Ejecuta una consulta
En este documento, se muestra cómo ejecutar una consulta en BigQuery y comprender cuántos datos procesará la consulta antes de ejecutarla a través de una prueba de validación.
Tipos de consultas
Puedes consultar datos de BigQuery a través de uno de los siguientes tipos de trabajos de consulta:
Trabajos de consultas interactivas. De forma predeterminada, BigQuery ejecuta las consultas como trabajos de consulta interactivos, que están diseñados para comenzar a ejecutarse lo más rápido posible.
Trabajos de consultas por lotes. Las consultas por lotes tienen una prioridad más baja que las consultas interactivas. Cuando un proyecto o una reserva usa todos sus recursos de procesamiento disponibles, es más probable que las consultas por lotes se pongan en cola y permanezcan allí. Una vez que comienza a ejecutarse una consulta por lotes, se ejecuta de la misma manera que una consulta interactiva. Para obtener más información, consulta colas de consultas.
Trabajos de consultas continuas. Con estos trabajos, la consulta se ejecuta de forma continua, lo que te permite analizar datos entrantes en BigQuery en tiempo real y, luego, escribir los resultados en una tabla de BigQuery o exportar los resultados a Bigtable o Pub/Sub. Puedes usar esta capacidad para realizar tareas sensibles urgentes, como crear y tomar medidas inmediatas sobre las estadísticas, aplicar inferencias de aprendizaje automático (AA) en tiempo real y compilar canalizaciones de datos controladas por eventos.
Puedes ejecutar trabajos de consulta con los siguientes métodos:
- Redacta y ejecuta una consulta en la Google Cloud consola.
- Ejecuta el comando
bq queryen la herramienta de línea de comandos de bq. - Llama de manera programática al método
jobs.queryojobs.inserten la API de REST de BigQuery. - Usa las bibliotecas cliente de BigQuery.
BigQuery guarda los resultados de las consultas en una tabla temporal (predeterminada) o en una tabla permanente. Cuando especificas una tabla permanente como la tabla de destino para los resultados, puedes elegir si deseas agregar o reemplazar una tabla existente o crear una tabla nueva con un nombre único.
Roles requeridos
Para obtener los permisos que necesitas para ejecutar un trabajo de consulta, pídele a tu administrador que te otorgue los siguientes roles de IAM:
-
Usuario de trabajo de BigQuery (
roles/bigquery.jobUser) en el proyecto. -
Visualizador de datos de BigQuery (
roles/bigquery.dataViewer) en todas las tablas y vistas a las que hace referencia la consulta. Para consultar las vistas, también necesitas este rol en todas las tablas y vistas subyacentes. Si usas vistas autorizadas o conjuntos de datos autorizados no necesitas acceso a los datos de origen subyacentes.
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen los permisos necesarios para ejecutar un trabajo de consulta. Para ver los permisos exactos que son necesarios, expande la sección Permisos requeridos:
Permisos necesarios
Se requieren los siguientes permisos para ejecutar un trabajo de consulta:
-
bigquery.jobs.createen el proyecto desde el que se ejecuta la consulta, independientemente de dónde se almacenen los datos. -
bigquery.tables.getDataen todas las tablas y vistas a las que hace referencia la consulta. Para consultar las vistas, también necesitas este permiso en todas las tablas y vistas subyacentes. Si usas vistas autorizadas o conjuntos de datos autorizados, no necesitas acceso a los datos de origen subyacentes.
También puedes obtener estos permisos con roles personalizados o con otros roles predefinidos.
Soluciona problemas
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
Este error ocurre cuando un principal no tiene permiso para crear trabajos de consulta en el proyecto.
Solución: Un administrador debe otorgarte el permiso bigquery.jobs.create en el proyecto que consultas. Este permiso es necesario además de cualquier permiso necesario para acceder a los datos consultados.
Para obtener más información sobre IAM de BigQuery, consulta Control de acceso con IAM.
Ejecuta una consulta interactiva
Para ejecutar una consulta interactiva, selecciona una de las siguientes opciones:
Console
Ve a la página de BigQuery.
Haz clic en Consulta en SQL.
En el Editor de consultas, ingresa una consulta de GoogleSQL válida.
Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Como alternativa, puedes usar el panel Referencia para crear consultas nuevas.
Opcional: Para mostrar automáticamente sugerencias de código cuando escribas una consulta, haz clic en Más y, luego, selecciona Autocompletar SQL. Si no necesitas sugerencias de autocompletado, anula la selección de Autocompletado de SQL. Esto también desactiva las sugerencias de autocompletado del nombre del proyecto.
Opcional: Para seleccionar configuración de consulta adicional, haz clic en Más y, luego, en Configuración de consulta.
Haz clic en Ejecutar.
Si no especificas una tabla de destino, el trabajo de consulta escribe el resultado en una tabla temporal (en caché).
Ahora puedes explorar los resultados de la consulta en la pestaña Resultados del panel Resultados de la consulta.
Opcional: para ordenar los resultados de la consulta, haz clic en Abrir el menú de ordenamiento junto al nombre de la columna y selecciona un orden. Si la estimación de bytes procesados del orden es mayor que cero, la cantidad de bytes se muestra en la parte superior del menú.
Opcional: Para ver los resultados de tu consulta, ve a la pestaña Visualización. Puedes acercar o alejar el gráfico, descargarlo como un archivo PNG, o activar o desactivar la visibilidad de la leyenda.
En el panel Configuración de la visualización, puedes cambiar el tipo de visualización y configurar las medidas y dimensiones de la visualización. Los campos de este panel se completan previamente con la configuración inicial deducida del esquema de tabla de destino de la consulta. La configuración se conserva entre las siguientes ejecuciones de consultas en el mismo editor de consultas.
En el caso de las visualizaciones de líneas, barras o dispersión, las dimensiones admitidas son los tipos de datos
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEySTRING, mientras que las medidas admitidas son los tipos de datosINT64,FLOAT64,NUMERICyBIGNUMERIC.Si los resultados de tu búsqueda incluyen el tipo
GEOGRAPHY, Mapa es el tipo de visualización predeterminado, que te permite visualizar tus resultados en un mapa interactivo.Opcional: En la pestaña JSON, puedes explorar los resultados de la consulta en formato JSON, en el que la clave es el nombre de la columna y el valor es el resultado de esa columna.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Usa el comando
bq query. En la siguiente marca, la marca--use_legacy_sql=falsete permite usar la sintaxis de GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
Reemplaza QUERY por una consulta de GoogleSQL válida. Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'El trabajo de consulta escribe el resultado en una tabla temporal (en caché).
De manera opcional, puedes especificar la tabla y la ubicación de destino para los resultados de la consulta. Si deseas escribir los resultados en una tabla existente, incluye la marca adecuada para agregar (
--append_table=true) o reemplazar (--replace=true) la tabla.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Reemplaza lo siguiente:
LOCATION: Es la región o multirregión para la tabla de destino, por ejemplo,
US.En este ejemplo, el conjunto de datos
usa_namesse almacena en la ubicación multirregión de EE.UU. Si especificas una tabla de destino para esta consulta, el conjunto de datos que contiene la tabla de destino también debe estar en la multirregión de EE.UU. No puedes consultar un conjunto de datos en una ubicación y escribir los resultados en una tabla de destino en otra ubicación.Puedes configurar un valor predeterminado para la ubicación con el archivo .bigqueryrc.
TABLE: Es un nombre para la tabla de destino, por ejemplo,
myDataset.myTable.Si la tabla de destino es una tabla nueva, BigQuery crea la tabla cuando ejecutas la consulta. Sin embargo, debes especificar un conjunto de datos existente.
Si la tabla no está en tu proyecto actual, agrega el ID del proyectoGoogle Cloud con el formato
PROJECT_ID:DATASET.TABLE, por ejemplo,myProject:myDataset.myTable. Si no se especifica--destination_table, se genera un trabajo de consulta que escribe el resultado en una tabla temporal.
API
Para ejecutar una consulta con la API, inserta un nuevo trabajo y propaga la propiedad de configuración del trabajo query. Opcionalmente, especifica tu locationubicaciónjobReference en la propiedad de la sección del recurso de trabajo.
Busca resultado mediante una llamada a getQueryResults.
Busca hasta que jobComplete sea igual a true. Verifica si hay errores y advertencias en la lista errors.
C#
Antes de probar este ejemplo, sigue las instrucciones de configuración para C# incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para C#.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Go
Antes de probar este ejemplo, sigue las instrucciones de configuración para Go incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Go.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Java
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Para ejecutar una consulta con un proxy, visita Configura un proxy.
Node.js
Antes de probar este ejemplo, sigue las instrucciones de configuración para Node.js incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Node.js.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
PHP
Antes de probar este ejemplo, sigue las instrucciones de configuración para PHP incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para PHP.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Python
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Python.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Ruby
Antes de probar este ejemplo, sigue las instrucciones de configuración para Ruby incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Ruby.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Ejecuta una consulta por lotes
Para ejecutar una consulta por lotes, selecciona una de las siguientes opciones:
Console
Ve a la página de BigQuery.
Haz clic en Consulta en SQL.
En el Editor de consultas, ingresa una consulta de GoogleSQL válida.
Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Haz clic en Más y, luego, en Configuración de consulta.
En la sección Administración de recursos, selecciona Por lotes.
Opcional: Ajusta la configuración de la consulta.
Haz clic en Guardar.
Haz clic en Ejecutar.
Si no especificas una tabla de destino, el trabajo de consulta escribe el resultado en una tabla temporal (en caché).
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Usa el comando
bq queryy especifica la marca--batch. En la siguiente marca, la marca--use_legacy_sql=falsete permite usar la sintaxis de GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
Reemplaza QUERY por una consulta de GoogleSQL válida. Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'El trabajo de consulta escribe el resultado en una tabla temporal (en caché).
De manera opcional, puedes especificar la tabla y la ubicación de destino para los resultados de la consulta. Si deseas escribir los resultados en una tabla existente, incluye la marca adecuada para agregar (
--append_table=true) o reemplazar (--replace=true) la tabla.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
Reemplaza lo siguiente:
LOCATION: Es la región o multirregión para la tabla de destino, por ejemplo,
US.En este ejemplo, el conjunto de datos
usa_namesse almacena en la ubicación multirregión de EE.UU. Si especificas una tabla de destino para esta consulta, el conjunto de datos que contiene la tabla de destino también debe estar en la multirregión de EE.UU. No puedes consultar un conjunto de datos en una ubicación y escribir los resultados en una tabla de destino en otra ubicación.Puedes configurar un valor predeterminado para la ubicación con el archivo .bigqueryrc.
TABLE: Es un nombre para la tabla de destino, por ejemplo,
myDataset.myTable.Si la tabla de destino es una tabla nueva, BigQuery crea la tabla cuando ejecutas la consulta. Sin embargo, debes especificar un conjunto de datos existente.
Si la tabla no está en tu proyecto actual, agrega el ID del proyectoGoogle Cloud con el formato
PROJECT_ID:DATASET.TABLE, por ejemplo,myProject:myDataset.myTable. Si no se especifica--destination_table, se genera un trabajo de consulta que escribe el resultado en una tabla temporal.
API
Para ejecutar una consulta con la API, inserta un nuevo trabajo y propaga la propiedad de configuración del trabajo query. Opcionalmente, especifica tu locationubicaciónjobReference en la propiedad de la sección del recurso de trabajo.
Cuando propagues las propiedades del trabajo de consulta, incluye la propiedad configuration.query.priority y establece el valor en BATCH.
Busca resultado mediante una llamada a getQueryResults.
Busca hasta que jobComplete sea igual a true. Verifica si hay errores y advertencias en la lista errors.
Go
Antes de probar este ejemplo, sigue las instrucciones de configuración para Go incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Go.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Java
Para ejecutar una consulta por lotes, establece la prioridad de consulta en QueryJobConfiguration.Priority.BATCH cuando crees una QueryJobConfiguration.
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Node.js
Antes de probar este ejemplo, sigue las instrucciones de configuración para Node.js incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Node.js.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Python
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Python.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Ejecuta una consulta continua
Ejecutar un trabajo de consulta continua requiere configuración adicional. Para obtener más información, consulta Crea consultas continuas.
Usa el panel Reference
En el editor de consultas, el panel Referencia muestra de forma dinámica información contextual sobre tablas, instantáneas, vistas y vistas materializadas. El panel te permite obtener una vista previa de los detalles del esquema de estos recursos o abrirlos en una pestaña nueva. También puedes usar el panel Referencia para crear consultas nuevas o editar las existentes insertando fragmentos de consultas o nombres de campos.
Para crear una consulta nueva con el panel Reference, sigue estos pasos:
En la consola de Google Cloud , ve a la página BigQuery.
Haz clic en Consulta en SQL.
Haz clic en quick_reference_all Referencia.
Haz clic en una tabla o vista reciente o destacada. También puedes usar la barra de búsqueda para encontrar tablas y vistas.
Haz clic en Ver acciones y, luego, en Insertar fragmento de consulta.
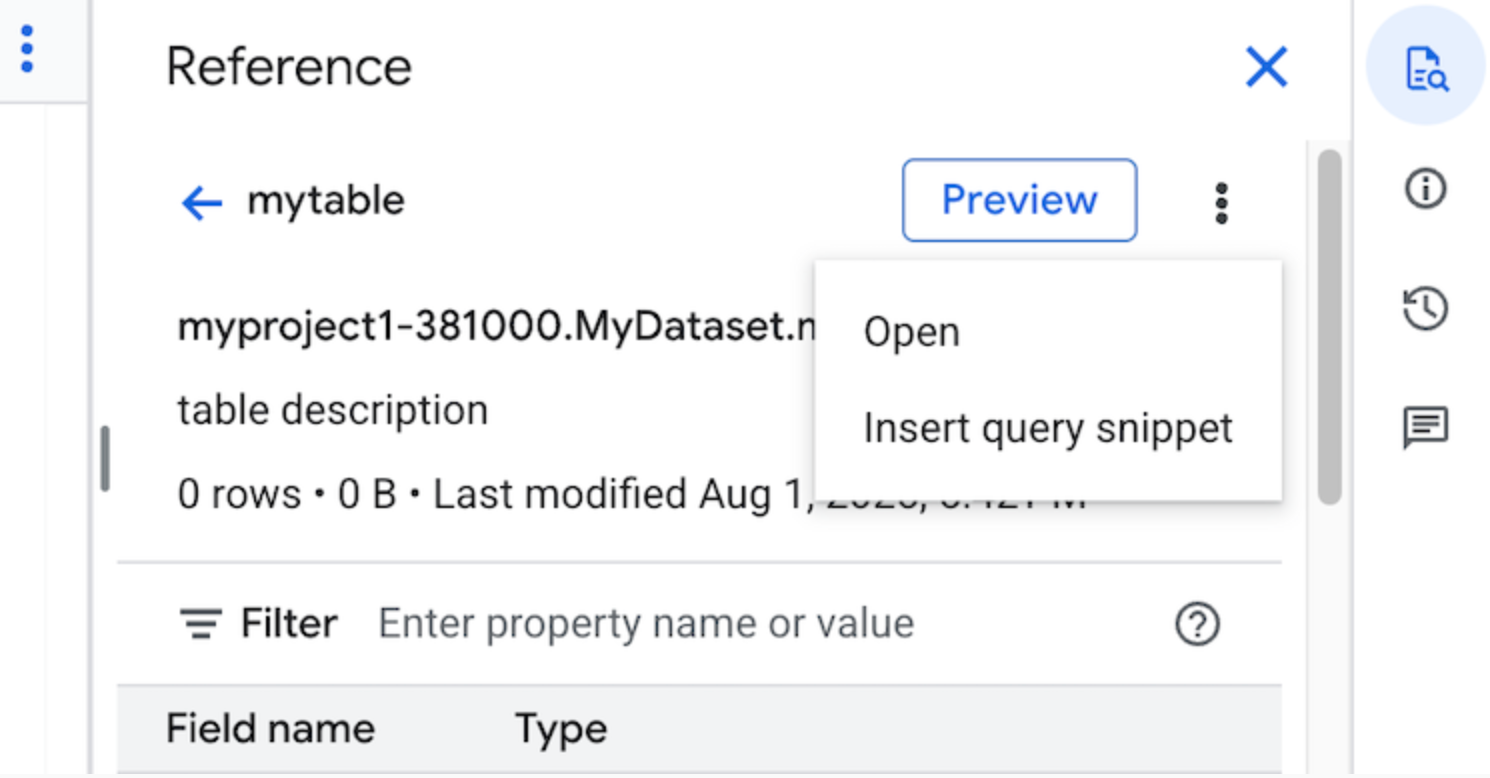
Opcional: Puedes obtener una vista previa de los detalles del esquema de la tabla o la vista, o bien abrirlos en una pestaña nueva.
Ahora puedes editar la consulta de forma manual o insertar nombres de campos directamente en ella. Para insertar un nombre de campo, apunta y haz clic en un lugar del editor de consultas en el que quieras insertarlo y, luego, haz clic en el nombre del campo en el panel Referencia.
Configuración de consulta
Cuando ejecutas una búsqueda, puedes especificar los siguientes parámetros de configuración:
Una tabla de destino para los resultados de la consulta.
Es la prioridad del trabajo.
Indica si se deben usar los resultados de las consultas en caché.
Es el tiempo de espera del trabajo en milisegundos.
Indica si se debe usar el modo de sesión.
Es el tipo de encriptación que se usará.
Es la cantidad máxima de bytes facturados por la búsqueda.
Es el dialecto de SQL que se usará.
Es la ubicación en la que se ejecutará la consulta. La consulta debe ejecutarse en la misma ubicación que las tablas a las que se hace referencia en ella.
Es la reserva para ejecutar tu búsqueda en (Vista previa).
Modo opcional de creación de trabajos
El modo opcional de creación de trabajos puede mejorar la latencia general de las consultas que se ejecutan durante un período breve, como las de los paneles o las cargas de trabajo de exploración de datos. En este modo, se ejecuta la consulta y se muestran los resultados intercalados para las instrucciones SELECT sin necesidad de usar jobs.getQueryResults para recuperar los resultados. Las consultas que usan el modo de creación de trabajos opcional no crean un trabajo cuando se ejecutan, a menos que BigQuery determine que es necesario crear un trabajo para completar la consulta.
Para habilitar el modo opcional de creación de trabajos, configura el campo jobCreationMode de la instancia QueryRequest en JOB_CREATION_OPTIONAL en el cuerpo de la solicitud jobs.query.
Cuando el valor de este campo se establece en JOB_CREATION_OPTIONAL, BigQuery determina si la consulta puede usar el modo opcional de creación de trabajos. Si es así, BigQuery ejecuta la consulta y devuelve todos los resultados en el campo rows de la respuesta. Como no se crea un trabajo para esta consulta, BigQuery no devuelve un jobReference en el cuerpo de la respuesta. En su lugar, devuelve un campo queryId, que puedes usar para obtener estadísticas sobre la búsqueda con la vista INFORMATION_SCHEMA.JOBS. Como no se crea ningún trabajo, no hay ningún jobReference que se pueda pasar a las APIs de jobs.get y jobs.getQueryResults para buscar estas consultas.
Si BigQuery determina que se requiere un trabajo para completar la consulta, se devuelve un jobReference. Puedes inspeccionar el campo job_creation_reason en la vista INFORMATION_SCHEMA.JOBS para determinar el motivo por el que se creó un trabajo para la consulta. En este caso, debes usar jobs.getQueryResults para recuperar los resultados cuando se complete la consulta.
Cuando usas el valor JOB_CREATION_OPTIONAL, es posible que el campo jobReference no esté presente en la respuesta. Verifica si el campo existe antes de acceder a él.
Cuando se especifica JOB_CREATION_OPTIONAL para consultas de varias instrucciones (secuencias de comandos), BigQuery puede optimizar el proceso de ejecución. Como parte de esta optimización, BigQuery puede determinar que puede completar la secuencia de comandos creando menos recursos de trabajo que la cantidad de instrucciones individuales, e incluso puede ejecutar toda la secuencia de comandos sin crear ningún trabajo.
Esta optimización depende de la evaluación que BigQuery realiza de la secuencia de comandos, y es posible que no se aplique en todos los casos. El sistema automatiza por completo la optimización. No se requieren controles ni acciones del usuario.
Para ejecutar una consulta con el modo de creación de trabajo opcional, selecciona una de las siguientes opciones:
Console
Ve a la página de BigQuery.
Haz clic en Consulta en SQL.
En el Editor de consultas, ingresa una consulta de GoogleSQL válida.
Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;Haz clic en Más y, luego, elige el modo de consulta Creación de trabajos opcional. Para confirmar esta elección, haz clic en Confirmar.
Haz clic en Ejecutar.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Usa el comando
bq queryy especifica la marca--job_creation_mode=JOB_CREATION_OPTIONAL. En la siguiente marca, la marca--use_legacy_sql=falsete permite usar la sintaxis de GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
Reemplaza QUERY por una consulta de GoogleSQL válida y LOCATION por una región válida en la que se encuentra el conjunto de datos. Por ejemplo, consulta el conjunto de datos públicos de BigQuery
usa_namespara determinar los nombres más comunes en Estados Unidos entre los años 1910 y 2013:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'El trabajo de consulta devuelve el resultado intercalado en la respuesta.
API
Para ejecutar una consulta en el modo de creación de trabajos opcional con la API, ejecuta una consulta de forma síncrona y propaga la propiedad QueryRequest. Especifica la propiedad jobCreationMode y establece su valor en JOB_CREATION_OPTIONAL.
Revisa la respuesta. Si jobComplete es igual a true y jobReference está vacío, lee los resultados del campo rows. También puedes obtener el queryId de la respuesta.
Si jobReference está presente, puedes verificar jobCreationReason para saber por qué BigQuery creó un trabajo. Busca resultado mediante una llamada a getQueryResults.
Sondea hasta que jobComplete sea igual a true. Verifica si hay errores y advertencias en la lista errors.
Java
Versión disponible: 2.51.0 y versiones posteriores
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Para ejecutar una consulta con un proxy, visita Configura un proxy.
Python
Versión disponible: 3.34.0 y versiones posteriores
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Python.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Nodo
Versión disponible: 8.1.0 y versiones posteriores
Antes de probar este ejemplo, sigue las instrucciones de configuración para Node.js incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Node.js.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Go
Versión disponible: 1.69.0 y versiones posteriores
Antes de probar este ejemplo, sigue las instrucciones de configuración para Go incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Go.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Controlador JDBC
Versión disponible: JDBC v1.6.1 y versiones posteriores
Requiere que se establezca JobCreationMode=2 en la cadena de conexión.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
Controlador ODBC
Versión disponible: ODBC v3.0.7.1016 y versiones posteriores
Requiere configurar JobCreationMode=2 en el archivo .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
Cuotas
Para obtener información sobre las cuotas relacionadas con las consultas interactivas y por lotes, consulta Trabajos de consulta.
Supervisa las consultas
Puedes obtener información sobre las consultas a medida que se ejecutan con el explorador de trabajos o consultando la vista INFORMATION_SCHEMA.JOBS_BY_PROJECT.
Ejecución de prueba
Una prueba de validación en BigQuery proporciona la siguiente información:
- estimación de cargos en el modo a pedido
- validación de tu consulta
- cantidad aproximada de bytes que procesa tu consulta en el modo de capacidad
Las pruebas de validación no usan ranuras de consulta y no se te cobra por realizar una prueba de validación. Puedes usar la estimación que muestra la ejecución de prueba para calcular los costos de las consultas en la calculadora de precios.
Realiza una ejecución de prueba
Para realizar una prueba de validación, sigue estos pasos:
Console
Dirígete a la página de BigQuery.
Ingresa tu consulta en el Editor de consultas.
Si la consulta es válida, aparecerá de forma automática una marca de verificación junto con la cantidad de datos que la consulta procesará. Si la consulta no es válida, aparece un signo de exclamación junto con un mensaje de error.
bq
Ingresa una consulta como la siguiente con la marca --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
Para una consulta válida, el comando genera la siguiente respuesta:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
Para realizar una ejecución de prueba mediante la API, envía un trabajo de consulta con dryRun configurado como true en el tipo JobConfiguration.
Go
Antes de probar este ejemplo, sigue las instrucciones de configuración para Go incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Go.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Java
Antes de probar este ejemplo, sigue las instrucciones de configuración para Java incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Java.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Node.js
Antes de probar este ejemplo, sigue las instrucciones de configuración para Node.js incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Node.js.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
PHP
Antes de probar este ejemplo, sigue las instrucciones de configuración para PHP incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para PHP.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Python
Configura la propiedad
QueryJobConfig.dry_run
como True.
Client.query() siempre muestra un QueryJob completo cuando se proporciona una configuración de consulta de ejecución de prueba.
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Python.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
¿Qué sigue?
- Obtén más información sobre cómo administrar trabajos de consulta.
- Obtén información sobre cómo ver el historial de consultas.
- Obtén información sobre cómo guardar y compartir consultas.
- Obtén más información sobre las colas de consultas.
- Obtén más información para escribir resultados de consultas.