Introdução à API BigQuery Storage Write
A API BigQuery Storage Write é uma API de ingestão de dados unificada para o BigQuery. Ele combina ingestão de streaming e carregamento em lote em uma única API de alto desempenho. É possível usar a API StorageWrite para fazer streaming de registros para o BigQuery em tempo real ou para processar em lote um número arbitrariamente grande de registros e confirmá-los em uma única operação atômica.
Vantagens de usar a API Storage Write
Semântica de envio exatamente uma vez. A API Storage Write é compatível com semântica de exatamente uma vez por meio de deslocamentos de stream. Diferentemente do método tabledata.insertAll, a API Storage Write nunca grava duas mensagens que têm o mesmo deslocamento em um stream, se o cliente fornecer deslocamentos de stream ao anexar registros.
Transações no nível do stream. É possível gravar dados em um stream e confirmar os dados como uma única transação. Se a operação de confirmação falhar, será possível repetir a operação com segurança.
Transações em vários streams. Vários workers podem criar os próprios streams para processar dados de maneira independente. Quando todos os workers forem concluídos, será possível confirmar todos os streams como uma transação.
Protocolo eficiente. A API Storage Write é mais eficiente do que o método insertAll legado porque usa streaming de gRPC em vez de REST sobre HTTP. A API Storage Write também é compatível com o formato binário buffer de protocolo e o formato colunar Apache Arrow, que são formatos eletrônicos mais eficientes que o JSON. As solicitações de gravação são assíncronas com ordenação garantida.
Detecção de atualização de esquema. Se o esquema da tabela subjacente mudar enquanto o cliente estiver fazendo streaming, a Storage Write API notificará o cliente. O cliente pode decidir se quer se reconectar usando o esquema atualizado ou continuar gravando na conexão atual.
Menor custo. A API Storage Write tem um custo significativamente menor
que a API de streaming insertAll mais antiga. Além disso, é possível ingerir
até 2 TiB por mês gratuitamente.
Permissões necessárias
Para usar a API Storage Write, você precisa ter permissões bigquery.tables.updateData.
Os papéis predefinidos de gerenciamento de identidade e acesso (IAM, na sigla em inglês) incluem permissões bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
Para mais informações sobre os papéis e as permissões do IAM no BigQuery, consulte Papéis e permissões predefinidos.
Escopos de autenticação
O uso da API Storage Write requer um dos seguintes escopos do OAuth:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
Para saber mais, consulte a Visão geral da autenticação.
Visão geral da API Storage Write
A abstração principal na API Storage Write é um stream. Um stream grava dados em uma tabela do BigQuery. Mais de um fluxo pode gravar simultaneamente na mesma tabela.
Stream padrão
A API StorageWrite fornece um stream padrão projetado para cenários em que você recebe dados continuamente. Ela tem as seguintes características:
- Os dados gravados no stream padrão são disponibilizados imediatamente para consulta.
- O stream padrão é compatível com a semântica do tipo "pelo menos uma vez".
- Não é necessário criar o stream padrão explicitamente.
Se você estiver migrando da API
tabledata.insertall legada, considere
usar o fluxo padrão. Ele tem uma semântica de gravação semelhante, com maior resiliência de dados e menos restrições de escalonamento.
Fluxo da API:
AppendRows(loop)
Para mais informações e código de exemplo, consulte Usar o fluxo padrão para semântica de pelo menos uma vez.
Fluxos criados pelo aplicativo
Você poderá criar um stream explicitamente se precisar de um dos seguintes comportamentos:
- Exatamente uma vez a gravação por meio do uso de deslocamentos de stream.
- Compatibilidade com outras propriedades ACID.
Em geral, os streams criados pelo aplicativo oferecem mais controle sobre a funcionalidade, à custa de mais complexidade.
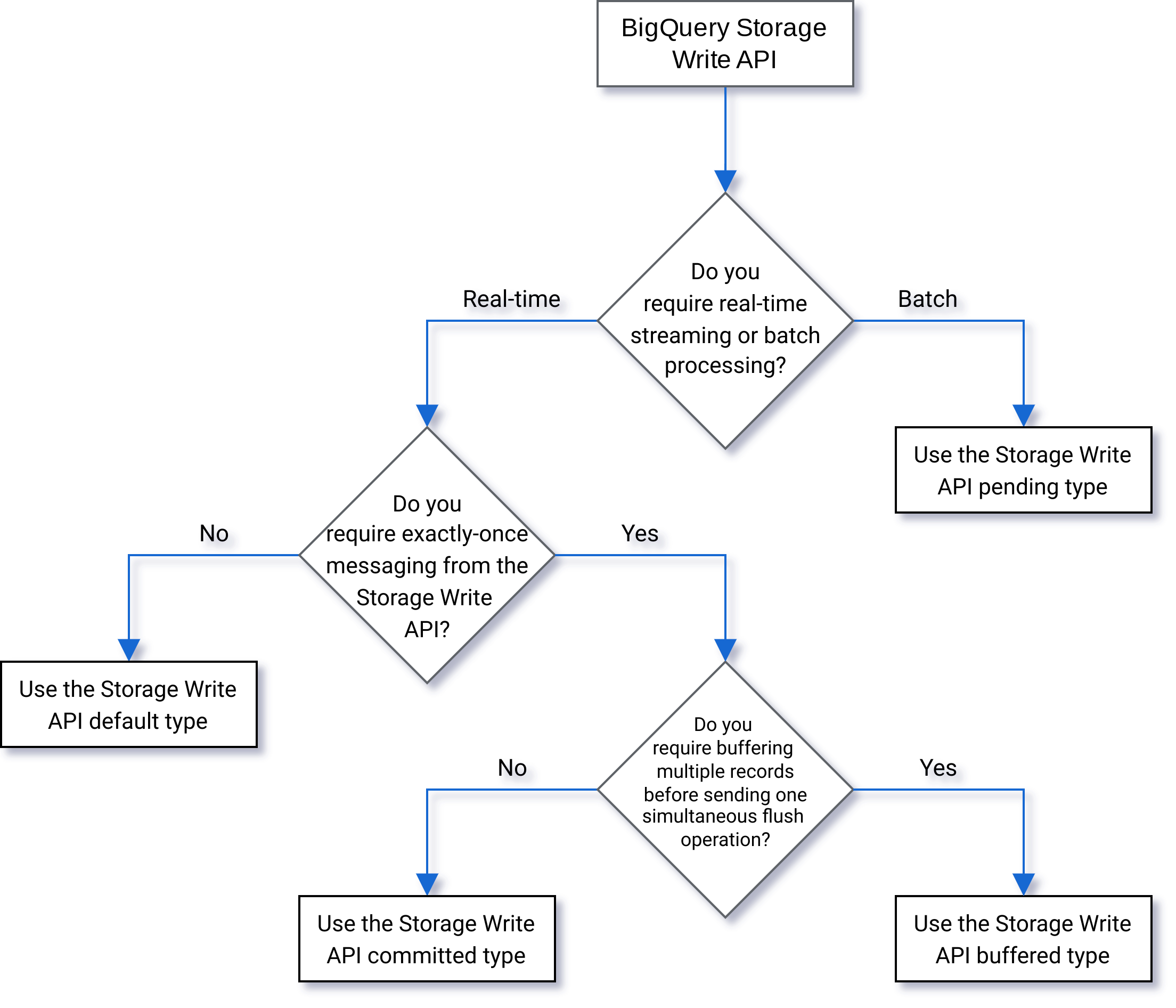
Ao criar um stream, especifique um tipo. O tipo controla quando os dados gravados no stream ficam visíveis no BigQuery para leitura.
Tipo pendente
No tipo pendente, os registros são armazenados em buffer em estado pendente até que você confirme o stream. Quando você confirma um stream, todos os dados pendentes ficam disponíveis para leitura. A confirmação é uma operação atômica. Use esse tipo para cargas de trabalho em lote, como uma alternativa para jobs de carregamento do BigQuery. Para mais informações, consulte Carregar dados em lote usando a API StorageWrite.
Fluxo da API:
Tipo de compromisso
No tipo de compromisso, os registros ficam disponíveis para leitura imediatamente conforme você os grava no stream. Use esse tipo para cargas de trabalho de streaming que precisam de latência de leitura mínima. O stream padrão usa uma forma pelo menos uma vez do tipo confirmado. Para mais informações, consulte Usar o tipo confirmado para a semântica exatamente uma vez.
Fluxo da API:
CreateWriteStreamAppendRows(loop)FinalizeWriteStream(opcional)
Tipo armazenado em buffer
O tipo armazenado em buffer é um tipo avançado que no geral não é usado, exceto com o conector de E/S do BigQuery para o Apache Beam. Se você quiser garantir que os lotes pequenos sejam exibidos juntos, use o tipo confirmado e envie cada um deles em uma solicitação. Nesse tipo, as confirmações no nível da linha são fornecidas e os registros são armazenados em buffer até que as linhas sejam confirmadas pela transferência do stream.
Fluxo da API:
CreateWriteStreamAppendRows⇒FlushRows(loop)FinalizeWriteStream(opcional)
Selecionar um tipo
Use o fluxograma a seguir para ajudar a decidir qual é o melhor tipo para sua carga de trabalho:
Detalhes da API
Considere o seguinte ao usar a API Storage Write:
AppendRows
O método AppendRows anexa um ou mais registros ao stream. A primeira
chamada para AppendRows precisa conter um nome de stream com o esquema de dados,
especificado como DescriptorProto. Como alternativa, adicione um esquema de seta serializado na primeira chamada para AppendRows se você estiver ingerindo dados no formato Apache Arrow. Como prática recomendada, envie um lote de linhas em cada chamada de AppendRows. Não envie uma linha por vez.
Tratamento do buffer de proto
Os buffers de protocolo fornecem um mecanismo extensível que é neutro em relação à linguagem e à plataforma, para serializar dados estruturados de maneira compatível com versões futuras e anteriores. Eles são vantajosos porque oferecem armazenamento de dados compacto com análise rápida e eficiente. Para saber mais sobre buffers de protocolo, consulte Visão geral do buffer de protocolo.
Se você consumir a API diretamente com uma mensagem de buffer de protocolo
predefinida, essa mensagem não poderá usar um especificador package e todos
os tipos aninhados ou de enumeração precisarão ser definidos na mensagem raiz de nível superior.
Referências a mensagens externas não são permitidas. Para ver um exemplo, consulte
sample_data.proto.
Os clientes Java e Go são compatíveis com buffers de protocolo arbitrários porque a biblioteca de cliente normaliza o esquema de buffer de protocolo.
Processamento do Apache Arrow
Para enviar feedback ou solicitar suporte para esse recurso, entre em contato com bq-write-api-feedback@google.com.
O Apache Arrow é um formato colunar universal e uma caixa de ferramentas multilíngue para processamento de dados. O Apache Arrow oferece um formato de memória independente de linguagem e orientado a colunas para dados simples e hierárquicos, organizado para operações analíticas eficientes em hardware moderno. Para saber mais sobre o Apache Arrow, consulte Apache Arrow.
A API Storage Write oferece suporte à ingestão do Arrow usando o esquema e os dados serializados do Arrow na classe AppendRowsRequest.
A biblioteca de cliente do Python inclui suporte integrado para ingestão do Apache Arrow. Outras linguagens podem exigir a chamada da API AppendRows bruta para
ingerir dados no formato Apache Arrow.
FinalizeWriteStream
O método FinalizeWriteStream finaliza o fluxo para que nenhum novo dado possa ser anexado a ele. Esse método é obrigatório no tipo
Pending e opcional em
Committed e
Buffered. O stream padrão não é compatível com esse método.
Tratamento de erros
Se ocorrer um erro, o google.rpc.Status retornado poderá incluir um
StorageError nos
detalhes do erro. Consulte
StorageErrorCode para encontrar o tipo de erro específico. Para
mais informações sobre o modelo de erro da API do Google, consulte Erros.
Conexões
A API StorageWrite é uma API gRPC que usa conexões bidirecionais. O método AppendRows cria uma conexão com um stream. Você pode
abrir várias conexões no fluxo padrão. Esses anexos são assíncronos, o que permite enviar uma série de gravações simultaneamente. As mensagens
de resposta em cada conexão bidirecional chegam na mesma ordem que as
solicitações foram enviadas.
Os streams criados pelo aplicativo podem ter apenas uma conexão ativa. Como prática recomendada, limite o número de conexões ativas e use uma conexão para o maior número possível de gravações de dados. Ao usar o stream padrão em Java ou Go, é possível usar a multiplexação da API Storage Write para gravar em várias tabelas de destino com conexões compartilhadas.
Geralmente, uma única conexão é compatível com pelo menos 1 MBps de capacidade de processamento. O limite superior depende de vários fatores, como largura de banda da rede, esquema dos dados e carga do servidor. Quando uma conexão atinge o limite de capacidade de processamento, as solicitações recebidas podem ser rejeitadas ou colocadas em fila até que o número de solicitações em trânsito diminua. Se você precisar de mais capacidade de processamento, crie mais conexões.
O BigQuery fechará a conexão gRPC se ela permanecer
inativa por muito tempo. Se isso acontecer, o código de resposta será HTTP 409. A conexão
gRPC também pode ser fechada no caso de uma reinicialização do servidor ou por outros
motivos. Se ocorrer um erro de conexão, crie uma nova conexão. As bibliotecas de cliente Java e Go serão reconectadas automaticamente se a conexão for encerrada.
Suporte à biblioteca de cliente
Há bibliotecas de cliente para a API Storage Write em várias linguagens de programação e expõe as construções da API baseadas em gRPC. Essa API aproveita recursos avançados, como streaming bidirecional, que podem exigir mais trabalho de desenvolvimento para ser compatível. Para isso, várias abstrações de nível superior estão disponíveis para essa API, o que simplifica essas interações e reduz as preocupações do desenvolvedor. Recomendamos usar essas outras abstrações de biblioteca sempre que possível.
Esta seção fornece mais detalhes sobre linguagens e bibliotecas em que outros recursos além da API gerada foram fornecidos aos desenvolvedores.
Para conferir exemplos de código relacionados à API Storage Write, acesse Todas as amostras de código do BigQuery.
Cliente Java
A biblioteca de cliente fornece dois objetos de gravação:
StreamWriter: aceita dados no formato de buffer de protocolo.JsonStreamWriter: aceita dados no formato JSON e os converte em buffers de protocolo antes de enviá-los pela rede. OJsonStreamWritertambém é compatível com atualizações automáticas de esquema. Se o esquema da tabela mudar, a gravação será reconectada automaticamente com o novo esquema, permitindo que o cliente envie dados usando o novo esquema.
O modelo de programação é semelhante para os dois escritores. A principal diferença é como você formata o payload.
O objeto gravador gerencia uma conexão da API StorageWrite. O objeto de gravação limpa automaticamente as solicitações, adiciona os cabeçalhos de roteamento regionais às solicitações e se reconecta após os erros de conexão. Caso você use a API gRPC diretamente, será necessário processar esses detalhes.
Cliente Go
O cliente Go usa uma arquitetura de cliente-servidor para codificar mensagens no formato de buffer de protocolo usando proto2. Consulte a documentação do Go para conferir detalhes sobre como usar o cliente Go com um exemplo de código.
Cliente Python
O cliente Python é um cliente de nível inferior que encapsula a API gRPC. Para usar isso, envie os dados como buffers de protocolo, seguindo o fluxo da API para o tipo especificado.
Evite usar a geração dinâmica de mensagens proto em Python, porque o desempenho dessa biblioteca é abaixo do padrão.
Para saber mais sobre o uso de buffers de protocolo com o Python, leia as Noções básicas do buffer de protocolo no Python.
Também é possível usar o formato de ingestão do Apache Arrow como um protocolo alternativo para ingerir dados usando a API Storage Write. Para mais informações, consulte Usar o formato Apache Arrow para ingerir dados.
Cliente Node.js
A biblioteca de cliente NodeJS aceita entrada JSON e oferece suporte para reconexão automática. Consulte a documentação para ver detalhes sobre como usar o cliente.
Gerenciar indisponibilidade
Tentar novamente com espera exponencial pode reduzir erros aleatórios e breves períodos de indisponibilidade do serviço, mas evitar a queda de linhas durante uma indisponibilidade prolongada requer mais atenção. Em especial, se um cliente não conseguir inserir uma linha de jeito nenhum, o que deverá fazer?
A resposta depende dos requisitos. Por exemplo, se o BigQuery estiver sendo usado para análises operacionais em que algumas linhas ausentes são aceitáveis, o cliente poderá desistir após algumas tentativas e descartar os dados. Se, por outro lado, todas as linhas forem essenciais para a empresa, como no caso de dados financeiros, será necessário ter uma estratégia para manter os dados até que possam ser inseridos mais tarde.
Uma forma comum de lidar com erros persistentes é publicar as linhas em um tópico do Pub/Sub para avaliação posterior e possível inserção. Outro método comum é a permanência temporária dos dados no cliente. Os dois métodos podem manter os clientes desbloqueados e, ao mesmo tempo, garantir que todas as linhas sejam inseridas quando a disponibilidade for restaurada.
Fazer streaming para tabelas particionadas
A API Storage Write é compatível com streaming de dados para tabelas particionadas.
Quando os dados são transmitidos, eles são inicialmente colocados na partição
__UNPARTITIONED__. Depois que forem coletados dados não particionados suficientes, o BigQuery reparticionará os dados, colocando-os na partição apropriada.
No entanto, não há contrato de nível de serviço (SLA, na sigla em inglês) que define quanto tempo leva
para que esses dados sejam removidos da partição __UNPARTITIONED__.
Para tabelas particionadas por tempo de ingestão e particionadas por coluna de unidade de tempo, os dados não particionados podem ser excluídos de uma consulta filtrando os valores NULL da partição __UNPARTITIONED__ usando uma das pseudocolunas (_PARTITIONTIME ou _PARTITIONDATE, dependendo do tipo de dados preferido).
Particionamento por tempo de processamento
Ao fazer streaming para uma tabela particionada por tempo de ingestão, a API Storage Write infere a partição de destino com base na hora UTC atual do sistema.
Se estiver fazendo streaming de dados para uma tabela particionada diária, é possível substituir
a inferência de data fornecendo um decorador de partição como parte da solicitação.
Inclua o decorador no parâmetro tableID. Por exemplo, é possível fazer o streaming para
a partição correspondente a 01-06-2025 para a tabela table1 usando o
decorador de partição table1$20250601.
Ao fazer streaming com um decorador de partição, é possível fazer isso para partições de 31 dias atrás até 16 dias no futuro. Para gravar em partições de datas fora desses limites, use um job de carregamento ou de consulta, como descrito em Gravar dados em uma partição específica.
O streaming usando um decorador de partição só é compatível com tabelas particionadas por dia com streams padrão, não com tabelas particionadas por hora, mês ou ano, nem com streams criados por aplicativos.
Particionamento de colunas por unidade de tempo
Ao transmitir para uma tabela particionada por coluna de unidade de tempo, o BigQuery coloca automaticamente os dados na partição correta com base nos valores da coluna de particionamento DATE, DATETIME ou TIMESTAMP predefinida da tabela. É possível fazer streaming de dados em uma tabela particionada por coluna de unidade de tempo se os dados referenciados pela coluna de particionamento estiverem entre 10 anos no passado e 1 ano no futuro.
Particionamento por intervalo de números inteiros
Quando você faz streaming para uma tabela particionada por intervalo de números inteiros, o BigQuery coloca automaticamente os dados na partição correta com base nos valores da coluna de particionamento INTEGER predefinida da tabela.
Plug-in de saída da API Fluent Bit Storage Write
O plug-in de saída da API Fluent Bit Storage Write automatiza o processo de ingestão de registros JSON no BigQuery, eliminando a necessidade de escrever código. Com esse plug-in, você só precisa configurar um plug-in de entrada compatível e um arquivo de configuração para começar a transmitir dados. O Fluent Bit é um processador de registro de código aberto e encaminhador multiplataforma que usa plug-ins de entrada e saída para processar diferentes tipos de origens e coletores de dados.
Esse plug-in oferece suporte para:
- Semântica pelo menos uma vez usando o tipo padrão.
- Semântica "exatamente uma vez" usando o tipo confirmado.
- Escalonamento dinâmico para streams padrão, quando a pressão de retorno é indicada.
Métricas do projeto da API Storage Write
Para métricas que monitoram a ingestão de dados com a
API Storage Write, use a
visualização INFORMATION_SCHEMA.WRITE_API_TIMELINE
ou consulte as
métricasGoogle Cloud .
Usar linguagem de manipulação de dados (DML) com dados transmitidos recentemente
Use a linguagem de manipulação de dados (DML), como as instruções UPDATE, DELETE ou MERGE, para modificar as linhas que foram gravadas recentemente em uma tabela do BigQuery API Storage Write. Gravações recentes são aquelas que ocorreram
nos últimos 30 minutos.
Para mais informações sobre como usar a DML para modificar os dados transmitidos, consulte Como usar a linguagem de manipulação de dados.
Limitações
- O suporte à execução de instruções DML mutantes em dados transmitidos recentemente não se estende aos dados transmitidos usando a API insertAll streaming.
- A execução da mutação de instruções DML em uma transação de várias instruções em relação a dados transmitidos recentemente não é compatível.
Cotas da API Storage Write
Para informações sobre as cotas e os limites da API Storage Write, consulte esta página.
É possível monitorar suas conexões simultâneas e o uso da cota de capacidade na página de Cotas do console doGoogle Cloud .
Calcular a capacidade de processamento
Suponha que sua meta seja coletar registros de 100 milhões de endpoints,
criando um registro de 1.500 por minuto. Em seguida, estime a capacidade como
100 million * 1,500 / 60 seconds = 2.5 GB per second.
Você precisa garantir com antecedência que tem uma cota adequada para disponibilizar essa capacidade de processamento.
Preços da API Storage Write
Para preços, consulte Preços de ingestão de dados.
Exemplo de caso de uso:
Suponha que haja um pipeline processando dados de eventos de registros de endpoint. Os eventos são gerados continuamente e precisam estar disponíveis para consulta no BigQuery o mais rápido possível. Como a atualização de dados é fundamental para esse caso de uso, a API Storage Write é a melhor opção para ingerir dados no BigQuery. Uma arquitetura recomendada para manter esses endpoints enxutos é o envio de eventos para o Pub/Sub, de onde são consumidos por um pipeline de streaming do Dataflow que faz streaming diretamente para o BigQuery.
Uma das principais preocupações de confiabilidade dessa arquitetura é como lidar com uma falha ao inserir um registro no BigQuery. Se cada registro for importante e não puder ser perdido, os dados precisarão ser armazenados em buffer antes de tentar inserir. Na arquitetura recomendada acima, o Pub/Sub pode desempenhar o papel de buffer com recursos de retenção de mensagens. O pipeline do Dataflow precisa ser configurado para repetir inserções de streaming do BigQuery com espera exponencial truncada. Depois que a capacidade do Pub/Sub como buffer se esgotar, como no caso de indisponibilidade prolongada do BigQuery ou uma falha na rede, os dados precisarão ser mantidos no cliente, que vai precisar de um mecanismo para retomar a inserção de registros persistentes depois que a disponibilidade for restaurada. Saiba mais sobre como lidar com essa situação na postagem do blog Guia de confiabilidade do Google Pub/Sub.
Outro caso de falha a ser resolvido é o de um registro contaminado. Um registro contaminado é um registro rejeitado pelo BigQuery por ter falhado na inserção com um erro não repetível ou um registro que não foi inserido com sucesso após o número máximo de novas tentativas. Os dois tipos de registro precisam ser armazenados em uma "fila de mensagens inativas" pelo pipeline do Dataflow para uma investigação mais detalhada.
Se uma semântica for necessária exatamente uma vez, crie um fluxo de gravação em tipo confirmado, com deslocamentos de registro fornecidos pelo cliente. Isso evita duplicações, já que a operação de gravação só será realizada se o valor de deslocamento corresponder ao próximo deslocamento de anexo. Não fornecer um deslocamento significa que os registros são anexados à atual ponta do stream e repetir um anexo com falha pode fazer com que o registro apareça mais de uma vez no stream.
Se as garantias de "exatamente uma vez" não forem necessárias, grave no stream padrão. Isso permitirá maior capacidade e não será contabilizado no limite de cota na criação de streams de gravação.
Estime a capacidade da sua rede e verifique antecipadamente se você tem uma cota adequada para disponibilizar essa capacidade.
Se a carga de trabalho estiver gerando ou processando dados a uma taxa muito desigual,
tente suavizar os picos de carga no cliente e fazer streaming no
BigQuery com uma capacidade constante. Isso pode simplificar o
planejamento da capacidade. Se isso não for possível, prepare-se para lidar com
erros do tipo 429 (recurso esgotado) se e quando sua capacidade exceder a cota
durante picos curtos.
Para um exemplo detalhado de como usar a API Storage Write, consulte Transmitir dados usando a API Storage Write.
A seguir
- Transmitir dados usando a API StorageWrite
- Carregar dados em lote usando a API StorageWrite
- Tipos de dados de buffer de protocolo e Arrow compatíveis
- Práticas recomendadas da API Storage Write