Pengantar Storage Write API BigQuery
Storage Write API BigQuery adalah API penyerapan data terpadu untuk BigQuery. API ini menggabungkan penyerapan streaming dan pemuatan batch ke dalam satu API berperforma tinggi. Anda dapat menggunakan Storage Write API untuk mengalirkan data ke BigQuery secara real time atau untuk memproses batch data dalam jumlah besar dan meng-commit data tersebut dalam satu operasi atomik.
Keuntungan menggunakan Storage Write API
Semantik pengiriman tepat satu kali. Storage Write API mendukung semantik tepat satu kali melalui penggunaan offset aliran. Tidak seperti metode tabledata.insertAll, Storage Write API tidak pernah menulis dua pesan yang memiliki offset yang sama dalam satu streaming, jika klien memberikan offset streaming ketika menambahkan kumpulan data.
Transaksi tingkat streaming. Anda dapat menulis data ke streaming dan meng-commit data sebagai satu transaksi. Jika operasi commit gagal, Anda dapat mencoba lagi operasi tersebut dengan aman.
Transaksi di seluruh stream. Beberapa pekerja dapat membuat alirannya sendiri untuk memproses data secara independen. Setelah semua pekerja selesai, Anda dapat melakukan commit untuk semua streaming sebagai transaksi.
Protokol yang efisien. Storage Write API lebih efisien daripada metode insertAll lama karena menggunakan streaming gRPC, bukan REST melalui HTTP. Storage Write API juga mendukung format biner protocol buffer dan format kolom Apache Arrow, yang merupakan format kabel yang lebih efisien daripada JSON. Permintaan tulis bersifat asinkron
dengan pengurutan yang terjamin.
Deteksi update skema. Jika skema tabel yang mendasarinya berubah saat klien melakukan streaming, Storage Write API akan memberi tahu klien. Klien dapat memutuskan apakah akan menghubungkan kembali menggunakan skema yang diperbarui, atau melanjutkan menulis ke koneksi yang ada.
Pengurangan biaya. Storage Write API memiliki biaya yang jauh lebih rendah daripada streaming API insertAll lama. Selain itu, Anda dapat menyerap hingga 2 TiB per bulan secara gratis.
Izin yang diperlukan
Untuk menggunakan Storage Write API, Anda harus memiliki izin bigquery.tables.updateData.
Peran Identity and Access Management (IAM) yang telah ditetapkan berikut mencakup izin bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Untuk mengetahui informasi lebih lanjut tentang peran dan izin IAM di BigQuery, baca Peran dan izin bawaan.
Cakupan autentikasi
Penggunaan Storage Write API memerlukan salah satu cakupan OAuth berikut:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Untuk mengetahui informasi selengkapnya, lihat Ringkasan Autentikasi.
Ringkasan Storage Write API
Abstraksi inti dalam Storage Write API adalah streaming. Streaming menulis data ke tabel BigQuery. Lebih dari satu streaming dapat menulis secara serentak ke tabel yang sama.
Streaming default
Storage Write API menyediakan streaming default, yang dirancang untuk skenario streaming ketika Anda memiliki data yang terus-menerus masuk. Tag tersebut memiliki karakteristik berikut:
- Data yang ditulis ke streaming default akan segera tersedia untuk kueri.
- Streaming default mendukung semantik setidaknya satu kali.
- Anda tidak perlu membuat streaming default secara eksplisit.
Jika Anda bermigrasi dari API tabledata.insertall lama, sebaiknya gunakan streaming default. API ini memiliki semantik tulis yang serupa, dengan ketahanan data yang lebih besar dan pembatasan penskalaan yang lebih sedikit.
Alur API:
AppendRows(loop)
Untuk mengetahui informasi selengkapnya dan kode contoh, lihat Menggunakan streaming default untuk semantik minimal satu kali.
Streaming yang dibuat aplikasi
Anda dapat membuat streaming secara eksplisit jika memerlukan salah satu perilaku berikut:
- Menulis semantik tepat satu kali melalui penggunaan offset streaming.
- Dukungan untuk properti ACID tambahan.
Secara umum, stream yang dibuat aplikasi memberikan lebih banyak kontrol atas fungsionalitas, dengan mengorbankan kompleksitas tambahan.
Saat membuat streaming, Anda menentukan jenis. Jenis mengontrol kapan data yang ditulis ke streaming terlihat di BigQuery untuk dibaca.
Jenis tertunda
Dalam jenis tertunda, kumpulan data di-buffer dalam status tertunda sampai Anda meng-commit streaming. Jika Anda meng-commit streaming, semua data yang tertunda akan tersedia untuk dibaca. Commit adalah operasi atomik. Gunakan jenis ini untuk batch workload, sebagai alternatif untuk tugas pemuatan BigQuery. Untuk mengetahui informasi selengkapnya, lihat Memuat batch data menggunakan Storage Write API.
Alur API:
Jenis komitmen
Pada jenis yang di-commit, catatan tersedia untuk segera dibaca saat Anda menulisnya ke streaming. Gunakan jenis ini untuk beban kerja streaming yang memerlukan latensi baca minimal. Streaming default menggunakan bentuk minimal satu kali dari jenis yang di-commit. Untuk mengetahui informasi selengkapnya, lihat Menggunakan jenis yang di-commit untuk semantik tepat satu kali.
Alur API:
CreateWriteStreamAppendRows(loop)FinalizeWriteStream(opsional)
Jenis buffering
Jenis buffering adalah jenis lanjutan yang umumnya tidak boleh digunakan, kecuali dengan konektor I/O Apache Beam BigQuery. Jika Anda memiliki batch kecil yang ingin dijamin muncul bersama, gunakan jenis abonemen dan kirim setiap batch dalam satu permintaan. Dalam jenis ini, commit tingkat baris disediakan, dan kumpulan data di-buffer hingga baris di-commit dengan mengosongkan streaming.
Alur API:
CreateWriteStreamAppendRows⇒FlushRows(loop)FinalizeWriteStream(opsional)
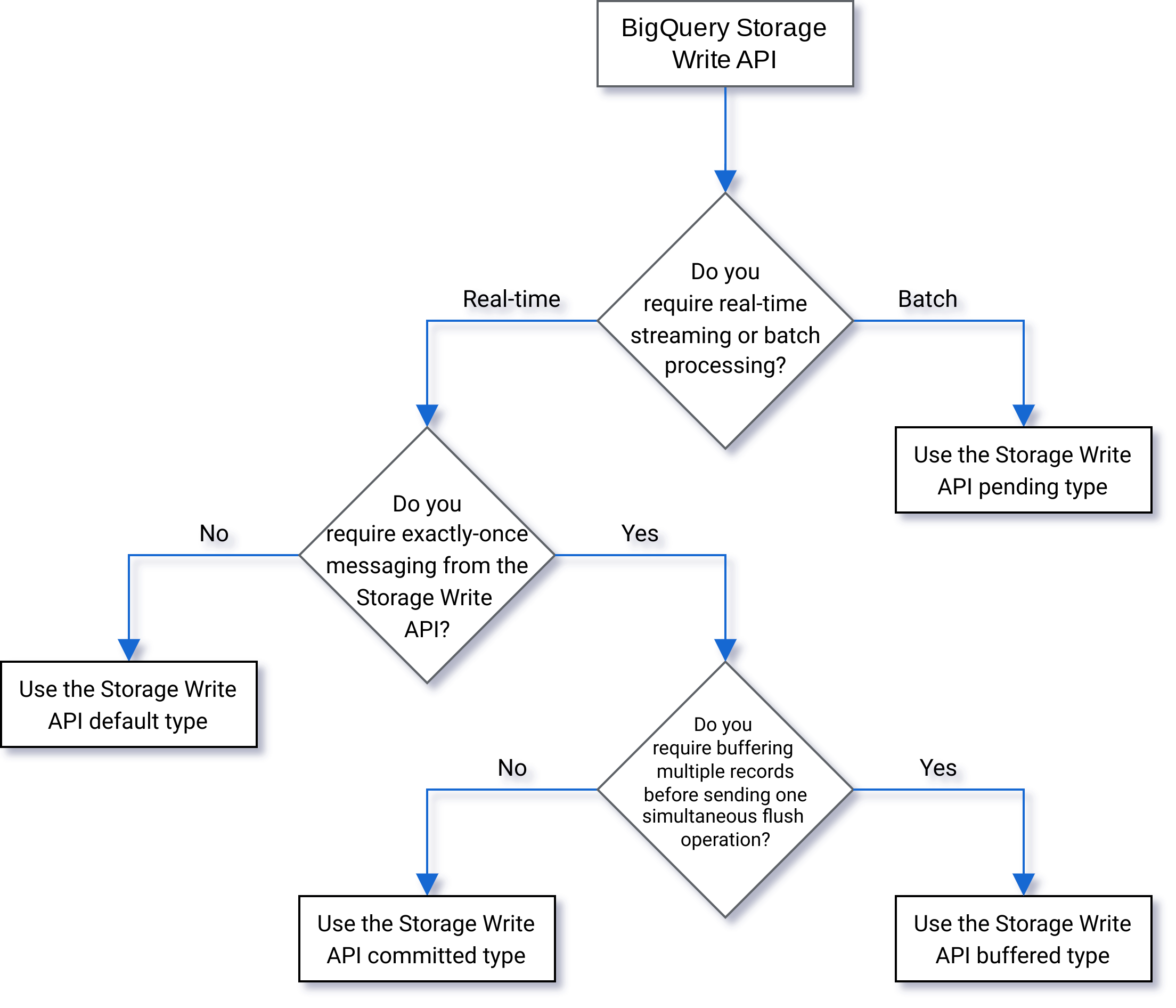
Memilih jenis
Gunakan diagram alur berikut untuk membantu memutuskan jenis mana yang terbaik untuk beban kerja Anda:
Detail API
Pertimbangkan hal berikut saat Anda menggunakan Storage Write API:
AppendRows
Metode AppendRows menambahkan satu atau beberapa data ke streaming. Panggilan pertama ke AppendRows harus berisi nama streaming beserta skema data, yang ditentukan sebagai DescriptorProto. Atau,
Anda dapat menambahkan skema panah berseri dalam panggilan pertama ke AppendRows jika Anda
memasukkan data dalam format Apache Arrow. Sebagai praktik terbaik, kirim batch baris di setiap panggilan AppendRows. Jangan kirim baris satu per satu.
Penanganan Buffering Proto
Buffering protokol menyediakan mekanisme bahasa yang netral, netral platform, dan dapat diperluas untuk membuat serialisasi data terstruktur dengan cara yang kompatibel dengan versi baru dan kompatibel dengan versi sebelumnya. Keduanya menguntungkan karena menyediakan penyimpanan data yang ringkas dengan penguraian yang cepat dan efisien. Untuk mempelajari buffering protokol lebih lanjut, lihat Ringkasan Buffering Protokol.
Jika Anda akan menggunakan API secara langsung dengan pesan buffering protokol yang telah ditetapkan, pesan buffering protokol tidak dapat menggunakan penentu package, dan semua jenis bertingkat atau enumerasi harus ditentukan dalam bagian atas tingkat pemula.
Referensi ke pesan eksternal tidak diizinkan. Sebagai contoh, lihat sample_data.proto.
Klien Java dan Go mendukung buffering protokol arbitrer, karena library klien menormalkan skema buffering protokol.
Penanganan Apache Arrow
Untuk memberikan masukan atau meminta dukungan terkait fitur ini, hubungi bq-write-api-feedback@google.com.
Apache Arrow adalah format kolom universal dan toolbox multi-bahasa untuk pemrosesan data. Apache Arrow menyediakan format memori berorientasi kolom yang independen terhadap bahasa untuk data datar dan hierarkis, yang disusun untuk operasi analitik yang efisien pada hardware modern. Untuk mempelajari Apache Arrow lebih lanjut, lihat Apache Arrow.
Storage Write API mendukung penyerapan Arrow menggunakan skema dan data Arrow berserial dalam class AppendRowsRequest.
Library klien Python mencakup dukungan bawaan untuk penyerapan Apache Arrow. Bahasa lain mungkin memerlukan panggilan AppendRows API mentah untuk menyerap data dalam format Apache Arrow.
FinalizeWriteStream
Metode FinalizeWriteStream akan menyelesaikan streaming sehingga tidak ada data baru yang dapat ditambahkan ke dalamnya. Metode ini diperlukan dalam jenis Pending dan opsional dalam jenis Committed dan Buffered. Streaming default tidak mendukung metode ini.
Penanganan error
Jika terjadi error, google.rpc.Status yang ditampilkan dapat menyertakan StorageError dalam detail error. Tinjau StorageErrorCode untuk menemukan jenis error tertentu. Untuk mengetahui informasi selengkapnya tentang model error Google API, lihat Error.
Koneksi
Storage Write API adalah gRPC API yang menggunakan koneksi dua arah. Metode AppendRows membuat koneksi ke streaming. Anda dapat membuka beberapa koneksi pada streaming default. Penambahan ini bersifat asinkron, yang memungkinkan Anda mengirim serangkaian operasi tulis secara bersamaan. Pesan respons pada setiap koneksi dua arah akan diterima dengan urutan yang sama seperti saat permintaan dikirim.
Streaming yang dibuat aplikasi hanya dapat memiliki satu koneksi aktif. Sebagai praktik terbaik, batasi jumlah koneksi aktif, dan gunakan satu koneksi untuk penulisan data sebanyak mungkin. Saat menggunakan streaming default di Java atau Go, Anda dapat menggunakan multiplexing Storage Write API untuk menulis ke beberapa tabel tujuan dengan koneksi bersama.
Umumnya, satu koneksi mendukung throughput setidaknya 1 MBps. Batas atas bergantung pada beberapa faktor, seperti bandwidth jaringan, skema data, dan beban server. Jika koneksi mencapai batas throughput, permintaan masuk dapat ditolak atau dimasukkan ke dalam antrean sampai jumlah permintaan yang sedang berlangsung turun. Jika Anda memerlukan lebih banyak throughput, buat lebih banyak koneksi.
BigQuery menutup koneksi gRPC jika koneksi tetap tidak ada aktivitas terlalu lama. Jika hal ini terjadi, kode responsnya adalah HTTP 409. Koneksi gRPC juga dapat ditutup jika server dimulai ulang atau karena alasan lainnya. Jika terjadi error koneksi, buat koneksi baru. Library klien Java dan Go secara otomatis terhubung kembali jika koneksi ditutup.
Dukungan library klien
Library klien untuk Storage Write API tersedia dalam beberapa bahasa pemrograman, dan mengekspos konstruksi API berbasis gRPC yang mendasarinya. API ini memanfaatkan fitur canggih seperti streaming dua arah, yang mungkin memerlukan pekerjaan pengembangan tambahan untuk mendukungnya. Untuk itu, sejumlah abstraksi tingkat lebih tinggi tersedia untuk API ini yang menyederhanakan interaksi tersebut dan mengurangi kekhawatiran developer. Sebaiknya manfaatkan abstraksi library lainnya ini jika memungkinkan.
Bagian ini memberikan detail tambahan tentang bahasa dan library yang memiliki kemampuan tambahan di luar API yang dihasilkan untuk developer.
Untuk melihat contoh kode yang terkait dengan Storage Write API, lihat Semua contoh kode BigQuery.
Klien Java
Library klien Java menyediakan dua objek penulis:
StreamWriter: Menerima data dalam format buffering protokol.JsonStreamWriter: Menerima data dalam format JSON dan mengubahnya menjadi buffering protokol sebelum mengirimkannya melalui kabel.JsonStreamWriterjuga mendukung pembaruan skema otomatis. Jika skema tabel berubah, penulis akan otomatis terhubung kembali dengan skema baru, sehingga klien dapat mengirim data menggunakan skema baru.
Model pemrogramannya serupa untuk kedua penulis. Perbedaan utamanya adalah cara Anda memformat payload.
Objek penulis mengelola koneksi Storage Write API. Objek penulis secara otomatis membersihkan permintaan, menambahkan header perutean regional ke permintaan, dan menghubungkan kembali setelah terjadi error koneksi. Jika menggunakan gRPC API secara langsung, Anda harus menangani detail ini.
Klien go
Klien Go menggunakan arsitektur klien-server untuk mengenkode pesan dalam format buffering protokol menggunakan proto2. Lihat dokumentasi Go untuk mengetahui detail tentang cara menggunakan klien Go, dengan kode contoh.
Klien Python
Klien Python adalah klien level rendah yang menggabungkan gRPC API. Untuk menggunakan klien ini, Anda harus mengirim data sebagai buffer protokol, dengan mengikuti alur API untuk jenis yang ditentukan.
Hindari penggunaan pembuatan pesan proto dinamis di Python karena performa library tersebut di bawah standar.
Untuk mempelajari lebih lanjut cara menggunakan buffering protokol dengan Python, baca Tutorial dasar-dasar buffering protokol di Python.
Anda juga dapat menggunakan format penyerapan Apache Arrow sebagai protokol alternatif untuk menyerap data menggunakan Storage Write API. Untuk mengetahui informasi selengkapnya, lihat Menggunakan format Apache Arrow untuk menyerap data.
Klien NodeJS
Library klien NodeJS menerima input JSON dan menyediakan dukungan koneksi ulang otomatis. Lihat dokumentasi untuk mengetahui detail tentang cara menggunakan klien.
Menangani ketidaktersediaan
Percobaan ulang dengan backoff eksponensial dapat mengurangi error acak dan periode ketidaktersediaan layanan yang singkat. Namun, untuk menghindari penurunan baris selama ketidaktersediaan yang diperpanjang, perlu pertimbangan lebih lanjut. Secara khusus, jika klien terus-menerus tidak dapat menyisipkan baris, apa yang harus dilakukan?
Jawabannya tergantung pada kebutuhan Anda. Misalnya, jika BigQuery digunakan untuk analisis operasional dengan beberapa baris yang hilang dapat diterima, klien dapat menyerah setelah beberapa kali percobaan ulang dan menghapus data. Sebaliknya, setiap baris bersifat penting bagi bisnis, seperti dengan data keuangan, Anda perlu memiliki strategi untuk mempertahankan data hingga dapat disisipkan nanti.
Salah satu cara umum untuk menangani error yang terus-menerus adalah dengan memublikasikan baris ke topik Pub/Sub untuk dievaluasi nanti dan kemungkinan penyisipan. Metode umum lainnya adalah mempertahankan data pada klien untuk sementara. Kedua metode tersebut dapat membuat klien tidak diblokir, sekaligus memastikan bahwa semua baris dapat disisipkan setelah ketersediaan dipulihkan.
Streaming ke tabel berpartisi
Storage Write API mendukung streaming data ke dalam tabel berpartisi.
Saat di-streaming, data awalnya ditempatkan di partisi __UNPARTITIONED__. Setelah data yang tidak dipartisi dikumpulkan secara memadai, BigQuery akan melakukan partisi ulang data, dan menempatkannya ke partisi yang sesuai.
Namun, tidak ada perjanjian tingkat layanan (SLA) yang menentukan waktu yang diperlukan untuk memindahkan data tersebut dari partisi __UNPARTITIONED__.
Untuk tabel berpartisi waktu penyerapan dan
berpartisi kolom unit waktu,
data yang tidak dipartisi dapat dikecualikan dari kueri dengan memfilter nilai NULL
dari partisi __UNPARTITIONED__ menggunakan salah satu kolom pseudo
(_PARTITIONTIME atau _PARTITIONDATE
bergantung pada jenis data yang Anda inginkan).
Partisi waktu penyerapan
Saat Anda melakukan streaming ke tabel berpartisi berdasarkan waktu penyerapan, Storage Write API akan menyimpulkan partisi tujuan dari waktu UTC sistem saat ini.
Jika melakukan streaming data ke tabel berpartisi harian, Anda dapat mengganti
inferensi tanggal dengan menyediakan dekorator partisi sebagai bagian dari permintaan.
Sertakan dekorator dalam parameter tableID. Misalnya, Anda dapat melakukan streaming ke
partisi yang sesuai dengan 2025-06-01 untuk tabel table1 menggunakan
dekorator partisi table1$20250601.
Saat melakukan streaming dengan dekorator partisi, Anda dapat melakukan streaming ke partisi dari 31 hari sebelumnya hingga 16 hari ke depan. Untuk menulis ke partisi untuk tanggal di luar batas ini, gunakan tugas pemuatan atau kueri, seperti yang dijelaskan dalam Menulis data ke partisi tertentu.
Streaming menggunakan dekorator partisi hanya didukung untuk tabel berpartisi harian dengan aliran default, bukan untuk tabel berpartisi per jam, bulanan, atau tahunan, atau aliran yang dibuat aplikasi.
Partisi kolom satuan waktu
Saat Anda melakukan streaming ke tabel berpartisi kolom unit waktu,
BigQuery akan otomatis memasukkan data ke partisi yang benar
berdasarkan nilai kolom partisi DATE, DATETIME, atau TIMESTAMP yang telah ditentukan sebelumnya. Anda dapat mengalirkan data ke tabel yang dipartisi kolom unit waktu jika data yang dirujuk oleh kolom partisi berdurasi antara 10 tahun terakhir dan 1 tahun ke depan.
Partisi rentang bilangan bulat
Saat Anda melakukan streaming ke tabel berpartisi rentang bilangan bulat, BigQuery akan otomatis memasukkan data ke partisi yang benar berdasarkan nilai kolom partisi INTEGER yang telah ditentukan sebelumnya di tabel.
Plugin output Storage Write API Fluent Bit
Plugin output Storage Write API Fluent Bit mengotomatiskan proses penyerapan data JSON ke BigQuery, sehingga Anda tidak perlu menulis kode. Dengan plugin ini, Anda hanya perlu mengonfigurasi plugin input yang kompatibel dan menyiapkan file konfigurasi untuk mulai melakukan streaming data. Fluent Bit adalah pemroses dan penerus log open source dan lintas platform yang menggunakan plugin input dan output untuk menangani berbagai jenis sumber dan sink data.
Plugin ini mendukung hal berikut:
- Semantik minimal satu kali menggunakan jenis default.
- Semantik tepat satu kali menggunakan jenis yang di-commit.
- Penskalaan dinamis untuk aliran default, saat tekanan balik ditunjukkan.
Metrik project Storage Write API
Untuk metrik yang memantau penyerapan data Anda dengan Storage Write API, gunakan tampilan INFORMATION_SCHEMA.WRITE_API_TIMELINE atau lihat metrikGoogle Cloud .
Menggunakan bahasa pengolahan data (DML) dengan data yang baru di-streaming
Anda dapat menggunakan bahasa manipulasi data (DML), seperti pernyataan UPDATE, DELETE, atau MERGE, untuk mengubah baris yang baru saja ditulis ke tabel BigQuery oleh BigQuery Storage Write API. Penulisan terbaru adalah penulisan yang terjadi dalam 30 menit terakhir.
Untuk mengetahui informasi selengkapnya tentang penggunaan DML untuk mengubah data yang di-streaming, lihat Menggunakan bahasa manipulasi data.
Batasan
- Dukungan untuk menjalankan pernyataan DML yang mengubah data terhadap data yang baru di-streaming tidak mencakup data yang di-streaming menggunakan insertAll streaming API.
- Menjalankan pernyataan DML yang mengubah data dalam transaksi multi-pernyataan terhadap data yang baru-baru ini di-streaming tidak didukung.
Kuota Storage Write API
Untuk mengetahui informasi tentang kuota dan batas Storage Write API, lihat Kuota dan batas Storage Write API BigQuery.
Anda dapat memantau penggunaan kuota koneksi serentak dan throughput di halaman Quotas diGoogle Cloud console.
Menghitung throughput
Misalkan sasaran Anda adalah mengumpulkan log dari 100 juta endpoint yang membuat 1.500 data log per menit. Kemudian, Anda dapat memperkirakan throughput sebagai 100 million * 1,500 / 60 seconds = 2.5 GB per second.
Anda harus memastikan terlebih dahulu bahwa Anda memiliki kuota yang memadai untuk menyalurkan throughput ini.
Harga Storage Write API
Untuk mengetahui harganya, lihat Harga penyerapan data.
Contoh kasus penggunaan
Misalkan ada data peristiwa pemrosesan pipeline dari log endpoint. Peristiwa dibuat secara terus-menerus dan harus tersedia untuk kueri di BigQuery sesegera mungkin. Karena keaktualan data sangat penting untuk kasus penggunaan ini, Storage Write API adalah pilihan terbaik untuk menyerap data ke BigQuery. Arsitektur yang direkomendasikan untuk menjaga agar endpoint tetap ringkas adalah mengirimkan peristiwa ke Pub/Sub, dari peristiwa tersebut digunakan oleh pipeline Dataflow streaming yang langsung streaming ke BigQuery.
Masalah keandalan utama arsitektur ini adalah cara menangani kegagalan memasukkan data ke BigQuery. Jika tiap kumpulan data penting dan tidak dapat hilang, data perlu di-buffer sebelum mencoba menyisipkan. Dalam arsitektur yang direkomendasikan di atas, Pub/Sub dapat berperan sebagai buffering dengan kemampuan retensi pesannya. Pipeline Dataflow harus dikonfigurasi untuk mencoba ulang penyisipan streaming BigQuery dengan backoff eksponensial terpotong. Setelah kapasitas Pub/Sub sebagai buffer habis, misalnya dalam kasus BigQuery tidak tersedia dalam waktu lama atau kegagalan jaringan, data harus dipertahankan di klien dan klien membutuhkan mekanisme untuk melanjutkan penyisipan kumpulan data yang dipertahankan setelah ketersediaan dipulihkan. Untuk mengetahui informasi selengkapnya tentang cara menangani situasi ini, lihat postingan blog Panduan Keandalan Google Pub/Sub.
Kasus kegagalan lain yang harus ditangani adalah kumpulan data poison. Kumpulan data poison adalah kumpulan data yang ditolak oleh BigQuery karena kumpulan data gagal disisipkan dengan error yang tidak dapat dicoba lagi atau kumpulan data yang belum berhasil dimasukkan setelah jumlah maksimum percobaan ulang. Kedua jenis kumpulan data harus disimpan di "antrean surat berhenti" oleh pipeline Dataflow untuk penyelidikan lebih lanjut.
Jika semantik tepat satu kali diperlukan, buat streaming tulis dalam jenis yang di-commit, dengan offset kumpulan data yang disediakan oleh klien. Tindakan ini akan menghindari duplikasi, karena operasi tulis hanya dilakukan jika nilai offset cocok dengan offset penambahan berikutnya. Jika offset tidak diberikan, kumpulan data akan ditambahkan ke akhir streaming saat ini, dan mencoba ulang penambahan yang gagal dapat mengakibatkan kumpulan data muncul lebih dari satu kali dalam streaming.
Jika jaminan tepat satu kali tidak diperlukan, penulisan ke streaming default memungkinkan throughput yang lebih tinggi dan juga tidak mengurangi batas kuota saat membuat streaming tulis.
Perkirakan throughput jaringan dan pastikan terlebih dahulu bahwa Anda memiliki kuota yang cukup untuk menyajikan throughput.
Jikaworkload Anda menghasilkan atau memproses data pada kecepatan yang sangat tidak merata, cobalah untuk lancarkan lonjakan beban pada klien dan streaming ke BigQuery dengan throughput yang konstan. Hal ini dapat menyederhanakan perencanaan kapasitas Anda. Jika tidak memungkinkan, pastikan Anda siap menangani error 429 (resource habis) jika dan saat throughput melebihi kuota selama lonjakan singkat.
Untuk contoh mendetail tentang cara menggunakan Storage Write API, lihat Melakukan streaming data menggunakan Storage Write API.
Langkah berikutnya
- Melakukan streaming data menggunakan Storage Write API
- Memuat data dalam batch menggunakan Storage Write API
- Jenis data Arrow dan buffering protokol yang didukung
- Praktik terbaik Storage Write API