Présentation de l'API BigQuery Storage Write
L'API BigQuery Storage Write est une API d'ingestion de données unifiée pour BigQuery. Elle combine l'ingestion en flux continu et le chargement par lot dans une seule API hautes performances. Vous pouvez utiliser l'API Storage Write pour diffuser des enregistrements dans BigQuery en temps réel ou pour traiter par lot un grand nombre d'enregistrements et effectuer leur commit en une seule opération atomique.
Avantages de l'utilisation de l'API Storage Write
Sémantique de diffusion "exactement une fois". L'API Storage Write est compatible avec la sémantique "exactement une fois" grâce à l'utilisation de décalages de flux. Contrairement à la méthode tabledata.insertAll, l'API Storage Write n'écrit jamais deux messages avec le même décalage dans un flux, si le client fournit des décalages de flux lors de l'ajout d'enregistrements.
Transactions au niveau du flux. Vous pouvez écrire des données dans un flux et les valider en tant que transaction unique. Si l'opération de commit échoue, vous pouvez retenter l'opération en toute sécurité.
Transactions dans plusieurs flux. Plusieurs nœuds de calcul peuvent créer leurs propres flux pour traiter les données de manière indépendante. Lorsque tous les nœuds de calcul sont terminés, vous pouvez valider tous les flux en tant que transaction.
Protocole efficace. L'API Storage Write est plus efficace que l'ancienne méthode insertAll, car elle utilise le streaming gRPC plutôt que REST via HTTP. L'API Storage Write est également compatible avec le format binaire Protocol Buffer et le format en colonnes Apache Arrow, qui constituent un format de communication plus efficace que JSON. Les requêtes d'écriture sont asynchrones avec un ordre garanti.
Détection des mises à jour de schéma. Si le schéma de la table sous-jacente change alors que le client est en streaming, l'API Storage Write informe le client. Le client peut choisir de se reconnecter à l'aide du schéma mis à jour ou de continuer à écrire sur la connexion existante.
Réduction des coûts L'API Storage Write a un coût nettement inférieur à celui de l'ancienne API de diffusion par flux insertAll. En outre, vous pouvez ingérer jusqu'à 2 Tio par mois gratuitement.
Autorisations requises
Pour utiliser l'API Storage Write, vous devez disposer des autorisations bigquery.tables.updateData.
Les rôles IAM (Identity and Access Management) suivants incluent les autorisations bigquery.tables.updateData :
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Pour en savoir plus sur les rôles et les autorisations IAM dans BigQuery, consultez la page Rôles prédéfinis et autorisations.
Champs d'application d'authentification
L'API Storage Write requiert l'un des champs d'application OAuth suivants :
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Pour en savoir plus, consultez la page Présentation de l'authentification.
Présentation de l'API Storage Write
L'abstraction principale dans l'API Storage Write est un flux. Un flux écrit des données dans une table BigQuery. Plusieurs flux peuvent écrire simultanément dans la même table.
Diffusion par défaut
L'API Storage Write fournit un flux par défaut conçu pour les scénarios dans lesquels vous recevez des données en continu. Il présente les caractéristiques suivantes :
- Les données écrites dans le flux par défaut sont disponibles immédiatement pour la requête.
- Le flux par défaut accepte la sémantique de type "au moins une fois".
- Vous n'avez pas besoin de créer explicitement le flux par défaut.
Si vous effectuez une migration à partir de l'ancienne API tabledata.insertall, envisagez d'utiliser le flux par défaut. Il présente une sémantique d'écriture similaire, avec une plus grande résilience des données et moins de restrictions de scaling.
Flux de l'API :
AppendRows(boucle)
Pour plus d'informations et un exemple de code, consultez la section Utiliser le flux par défaut pour la sémantique de type "au moins une fois".
Flux créés par l'application
Vous pouvez créer explicitement un flux si vous avez besoin de l'un des comportements suivants :
- Sémantique d'écriture de type "exactement une fois" grâce à l'utilisation de décalages de flux.
- Compatibilité avec les propriétés ACID supplémentaires.
En général, les flux créés par une application offrent davantage de contrôle sur les fonctionnalités au prix d'une complexité supplémentaire.
Lorsque vous créez un flux, vous spécifiez un type. Le type contrôle à quel moment les données écrites dans le flux deviennent visibles dans BigQuery pour lecture.
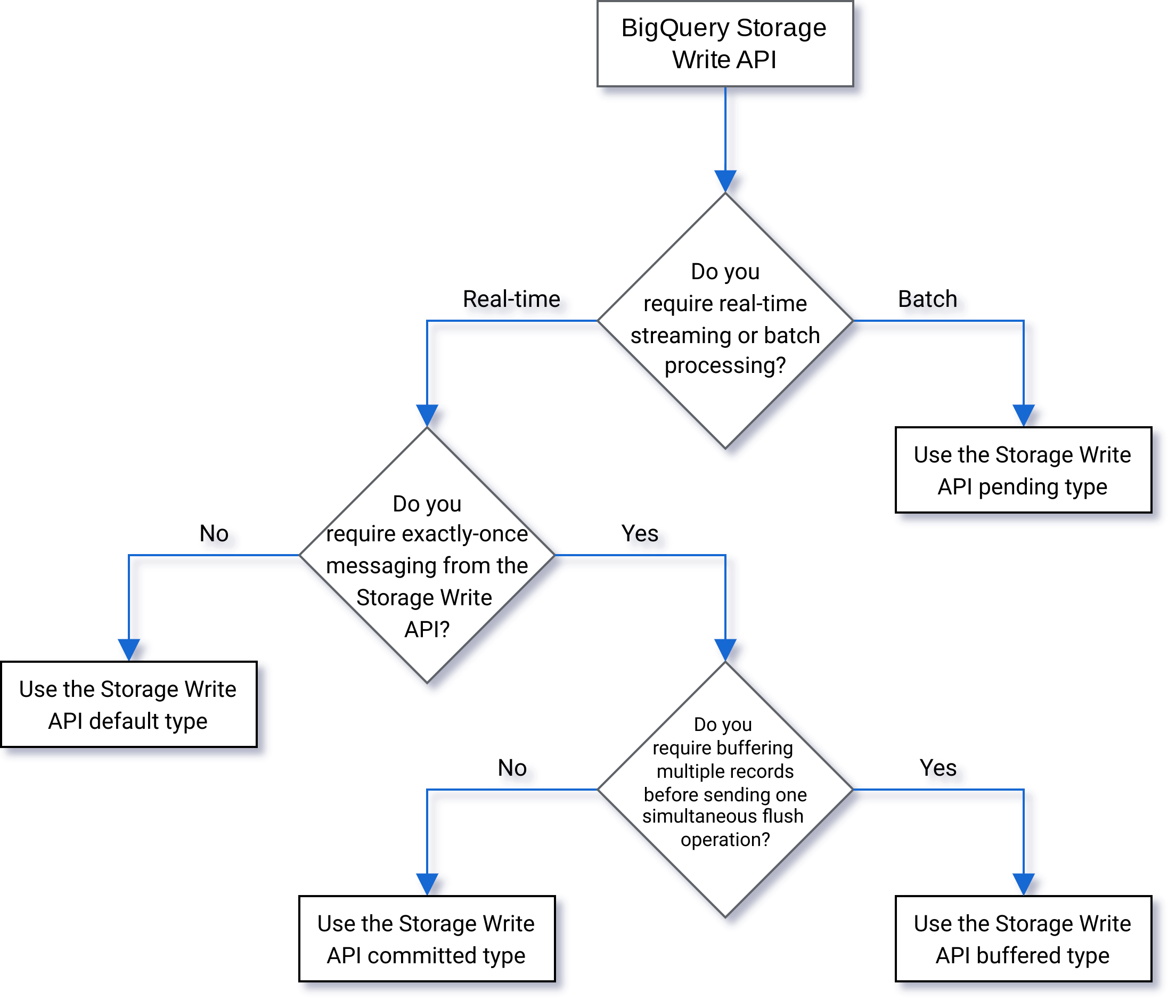
Type en attente
Dans type en attente, les enregistrements sont mis en mémoire tampon dans un état en attente jusqu'à ce que vous effectuiez un commit du flux. Lorsque vous effectuez le commit d'un flux, toutes les données en attente deviennent disponibles pour lecture. Le commit est une opération atomique. Utilisez ce type pour les charges de travail par lot, plutôt que les tâches de chargement BigQuery. Pour en savoir plus, consultez la page Charger des données par lot à l'aide de l'API Storage Write.
Flux de l'API :
Type commit
Dans le type commit, les enregistrements sont disponibles pour lecture immédiate dès que vous les écrivez dans le flux. Utilisez ce type pour les charges de travail par flux qui nécessitent une latence minimale en lecture. Le flux par défaut utilise une forme "au moins une fois" du type commit. Pour en savoir plus, consultez Utiliser le type commit pour la sémantique de type "exactement une fois".
Flux de l'API :
CreateWriteStreamAppendRows(boucle)FinalizeWriteStream(facultatif)
Type de mémoire tampon
Le type de mémoire tampon est un type avancé qui ne doit généralement pas être utilisé, excepté avec le connecteur d'E/S BigQuery Apache Beam. Si vous souhaitez que des petits lots soient affichés ensemble, utilisez le type commit et envoyez chaque lot en une seule requête. Dans ce type, les commits au niveau des lignes sont fournis et les enregistrements sont mis en mémoire tampon jusqu'au commit des lignes lors du vidage du flux.
Flux de l'API :
CreateWriteStreamAppendRows⇒FlushRows(boucle)FinalizeWriteStream(facultatif)
Sélectionner un type
Utilisez l'organigramme suivant pour déterminer le type qui convient le mieux à votre charge de travail :
Détails de l'API
Tenez compte des points suivants lorsque vous utilisez l'API Storage Write :
AppendRows
La méthode AppendRows ajoute un ou plusieurs enregistrements au flux. Le premier appel à AppendRows doit contenir un nom de flux avec le schéma de données, spécifié en tant que DescriptorProto. Vous pouvez également ajouter un schéma Arrow sérialisé lors du premier appel à AppendRows si vous ingérez des données au format Apache Arrow. Nous vous recommandons d'envoyer un lot de lignes dans chaque appel AppendRows. N'envoyez pas une ligne à la fois.
Gestion du tampon de protocole
Les tampons de protocole offrent un mécanisme extensible de sérialisation des données structurées indépendant de la langue et de la plate-forme, à compatibilité ascendante et de manière rétrocompatible. Ils proposent un espace de stockage de données compact, ainsi que des analyses rapides et efficaces. Pour en savoir plus sur les tampons de protocole, consultez la page Présentation du tampon de protocole.
Si vous souhaitez utiliser directement l'API avec un message de tampon de protocole prédéfini, ce message ne peut pas utiliser de spécificateur package, et tous les types imbriqués ou d'énumération doivent être définis dans le message racine principal.
Les références à des messages externes ne sont pas autorisées. Pour obtenir un exemple, consultez la page sample_data.proto.
Les clients Java et Go acceptent les tampons de protocole arbitraires, car la bibliothèque cliente normalise le schéma du tampon de protocole.
Gestion d'Apache Arrow
Pour envoyer des commentaires ou demander de l'aide concernant cette fonctionnalité, contactez bq-write-api-feedback@google.com.
Apache Arrow est un format de colonne universel et une boîte à outils multilingue pour le traitement des données. Apache Arrow fournit un format de mémoire orienté colonne et indépendant du langage pour les données plates et hiérarchiques, organisé pour des opérations analytiques efficaces sur du matériel moderne. Pour en savoir plus sur Apache Arrow, consultez Apache Arrow.
L'API Storage Write est compatible avec l'ingestion Arrow à l'aide du schéma et des données Arrow sérialisés dans la classe AppendRowsRequest.
La bibliothèque cliente Python inclut la compatibilité intégrée pour l'ingestion Apache Arrow. Pour les autres langues, vous devrez peut-être appeler l'API AppendRows brute pour ingérer des données au format Apache Arrow.
FinalizeWriteStream
La méthode FinalizeWriteStream finalise le flux afin qu'aucune nouvelle donnée ne puisse être ajoutée. Cette méthode est obligatoire pour le type Pending, et facultative pour les types Committed et Buffered. Le flux par défaut n'est pas compatible avec cette méthode.
Gestion des exceptions
Si une erreur se produit, l'élément google.rpc.Status renvoyé peut inclure une erreur StorageError dans les détails d'erreur. Examinez StorageErrorCode pour trouver le type d'erreur spécifique. Pour en savoir plus sur le modèle d'erreur des API Google, consultez la page Erreurs.
Connexions
L'API Storage Write est une API gRPC qui utilise des connexions bidirectionnelles. La méthode AppendRows crée une connexion à un flux. Vous pouvez ouvrir plusieurs connexions sur le flux par défaut. Ces ajouts sont asynchrones, ce qui vous permet d'envoyer une série d'écritures simultanément. Les messages de réponse sur chaque connexion bidirectionnelle arrivent dans le même ordre que les requêtes envoyées.
Les flux créés par une application ne peuvent avoir qu'une seule connexion active. Nous vous recommandons de limiter le nombre de connexions actives et d'utiliser une connexion pour autant d'écritures de données que possible. Lorsque vous utilisez le flux par défaut en Java ou Go, vous pouvez utiliser le multiplexage de l'API Storage Write pour écrire dans plusieurs tables de destination avec des connexions partagées.
En règle générale, une seule connexion accepte un débit d'au moins 1 Mbit/s. La limite supérieure dépend de plusieurs facteurs, tels que la bande passante réseau, le schéma des données et la charge du serveur. Lorsqu'une connexion atteint la limite de débit, les requêtes entrantes peuvent être rejetées ou mises en file d'attente jusqu'à la diminution du nombre de requêtes en cours. Si vous avez besoin de plus de débit, créez davantage de connexions.
BigQuery ferme la connexion gRPC si elle reste inactive trop longtemps. Dans ce cas, le code de réponse est HTTP 409. La connexion gRPC peut également être fermée en cas de redémarrage du serveur ou pour d'autres raisons. Si une erreur de connexion se produit, créez une connexion. Les bibliothèques clientes Java et Go se reconnectent automatiquement si la connexion est fermée.
Compatibilité avec les bibliothèques clientes
Les bibliothèques clientes pour l'API Storage Write sont disponibles dans plusieurs langages de programmation et exposent les constructions d'API sous-jacentes basées sur gRPC. Cette API exploite des fonctionnalités avancées telles que le streaming bidirectionnel, qui peut nécessiter des tâches de développement supplémentaires. À cette fin, un certain nombre d'abstractions de niveau supérieur sont disponibles pour cette API afin de simplifier ces interactions et de réduire les préoccupations des développeurs. Nous vous recommandons d'exploiter ces autres abstractions de bibliothèque lorsque cela est possible.
Cette section fournit des informations supplémentaires sur les langages et les bibliothèques dans lesquels des fonctionnalités supplémentaires, en plus de l'API générée, ont été fournies aux développeurs.
Pour afficher des exemples de code liés à l'API Storage Write, consultez Tous les exemples de code BigQuery.
Client Java
La bibliothèque cliente Java fournit deux objets "writer" :
StreamWriter: accepte les données au format de tampon de protocole.JsonStreamWriter: accepte les données au format JSON et les convertit en tampons de protocole avant de les envoyer via le réseau. La fonctionJsonStreamWriterest également compatible avec les mises à jour automatiques de schéma. Si le schéma de la table change, le rédacteur se reconnecte automatiquement au nouveau schéma, ce qui permet au client d'envoyer des données à l'aide du nouveau schéma.
Le modèle de programmation est similaire pour les deux objets "writer". La principale différence réside dans la mise en forme de la charge utile.
L'objet rédacteur gère une connexion à l'API Storage Write. L'objet rédacteur nettoie automatiquement les requêtes, ajoute les en-têtes de routage régionaux aux requêtes, puis se reconnecte après les erreurs de connexion. Si vous utilisez directement l'API gRPC, vous devez gérer ces détails.
Client Go
Le client Go utilise une architecture client-serveur pour encoder les messages au format de tampon de protocole à l'aide de proto2. Consultez la documentation Go pour découvrir comment utiliser le client Go avec un exemple de code.
Client Python
Le client Python est un client de niveau inférieur qui encapsule l'API gRPC. Pour utiliser ce client, vous devez envoyer les données sous forme de tampons de protocole, en suivant le flux d'API pour le type spécifié.
Évitez d'utiliser la génération dynamique de messages proto en Python, car les performances de cette bibliothèque sont insuffisantes.
Pour en savoir plus sur l'utilisation des tampons de protocole avec Python, consultez le tutoriel sur les principes de base des tampons de protocole dans Python.
Vous pouvez également utiliser le format d'ingestion Apache Arrow comme protocole alternatif pour ingérer des données à l'aide de l'API Storage Write. Pour en savoir plus, consultez Utiliser le format Apache Arrow pour ingérer des données.
Client Node.js
La bibliothèque cliente NodeJS accepte les entrées JSON et prend en charge la reconnexion automatique. Consultez la documentation pour en savoir plus sur l'utilisation du client.
Gérer l'indisponibilité
Une nouvelle tentative avec un intervalle exponentiel entre les tentatives permet de limiter l'impact des erreurs inattendues et des courtes périodes d'indisponibilité des services. Cependant, il en faut plus pour s'assurer de ne pas perdre de lignes lors d'une période d'indisponibilité étendue. Plus spécifiquement, que faut-il faire si un client est constamment dans l'impossibilité d'insérer une ligne ?
La réponse dépend de vos besoins. Par exemple, si BigQuery est utilisé pour une application d'analyse opérationnelle qui peut tolérer que certaines lignes soient manquantes, le client peut renoncer après quelques tentatives et supprimer les données. Si chaque ligne est essentielle pour l'entreprise, par exemple en ce qui concerne les données financières, vous devez disposer d'une stratégie permettant de conserver les données jusqu'à ce qu'elles puissent être insérées ultérieurement.
Une manière courante de traiter les erreurs persistantes consiste à publier les lignes dans un sujet Pub/Sub pour une évaluation ultérieure et une possible insertion. Une autre méthode courante consiste à conserver temporairement les données sur le client. Ces deux méthodes évitent de bloquer le client tout en garantissant que toutes les lignes peuvent être insérées une fois la disponibilité restaurée.
Insérer des données en flux continu dans des tables partitionnées
L'API Storage Write permet de diffuser des données dans des tables partitionnées.
Lorsque les données sont diffusées en continu, elles sont initialement placées dans la partition __UNPARTITIONED__. Une fois qu'une quantité suffisante de données non partitionnées est collectée, BigQuery partitionne à nouveau les données, en les plaçant dans la partition appropriée.
Toutefois, aucun contrat de niveau de service n'est établi qui définit le temps nécessaire pour que ces données soient retirées de la partition __UNPARTITIONED__.
Pour les tables partitionnées par date d'ingestion et partitionnées par colonne d'unité de temps, les données non partitionnées peuvent être exclues d'une requête en filtrant les valeurs NULL de la partition __UNPARTITIONED__ à l'aide de l'une des pseudo-colonnes (_PARTITIONTIME ou _PARTITIONDATE selon le type de données préféré).
Partitionnement par date d'ingestion
Lorsque vous insérez du contenu en flux continu dans une table partitionnée par date d'ingestion, l'API Storage Write déduit la partition de destination de l'heure UTC actuelle du système.
Si vous insérez des données en flux continu dans une table partitionnée par jour, vous pouvez remplacer la date déduite en fournissant un décorateur de partition dans la requête.
Incluez le décorateur dans le paramètre tableID. Par exemple, vous pouvez insérer des données en flux continu dans la partition correspondant à 2025-06-01 pour la table table1 à l'aide du décorateur de partition table1$20250601.
Lorsque vous insérez des données en flux continu à l'aide d'un décorateur de partition, vous pouvez insérer des données dans des partitions pour la période comprise entre les 31 derniers jours et les 16 prochains jours. Pour écrire sur des partitions pour des dates situées en dehors de ces limites, utilisez plutôt une tâche de chargement ou de requête, comme décrit dans la section Écrire des données dans une partition spécifique.
L'insertion à l'aide d'un décorateur de partition n'est compatible qu'avec les tables partitionnées quotidiennes avec des flux par défaut, et non avec les tables partitionnées par heure, par mois ou par année, ni avec les flux créés par l'application.
Partitionnement par colonnes d'unités de temps
Lorsque vous diffusez des données dans une table partitionnée par colonne d'unité de temps, BigQuery les enregistre automatiquement dans la partition appropriée en fonction des valeurs de la colonne de partitionnement DATE, DATETIME ou TIMESTAMP prédéfinie de la table. Vous pouvez insérer des données en flux continu dans une table partitionnée par colonne d'unité de temps si les données référencées par la colonne de partitionnement se situent entre 10 ans dans le passé et 1 an dans le futur.
Partitionnement par plages d'entiers
Lorsque vous diffusez des données dans une table partitionnée par plage d'entiers, BigQuery les enregistre automatiquement dans la partition appropriée en fonction des valeurs de la colonne de partitionnement INTEGER prédéfinie de la table.
Plug-in de sortie de l'API Fluent Bit Storage Write
Le plug-in de sortie de l'API Fluent Bit Storage Write automatise le processus d'ingestion des enregistrements JSON dans BigQuery, ce qui vous évite d'avoir à écrire du code. Avec ce plug-in, il vous suffit de configurer un plug-in d'entrée compatible et de créer un fichier de configuration pour lancer la diffusion des données. Fluent Bit est un processeur et redirecteur de journaux Open Source et multiplate-forme qui utilise des plug-ins d'entrée et de sortie pour gérer différents types de sources et de récepteurs de données.
Ce plug-in est compatible avec les éléments suivants :
- Sémantique de type "au moins une fois" avec le type par défaut
- Sémantique de type "exactement une fois" avec le type de commit
- Scaling dynamique pour les flux par défaut, lorsque la contre-pression est indiquée
Métriques de projet de l'API Storage Write
Pour connaître les métriques à surveiller pour l'ingestion de données avec l'API Storage Write, utilisez la vue INFORMATION_SCHEMA.WRITE_API_TIMELINE ou consultez les métriquesGoogle Cloud .
Utiliser le langage de manipulation de données (LMD) avec des données récemment diffusées
Vous pouvez utiliser un langage de manipulation de données (LMD), tel que les instructions UPDATE, DELETE ou MERGE, pour modifier les lignes récemment écrites dans une table BigQuery par l'API BigQuery Storage Write. Les écritures récentes sont celles qui se sont produites au cours des 30 dernières minutes.
Pour en savoir plus sur l'utilisation du LMD pour modifier vos données diffusées, consultez la page Utiliser le langage de manipulation de données.
Limites
- La compatibilité avec l'exécution d'instructions LMD impliquant une mutation sur des données récemment diffusées ne s'applique pas aux données diffusées à l'aide de l'API insertAll streaming.
- Il n'est pas possible d'exécuter des instructions LMD impliquant une mutation dans une transaction à plusieurs instructions sur des données récemment diffusées.
Quotas de l'API Storage Write
Pour en savoir plus sur les quotas et limites de l'API Storage Write, consultez la page Quotas et limites de l'API BigQuery Storage Write.
Vous pouvez surveiller vos connexions simultanées et votre utilisation du quota de débit sur la page Quotas de la consoleGoogle Cloud .
Calculer le débit
Supposons que votre objectif soit de collecter les journaux de 100 millions de points de terminaison qui génèrent 1 500 enregistrements de journaux par minute. Vous pouvez ensuite estimer le débit à 100 million * 1,500 / 60 seconds = 2.5 GB per second.
Vous devez vous assurer à l'avance de disposer d'un quota suffisant pour diffuser ce débit.
Tarifs de l'API Storage Write
Pour connaître les tarifs, consultez la section Tarifs de l'ingestion de données.
Exemple d'utilisation
Supposons qu'un pipeline traite des données d'événement à partir des journaux de points de terminaison. Les événements sont générés en continu et doivent être disponibles dès que possible pour des requêtes dans BigQuery. La fraîcheur des données étant primordiale pour ce cas d'utilisation, l'API Storage Write est la meilleure option pour ingérer les données dans BigQuery. Une architecture recommandée pour ne pas surcharger ces points de terminaison consiste à envoyer les événements vers Pub/Sub afin qu'ils soient consommés par un pipeline Dataflow de traitement en flux continu qui les diffuse directement vers BigQuery.
La principale préoccupation de fiabilité pour cette architecture est la gestion des échecs d'insertion d'un enregistrement dans BigQuery. Si chaque enregistrement est important et ne peut pas être perdu, les données doivent être mises en mémoire tampon avant d'essayer de les insérer. Dans l'architecture recommandée ci-dessus, Pub/Sub peut jouer le rôle d'un tampon avec ses fonctionnalités de conservation des messages. Le pipeline Dataflow doit être configuré de manière à relancer les insertions par flux BigQuery avec un intervalle exponentiel tronqué entre les tentatives. Une fois la capacité de Pub/Sub en tant que mémoire tampon épuisée, par exemple en cas d'indisponibilité prolongée de BigQuery ou de défaillance du réseau, les données doivent être conservées côté client et le client doit mettre en œuvre un mécanisme de reprise d'insertion des enregistrements une fois la disponibilité restaurée. Pour savoir comment gérer cette situation, consultez l'article de blog Guide de fiabilité Google Pub/Sub.
Les enregistrements nocifs sont un autre type de défaillance à gérer. Un enregistrement nocif est soit un enregistrement refusé par BigQuery parceque son insertion génère une erreur ne permettant aucune autre tentative, soit un enregistrement qu'il n'a pas été possible d'insérer après le nombre maximal de tentatives. Les deux types d'enregistrements doivent être stockés dans une file d'attente de lettres mortes par le pipeline Dataflow pour une analyse plus approfondie.
Si la sémantique "exactement une fois" est requise, créez un flux d'écriture dans le type commit, avec les décalages d'enregistrement fournis par le client. Cela évite les doublons, car l'opération d'écriture n'est appliquée que si la valeur de décalage correspond au prochain décalage d'ajout. Si vous ne fournissez pas de décalage, les enregistrements sont ajoutés à la fin actuelle du flux, ce qui implique un risque de création de doublon de cet enregistrement dans le flux en ca de nouvelle tentative d'insertion.
Si aucune garantie de type "exactement une fois" n'est requise, écrire dans le flux par défaut permet d'obtenir un débit plus élevé et de ne pas consommer la limite de quota applicable à la création de flux d'écriture.
Estimez le débit de votre réseau et assurez-vous à l'avance que vous disposez d'un quota suffisant pour diffuser le débit.
Si votre charge de travail génère ou traite des données à un rythme très inégal, essayez d'atténuer les pics de charge du côté client et d'envoyer les données en streaming à BigQuery avec un débit constant. Cela peut simplifier votre planification de capacité. Si cela n'est pas possible, assurez-vous d'être prêt à gérer les erreurs 429 (ressources épuisées) si et quand votre débit dépasse le quota pendant de courts pics d'activité.
Pour obtenir un exemple détaillé d'utilisation de l'API Storage Write, consultez Diffuser des données à l'aide de l'API Storage Write.
Étapes suivantes
- Diffuser des données à l'aide de l'API Storage Write
- Charger des données par lot à l'aide de l'API Storage Write
- Types de données Arrow et de tampons de protocole compatibles
- Bonnes pratiques concernant l'API Storage Write