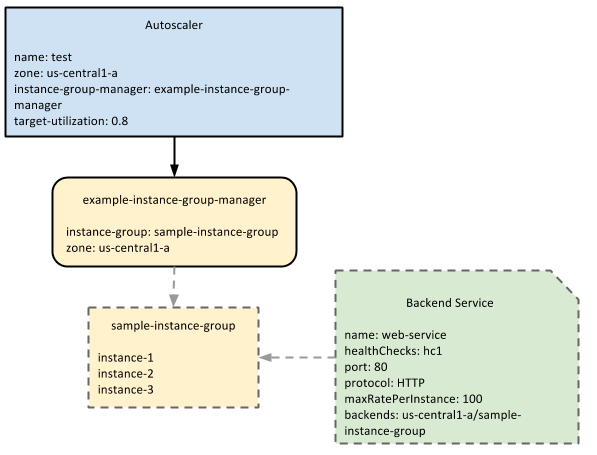
L'autoscaler surveille la capacité de diffusion du groupe d'instances géré défini dans le service de backend et effectue un scaling en fonction de l'objectif d'utilisation. Dans cet exemple, la capacité de traitement est mesurée dans la valeur maxRatePerInstance.Configurations d'équilibrage de charge applicables
Vous pouvez définir l'une des trois options suivantes pour votre équilibrage de charge capacité de diffusion. Lorsque vous créez le backend, vous avez le choix de l'utilisation maximale du backend, du nombre maximal de requêtes par seconde et du nombre maximal de requêtes par seconde pour l'ensemble du groupe. L'autoscaling fonctionne uniquement avec l'utilisation maximale du backend et le nombre maximal de requêtes par seconde et par instance, car la valeur de ces paramètres peut être contrôlée en ajoutant ou en supprimant des instances. Par exemple, si vous définissez un backend pour gérer 10 requêtes par seconde et par instance alors que l'autoscaler est configuré pour conserver 80 % de ce débit, l'autoscaler peut ajouter ou supprimer des instances lorsque le nombre de requêtes par seconde et par instance change.
L'autoscaling ne fonctionne pas avec le nombre maximal de requêtes par groupe, car ce paramètre est indépendant du nombre d'instances présentes dans le groupe d'instances. L'équilibreur de charge envoie en continu le nombre maximal de requêtes par groupe au groupe d'instances, quel que soit le nombre d'instances présentes dans le groupe.
Par exemple, si vous définissez le backend pour gérer 100 requêtes maximum par groupe et par seconde, l'équilibreur de charge envoie 100 requêtes par seconde au groupe, que le groupe ait deux ou 100 instances. Cette valeur ne peut pas être ajustée. L'autoscaling ne fonctionne donc pas avec une configuration d'équilibrage de charge qui utilise le nombre maximal de requêtes par seconde et par groupe.
Activer l'autoscaling basé sur la capacité de diffusion de l'équilibrage de charge
Console
- Accédez à la page Groupes d'instances dans la console Google Cloud .
- Si vous disposez d'un groupe d'instances, sélectionnez-le, puis cliquez sur Modifier. Si vous n'en avez pas, cliquez sur Créer un groupe d'instances.
- Cliquez sur Taille du groupe et autoscaling pour développer la section.
- Dans la liste Mode Autoscaling, assurez-vous que l'option Activé : ajouter et supprimer des instances dans le groupe est sélectionnée.
- Spécifiez le nombre minimal et maximal d'instances que l'autoscaler doit créer dans ce groupe.
- Dans la section Signaux d'autoscaling, cliquez sur Ajouter un signal.
- Définissez le Type de signal sur Utilisation de l'équilibrage de charge HTTP.
Saisissez la valeur Utilisation cible de l'équilibrage de charge HTTP en pourcentage. Par exemple, pour 60 % d'utilisation de l'équilibrage de la charge HTTP, saisissez
60.Vous pouvez utiliser le champ Période d'initialisation pour définir la période d'initialisation, qui indique à l'autoscaler le temps nécessaire à l'initialisation de votre application. Spécifier une période d'initialisation précise améliore les décisions de l'autoscaler. Par exemple, lors d'un scaling horizontal, l'autoscaler ignore les données des VM qui sont toujours en cours d'initialisation, car il est possible que ces VM ne représentent pas encore une utilisation normale de l'application. La période d'initialisation par défaut est de 60 secondes.
Enregistrez les modifications.
gcloud
Pour activer un autoscaler qui évolue en fonction de la capacité de traitement, utilisez la sous-commande
set-autoscaling. Par exemple, la commande suivante crée un autoscaler qui effectue un scaling du groupe d'instances géré cible afin de maintenir 60 % de la capacité de diffusion. Outre le paramètre--target-load-balancing-utilization, le paramètre--max-num-replicasest également obligatoire lors de la création d'un autoscaler :gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \ --max-num-replicas 20 \ --target-load-balancing-utilization 0.6 \ --cool-down-period 90Vous pouvez utiliser l'option
--cool-down-periodpour définir la période d'initialisation, qui indique à l'autoscaler le temps nécessaire à l'initialisation de votre application. Spécifier une période d'initialisation précise améliore les décisions de l'autoscaler. Par exemple, lors d'un scaling horizontal, l'autoscaler ignore les données des VM qui sont toujours en cours d'initialisation, car il est possible que ces VM ne représentent pas encore une utilisation normale de l'application. La période d'initialisation par défaut est de 60 secondes.Vous pouvez vérifier que l'autoscaler a bien été créé à l'aide de la sous-commande
instance-groups managed describe:gcloud compute instance-groups managed describe example-managed-instance-group
Pour obtenir la liste des commandes et indicateurs
gclouddisponibles, consultez la référencegcloud.REST
Pour créer un autoscaler, utilisez la méthode
autoscalers.insertpour un MIG zonal ou la méthoderegionAutoscalers.insertpour un MIG régional.L'exemple suivant crée un autoscaler pour un MIG zonal :
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
Le corps de votre requête doit contenir les champs
name,targetetautoscalingPolicy.autoscalingPolicydoit définirloadBalancingUtilization.Vous pouvez utiliser le champ
coolDownPeriodSecpour définir la période d'initialisation, qui indique à l'autoscaler le temps nécessaire à l'initialisation de votre application. Spécifier une période d'initialisation précise améliore les décisions de l'autoscaler. Par exemple, lors d'un scaling horizontal, l'autoscaler ignore les données des VM qui sont toujours en cours d'initialisation, car il est possible que ces VM ne représentent pas encore une utilisation normale de l'application. La période d'initialisation par défaut est de 60 secondes.{ "name": "example-autoscaler", "target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group", "autoscalingPolicy": { "maxNumReplicas": 20, "loadBalancingUtilization": { "utilizationTarget": 0.8 }, "coolDownPeriodSec": 90 } }Pour plus d'informations sur l'activation de l'autoscaling basé sur la capacité de diffusion de l'équilibrage de charge, suivez le tutoriel Procéder à l'autoscaling d'un service Web à l'échelle mondiale sur Compute Engine.
Étape suivante
- Découvrez comment gérer les autoscalers.
- Découvrez comment les autoscalers prennent des décisions.
- Découvrez comment utiliser plusieurs signaux d'autoscaling pour effectuer un scaling de votre groupe.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/10/19 (UTC).
-