BigQuery ストレージの概要
このページでは、BigQuery のストレージ コンポーネントについて説明します。
BigQuery ストレージは、大規模なデータセットに対して分析クエリを実行するように最適化されています。また、高スループットのストリーミング取り込みと高スループット読み取りをサポートしています。BigQuery ストレージについて理解することで、ワークロードを最適化できます。
概要
BigQuery のアーキテクチャの主な特長の一つに、ストレージとコンピューティングの分離があります。これにより、BigQuery はストレージとコンピューティングの両方を必要に応じてスケーリングできます。
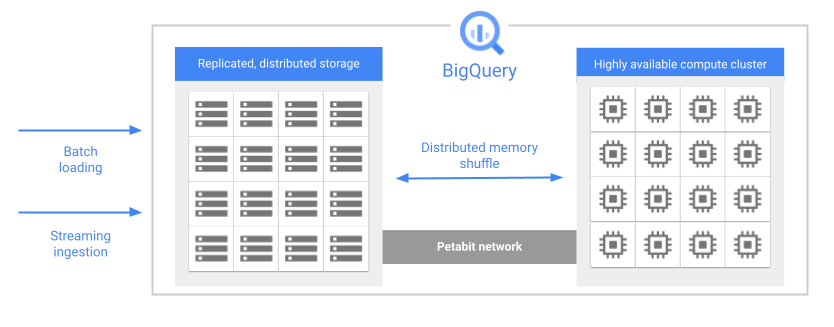
クエリを実行すると、クエリエンジンは処理を複数のワーカーに並行して分散します。複数のワーカーが、ストレージ内の関連するテーブルをスキャンし、クエリを処理してから結果を収集します。BigQuery は、ペタビット規模のネットワークを使用して、クエリをメモリ内で完全に実行し、データをワーカーノードにすばやく移動させます。
BigQuery ストレージの主な特長は次のとおりです。
マネージド。BigQuery ストレージはフルマネージド サービスです。ストレージ リソースのプロビジョニングや、ストレージ ユニットの予約は必要ありません。BigQuery は、システムにデータを読み込むときに、自動的にストレージを割り当てます。料金は、使用したストレージ量に対してのみ発生します。BigQuery の料金モデルでは、コンピューティングとストレージが別々に課金されます。料金の詳細については、BigQuery の料金をご覧ください。
耐久性。BigQuery ストレージは、99.999999999%(イレブンナイン)の年間耐久性を実現するよう設計されています。BigQuery は、複数のアベイラビリティ ゾーンにわたってデータを複製し、マシンレベルやゾーンの障害によるデータの損失を防止します。詳細については、信頼性: 障害対策をご覧ください。
暗号化。BigQuery は、データがディスクに書き込まれる前に、そのすべてを自動的に暗号化します。独自の暗号鍵を指定することも、Google に暗号鍵の管理を委任することもできます。詳細については、保存時の暗号化をご覧ください。
効率的。BigQuery ストレージでは、分析ワークロード用に最適化された効率的なエンコード形式が使用されます。BigQuery のストレージ形式の詳細については、BigQuery の次世代カラム型ストレージ形式、Capacitor というブログ投稿をご覧ください。
テーブルデータ
BigQuery に保存するデータの大半はテーブルデータです。テーブルデータには、標準テーブル、テーブル クローン、テーブル スナップショット、マテリアライズド ビューなどがあります。これらのリソースに使用したストレージに対して課金されます。詳細については、ストレージの料金をご覧ください。
標準テーブルには構造化データが含まれています。すべてのテーブルにスキーマがあり、スキーマのすべての列にデータ型があります。BigQuery はカラム型形式でデータを保存します。このドキュメントのストレージ レイアウトをご覧ください。
テーブル クローンは、標準テーブルの軽量かつ書き込み可能なコピーです。BigQuery は、テーブル クローンとそのベーステーブルの差分のみを保存します。
テーブル スナップショットは、テーブルのポイントインタイム コピーです。テーブルのスナップショットは読み取り専用ですが、テーブルのスナップショットからテーブルを復元できます。BigQuery は、スナップショットとそのベーステーブルの差分のみを保存します。
マテリアライズド ビューは事前に計算されたビューで、ビュークエリの結果を定期的にキャッシュに保存します。キャッシュに保存された結果は BigQuery ストレージに保存されます。
また、キャッシュに保存されたクエリ結果は一時テーブルとして保存されます。一時テーブルに保存されている、キャッシュに保存されたクエリ結果については課金されません。
外部テーブルは特殊なタイプのテーブルで、データは BigQuery の外部にあるデータストア(Cloud Storage など)に格納されます。外部テーブルには、標準テーブルと同じようにテーブル スキーマがありますが、テーブル定義は外部データストアを参照しています。この場合、テーブルのメタデータのみが BigQuery ストレージに保持されます。BigQuery では外部テーブル ストレージに対する課金は発生しませんが、外部データストアで課金される可能性があります。
BigQuery では、テーブルとその他のリソースをデータセットという論理コンテナに編成します。BigQuery リソースをグループ化する方法は、権限、割り当て、課金、その他の BigQuery ワークロードの要素に影響を及ぼします。詳細とベスト プラクティスについては、BigQuery リソースの整理をご覧ください。
テーブルに使用されるデータ保持ポリシーは、テーブルを含むデータセットの構成によって決まります。詳細については、タイムトラベルとフェイルセーフによるデータの保持をご覧ください。
メタデータ
BigQuery ストレージには BigQuery リソースに関するメタデータも保存されます。メタデータ ストレージは課金されません。
テーブル、ビュー、ユーザー定義関数(UDF)など、永続エンティティを BigQuery で作成すると、BigQuery はそのエンティティに関するメタデータを保存します。UDF や論理ビューなどのテーブルデータが含まれていないリソースの場合も同様です。
メタデータには、テーブル スキーマ、パーティショニングとクラスタリングの仕様、テーブルの有効期限などの情報が含まれます。このタイプのメタデータはユーザーに表示され、リソースの作成時に構成できます。また、BigQuery には、クエリを最適化するために内部的に使用するメタデータも格納されます。このメタデータはユーザーに表示されません。
ストレージ レイアウト
従来のデータベース システムの多くは、データを行指向形式で格納しています。つまり、各行が一緒に保存され、各行のフィールドがディスク上で順番に並んでいます。行指向のデータベースでは、個々のレコードを効率的に検索できます。ただし、システムはレコードにアクセスするたびにすべてのフィールドを読み取る必要があるため、多くのレコードで分析関数を実行すると効率が低下します。
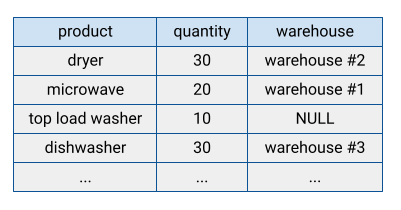
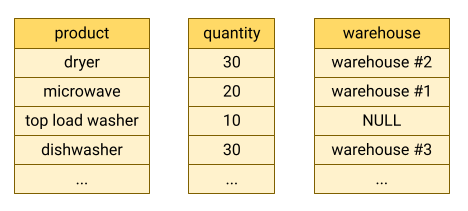
BigQuery では、テーブルデータをカラム型形式で保存します。つまり、各列が別々に保存されます。列指向データベースは、データセット全体に対して個々の列をスキャンする場合に特に効率的です。
列指向データベースは、非常に多くのレコードからデータを集計する分析ワークロード用に最適化されています。多くの場合、分析クエリはテーブルから数列を読み取るだけで済みます。たとえば、数百万行にわたる列の合計を計算する場合、BigQuery では、各行のすべてのフィールドを読み取ることなく、その列データを読み取ることができます。
列指向のデータベースのもう一つの利点は、列内のデータが行全体のデータよりも冗長性が高いことです。この特性により、ランレングス エンコードなどの手法でデータの圧縮が可能になり、読み取りパフォーマンスが向上します。
ストレージの課金モデル
BigQuery データ ストレージの課金は、論理バイト、物理(圧縮)バイト、またはその両方の組み合わせに基づいて行われます。選択したストレージ課金モデルによって、ストレージの料金が決まります。選択したストレージ課金モデルは、BigQuery のパフォーマンスには影響しません。いずれの課金モデルを選択しても、データは物理バイトとして保存されます。
ストレージ課金モデルはデータセット レベルで設定します。データセットの作成時にストレージ課金モデルを指定しない場合、デフォルトで論理ストレージの課金モデルが使用されます。ただし、作成後にデータセットのストレージ課金モデルを変更することもできます。データセットのストレージ課金モデルを変更した後に再度変更するには、14 日間待つ必要があります。
データセットの課金モデルを変更した場合は、変更が反映されるまでに 24 時間かかります。データセットの課金モデルを変更しても、長期ストレージ内のテーブルまたはテーブル パーティションはアクティブ ストレージにリセットされません。 データセットの課金モデルを変更しても、クエリのパフォーマンスとクエリのレイテンシは影響を受けません。
データセットでは、データの保持にタイムトラベル ストレージとフェイルセーフ ストレージが使用されます。物理ストレージの課金モデルを使用する場合、タイムトラベル ストレージとフェイルセーフ ストレージにはアクティブ ストレージの料金が別途適用されますが、論理ストレージの課金モデルを使用する場合は基本料金に含まれます。物理ストレージの費用とデータの保持のバランスをとるために、データセットに使用するタイムトラベル期間を変更できます。フェイルセーフ期間を変更することはできません。データセットのデータ保持の詳細については、タイムトラベルとフェイルセーフによるデータの保持をご覧ください。ストレージ費用の予測の詳細については、ストレージ課金を予測するをご覧ください。
所属する組織が、対象のデータセットと同じリージョンで以前の定額制スロット コミットメントを利用している場合、そのデータセットに物理ストレージ課金を適用することはできません。これは、BigQuery エディションで購入したコミットメントには適用されません。
ストレージを最適化する
BigQuery ストレージを最適化すると、クエリのパフォーマンスが向上し、コストが抑制されます。テーブル ストレージ メタデータを表示するには、次の INFORMATION_SCHEMA ビューに対してクエリを実行します。
ストレージの最適化については、BigQuery のストレージを最適化するをご覧ください。
データの読み込み
BigQuery にデータを取り込むには、いくつかの基本的なパターンがあります。
バッチ読み込み: 1 つのバッチ オペレーションで、ソースデータを BigQuery テーブルに読み込みます。これは 1 回限りのオペレーションですが、スケジュールを設定して自動化することもできます。バッチ読み込みオペレーションでは、新しいテーブルの作成や、既存テーブルへのデータの追加を行うことができます。
ストリーミング: 連続してデータの小さなバッチをストリーミングします。これにより、データをほぼリアルタイムでクエリできるようになります。
生成されたデータ: SQL ステートメントを使用して、既存のテーブルに行を挿入したり、テーブルにクエリ結果を書き込みます。
取り込み方法の選択については、データの読み込みの概要をご覧ください。料金については、データ取り込みの料金をご覧ください。
BigQuery ストレージからのデータの読み取り
ほとんどの場合、BigQuery にデータを保存して、そのデータに対して分析クエリを実行します。ただし、テーブルからレコードを直接読み取る場合もあります。BigQuery では、次のような方法でテーブルデータを読み取ることができます。
BigQuery API:
tabledata.listメソッドによる同期ページ分割アクセス。データは順番に(呼び出しごとに 1 ページずつ)読み取られます。詳細については、テーブルデータの閲覧をご覧ください。BigQuery Storage API: サーバー側の列の投影とフィルタリングもサポートするストリーミングの高スループット アクセス。読み取りは、複数の分離したストリームにセグメント化することで、多数のリーダー間で並列化できます。
エクスポート: 抽出ジョブまたは
EXPORT DATAステートメントを使用した Google Cloud Storage への非同期で高スループットのコピー。Cloud Storage にデータをコピーする必要がある場合は、抽出ジョブまたはEXPORT DATAステートメントを使用してデータをエクスポートします。コピー: BigQuery 内のデータセットの非同期コピー。コピー元とコピー先のロケーションが同じ場合、コピーは論理的に行われます。
料金については、データ抽出の料金をご覧ください。
アプリケーションの要件に応じて、次のようにテーブルデータを読み取ることができます。
- 読み取りとコピー: Cloud Storage に保存されているコピーが必要な場合は、抽出ジョブまたは
EXPORT DATAステートメントを使用してデータをエクスポートします。データの読み取りのみを行う場合は、BigQuery Storage API を使用します。BigQuery 内でコピーを作成する場合は、コピージョブを使用します。 - スケーリング: BigQuery API は最も効率が悪いメソッドであるため、大量の読み取りには使用しないでください。1 日あたり 50 TB を超えるデータをエクスポートする必要がある場合は、
EXPORT DATAステートメントか BigQuery Storage API を使用します。 - 最初の行を返すまでの時間: BigQuery API は最初の行を返すのに最も速い方法ですが、少量のデータを読み取る場合にのみ使用してください。BigQuery Storage API は、最初の行を返すのには時間がかかりますが、スループットは大幅に高まります。エクスポートとコピーが終了してからでないと、行を読み取ることができないため、これらのタイプのジョブでは、最初の行を返すまでの時間が数分程度かかる場合があります。
削除
テーブルを削除した場合、データは少なくともタイムトラベル期間の間は保持されます。この期間がすぎると、Google Cloud 削除タイムライン内でデータがディスクからクリーンアップされます。DROP COLUMN ステートメントなど、一部の削除オペレーションはメタデータのみのオペレーションです。この場合、影響を受ける行を次回に変更したときにストレージが解放されます。テーブルを変更しない場合は、ストレージが解放される時間は保証されていません。詳細については、 Google Cloud上のデータの削除をご覧ください。
次のステップ
- テーブルの操作について学習する。
- ストレージを最適化する方法を学習する。
- BigQuery でデータをクエリする方法を学習する。
- データ セキュリティとガバナンスについて学習する。