处理时序数据
本文档介绍了如何使用 SQL 函数来支持时序分析。
简介
时序是一系列数据点,每个数据点都包含时间以及与该时间关联的值。通常,时序还会有一个标识符,用于对该时序进行唯一命名。
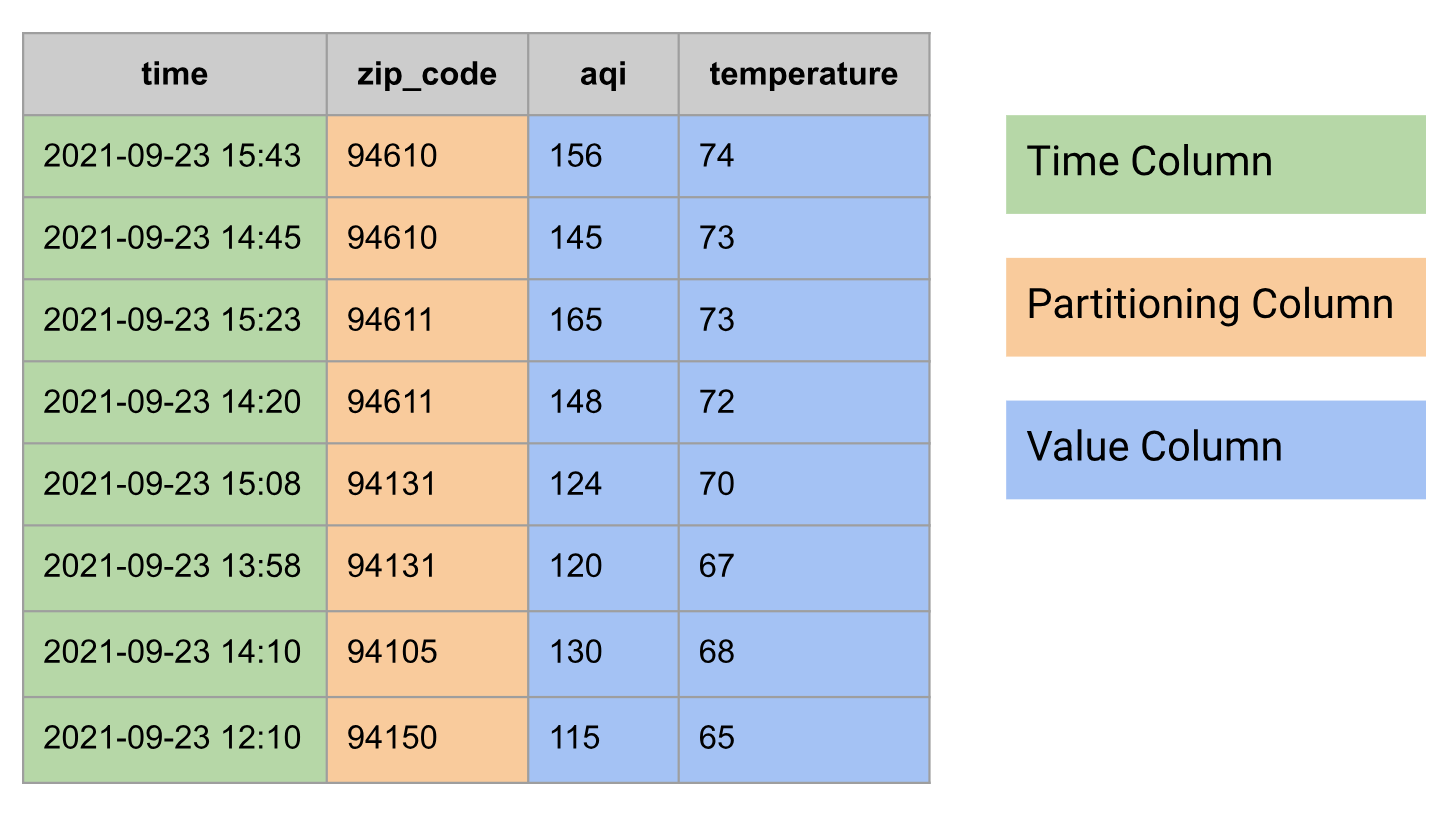
在关系型数据库中,时序会建模为包含以下列组的表:
- 时间列
- 可能包含分区列,例如邮政编码
- 一个或多个值列,或组合多个值的
STRUCT类型,例如温度和 AQI
以下示例展示了建模为表的时序数据:
聚合时序
在时序分析中,时间聚合是沿时间轴执行的聚合。
您可以使用时间分桶函数(TIMESTAMP_BUCKET、DATE_BUCKET、DATETIME_BUCKET)在 BigQuery 中执行时间聚合。时间分桶函数将输入时间值映射到它们所属的存储桶。
通常,执行时间聚合是为了使用 AVG、MIN、MAX、COUNT 或 SUM 等聚合函数将某个时间范围内的多个数据点合并为单个数据点。例如,15 分钟的平均请求延迟时间、每日最低和最高温度,以及每日出租车行程数。
对于本部分中的查询,请创建一个名为 mydataset.environmental_data_hourly 的表:
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 12:32:38', 38, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 13:29:59', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 14:31:22', 43, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 15:31:38', 42, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 15:09:19', 150, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 16:06:39', 151, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 17:08:01', 155, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 18:09:23', 154, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
关于上述数据,可以观察到一个有趣的结果:测量是在任意时间段进行的,这称为“未校准时序”。聚合是校准时序的方式之一。
获取 3 小时的平均值
以下查询会计算每个邮政编码的 3 小时平均空气质量指数 (AQI) 和温度。TIMESTAMP_BUCKET 函数通过将每个时间值分配给特定日期来执行时间聚合。
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 40 | 57 |
| 2020-09-08 15:00:00 | 60606 | 42 | 65 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 152 | 62 |
| 2020-09-08 18:00:00 | 94105 | 152 | 67 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
获取 3 小时的最小值和最大值
在以下查询中,您将计算每个邮政编码的 3 小时最低和最高温度:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----------------+-----------------+
| time | zip_code | temperature_min | temperature_max |
+---------------------+----------+-----------------+-----------------+
| 2020-09-08 00:00:00 | 60606 | 60 | 66 |
| 2020-09-08 03:00:00 | 60606 | 57 | 59 |
| 2020-09-08 06:00:00 | 60606 | 55 | 56 |
| 2020-09-08 09:00:00 | 60606 | 55 | 56 |
| 2020-09-08 12:00:00 | 60606 | 56 | 59 |
| 2020-09-08 15:00:00 | 60606 | 63 | 68 |
| 2020-09-08 18:00:00 | 60606 | 67 | 69 |
| 2020-09-08 21:00:00 | 60606 | 63 | 67 |
| 2020-09-08 00:00:00 | 94105 | 71 | 74 |
| 2020-09-08 03:00:00 | 94105 | 66 | 69 |
| 2020-09-08 06:00:00 | 94105 | 64 | 65 |
| 2020-09-08 09:00:00 | 94105 | 62 | 63 |
| 2020-09-08 12:00:00 | 94105 | 61 | 62 |
| 2020-09-08 15:00:00 | 94105 | 62 | 63 |
| 2020-09-08 18:00:00 | 94105 | 64 | 69 |
| 2020-09-08 21:00:00 | 94105 | 72 | 76 |
+---------------------+----------+-----------------+-----------------*/
通过自定义校准获取 3 小时的平均值
执行时序聚合时,您可以隐式或显式地对时序窗口使用特定校准。上述查询使用了隐式校准,它生成了从 00:00:00、03:00:00 和 06:00:00 等时间开始的存储桶。如需在 TIMESTAMP_BUCKET 函数中明确设置这种校准方式,请传递一个指定起点的可选参数。
在以下查询中,起点设置为 2020-01-01 02:00:00。此操作会更改校准,并生成从 02:00:00、05:00:00 和 08:00:00 等时间开始的存储桶:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR, TIMESTAMP '2020-01-01 02:00:00') AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-07 23:00:00 | 60606 | 23 | 65 |
| 2020-09-08 02:00:00 | 60606 | 21 | 59 |
| 2020-09-08 05:00:00 | 60606 | 24 | 56 |
| 2020-09-08 08:00:00 | 60606 | 33 | 55 |
| 2020-09-08 11:00:00 | 60606 | 38 | 56 |
| 2020-09-08 14:00:00 | 60606 | 43 | 62 |
| 2020-09-08 17:00:00 | 60606 | 37 | 68 |
| 2020-09-08 20:00:00 | 60606 | 27 | 66 |
| 2020-09-08 23:00:00 | 60606 | 22 | 63 |
| 2020-09-07 23:00:00 | 94105 | 61 | 74 |
| 2020-09-08 02:00:00 | 94105 | 67 | 69 |
| 2020-09-08 05:00:00 | 94105 | 72 | 65 |
| 2020-09-08 08:00:00 | 94105 | 90 | 63 |
| 2020-09-08 11:00:00 | 94105 | 120 | 62 |
| 2020-09-08 14:00:00 | 94105 | 143 | 62 |
| 2020-09-08 17:00:00 | 94105 | 153 | 65 |
| 2020-09-08 20:00:00 | 94105 | 147 | 72 |
| 2020-09-08 23:00:00 | 94105 | 137 | 75 |
+---------------------+----------+-----+-------------*/
通过空白填充来聚合时序
有时,在聚合时序后,数据可能存在空白,需要使用一些值进行填充,以便进一步分析或呈现数据。填充这些空白的技术称为“空白填充”。在 BigQuery 中,您可以使用 GAP_FILL 表函数通过提供的空白填充方法之一填充时序数据中的缺口:
- NULL(也称为常量)
- LOCF,末次观测值转结
- 线性,两个相邻数据点之间的线性插值
对于本部分中的查询,请创建一个名为 mydataset.environmental_data_hourly_with_gaps 的表,该表基于上一部分中使用的数据,但存在空白。在真实场景中,由于气象站发生短期故障,数据可能缺失数据点。
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly_with_gaps AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
-- No data points between hours 12 and 15.
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
-- No data points between hours 15 and 18.
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
获取 3 小时的平均值(包括空白)
以下查询会计算各邮政编码 3 小时的平均 AQI 和温度:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
请注意,输出在特定时间间隔内存在空白。例如,邮政编码 60606 的时序在 2020-09-08 12:00:00 没有数据点,邮政编码 94105 的时序在 2020-09-08 15:00:00 没有数据点。
获取 3 小时的平均值(填充空白)
使用上一部分中的查询,并添加 GAP_FILL 函数来填充空白:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code']
)
ORDER BY zip_code, time;
/*---------------------+----------+------+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+------+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | NULL | NULL |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | NULL | NULL |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+------+-------------*/
输出表目前在 2020-09-08 12:00:00(针对邮政编码 60606)和 2020-09-08 15:00:00(针对邮政编码 94105)包含一个缺失的行,对应指标列中的值为 NULL。由于您没有指定任何空白填充方法,因此 GAP_FILL 使用默认的空白填充方法 NULL。
使用线性和 LOCF 空白填充方法来填充空白
在以下查询中,GAP_FILL 函数与 LOCF 空白填充方法(针对 aqi 列)和线性插值(针对 temperature 列)结合使用:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code'],
value_columns => [
('aqi', 'locf'),
('temperature', 'linear')
]
)
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 36 | 62 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 125 | 65 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
在此查询中,第一个空白填充行的 aqi 值为 36,该值取自此时序(邮政编码 60606)的上一个数据点 2020-09-08 09:00:00。temperature 值 62 是数据点 2020-09-08 09:00:00 和 2020-09-08 15:00:00 之间的线性插值结果。另一个缺失的行是采用类似的方式创建的,即 aqi 值 125 沿用此时序(邮政编码 94105)的上一个数据点,并且温度值 65 是上一个和下一个可用数据点之间的线性插值结果。
通过空白填充来校准时序
时序可以校准,也可以未经校准。如果数据点仅以一定间隔时间出现,则校准时序。
在现实环境中,收集时序时很少校准,通常需要进一步处理才能校准。
例如,假设 IoT 设备以每分钟一次的频率将其指标发送到一个集中式收集器。期望设备在完全相同的时刻发送其指标是不合理的。通常,每台设备都以相同的频率(时间段)发送其指标,但时间偏移值(校准)不同。下图演示了此示例。您可以看到每台设备以一分钟的时间间隔发送其数据,其中存在一些数据缺失(设备 3 9:36:39)的数据延迟(设备 1 9:37:28)的情况。

您可以使用时间聚合对未校准的数据执行时序校准。如果您要更改时序的采样周期(例如从原来的 1 分钟采样周期更改为 15 分钟的采样周期),这会非常有用。您可以校准数据以进一步处理时序,例如联接时序数据或用于显示目的(例如绘制图表)。
您可以将 GAP_FILL 表函数与 LOCF 或线性空白填充方法结合使用,以执行时序校准。具体思路是将 GAP_FILL 与选定的输出时间段和校准方式(由可选起点参数控制)搭配使用。操作结果是具有校准时序的表,其中每个数据点的值都来自输入时序,并具有用于该特定值列的空白填充方法(LOCF 或线性)。
创建一个 mydataset.device_data 表,类似于上图:
CREATE OR REPLACE TABLE mydataset.device_data AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<device_id INT64, time TIMESTAMP, signal INT64, state STRING>>[
STRUCT(2, TIMESTAMP '2023-11-01 09:35:07', 87, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:35:26', 82, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:35:39', 74, 'INACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:36:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:36:26', 82, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:37:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:37:28', 80, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:37:39', 77, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:38:07', 86, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:38:26', 81, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:38:39', 77, 'ACTIVE')
]);
以下是按 time 和 device_id 列排序的实际数据:
SELECT * FROM mydataset.device_data ORDER BY time, device_id;
/*-----------+---------------------+--------+----------+
| device_id | time | signal | state |
+-----------+---------------------+--------+----------+
| 2 | 2023-11-01 09:35:07 | 87 | ACTIVE |
| 1 | 2023-11-01 09:35:26 | 82 | ACTIVE |
| 3 | 2023-11-01 09:35:39 | 74 | INACTIVE |
| 2 | 2023-11-01 09:36:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:36:26 | 82 | ACTIVE |
| 2 | 2023-11-01 09:37:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:37:28 | 80 | ACTIVE |
| 3 | 2023-11-01 09:37:39 | 77 | ACTIVE |
| 2 | 2023-11-01 09:38:07 | 86 | ACTIVE |
| 1 | 2023-11-01 09:38:26 | 81 | ACTIVE |
| 3 | 2023-11-01 09:38:39 | 77 | ACTIVE |
+-----------+---------------------+--------+----------*/
该表包含每台设备的时序,并包含两个指标列:
signal- 在采样时设备观察到的信号电平,以0到100之间的整数值表示。state- 采样时设备的状态,以自由格式的字符串表示。
在以下查询中,GAP_FILL 函数用于以 1 分钟为间隔校准时序。请注意,线性插值用于计算 signal 列的值,LOCF 用于计算 state 列的值。对于此示例数据,线性插值适合用于计算输出值。
SELECT *
FROM GAP_FILL(
TABLE mydataset.device_data,
ts_column => 'time',
bucket_width => INTERVAL 1 MINUTE,
partitioning_columns => ['device_id'],
value_columns => [
('signal', 'linear'),
('state', 'locf')
]
)
ORDER BY time, device_id;
/*---------------------+-----------+--------+----------+
| time | device_id | signal | state |
+---------------------+-----------+--------+----------+
| 2023-11-01 09:36:00 | 1 | 82 | ACTIVE |
| 2023-11-01 09:36:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:36:00 | 3 | 75 | INACTIVE |
| 2023-11-01 09:37:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:37:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:37:00 | 3 | 76 | INACTIVE |
| 2023-11-01 09:38:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:38:00 | 2 | 86 | ACTIVE |
| 2023-11-01 09:38:00 | 3 | 77 | ACTIVE |
+---------------------+-----------+--------+----------*/
输出表包含每个设备和值列(signal 和 state)的校准时序,时序是使用函数调用中指定的空白填充方法计算得出的。
联接时序数据
您可以使用窗口联接或 AS OF 联接来联接时序数据。
窗口联接
有时,您需要将两个或更多表与时序数据联接。请考虑以下两个表:
mydataset.sensor_temperatures,它包含每个传感器每 15 秒报告一次的温度数据。mydataset.sensor_fuel_rates,它包含每个传感器每 15 秒测量一次的燃料消耗率。
若要创建这些表,请运行以下查询:
CREATE OR REPLACE TABLE mydataset.sensor_temperatures AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, temp FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:00.063', 37.1),
(1, TIMESTAMP '2020-01-01 12:00:15.024', 37.2),
(1, TIMESTAMP '2020-01-01 12:00:30.032', 37.3),
(2, TIMESTAMP '2020-01-01 12:00:01.001', 38.1),
(2, TIMESTAMP '2020-01-01 12:00:15.082', 38.2),
(2, TIMESTAMP '2020-01-01 12:00:31.009', 38.3)
]);
CREATE OR REPLACE TABLE mydataset.sensor_fuel_rates AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, rate FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:11.016', 10.1),
(1, TIMESTAMP '2020-01-01 12:00:26.015', 10.2),
(1, TIMESTAMP '2020-01-01 12:00:41.014', 10.3),
(2, TIMESTAMP '2020-01-01 12:00:08.099', 11.1),
(2, TIMESTAMP '2020-01-01 12:00:23.087', 11.2),
(2, TIMESTAMP '2020-01-01 12:00:38.077', 11.3)
]);
以下是表中的实际数据:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 |
+-----------+---------------------+------*/
SELECT * FROM mydataset.sensor_fuel_rates ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | rate |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------*/
如需检查每个传感器报告的温度下的燃料消耗率,您可以联接两个时序。
虽然两个时序中的数据未经校准,但采样间隔相同(15 秒),因此此类数据非常适合进行窗口联接。使用时间分桶函数来校准用作联接键的时间戳。
以下查询说明了如何使用 TIMESTAMP_BUCKET 函数将每个时间戳分配给时长为 15 秒的时段:
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_temperatures
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | temp | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_fuel_rates
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | rate | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:11 | 10.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:26 | 10.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:41 | 10.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:08 | 11.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:23 | 11.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:38 | 11.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
您可以使用此概念将每个传感器报告的燃料消耗率数据与温度联接:
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.ts AS rate_ts,
t2.rate AS rate
FROM mydataset.sensor_temperatures t1
LEFT JOIN mydataset.sensor_fuel_rates t2
ON TIMESTAMP_BUCKET(t1.ts, INTERVAL 15 SECOND) =
TIMESTAMP_BUCKET(t2.ts, INTERVAL 15 SECOND)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+---------------------+------+
| sensor_id | temp_ts | temp | rate_ts | rate |
+-----------+---------------------+------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------+---------------------+------*/
AS OF 联接
在本部分,使用 mydataset.sensor_temperatures 表并创建新表 mydataset.sensor_location。
mydataset.sensor_temperatures 表包含来自不同传感器的温度数据,数据每 15 秒报告一次:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:45 | 38.1 |
| 2 | 2020-01-01 12:01:01 | 38.2 |
| 2 | 2020-01-01 12:01:15 | 38.3 |
+-----------+---------------------+------*/
若要创建 mydataset.sensor_location,请运行以下查询:
CREATE OR REPLACE TABLE mydataset.sensor_locations AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, location GEOGRAPHY>>[
(1, TIMESTAMP '2020-01-01 11:59:47.063', ST_GEOGPOINT(-122.022, 37.406)),
(1, TIMESTAMP '2020-01-01 12:00:08.185', ST_GEOGPOINT(-122.021, 37.407)),
(1, TIMESTAMP '2020-01-01 12:00:28.032', ST_GEOGPOINT(-122.020, 37.405)),
(2, TIMESTAMP '2020-01-01 07:28:41.239', ST_GEOGPOINT(-122.390, 37.790))
]);
/*-----------+---------------------+------------------------+
| sensor_id | ts | location |
+-----------+---------------------+------------------------+
| 1 | 2020-01-01 11:59:47 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:08 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:28 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 07:28:41 | POINT(-122.39 37.79) |
+-----------+---------------------+------------------------*/
现在,将来自 mydataset.sensor_temperatures 的数据与来自 mydataset.sensor_location 的数据联接。
在这种情况下,您不能使用窗口联接,因为温度数据和位置日期不是在同一时间间隔内报告的。
在 BigQuery 中执行此操作的一种方法是使用 RANGE 数据类型将时间戳数据转换为某个范围。范围表示行的时间有效性,应提供该行有效的开始时间和结束时间。
使用 LEAD 窗口函数查找时序中相对于当前数据点(该数据点也是当前行时间有效性的结束边界)的下一个数据点。以下查询对此进行了演示,该查询将位置数据转换为有效范围:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT * FROM locations_ranges ORDER BY sensor_id, ts_range;
/*-----------+--------------------------------------------+------------------------+
| sensor_id | ts_range | location |
+-----------+--------------------------------------------+------------------------+
| 1 | [2020-01-01 11:59:47, 2020-01-01 12:00:08) | POINT(-122.022 37.406) |
| 1 | [2020-01-01 12:00:08, 2020-01-01 12:00:28) | POINT(-122.021 37.407) |
| 1 | [2020-01-01 12:00:28, UNBOUNDED) | POINT(-122.02 37.405) |
| 2 | [2020-01-01 07:28:41, UNBOUNDED) | POINT(-122.39 37.79) |
+-----------+--------------------------------------------+------------------------*/
现在,您可以将温度数据(左侧)与位置数据(右侧)联接起来:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.location AS location
FROM mydataset.sensor_temperatures t1
LEFT JOIN locations_ranges t2
ON RANGE_CONTAINS(t2.ts_range, t1.ts)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+------------------------+
| sensor_id | temp_ts | temp | location |
+-----------+---------------------+------+------------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:15 | 37.2 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:30 | 37.3 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 12:00:01 | 38.1 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:15 | 38.2 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:31 | 38.3 | POINT(-122.39 37.79) |
+-----------+---------------------+------+------------------------*/
合并和拆分范围数据
在本部分中,合并存在重叠范围的范围数据,并将范围数据拆分为较小的范围。
合并范围数据
具有范围值的表可能存在重叠的范围。在以下查询中,时间范围以大约 5 分钟的间隔捕获传感器状态:
CREATE OR REPLACE TABLE mydataset.sensor_metrics AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATETIME>, flow INT64, spins INT64>>[
(1, RANGE<DATETIME> "[2020-01-01 12:00:01, 2020-01-01 12:05:23)", 10, 1),
(1, RANGE<DATETIME> "[2020-01-01 12:05:12, 2020-01-01 12:10:46)", 10, 20),
(1, RANGE<DATETIME> "[2020-01-01 12:10:27, 2020-01-01 12:15:56)", 11, 4),
(1, RANGE<DATETIME> "[2020-01-01 12:16:00, 2020-01-01 12:20:58)", 11, 9),
(1, RANGE<DATETIME> "[2020-01-01 12:20:33, 2020-01-01 12:25:08)", 11, 8),
(2, RANGE<DATETIME> "[2020-01-01 12:00:19, 2020-01-01 12:05:08)", 21, 31),
(2, RANGE<DATETIME> "[2020-01-01 12:05:08, 2020-01-01 12:10:30)", 21, 2),
(2, RANGE<DATETIME> "[2020-01-01 12:10:22, 2020-01-01 12:15:42)", 21, 10)
]);
对该表的以下查询显示了几个重叠的范围:
SELECT * FROM mydataset.sensor_metrics;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:05:23) | 10 | 1 |
| 1 | [2020-01-01 12:05:12, 2020-01-01 12:10:46) | 10 | 20 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:20:58) | 11 | 9 |
| 1 | [2020-01-01 12:20:33, 2020-01-01 12:25:08) | 11 | 8 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:10:30) | 21 | 2 |
| 2 | [2020-01-01 12:10:22, 2020-01-01 12:15:42) | 21 | 10 |
+-----------+--------------------------------------------+------+-------*/
对于某些重叠的范围,flow 列中的值相同。例如,第 1 行和第 2 行重叠,具有相同的 flow 测量结果。您可以合并这两行,以减少表中的行数。您可以使用 RANGE_SESSIONIZE 表函数来查找与每行重叠的范围,并提供一个额外的 session_range 列以包含作为所有重叠范围的并集的范围。如需显示每行的会话范围,请运行以下查询:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
# Input data.
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
# Range column.
"duration",
# Partitioning columns. Ranges are sessionized only within these partitions.
["sensor_id", "flow"],
# Sessionize mode.
"OVERLAPS")
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
请注意,对于值为 2 的 sensor_id,第一行的结束边界与第二行的起始边界具有相同的日期时间值。但由于结束边界是互斥的,因此它们不会重叠(只会接触),因此不在同一会话范围内。如果您要将这两行放在同一会话范围内,请使用 MEETS sessionize 模式。
如需合并范围,请按 session_range 和分区列(sensor_id 和 flow)对结果进行分组:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
最后,使用 SUM 聚合 spins 列,以在会话数据中添加该列。
SELECT sensor_id, session_range, flow, SUM(spins) as spins
FROM RANGE_SESSIONIZE(
TABLE mydataset.sensor_metrics,
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | session_range | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 | 21 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 | 17 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 | 12 |
+-----------+--------------------------------------------+------+-------*/
拆分范围数据
您还可以将某个范围拆分为多个较小的范围。在此示例中,请使用下面包含范围数据的表:
/*-----------+--------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
现在,将原始范围拆分为以 3 个月为间隔:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data, UNNEST(GENERATE_RANGE_ARRAY(duration, INTERVAL 3 MONTH)) AS expanded_range;
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2020-07-15) | 21 | 31 |
| 2 | [2020-07-15, 2020-10-15) | 21 | 31 |
| 2 | [2020-10-15, 2021-01-15) | 21 | 31 |
| 2 | [2021-01-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-07-15) | 21 | 12 |
| 2 | [2021-07-15, 2021-10-15) | 21 | 12 |
| 2 | [2021-10-15, 2022-01-15) | 21 | 12 |
| 2 | [2022-01-15, 2022-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
在上一个查询中,每个原始范围都被拆分为多个较小的范围,宽度设置为 INTERVAL 3 MONTH。但是,这 3 个月的范围未校准为共同的起点。如需将这些范围校准为共同的起点 2020-01-01,请运行以下查询:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_OVERLAPS(duration, expanded_range);
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-04-01, 2020-07-01) | 21 | 31 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 12 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
在上一个查询中,范围为 [2020-04-15, 2021-04-15) 的行被拆分为 5 个范围,从范围 [2020-04-01, 2020-07-01) 开始。请注意,起始边界现在超出了原始起始边界,以便与共同的起点一致。如果您不希望起始边界超出原始起始边界,则可以限制 JOIN 条件:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_CONTAINS(duration, RANGE_START(expanded_range));
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
现在可以看到,范围 [2020-04-15, 2021-04-15) 被拆分为 4 个范围,从范围 [2020-07-01, 2020-10-01) 开始。
存储数据的最佳做法
存储时序数据时,请务必考虑针对存储数据的表所使用的查询模式。通常,查询时序数据时,您可以过滤特定时间范围内的数据。
为了优化这些使用模式,建议将时序数据存储在分区表中,数据按时间列或注入时间进行分区。这样可以显著提高时序数据的查询时间性能,因为可以让 BigQuery 删减不包含查询数据的分区。
您可以对时间、范围或其中一个分区列启用聚簇,以进一步提高查询时间性能。