Menjalankan kueri
Dokumen ini menunjukkan cara menjalankan kueri di BigQuery dan memahami jumlah data yang akan diproses kueri sebelum dieksekusi dengan melakukan uji coba.
Jenis kueri
Anda dapat membuat kueri data BigQuery menggunakan salah satu jenis tugas kueri berikut:
Tugas kueri interaktif. Secara default, BigQuery menjalankan kueri sebagai tugas kueri interaktif, yang dimaksudkan untuk mulai dieksekusi secepat mungkin.
Tugas kueri batch. Kueri batch memiliki prioritas lebih rendah daripada kueri interaktif. Jika project atau reservasi menggunakan semua resource komputasi yang tersedia, kueri batch cenderung diantrekan dan tetap berada dalam antrean. Setelah kueri batch mulai berjalan, kueri batch akan berjalan sama seperti kueri interaktif. Untuk mengetahui informasi selengkapnya, lihat antrean kueri.
Tugas kueri berkelanjutan. Dengan tugas ini, kueri berjalan terus-menerus, sehingga Anda dapat menganalisis data yang masuk di BigQuery secara real time, lalu menulis hasilnya ke tabel BigQuery, atau mengekspor hasilnya ke Bigtable atau Pub/Sub. Anda dapat menggunakan kemampuan ini untuk melakukan tugas yang sensitif terhadap waktu, seperti membuat dan langsung menindaklanjuti insight, menerapkan inferensi machine learning (ML) real-time, dan membangun pipeline data berbasis peristiwa.
Anda dapat menjalankan tugas kueri menggunakan metode berikut:
- Buat dan jalankan kueri di konsolGoogle Cloud .
- Jalankan perintah
bq querydi alat command line bq. - Secara terprogram panggil metode
jobs.queryataujobs.insertdi BigQuery REST API. - Menggunakan library klien BigQuery.
BigQuery menyimpan hasil kueri ke tabel sementara (default) atau tabel permanen. Saat menentukan tabel permanen sebagai tabel tujuan untuk hasil, Anda dapat memilih apakah akan menambahkan atau menimpa tabel yang sudah ada, atau membuat tabel baru dengan nama unik.
Peran yang diperlukan
Untuk mendapatkan izin yang diperlukan untuk menjalankan tugas kueri, minta administrator untuk memberi Anda peran IAM berikut:
-
Pengguna Tugas BigQuery (
roles/bigquery.jobUser) di project. -
BigQuery Data Viewer (
roles/bigquery.dataViewer) pada semua tabel dan tampilan yang dirujuk oleh kueri Anda. Untuk membuat kueri tampilan, Anda juga memerlukan peran ini di semua tabel dan tampilan yang mendasarinya. Jika menggunakan tampilan yang diotorisasi atau set data yang diotorisasi, Anda tidak memerlukan akses ke data sumber pokok.
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, lihat Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin yang diperlukan untuk menjalankan tugas kueri. Untuk melihat izin yang benar-benar diperlukan, luaskan bagian Izin yang diperlukan:
Izin yang diperlukan
Izin berikut diperlukan untuk menjalankan tugas kueri:
-
bigquery.jobs.createdi project tempat kueri dijalankan, terlepas dari lokasi penyimpanan data. -
bigquery.tables.getDatadi semua tabel dan tampilan yang dirujuk oleh kueri Anda. Untuk membuat kueri tampilan, Anda juga memerlukan izin ini pada semua tabel dan tampilan yang mendasarinya. Jika menggunakan tampilan yang diotorisasi atau set data yang diotorisasi, Anda tidak memerlukan akses ke data sumber pokok.
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Pemecahan masalah
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Error ini terjadi saat akun utama tidak memiliki izin untuk membuat tugas kueri di project.
Penyelesaian: Administrator harus memberi Anda izin bigquery.jobs.create
pada project yang Anda kueri. Izin ini diperlukan selain izin apa pun yang diperlukan untuk mengakses data yang dikueri.
Untuk mengetahui informasi selengkapnya tentang izin BigQuery, lihat Kontrol akses dengan IAM.
Menjalankan kueri interaktif
Untuk menjalankan kueri interaktif, pilih salah satu opsi berikut:
Konsol
Buka halaman BigQuery.
Klik SQL query.
Di editor kueri, masukkan kueri GoogleSQL yang valid.
Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Atau, Anda dapat menggunakan panel Referensi untuk membuat kueri baru.
Opsional: Untuk menampilkan saran kode secara otomatis saat Anda mengetik kueri, klik Lainnya, lalu pilih Pelengkapan otomatis SQL. Jika Anda tidak memerlukan saran pelengkapan otomatis, batalkan pilihan Pelengkapan otomatis SQL. Tindakan ini juga akan menonaktifkan saran isi otomatis nama project.
Opsional: Untuk memilih setelan kueri tambahan, klik Lainnya, lalu klik Setelan kueri.
Klik Run.
Jika Anda tidak menentukan tabel tujuan, tugas kueri akan menulis output ke tabel sementara (cache).
Sekarang Anda dapat menjelajahi hasil kueri di tab Results pada panel Query results.
Opsional: Untuk mengurutkan hasil kueri berdasarkan kolom, klik Buka menu pengurutan di samping nama kolom, lalu pilih tata urutan. Jika estimasi byte yang diproses untuk pengurutan lebih dari nol, jumlah byte akan ditampilkan di bagian atas menu.
Opsional: Untuk melihat visualisasi hasil kueri Anda, buka tab Visualisasi. Anda dapat memperbesar atau memperkecil diagram, mendownload diagram sebagai file PNG, atau mengalihkan visibilitas legenda.
Di panel Konfigurasi visualisasi, Anda dapat mengubah jenis visualisasi serta mengonfigurasi ukuran dan dimensi visualisasi. Kolom di panel ini diisi otomatis dengan konfigurasi awal yang disimpulkan dari skema tabel tujuan kueri. Konfigurasi dipertahankan di antara kueri berikut yang dijalankan di editor kueri yang sama.
Untuk visualisasi Garis, Batang, atau Sebar, dimensi yang didukung adalah jenis data
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIME, danSTRING, sementara pengukuran yang didukung adalah jenis dataINT64,FLOAT64,NUMERIC, danBIGNUMERIC.Jika hasil kueri Anda mencakup jenis
GEOGRAPHY, maka Peta adalah jenis visualisasi default, yang memungkinkan Anda memvisualisasikan hasil di peta interaktif.Opsional: Di tab JSON, Anda dapat menjelajahi hasil kueri dalam format JSON, dengan kunci adalah nama kolom dan nilai adalah hasil untuk kolom tersebut.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Gunakan perintah
bq query. Pada contoh berikut, flag--use_legacy_sql=falsememungkinkan Anda menggunakan sintaksis GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
Ganti QUERY dengan kueri GoogleSQL yang valid. Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Tugas kueri menulis output ke tabel sementara (cache).
Selain itu, Anda dapat menentukan tabel tujuan dan lokasi untuk hasil kueri. Untuk menulis hasilnya ke tabel yang sudah ada, sertakan flag yang sesuai untuk menambahkan (
--append_table=true) atau menimpa (--replace=true) tabel.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Ganti kode berikut:
LOCATION: region atau multi-region untuk tabel tujuan—misalnya,
USDalam contoh ini, set data
usa_namesdisimpan di lokasi multi-region AS. Jika Anda menentukan tabel tujuan untuk kueri ini, set data yang berisi tabel tujuan juga harus berada di multi-region AS. Anda tidak dapat mengkueri set data di satu lokasi dan menulis hasilnya ke tabel di lokasi lain.Anda dapat menetapkan nilai default untuk lokasi menggunakan .bigqueryrc file.
TABLE: nama untuk tabel tujuan—misalnya,
myDataset.myTableJika tabel tujuan adalah tabel baru, BigQuery akan membuat tabel tersebut saat Anda menjalankan kueri. Namun, Anda harus menentukan set data yang sudah ada.
Jika tabel tidak ada dalam project Anda saat ini, tambahkan project IDGoogle Cloud menggunakan format
PROJECT_ID:DATASET.TABLE—misalnya,myProject:myDataset.myTable. Jika--destination_tabletidak ditentukan, tugas kueri akan dibuat yang menulis output ke tabel sementara.
API
Untuk menjalankan kueri menggunakan API, sisipkan tugas baru
dan isi properti konfigurasi tugas query. Anda juga bisa menentukan lokasi di properti location di bagian jobReference di resource tugas.
Lakukan polling untuk hasil dengan memanggil
getQueryResults.
Polling hingga jobComplete sama dengan true. Periksa error dan peringatan dalam
daftar errors.
C#
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan C# di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery C# API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Go
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Untuk menjalankan kueri dengan proxy, lihat Mengonfigurasi proxy.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
PHP
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan PHP di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery PHP API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Ruby
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Ruby di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Ruby API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Menjalankan kueri batch
Untuk menjalankan kueri batch, pilih salah satu opsi berikut:
Konsol
Buka halaman BigQuery.
Klik SQL query.
Di editor kueri, masukkan kueri GoogleSQL yang valid.
Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Klik More, lalu klik Query settings.
Di bagian Resource management, pilih Batch.
Opsional: Sesuaikan setelan kueri Anda.
Klik Simpan.
Klik Run.
Jika Anda tidak menentukan tabel tujuan, tugas kueri akan menulis output ke tabel sementara (cache).
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Gunakan perintah
bq querydan tentukan flag--batch. Pada contoh berikut, flag--use_legacy_sql=falsememungkinkan Anda menggunakan sintaksis GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Ganti QUERY dengan kueri GoogleSQL yang valid. Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Tugas kueri menulis output ke tabel sementara (cache).
Selain itu, Anda dapat menentukan tabel tujuan dan lokasi untuk hasil kueri. Untuk menulis hasilnya ke tabel yang sudah ada, sertakan flag yang sesuai untuk menambahkan (
--append_table=true) atau menimpa (--replace=true) tabel.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Ganti kode berikut:
LOCATION: region atau multi-region untuk tabel tujuan—misalnya,
USDalam contoh ini, set data
usa_namesdisimpan di lokasi multi-region AS. Jika Anda menentukan tabel tujuan untuk kueri ini, set data yang berisi tabel tujuan juga harus berada di multi-region AS. Anda tidak dapat mengkueri set data di satu lokasi dan menulis hasilnya ke tabel di lokasi lain.Anda dapat menetapkan nilai default untuk lokasi menggunakan .bigqueryrc file.
TABLE: nama untuk tabel tujuan—misalnya,
myDataset.myTableJika tabel tujuan adalah tabel baru, BigQuery akan membuat tabel tersebut saat Anda menjalankan kueri. Namun, Anda harus menentukan set data yang sudah ada.
Jika tabel tidak ada dalam project Anda saat ini, tambahkan project IDGoogle Cloud menggunakan format
PROJECT_ID:DATASET.TABLE—misalnya,myProject:myDataset.myTable. Jika--destination_tabletidak ditentukan, tugas kueri akan dibuat yang menulis output ke tabel sementara.
API
Untuk menjalankan kueri menggunakan API, sisipkan tugas baru
dan isi properti konfigurasi tugas query. Anda juga bisa menentukan lokasi di properti location di bagian jobReference di resource tugas.
Saat Anda mengisi properti tugas kueri, sertakan properti configuration.query.priority dan tetapkan nilainya ke BATCH.
Lakukan polling untuk hasil dengan memanggil
getQueryResults.
Polling hingga jobComplete sama dengan true. Periksa error dan peringatan dalam
daftar errors.
Go
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Java
Untuk menjalankan kueri batch, tetapkan prioritas kueri ke QueryJobConfiguration.Priority.BATCH saat membuat QueryJobConfiguration.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Menjalankan kueri berkelanjutan
Menjalankan tugas kueri berkelanjutan memerlukan konfigurasi tambahan. Untuk mengetahui informasi selengkapnya, lihat Membuat kueri berkelanjutan.
Menggunakan panel Referensi
Di editor kueri, panel Referensi menampilkan informasi yang relevan dengan konteks secara dinamis tentang tabel, snapshot, tampilan, dan tampilan terwujud. Panel ini memungkinkan Anda melihat pratinjau detail skema resource tersebut, atau membukanya di tab baru. Anda juga dapat menggunakan panel Referensi untuk membuat kueri baru atau mengedit kueri yang ada dengan menyisipkan cuplikan kueri atau nama kolom.
Untuk membuat kueri baru menggunakan panel Referensi, ikuti langkah-langkah berikut:
Di konsol Google Cloud , buka halaman BigQuery.
Klik SQL query.
Klik quick_reference_all Reference.
Klik tabel atau tampilan terbaru atau yang dibintangi. Anda juga dapat menggunakan kotak penelusuran untuk menemukan tabel dan tampilan.
Klik Lihat tindakan, lalu klik Sisipkan cuplikan kueri.
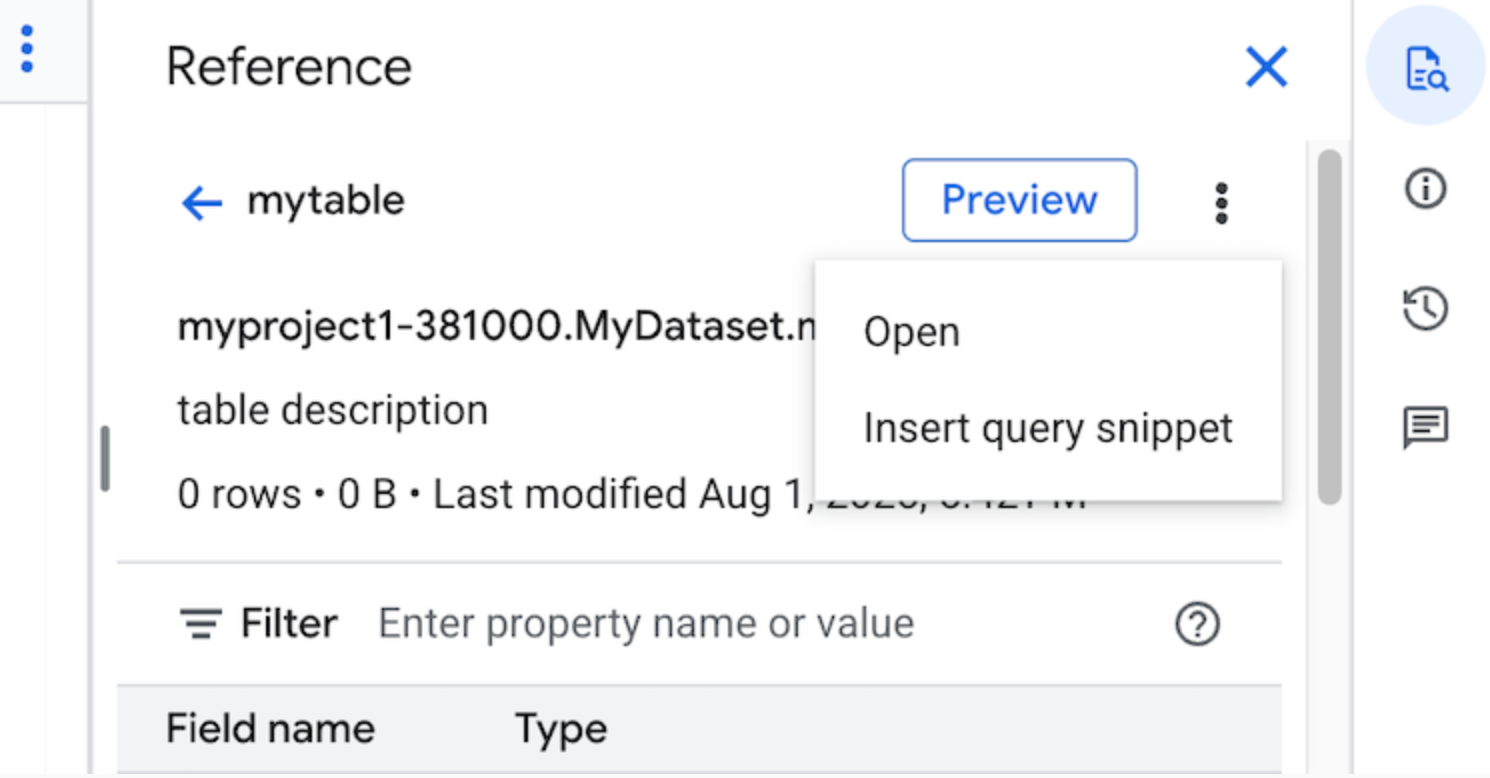
Opsional: Anda dapat melihat pratinjau detail skema tabel atau tampilan, atau membukanya di tab baru.
Sekarang Anda dapat mengedit kueri secara manual atau menyisipkan nama kolom langsung ke dalam kueri. Untuk menyisipkan nama kolom, arahkan kursor ke tempat di editor kueri yang ingin Anda sisipkan nama kolom, lalu klik nama kolom di panel Referensi.
Setelan kueri
Saat menjalankan kueri, Anda dapat menentukan setelan berikut:
Tabel tujuan untuk hasil kueri.
Prioritas tugas.
Apakah akan menggunakan hasil kueri yang di-cache.
Waktu tunggu tugas dalam milidetik.
Apakah akan menggunakan mode sesi.
Jenis enkripsi yang akan digunakan.
Jumlah maksimum byte yang ditagih untuk kueri.
Dialek SQL yang akan digunakan.
Lokasi tempat menjalankan kueri. Kueri harus berjalan di lokasi yang sama dengan tabel yang direferensikan dalam kueri.
Mode pembuatan tugas opsional
Mode pembuatan tugas opsional dapat meningkatkan latensi keseluruhan kueri yang berjalan
dalam durasi singkat, seperti kueri dari dasbor atau beban kerja eksplorasi
data. Mode ini menjalankan kueri dan menampilkan hasil sebaris untuk pernyataan
SELECT tanpa memerlukan penggunaan
jobs.getQueryResults
untuk mengambil hasil. Kueri yang menggunakan mode pembuatan tugas opsional tidak membuat tugas saat dijalankan, kecuali jika BigQuery menentukan bahwa pembuatan tugas diperlukan untuk menyelesaikan kueri.
Untuk mengaktifkan mode pembuatan tugas opsional, tetapkan kolom jobCreationMode dari instance
QueryRequest
ke JOB_CREATION_OPTIONAL di isi permintaan
jobs.query.
Jika nilai kolom ini ditetapkan ke JOB_CREATION_OPTIONAL,
BigQuery akan menentukan apakah kueri dapat menggunakan mode pembuatan
tugas opsional. Jika ya, BigQuery akan menjalankan kueri dan menampilkan semua hasil di kolom rows respons. Karena tugas tidak dibuat untuk kueri ini, BigQuery tidak menampilkan jobReference dalam isi respons. Sebagai gantinya, fungsi ini menampilkan kolom queryId, yang dapat Anda gunakan untuk mendapatkan
insight tentang kueri menggunakan tampilan INFORMATION_SCHEMA.JOBS. Karena tidak ada tugas yang dibuat, tidak ada jobReference yang dapat diteruskan ke API jobs.get dan jobs.getQueryResults untuk mencari kueri ini.
Jika BigQuery menentukan bahwa tugas diperlukan untuk menyelesaikan
kueri, jobReference akan ditampilkan. Anda dapat memeriksa kolom job_creation_reason
di tampilan INFORMATION_SCHEMA.JOBS untuk menentukan
alasan tugas dibuat untuk kueri. Dalam hal ini, Anda harus menggunakan
jobs.getQueryResults
untuk mengambil hasil saat kueri selesai.
Saat Anda menggunakan nilai JOB_CREATION_OPTIONAL, kolom jobReference mungkin tidak ada dalam respons. Periksa apakah kolom ada sebelum mengaksesnya.
Jika JOB_CREATION_OPTIONAL ditentukan untuk kueri multi-pernyataan (skrip),
BigQuery dapat mengoptimalkan proses eksekusi. Sebagai bagian dari pengoptimalan ini, BigQuery dapat menentukan bahwa BigQuery dapat menyelesaikan skrip dengan membuat lebih sedikit resource tugas daripada jumlah pernyataan individual, bahkan mungkin menjalankan seluruh skrip tanpa membuat tugas sama sekali.
Pengoptimalan ini bergantung pada penilaian BigQuery terhadap skrip, dan pengoptimalan mungkin tidak diterapkan dalam setiap kasus. Pengoptimalan sepenuhnya
otomatis oleh sistem. Tidak ada kontrol atau tindakan pengguna yang diperlukan.
Untuk menjalankan kueri menggunakan mode pembuatan tugas opsional, pilih salah satu opsi berikut:
Konsol
Buka halaman BigQuery.
Klik SQL query.
Di editor kueri, masukkan kueri GoogleSQL yang valid.
Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Klik Lainnya, lalu pilih mode kueri Pembuatan tugas opsional. Untuk mengonfirmasi pilihan ini, klik Konfirmasi.
Klik Run.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Gunakan perintah
bq querydan tentukan flag--job_creation_mode=JOB_CREATION_OPTIONAL. Pada contoh berikut, flag--use_legacy_sql=falsememungkinkan Anda menggunakan sintaksis GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Ganti QUERY dengan kueri GoogleSQL yang valid, dan ganti LOCATION dengan region yang valid tempat set data berada. Misalnya, buat kueri set data publik BigQuery
usa_namesuntuk menentukan nama yang paling umum di Amerika Serikat antara tahun 1910 dan 2013:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'Tugas kueri menampilkan output secara inline dalam respons.
API
Untuk menjalankan kueri dalam mode pembuatan tugas opsional menggunakan API, jalankan kueri secara sinkron
dan isi properti QueryRequest. Sertakan properti jobCreationMode dan tetapkan nilainya ke JOB_CREATION_OPTIONAL.
Periksa responsnya. Jika jobComplete sama dengan true dan jobReference kosong, baca hasil dari kolom rows. Anda juga bisa mendapatkan queryId dari respons.
Jika jobReference ada, Anda dapat memeriksa jobCreationReason untuk mengetahui alasan tugas dibuat oleh BigQuery. Lakukan polling untuk hasil dengan memanggil
getQueryResults.
Polling hingga jobComplete sama dengan true. Periksa error dan peringatan dalam
daftar errors.
Java
Versi yang tersedia: 2.51.0 dan yang lebih baru
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Untuk menjalankan kueri dengan proxy, lihat Mengonfigurasi proxy.
Python
Versi yang tersedia: 3.34.0 dan yang lebih baru
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node
Versi yang tersedia: 8.1.0 dan yang lebih baru
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Go
Versi yang tersedia: 1.69.0 dan yang lebih baru
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Driver JDBC
Versi yang tersedia: JDBC v1.6.1 dan yang lebih baru
Memerlukan penetapan JobCreationMode=2 dalam string koneksi.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
Driver ODBC
Versi yang tersedia: ODBC v3.0.7.1016 dan yang lebih baru
Memerlukan penetapan JobCreationMode=2 dalam file .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Kuota
Untuk mengetahui informasi tentang kuota terkait kueri batch dan interaktif, baca Tugas kueri.
Memantau kueri
Anda bisa mendapatkan informasi tentang kueri saat kueri tersebut dijalankan menggunakan
penjelajah tugas atau dengan membuat kueri untuk
tampilan INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Dry run
Uji coba di BigQuery memberikan informasi berikut:
- perkiraan tagihan dalam mode on demand
- validasi kueri
- perkiraan byte yang diproses oleh kueri Anda dalam mode kapasitas
Uji coba tidak menggunakan slot kueri, dan Anda tidak dikenai biaya untuk melakukan uji coba. Anda dapat menggunakan perkiraan yang ditampilkan oleh uji coba untuk menghitung biaya kueri di kalkulator harga.
Melakukan uji coba
Untuk melakukan uji coba, lakukan hal berikut:
Konsol
Buka halaman BigQuery.
Masukkan kueri Anda di editor kueri.
Jika kueri valid, tanda centang akan muncul secara otomatis bersama dengan jumlah data yang akan diproses oleh kueri. Jika kueri tidak valid, tanda seru akan muncul bersama dengan pesan error.
bq
Masukkan kueri seperti berikut menggunakan flag --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Untuk kueri yang valid, perintah tersebut menghasilkan respons berikut:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Untuk melakukan uji coba menggunakan API, kirim tugas kueri dengan
dryRun ditetapkan ke true pada
jenis
JobConfiguration.
Go
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Go di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Go API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Java API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
PHP
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan PHP di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery PHP API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Python
Tetapkan properti QueryJobConfig.dry_run ke True.
Client.query() selalu menampilkan QueryJob yang telah selesai saat diberi konfigurasi kueri uji coba.
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Langkah berikutnya
- Pelajari cara mengelola tugas kueri.
- Pelajari cara melihat histori kueri.
- Pelajari cara menyimpan dan membagikan kueri.
- Pelajari antrean kueri.
- Pelajari cara menulis hasil kueri.