Exécuter une requête
Ce document explique comment exécuter une requête dans BigQuery et connaître la quantité de données que la requête va traiter avant son exécution en effectuant un dry run (test à blanc).
Types de requêtes
Vous pouvez interroger des données BigQuery à l'aide de l'un des types de job de requête suivants :
Tâches de requête interactives. Par défaut, BigQuery exécute les requêtes en tant que tâches de requête interactives, qui sont censées commencer à s'exécuter le plus rapidement possible.
Tâches de requête par lot Les requêtes par lot ont une priorité inférieure à celle des requêtes interactives. Lorsqu'un projet ou une réservation utilise toutes ses ressources de calcul disponibles, les requêtes par lot sont plus susceptibles d'être mises en file d'attente et d'y rester. Une fois qu'une requête par lot a commencé à s'exécuter, elle fonctionne de la même manière qu'une requête interactive. Pour en savoir plus, consultez la section Files d'attente de requêtes.
Jobs de requête continue. Avec ces jobs, la requête s'exécute en continu, ce qui vous permet d'analyser les données entrantes dans BigQuery en temps réel, puis d'écrire les résultats dans une table BigQuery ou de les exporter vers Bigtable ou Pub/Sub. Grâce à cette fonctionnalité, vous pouvez effectuer des tâches urgentes, telles que la création et l'action immédiate sur les insights, l'application d'inférences de machine learning (ML) en temps réel et la création de pipelines de données basés sur des événements.
Vous pouvez exécuter des jobs de requête à l'aide des méthodes suivantes :
- Rédigez et exécutez une requête dans la consoleGoogle Cloud .
- Exécutez la commande
bq querydans l'outil de ligne de commande bq. - Appelez de manière automatisée la méthode
jobs.queryoujobs.insertdans l'API REST BigQuery. - Utilisez les bibliothèques clientes BigQuery.
BigQuery enregistre les résultats de la requête dans une table temporaire (par défaut) ou dans une table permanente. Lorsque vous spécifiez une table permanente comme table de destination pour les résultats, vous pouvez choisir d'ajouter ou d'écraser une table existante, ou de créer une table avec un nom unique.
Rôles requis
Pour obtenir les autorisations nécessaires pour exécuter un job de requête, demandez à votre administrateur de vous accorder les rôles IAM suivants :
-
Utilisateur de job BigQuery (
roles/bigquery.jobUser) sur le projet. -
Lecteur de données BigQuery (
roles/bigquery.dataViewer) sur toutes les tables et vues auxquelles votre requête fait référence. Pour interroger des vues, vous devez également disposer de ce rôle sur toutes les tables et vues sous-jacentes. Si vous utilisez des vues autorisées ou des ensembles de données autorisés, vous n'avez pas besoin d'accéder aux données sources sous-jacentes.
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour exécuter un job de requête. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour exécuter un job de requête :
-
bigquery.jobs.createsur le projet à partir duquel la requête est exécutée, quel que soit l'emplacement de stockage des données. -
bigquery.tables.getDatasur toutes les tables et vues auxquelles votre requête fait référence. Pour interroger des vues, vous devez également disposer de cette autorisation sur toutes les tables et vues sous-jacentes. Si vous utilisez des vues autorisées ou des ensembles de données autorisés, vous n'avez pas besoin d'accéder aux données sources sous-jacentes.
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Dépannage
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Cette erreur se produit lorsqu'un compte principal ne dispose pas de l'autorisation nécessaire pour créer des jobs de requête dans le projet.
Solution : Un administrateur doit vous accorder l'autorisation bigquery.jobs.create sur le projet que vous interrogez. Cette autorisation est requise en plus de toute autorisation requise pour accéder aux données interrogées.
Pour plus d'informations sur les autorisations BigQuery, consultez la page Contrôle des accès avec IAM.
Exécuter une requête interactive
Pour exécuter une requête interactive, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Cliquez sur Requête SQL.
Dans l'éditeur de requête, saisissez une requête GoogleSQL valide.
Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Vous pouvez également utiliser le panneau "Référence" pour créer des requêtes.
Facultatif : Pour afficher automatiquement des suggestions de code lorsque vous saisissez une requête, cliquez sur Plus, puis sélectionnez Saisie semi-automatique SQL. Si vous n'avez pas besoin de suggestions de saisie semi-automatique, désélectionnez Saisie semi-automatique SQL. Cela désactive également les suggestions de saisie automatique du nom du projet.
Facultatif : Pour sélectionner des paramètres de requête supplémentaires, cliquez sur Plus, puis sur Paramètres de requête.
Cliquez sur Exécuter.
Si vous ne spécifiez pas de table de destination, le job de requête écrit la sortie dans une table (en cache) temporaire.
Vous pouvez maintenant explorer les résultats de la requête dans l'onglet Résultats du volet Résultats de la requête.
Facultatif : Pour trier les résultats de la requête par colonne, cliquez sur Ouvrir le menu de tri à côté du nom de la colonne et sélectionnez un ordre de tri. Si le nombre d'octets estimés pris en compte pour le tri est supérieur à zéro, il s'affiche en haut du menu.
Facultatif : Pour visualiser les résultats de votre requête, accédez à l'onglet Visualisation. Vous pouvez faire un zoom avant ou arrière sur le graphique, le télécharger au format PNG ou activer/désactiver la visibilité de la légende.
Dans le volet Configuration de la visualisation, vous pouvez modifier le type de visualisation et configurer les mesures et les dimensions de la visualisation. Les champs de ce volet sont préremplis avec la configuration initiale déduite du schéma de la table de destination de la requête. La configuration est conservée entre les exécutions de requêtes suivantes dans le même éditeur de requête.
Pour les visualisations En courbes, À barres ou Graphique à nuage de points, les dimensions acceptées sont les types de données
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEetSTRING, tandis que les mesures acceptées sont les types de donnéesINT64,FLOAT64,NUMERICetBIGNUMERIC.Si les résultats de votre requête incluent le type
GEOGRAPHY, Carte est le type de visualisation par défaut, qui vous permet de visualiser vos résultats sur une carte interactive.Facultatif : Dans l'onglet JSON, vous pouvez explorer les résultats de la requête au format JSON, où la clé est le nom de la colonne et la valeur est le résultat de cette colonne.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Utilisez la commande
bq query. Dans l'exemple suivant, l'option--use_legacy_sql=falsevous permet d'utiliser la syntaxe GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
Remplacez QUERY par une requête GoogleSQL valide. Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Le job de requête écrit la sortie dans une table (en cache) temporaire.
Sinon, vous pouvez spécifier la table de destination et l'emplacement pour les résultats de la requête. Pour écrire les résultats dans une table existante, ajoutez l'option appropriée afin d'ajouter (
--append_table=true) ou d'écraser (--replace=true) la table.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Remplacez les éléments suivants :
LOCATION : région ou emplacement multirégional de la table de destination, par exemple
USDans cet exemple, l'ensemble de données
usa_namesest stocké dans l'emplacement multirégional États-Unis. Si vous spécifiez une table de destination pour cette requête, l'ensemble de données contenant la table de destination doit également se trouver dans l'emplacement multirégional des États-Unis. Vous ne pouvez pas interroger un ensemble de données dans un emplacement spécifique et écrire les résultats dans une table dont l'emplacement est différent.Vous pouvez définir une valeur par défaut correspondant à l'emplacement en utilisant le fichier .bigqueryrc.
TABLE : nom de la table de destination, par exemple
myDataset.myTable.Si la table de destination est une nouvelle table, BigQuery la crée lorsque vous exécutez votre requête. Cependant, vous devez spécifier un ensemble de données existant.
Si la table ne se trouve pas dans votre projet actuel, ajoutez l'ID du projetGoogle Cloud en utilisant le format
PROJECT_ID:DATASET.TABLE(par exemple,myProject:myDataset.myTable). Si--destination_tablen'est pas spécifiée, un job de requête est généré pour écrire la sortie dans une table temporaire.
API
Pour exécuter une requête à l'aide de l'API, insérez une nouvelle tâche, puis définissez la propriété de configuration de tâche query. (Facultatif) Spécifiez votre locationemplacementjobReference dans la propriété de la section de la ressource de job.
Interrogez les résultats en appelant getQueryResults
jusqu'à ce que jobComplete ait la valeur true. Recherchez les erreurs et les avertissements dans la liste errors.
C#
Avant d'essayer cet exemple, suivez les instructions de configuration pour C# du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour C#.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Pour exécuter une requête avec un proxy, consultez la section Configurer un proxy.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
PHP
Avant d'essayer cet exemple, suivez les instructions de configuration pour PHP du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour PHP.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Ruby
Avant d'essayer cet exemple, suivez les instructions de configuration pour Ruby du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Ruby.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Exécuter une requête par lot
Pour exécuter une requête par lot, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Cliquez sur Requête SQL.
Dans l'éditeur de requête, saisissez une requête GoogleSQL valide.
Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Cliquez sur Plus, puis sur Paramètres de requête.
Dans la section Gestion des ressources, sélectionnez Par lot.
Facultatif : Ajustez les paramètres de votre requête.
Cliquez sur Enregistrer.
Cliquez sur Exécuter.
Si vous ne spécifiez pas de table de destination, le job de requête écrit la sortie dans une table (en cache) temporaire.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Exécutez la commande
bq query, puis spécifiez l'option--batch. Dans l'exemple suivant, l'option--use_legacy_sql=falsevous permet d'utiliser la syntaxe GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Remplacez QUERY par une requête GoogleSQL valide. Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Le job de requête écrit la sortie dans une table (en cache) temporaire.
Sinon, vous pouvez spécifier la table de destination et l'emplacement pour les résultats de la requête. Pour écrire les résultats dans une table existante, ajoutez l'option appropriée afin d'ajouter (
--append_table=true) ou d'écraser (--replace=true) la table.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Remplacez les éléments suivants :
LOCATION : région ou emplacement multirégional de la table de destination, par exemple
USDans cet exemple, l'ensemble de données
usa_namesest stocké dans l'emplacement multirégional États-Unis. Si vous spécifiez une table de destination pour cette requête, l'ensemble de données contenant la table de destination doit également se trouver dans l'emplacement multirégional des États-Unis. Vous ne pouvez pas interroger un ensemble de données dans un emplacement spécifique et écrire les résultats dans une table dont l'emplacement est différent.Vous pouvez définir une valeur par défaut correspondant à l'emplacement en utilisant le fichier .bigqueryrc.
TABLE : nom de la table de destination, par exemple
myDataset.myTable.Si la table de destination est une nouvelle table, BigQuery la crée lorsque vous exécutez votre requête. Cependant, vous devez spécifier un ensemble de données existant.
Si la table ne se trouve pas dans votre projet actuel, ajoutez l'ID du projetGoogle Cloud en utilisant le format
PROJECT_ID:DATASET.TABLE(par exemple,myProject:myDataset.myTable). Si--destination_tablen'est pas spécifiée, un job de requête est généré pour écrire la sortie dans une table temporaire.
API
Pour exécuter une requête à l'aide de l'API, insérez une nouvelle tâche, puis définissez la propriété de configuration de tâche query. (Facultatif) Spécifiez votre locationemplacementjobReference dans la propriété de la section de la ressource de job.
Lorsque vous spécifiez les propriétés du job de requête, incluez la propriété configuration.query.priority et définissez la valeur sur BATCH.
Interrogez les résultats en appelant getQueryResults
jusqu'à ce que jobComplete ait la valeur true. Recherchez les erreurs et les avertissements dans la liste errors.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Java
Pour exécuter une requête par lot, définissez la priorité de la requête sur QueryJobConfiguration.Priority.BATCH lors de la création d'une configuration QueryJobConfiguration.
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Exécuter une requête continue
L'exécution d'une requête continue nécessite une configuration supplémentaire. Pour en savoir plus, consultez Créer des requêtes continues.
Utiliser le panneau Référence
Dans l'éditeur de requêtes, le panneau Référence affiche de manière dynamique des informations contextuelles sur les tables, les instantanés, les vues et les vues matérialisées. Ce panneau vous permet de prévisualiser les détails du schéma de ces ressources ou de les ouvrir dans un nouvel onglet. Vous pouvez également utiliser le panneau Référence pour créer des requêtes ou modifier des requêtes existantes en insérant des extraits de requête ou des noms de champs.
Pour créer une requête à l'aide du panneau Référence, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Cliquez sur Requête SQL.
Cliquez sur quick_reference_all Référence.
Cliquez sur une table ou une vue récente ou suivie. Vous pouvez également utiliser la barre de recherche pour trouver des tables et des vues.
Cliquez sur Afficher les actions, puis sur Insérer un extrait de requête.
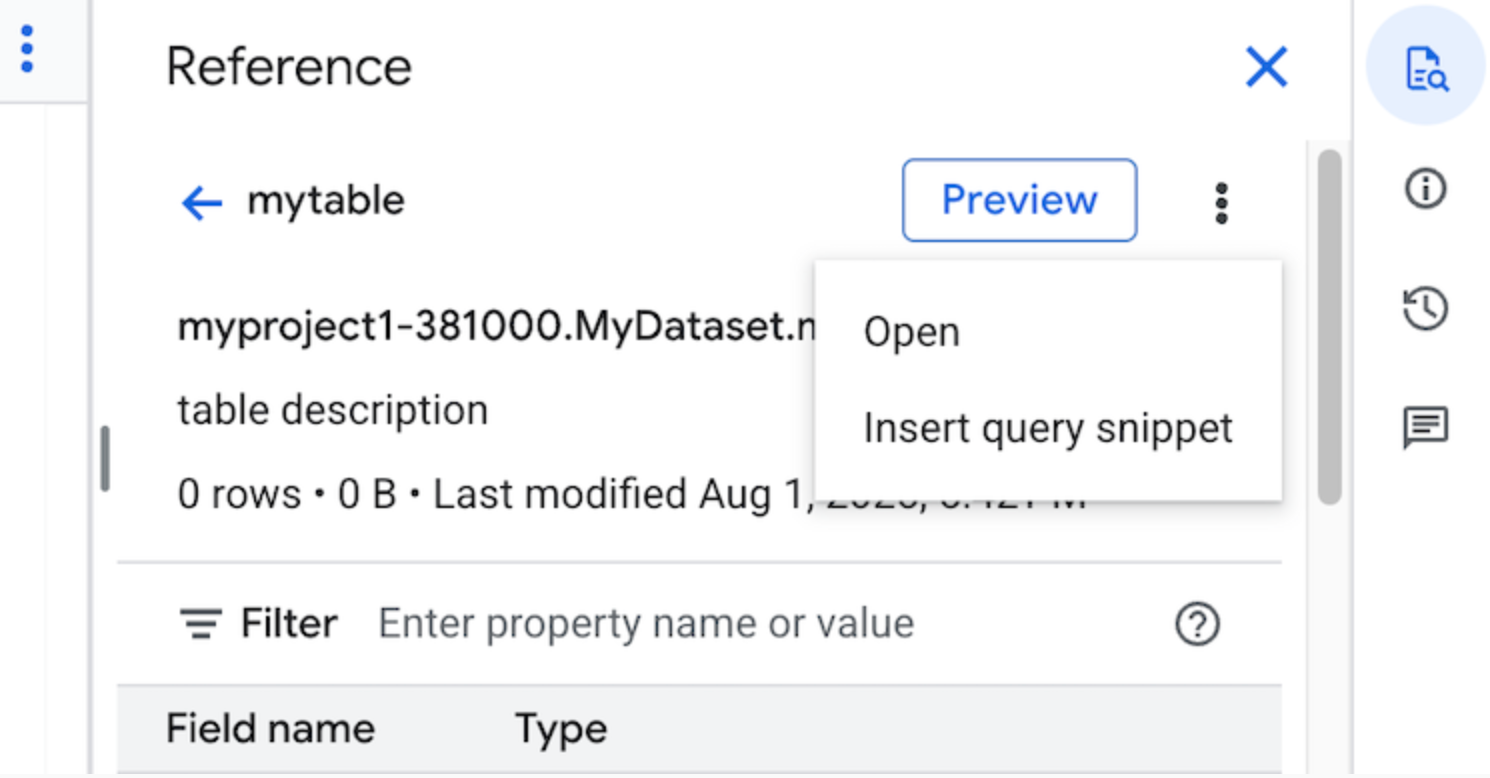
Facultatif : Vous pouvez prévisualiser les détails du schéma de la table, les afficher ou les ouvrir dans un nouvel onglet.
Vous pouvez maintenant modifier la requête manuellement ou insérer des noms de champs directement dans votre requête. Pour insérer un nom de champ, pointez sur l'emplacement de l'éditeur de requête où vous souhaitez insérer le nom de champ, puis cliquez sur le nom de champ dans le panneau Référence.
Paramètres de requête
Lorsque vous exécutez une requête, vous pouvez spécifier les paramètres suivants :
Table de destination pour les résultats de la requête.
Priorité du job.
Indique s'il faut utiliser les résultats de requête mis en cache.
Délai avant expiration du job en millisecondes.
Indique s'il faut utiliser le mode session.
Type de chiffrement à utiliser.
Nombre maximal d'octets facturés pour la requête.
Le dialecte SQL à utiliser.
location dans laquelle exécuter la requête. La requête doit s'exécuter au même emplacement que les tables référencées dans la requête.
La réservation pour exécuter votre requête en version bêta.
Mode de création de job facultatif
Le mode de création de job facultatif peut améliorer la latence globale des requêtes qui s'exécutent pendant une courte durée, comme celles des tableaux de bord ou des charges de travail d'exploration de données. Ce mode exécute la requête et renvoie les résultats intégrés pour les instructions SELECT sans nécessiter l'utilisation de jobs.getQueryResults pour récupérer les résultats. Les requêtes utilisant le mode de création de job facultative ne créent pas de job lorsqu'elles sont exécutées, sauf si BigQuery détermine qu'une création de job est nécessaire pour terminer la requête.
Pour activer le mode de création de job facultatif, définissez le champ jobCreationMode de l'instance QueryRequest sur JOB_CREATION_OPTIONAL dans le corps de la requête jobs.query.
Lorsque la valeur de ce champ est définie sur JOB_CREATION_OPTIONAL, BigQuery détermine si la requête peut utiliser le mode de création de job facultatif. Si tel est le cas, BigQuery exécute la requête et renvoie tous les résultats dans le champ rows de la réponse. Étant donné qu'aucune tâche n'est créée pour cette requête, BigQuery ne renvoie pas de jobReference dans le corps de la réponse. Il renvoie un champ queryId que vous pouvez utiliser pour obtenir des insights sur la requête à l'aide de la vue INFORMATION_SCHEMA.JOBS. Étant donné qu'aucun job n'est créé, aucun jobReference ne peut être transmis aux API jobs.get et jobs.getQueryResults pour rechercher ces requêtes.
Si BigQuery détermine qu'une tâche est nécessaire pour terminer la requête, une valeur jobReference est renvoyée. Vous pouvez inspecter le champ job_creation_reason dans la vue INFORMATION_SCHEMA.JOBS pour déterminer la raison pour laquelle une tâche a été créée pour la requête. Dans ce cas, vous devez utiliser jobs.getQueryResults pour récupérer les résultats une fois la requête terminée.
Lorsque vous utilisez la valeur JOB_CREATION_OPTIONAL, il est possible que le champ jobReference ne soit pas présent dans la réponse. Vérifiez si le champ existe avant d'y accéder.
Lorsque JOB_CREATION_OPTIONAL est spécifié pour les requêtes multi-instructions (scripts), BigQuery peut optimiser le processus d'exécution. Dans le cadre de cette optimisation, BigQuery peut déterminer qu'il peut exécuter le script en créant moins de ressources de job que le nombre d'instructions individuelles, voire en exécutant l'intégralité du script sans créer de job.
Cette optimisation dépend de l'évaluation du script par BigQuery. Il est possible qu'elle ne soit pas appliquée dans tous les cas. L'optimisation est entièrement automatisée par le système. Aucune action ni aucun contrôle utilisateur ne sont requis.
Pour exécuter une requête en mode de création de job facultatif, sélectionnez l'une des options suivantes :
Console
Accédez à la page BigQuery.
Cliquez sur Requête SQL.
Dans l'éditeur de requête, saisissez une requête GoogleSQL valide.
Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Cliquez sur Plus, puis sélectionnez le mode de requête Création de job facultative. Pour confirmer ce choix, cliquez sur Confirmer.
Cliquez sur Exécuter.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Exécutez la commande
bq query, puis spécifiez l'option--job_creation_mode=JOB_CREATION_OPTIONAL. Dans l'exemple suivant, l'option--use_legacy_sql=falsevous permet d'utiliser la syntaxe GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Remplacez QUERY par une requête GoogleSQL valide, et LOCATION par une région valide où se trouve l'ensemble de données. Par exemple, interrogez l'ensemble de données public BigQuery
usa_namespour déterminer les noms les plus couramment utilisés aux États-Unis entre 1910 et 2013 :bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'La requête renvoie la sortie dans la réponse.
API
Pour exécuter une requête en mode création de tâche facultative à l'aide de l'API, exécutez une requête de manière synchrone et renseignez la propriété QueryRequest. Incluez la propriété jobCreationMode et définissez sa valeur sur JOB_CREATION_OPTIONAL.
Vérifiez la réponse. Si jobComplete est égal à true et que jobReference est vide, lisez les résultats du champ rows. Vous pouvez également obtenir le queryId à partir de la réponse.
Si jobReference est présent, vous pouvez vérifier jobCreationReason pour savoir pourquoi une tâche a été créée par BigQuery. Interrogez les résultats en appelant getQueryResults
jusqu'à ce que jobComplete ait la valeur true. Recherchez les erreurs et les avertissements dans la liste errors.
Java
Version disponible : 2.51.0 et versions ultérieures
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Pour exécuter une requête avec un proxy, consultez la section Configurer un proxy.
Python
Version disponible : 3.34.0 ou version ultérieure
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Nœud
Version disponible : 8.1.0 et versions ultérieures
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Go
Version disponible : 1.69.0 et versions ultérieures
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Pilote JDBC
Version disponible : JDBC v1.6.1 et versions ultérieures
Nécessite de définir JobCreationMode=2 dans la chaîne de connexion.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
Pilote ODBC
Version disponible : ODBC v3.0.7.1016 et versions ultérieures
Nécessite de définir JobCreationMode=2 dans le fichier .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Quotas
Pour en savoir plus sur les quotas concernant les requêtes interactives et par lot, consultez la page Jobs de requête.
Surveiller les requêtes
Vous pouvez obtenir des informations sur les requêtes en cours d'exécution à l'aide de l'explorateur de jobs ou en interrogeant la vue INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Dry run
Une simulation de BigQuery fournit les informations suivantes :
- Estimation des frais en mode à la demande
- Validation de votre requête
- Nombre approximatif d'octets traités par votre requête en mode de capacité
Les simulations n'utilisent pas d'emplacements de requête, et leur exécution ne vous est pas facturée. L'estimation renvoyée par la simulation vous permettra de calculer les coûts de requête dans le simulateur de coût.
Effectuer une simulation
Pour effectuer une simulation, procédez comme suit :
Console
Accédez à la page BigQuery.
Saisissez votre requête dans l'Éditeur de requête.
Si la requête est valide, une coche apparaît automatiquement avec la quantité de données que la requête va traiter. Si la requête n'est pas valide, un point d'exclamation apparaît avec un message d'erreur.
bq
Saisissez une requête semblable à celle-ci à l'aide de l'option --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Pour une requête valide, la commande génère la réponse suivante :
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Pour effectuer une simulation avec l'API, envoyez une tâche de requête avec la valeur dryRun définie sur true dans le type JobConfiguration.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
PHP
Avant d'essayer cet exemple, suivez les instructions de configuration pour PHP du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour PHP.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Définissez la propriété QueryJobConfig.dry_run sur True.
La méthode Client.query() renvoie toujours une tâche QueryJob terminée lorsque vous lui transmettez une configuration de requête simulée.
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Étapes suivantes
- Apprenez à gérer les jobs de requête.
- Apprenez à afficher l'historique des requêtes.
- Découvrez comment enregistrer et partager des requêtes.
- Découvrez les files d'attente de requêtes.
- Découvrez comment écrire des résultats de requête.