Información general sobre el almacenamiento de BigQuery
En esta página se describe el componente de almacenamiento de BigQuery.
El almacenamiento de BigQuery está optimizado para ejecutar consultas analíticas en conjuntos de datos de gran tamaño. También admite la ingestión en streaming de alto rendimiento y lecturas de alto rendimiento. Conocer el almacenamiento de BigQuery puede ayudarte a optimizar tus cargas de trabajo.
Información general
Una de las características clave de la arquitectura de BigQuery es la separación del almacenamiento y los recursos de computación. De esta forma, BigQuery puede escalar tanto el almacenamiento como los recursos de computación de forma independiente en función de la demanda.
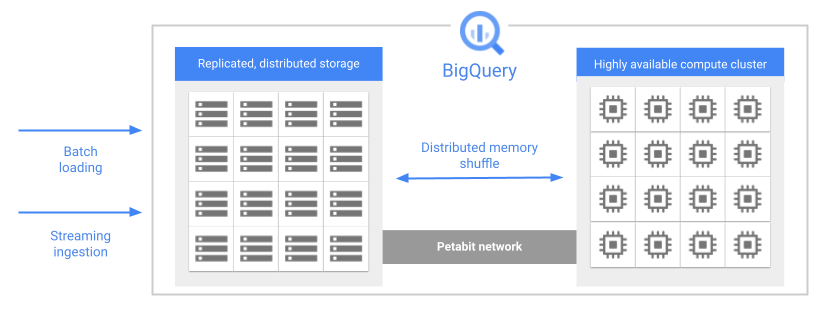
Cuando ejecutas una consulta, el motor de consultas distribuye el trabajo en paralelo entre varios trabajadores, que analizan las tablas pertinentes del almacenamiento, procesan la consulta y, a continuación, recogen los resultados. BigQuery ejecuta las consultas completamente en la memoria, utilizando una red de petabits para asegurarse de que los datos se muevan extremadamente rápido a los nodos de trabajo.
Estas son algunas de las características principales del almacenamiento de BigQuery:
Gestionado. El almacenamiento de BigQuery es un servicio totalmente gestionado. No es necesario aprovisionar recursos de almacenamiento ni reservar unidades de almacenamiento. BigQuery asigna automáticamente el almacenamiento cuando cargas datos en el sistema. Solo pagas por la cantidad de almacenamiento que utilizas. El modelo de precios de BigQuery cobra por los recursos de computación y el almacenamiento por separado. Para obtener información sobre los precios, consulta los precios de BigQuery.
Durable. El almacenamiento de BigQuery está diseñado para ofrecer una durabilidad anual del 99,999999999 % (once nueves). BigQuery replica tus datos en varias zonas de disponibilidad para protegerlos frente a la pérdida de datos debido a fallos a nivel de máquina o zonales. Para obtener más información, consulta Fiabilidad: planificación ante desastres.
Cifrado. BigQuery cifra automáticamente todos los datos antes de que se escriban en el disco. Puedes proporcionar tu propia clave de cifrado o dejar que Google gestione la clave de cifrado. Para obtener más información, consulta Cifrado en reposo.
Eficiente. El almacenamiento de BigQuery usa un formato de codificación eficiente optimizado para cargas de trabajo analíticas. Si quieres obtener más información sobre el formato de almacenamiento de BigQuery, consulta la entrada de blog Inside Capacitor, BigQuery's next-generation columnar storage format (en inglés).
Datos de la tabla
La mayoría de los datos que almacenas en BigQuery son datos de tabla. Los datos de las tablas incluyen tablas estándar, clones de tablas, instantáneas de tablas y vistas materializadas. Se te cobra por el almacenamiento que utilizas para estos recursos. Para obtener más información, consulta la página Precios de almacenamiento.
Las tablas estándar contienen datos estructurados. Cada tabla tiene un esquema y cada columna del esquema tiene un tipo de datos. BigQuery almacena los datos en formato de columnas. Consulta la sección Diseño del almacenamiento de este documento.
Los clones de tablas son copias ligeras y editables de las tablas estándar. BigQuery solo almacena el delta entre una clonación de una tabla y su tabla base.
Las capturas de tablas son copias de tablas de un momento concreto. Las capturas de tablas son de solo lectura, pero puedes restaurar una tabla a partir de una captura de tabla. BigQuery solo almacena el delta entre una instantánea de una tabla y su tabla base.
Las vistas materializadas son vistas precalculadas que almacenan en caché periódicamente los resultados de la consulta de la vista. Los resultados almacenados en caché se guardan en el almacenamiento de BigQuery.
Además, los resultados de las consultas almacenados en caché se guardan como tablas temporales. No se te cobrará por los resultados de las consultas almacenados en caché en tablas temporales.
Las tablas externas son un tipo especial de tabla en la que los datos residen en un almacén de datos externo a BigQuery, como Cloud Storage. Una tabla externa tiene un esquema de tabla, al igual que una tabla estándar, pero la definición de la tabla apunta al almacén de datos externo. En este caso, solo los metadatos de la tabla se conservan en el almacenamiento de BigQuery. BigQuery no cobra por el almacenamiento de tablas externas, aunque el almacén de datos externo sí puede hacerlo.
BigQuery organiza las tablas y otros recursos en contenedores lógicos llamados conjuntos de datos. La forma en que agrupes tus recursos de BigQuery afectará a los permisos, las cuotas, la facturación y otros aspectos de tus cargas de trabajo de BigQuery. Para obtener más información y consultar las prácticas recomendadas, consulta el artículo sobre cómo organizar recursos de BigQuery.
La política de conservación de datos que se usa en una tabla se determina en función de la configuración del conjunto de datos que contiene la tabla. Para obtener más información, consulta el artículo Conservación de datos con la función de recuperación de versiones anteriores y el sistema de seguridad.
Metadatos
El almacenamiento de BigQuery también contiene metadatos sobre tus recursos de BigQuery. No se te cobra por el almacenamiento de metadatos.
Cuando creas una entidad persistente en BigQuery, como una tabla, una vista o una función definida por el usuario (UDF), BigQuery almacena metadatos sobre la entidad. Esto se aplica incluso a los recursos que no contienen datos de tabla, como las funciones definidas por el usuario y las vistas lógicas.
Los metadatos incluyen información como el esquema de la tabla, las especificaciones de partición y clustering, los tiempos de vencimiento de la tabla y otra información. Este tipo de metadatos es visible para el usuario y se puede configurar al crear el recurso. Además, BigQuery almacena metadatos que utiliza internamente para optimizar las consultas. Los usuarios no pueden ver directamente estos metadatos.
Diseño de almacenamiento
Muchos sistemas de bases de datos tradicionales almacenan sus datos en formato orientado a filas, lo que significa que las filas se almacenan juntas y los campos de cada fila aparecen secuencialmente en el disco. Las bases de datos orientadas a filas son eficientes a la hora de buscar registros concretos. Sin embargo, pueden ser menos eficientes a la hora de realizar funciones analíticas en muchos registros, ya que el sistema tiene que leer todos los campos al acceder a un registro.
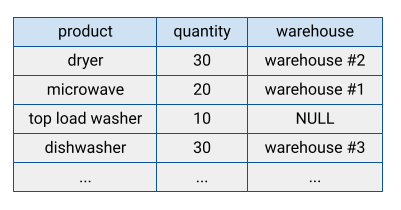
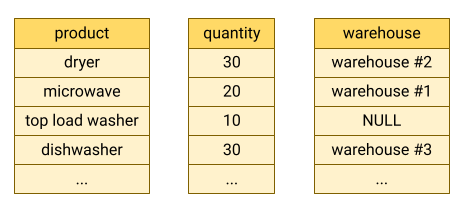
BigQuery almacena los datos de las tablas en formato de columnas, lo que significa que almacena cada columna por separado. Las bases de datos orientadas a columnas son especialmente eficientes a la hora de analizar columnas concretas en todo un conjunto de datos.
Las bases de datos orientadas a columnas están optimizadas para cargas de trabajo analíticas que agregan datos en un número muy elevado de registros. A menudo, una consulta analítica solo necesita leer unas pocas columnas de una tabla. Por ejemplo, si quieres calcular la suma de una columna de millones de filas, BigQuery puede leer los datos de esa columna sin leer todos los campos de cada fila.
Otra ventaja de las bases de datos orientadas a columnas es que los datos de una columna suelen tener más redundancia que los datos de una fila. Esta característica permite una mayor compresión de datos mediante técnicas como la codificación de longitud de ejecución, lo que puede mejorar el rendimiento de lectura.
Modelos de facturación del almacenamiento
Se le puede facturar el almacenamiento de datos de BigQuery en bytes lógicos o físicos (comprimidos), o bien una combinación de ambos. El modelo de facturación del almacenamiento que elijas determinará los precios del almacenamiento. El modelo de facturación del almacenamiento que elijas no influye en el rendimiento de BigQuery. Independientemente del modelo de facturación que elijas, tus datos se almacenan como bytes físicos.
El modelo de facturación del almacenamiento se define a nivel del conjunto de datos. Si no especificas un modelo de facturación de almacenamiento al crear un conjunto de datos, se usará de forma predeterminada la facturación de almacenamiento lógico. Sin embargo, puedes cambiar el modelo de facturación del almacenamiento de un conjunto de datos después de crearlo. Si cambia el modelo de facturación del almacenamiento de un conjunto de datos, debe esperar 14 días para volver a cambiarlo.
Cuando cambias el modelo de facturación de un conjunto de datos, el cambio tarda 24 horas en aplicarse. Las tablas o particiones de tabla que estén en el almacenamiento a largo plazo no se restablecerán al almacenamiento activo cuando cambies el modelo de facturación de un conjunto de datos. El rendimiento y la latencia de las consultas no se ven afectados por el cambio del modelo de facturación de un conjunto de datos.
Los conjuntos de datos usan desplazamiento en el tiempo y almacenamiento a prueba de fallos para la conservación de datos. El viaje en el tiempo y el almacenamiento a prueba de fallos se cobran por separado a las tarifas de almacenamiento activo cuando usas la facturación de almacenamiento físico, pero se incluyen en la tarifa base que se te cobra cuando usas la facturación de almacenamiento lógico. Puede modificar el periodo de tiempo de los viajes en el tiempo que utiliza para un conjunto de datos con el fin de equilibrar los costes de almacenamiento físico con la conservación de datos. No puedes modificar la ventana de seguridad. Para obtener más información sobre la conservación de datos de conjuntos de datos, consulta el artículo Conservación de datos con la función de viaje en el tiempo y el sistema de seguridad. Para obtener más información sobre cómo predecir los costes de almacenamiento, consulta Predecir la facturación del almacenamiento.
No puedes registrar un conjunto de datos en la facturación de almacenamiento físico si tu organización tiene compromisos de slots de tarifa plana antiguos en la misma región que el conjunto de datos. Esto no se aplica a los compromisos comprados con una edición de BigQuery.
Optimizar almacenamiento
Optimizar el almacenamiento de BigQuery mejora el rendimiento de las consultas y controla los costes. Para ver los metadatos de almacenamiento de tablas, consulta las siguientes vistas de INFORMATION_SCHEMA:
Para obtener información sobre cómo optimizar el almacenamiento, consulta Optimizar el almacenamiento en BigQuery.
Cargar datos
Hay varios patrones básicos para ingerir datos en BigQuery.
Carga por lotes: carga los datos de origen en una tabla de BigQuery en una sola operación por lotes. Puede ser una operación puntual o puedes automatizarla para que se produzca según una programación. Una operación de carga por lotes puede crear una tabla o añadir datos a una tabla ya creada.
Streaming: transmite continuamente lotes de datos más pequeños para que los datos estén disponibles para las consultas casi en tiempo real.
Datos generados: usa instrucciones SQL para insertar filas en una tabla o escribir los resultados de una consulta en una tabla.
Para obtener más información sobre cuándo elegir cada uno de estos métodos de ingestión, consulta las instrucciones sobre la carga de datos. Para obtener información sobre los precios, consulta la página Precios de la ingestión de datos.
Leer datos del almacenamiento de BigQuery
La mayoría de las veces, los datos se almacenan en BigQuery para ejecutar consultas analíticas sobre ellos. Sin embargo, a veces puede que quieras leer registros directamente de una tabla. BigQuery ofrece varias formas de leer datos de tablas:
API de BigQuery: Acceso paginado síncrono con el método
tabledata.list. Los datos se leen de forma secuencial, una página por invocación. Para obtener más información, consulta Navegar por los datos de una tabla.API Storage de BigQuery: acceso de streaming de alto rendimiento que también admite la proyección y el filtrado de columnas del lado del servidor. Las lecturas se pueden paralelizar en muchos lectores segmentándolas en varias secuencias disjuntas.
Exportar: copia asíncrona de alto rendimiento en Google Cloud Storage, ya sea con trabajos de extracción o con la instrucción
EXPORT DATA. Si necesitas copiar datos en Cloud Storage, exporta los datos con una tarea de extracción o con una instrucciónEXPORT DATA.Copiar: copia asíncrona de conjuntos de datos en BigQuery. La copia se realiza de forma lógica cuando la ubicación de origen y de destino es la misma.
Para obtener información sobre los precios, consulta la página Precios de la extracción de datos.
Según los requisitos de la aplicación, puedes leer los datos de la tabla:
- Leer y copiar: si necesitas una copia en reposo en Cloud Storage, exporta los datos con una tarea de extracción o con una instrucción
EXPORT DATA. Si solo quieres leer los datos, usa la API Storage de BigQuery. Si quieres hacer una copia en BigQuery, usa una tarea de copia. - Escala: la API de BigQuery es el método menos eficiente y no debe usarse para lecturas de gran volumen. Si necesitas exportar más de 50 TB de datos al día, usa la instrucción
EXPORT DATAo la API Storage de BigQuery. - Tiempo necesario para devolver la primera fila: la API de BigQuery es el método más rápido para devolver la primera fila, pero solo se debe usar para leer pequeñas cantidades de datos. La API Storage de BigQuery tarda más en devolver la primera fila, pero tiene un rendimiento mucho mayor. Las exportaciones y las copias deben finalizar antes de que se puedan leer las filas, por lo que el tiempo hasta la primera fila de estos tipos de trabajos puede ser del orden de minutos.
Eliminación
Cuando eliminas una tabla, los datos se conservan durante al menos el periodo de tu ventana de viaje en el tiempo. Después, los datos se eliminan del disco en el Google Cloud plazo de eliminación.
Algunas operaciones de eliminación, como la instrucción DROP COLUMN, son operaciones de solo metadatos. En este caso, el almacenamiento se libera la próxima vez que modifiques las filas afectadas. Si no modificas la tabla, no hay un plazo garantizado para que se libere el almacenamiento. Para obtener más información, consulta Eliminación de datos en Google Cloud.
Siguientes pasos
- Consulta cómo trabajar con tablas.
- Consulta cómo optimizar el almacenamiento.
- Consulta cómo consultar datos en BigQuery.
- Consulta información sobre la seguridad y la gestión de datos.