En este documento se describe cómo escalar un grupo de instancias gestionado (MIG) en función de la capacidad de servicio de un balanceador de carga de aplicaciones externo o interno. Esto significa que el autoescalado añade o elimina instancias de VM del grupo cuando el balanceador de carga indica que el grupo ha alcanzado una fracción configurable de su capacidad, donde la capacidad se define mediante la capacidad objetivo del modo de balanceo seleccionado del grupo de instancias de backend.
También puedes escalar un MIG en función de su uso de CPU o de las métricas de Monitoring.
Limitaciones
Puedes autoescalar un grupo de instancias gestionado en función de la capacidad de servicio de un balanceador de carga de aplicación externo y de un balanceador de carga de aplicación interno. No se admiten otros tipos de balanceadores de carga.
Antes de empezar
- Consulta las limitaciones de la herramienta de ajuste automático de escala.
- Consulta los conceptos básicos del escalado automático.
-
Si aún no lo has hecho, configura la autenticación.
La autenticación verifica tu identidad para acceder a Google Cloud servicios y APIs. Para ejecutar código o ejemplos desde un entorno de desarrollo local, puedes autenticarte en Compute Engine seleccionando una de las siguientes opciones:
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
gcloud
-
Instala Google Cloud CLI. Después de la instalación, inicializa la CLI de Google Cloud ejecutando el siguiente comando:
gcloud initSi utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
- Set a default region and zone.
REST
Para usar las muestras de la API REST de esta página en un entorno de desarrollo local, debes usar las credenciales que proporciones a la CLI de gcloud.
Instala Google Cloud CLI. Después de la instalación, inicializa la CLI de Google Cloud ejecutando el siguiente comando:
gcloud initSi utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
Para obtener más información, consulta el artículo Autenticarse para usar REST de la documentación sobre autenticación de Google Cloud .
Escalar según la capacidad de servicio de balanceo de carga HTTP o HTTPS
Compute Engine ofrece asistencia para el balanceo de carga en tus grupos de instancias. Puedes usar el autoescalado junto con el balanceo de carga configurando un autoescalador que se ajuste en función de la carga de tus instancias.
Un balanceador de carga HTTP(S) externo o interno distribuye las solicitudes a los servicios de backend según su mapa de URLs. El balanceador de carga puede tener uno o varios servicios de backend, cada uno de los cuales admite backends de grupos de instancias o de grupos de puntos finales de red (NEG). Cuando los backends son grupos de instancias, el balanceador de carga HTTP(S) ofrece dos modos de balanceo:
UTILIZATIONyRATE. ConUTILIZATION, puede especificar un objetivo máximo para la utilización media del backend de las instancias del grupo de instancias. ConRATE, debes especificar un número objetivo de solicitudes por segundo por instancia o por grupo. Solo los grupos de instancias zonales admiten la especificación de una frecuencia máxima para todo el grupo. Los grupos de instancias gestionadas regionales no admiten la definición de una tarifa máxima por grupo.El modo de balanceo y la capacidad objetivo que especifiques definen las condiciones en las que Google Cloud determina cuándo una VM de backend está a plena capacidad. Google Cloud intenta enviar tráfico a las VMs en buen estado que tienen capacidad restante. Si todas las VMs ya están al máximo de su capacidad, se supera la utilización o la tasa de destino.
Cuando asocias un auto escalador a un backend de grupo de instancias de un balanceador de carga HTTP(S), el auto escalador escala el grupo de instancias gestionado para mantener una fracción de la capacidad de servicio del balanceo de carga.
Por ejemplo, supongamos que la capacidad de servicio de balanceo de carga de un grupo de instancias gestionado es de 100 RPS por instancia. Si creas un escalador automático con la política de balanceo de carga HTTP(S) y lo configuras para que mantenga un nivel de uso objetivo del 0,8 (80 %), el escalador automático añade o elimina instancias del grupo de instancias gestionado para mantener el 80% de la capacidad de servicio, es decir, 80 RPS por instancia.
En el siguiente diagrama se muestra cómo interactúa el escalador automático con un grupo de instancias gestionado y un servicio de backend:
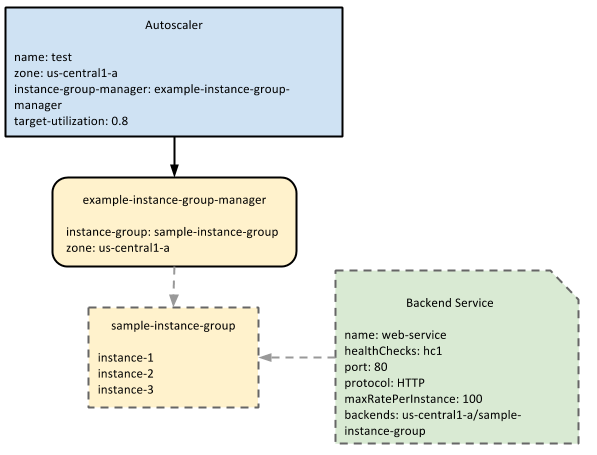
La herramienta de adaptación dinámica monitoriza la capacidad de servicio del grupo de instancias gestionado, que se define en el servicio de backend, y escala en función del uso objetivo. En este ejemplo, la capacidad de servicio se mide en el valor maxRatePerInstance.Configuraciones de balanceo de carga aplicables
Puede definir una de las tres opciones de capacidad de servicio del balanceo de carga. Cuando creas el backend por primera vez, puedes elegir entre la utilización máxima del backend, el número máximo de solicitudes por segundo por instancia o el número máximo de solicitudes por segundo de todo el grupo. El autoescalado solo funciona con la utilización máxima del backend y el número máximo de solicitudes por segundo o por instancia, ya que el valor de estos ajustes se puede controlar añadiendo o quitando instancias. Por ejemplo, si configura un backend para que gestione 10 solicitudes por segundo por instancia y el escalador automático está configurado para mantener el 80% de esa tasa, el escalador automático puede añadir o quitar instancias cuando cambien las solicitudes por segundo por instancia.
El autoescalado no funciona con el número máximo de solicitudes por grupo porque este ajuste es independiente del número de instancias del grupo de instancias. El balanceador de carga envía continuamente el número máximo de solicitudes por grupo al grupo de instancias, independientemente del número de instancias que haya en el grupo.
Por ejemplo, si configuras el backend para que gestione un máximo de 100 solicitudes por grupo por segundo, el balanceador de carga enviará 100 solicitudes por segundo al grupo, independientemente de si el grupo tiene dos instancias o 100. Como este valor no se puede ajustar, el autoescalado no funciona con una configuración de balanceo de carga que utilice el número máximo de solicitudes por segundo por grupo.
Habilitar el autoescalado en función de la capacidad de servicio del balanceo de carga
Consola
- Ve a la página Grupos de instancias de la consola de Google Cloud Google Cloud.
- Si tienes un grupo de instancias, selecciónalo y haz clic en Editar. Si no tienes ningún grupo de instancias, haz clic en Crear grupo de instancias.
- Haga clic en Tamaño del grupo y escalado automático para desplegar la sección.
- En la lista Modo de autoescalado, asegúrate de que esté seleccionada la opción Activado: añadir y quitar instancias del grupo.
- Especifica el número mínimo y máximo de instancias que quieres que el escalador automático cree en este grupo.
- En la sección Señales de escalado automático, haga clic en Añadir una señal.
- En Tipo de señal, selecciona Uso del balanceo de carga HTTP.
Introduce el valor de Uso del balanceo de carga HTTP objetivo en porcentaje. Por ejemplo, si el uso del balanceo de carga HTTP es del 60 %, introduce
60.Puedes usar el campo Periodo de inicialización para definir el periodo de inicialización, que indica al autoescalador cuánto tarda tu aplicación en inicializarse. Si especificas un periodo de inicialización preciso, la herramienta de adaptación dinámica tomará mejores decisiones. Por ejemplo, al escalar horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que esas VMs aún no representen el uso normal de tu aplicación. El periodo de inicialización predeterminado es de 60 segundos.
Guarda los cambios.
gcloud
Para habilitar un autoescalador que se escale en función de la capacidad de servicio, usa el subcomando
set-autoscaling. Por ejemplo, el siguiente comando crea un escalador automático que escala el grupo de instancias gestionadas de destino para mantener el 60% de la capacidad de servicio. Junto con el parámetro--target-load-balancing-utilization, también se necesita el parámetro--max-num-replicasal crear un escalador automático:gcloud compute instance-groups managed set-autoscaling example-managed-instance-group \ --max-num-replicas 20 \ --target-load-balancing-utilization 0.6 \ --cool-down-period 90Puedes usar la marca
--cool-down-periodpara definir el periodo de inicialización, que indica al autoescalador cuánto tarda tu aplicación en inicializarse. Si especificas un periodo de inicialización preciso, la herramienta de adaptación dinámica tomará mejores decisiones. Por ejemplo, al escalar horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que esas VMs aún no representen el uso normal de tu aplicación. El periodo de inicialización predeterminado es de 60 segundos.Para comprobar que la herramienta de escalado automático se ha creado correctamente, usa el subcomando
instance-groups managed describe:gcloud compute instance-groups managed describe example-managed-instance-group
Para ver una lista de los comandos y las marcas de
gclouddisponibles, consulta la referencia degcloud.REST
Para crear un escalador automático, usa el método
autoscalers.insertpara un MIG zonal o el métodoregionAutoscalers.insertpara un MIG regional.En el siguiente ejemplo se crea una herramienta de escalado automático para un MIG zonal:
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/autoscalers/
El cuerpo de la solicitud debe contener los campos
name,targetyautoscalingPolicy.autoscalingPolicydebe definirloadBalancingUtilization.Puedes usar el campo
coolDownPeriodSecpara definir el periodo de inicialización, que indica al autoescalador cuánto tarda tu aplicación en inicializarse. Si especificas un periodo de inicialización preciso, la herramienta de adaptación dinámica tomará mejores decisiones. Por ejemplo, al escalar horizontalmente, el escalador automático ignora los datos de las VMs que aún se están inicializando, ya que es posible que esas VMs aún no representen el uso normal de tu aplicación. El periodo de inicialización predeterminado es de 60 segundos.{ "name": "example-autoscaler", "target": "zones/us-central1-f/instanceGroupManagers/example-managed-instance-group", "autoscalingPolicy": { "maxNumReplicas": 20, "loadBalancingUtilization": { "utilizationTarget": 0.8 }, "coolDownPeriodSec": 90 } }Para obtener más información sobre cómo habilitar el autoescalado en función de la capacidad de servicio del balanceo de carga, consulta el tutorial Autoescalar a nivel mundial un servicio web en Compute Engine.
Siguientes pasos
- Consulta información sobre cómo gestionar escaladores automáticos.
- Consulta cómo toman decisiones las herramientas de ajuste automático de escala.
- Consulta cómo usar varias señales de autoescalado para escalar tu grupo.
A menos que se indique lo contrario, el contenido de esta página está sujeto a la licencia Reconocimiento 4.0 de Creative Commons y las muestras de código están sujetas a la licencia Apache 2.0. Para obtener más información, consulta las políticas del sitio web de Google Developers. Java es una marca registrada de Oracle o sus afiliados.
Última actualización: 2025-10-19 (UTC).
-