Incorporado a jobs de consulta, o BigQuery inclui informações de cronologia e plano de consulta diagnóstica. Isso é semelhante aos dados fornecidos por instruções como EXPLAIN em outros sistemas analíticos e de bancos de dados. Essas informações podem ser recuperadas a partir das respostas de API de métodos como jobs.get.
Para consultas de longa duração, o BigQuery atualizará essas estatísticas periodicamente. Essas atualizações ocorrem independentemente da taxa em que o status do job é pesquisado, mas não costumam ser com mais frequência do que a cada 30 segundos. Além disso, os jobs de consulta que não usam recursos de execução, como solicitações de simulação ou resultados que podem ser exibidos a partir de resultados armazenados em cache, não incluirão as informações de diagnóstico adicionais, embora outras estatísticas possam ser presente.
Experiência
Quando o BigQuery executa um job de consulta, ele converte a instrução SQL declarativa em um gráfico de execução, desmembrado em uma série de estágios de consulta que, por sua vez, são compostos por conjuntos mais granulares de etapas de execução. O BigQuery usa uma arquitetura paralela altamente distribuída para executar essas consultas. Os estágios modelam as unidades de trabalho que muitos workers em potencial podem executar paralelamente. Os estágios se comunicam entre si usando uma arquitetura de embaralhamento distribuída rapidamente.
No plano de consulta, os termos unidades de trabalho e workers são usados para transmitir
informações sobre paralelismo, especificamente. Em outros locais do
BigQuery, é possível encontrar o termo slot,
que é uma representação abstrata de várias facetas da execução de consulta, incluindo
recursos de computação, memória e E/S. As estatísticas de jobs de nível superior fornecem a estimativa de custo da consulta individual usando a estimativa totalSlotMs da consulta que utiliza essa contabilidade abstrata.
Outra propriedade importante da arquitetura de execução de consulta é o fato de ela ser dinâmica, ou seja, o plano pode ser modificado enquanto uma consulta está em execução. Os estágios que são introduzidos durante a execução de uma consulta costumam ser usados para melhorar a distribuição de dados em todos os workers da consulta. Nos planos em que isso ocorre, eles normalmente são rotulados como estágios de repartição.
Além do plano de consulta, os jobs de consulta também exibem um cronograma de execução, que fornece uma contabilidade das unidades de trabalho concluídas, pendentes e ativas nos workers de consulta. Como uma consulta pode ter vários cenários com workers ativos simultaneamente, o cronograma se destina a mostrar o progresso geral dela.
Como visualizar informações com o console do Google Cloud
No console do Google Cloud, é possível ver detalhes do plano de consulta de uma consulta concluída clicando no botão Detalhes da execução (perto do botão de Resultados.

Informações do plano de consulta
Na resposta da API, os planos de consulta são representados como uma lista de estágios de consulta. Cada item na lista mostra estatísticas da visão geral por estágio, informações detalhadas da etapa e classificações de duração dos estágios. Nem todos os detalhes são renderizados no console do Google Cloud, mas todos podem estar presentes nas respostas da API.
Visão geral do cenário
Os campos de visão geral de cada estágio podem incluir o seguinte:
| Campo da API | Descrição |
|---|---|
id |
Código numérico exclusivo do cenário. |
name |
Nome simples de resumo do cenário. O steps dentro do estágio fornece detalhes adicionais sobre as etapas de execução. |
status |
Status de execução do cenário. Os estados possíveis incluem PENDING, RUNNING, COMPLETE, FAILED e CANCELLED. |
inputStages |
Uma lista dos códigos que formam o gráfico de dependência do cenário. Por exemplo, um cenário JOIN geralmente precisa de dois cenários dependentes que preparam os dados nos lados esquerdo e direito do relacionamento JOIN. |
startMs |
Carimbo de data/hora, em milissegundos da época, que representa quando o primeiro trabalhador no cenário iniciou a execução. |
endMs |
Carimbo de data/hora, em milissegundos de época, que representa quando o último trabalhador concluiu a execução. |
steps |
Lista mais detalhada de etapas de execução no cenário. Consulte a próxima seção para mais informações. |
recordsRead |
Tamanho de entrada do cenário como número de registros, em todos os trabalhadores do cenário. |
recordsWritten |
Tamanho de saída do cenário como número de registros, em todos os trabalhadores do cenário. |
parallelInputs |
Número de unidades de trabalho carregáveis em paralelo do cenário. Dependendo do estágio e da consulta, isso pode representar o número de segmentos colunares em uma tabela ou o número de partições em um embaralhamento intermediário. |
completedParallelInputs |
Número de unidades de trabalho dentro do cenário que foram concluídas. Para algumas consultas, nem todas as entradas dentro de um cenário precisam ser concluídas para que o cenário seja concluído. |
shuffleOutputBytes |
Representa o total de bytes gravados em todos os trabalhadores em um cenário de consulta. |
shuffleOutputBytesSpilled |
Consultas que transmitem dados significativos entre cenários podem precisar recorrer à transmissão baseada em disco. A estatística de bytes espalhados comunica o volume de dados espalhados no disco. Depende de um algoritmo de otimização para que não seja determinístico para qualquer consulta. |
Informações da etapa por cenário
As etapas representam as operações mais granulares que cada trabalhador em um cenário precisa executar, apresentadas como uma lista ordenada de operações. As etapas são categorizadas, e algumas operações fornecem informações mais detalhadas. As categorias de operação presentes no plano de consulta incluem os seguintes itens:
| Etapa | Descrição |
|---|---|
| LER | Uma leitura de uma ou mais colunas de uma tabela de entrada ou de um embaralhamento intermediário. Somente as primeiras dezesseis colunas lidas serão retornadas nos detalhes da etapa. |
| WRITE | Uma gravação de uma ou mais colunas em uma tabela de saída ou em um resultado intermediário. Para saídas particionadas HASH de um cenário, isso também inclui as colunas usadas como a chave de partição. |
| COMPUTAÇÃO | Operações como avaliação de expressão e funções SQL. |
| FILTRAR | Operador que implementa as cláusulas WHERE, OMIT IF e HAVING. |
| SORT | Classifica ou ordena por operação. Inclui as chaves de coluna e a direção de classificação. |
| AGGREGATE | Uma operação de agregação, como GROUP BY ou COUNT. |
| LIMIT | Operador que implementa a cláusula LIMIT. |
| JOIN | Uma operação JOIN, que inclui o tipo de junção e as colunas usadas. |
| ANALYTIC_FUNCTION | Uma invocação de uma função de janela (também conhecida como "função analítica"). |
| USER_DEFINED_FUNCTION | Uma chamada a uma função definida pelo usuário. |
Classificação de cronologia por estágio
Os estágios de consulta também fornecem classificações de duração dos estágios, tanto em termos absolutos quanto relativos. Como cada estágio de execução representa o trabalho realizado por um ou mais workers independentes, as informações são fornecidas no tempo médio e no pior cenário. Esses tempos representam o desempenho médio de todos os workers em um estágio, assim como o desempenho mais lento de cauda longa dos workers em uma determinada classificação. Além disso, os tempos médio e máximo são desmembrados nas representações absoluta e relativa. Para estatísticas com base em proporção, os dados são fornecidos como uma fração do maior tempo gasto por qualquer worker em qualquer segmento.
O console do Google Cloud apresenta a cronologia dos cenários usando as representações de cronologia relativa.
As informações de cronologia de cenário são relatadas da seguinte maneira:
| Cronologia relativa | Cronologia absoluta | Numerador de proporção |
|---|---|---|
waitRatioAvg |
waitMsAvg |
Tempo que o trabalho médio passou aguardando ser programado. |
waitRatioMax |
waitMsMax |
Tempo que o trabalho mais lento passou aguardando ser programado. |
readRatioAvg |
readMsAvg |
Tempo que o trabalho médio passou lendo dados de entrada. |
readRatioMax |
readMsMax |
Tempo que o trabalho mais lento passou lendo dados de entrada. |
computeRatioAvg |
computeMsAvg |
Tempo que o worker médio passou ligado à CPU. |
computeRatioMax |
computeMsMax |
Tempo que o worker mais lento passou ligado à CPU. |
writeRatioAvg |
writeMsAvg |
Tempo que o trabalho médio passou gravando dados de saída. |
writeRatioMax |
writeMsMax |
Tempo que o worker mais lento passou gravando dados de saída. |
Explicação para consultas federadas
As consultas federadas permitem enviar uma instrução de consulta a uma fonte de dados externa usando a função EXTERNAL_QUERY.
As consultas federadas estão sujeitas à técnica de otimização conhecida como pushdowns SQL, e o plano de consulta mostra as operações enviadas para a fonte de dados externa, se houver.
Por exemplo, se você executar a seguinte consulta:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
O plano de consulta mostrará as seguintes etapas da fase:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Nesse plano, table_for_external_query_$_0(...) representa a
função EXTERNAL_QUERY. Entre os parênteses, é possível ver a consulta que a
fonte de dados externa executa. Com base nisso, é possível notar que:
- Uma fonte de dados externa retorna apenas três colunas selecionadas.
- Uma fonte de dados externa retorna apenas as linhas em que
country_codeé'ee'ou'hu'. - O operador
LIKEnão é pushdown e é avaliado pelo BigQuery.
Para fins de comparação, se não houver push-downs, o plano de consulta mostrará as seguintes etapas do estágio:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
Desta vez, uma fonte de dados externa retorna todas as colunas e linhas da tabela company, e o BigQuery realiza a filtragem.
Metadados do cronograma
O cronograma da consulta informa a evolução em momentos específicos no tempo, fornecendo visualizações instantâneas do progresso geral da consulta. O cronograma é representado por uma série de amostras que informam os seguintes detalhes:
| Campo | Descrição |
|---|---|
elapsedMs |
Milissegundos decorridos desde o início da execução da consulta. |
totalSlotMs |
Uma representação cumulativa dos milissegundos de slot usados pela consulta. |
pendingUnits |
Total de unidades de trabalho programadas que aguardam execução. |
activeUnits |
Total de unidades de trabalho ativas sendo processadas por trabalhadores. |
completedUnits |
Total de unidades de trabalho que foram concluídas durante a execução dessa consulta. |
Um exemplo de consulta
A consulta a seguir conta o número de linhas no conjunto de dados público de Shakespeare e tem uma segunda contagem condicional que restringe os resultados às linhas que fazem referência ao termo "Hamlet":
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
Clique em Detalhes da execução para ver o plano de consulta:
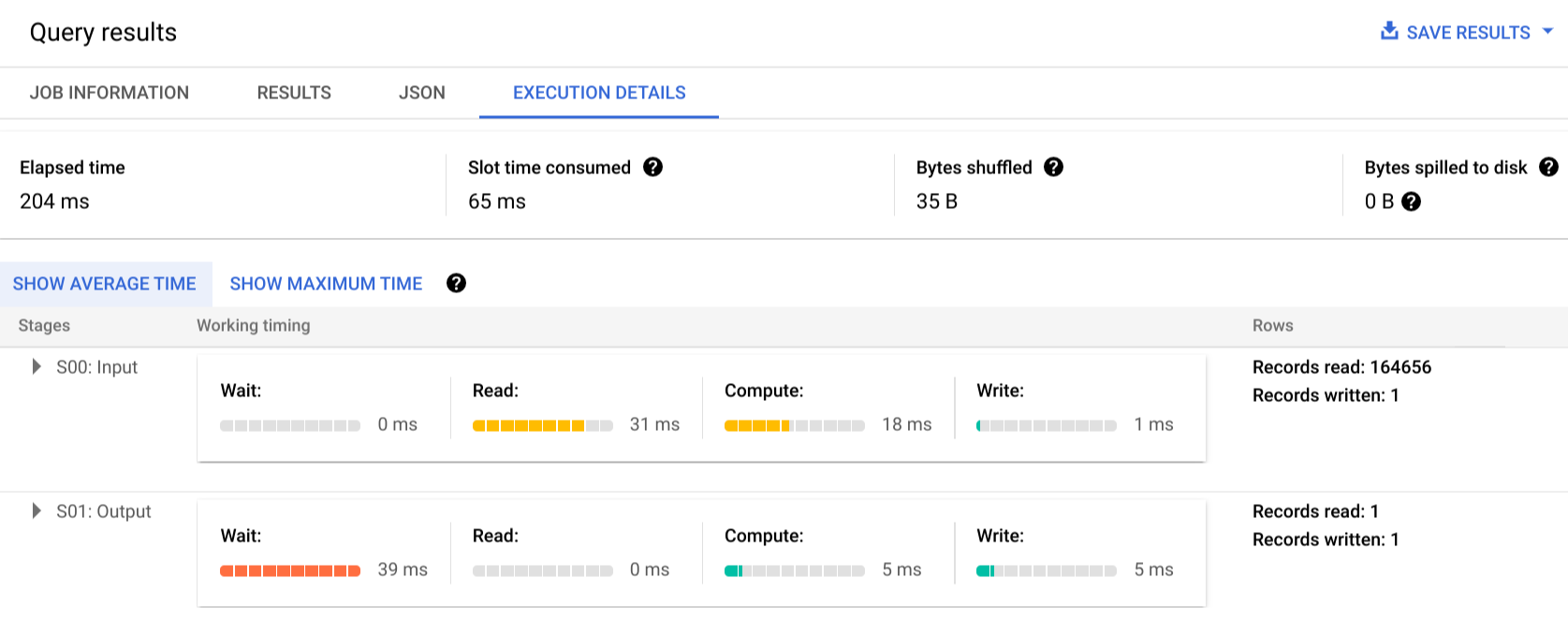
Os indicadores de cor mostram os tempos relativos de todas as etapas em todos os estágios.
Se quiser saber mais sobre as etapas dos estágios de execução, clique em para expandir os detalhes de cada um:

Nesse exemplo, o maior tempo em qualquer segmento foi aquele em que o único worker no Estágio 01 passou aguardando a conclusão do Estágio 00. Isso ocorre porque o Estágio 01 era dependente da entrada do Estágio 00 e não podia ser iniciado até que o primeiro estágio gravasse a saída no embaralhamento intermediário.
Relatórios de erros
É possível que os jobs de consulta falhem no meio da execução. Como as informações do plano são atualizadas periodicamente, é possível observar, no gráfico de execução, onde ocorreu a falha. No console do Google Cloud, os estágios bem-sucedidos ou com falha têm uma marca de seleção ou um ponto de exclamação ao lado do nome.
Para mais informações sobre como interpretar e corrigir erros, consulte o Guia de solução de problemas.
Representação de amostra de API
As informações do plano de consulta são incorporadas nos dados de resposta do job. Para recuperá-las, chame jobs.get. Por exemplo, o trecho a seguir de uma resposta JSON de um job que retorna a consulta de amostra de Hamlet mostra o plano de consulta e as informações do cronograma.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
Como usar informações de execução
Os planos de consulta do BigQuery fornecem informações sobre como o serviço executa consultas, mas a natureza gerenciada do serviço limita a possibilidade de alguns detalhes serem diretamente acionáveis. Muitas otimizações ocorrem automaticamente com o uso do serviço, que pode ser diferente de outros ambientes em que o ajuste, provisionamento e monitoramento exigem uma equipe dedicada e capacitada.
Para técnicas específicas capazes de melhorar a execução e o desempenho de consultas, confira a documentação de práticas recomendadas. As estatísticas do plano de consulta e do cronograma podem ajudar você a entender se determinados estágios dominam a utilização de recursos. Por exemplo, um estágio JOIN que gera muito mais linhas de saída do que de entrada pode indicar uma oportunidade para fazer a filtragem mais cedo na consulta.
Além disso, as informações de cronograma podem ajudar a identificar se determinada consulta é lenta isoladamente ou devido aos efeitos de outras consultas que disputam os mesmos recursos. Se o número de unidades ativas permanece limitado durante todo o ciclo de vida da consulta, mas a quantidade de unidades de trabalho consultadas permanece alta, isso pode indicar que, nesses casos, reduzir o número de consultas simultâneas melhora significativamente o tempo de execução geral de determinadas consultas.