Como programar consultas
Nesta página, você aprende a programar consultas recorrentes no BigQuery.
É possível programar consultas para que sejam executadas de maneira recorrente. As consultas programadas precisam ser escritas em GoogleSQL, que pode incluir instruções em linguagem de definição de dados (DDL) e linguagem de manipulação de dados (DML). É possível organizar os resultados da consulta por data e hora parametrizando a string de consulta e a tabela de destino.
Ao criar ou atualizar a programação de uma consulta, o horário programado para a consulta é convertido do seu horário local para UTC. O UTC não é afetado pelo horário de verão.
Antes de começar
- Nas consultas programadas, são usados recursos do serviço de transferência de dados do BigQuery. Verifique se você concluiu todas as ações necessárias em Como ativar o serviço de transferência de dados do BigQuery.
- Atribua papéis do Identity and Access Management (IAM) que concedam aos usuários as permissões necessárias para realizar cada tarefa deste documento.
- Se você planeja especificar uma chave de criptografia gerenciada pelo cliente (CMEK), verifique se a conta de serviço tem permissões para criptografar e descriptografar e que você tem o Cloud KMS ID do recurso da chave necessário para usar a CMEK. Para informações sobre como as CMEKs funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar chave de criptografia com consultas programadas.
Permissões necessárias
Para programar uma consulta, você precisa destas permissões do IAM:
Para criar a transferência, você precisa ter as permissões
bigquery.transfers.updateebigquery.datasets.getoubigquery.jobs.create,bigquery.transfers.getebigquery.datasets.get.Para executar uma consulta programada, você precisa ter:
- Permissões
bigquery.datasets.getno conjunto de dados de destino bigquery.jobs.create
- Permissões
Para modificar ou excluir uma consulta programada, você precisa ter as permissões
bigquery.transfers.update e bigquery.transfers.get ou a permissão
bigquery.jobs.create e a propriedade da consulta programada.
O papel predefinido do IAM Administrador do BigQuery (roles/bigquery.admin) inclui as permissões necessárias para programar ou modificar uma consulta.
Para mais informações sobre os papéis do IAM no BigQuery, consulte Papéis e permissões predefinidos.
Para criar ou atualizar consultas programadas executadas por uma conta de serviço, você precisa ter acesso a essa conta de serviço. Para mais informações sobre como conceder o papel da conta de serviço aos usuários, consulte Papel do usuário da conta de serviço. Para selecionar uma conta de serviço na interface de consulta programada do console do Google Cloud , você precisa das seguintes permissões do IAM:
iam.serviceAccounts.listpara listar suas contas de serviço.iam.serviceAccountUserpara atribuir uma conta de serviço a uma consulta programada.
Opções de configuração
As seções a seguir descrevem as opções de configuração.
String de consulta
A string de consulta precisa ser válida e escrita em GoogleSQL. Cada execução de uma consulta programada pode receber os parâmetros de consulta a seguir.
Para testar uma string de consulta manualmente com os parâmetros
@run_time e @run_date antes de programar uma consulta, use a ferramenta de linha de comando bq.
Parâmetros disponíveis
| Parâmetro | Tipo do GoogleSQL | Valor |
|---|---|---|
@run_time |
TIMESTAMP |
Representado no horário UTC. Para consultas programadas regularmente, run_time representa o ambiente de execução pretendido. Por exemplo, se a consulta programada for definida como "a cada 24 horas", a diferença de run_time entre duas consultas consecutivas será exatamente 24 horas, mesmo que o ambiente de execução real seja ligeiramente diferente. |
@run_date |
DATE |
Representa uma data do calendário lógico. |
Exemplo
Neste exemplo, o parâmetro @run_time faz parte da string de consulta, em que é consultado um
conjunto de dados público chamado hacker_news.stories.
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
Tabela de destino
Se a tabela de destino dos resultados não existir quando você configurar a consulta programada, o BigQuery tentará criar a tabela para você.
Se você estiver usando uma consulta em DDL ou DML, no console do Google Cloud , escolha a região ou o Local de processamento. Essa informação é necessária nas consultas em DDL ou DML que criam a tabela de destino.
Se a tabela de destino existir e você estiver usando a preferência de gravação WRITE_APPEND, o BigQuery anexa dados à tabela de destino e tenta mapear o esquema.
O BigQuery permite automaticamente adições e reordenações de campos, além de acomodar campos opcionais ausentes. Se o esquema da tabela mudar tanto entre as execuções que o BigQuery não conseguir processar as alterações automaticamente, a consulta programada falhará.
É possível que as colunas se refiram a tabelas de projetos e conjuntos de dados diferentes. Ao configurar a consulta programada, você não precisa incluir o conjunto de dados de destino no nome da tabela. Esse conjunto será especificado separadamente.
O conjunto de dados e a tabela de destino de uma consulta programada precisam estar no mesmo projeto que a consulta programada.
Preferência de gravação
A preferência de gravação selecionada determina como os resultados da consulta são gravados em uma tabela de destino atual.
WRITE_TRUNCATE: caso haja uma tabela, os respectivos dados serão substituídos no BigQuery.WRITE_APPEND: caso haja uma tabela, os dados serão anexados a ela no BigQuery.
Caso esteja usando uma consulta em DDL ou DML, não é possível usar a opção de preferência de gravação.
A criação, substituição ou anexação de uma tabela de destino só ocorre se a consulta for concluída no BigQuery. Essas ações ocorrem como uma atualização atômica na conclusão do job.
Cluster
As consultas programadas podem criar clustering somente em novas tabelas. Isso acontece quando as tabelas incluem uma instrução CREATE TABLE AS SELECT em DDL. Consulte
Como criar uma tabela em clusters usando o resultado de uma consulta
na página Como usar instruções de linguagem de definição
de dados.
Opções de particionamento
Nas consultas programadas, pode ocorrer a criação de tabelas de destino particionadas ou não particionadas. O particionamento está disponível no console Google Cloud , na ferramenta de linha de comando bq e nos métodos de configuração da API. Se você estiver usando uma consulta em DDL ou DML com particionamento, deixe o Campo de particionamento da tabela de destino em branco.
É possível usar os seguintes tipos de particionamento de tabelas no BigQuery:
- Particionamento por intervalo de números inteiros: tabelas particionadas com base em intervalos de valores em uma coluna
INTEGERespecífica. - Particionamento de colunas de unidade de tempo: tabelas particionadas com base em
TIMESTAMP,DATEouDATETIME. - Particionamento de tempo de ingestão: tabelas particionadas por tempo de ingestão. O BigQuery atribui linhas automaticamente às partições com base no horário em que ele ingere os dados.
Para criar uma tabela particionada usando uma consulta programada no console doGoogle Cloud , use as seguintes opções:
Para usar o particionamento por intervalo de números inteiros, deixe o campo Particionamento da tabela de destino em branco.
Para usar o particionamento de coluna de unidade de tempo, especifique o nome da coluna no campo Particionamento da tabela de destino ao configurar uma consulta programada.
Para usar o particionamento por tempo de ingestão, deixe o Campo de particionamento da tabela de destino em branco e indique o particionamento de data no nome da tabela de destino. Por exemplo,
mytable${run_date}. Para mais informações, consulte Sintaxe de modelos de parâmetros.
Parâmetros disponíveis
Ao configurar a consulta programada, é possível especificar o modo de particionamento da tabela de destino com parâmetros de tempo de execução.
| Parâmetro | Tipo de modelo | Valor |
|---|---|---|
run_time |
Carimbo de data/hora formatado | Na hora UTC, de acordo com a programação. Para consultas programadas regularmente, run_time representa o ambiente de execução pretendido. Por exemplo, se a consulta programada for definida como "a cada 24 horas", a diferença run_time entre duas consultas consecutivas será exatamente 24 horas, mesmo que o ambiente de execução real seja ligeiramente diferente.Consulte TransferRun.runTime. |
run_date |
String de data | A data do parâmetro run_time no formato a seguir: %Y-%m-%d; por exemplo, 2018-01-01. Esse formato é compatível com tabelas particionadas por tempo de ingestão. |
Sistema de modelo
As consultas programadas são compatíveis com parâmetros de tempo de execução no nome da tabela de destino com uma sintaxe de modelos.
Sintaxe de modelos de parâmetros
A sintaxe de modelos é compatível com modelos básicos de strings e ajuste de horário. A referência aos parâmetros é feita nos seguintes formatos:
{run_date}{run_time[+\-offset]|"time_format"}
| Parâmetro | Objetivo |
|---|---|
run_date |
Este parâmetro é substituído pela data no formato YYYYMMDD. |
run_time |
O parâmetro é compatível com as propriedades a seguir:
|
- Nenhum espaço em branco é permitido entre run_time, offset e time_format.
- Para incluir as chaves literais na string, insira caracteres de escape como
'\{' and '\}'. - Para incluir aspas literais ou uma barra vertical em "time_format", como
"YYYY|MM|DD", insira-os como caracteres de escape na string de formatação como'\"'ou'\|'.
Exemplos de modelos de parâmetros
Nestes exemplos, são demonstrados a especificação de nomes de tabelas de destino com formatos de tempo diferentes e o ajuste do ambiente de execução.| run_time (UTC) | Parâmetro modelado | Nome da tabela de destino da saída |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}
ou mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
Usar uma conta de serviço
É possível configurar uma consulta programada para usar uma conta de serviço como autenticação. Uma conta de serviço é uma conta especial associada ao seu projeto Google Cloud . A conta de serviço pode executar jobs, como consultas programadas ou pipelines de processamento em lote, com as próprias credenciais de serviço em vez das credenciais de um usuário final.
Para saber mais sobre usar contas de serviço como método de autenticação, consulte Introdução à autenticação.
É possível configurar a consulta programada com uma conta de serviço. Se você fez login com uma identidade federada, é necessário uma conta de serviço para criar uma transferência. Se você fez login com uma Conta do Google, uma conta de serviço para a transferência é opcional.
É possível atualizar uma consulta programada com as credenciais de uma conta de serviço com a ferramenta de linha de comando bq ou o console Google Cloud . Para mais informações, consulte Atualizar credenciais de consultas programadas.
Especificar a chave de criptografia com consultas programadas
É possível especificar chaves de criptografia gerenciadas pelo cliente (CMEKs, na sigla em inglês) para criptografar dados de uma execução de transferência. É possível usar uma CMEK para dar suporte a transferências de consultas programadas.Quando você especifica uma CMEK com uma transferência, o serviço de transferência de dados do BigQuery aplica a CMEK a qualquer cache intermediário no disco de dados ingeridos para que todo o fluxo de trabalho de transferência de dados fique em conformidade com a CMEK.
Não é possível atualizar uma transferência atual para adicionar uma CMEK se a transferência não tiver sido criada originalmente com uma CMEK. Por exemplo, não é possível alterar uma tabela de destino que, originalmente, estava criptografada por padrão, para ser criptografada com CMEKs. Por outro lado, também não é possível alterar uma tabela de destino criptografada por CMEK para ter um tipo diferente de criptografia.
É possível atualizar uma CMEK para uma transferência se a configuração de transferência tiver sido criada originalmente com uma criptografia CMEK. Quando você atualiza uma CMEK para uma configuração de transferência, o serviço de transferência de dados do BigQuery propaga a CMEK para as tabelas de destino na próxima execução da transferência, em que o serviço de transferência de dados do BigQuery substitui todas as CMEKs desatualizadas pela nova CMEK durante a execução da transferência. Para saber mais, consulte Atualizar uma transferência.
Também é possível usar as chaves padrão do projeto. Quando você especifica uma chave padrão do projeto com uma transferência, o serviço de transferência de dados do BigQuery a usa como padrão para qualquer nova configuração de transferência.
Configurar consultas programadas
Para ver uma descrição da sintaxe, consulte
Como formatar a programação.
Veja mais detalhes sobre a sintaxe de programação em Recurso: TransferConfig.
Console
Abra a página do BigQuery no console do Google Cloud .
Execute a consulta do seu interesse. Quando estiver satisfeito com os resultados, clique em Programar consulta.
As opções de consulta programada são exibidas no painel Nova consulta programada.
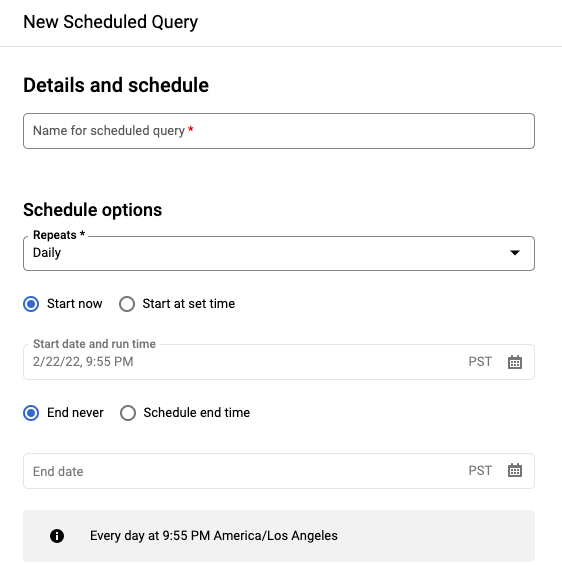
No painel Nova consulta programada:
- Em Nome da consulta programada, insira um nome, como
My scheduled query. Esse nome pode ser qualquer valor que possa ser identificado mais tarde, caso precise modificar a consulta. Opcional: por padrão, a consulta está programada para ser executada Diariamente. É possível alterar a programação padrão selecionando uma opção no menu suspenso Repete:
Para especificar uma frequência personalizada, selecione Personalizado e, em seguida, insira uma especificação de horário do tipo cron no campo Programação personalizada. Por exemplo,
every mon 23:30ouevery 6 hours: Para detalhes sobre programações válidas, incluindo intervalos personalizados, consulte o camposcheduleem Recurso:TransferConfig.
Para mudar o horário de início, selecione a opção Iniciar no horário definido e insira a data e a hora de início selecionadas.
Para especificar um horário de término, selecione a opção Programar horário de término e insira a data e a hora de término selecionadas.
Para salvar a consulta sem programação para executar sob demanda posteriormente, selecione Sob demanda no menu Repetições.
- Em Nome da consulta programada, insira um nome, como
Para uma consulta
SELECTdo GoogleSQL, selecione a opção Definir uma tabela de destino para os resultados da consulta e forneça as seguintes informações sobre o conjunto de dados de destino.- Em Nome do conjunto de dados, escolha o conjunto de dados de destino apropriado.
- Em Nome da tabela, insira o nome da tabela de destino.
Em Preferência de gravação na tabela de destino, escolha Adicionar ao final da tabela para adicionar ao final da tabela ou Substituir tabela para substituir a tabela de destino.

Escolha o Tipo de local.
Se você tiver ativado a tabela de destino para os resultados da consulta, selecione Seleção automática de local para selecionar automaticamente o local em que a tabela de destino está.
Caso contrário, escolha o local onde os dados consultados estão localizados.
Opções avançadas:
Opcional: CMEK se você usar chaves de criptografia gerenciadas pelo cliente, selecione Chave gerenciada pelo cliente em Opções avançadas. Uma lista das CMEKs disponíveis será exibida. Para informações sobre como as chaves de criptografia gerenciadas pelo cliente (CMEK) funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar chave de criptografia com consultas programadas.
Autenticar com conta de serviço. Se você tem uma ou mais contas de serviço associadas ao projeto do Google Cloud , é possível associar uma conta de serviço à consulta programada em vez de usar as credenciais de usuário. Em Credencial de consulta programada, clique no menu para ver uma lista de contas de serviço disponíveis. Uma conta de serviço é necessária se você fez login como uma identidade federada.

Outras configurações:
Opcional: marque Enviar notificações por e-mail para permitir notificações sobre falhas na execução da transferências.
Opcional: em Tópico do Pub/Sub, insira o nome do tópico do Pub/Sub. Por exemplo:
projects/myproject/topics/mytopic.
Clique em Salvar.
bq
Opção 1: use o comando bq query.
Para criar uma consulta programada, adicione as opções destination_table (ou
target_dataset), --schedule e --display_name ao
comando bq query.
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
Substitua:
name. O nome de exibição da consulta programada. Ele pode ser qualquer valor que você possa identificar posteriormente, se precisar modificar a consulta.table. A tabela de destino dos resultados da consulta.--target_dataseté uma maneira alternativa de nomear o conjunto de dados de destino para os resultados da consulta, quando usado com consultas DDL e DML.- Use
--destination_tableou--target_dataset, mas não ambos.
interval. Quando usado combq query, transforma a consulta em uma consulta programada recorrente. É necessário definir uma frequência de execução da consulta. Para detalhes sobre programações válidas, incluindo intervalos personalizados, consulte o camposcheduleem Recurso:TransferConfig. Exemplos:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
Sinalizações opcionais:
--project_idé a ID do projeto. Se--project_idnão for especificado, o projeto padrão será usado.--replacesubstitui a tabela de destino pelos resultados da consulta após cada execução da consulta programada. Todos os dados atuais são apagados. Para tabelas não particionadas, o esquema também é apagado.--append_tableanexa os resultados à tabela de destino.Nas consultas em DDL e DML, também é possível usar a sinalização
--locationpara especificar uma determinada região de processamento. Se--locationnão for especificado, será usado o local Google Cloud mais próximo.
Por exemplo, o comando a seguir usa a consulta SELECT 1 from mydataset.test para criar uma consulta programada chamada
My Scheduled Query.
A tabela de destino é mytable, no conjunto de dados mydataset. A consulta programada é criada no projeto padrão:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
Opção 2: use o comando bq mk.
As consultas programadas são um tipo de transferência. Para programar uma consulta, use a ferramenta de linha de comando bq para fazer uma configuração de transferência.
As consultas precisam estar em SQL padrão para serem programadas.
Digite o comando bq mk e forneça as seguintes sinalizações obrigatórias:
--transfer_config--data_source--target_dataset(opcional para consultas DDL e DML)--display_name--params
Sinalizações opcionais:
--project_idé a ID do projeto. Se--project_idnão for especificado, o projeto padrão será usado.--scheduleé a frequência de execução da consulta. Se--schedulenão for especificado, o padrão será "a cada 24 horas" com base no horário de criação.Nas consultas em DDL e DML, também é possível usar a sinalização
--locationpara especificar uma determinada região de processamento. Se--locationnão for especificado, será usado o local Google Cloud mais próximo.--service_account_nameserve para autenticar a consulta programada com uma conta de serviço em vez da conta de usuário individual.--destination_kms_keyespecifica o ID de recurso da chave para a chave se você usar uma chave de criptografia gerenciada pelo cliente (CMEK, na sigla em inglês) para essa transferência. Para informações sobre como as CMEKs funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar chave de criptografia com consultas programadas.
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
Substitua:
dataset. O conjunto de dados de destino na configuração da transferência.- Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras.
name. O nome de exibição da configuração de transferência. Ele pode ser qualquer valor que você possa identificar posteriormente, se precisar modificar a consulta.parameters. Contém os parâmetros da configuração de transferência criada no formato JSON. Por exemplo,--params='{"param":"param_value"}'.- Para uma consulta programada, você precisa fornecer o parâmetro
query: - O parâmetro
destination_table_name_templateé o nome da tabela de destino.- Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras.
- Para o parâmetro
write_disposition, é possível escolherWRITE_TRUNCATEpara substituir a tabela de destino ouWRITE_APPENDpara anexar os resultados da consulta a ela.- Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras.
- Para uma consulta programada, você precisa fornecer o parâmetro
data_source. É a fonte de dados:scheduled_query.- Opcional: a sinalização
--service_account_nameserve para autenticar usando uma conta de serviço em vez de uma conta de usuário individual. - Opcional: o
--destination_kms_keyespecifica o ID de recurso da chave para a chave do Cloud KMS, por exemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.
Por exemplo, o comando a seguir usa a consulta SELECT 1
from mydataset.test para criar uma configuração de transferência de consulta programada chamada My Scheduled Query. A tabela de destino mytable é substituída em todas as gravações, e o conjunto de dados de destino é mydataset. A consulta programada é criada
no projeto padrão e autenticada como conta de serviço:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
Ao executar o comando pela primeira vez, você recebe uma mensagem como esta:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções na mensagem e cole o código de autenticação na linha de comando.
API
Use o método projects.locations.transferConfigs.create e forneça uma instância do recurso TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Configurar consultas programadas com uma conta de serviço
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Visualizar o status da consulta programada
Console
Para conferir o status das suas consultas programadas, clique em Programação no menu de navegação e filtre por Consulta programada. Clique em uma consulta programada para saber mais sobre ela.
bq
As consultas programadas são um tipo de transferência. Para mostrar os detalhes de uma consulta programada, use a ferramenta de linha de comando bq para listar as configurações de transferência.
Insira o comando bq ls e forneça a sinalização de execução da transferência
--transfer_config. As sinalizações abaixo também são obrigatórias:
--transfer_location
Exemplo:
bq ls \
--transfer_config \
--transfer_location=us
Para mostrar os detalhes de uma única consulta programada, insira o comando bq show
e forneça o transfer_path da consulta programada ou da configuração de transferência.
Exemplo:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
Use o método projects.locations.transferConfigs.list e forneça uma instância do recurso TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Atualizar consultas programadas
Console
Para atualizar uma consulta programada, siga estas etapas:
- No menu de navegação, clique em Consultas programadas ou Programação.
- Na lista de consultas programadas, clique no nome da consulta que você quer alterar.
- Na página Detalhes da consulta programada que é aberta, clique em Editar.
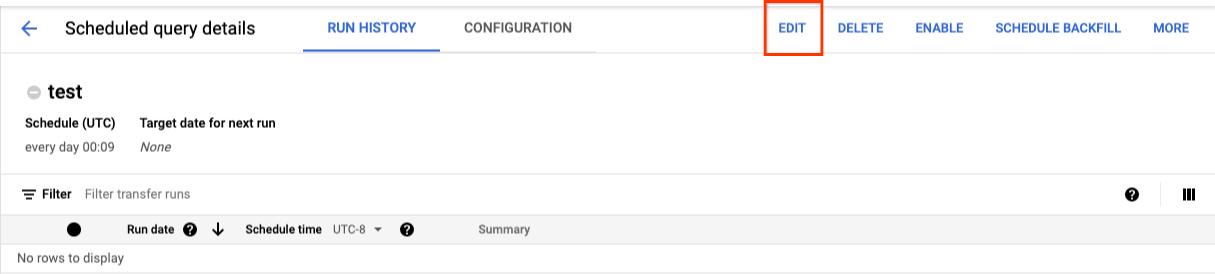
- Opcional: altere o texto da consulta no painel de edição da consulta.
- Clique em Programar consulta e selecione Atualizar consulta programada.
- Opcional: altere outras opções de programação da consulta.
- Clique em Atualizar.
bq
As consultas programadas são um tipo de transferência. Para atualizar a consulta programada, use a ferramenta de linha de comando bq para fazer uma configuração de transferência.
Insira o comando bq update com a sinalização --transfer_config
necessária.
Sinalizações opcionais:
--project_idé a ID do projeto. Se--project_idnão for especificado, o projeto padrão será usado.--scheduleé a frequência de execução da consulta. Se--schedulenão for especificado, o padrão será "a cada 24 horas" com base no horário de criação.--service_account_namesó entrará em vigor se--update_credentialstambém estiver definido. Para mais informações, consulte Atualizar credenciais de consultas programadas.--target_dataset(opcional para consultas DDL e DML) é uma maneira alternativa de nomear o conjunto de dados de destino para os resultados da consulta, quando usado com consultas DDL e DML.--display_nameé o nome da consulta programada.--paramsé o parâmetro da configuração de transferência criada no formato JSON. Por exemplo: --params='{"param":"param_value"}'.--destination_kms_keyespecifica o ID de recurso da chave para a chave do Cloud KMS se você usar uma chave de criptografia gerenciada pelo cliente (CMEK, na sigla em inglês) para essa transferência. Para informações sobre como as chaves de criptografia gerenciadas pelo cliente (CMEK) funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar chave de criptografia com consultas programadas.
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
Substitua:
dataset. O conjunto de dados de destino na configuração da transferência. Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras.name. O nome de exibição da configuração de transferência. Ele pode ser qualquer valor que você possa identificar posteriormente, se precisar modificar a consulta.parameters. Contém os parâmetros da configuração de transferência criada no formato JSON. Por exemplo,--params='{"param":"param_value"}'.- Para uma consulta programada, você precisa fornecer o parâmetro
query: - O parâmetro
destination_table_name_templateé o nome da tabela de destino. Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras. - Para o parâmetro
write_disposition, é possível escolherWRITE_TRUNCATEpara substituir a tabela de destino ouWRITE_APPENDpara anexar os resultados da consulta a ela. Esse parâmetro é opcional nas consultas DDL e DML, mas necessário em todas as outras.
- Para uma consulta programada, você precisa fornecer o parâmetro
- Opcional: o
--destination_kms_keyespecifica o ID de recurso da chave para a chave do Cloud KMS, por exemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name. RESOURCE_NAME: o nome do recurso da transferência, também conhecido como configuração da transferência. Se você não souber o nome do recurso da transferência, encontre-o com:bq ls --transfer_config --transfer_location=location.
Por exemplo, o comando a seguir usa a consulta SELECT 1
from mydataset.test para atualizar
uma configuração de transferência de consulta programada chamada My Scheduled Query. A tabela de destino mytable é substituída em todas
as gravações, e o conjunto de dados de destino é mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
Use o método projects.transferConfigs.patch e forneça o nome do recurso da transferência por meio do parâmetro transferConfig.name. Se você não souber o nome do recurso da
transferência, use o
comando bq ls --transfer_config --transfer_location=location
para listar todas as transferências ou chame o
método projects.locations.transferConfigs.list
e forneça o ID do projeto por meio do parâmetro parent.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Atualizar consultas programadas com restrições de propriedade
Se você tentar atualizar uma consulta programada que não é sua, a atualização poderá falhar com a seguinte mensagem de erro:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
O proprietário da consulta programada é o usuário associado à consulta programada ou o usuário que tem acesso à conta de serviço associada à consulta programada. O usuário associado pode ser visto nos detalhes de configuração da consulta programada. Para informações sobre como atualizar a consulta programada para ter propriedade, consulte Atualizar credenciais de consulta programada. Para conceder aos usuários acesso a uma conta de serviço, você precisa ter o papel de usuário da conta de serviço.
Os parâmetros restritos ao proprietário para consultas programadas são:
- O texto da consulta
- O conjunto de dados de destino
- O modelo de nome da tabela de destino
Atualizar as credenciais de consultas programadas
Se você estiver programando uma consulta existente, talvez precise atualizar as credenciais do usuário na consulta. As credenciais são atualizadas automaticamente para novas consultas programadas.
Algumas outras situações que podem exigir atualização de credenciais incluem:
- Você quer consultar os dados do drive em uma consulta programada.
Você recebe um erro INVALID_USER ao tentar programar a consulta:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERIDVocê recebe o seguinte erro de parâmetros restritos ao tentar atualizar a consulta:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
Console
Para atualizar as credenciais atuais de uma consulta programada:
Encontre e visualize o status de uma consulta programada.
Clique no botão MAIS e selecione Atualizar credenciais.
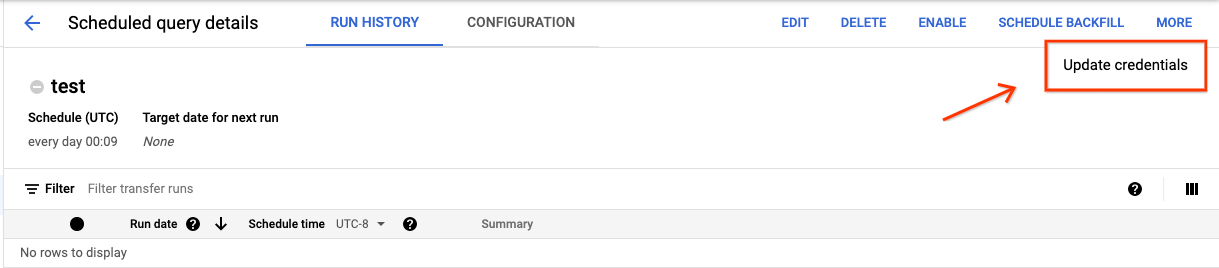
Aguarde de 10 a 20 minutos para que a alteração entre em vigor. Pode ser necessário limpar o cache do navegador.
bq
As consultas programadas são um tipo de transferência. Para atualizar as credenciais de uma consulta programada, use a ferramenta de linha de comando bq para atualizar a configuração de transferência.
Insira o comando bq update e forneça a sinalização de execução da transferência
--transfer_config. As sinalizações abaixo também são obrigatórias:
--update_credentials
Sinalização opcional:
--service_account_nameserve para autenticar a consulta programada com uma conta de serviço em vez da conta de usuário individual.
Por exemplo, o comando a seguir atualiza uma configuração de transferência de consulta programada para autenticar como conta de serviço:
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Configurar uma execução manual em datas históricas
Além de agendar uma consulta para ser executada no futuro, também é possível acionar execuções imediatas manualmente. É necessário acionar uma execução imediata se sua consulta usar o parâmetro run_date e houver problemas durante uma execução anterior.
Por exemplo: todos os dias às 9h, você consulta uma tabela de origem para as linhas que correspondem à data atual. No entanto, você acha que os dados não foram adicionados à tabela de origem nos últimos três dias. Nessa situação, é possível definir a consulta para ser executada em
dados históricos em um período que você especificar. Ela será executada usando
combinações de parâmetros run_date e run_time que correspondem às datas que você
configurou na consulta programada.
Depois de configurar uma consulta programada, veja como executar a consulta usando um período histórico:
Console
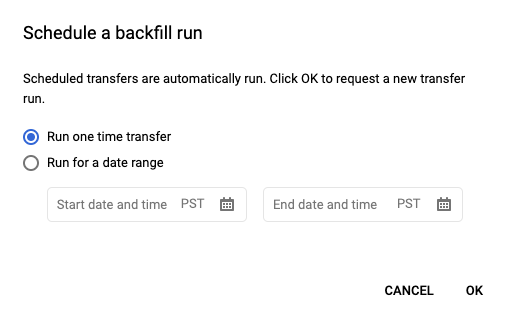
Depois de clicar em Programar para salvar a consulta, clique no botão Consultas programadas para ver todas as consultas relacionadas. Clique em qualquer nome de exibição para ver os detalhes da programação de consulta. No canto superior direito da página, clique em Programar preenchimento para especificar um período histórico.
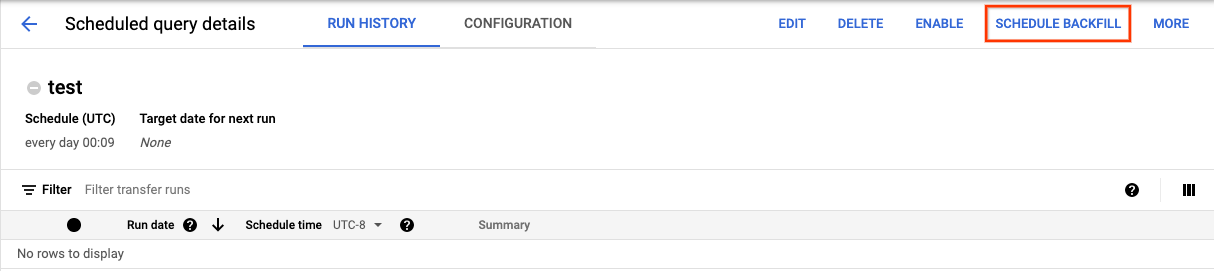
Os ambientes de execução escolhidos estão todos no intervalo selecionado, incluindo a primeira data e excluindo a última data.
Exemplo 1
A consulta programada está definida para ser executada every day 09:00 no horário do Pacífico. Faltam
dados de 1º, 2 e 3 de janeiro. Escolha o período histórico
de dados a seguir:
Start Time = 1/1/19
End Time = 1/4/19
Sua consulta será executada usando os parâmetros run_date e run_time que correspondem aos horários a seguir:
- 01/01/19 às 9h, horário do Pacífico
- 02/01/19 às 9h, horário do Pacífico
- 03/01/19 às 9h, horário do Pacífico
Exemplo 2
A consulta programada está definida para ser executada every day 23:00 no horário do Pacífico. Faltam
dados de 1º, 2 e 3 de janeiro. Escolha os períodos históricos de dados a seguir. Datas posteriores são escolhidas porque o UTC tem uma data diferente às
23h, horário do Pacífico:
Start Time = 1/2/19
End Time = 1/5/19
Sua consulta será executada usando os parâmetros run_date e run_time que correspondem aos horários a seguir:
- 02/01/19 às 6h UTC ou 01/01/2019 às 23h, horário do Pacífico
- 03/01/19 às 6h UTC ou 02/01/2019 às 23h, horário do Pacífico
- 04/01/19 às 6h UTC ou 03/01/2019 às 23h, horário do Pacífico
Depois de configurar execuções manuais, atualize a página para vê-las na lista de execuções.
bq
Para executar manualmente a consulta em um período histórico:
Insira o comando bq mk e forneça a sinalização de execução de transferência --transfer_run. As sinalizações abaixo também são obrigatórias:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
Substitua:
start_timeeend_time. Os carimbos de data/hora que terminam em Z ou contêm um deslocamento de fuso horário válido. Exemplos:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name. O nome de recurso da transferência ou consulta programada. Ele também é conhecido como a configuração da transferência.
Por exemplo, o comando a seguir programa um preenchimento para o recurso de consulta
programada (ou configuração de transferência):
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7.
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Para ver mais informações, consulte bq mk --transfer_run.
API
Use o método projects.locations.transferConfigs.scheduleRun e forneça um caminho do recurso TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Configurar alertas para consultas programadas
É possível configurar políticas de alertas para consultas programadas com base em métricas de contagem de linhas. Para mais informações, consulte Configurar alertas com consultas programadas.
Excluir consultas programadas
Console
Para excluir uma consulta programada na página Consultas programadas do console Google Cloud , faça o seguinte:
- No menu de navegação, clique em Consultas programadas.
- Na lista de consultas programadas, clique no nome da consulta que você quer excluir.
Na página Detalhes da consulta programada, clique em Excluir.
Também é possível excluir uma consulta programada na página Programação do console do Google Cloud :
- No menu de navegação, clique em Programação.
- Na lista de consultas programadas, clique no menu Ações da consulta que você quer excluir.
Selecione Excluir.

Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Desativar ou ativar consultas programadas
Para pausar as execuções programadas de uma consulta selecionada sem excluir a programação, desative a programação.
Para desativar uma programação de uma consulta selecionada, siga estas etapas:
- No menu de navegação do console Google Cloud , clique em Programação.
- Na lista de consultas programadas, clique no menu Ações da consulta que você quer desativar.
Selecione Disable.

Para ativar uma consulta programada desativada, clique no menu Ações da consulta que você quer ativar e selecione Ativar.
Cotas
As consultas programadas são sempre executadas como jobs de consulta em lote e estão sujeitas às mesmas cotas e limites do BigQuery que as consultas manuais.
As consultas programadas usam recursos do serviço de transferência de dados do BigQuery, mas não são transferências e não estão sujeitas à cota de jobs de carregamento.
A identidade usada para executar a consulta determina quais cotas são aplicadas. Isso depende da configuração da consulta programada:
Credenciais do criador (padrão): se você não especificar uma conta de serviço, a consulta programada será executada usando as credenciais do usuário que a criou. O trabalho de consulta é cobrado do projeto do criador e está sujeito às cotas desse usuário e projeto.
Credenciais da conta de serviço: se você configurar a consulta programada para usar uma conta de serviço, ela será executada com as credenciais dessa conta. Nesse caso, o job ainda é faturado para o projeto que contém a consulta programada, mas a execução está sujeita às cotas da conta de serviço especificada.
Preços
As consultas programadas têm o mesmo preço das consultas manuais do BigQuery.
Regiões compatíveis
As consultas programadas são compatíveis nos locais a seguir.
Regiões
A tabela a seguir lista as regiões das Américas em que o BigQuery está disponível.| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Las Vegas | us-west4 |
|
| Los Angeles | us-west2 |
|
| México | northamerica-south1 |
|
| Montreal | northamerica-northeast1 |
|
| Norte da Virgínia | us-east4 |
|
| Oregon | us-west1 |
|
| Salt Lake City | us-west3 |
|
| São Paulo | southamerica-east1 |
|
| Santiago | southamerica-west1 |
|
| Carolina do Sul | us-east1 |
|
| Toronto | northamerica-northeast2 |
|
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Délhi | asia-south2 |
|
| Hong Kong | asia-east2 |
|
| Jacarta | asia-southeast2 |
|
| Melbourne | australia-southeast2 |
|
| Mumbai | asia-south1 |
|
| Osaka | asia-northeast2 |
|
| Seul | asia-northeast3 |
|
| Singapura | asia-southeast1 |
|
| Sydney | australia-southeast1 |
|
| Taiwan | asia-east1 |
|
| Tóquio | asia-northeast1 |
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Bélgica | europe-west1 |
|
| Berlim | europe-west10 |
|
| Finlândia | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| Londres | europe-west2 |
|
| Madri | europe-southwest1 |
|
| Milão | europe-west8 |
|
| Países Baixos | europe-west4 |
|
| Paris | europe-west9 |
|
| Estocolmo | europe-north2 |
|
| Turim | europe-west12 |
|
| Varsóvia | europe-central2 |
|
| Zurique | europe-west6 |
|
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Damã | me-central2 |
|
| Doha | me-central1 |
|
| Tel Aviv | me-west1 |
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Johannesburgo | africa-south1 |
Locais multirregionais
Veja na tabela a seguir as multirregiões onde o BigQuery está disponível.| Descrição multirregional | Nome multirregional |
|---|---|
| Data centers dentro de estados membro da União Europeia1 | EU |
| Data centers nos Estados Unidos2 | US |
1 Os dados localizados na multirregião EU são armazenados apenas
em um dos seguintes locais: europe-west1 (Bélgica) ou europe-west4 (Países Baixos).
O BigQuery determina automaticamente o local exato em que os dados são armazenados e processados.
2 Os dados localizados na multirregião US são armazenados apenas em um dos seguintes locais: us-central1 (Iowa), us-west1 (Oregon) ou us-central2 (Oklahoma). O local exato em que os dados são armazenados e processados é determinado automaticamente pelo BigQuery.
A seguir
- Veja um exemplo de consulta programada que usa uma conta de serviço e inclui
os parâmetros
@run_datee@run_timeem Como criar snapshots da tabela com uma consulta programada.