Menelusuri data yang diindeks
Halaman ini memberikan contoh penelusuran data tabel di BigQuery.
Saat Anda mengindeks data, BigQuery dapat mengoptimalkan beberapa kueri
yang menggunakan fungsi SEARCH
atau fungsi dan operator lainnya,
seperti =, IN, LIKE, dan STARTS_WITH.
Kueri SQL menampilkan hasil yang benar dari semua data yang diserap, meskipun beberapa data belum diindeks. Namun, performa kueri dapat sangat meningkat dengan indeks. Penghematan dalam byte yang diproses dan slot milidetik akan dimaksimalkan jika jumlah hasil penelusuran merupakan pecahan yang relatif kecil dari total baris di tabel Anda karena data yang dipindai lebih sedikit. Untuk menentukan apakah indeks digunakan untuk kueri, lihat penggunaan indeks penelusuran.
Membuat indeks penelusuran
Tabel bernama Logs berikut digunakan untuk menunjukkan berbagai cara
menggunakan fungsi SEARCH. Tabel contoh ini cukup kecil, tetapi pada praktiknya,
peningkatan performa yang Anda dapatkan dengan SEARCH akan meningkat sesuai ukuran
tabel.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
Tabel tersebut akan terlihat seperti berikut:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Buat indeks penelusuran pada tabel Logs menggunakan penganalisis teks default:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Untuk mengetahui informasi selengkapnya tentang indeks penelusuran, lihat Mengelola indeks penelusuran.
Menggunakan fungsi SEARCH
Fungsi SEARCH menyediakan penelusuran yang ditokenkan pada data.
SEARCH dirancang untuk digunakan dengan indeks guna
mengoptimalkan pencarian.
Anda dapat menggunakan fungsi SEARCH untuk menelusuri seluruh tabel atau
membatasi penelusuran ke kolom tertentu.
Menelusuri seluruh tabel
Kueri berikut menelusuri semua kolom tabel Logs untuk nilai
bar dan menampilkan baris yang berisi nilai ini, terlepas dari
kapitalisasinya. Karena indeks penelusuran menggunakan penganalisis teks default, Anda tidak
perlu menentukannya dalam fungsi SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Kueri berikut menelusuri semua kolom tabel Logs untuk
nilai `94.60.64.181` dan menampilkan baris yang berisi nilai ini. Backtick
memungkinkan penelusuran yang tepat, itulah sebabnya baris terakhir tabel Logs
yang berisi 181.94.60.64 dihilangkan.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Menelusuri subset kolom
SEARCH memudahkan penentuan subset kolom untuk menelusuri
data. Kueri berikut menelusuri kolom Message dalam tabel Logs untuk
menemukan nilai 94.60.64.181 dan menampilkan baris yang berisi nilai ini.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Kueri berikut menelusuri kolom Source dan Message pada tabel Logs. Metode ini menampilkan baris yang berisi nilai 94.60.64.181 dari
salah satu kolom.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Mengecualikan kolom dari penelusuran
Jika tabel memiliki banyak kolom dan Anda ingin menelusuri sebagian besar kolom, akan lebih mudah
dengan hanya menentukan kolom yang akan dikecualikan dari penelusuran. Kueri berikut
menelusuri semua kolom tabel Logs kecuali untuk
kolom Message. Metode ini menampilkan baris kolom apa pun selain Message
yang berisi nilai 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Menggunakan penganalisis teks lain
Contoh berikut membuat tabel bernama contact_info dengan indeks yang
menggunakan penganalisis teks
NO_OP_ANALYZER:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
Kueri berikut menelusuri Kim di kolom name dan kim
di kolom email.
Karena indeks penelusuran tidak menggunakan penganalisis teks default, Anda harus meneruskan
nama penganalisis ke fungsi SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER tidak mengubah teks, sehingga fungsi SEARCH hanya
menampilkan TRUE untuk pencocokan persis:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Mengonfigurasi opsi penganalisis teks
Penganalisis
teks LOG_ANALYZER dan PATTERN_ANALYZER dapat
disesuaikan dengan menambahkan string berformat JSON ke opsi konfigurasi. Anda
dapat mengonfigurasi penganalisis teks di fungsi
SEARCH, pernyataan DDL
CREATE
SEARCH INDEX,
dan fungsi
TEXT_ANALYZE.
Contoh berikut membuat tabel bernama complex_table dengan indeks yang
menggunakan penganalisis teks LOG_ANALYZER. Fungsi ini menggunakan string berformat JSON untuk
mengonfigurasi opsi penganalisis:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalization": {"mode": "NONE"} } ] }''');
Tabel berikut menunjukkan contoh panggilan ke fungsi SEARCH dengan
analisis teks yang berbeda dan hasilnya. Tabel pertama memanggil fungsi SEARCH menggunakan penganalisis teks default, LOG_ANALYZER:
| Panggilan fungsi | Hasil | Alasan |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERROR | search_terms adalah `NULL`. |
| SEARCH('foobarexample', '') | ERROR | search_terms tidak berisi token. |
| SEARCH('foobar-example', 'foobar example') | TRUE | '-' dan ' ' adalah pembatas. |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms tidak dipisahkan. |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | Backslash ganda akan meng-escape ampersand yang merupakan pemisah. |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | Garis miring terbalik tunggal meng-escape ampersand dalam string mentah. |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | Tanda petik terbalik memerlukan pencocokan persis untuk foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | Kecocokan persis ditemukan. |
| SEARCH('foobar-example', 'example foobar') | TRUE | Urutan istilah tidak penting. |
| SEARCH('foobar-example', 'foobar example') | TRUE | Token dibuat dalam huruf kecil. |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | Kecocokan persis ditemukan. |
| SEARCH('foobar-example', '`foobar`') | FALSE | Tanda petik terbalik mempertahankan kapitalisasi. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | Tanda petik terbalik tidak memiliki arti khusus untuk data_to_search dan |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | Pencocokan persis ditemukan setelah pemisah di data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | Pencocokan persis ditemukan di antara pembatas spasi. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | Tidak ada satu entri array yang cocok dengan semua istilah penelusuran. |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms setara dengan foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | Hal ini setara dengan contoh sebelumnya. |
| SEARCH('foobar=', 'foobar\\=') | TRUE | Tanda sama dengan adalah pemisah dalam data dan kueri. |
| SEARCH('foobar=', R'foobar\=') | TRUE | Hal ini setara dengan contoh sebelumnya. |
| SEARCH('foobar.example', '`foobar`') | TRUE | Kecocokan persis ditemukan. |
| SEARCH('foobar.example', '`foobar.`') | FALSE | `foobar.` tidak dianalisis karena tanda kutip terbalik; tidak |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` tidak dianalisis karena tanda kutip terbalik; diikuti |
Tabel berikut menunjukkan contoh panggilan ke fungsi SEARCH menggunakan
analis teks NO_OP_ANALYZER dan alasan berbagai nilai yang ditampilkan:
| Panggilan fungsi | Hasil | Alasan |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | Kecocokan persis ditemukan. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | Tanda petik terbalik bukan karakter khusus untuk NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | Penggunaan huruf besar tidak cocok. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | Tidak ada pemisah untuk NO_OP_ANALYZER. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | Tidak ada pemisah untuk NO_OP_ANALYZER. |
Operator dan fungsi lainnya
Anda dapat melakukan pengoptimalan indeks penelusuran dengan beberapa operator, fungsi, dan predikat.
Mengoptimalkan dengan operator dan fungsi perbandingan
BigQuery dapat mengoptimalkan beberapa kueri yang menggunakan
operator sama dengan
(=),
operator IN,
operator LIKE,
atau
fungsiSTARTS_WITH
untuk membandingkan literal string dengan data yang diindeks.
Mengoptimalkan dengan predikat string
Predikat berikut memenuhi syarat untuk pengoptimalan indeks penelusuran:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)STARTS_WITH(column_name, 'prefix')column_name LIKE 'prefix%'
Mengoptimalkan dengan predikat numerik
Jika indeks penelusuran dibuat dengan jenis data numerik, BigQuery
dapat mengoptimalkan beberapa kueri yang menggunakan operator sama dengan (=) atau operator IN
dengan data yang diindeks. Predikat berikut memenuhi syarat untuk pengoptimalan indeks penelusuran:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Mengoptimalkan fungsi yang menghasilkan data yang diindeks
BigQuery mendukung pengoptimalan indeks penelusuran saat fungsi
tertentu diterapkan ke data yang diindeks.
Jika indeks penelusuran menggunakan penganalisis teks LOG_ANALYZER default, Anda dapat
menerapkan fungsi
UPPER
atau LOWER
ke kolom, seperti UPPER(column_name) = 'STRING_LITERAL'.
Untuk JSON data string skalar yang diekstrak dari kolom JSON yang diindeks, Anda dapat
menerapkan fungsi
STRING
atau versi amannya,
SAFE.STRING.
Jika nilai JSON yang diekstrak bukan string, fungsi STRING akan
menghasilkan error dan fungsi SAFE.STRING akan menampilkan NULL.
Untuk data
berformat JSON terindeks STRING (bukan JSON), Anda dapat menerapkan fungsi
berikut:
Misalnya, tabel terindeks berikut bernama dataset.person_data dengan kolom JSON dan STRING:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
Kueri berikut memenuhi syarat untuk pengoptimalan:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
Kombinasi fungsi ini juga dioptimalkan, seperti
UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Penggunaan indeks penelusuran
Untuk menentukan apakah indeks penelusuran digunakan untuk kueri, Anda dapat melihat
detail tugas atau membuat kueri salah satu tampilan INFORMATION_SCHEMA.JOBS*.
Melihat detail tugas
Di Informasi Tugas pada Hasil kueri, kolom Mode Penggunaan Indeks dan Alasan Indeks Tidak Digunakan memberikan informasi mendetail tentang penggunaan indeks penelusuran.
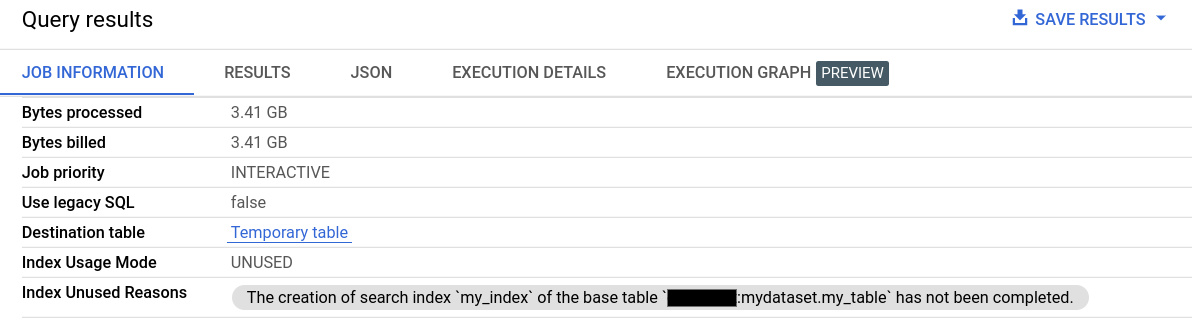
Informasi tentang penggunaan indeks penelusuran juga tersedia melalui
kolom searchStatistics
dalam metode Jobs.Get API. Kolom
indexUsageMode di searchStatistics menunjukkan apakah indeks penelusuran
digunakan dengan nilai berikut:
UNUSED: tidak ada indeks penelusuran yang digunakan.PARTIALLY_USED: sebagian kueri menggunakan indeks penelusuran dan sebagian lagi tidak.FULLY_USED: setiap fungsiSEARCHdalam kueri menggunakan indeks penelusuran.
Jika indexUsageMode adalah UNUSED atau PARTIALLY_USED, kolom indexUnusuedReasons
akan berisi informasi tentang alasan indeks penelusuran tidak digunakan dalam kueri.
Untuk melihat searchStatistics untuk kueri, jalankan perintah bq show.
bq show --format=prettyjson -j JOB_ID
Contoh
Misalnya Anda menjalankan kueri yang memanggil fungsi SEARCH pada data dalam tabel. Anda
dapat melihat
detail tugas kueri untuk
menemukan ID tugas, lalu menjalankan perintah bq show untuk melihat informasi lebih lanjut:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
Output-nya berisi banyak kolom, termasuk searchStatistics, yang terlihat
mirip dengan contoh berikut ini. Dalam contoh ini, indexUsageMode menunjukkan bahwa indeks
tidak digunakan. Alasannya adalah tabel tersebut tidak memiliki indeks penelusuran. Untuk
mengatasi masalah ini, buat indeks penelusuran di tabel. Lihat
bidang code indexUnusedReason
untuk mengetahui daftar semua alasan indeks penelusuran tidak dapat digunakan dalam kueri.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Membuat kueri tampilan INFORMATION_SCHEMA
Anda juga dapat melihat penggunaan indeks penelusuran untuk beberapa tugas di suatu region dalam tampilan berikut:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
Kueri berikut menampilkan informasi tentang penggunaan indeks untuk semua kueri yang dapat dioptimalkan di indeks penelusuran selama 7 hari terakhir:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
Hasilnya mirip dengan berikut ini:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Praktik terbaik
Bagian berikut menjelaskan praktik terbaik untuk penelusuran.
Menelusuri secara selektif
Penelusuran berfungsi optimal saat penelusuran Anda memiliki sedikit hasil. Buat pencarian Anda agar sespesifik mungkin.
Pengoptimalan ORDER BY LIMIT
Kueri yang menggunakan SEARCH, =, IN, LIKE, atau STARTS_WITH pada tabel yang dipartisi
yang sangat besar dapat dioptimalkan
jika Anda menggunakan klausa ORDER BY pada kolom yang dipartisi dan klausa LIMIT.
Untuk kueri yang tidak berisi fungsi SEARCH, Anda dapat menggunakan
operator dan fungsi lainnya untuk
memanfaatkan pengoptimalan. Pengoptimalan akan diterapkan terlepas dari apakah tabel diindeks atau tidak. Praktik ini berfungsi dengan baik jika Anda menelusuri istilah umum.
Misalnya, tabel Logs yang dibuat sebelumnya
dipartisi di kolom jenis DATE tambahan
yang bernama day. Kueri berikut dioptimalkan:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Membatasi penelusuran
Saat Anda menggunakan fungsi SEARCH, hanya telusuri kolom tabel yang Anda
harapkan berisi istilah penelusuran. Cara ini meningkatkan performa dan
mengurangi jumlah byte yang perlu dipindai.
Menggunakan tanda kutip tunggal terbalik
Saat Anda menggunakan fungsi SEARCH dengan penganalisis teks LOG_ANALYZER,
menyertakan kueri penelusuran dengan tanda kutip tunggal terbalik
akan menghasilkan pencocokan persis. Praktik ini berguna
jika penelusuran Anda peka huruf besar/kecil atau berisi karakter yang tidak boleh
diartikan sebagai pembatas. Misalnya, untuk menelusuri alamat IP
192.0.2.1, gunakan `192.0.2.1`. Tanpa tanda kutip tunggal terbalik, penelusuran akan menampilkan
baris apa pun yang berisi token individual 192, 0, 2, dan 1, dalam urutan
apa pun.