Introducción a la API de BigQuery Storage Write
La API de BigQuery Storage Write es una API de transferencia de datos unificada para BigQuery. Combina la transferencia de transmisión y la carga por lotes en una sola API de alto rendimiento. Puedes usar la API de Storage Write para transmitir registros a BigQuery en tiempo real o procesar por lotes una gran cantidad arbitraria de registros y confirmarlos en una sola operación atómica.
Ventajas de usar la API de Storage Write
Semántica de entrega exacta una vez. La API de Storage Write admite una semántica de tipo “solo una vez” a través del uso de compensaciones de transmisión. A diferencia del método tabledata.insertAll, la API de Storage Write nunca escribe dos mensajes que tienen la misma compensación dentro de una transmisión, si el cliente proporciona compensaciones de transmisión cuando agrega registros.
Transacciones a nivel de transmisión. Puedes escribir datos en una transmisión y confirmarlos como una sola transacción. Si la operación de confirmación falla, puedes reintentar la operación de forma segura.
Transacciones en las transmisiones. Varios trabajadores pueden crear sus propias transmisiones para procesar datos de forma independiente. Cuando todos los trabajadores finalizan, puedes confirmar todas las transmisiones como una transacción.
Protocolo eficiente. La API de Storage Write es más eficiente que el método insertAll heredado porque usa transmisión de gRPC en lugar de REST a través de HTTP. La API de Storage Write también admite el formato binario de búfer de protocolo y el formato columnar de Apache Arrow, que son formatos de conexión más eficientes que JSON. Las solicitudes de escritura son asíncronas con orden garantizado.
Detección de actualización del esquema. Si el esquema de la tabla subyacente cambia mientras el cliente está transmitiendo, la API de Storage Write notifica al cliente. El cliente puede decidir si quiere volver a conectarse a través del esquema actualizado o continuar escribiendo en la conexión existente.
Costo menor. La API de Storage Write tiene un costo mucho menor que la API de transmisión insertAll anterior. Además, puedes transferir hasta 2 TiB por mes de forma gratuita.
Permisos necesarios
Para usar la API de Storage Write, debes tener los permisos bigquery.tables.updateData.
Las siguientes funciones predefinidas de Identity and Access Management (IAM) incluyen los permisos bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Para obtener más información sobre las funciones de IAM y los permisos en BigQuery, consulta Funciones y permisos predefinidos.
Permisos de autenticación
El uso de la API de Storage Write requiere uno de los siguientes permisos de OAuth:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Para obtener más información, consulta Descripción general de la autenticación.
Descripción general de la API de Storage Write
La abstracción principal en la API de Storage Write es una transmisión. Una transmisión escribe datos en una tabla de BigQuery. Más de una transmisión puede escribir de forma simultánea en la misma tabla.
Transmisión predeterminada
La API de Storage Write proporciona una transmisión predeterminada, diseñada para situaciones de transmisión en las que tienes datos que llegan de forma continua. Tiene las siguientes características:
- Los datos escritos en la transmisión predeterminada están disponibles de inmediato para realizar consultas.
- La transmisión predeterminada admite semántica de al menos una vez.
- No necesitas crear de forma explícita la transmisión predeterminada.
Si migras desde la API tabledata.insertall heredada, considera usar la transmisión predeterminada. Tiene una semántica de escritura similar, con mayor resiliencia de datos y menos restricciones de escalamiento.
Flujo de la API:
AppendRows(bucle)
Para obtener más información y el código de ejemplo, consulta Usa la transmisión predeterminada para la semántica de al menos una vez.
Transmisiones creadas por la aplicación
Puedes crear una transmisión de forma explícita si necesitas uno de los siguientes comportamientos:
- Escribe semánticas de escritura de tipo “solo una vez” a través del uso de desplazamientos de transmisión.
- Asistencia con propiedades ACID adicionales.
En general, las transmisiones creadas por la aplicación brindan un mayor control sobre la funcionalidad a costa de una complejidad adicional.
Cuando creas una transmisión, especificas un tipo. El tipo controla cuándo los datos escritos en la transmisión se vuelven visibles en BigQuery para su lectura.
Tipo pendiente
En tipo pendiente, los registros se almacenan en búfer en un estado pendiente hasta que confirmes la transmisión. Cuando confirmas una transmisión, todos los datos pendientes pasan a estar disponibles para su lectura. La confirmación es una operación atómica. Usa este tipo para las cargas de trabajo por lotes como alternativa a los trabajos de carga de BigQuery. Para obtener más información, consulta Carga datos por lotes con la API de Storage Write.
Flujo de la API:
Tipo de compromiso
En el tipo de compromiso, los registros están disponibles para su lectura inmediata a medida que los escribes en la transmisión. Usa este tipo para las cargas de trabajo de transmisión que necesitan una latencia mínima de lectura. La transmisión predeterminada usa al menos una forma del tipo confirmado. Para obtener más información, consulta Usa el tipo de confirmación para la semántica de tipo "exactamente una vez".
Flujo de la API:
CreateWriteStreamAppendRows(bucle)FinalizeWriteStream(opcional)
Tipo de almacenamiento en búfer
El tipo de almacenamiento en búfer es un tipo avanzado que, por lo general, no se debe usar con el conector de E/S de BigQuery de Apache Beam. Si tienes lotes pequeños que deseas garantizar que aparezcan juntos, usa el tipo de confirmación y envía cada lote en una solicitud. En este tipo, se proporcionan confirmaciones a nivel de fila, y los registros se almacenan en búfer hasta que las filas se confirmen a través de la limpieza de la transmisión.
Flujo de la API:
CreateWriteStreamAppendRows⇒FlushRows(bucle)FinalizeWriteStream(opcional)
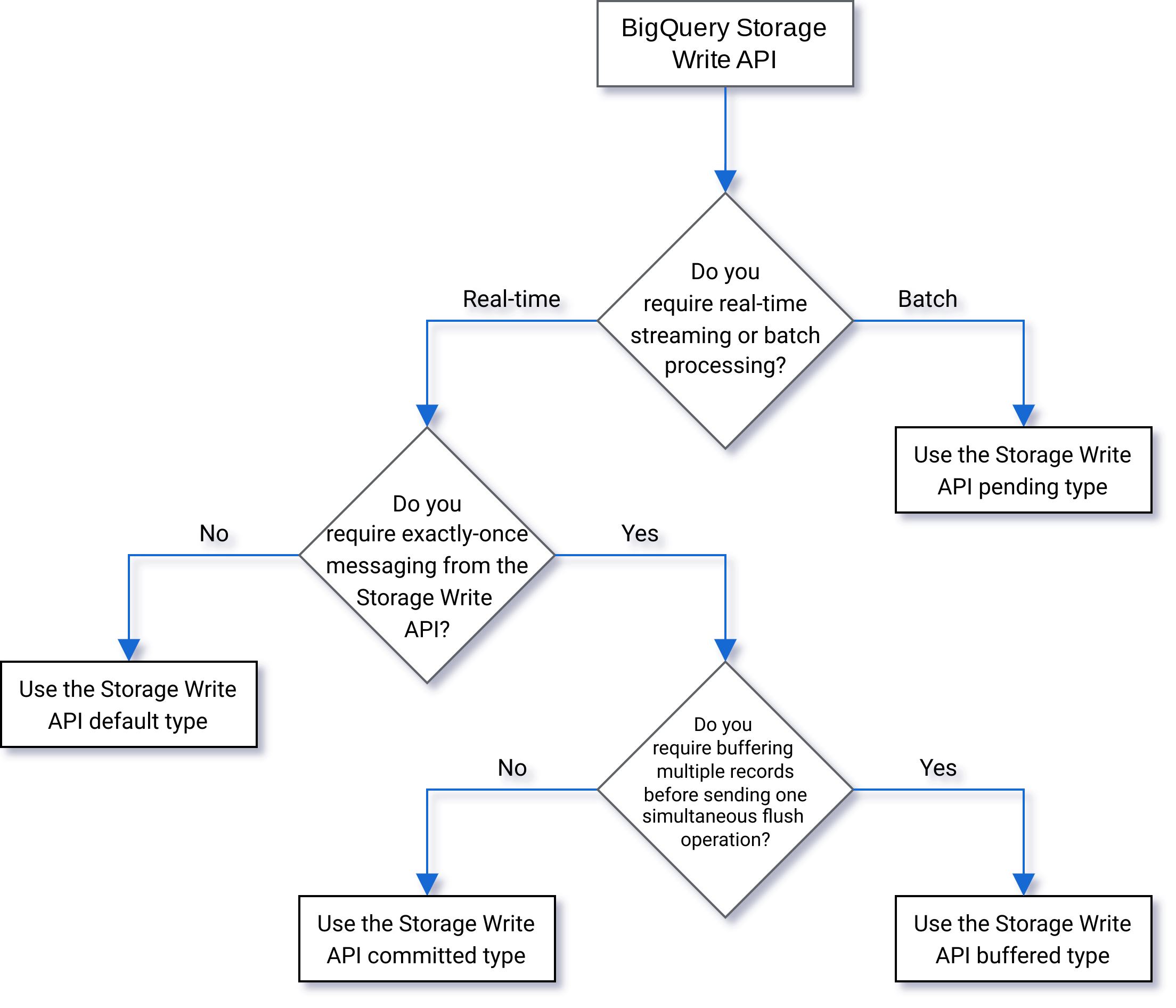
Selecciona un tipo
Usa el siguiente diagrama de flujo para decidir qué tipo es mejor para tu carga de trabajo:
Detalles de la API
Ten en cuenta lo siguiente cuando uses la API de Storage Write:
AppendRows
El método AppendRows agrega uno o más registros a la transmisión. La primera llamada a AppendRows debe contener un nombre de transmisión junto con el esquema de datos, especificado como DescriptorProto. Como alternativa, puedes agregar un esquema de flecha serializado en la primera llamada a AppendRows si ingieres datos en formato Apache Arrow. Como práctica recomendada, envía un lote de filas en cada llamada a AppendRows. No envíes una fila a la vez.
Manejo de búferes de Proto
Los búferes de protocolo proporcionan un mecanismo extensible, con un formato de lenguaje y plataforma neutros, para serializar datos estructurados de manera compatible con versiones anteriores y futuras. Son excelentes porque proporcionan almacenamiento de datos compacto a través de un análisis rápido y eficiente. Para obtener más información sobre los búferes de protocolo, consulta Descripción general del búfer de protocolo.
Si vas a consumir la API de forma directa con un mensaje de búfer de protocolo predefinido, el mensaje de búfer de protocolo no puede usar un especificador package, y todos los tipos anidados o de enumeración deben definirse en la parte superior nivel superior.
No se permiten referencias a mensajes externos. Para ver un ejemplo, consulta sample_data.proto.
Los clientes Java y Go admiten búferes de protocolo arbitrarios, ya que la biblioteca cliente normaliza el esquema de búfer de protocolo.
Control de Apache Arrow
Para enviar comentarios o solicitar asistencia para esta función, comunícate con bq-write-api-feedback@google.com.
Apache Arrow es un formato columnar universal y un conjunto de herramientas multilingüe para el procesamiento de datos. Apache Arrow proporciona un formato de memoria orientado a columnas independiente del lenguaje para datos planos y jerárquicos, organizado para operaciones analíticas eficientes en hardware moderno. Para obtener más información sobre Apache Arrow, consulta Apache Arrow.
La API de Storage Write admite la transferencia de datos con Arrow a través de un esquema y datos de Arrow serializados en la clase AppendRowsRequest.
La biblioteca cliente de Python incluye compatibilidad integrada para la transferencia de datos de Apache Arrow. Es posible que otros lenguajes requieran llamar a la API de AppendRows sin procesar para ingerir datos en formato Apache Arrow.
FinalizeWriteStream
El método FinalizeWriteStream finaliza la transmisión para que no se puedan agregar datos nuevos. Este método es obligatorio en el
tipo Pending y opcional en los tipos
Committed y
Buffered. La transmisión predeterminada no es compatible con este método.
Manejo de errores
Si se produce un error, el google.rpc.Status que se muestra puede incluir un StorageError en los detalles del error. Revisa
StorageErrorCode para encontrar el tipo de error específico. Para obtener más información sobre el modelo de error de la API de Google, consulta Errores.
Conexiones
La API de Storage Write es una API de gRPC que usa conexiones bidireccionales. El método AppendRows crea una conexión a una transmisión. Puedes abrir varias conexiones en la transmisión predeterminada. Estos agregados son asíncronos,
lo que te permite enviar una serie de operaciones de escritura de forma simultánea. Los mensajes de respuesta en cada conexión bidireccional llegan en el mismo orden en que se enviaron las solicitudes.
Las transmisiones creadas por la aplicación solo pueden tener una única conexión activa. Como práctica recomendada, limita la cantidad de conexiones activas y usa una conexión para la mayor cantidad posible de escrituras de datos. Cuando usas la transmisión predeterminada en Java o Go, puedes usar la multiplexación de la API de Storage Write para escribir en varias tablas de destino con conexiones compartidas.
En general, una sola conexión admite al menos 1 Mbps de capacidad de procesamiento. El límite superior depende de varios factores, como el ancho de banda de la red, el esquema de los datos y la carga del servidor. Cuando una conexión alcanza el límite de capacidad de procesamiento, las solicitudes entrantes se pueden rechazar o poner en cola hasta que disminuya la cantidad de solicitudes en tránsito. Si necesitas más capacidad de procesamiento, crea más conexiones.
BigQuery cierra la conexión de gRPC si la conexión permanece inactiva por mucho tiempo. Si esto sucede, el código de respuesta es HTTP 409. La conexión de gRPC también se puede cerrar en caso de reinicio del servidor o por otros motivos. Si se produce un error de conexión, crea una conexión nueva. Las bibliotecas cliente de Java y Go se vuelven a conectar de forma automática si se cierra la conexión.
Compatibilidad de la biblioteca cliente
Las bibliotecas cliente para la API de Storage Write existen en varios lenguajes de programación y exponen las construcciones subyacentes de la API basada en gRPC. Esta API aprovecha funciones avanzadas como la transmisión bidireccional, lo que puede requerir trabajo de desarrollo adicional para la compatibilidad. En este sentido, hay una serie de abstracciones de nivel superior disponibles para esta API, lo que simplifica esas interacciones y reduce los problemas de los desarrolladores. Recomendamos aprovechar estas otras abstracciones de biblioteca cuando sea posible.
En esta sección, se proporcionan detalles adicionales sobre los lenguajes y las bibliotecas en los que se proporcionaron a los desarrolladores capacidades adicionales más allá de la API generada.
Para ver muestras de código relacionadas con la API de Storage Write, consulta Todas las muestras de código de BigQuery.
Cliente de Java
La biblioteca cliente de Java proporciona dos objetos de escritor:
StreamWriter: Acepta datos en formato de búfer de protocolo.JsonStreamWriter: acepta datos en formato JSON y los convierte en búferes de protocolo antes de enviarlos por el cable.JsonStreamWritertambién admite actualizaciones automáticas de esquemas. Si el esquema de la tabla cambia, el escritor se vuelve a conectar de manera automática con el esquema nuevo, lo que permite que el cliente envíe datos con el esquema nuevo.
El modelo de programación es similar para ambos escritores. La diferencia principal es la forma en que le das formato a la carga útil.
El objeto de escritor administra una conexión de la API de Storage Write. El objeto de escritor limpia las solicitudes de forma automática, agrega los encabezados de enrutamiento regionales a las solicitudes y se vuelve a conectar después de los errores de conexión. Si usas la API de gRPC de forma directa, debes manejar estos detalles.
Cliente de Go
El cliente de Go usa una arquitectura cliente-servidor para codificar los mensajes en formato del búfer de protocolo usando proto2. Consulta la documentación de Go para obtener detalles sobre cómo usar el cliente de Go con código de ejemplo.
Cliente de Python
El cliente de Python es un cliente de nivel inferior que une la API de gRPC. Para usar este cliente, debes enviar los datos como búferes de protocolo, siguiendo el flujo de la API para el tipo especificado.
Evita usar la generación dinámica de mensajes .proto en Python, ya que el rendimiento de esa biblioteca es inferior al estándar.
Para obtener más información sobre el uso de búferes de protocolo con Python, lee el instructivo sobre los conceptos básicos del búfer de protocolo en Python.
También puedes usar el formato de transferencia de Apache Arrow como protocolo alternativo para transferir datos con la API de Storage Write. Para obtener más información, consulta Cómo usar el formato de Apache Arrow para transferir datos.
Cliente de NodeJS
La biblioteca cliente de NodeJS acepta la entrada JSON y proporciona asistencia automática para la reconexión. Consulta la documentación para obtener detalles sobre cómo usar el cliente.
Controla la falta de disponibilidad
Si vuelves a intentarlo con una retirada exponencial puedes mitigar errores aleatorios y períodos breves de falta de disponibilidad del servicio, pero debes estar más pendiente para evitar quitar filas durante la falta de disponibilidad extendida. En particular, si un cliente no puede insertar una fila de forma persistente, ¿qué debe hacer?
La respuesta depende de tus requisitos. Por ejemplo, si BigQuery se usa para estadísticas operativas en las que algunas filas faltantes son aceptables, el cliente puede renunciar después de unos pocos reintentos y descartar los datos. Si, en cambio, cada fila es crucial para la empresa, como con los datos financieros, debes tener una estrategia para conservar los datos hasta que se puedan insertar más adelante.
Una forma común de tratar errores persistentes es publicar las filas en un tema de Pub/Sub para una evaluación posterior y una posible inserción. Otro método común es conservar de forma temporal los datos en el cliente. Ambos métodos pueden mantener a los clientes bloqueados y, al mismo tiempo, garantizar que todas las filas se puedan insertar una vez que se restablezca la disponibilidad.
Transmite a tablas particionadas
La API de Storage Write admite la transmisión de datos a tablas particionadas.
Cuando los datos se transmiten, al principio se colocan en la partición __UNPARTITIONED__. Una vez que se recopilan suficientes datos no particionados, BigQuery vuelve a particionarlos y los coloca en la partición adecuada.
Sin embargo, no existe un Acuerdo de Nivel de Servicio(ANS) que defina cuánto tiempo les tomará a esos datos salir de la partición __UNPARTITIONED__.
En el caso de las tablas particionadas por tiempo de transferencia y las tablas particionadas por columna de unidad de tiempo, los datos no particionados se pueden excluir de una consulta filtrando los valores NULL de la partición __UNPARTITIONED__ con una de las pseudocolumnas (_PARTITIONTIME o _PARTITIONDATE, según tu tipo de datos preferido).
Partición por tiempo de transferencia
Cuando transmites a una tabla particionada por tiempo de transferencia, la API de Storage Write infiere la partición de destino a partir de la hora UTC actual del sistema.
Si transmites datos a una tabla particionada diaria, puedes anular la inferencia de fecha si proporcionas un decorador de partición como parte de la solicitud.
Incluye el decorador en el parámetro tableID. Por ejemplo, puedes transmitir a la partición correspondiente al 2025-06-01 para la tabla table1 con el decorador de partición table1$20250601.
Cuando transmites con un decorador de partición, puedes transmitir a particiones desde 31 días en el pasado hasta 16 días en el futuro. Para escribir en particiones para fechas fuera de estos límites, usa un trabajo de carga o de consulta, como se describe en Escribe datos en una partición específica.
La transmisión con un decorador de particiones solo se admite para tablas particionadas por día con transmisiones predeterminadas, no para tablas particionadas por hora, mes o año, ni para transmisiones creadas por la aplicación.
Partición de columnas por unidad de tiempo
Cuando transmites datos a una tabla particionada por columna de unidad de tiempo, BigQuery coloca automáticamente los datos en la partición correcta según los valores de la columna de partición DATE, DATETIME o TIMESTAMP predefinida de la tabla. Puedes transmitir datos a una tabla particionada por columna de unidad de tiempo si los datos a los que hace referencia la columna de partición se encuentran entre 10 años en el pasado y 1 año en el futuro.
Partición por rangos de números enteros
Cuando transmites datos a una tabla particionada por rango de números enteros, BigQuery coloca automáticamente los datos en la partición correcta según los valores de la columna de partición INTEGER predefinida de la tabla.
Complemento de salida de la API de Fluent Bit Storage Write
El complemento de salida de la API de Fluent Bit Storage Write automatiza el proceso de transferencia de registros JSON a BigQuery, lo que elimina la necesidad de que escribas código. Con este complemento, solo necesitas configurar un complemento de entrada compatible y configurar un archivo de configuración para comenzar a transmitir datos. Fluent Bit es un procesador y servidor de reenvío de registros de código abierto y multiplataforma que usa complementos de entrada y salida para controlar diferentes tipos de fuentes y receptores de datos.
Este complemento admite lo siguiente:
- Semántica de al menos una vez con el tipo predeterminado.
- Semántica de “exactamente una vez” con el tipo de confirmación.
- Ajuste de escala dinámico para transmisiones predeterminadas cuando se indica contrapresión.
Métricas del proyecto de la API de Storage Write
Para que las métricas supervisen la transferencia de datos con la API de Storage Write, usa la vista INFORMATION_SCHEMA.WRITE_API_TIMELINE o consulta las métricas deGoogle Cloud .
Usa el lenguaje de manipulación de datos (DML) con datos transmitidos de forma reciente
Puedes usar el lenguaje de manipulación de datos (DML), como las declaraciones UPDATE, DELETE o MERGE, para modificar las filas que la API de Storage Write de BigQuery escribió de forma reciente en una tabla de BigQuery. Las operaciones de escritura recientes son aquellas que ocurrieron en los últimos 30 minutos.
Si deseas obtener más información sobre el uso de DML para modificar tus datos transmitidos, consulta Usa el lenguaje de manipulación de datos.
Limitaciones
- La compatibilidad para ejecutar declaraciones DML mutables en datos transmitidos recientemente no se extiende a los datos transmitidos a través de la API de transmisión de insertAll.
- No se admite la ejecución de declaraciones DML mutables dentro de una transacción de varias declaraciones en datos transmitidos de forma reciente.
Cuotas de la API de Storage Write
Para obtener información sobre las cuotas y los límites de la API de Storage Write, consulta Cuotas y límites de la API de BigQuery Storage Write.
Puedes supervisar las conexiones simultáneas y el uso de cuotas de capacidad de procesamiento en la página Cuotas de la consola deGoogle Cloud .
Calcula la capacidad de procesamiento
Supongamos que tu objetivo es recopilar registros de 100 millones de extremos y crear un registro de 1,500 por minuto. Luego, puedes estimar la capacidad de procesamiento como 100 million * 1,500 / 60 seconds = 2.5 GB per second.
Debes asegurarte de antemano de tener una cuota adecuada para entregar esta capacidad de procesamiento.
Precios de la API de Storage Write
Para obtener información sobre los precios, consulta Precios de transferencia de datos.
Ejemplo de caso de uso
Supongamos que hay una canalización que procesa datos de eventos de registros de extremos. Los eventos se generan de forma continua y deben estar disponibles para realizar consultas en BigQuery lo antes posible. Dado que la actualidad de los datos es fundamental para este caso de uso, la API de Storage Write es la mejor opción para transferir datos a BigQuery. Una arquitectura recomendada para mantener estos extremos eficientes es enviar eventos a Pub/Sub, desde donde los consume una canalización de Dataflow de transmisión que se transmite de forma directa a BigQuery.
Una preocupación principal de confiabilidad de esta arquitectura es cómo lidiar con el fallo de insertar un registro en BigQuery. Si cada registro es importante y no se puede perder, los datos se deben almacenar en búfer antes de intentar insertarlos. En la arquitectura recomendada anterior, Pub/Sub puede desempeñar la función de un búfer con sus capacidades de retención de mensajes. La canalización de Dataflow debe estar configurada para reintentar las inserciones de transmisión de BigQuery con una retirada exponencial truncada. Después de que se agota la capacidad de Pub/Sub como un búfer, por ejemplo, en el caso de una falta de disponibilidad prolongada de BigQuery o de una falla de la red, los datos se deben conservar en el cliente y el cliente necesita un mecanismo para reanudar la inserción de registros persistentes una vez que se restablece la disponibilidad. Para obtener más información sobre cómo manejar esta situación, consulta la entrada de blog de la Guía de confiabilidad de Google Pub/Sub.
Otro caso de falla que se debe controlar es el de un registro tóxico. Un registro tóxico es un registro que BigQuery rechazó porque no se puede insertar con un error que no se puede reintentar o un registro que no se insertó de forma correcta después de la cantidad máxima de reintentos. Ambos tipos de registros se deben almacenar en una “cola de mensajes no entregados” a través de la canalización de Dataflow para una investigación más detallada.
Si se requiere una semántica de una y solo una vez, crea una transmisión de escritura en tipo confirmado, con compensaciones de registros proporcionadas por el cliente. Esto evita los duplicados, ya que la operación de escritura solo se realiza si el valor de desplazamiento coincide con el desplazamiento de anexo siguiente. Si no se proporciona un desplazamiento, se agregan los registros al extremo actual de la transmisión y, si se reintenta una operación fallida, es posible que el registro aparezca más de una vez en la transmisión.
Si no se requieren garantías de una sola vez, escribir en la transmisión predeterminada permite una capacidad de procesamiento mayor y no se considera en el límite de cuota sobre la creación de transmisiones de escritura.
Estima la capacidad de procesamiento de tu red y asegúrate con anticipación de que tengas una cuota adecuada para entregar la capacidad de procesamiento.
Si tu carga de trabajo genera o procesa datos a una tasa muy desigual, intenta disminuir los picos de carga en el cliente y transmitir a BigQuery con una capacidad de procesamiento constante. Esto puede simplificar la planificación de capacidad. Si eso no es posible, asegúrate de estar preparado para controlar errores 429 (recursos agotados) en caso de que tu capacidad de procesamiento supere la cuota durante aumentos repentinos cortos.
Para ver un ejemplo detallado de cómo usar la API de Storage Write, consulta Transmite datos con la API de Storage Write.
¿Qué sigue?
- Transmite datos con la API de Storage Write
- Carga datos por lotes con la API de Storage Write
- Tipos de datos de Arrow y búfer de protocolo admitidos
- Prácticas recomendadas para la API de Storage Write