BigQuery Studio にデータを読み込んでクエリを実行する
BigQuery を使用する手始めとして、BigQuery Studio を使用してデータセットを作成し、テーブルにデータを読み込み、テーブルに対してクエリを実行してみましょう。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、[ガイドを表示] をクリックしてください。
始める前に
BigQuery を使用する前に、Google Cloud コンソールにログインしてプロジェクトを作成する必要があります。プロジェクトで課金を有効にしていない場合、アップロードしたデータはすべて BigQuery サンドボックスに保存されます。このサンドボックスでは制限付きの BigQuery 機能を使用しながら、BigQuery について料金なしで学習できます。詳細については、BigQuery サンドボックスを有効にするをご覧ください。- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
- 省略可: 既存のプロジェクトを選択する場合は、必ず BigQuery API を有効にしてください。新しいプロジェクトでは、BigQuery API が自動的に有効になります。
- Google Cloud コンソールで、[BigQuery Studio] ページを開きます。 [BigQuery Studio] に移動
- [
エクスプローラ ] ペインでプロジェクト名をクリックします。 - [アクションを表示] をクリックします。
- [データセットを作成] を選択します。
- [データセットを作成する] ページで、次の操作を行います。
- [データセット ID] に「
babynames」と入力します。 - [ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。一般公開データセットは
usマルチリージョン ロケーションに保存されています。わかりやすくするため、データセットを同じロケーションに保存します。 - 残りのデフォルトの設定は変更せず、[
データセットを作成 ] をクリックします。 新しいブラウザタブで次の URL を開き、米国社会保障局のデータをダウンロードします。
https://www.ssa.gov/OACT/babynames/names.zipファイルを抽出します。
データセット スキーマの詳細については、zip ファイルの
NationalReadMe.pdfファイルをご覧ください。データの内容を確認するには、
yob2024.txtファイルを開きます。このファイルには、名前、出生時の性別、その名前の子供の数の値がカンマ区切りで含まれています。このファイルにはヘッダー行がありません。後で確認できるように、
yob2024.txtファイルの場所をメモします。- [
エクスプローラ ] ペインで、プロジェクト名を開きます。 - babynames データセットの横にある [ アクションを表示] をクリックし、[開く] を選択します。
- [ テーブルを作成] をクリックします。
特に指示のない限り、すべての設定にデフォルト値を使用します。
- [テーブルの作成] ページで、次の操作を行います。
- [ソース] セクションの [
テーブルの作成元 ] で、リストから [アップロード] を選択します。 - [ファイルを選択] フィールドで [参照] をクリックします。
- ローカルの
yob2024.txtファイルを選択して [開く] をクリックします。 - [
ファイル形式 ] リストから [CSV] を選択します。 - [宛先] セクションの [
テーブル ] フィールドに「names_2024」と入力します。 - [スキーマ] セクションで [
テキストとして編集 ] をクリックし、次のスキーマ定義をテキスト フィールドに貼り付けます。 - [
テーブルを作成 ] をクリックします。BigQuery によってテーブルが作成され、データが読み込まれるのを待ちます。
- [
エクスプローラ ] ペインで、プロジェクトとbabynamesデータセットを開いて、names_2024テーブルを選択します。 - [
プレビュー ] タブをクリックします。テーブルの最初の数行が BigQuery に表示されます。 - [names_2024] タブの横にある [ SQL クエリ] オプションをクリックします。新しいエディタタブが開きます。
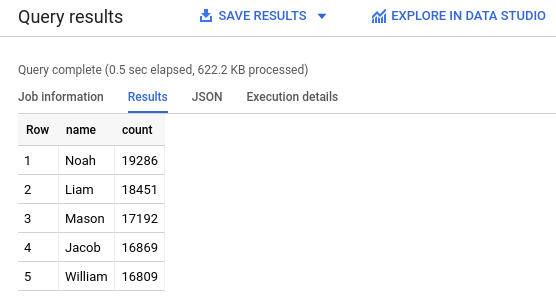
- 次のクエリをコピーしてクエリエディタに貼り付けます。このクエリは、2024 年に米国で生まれた男児につけられた名前のうち最も多いもの 5 つを取得します。
SELECT name, count FROM `babynames.names_2024` WHERE assigned_sex_at_birth = 'M' ORDER BY count DESC LIMIT 5; - [
実行 ] をクリックします。結果が [クエリ結果] セクションに表示されます。
- Google Cloud コンソールで、[BigQuery] ページを開きます。 [BigQuery] に移動
- [エクスプローラ] ペインで、作成した
babynamesデータセットをクリックします。 - [アクションを表示] オプションを開いて、[削除] をクリックします。
- [データセットの削除] ダイアログで削除コマンドを確定します。「
delete」という単語を入力して、[削除] をクリックします。 - BigQuery へのデータの読み込みの詳細については、データの読み込みの概要をご覧ください。
- データのクエリの詳細については、BigQuery 分析の概要をご覧ください。
- ネストされたデータと繰り返しデータを含む JSON ファイルの読み込みについて学習するには、ネストされた JSON データと繰り返し JSON データを読み込むをご覧ください。
- プログラムで BigQuery にアクセスする方法については、REST API リファレンスまたは BigQuery クライアント ライブラリのページをご覧ください。
BigQuery データセットを作成する
Google Cloud コンソールを使用して、データを保存するデータセットを作成します。データセットを作成する場所は、米国のマルチリージョン ロケーションとします。BigQuery のリージョンとマルチリージョンの詳細については、ロケーションをご覧ください。
ソースデータを含むファイルをダウンロードする
ダウンロードするファイルには、人気のある新生児の名前に関する約 7 MB のデータが含まれます。これは米国社会保障局から提供されています。このデータの詳細については、米国社会保障局の人気の名前の背景情報をご覧ください。
テーブルにデータを読み込む
次に、新しいテーブルにデータを読み込みます。
name:string,assigned_sex_at_birth:string,count:integerテーブルデータのプレビューを確認する
テーブルデータのプレビューを表示する手順は次のとおりです。
![テーブルの [プレビュー] タブ。](https://cloud.google.com/static/bigquery/images/table-preview-ui.png?authuser=1&hl=ja)
テーブルデータをクエリする
次に、テーブルに対してクエリを実行します。
これで、 Google Cloud コンソールを使用してサンプルデータを BigQuery に読み込み、一般公開データセット内のテーブルに対してクエリを正常に実行できました。
クリーンアップする
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。