BigQuery のクエリジョブには、診断で使用できるクエリプランとタイミング情報が埋め込まれます。これは、他のデータベースや分析システムの EXPLAIN ステートメントなどで提供される情報に似ています。この情報は、jobs.get などのメソッドで API レスポンスから取得できます。
長期実行されるクエリの場合、BigQuery はこの統計情報を定期的に更新します。この更新は、ジョブ ステータスのポーリング間隔とは関係なく実行されますが、通常、更新間隔が 30 秒よりも短くなることはありません。また、実行リソースを使用しないクエリジョブ(ドライラン リクエストや、キャッシュに保存された結果が提供される場合など)の場合、追加の診断情報はありませんが、他の統計情報が提供される可能性があります。
背景
BigQuery がクエリジョブを実行すると、宣言型の SQL ステートメントを実行グラフに変換し、一連のクエリステージに分割します。クエリステージは、より細かい実行ステップで構成されます。BigQuery は、高度な分散並列アーキテクチャを利用して、このようなクエリを実行します。ステージは、多くのワーカーが同時に実行できる作業単位をモデル化したものです。ステージは、高速分散シャッフル アーキテクチャを使用して相互に通信します。
クエリプランでは、特に並列処理に関する情報を伝えるために「作業単位」と「ワーカー」という用語を使用します。BigQuery では、コンピューティング、メモリ、I/O リソースなど、クエリの実行に必要な複数のファセットを抽象的に表すために「スロット」という用語を使用する場合があります。ジョブ統計の概要では、この抽象的な単位に基づき、個々のクエリの totalSlotMs を表示しています。
クエリ実行のアーキテクチャでもう 1 つの重要な特性は動的である点です。つまり、クエリの実行中にクエリプランが変更される可能性があります。クエリの実行中に追加されるステージは、主にクエリワーカー全体にわたるデータ分散を向上させるために使用されます。通常、このようなクエリプランでは、ステージに「再パーティショニング ステージ」というラベルが付けられます。
クエリプランに加えて、クエリジョブでも実行タイムラインを公開します。これにより、クエリワーカー内で完了した作業単位、保留中の作業単位、アクティブな作業単位の数を確認できます。1 つのクエリの複数のステージでアクティブなワーカーが同時に実行している場合があるため、タイムラインはクエリ全体の進行状況を把握する際に有用です。
Google Cloud コンソールで情報を表示する
Google Cloud コンソールで、[実行の詳細] ボタン([結果] ボタンの近く)をクリックして、完了したクエリのクエリプランの詳細を確認できます。
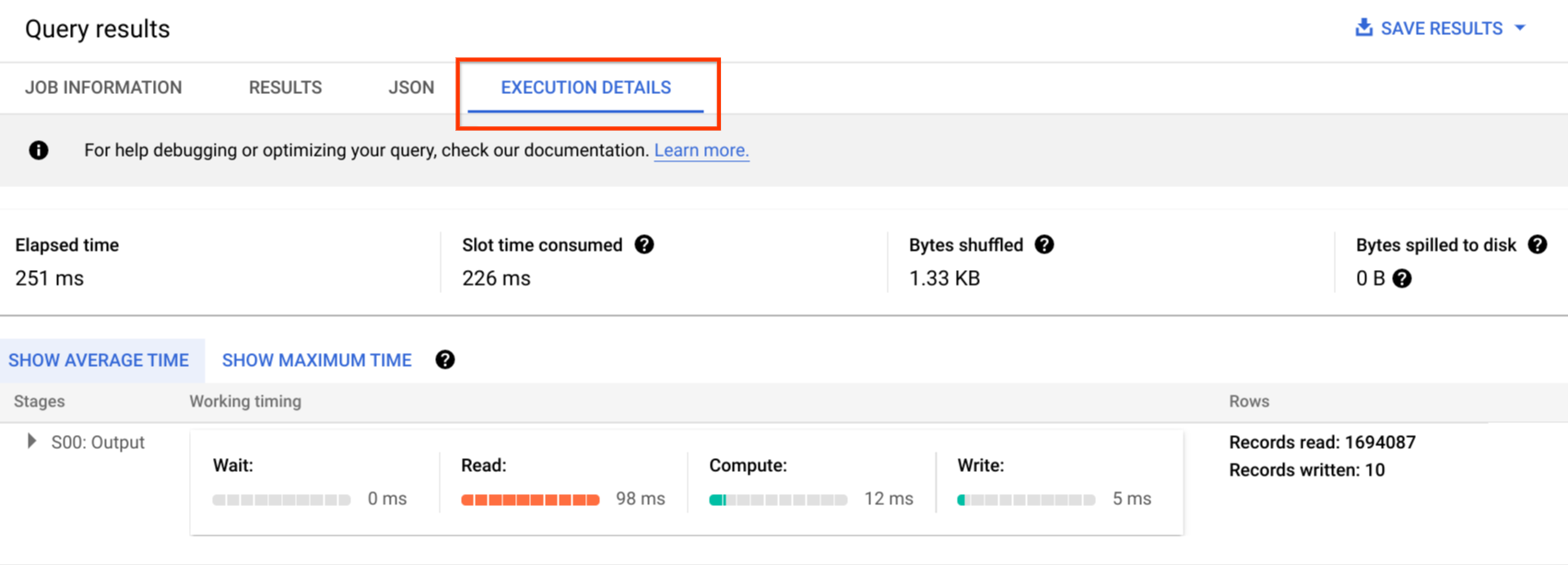
クエリプランの情報
API レスポンス内では、クエリプランはクエリステージのリストとして表されます。リスト内の各アイテムはステージごとの統計情報の概要、詳細なステップ情報、ステージ タイミングの分類を表します。 Google Cloud コンソールに表示されない情報もありますが、それらの情報はすべて API レスポンスに含まれています。
ステージの概要
各ステージには、次のような概要フィールドがあります。
| API フィールド | 説明 |
|---|---|
id |
ステージの一意の数値 ID。 |
name |
ステージの簡単な概要名。ステージ内の steps に、実行ステップの詳細が含まれます。 |
status |
ステージの実行ステータス。PENDING、RUNNING、COMPLETE、FAILED、CANCELLED のいずれかになります。 |
inputStages |
ステージの依存関係グラフを形成する ID のリスト。たとえば、JOIN ステージの場合、JOIN 関係の左右のデータを準備するために、2 つの依存ステージが必要になります。 |
startMs |
エポックミリ秒単位のタイムスタンプ。ステージ内で最初のワーカーが開始した時間を表します。 |
endMs |
最後のワーカーが実行を完了した時間を表すタイムスタンプ(エポックミリ秒単位)。 |
steps |
ステージ内の実行ステップの詳細なリスト。詳細については、次のセクションをご覧ください。 |
recordsRead |
ステージ ワーカー全体でのステージの入力サイズ(レコード数)。 |
recordsWritten |
ステージ ワーカー全体でのステージの出力サイズ(レコード数)。 |
parallelInputs |
ステージで同時に読み込み可能な作業単位の数。ステージとクエリに応じて、テーブルの列セグメントの数や、中間シャッフル内のパーティションの数を表す場合があります。 |
completedParallelInputs |
ステージ内で完了した作業単位の数。クエリによっては、ステージ内のすべての入力が完了していなくても、ステージが完了する場合があります。 |
shuffleOutputBytes |
クエリステージ内のワーカー全体で発生した書き込みの合計バイト数を表します。 |
shuffleOutputBytesSpilled |
ステージ間で重要なデータを送信するクエリでは、ディスクベースの送信へのフォールバックが必要になる場合があります。オーバーフローされたバイトの統計情報は、ディスクにオーバーフローしたデータの量を表します。最適化アルゴリズムに依存するため、任意のクエリに対して決定論的に確定されるものではありません。 |
ステージごとのタイミング情報
クエリステージは、ステージのタイミング分類を、相対的形式と絶対的形式の両方で提供します。実行の各ステージは、1 つ以上の独立したワーカーによって実行された作業を表すため、情報は平均時間と最長時間の両方で提供されます。これは、ステージ内のすべてのワーカーの平均的なパフォーマンスと、長時間ワーカーのパフォーマンスを表します。平均時間と最長時間は、絶対的な形式と相対的な形式で表現されます。比率ベースの統計の場合、セグメントのワーカーによって費やされた最長時間との比率でデータが提供されます。
Google Cloud コンソールでは、相対的な表現でステージのタイミングが表示されます。
ステージのタイミング情報は次のように表示されます。
| 相対的なタイミング | 絶対的なタイミング | 割合の分子 |
|---|---|---|
waitRatioAvg |
waitMsAvg |
平均的なワーカーがスケジュール完了の待機に費やした時間。 |
waitRatioMax |
waitMsMax |
最も遅いワーカーがスケジュール完了の待機に費やした時間。 |
readRatioAvg |
readMsAvg |
平均的なワーカーが入力データの読み取りに費やした時間。 |
readRatioMax |
readMsMax |
最も遅いワーカーが入力データの読み取りに費やした時間。 |
computeRatioAvg |
computeMsAvg |
平均的なワーカーが CPU のバインドに費やした時間。 |
computeRatioMax |
computeMsMax |
最も遅いワーカーが CPU のバインドに費やした時間。 |
writeRatioAvg |
writeMsAvg |
平均的なワーカーが出力データの書き込みに費やした時間。 |
writeRatioMax |
writeMsMax |
最も遅いワーカーが出力データの書き込みに費やした時間。 |
ステップの概要
ステップには、ステージ内の各ワーカーが実行するオペレーションが含まれ、オペレーションの順序付きリストとして表されます。各ステップ オペレーションにはカテゴリがあり、一部のオペレーションでは詳細情報が提供されます。クエリプランのオペレーションには、次のようなカテゴリがあります。
| ステップのカテゴリ | 説明 |
|---|---|
READ |
入力テーブルまたは中間シャッフルからの 1 つ以上の列の読み取り。読み取られた最初の 16 列のみがステップの詳細で返されます。 |
WRITE |
出力テーブルまたは中間シャッフルへの 1 つ以上の列の書き込み。ステージの HASH パーティション分割された出力の場合は、パーティション キーとして使用される列も含まれます。 |
COMPUTE |
式の評価と SQL 関数。 |
FILTER |
WHERE、OMIT IF、HAVING 句で使用されます。 |
SORT |
列キーと並べ替え順を含む ORDER BY オペレーション。 |
AGGREGATE |
GROUP BY や COUNT などの句の集計を実装します。 |
LIMIT |
LIMIT 句を実装します。 |
JOIN |
JOIN などの句の結合を実装します。結合タイプおよび場合によっては結合条件も含まれます。 |
ANALYTIC_FUNCTION |
ウィンドウ関数(「分析関数」とも呼ばれます)の呼び出し。 |
USER_DEFINED_FUNCTION |
ユーザー定義関数の呼び出し。 |
ステップの詳細を理解する
BigQuery には、ステージ内の各ステップで行われたオペレーションを説明する [ステップの詳細] があります。クエリのパフォーマンスの問題の原因を特定するには、ステージの各ステップを理解する必要があります。
ステージのステップの詳細を確認する手順は次のとおりです。
[クエリ結果] ペインで、[実行グラフ] をクリックします。
![[実行グラフ] タブ。](https://cloud.google.com/static/bigquery/images/execution-graph-tab.png?authuser=00&hl=ja)
目的のステージをクリックして、ステージ情報を含むパネルを開きます。
ステージ情報を含むパネルで、[ステップの詳細] セクションに移動します。
![ステージの詳細を含む [実行グラフ]。](https://cloud.google.com/static/bigquery/images/execution-graph-stage-details.png?authuser=00&hl=ja)
各ステップは、そのステップで行われたオペレーションを説明するサブステップで構成されます。サブステップでは、変数を使用してステップ間の関係を記述します。変数はドル記号で始まり、その後に一意の番号が続きます。
以下に、ステップ間で変数が共有されているステージのステップの詳細の例を示します。
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
この例のステップの詳細では次のオペレーションを行っています。
このステージでは、変数
$30と$31を使用して、テーブルlineitemから列l_orderkeyとl_quantityをそれぞれ読み取りました。このステージでは、変数
$30と$31を集計し、集計結果をそれぞれ変数$100と$70に保存しました。このステージでは、変数
$100と$70の結果をシャッフルに書き込みました。また、$100を使用してシャッフル内のステージの結果を並べ替えました。
クエリの実行グラフが複雑で、ステージのステップの詳細をすべて表示すると、クエリ情報を取得する際にペイロード サイズの問題が発生する場合、BigQuery はステップの詳細を切り捨てることがあります。
クエリテキストでステップを理解する
プレビュー版のサポートについては、bq-query-inspector-feedback@google.com までメールでお問い合わせください。
ステージのステップがクエリにどのように関連しているかを理解するのは、必ずしも簡単ではありません。[クエリテキスト] セクションには、一部のステップが元のクエリテキストとどのように関連しているかが表示されます。
[クエリテキスト] セクションでは、元のクエリテキストのさまざまな部分がハイライト表示され、ハイライト表示されている元のクエリテキストの直前のクエリテキストにマッピングされるステップが表示されます。元のクエリテキストのハイライト表示されている部分の直前のステップのみが、ハイライト表示されているクエリテキストに適用されます。
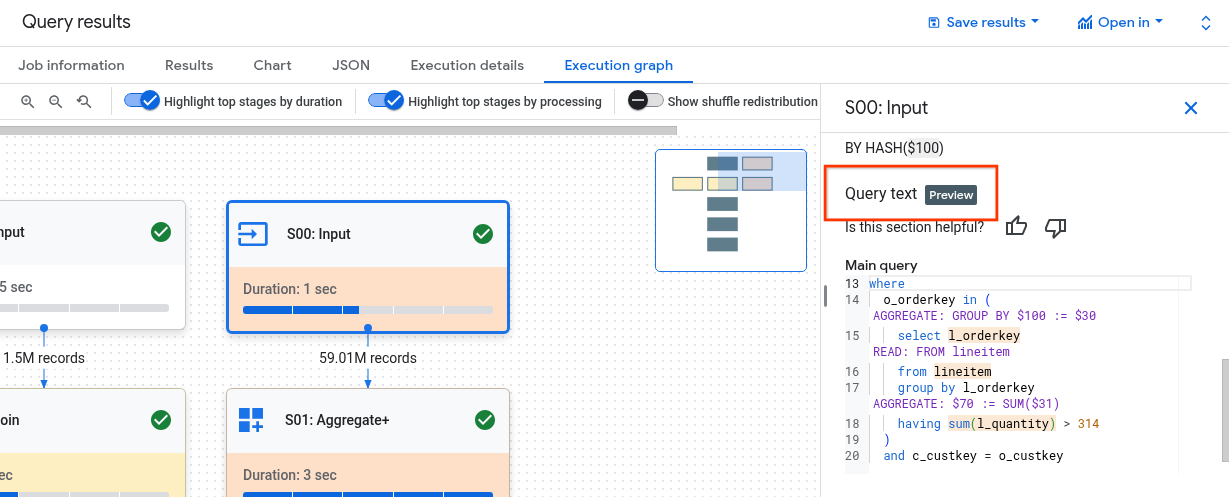
スクリーンショットの例は、次のマッピングを示しています。
ステップ
AGGREGATE: GROUP BY $100 := $30は、クエリテキストselect l_orderkeyにマッピングされます。ステップ
READ: FROM lineitemは、クエリテキストselect ... from lineitemにマッピングされます。ステップ
AGGREGATE: $70 := SUM($31)は、クエリテキストsum(l_quantity)にマッピングされます。
すべてのステップがクエリテキストにマッピングされるわけではありません。
クエリでビューが使用され、ステージのステップがビューのクエリテキストにマッピングされている場合、[クエリテキスト] セクションには、ビュー名とビューのクエリテキストがそのマッピングとともに表示されます。ただし、ビューが削除された場合、またはビューに対する bigquery.tables.get IAM 権限を失った場合、[クエリテキスト] セクションには、ビューのステージ ステップのマッピングは表示されません。
ステップを解釈して最適化する
以降のセクションでは、クエリプランのステップを解釈する方法と、クエリを最適化する方法について説明します。
READ ステップ
READ ステップは、ステージが処理のためにデータにアクセスしていることを意味します。データは、クエリで参照されるテーブルから直接読み取ることも、シャッフル メモリから読み取ることもできます。前のステージのデータが読み取られると、BigQuery はシャッフル メモリからデータを読み取ります。スキャンされるデータの量は、オンデマンド スロットの使用時には費用に、予約の使用時にはパフォーマンスに影響します。
潜在的なパフォーマンスの問題
- パーティショニングされていないテーブルの大規模なスキャン: クエリがごく一部のデータのみを必要とする場合、テーブル スキャンは非効率的であることを示している可能性があります。この場合は、パーティショニングが有効な最適化戦略となる可能性があります。
- フィルタ比率が小さい大規模テーブルのスキャン: スキャンされたデータがフィルタによって効果的に削減されていないことを示しています。フィルタ条件を変更することを検討してください。
- シャッフル バイトのディスクへのオーバーフロー: クラスタ内で類似データを維持できるクラスタリングなどの最適化手法を使用し、データが効率的に保存されていないことを示します。
最適化
- ターゲットを絞ったフィルタリング:
WHERE句を戦略的に使用して、クエリのできるだけ早い段階で無関係なデータを除外します。これにより、クエリで処理する必要があるデータの量を削減できます。 - パーティショニングとクラスタリング: BigQuery は、テーブルのパーティショニングとクラスタリングを使用して、特定のデータ セグメントを効率的に見つけます。ユーザーの典型的なクエリパターンに基づいて、テーブルをパーティショニングおよびクラスタリングすることで、
READステップでスキャンされるデータを最小限に抑えます。 - 関連する列の選択:
SELECT *ステートメントの使用は避けてください。代わりに、特定の列を選択するか、SELECT * EXCEPTを使用して、不要なデータを読み取らないようにします。 - マテリアライズド ビュー: マテリアライズド ビューでは、よく使用される集計を事前に計算して保存できるため、これらのビューを使用するクエリの
READステップで、ベーステーブルを読み込む必要性を減らせる可能性があります。
COMPUTE ステップ
COMPUTE ステップで、BigQuery はデータに対して次のアクションを実行します。
- クエリの
SELECT、WHERE、HAVINGなどの句内の式を評価します。式には、計算、比較、論理演算などがあります。 - 組み込み SQL 関数とユーザー定義関数を実行します。
- クエリの条件に基づいてデータの行をフィルタします。
最適化
クエリプランでは、COMPUTE ステップのボトルネックを特定できます。計算量が多いステージや、処理される行数の多いステージを探してください。
COMPUTEステップとデータ量の関連付け: 計算量が非常に多く、大量のデータを処理しているステージは、最適化が適している可能性があります。- データの偏り: コンピューティングの最大値が平均値よりもはるかに大きい場合、これはステージが少数のデータスライスの処理に過度に時間を費やしていることを示しています。データの分散を調べ、データスキューがないか確認することを検討してください。
- データ型の検討: 列に適切なデータ型を使用します。たとえば、文字列の代わりに整数、日時、タイムスタンプを使用すると、パフォーマンスが向上する可能性があります。
WRITE ステップ
WRITE ステップは、中間データと最終出力に対して行われます。
- シャッフル メモリへの書き込み: マルチステージ クエリの
WRITEステップでは、処理済みデータを別のステージに送信し、さらなる処理を行うことがよくあります。これは、複数のソースのデータを結合または集計するシャッフル メモリによく見られます。このステージで書き込まれるデータは通常、最終的な出力ではなく中間結果です。 - 最終的な出力: クエリ結果は、宛先テーブルまたは一時テーブルのいずれかに書き込まれます。
ハッシュ パーティショニング
クエリプランのステージがハッシュ パーティショニングされた出力にデータを書き込む場合、BigQuery は出力に含まれる列と、パーティション キーとして選択された列を書き込みます。
最適化
WRITE ステップ自体は直接最適化できない場合がありますが、その役割を理解することで、早い段階で潜在的なボトルネックを特定できます。
- 書き込まれるデータの最小化: フィルタリングと集計によって前のステージを最適化し、このステップで書き込まれるデータの量を減らします。
パーティショニング: テーブル パーティショニングによって、書き込みパフォーマンスが大きく向上します。特定のパーティションに限定してデータを書き込むことで、BigQuery がより高速に書き込みを実行できるようになります。
DML ステートメントの
WHERE句にテーブル パーティション列に対する静的条件が含まれる場合、BigQuery は関連するテーブル パーティションのみを変更します。非正規化のトレードオフ: 非正規化を行うと、中間
WRITEステップの結果セットが小さくなることがあります。ただし、ストレージ使用量の増加やデータ整合性の問題など、デメリットもあります。
JOIN ステップ
JOIN ステップで、BigQuery は 2 つのデータソースのデータを結合します。結合には結合条件を含めることができます。結合はリソースを大量に消費します。BigQuery で大規模なデータを結合する場合、結合キーは独立してシャッフルされ、同じスロットに並べられるため、結合は各スロットでローカルに実行されます。
通常、JOIN ステップのクエリプランには次の詳細が表示されます。
- 結合パターン: 使用される結合のタイプを示します。各タイプは、結合されたテーブルの行のうち、いくつの行が結果セットに含まれるかを定義します。
- 結合列: データソース間で行を照合するために使用される列です。列の選択は、結合のパフォーマンスにおいて重要です。
結合パターン
- ブロードキャスト結合: 1 つのテーブル(通常小さいもの)が単一のワーカーノードまたはスロットのメモリに収まる場合、BigQuery は他のすべてのノードにブロードキャストし、結合を効率的に実行できます。ステップの詳細で
JOIN EACH WITH ALLを探してください。 - ハッシュ結合: テーブルが大きい場合や、ブロードキャスト結合が適さない場合は、ハッシュ結合を使用できる場合があります。BigQuery は、ハッシュ オペレーションとシャッフル オペレーションを使用して左右のテーブルをシャッフルし、合致するキーを同じスロットに配置してから、ローカルで結合を行います。ハッシュ結合は、データを移動する必要があるため費用のかかるオペレーションですが、ハッシュ間で行を効率的に合致させることができます。ステップの詳細で
JOIN EACH WITH EACHを探してください。 - 自己結合: テーブルが自身と結合される SQL アンチパターン。
- クロス結合: SQL アンチパターン。入力データよりも大きい出力データを生成するため、重大なパフォーマンスの問題を引き起こす可能性があります。
- スキュー結合: 1 つのテーブルにおける結合キーのデータ分散が非常に偏っているため、パフォーマンスの問題につながる可能性があります。クエリプランで最長計算時間が平均計算時間よりもはるかに大きいケースを探してください。詳細については、カーディナリティの高い結合とパーティション スキューをご覧ください。
デバッグ
- 大量のデータ: クエリプランの
JOINステップで処理されるデータ量が非常に多い場合は、結合条件と結合キーを確認します。フィルタリングするか、より選択的な結合キーを使用することを検討してください。 - データ分散の偏り: 結合キーのデータ分散を分析します。1 つのテーブルに大きな偏りがある場合、クエリの分割や事前フィルタリングなどの方法を検討してください。
- カーディナリティの高い結合: 左右の入力行数よりもはるかに多くの行を生成する結合は、クエリのパフォーマンスを大幅に低下させる可能性があります。非常に多くの行を生成する結合は避けてください。
- 順序付けが不適切なテーブル: クエリの要件に基づいて、適切な結合タイプ(
INNERやLEFTなど)を選択し、テーブルを大きい順に並べていることを確認してください。
最適化
- 選択的な結合キー: 結合キーには、可能であれば
STRINGではなくINT64を使用します。STRINGの比較は、文字列内の各文字を比較するため、INT64の比較よりも時間がかかります。整数の場合は 1 回の比較で済みます。 - 結合前のフィルタリング: 結合前に個々のテーブルに
WHERE句フィルタを適用します。これにより、結合オペレーションが行われるデータ量が削減されます。 - 結合列での関数の使用の回避: 結合列では、関数の呼び出しは行わないでください。代わりに、ELT SQL パイプラインを使用して、取り込み時または取り込み後にテーブルデータを標準化します。このアプローチでは、結合列を動的に変更する必要がないため、データの整合性を損なうことなく、より効率的な結合が可能になります。
- 自己結合の回避: 自己結合は、行依存の関係を計算するためによく使用されます。ただし、自己結合により出力行の数が 4 倍になり、パフォーマンスの問題が発生する可能性があります。自己結合ではなく、ウィンドウ(分析)関数の使用を検討してください。
- 大きなテーブルを最初に配置: SQL クエリ オプティマイザーを使用すれば、結合のどちら側にどのテーブルを配置するかが自動で判断されますが、結合後のテーブルは適切に並べ替えることをおすすめします。ベスト プラクティスは、最初に最大のテーブルを配置し、次に最小のテーブルを配置することです。その後は、サイズの大きい順にテーブルを配置します。
- 非正規化: 場合によっては、テーブルを戦略的に非正規化(重複データを追加)することで、結合を完全に排除できます。ただし、このアプローチにはストレージとデータの整合性のトレードオフが伴います。
- パーティショニングとクラスタリング: 結合キーに基づいてテーブルをパーティショニングし、同じロケーションにあるデータをクラスタリングすると、BigQuery が関連するデータ パーティションをターゲットにできるため、結合が大幅に高速化されます。
- スキュー結合の最適化: スキュー結合に関連するパフォーマンスの問題を回避するには、できるだけ早い段階でテーブルのデータを事前にフィルタリングするか、クエリを 2 つ以上のクエリに分割します。
AGGREGATE ステップ
AGGREGATE ステップでは、BigQuery がデータを集計してグループ化します。
デバッグ
- ステージの詳細: 集計の入力行数と出力行数、シャッフル サイズを確認し、集計ステップでどの程度のデータが削減されたか、データ シャッフルが行われたかどうかを判断します。
- シャッフル サイズ: シャッフル サイズが大きい場合、集計中にワーカーノード間で大量のデータが移動されたことを示している可能性があります。
- データ分散の確認: データがパーティション間で均等に分散されていることを確認します。データ分散に偏りがあると、集計ステップでワークロードに不均衡が生じる可能性があります。
- 集計の確認: 集計句を分析して、その必要性と効率性を確認します。
最適化
- クラスタリング:
GROUP BY、COUNT、その他の集計句で頻繁に使用される列に基づいてテーブルをクラスタリングします。 - パーティショニング: クエリパターンに合ったパーティショニング戦略を選択します。取り込み時間パーティション分割テーブルを使用して、集計中にスキャンされるデータ量を減らすことを検討してください。
- 早い段階での集計: 可能であれば、クエリ パイプラインの早い段階で集計を行います。これにより、集計中に処理する必要があるデータ量を減らすことができます。
- シャッフルの最適化: シャッフルがボトルネックの場合は、シャッフルを最小限に抑える方法を検討します。たとえば、テーブルを非正規化するか、クラスタリングを使用して関連データを同じ場所に配置します。
エッジケース
- DISTINCT 集計:
DISTINCT集計を使用するクエリは、特に大規模なデータセットで計算コストが高くなる可能性があります。近似結果を得るには、APPROX_COUNT_DISTINCTなどの代替手段を検討してください。 - 大量のグループ: クエリで大量のグループが生成されると、膨大な量のメモリが消費される可能性があります。このような場合は、グループの数を制限するか、別の集計方法を使用することを検討してください。
REPARTITION ステップ
REPARTITION と COALESCE はどちらも、BigQuery がクエリのシャッフルされたデータに直接適用する最適化手法です。
REPARTITION: このオペレーションは、ワーカーノード間のデータ分散を再調整することを目的としています。シャッフル後に、1 つのワーカーノードに過剰な量のデータが割り当てられた場合、REPARTITIONステップではデータをより均等に再分散し、単一のワーカーがボトルネックになることを防ぎます。これは、結合などの計算負荷の高いオペレーションで特に重要です。COALESCE: このステップは、シャッフル後にデータの小さなバケットが多数ある場合に実行されます。COALESCEステップでは、これらのバケットを大きなバケットに結合し、多数の小さなデータを管理することに伴うオーバーヘッドを削減します。これは、非常に小さな中間結果セットを処理する場合に特に便利です。
クエリプランに REPARTITION ステップまたは COALESCE ステップがあっても、クエリに問題があるとは限りません。多くの場合、BigQuery がパフォーマンスの向上のために、データ分散を事前に最適化していることを示しています。ただし、これらのオペレーションが繰り返し実行される場合は、データに根本的な偏りがあるか、クエリによって過度のデータ シャッフルが発生している可能性があります。
最適化
REPARTITION ステップの数を減らすには、次の方法を試してください。
- データ分散: テーブルのパーティショニングとクラスタリングが効果的に行われていることを確認します。データが適切に分散されていると、シャッフル後に大きな不均衡が生じる可能性が低くなります。
- クエリ構造: データスキューの原因となることが考えられる部分がないかどうかについて、クエリを分析します。たとえば、選択性の高いフィルタや結合があり、データの小さなサブセットが単一のワーカーで処理されていないかを確認します。
- 結合戦略: さまざまな結合戦略を試し、よりバランスの取れたデータ分散につながるかものがないか確認します。
COALESCE ステップの数を減らすには、次の方法を試してください。
- 集計戦略: クエリ パイプラインの早い段階で集計を行うことを検討してください。これにより、
COALESCEステップを発生させる可能性のある小さな中間結果セットの数を減らすことができます。 - データ量: 非常に小さなデータセットを扱っている場合、
COALESCEはそれほど懸念する必要はないかもしれません。
過度な最適化は避けるようにしてください。早計な最適化は、クエリをかえって複雑にし、大きなメリットが得られない可能性があります。
連携クエリの説明
連携クエリでは、EXTERNAL_QUERY 関数を使用してクエリ ステートメントを外部データソースに送信できます。連携クエリには、SQL プッシュダウンと呼ばれる最適化手法が適用されます。クエリプランには、外部データソースにプッシュダウンされたオペレーション(存在する場合)が表示されます。たとえば、次のクエリを実行するとします。
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
クエリプランには、次のステージのステップが表示されます。
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
このプランでは、table_for_external_query_$_0(...) は EXTERNAL_QUERY 関数を表します。かっこ内には、外部データソースが実行するクエリが示されます。これに基づき、次のことがわかります。
- 外部データソースは、選択された 3 つの列のみを返します。
- 外部データソースは、
country_codeが'ee'または'hu'の行のみを返します。 LIKE演算子はプッシュダウンされず、BigQuery によって評価されます。
比較として、プッシュダウンが行われない場合、クエリプランには次のステージのステップが表示されます。
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
この場合、外部データソースは company テーブルのすべての列とすべての行を返し、BigQuery によってフィルタが実行されます。
タイムライン メタデータ
クエリ タイムラインは、特定の時点での進捗状況を表し、クエリ全体の進捗状況を示すスナップショットとなります。タイムラインは一連のサンプルとして表され、以下の情報を提供します。
| 項目 | 説明 |
|---|---|
elapsedMs |
クエリを開始してからの経過時間(ミリ秒)。 |
totalSlotMs |
クエリで使用されるスロットの合計処理時間(ミリ秒)。 |
pendingUnits |
スケジュールされ、実行待ちの作業単位の合計数。 |
activeUnits |
ワーカーが処理しているアクティブな作業単位の合計数。 |
completedUnits |
このクエリの実行中に完了した作業単位の合計数。 |
クエリの例
次のクエリは、Shakespeare 一般公開データセット内の行数をカウントし、2 番目の条件付きカウントで「hamlet」を参照する行に結果を制限します。
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
[実行の詳細] をクリックして、クエリプランを表示します。

カラー インジケーターは、すべてのステージのすべてのステップの相対的なタイミングを表します。
実行ステージのステップの詳細を表示するには、 をクリックしてステージの詳細を開きます。
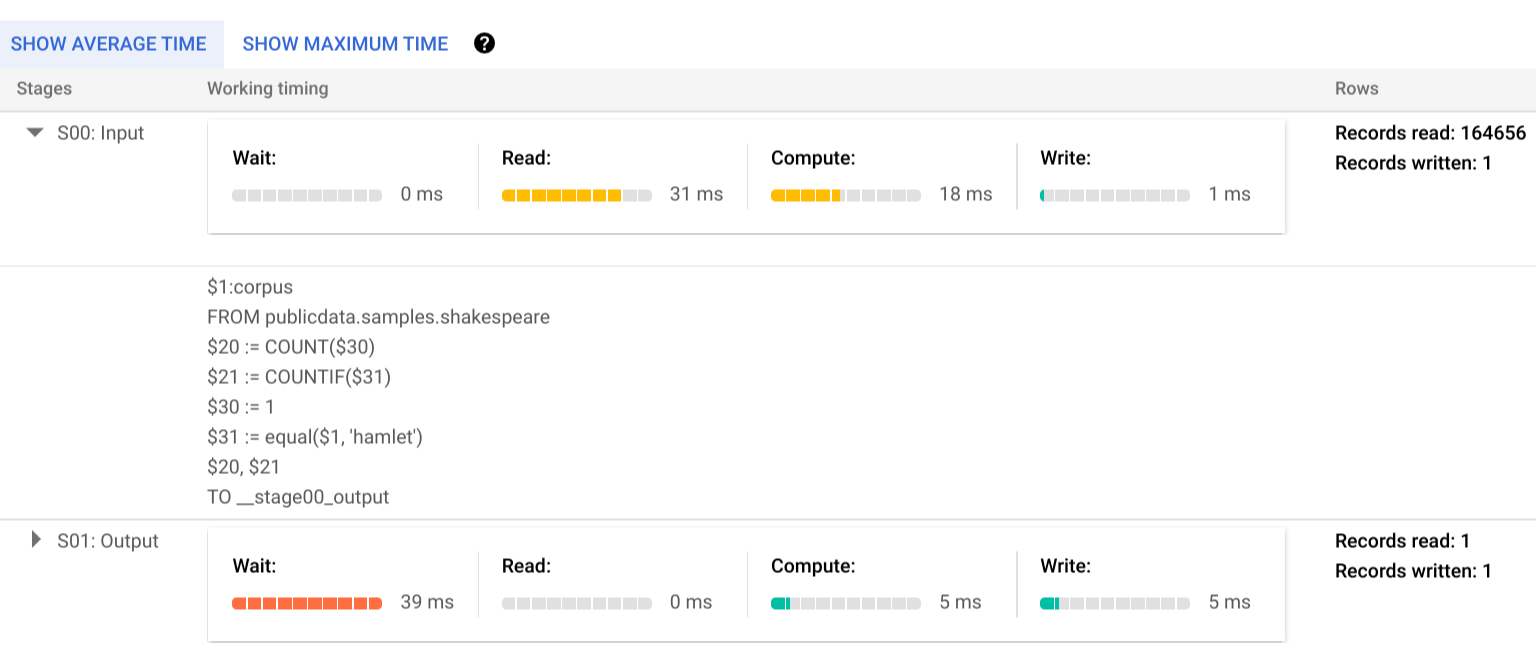
この例では、ステージ 01 の単一ワーカーがステージ 00 の完了を待っていた時間がセグメントの最長時間になっています。これは、ステージ 01 がステージ 00 の入力に依存しており、最初のステージがその出力を中間シャッフルに書き込むまで開始できなかったためです。
エラー報告
実行中にクエリジョブが失敗することもあります。プラン情報は定期的に更新されるため、実行グラフ内で失敗した場所を確認できます。 Google Cloud コンソールでは、ステージ名の横にチェックマークまたは感嘆符を付けて、ステージの成功と失敗を表しています。
エラーの解釈と解決方法の詳細については、トラブルシューティング ガイドをご覧ください。
API サンプルの表現
クエリプラン情報は、ジョブのレスポンス情報に埋め込まれており、jobs.get を呼び出すことで取得できます。たとえば、サンプルの hamlet クエリを返すジョブの JSON レスポンスの次の抜粋には、クエリプランとタイムライン情報の両方が表示されています。
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
実行情報を使用する
BigQuery のクエリプランでは、サービスによるクエリの実行方法に関する情報が提供されますが、マネージド サービスであるため、この情報をそのまま利用できるとは限りません。多くの最適化はサービスを使用して自動で行われます。これは、チューニング、プロビジョニング、モニタリングを行うために、知識豊富な専任のスタッフが必要となる環境とは異なる場合があります。
クエリの実行とパフォーマンスを改善する具体的な手法については、ベスト プラクティスのドキュメントをご覧ください。クエリプランとタイムラインの統計情報により、特定のステージがリソース使用量の大部分を占めているかどうかを把握できます。たとえば、JOIN ステージで入力行よりも出力行がはるかに多い場合は、クエリの早い段階でフィルタリングが必要かもしれません。
また、タイムライン情報を見ると、特定のクエリが単体でも遅いのか、同じリソースを利用する別のクエリとの競合で遅いのかを識別できます。クエリの全期間を通じてアクティブな作業単位の数が限定されていても、キューに入る作業単位の数が多い場合は、同時クエリの数を減らすことで、特定のクエリの全体的な実行時間を大幅に短縮できる可能性があります。