ベクトル検索の概要
このドキュメントでは、BigQuery でのベクトル検索の概要について説明します。ベクトル検索は、エンベディングを使用して類似したオブジェクトを比較する手法であり、Google 検索、YouTube、Google Play などの Google プロダクトを強化するために使用されます。ベクトル検索を使用すると、大規模な検索を実行できます。ベクトル検索でベクトル インデックスを使用すると、反転ファイル インデックス(IVF)や ScaNN アルゴリズムなどの基盤となるテクノロジーを活用できます。
ベクトル検索はエンベディングに基づいて構築されています。エンベディングは、テキストや音声ファイルなど、特定のエンティティを表す高次元の数値ベクトルです。機械学習(ML)モデルは、エンベディングを使用してエンティティに関するセマンティクスをエンコードし、エンティティについての推論と比較を容易にします。たとえば、クラスタリング モデル、分類モデル、推奨事項モデルでの一般的なオペレーションは、エンベディング空間内のベクトル間の距離を測定し、意味的に最も類似したアイテムを見つけることです。
エンベディング空間におけるセマンティック類似性と距離という概念は、さまざまなアイテムがどのようにプロットされるかを考えると視覚的にわかります。たとえば、猫、犬、ライオンなどの用語は、すべて動物のタイプを表しますが、意味的な特徴が共通しているため、この空間内で互いに近い位置にグループ化されます。同様に、「車」、「トラック」、「車両」などの一般的なキーワードは別のクラスタを形成します。これを次のイメージに示します。
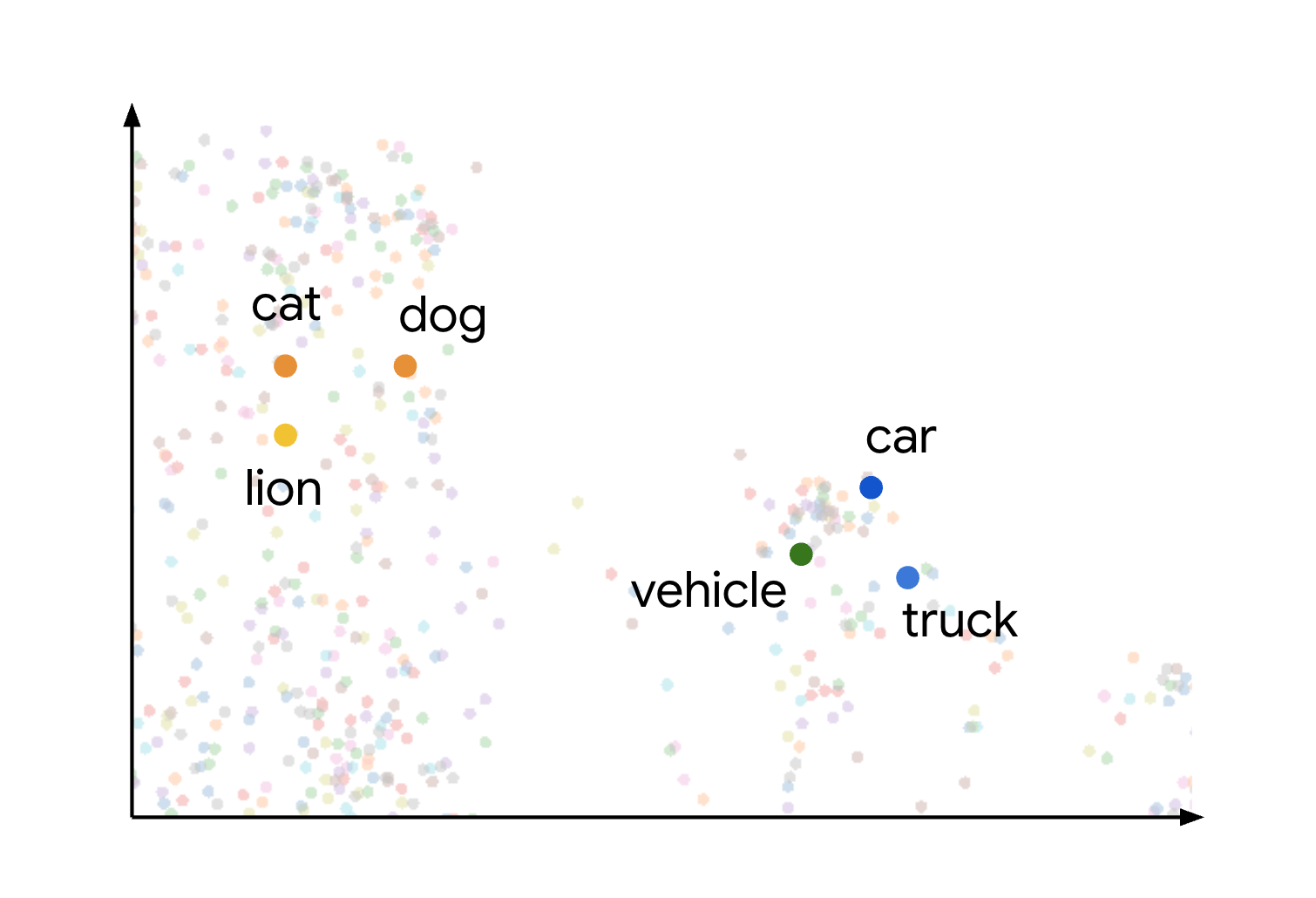
動物クラスタと車両クラスタが互いに離れて配置されていることがわかります。グループ間の分離は、エンベディング空間内でオブジェクトが近いほど意味的に類似性が高く、距離が大きいほど意味的に類似性が低いという原則を示しています。
BigQuery は、エンベディングの生成、コンテンツのインデックス登録、ベクトル検索の実行のエンドツーエンドの機能を提供します。これらのタスクは、個別に完了することも、1 つのジャーニーで完了することもできます。これらのタスクをすべて完了する方法を示すチュートリアルについては、セマンティック検索と検索拡張生成を行うをご覧ください。
SQL を使用してベクトル検索を行うには、VECTOR_SEARCH 関数を使用します。必要に応じて、CREATE VECTOR INDEX ステートメントを使用してベクトル インデックスを作成できます。ベクトル インデックスを使用する場合、VECTOR_SEARCH は近似最近傍検索の手法を使用して、ベクトル検索のパフォーマンスを向上させますが、再現率が低下するため、より近似的な結果が返されます。ベクトル インデックスがない場合、VECTOR_SEARCH はブルート フォース検索を使用して、すべてのレコードの距離を測定します。ベクトル インデックスが利用可能な場合でも、ブルート フォースを使って正確な結果を得ることができます。
このドキュメントでは SQL アプローチに焦点を当てていますが、Python で BigQuery DataFrames を使用してベクトル検索を実行することもできます。Python アプローチを示すノートブックについては、BigQuery DataFrames を使用してベクトル検索アプリケーションを構築するをご覧ください。
ユースケース
エンベディング生成とベクトル検索を組み合わせると、多くの興味深いユースケースが可能になります。いくつかの考えられるユースケースは次のとおりです。
- 検索拡張生成(RAG): BigQuery 内で、ドキュメントの解析、コンテンツのベクトル検索の実行、Gemini モデルを使用した自然言語の質問に対する回答の要約生成を行います。このシナリオを示すノートブックについては、BigQuery DataFrames を使用してベクトル検索アプリケーションを構築するをご覧ください。
- 代替商品や一致する商品を推奨する: 顧客の行動や商品の類似性に基づいて代替商品を提案することで、e コマース アプリケーションを強化します。
- ログ分析: チームがログの異常をプロアクティブにトリアージし、調査を迅速化するのに役立ちます。この機能を使用して LLM のコンテキストを拡充し、脅威の検出、フォレンジック、トラブルシューティングのワークフローを改善することもできます。このシナリオを示すノートブックについては、テキスト エンベディングと BigQuery ベクトル検索によるログの異常検出と調査をご覧ください。
- クラスタリングとターゲティング: オーディエンスを正確にセグメント化します。たとえば、病院チェーンは自然言語のメモと構造化データを使用して患者をクラスタリングできます。また、マーケターはクエリの意図に基づいて広告をターゲティングできます。このシナリオを示すノートブックについては、Create-Campaign-Customer-Segmentation をご覧ください。
- エンティティ解決と重複除去: データをクレンジングして統合します。たとえば、広告会社は個人を特定できる情報(PII)レコードの重複除去を行い、不動産会社は一致する郵送先住所を特定できます。
料金
VECTOR_SEARCH 関数と CREATE VECTOR INDEX ステートメントでは、BigQuery コンピューティングの料金が使用されます。
VECTOR_SEARCH関数: オンデマンド料金またはエディション料金を使用して、類似度検索に対して課金されます。- オンデマンド: ベーステーブル、インデックス、検索クエリでスキャンされたバイト数に対して課金されます。
エディションの料金: 予約エディション内でジョブを完了するために必要なスロットに対して課金されます。類似性計算の規模が大きく、複雑になるほど、料金が高くなります。
CREATE VECTOR INDEXステートメント: インデックス付きテーブルデータの合計サイズが組織ごとの上限を下回っている限り、ベクトル インデックスの作成と更新に必要な処理に対する料金は発生しません。この上限を超えるインデックス登録をサポートするには、インデックス管理ジョブ用に独自の予約を指定する必要があります。
エンベディングとインデックスについてもストレージを考慮する必要があります。エンベディングとインデックスとして保存されるバイト数は、アクティブ ストレージの費用の対象となります。
- ベクトル インデックスがアクティブな場合、ストレージの費用が発生します。
- インデックスのストレージ サイズは、
INFORMATION_SCHEMA.VECTOR_INDEXESビューを使用して確認できます。ベクトル インデックスのカバレッジが 100% でない場合でも、インデックスに登録されたものに対して費用が発生します。インデックス カバレッジは、INFORMATION_SCHEMA.VECTOR_INDEXESビューを使用して確認できます。
割り当てと上限
詳細については、ベクトル インデックスの上限をご覧ください。
制限事項
VECTOR_SEARCH 関数を含むクエリは、BigQuery BI Engine によって高速化されません。
次のステップ
- ベクトル インデックスの作成の詳細を確認する。
VECTOR_SEARCH関数を使用してベクトル検索を行う方法を学習する。- ベクトル検索を使用したエンベディングの検索のチュートリアルでは、ベクトル インデックスを作成し、インデックスありとインデックスなしの両方でエンベディングのベクトル検索を行う方法を学習できます。
セマンティック検索と検索拡張生成を行うのチュートリアルでは、次のタスクを行う方法を学習できます。
- テキスト エンベディングを生成する。
- エンベディングにベクトル インデックスを作成する。
- エンベディングでベクトル検索を行い、類似したテキストを検索する。
- ベクトル検索の結果からプロンプト入力を補強して結果を改善することで、検索拡張生成(RAG)を行う。
検索拡張生成パイプラインで PDF を解析するチュートリアルでは、解析された PDF コンテンツに基づいて RAG パイプラインを作成する方法を確認できます。