BigQuery で Salesforce Data Cloud のデータを操作する
Data Cloud ユーザーは、BigQuery でネイティブに Data Cloud データにアクセスできます。BigQuery Omni で Data Cloud のデータを分析し、 Google Cloudのデータを使用してクロスクラウド分析を行うことができます。このドキュメントでは、Data Cloud データへのアクセス方法と、BigQuery でそのデータを使用して実行できる分析タスクについて説明します。
Data Cloud は、次のアーキテクチャに基づいて BigQuery と連携します。
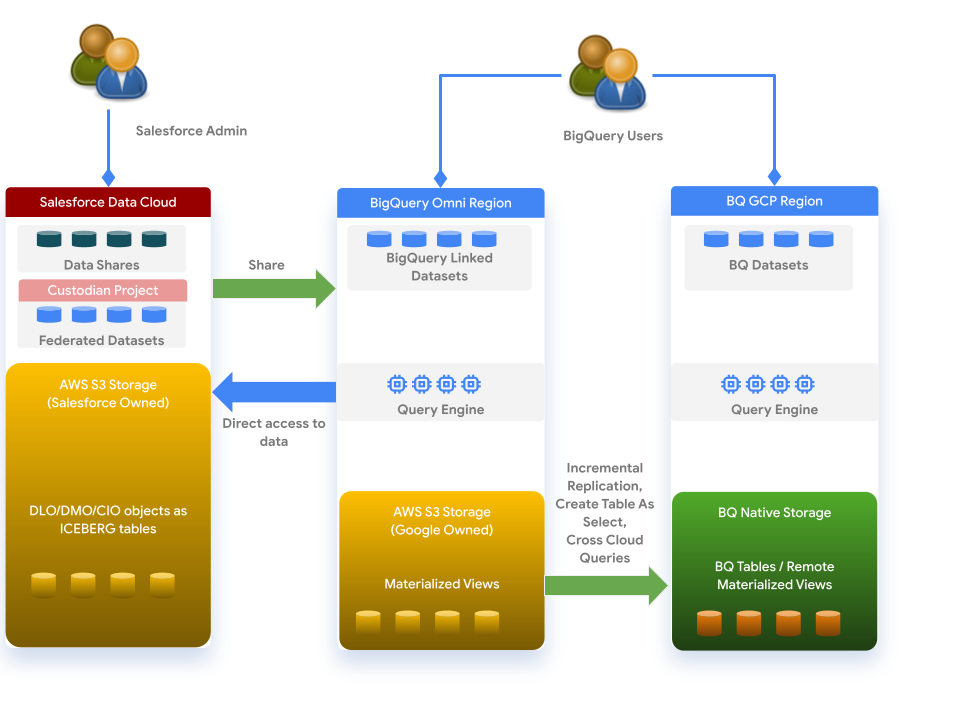
始める前に
Data Cloud データを操作するには、Data Cloud ユーザーである必要があります。プロジェクトで VPC Service Controls が有効になっている場合は、追加の権限が必要です。
必要なロール
次のロールと権限が必要です。
- Analytics Hub サブスクライバー(
roles/analyticshub.subscriber) - BigQuery 管理者(
roles/bigquery.admin)
Data Cloud のデータを共有する
Data Cloud から BigQuery にデータを共有する方法については、Data Shares - Zero-ETL Integration with BigQuery をご覧ください。
Data Cloud データセットを BigQuery にリンクする
BigQuery で Data Cloud データセットにアクセスするには、まず次の手順でデータセットを BigQuery にリンクする必要があります。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[Salesforce Data Cloud] をクリックします。
Data Cloud のデータセットが表示されます。次の命名パターンのデータセット名を探します。
listing_DATA_SHARE_NAME_TARGET_NAME
DATA_SHARE_NAME: Data Cloud 内のデータ共有の名前。TARGET_NAME: Data Cloud の BigQuery ターゲットの名前。
BigQuery に追加するデータセットをクリックします。
[データセットをプロジェクトに追加] をクリックします。
リンクされたデータセットの名前を指定します。
リンクされたデータセットが作成されたら、データセットとそこにあるテーブルを調べることができます。テーブルのメタデータはすべて、Data Cloud から動的に取得されます。データセット内のすべてのオブジェクトは、Data Cloud オブジェクトにマッピングされるビューです。BigQuery は、次の 3 種類の Data Cloud オブジェクトをサポートしています。
- データレイク オブジェクト(DLO)
- データモデル オブジェクト(DMO)
- 計算済みインサイト オブジェクト(CIO)
BigQuery では、これらのオブジェクトはすべてビューとして表されます。これらのビューは、Amazon S3 に保存されている非表示テーブルを参照します。
Data Cloud データを操作する
次の例では、Data Cloud にホストされている Northwest Trail Outfitters(NTO)というデータセットを使用します。このデータセットは、NTO 組織のオンライン販売データを表す 3 つのテーブルで構成されています。
linked_nto_john.nto_customers__dlllinked_nto_john.nto_products__dlllinked_nto_john.nto_orders__dll
これらの例では、オフライン販売データのデータセットも使用されています。これはオフライン販売を対象としており、次の 3 つのテーブルで構成されています。
nto_pos.customersnto_pos.productsnto_pos.orders
次のデータセットには、追加のオブジェクトが保存されます。
aws_dataus_data
アドホック クエリを実行する
BigQuery Omni を使用すると、アドホック クエリを実行し、サブスクライブしたデータセットを使用して Data Cloud データを分析できます。次の例は、Data Cloud から customers テーブルに対してクエリを実行する簡単なクエリを示しています。
SELECT name__c, age__c FROM `listing_nto_john.nto_customers__dll` WHERE age > 40 LIMIT 1000;
クロスクラウド クエリを実行する
クロスクラウド クエリを使用すると、BigQuery Omni リージョン内の任意のテーブルと BigQuery リージョン内のテーブルを結合できます。クロスクラウド クエリの詳細については、こちらのブログ投稿をご覧ください。この例では、john という名前の顧客の売上合計を取得します。
-- Get combined sales for a customer from both offline and online sales USING ( SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' UNION ALL SELECT total_price FROM `listing_nto_john.nto_orders__dll` WHERE customer_name = 'john' ) a SELECT SUM(total_price);
CTAS によるクロスクラウド データ転送
Create Table As Select(CTAS)を使用すると、BigQuery Omni リージョンの Data Cloud テーブルから US リージョンにデータを移動できます。
-- Move all the orders for March to the US region CREATE OR REPLACE TABLE us_data.online_orders_march AS SELECT * FROM listing_nto_john.nto_orders__dll WHERE EXTRACT(MONTH FROM order_time) = 3
宛先テーブルは、US リージョンの BigQuery マネージド テーブルです。このテーブルは他のテーブルと結合できます。このオペレーションでは、転送するデータの量に基づいて AWS 下り(外向き)料金が発生します。
データの移行後は、online_orders_march テーブルで実行されるクエリに対して下り(外向き)料金は発生しません。
クロスクラウド マテリアライズド ビュー
クロスクラウド マテリアライズド ビュー(CCMV)は、BigQuery Omni リージョンから BigQuery Omni 以外の BigQuery リージョンにデータを段階的に転送します。オンライン トランザクションから総売上の概要を転送する新しい CCMV を設定し、そのデータを US リージョンに複製します。
Ads Data Hub から CCMV にアクセスして、他の Ads Data Hub データと結合できます。ほとんどの場合、CCMV は通常の BigQuery マネージド テーブルのように機能します。
ローカル マテリアライズド ビューを作成する
ローカル マテリアライズド ビューを作成するには:
-- Create a local materialized view that keeps track of total sales by day CREATE MATERIALIZED VIEW `aws_data.total_sales` OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT EXTRACT(DAY FROM order_time) AS date, SUM(order_total) as sales FROM `listing_nto_john.nto_orders__dll` GROUP BY 1;
マテリアライズド ビューを承認する
CCMV を作成するには、マテリアライズド ビューを承認する必要があります。ビュー(aws_data.total_sales)またはデータセット(aws_data)のいずれかを承認できます。マテリアライズド ビューを承認するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
ソース データセット
listing_nto_johnを開きます。[共有] をクリックし、[データセットを承認] をクリックします。
データセット名(この場合は
listing_nto_john)を入力し、[OK] をクリックします。
レプリカ マテリアライズド ビューを作成する
US リージョンに新しいレプリカ マテリアライズド ビューを作成します。マテリアライズド ビューは、ソースデータが変更されるたびにレプリケーションを行い、レプリカを最新の状態に保ちます。
-- Create a replica MV in the us region. CREATE MATERIALIZED VIEW `us_data.total_sales_replica` AS REPLICA OF `aws_data.total_sales`;
レプリカ マテリアライズド ビューでクエリを実行する
次の例では、レプリカ マテリアライズド ビューに対してクエリを実行します。
-- Find total sales for the current month for the dashboard SELECT EXTRACT(MONTH FROM CURRENT_DATE()) as month, SUM(sales) FROM us_data.total_sales_replica WHERE month = EXTRACT(MONTH FROM date) GROUP BY 1
INFORMATION_SCHEMA による Data Cloud のデータの使用
Data Cloud のデータセットは、BigQuery の INFORMATION_SCHEMA ビューをサポートしています。INFORMATION_SCHEMA ビューのデータは Data Cloud から定期的に同期されるため、データが古い可能性があります。TABLES ビューと SCHEMATA ビューの SYNC_STATUS 列には、最後に行った同期時刻、BigQuery が最新データを提供できないエラー、エラーを修正するために必要な手順が表示されます。
INFORMATION_SCHEMA クエリでは、最初の同期の前に作成されたデータセットは反映されません。
Data Cloud データセットには、データセット スコープのクエリで INFORMATION_SCHEMA でのみアクセスできるなど、他のリンクされたデータセットと同じ制限があります。
次のステップ
BigQuery Omni について確認する。
クロスクラウド結合について確認する。
マテリアライズド ビューについて確認する。