Carregar dados do Amazon S3 no BigQuery
É possível carregar dados do Amazon S3 para o BigQuery usando o conector do serviço de transferência de dados do BigQuery para o Amazon S3. Com o serviço de transferência de dados do BigQuery, é possível programar jobs de transferência recorrentes que adicionam seus dados mais recentes do Amazon S3 ao BigQuery.
Antes de começar
Antes de criar uma transferência de dados do Amazon S3, siga estas recomendações:
- Verifique se você realizou todas as ações necessárias para ativar o serviço de transferência de dados do BigQuery.
- Crie um conjunto de dados do BigQuery para armazenar os dados.
- Crie a tabela de destino da transferência de dados e especifique a definição do esquema. Ela precisa seguir as regras de nomenclatura de tabela. O nome da tabela de destino também aceita parâmetros.
- Recupere seu URI do Amazon S3, seu código de chave de acesso e sua chave de acesso secreta. Para mais informações sobre como gerenciar suas chaves de acesso, consulte a documentação da AWS.
- Se você pretende configurar notificações de execução de transferência do Pub/Sub,
é preciso ter permissões
pubsub.topics.setIamPolicy. As permissões do Pub/Sub não serão necessárias se você configurar notificações por e-mail. Para mais informações, consulte Notificações de execução do serviço de transferência de dados do BigQuery.
Limitações
As transferências de dados do Amazon S3 estão sujeitas às limitações a seguir:
- No momento, não é possível parametrizar a parte do bucket do URI do Amazon S3.
- As transferências de dados do Amazon S3 com o parâmetro Disposição de gravação definido como
WRITE_TRUNCATEtransferem todos os arquivos correspondentes para Google Cloud durante cada execução. Isso pode resultar em custos adicionais de transferência de dados de saída do Amazon S3. Para mais informações sobre quais arquivos são transferidos durante uma execução, consulte Impacto da correspondência de prefixos versus correspondência de caracteres curinga. - As transferências de dados da região AWS GovCloud (
us-gov) não são compatíveis. - As transferências de dados para locais do BigQuery Omninão são compatíveis.
Dependendo do formato dos dados de origem do Amazon S3, pode haver outras limitações. Veja mais informações aqui:
O tempo mínimo de intervalo entre transferências de dados recorrentes é de 1 hora. O intervalo padrão para uma transferência de dados recorrente é a cada 24 horas.
Permissões necessárias
Antes de criar uma transferência de dados do Amazon S3, siga estas recomendações:
Certifique-se de que a pessoa que está criando a transferência de dados tenha as seguintes permissões necessárias no BigQuery:
- Permissões
bigquery.transfers.updatepara criar a transferência de dados - Permissões
bigquery.datasets.getebigquery.datasets.updateno conjunto de dados de destino
O papel predefinido
bigquery.admindo IAM inclui permissõesbigquery.transfers.update,bigquery.datasets.updateebigquery.datasets.get. Para mais informações sobre os papéis do IAM no serviço de transferência de dados do BigQuery, consulte o controle de acesso.- Permissões
Consulte a documentação do Amazon S3 para garantir que você tenha configurado as permissões necessárias para ativar a transferência de dados. No mínimo, os dados de origem do Amazon S3 precisam ter a política
AmazonS3ReadOnlyAccess(em inglês) gerenciada pela AWS aplicada a eles.
Configurar uma transferência de dados do Amazon S3
Para criar uma transferência de dados do Amazon S3:
Console
Acesse a página "Transferências de dados" no console Google Cloud .
Clique em Criar transferência.
Na página Criar transferência:
Na seção Tipo de origem, em Origem, escolha Amazon S3.

No campo Nome de exibição da seção Transferir nome da configuração, insira um nome para a transferência, como
My Transfer. O nome da transferência pode ser qualquer valor que permita identificá-la, caso você precise modificá-la mais tarde.
Na seção Opções de programação, faça o seguinte:
Selecione uma Frequência de repetição. Se você selecionar Horas, Dias, Semanas ou Meses, também precisará especificar uma frequência. Também é possível selecionar Personalizada para criar uma frequência de repetição mais específica. Se você selecionar On demand, essa transferência de dados só vai ser executada quando você acioná-la manualmente.
Se aplicável, selecione Começar agora ou Começar no horário definido e escolha uma data de início e um horário de execução.
No campo Conjunto de dados de destino da seção Configurações de destino, escolha o conjunto criado para armazenar seus dados.
Na seção Detalhes da fonte de dados, faça o seguinte:
- Em Tabela de destino, insira o nome da tabela criada para armazenar os dados no BigQuery. Os nomes de tabelas de destino aceitam parâmetros.
- Em URI do Amazon S3, insira o URI com o formato
s3://mybucket/myfolder/.... Os URIs também aceitam parâmetros. - Para Código da chave de acesso, insira seu código de chave de acesso.
- Em Chave de acesso secreta, insira sua chave de acesso secreta.
- Em Formato do arquivo, escolha seu formato de dados: JSON delimitado por nova linha, CSV, Avro, Parquet ou ORC.
- Em Disposição de gravação, escolha uma das seguintes opções:
WRITE_APPENDpara anexar novos dados de maneira incremental à tabela de destino atual.WRITE_APPENDé o valor padrão da preferência de gravação.WRITE_TRUNCATEpara substituir os dados na tabela de destino durante cada execução de transferência de dados.
Para mais informações sobre como o serviço de transferência de dados do BigQuery ingere dados usando
WRITE_APPENDouWRITE_TRUNCATE, consulte Ingestão de dados para Transferências do Amazon S3 Para mais informações sobre o campowriteDisposition, consulteJobConfigurationLoad.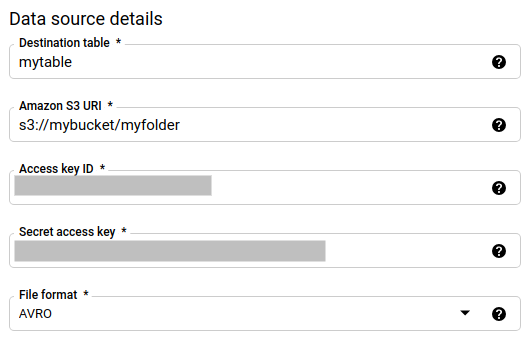
Na seção Opções de transferência. Todos os formatos:
- Em Número de erros permitidos, insira um valor inteiro para o número máximo de registros inválidos que podem ser ignorados.
- (Opcional) Em Tipos de destino decimal, insira uma lista separada por vírgulas de possíveis tipos de dados SQL em que os valores decimais de origem podem ser convertidos. O tipo de dados SQL selecionado para conversão depende das seguintes condições:
- O tipo de dados selecionado para a conversão será o primeiro da lista a seguir que for compatível com a precisão e a escalonabilidade dos dados de origem, nesta ordem: NUMERIC, BIGNUMERIC e STRING.
- Se nenhum dos tipos de dados listados for compatível com a precisão e a escala, será selecionado o tipo de dados que aceita o intervalo mais amplo na lista especificada. Se um valor exceder o intervalo compatível durante a leitura dos dados de origem, um erro será gerado.
- O tipo de dados STRING é compatível com todos os valores de precisão e escala.
- Se este campo for deixado em branco, o tipo de dados será padronizado como NUMERIC,STRING para ORC e NUMERIC para os outros formatos de arquivo.
- Este campo não pode conter tipos de dados duplicados.
- A ordem dos tipos de dados listados nesse campo é ignorada.

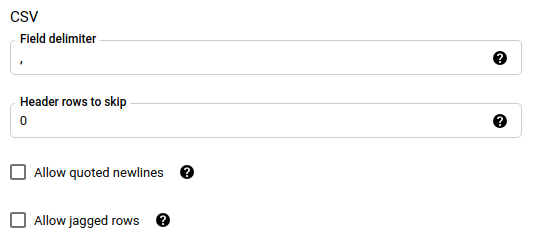
Se você escolheu CSV ou JSON como seu formato de arquivo, na seção JSON, CSV, marque Ignorar valores desconhecidos para aceitar linhas que contenham valores que não correspondam ao esquema. Valores desconhecidos são ignorados. Para arquivos CSV, essa opção ignora valores extras no final de uma linha.

Se você escolheu CSV como seu formato de arquivo, na seção CSV, insira outras opções CSV para carregar dados.
No menu Conta de serviço, selecione uma conta de serviço entre aquelas associadas ao Google Cloud projeto. É possível associar uma conta de serviço à transferência de dados em vez de usar suas credenciais de usuário. Para saber mais sobre o uso de contas de serviço com transferências de dados, consulte Usar contas de serviço.
- Se você fez login com uma identidade federada, é necessário uma conta de serviço para criar uma transferência de dados. Se você fez login com uma Conta do Google, uma conta de serviço para a transferência de dados é opcional.
- A conta de serviço precisa ter as permissões necessárias.
(Opcional) Na seção Opções de notificação, faça o seguinte:
- Clique no botão para ativar as notificações por e-mail. Quando você ativa essa opção, o administrador de transferência recebe uma notificação por e-mail quando uma execução de transferência de dados falha.
- Para Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar tópico. Essa opção configura notificações de execução do Pub/Sub para a transferência de dados.
Clique em Salvar.
bq
Insira o comando bq mk e forneça a sinalização de execução da transferência
--transfer_config.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
Em que:
- project_id: opcional. O ID do seu projeto Google Cloud .
Se
--project_idnão for fornecido para especificar um projeto determinado, o projeto padrão será usado. - data_source: obrigatório. É a fonte de dados:
amazon_s3; - display_name: obrigatório. O nome de exibição da configuração da transferência de dados. O nome da transferência pode ser qualquer valor que permita identificá-la, caso você precise modificá-la mais tarde.
- dataset: obrigatório. O conjunto de dados de destino na configuração da transferência de dados.
- service_account: o nome da conta de serviço usado para autenticar a transferência de dados. A conta de serviço
precisa pertencer ao mesmo
project_idusado para criar a transferência de dados e ter todas as permissões necessárias. parameters: obrigatório. São os parâmetros da configuração de transferência criada no formato JSON. Por exemplo:
--params='{"param":"param_value"}'. Veja a seguir os parâmetros de uma transferência do Amazon S3:- destination_table_name_template: obrigatório. É o nome da tabela de destino.
data_path: obrigatório. É o URI do Amazon S3 neste formato:
s3://mybucket/myfolder/...Os URIs também aceitam parâmetros.
access_key_id: obrigatório. É o ID da chave de acesso.
secret_access_key: obrigatório. É a chave de acesso secreta.
file_format: opcional. Indica o tipo de arquivo que você quer transferir:
CSV,JSON,AVRO,PARQUETouORC. O valor padrão éCSV.write_disposition: opcional.
WRITE_APPENDtransfere apenas os arquivos que foram modificados desde a execução anterior. OWRITE_TRUNCATEvai transferir todos os arquivos correspondentes, incluindo os que foram transferidos em uma execução anterior. O padrão éWRITE_APPEND.max_bad_records: opcional. É o número de registros inválidos permitidos. O padrão é
0.decimal_target_types: opcional. Uma lista separada por vírgulas de possíveis tipos de dados SQL em que os valores decimais de origem podem ser convertidos. Se este campo não for fornecido, o tipo de dados será padronizado como "NUMERIC,STRING" para ORC e "NUMERIC" para os outros formatos de arquivo.
ignore_unknown_values: opcional e ignorado se file_format não for
JSONouCSV. Define se valores desconhecidos nos seus dados serão ignorados.field_delimiter: opcional e aplicável somente quando
file_formatéCSV. É o caractere que separa os campos. O valor padrão é a vírgula.skip_leading_rows: opcional e aplicável somente quando file_format é
CSV. Indica o número de linhas de cabeçalho que você não quer importar. O valor padrão é0.allow_quoted_newlines: opcional e aplicável somente quando file_format é
CSV. Indica se novas linhas são permitidas dentro de campos entre aspas.allow_jagged_rows: opcional e aplicável somente quando file_format é
CSV. Indica se você aceitará linhas que estão faltando em colunas opcionais. Os valores em falta são preenchidos com NULLs.
Por exemplo, o comando a seguir cria uma transferência de dados do Amazon S3 chamada
My Transfer usando o valor data_path de
s3://mybucket/myfile/*.csv, o conjunto de dados de destino mydataset e o file_format
CSV. Este exemplo inclui valores não padrão para os parâmetros opcionais associados ao CSV file_format.
A transferência de dados é criada no projeto padrão:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
Após executar o comando, você recebe uma mensagem semelhante a esta:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções e cole o código de autenticação na linha de comando.
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso
TransferConfig.
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Java.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Impacto da correspondência de prefixos e de caracteres curinga
A API Amazon S3 é compatível com a correspondência de prefixos, e não com a de caracteres curinga. Todos os arquivos do Amazon S3 que correspondem a um prefixo são transferidos para Google Cloud. No entanto, só aqueles que correspondem ao URI do Amazon S3 na configuração de transferência são realmente carregados no BigQuery. Isso pode resultar em custos excessivos de transferência de dados de saída do Amazon S3 relacionados aos arquivos que são transferidos, mas não carregados no BigQuery.
Por exemplo, veja este caminho de dados:
s3://bucket/folder/*/subfolder/*.csv
Com esses arquivos no local de origem também estão:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
Isso faz com que todos os arquivos do Amazon S3 com o prefixo s3://bucket/folder/ sejam transferidos para Google Cloud. Nesse exemplo, os itens file1.csv e file2.csv serão transferidos.
No entanto, somente arquivos correspondentes a s3://bucket/folder/*/subfolder/*.csv serão carregados no BigQuery. Nesse exemplo, apenas file1.csv será carregado no BigQuery.
Resolver problemas na configuração da transferência
Se você estiver com problemas para configurar a transferência de dados, consulte Problemas de transferência do Amazon S3.
A seguir
- Para uma introdução às transferências de dados do Amazon S3, consulte Visão geral das transferências do Amazon S3.
- Consulte Introdução ao serviço de transferência de dados do BigQuery para uma visão geral desse serviço.
- Para informações sobre o uso de transferências de dados, incluindo ver detalhes sobre a configuração, listar configurações e visualizar o histórico de execução, consulte Como trabalhar com transferências.
- Saiba como carregar dados com operações entre nuvens.