Charger et interroger des données
Découvrez BigQuery en créant un ensemble de données, en chargeant des données dans une table et en interrogeant la table.
Pour obtenir des instructions détaillées sur cette tâche directement dans la console Google Cloud , cliquez sur Visite guidée :
Avant de commencer
Avant de pouvoir explorer BigQuery, vous devez vous connecter à la consoleGoogle Cloud et créer un projet. Si vous n'activez pas la facturation dans votre projet, toutes les données que vous importez sont placées dans le bac à sable BigQuery. Vous pouvez ainsi apprendre à utiliser BigQuery sans frais, mais en n'utilisant qu'un ensemble limité de fonctionnalités BigQuery. Pour en savoir plus, consultez Activer le bac à sable BigQuery.- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
- Facultatif : Si vous sélectionnez un projet existant, veillez à activer l'API BigQuery. L'API BigQuery est automatiquement activée dans les nouveaux projets.
- Dans la console Google Cloud , ouvrez la page "BigQuery". Accéder à BigQuery
- Dans le panneau de gauche, cliquez sur Explorer.
- Dans le volet
Explorateur , cliquez sur le nom de votre projet. - Cliquez sur Afficher les actions.
- Sélectionnez Create Dataset (Créer un ensemble de données).
- Sur la page Créer un ensemble de données, procédez comme suit :
- Dans le champ ID de l'ensemble de données, saisissez
babynames. - Pour Type d'emplacement, sélectionnez Multirégional, puis choisissez US (plusieurs régions aux États-Unis). Les ensembles de données publics sont stockés dans l'emplacement multirégional
us. Par souci de simplicité, stockez votre ensemble de données dans le même emplacement. - Conservez les autres paramètres par défaut, puis cliquez sur
Créer un ensemble de données . Téléchargez les données de l'Administration de la sécurité sociale des États-Unis en ouvrant l'URL suivante dans un nouvel onglet du navigateur :
https://www.ssa.gov/OACT/babynames/names.zipExtrayez le fichier.
Pour en savoir plus sur le schéma de l'ensemble de données, consultez le fichier
NationalReadMe.pdfdu fichier ZIP.Pour voir à quoi ressemblent les données, ouvrez le fichier
yob2024.txt. Ce fichier contient des valeurs séparées par une virgule spécifiant le prénom, le genre attribué à la naissance et le nombre d'enfants portant ce prénom. Le fichier ne comporte pas de ligne d'en-tête.Notez l'emplacement du fichier
yob2024.txtpour pouvoir le retrouver ultérieurement.- Dans le panneau de gauche, cliquez sur Explorer.
- Dans le volet
Explorateur , développez le nom de votre projet. - Cliquez sur Ensembles de données, puis à côté de l'ensemble de données babynames, cliquez sur Afficher les actions et sélectionnez Ouvrir.
- Cliquez sur Créer une table.
Sauf indication contraire, utilisez les valeurs par défaut pour tous les paramètres.
- Sur la page Créer une table, procédez comme suit :
- Dans la section Source, sous
Créer une table à partir de , sélectionnez Importer dans la liste. - Dans le champ Sélectionner un fichier, cliquez sur Parcourir.
- Accédez à votre fichier
yob2024.txtlocal et sélectionnez-le, puis cliquez sur Ouvrir. - Dans la liste
Format de fichier , sélectionnez CSV. - Dans la section Destination, saisissez
names_2024dans le champTable . - Dans la section Schéma, cliquez sur le bouton
Modifier sous forme de texte et collez la définition de schéma suivante dans le champ de texte : - Cliquez sur
Créer une table .Attendez que BigQuery crée la table et charge les données.
- Dans le panneau de gauche, cliquez sur Explorer.
- Dans le volet
Explorateur , développez votre projet et cliquez sur Ensembles de données. - Cliquez sur l'ensemble de données
babynames, puis sélectionnez la tablenames_2024. - Cliquez sur l'onglet
Aperçu . BigQuery affiche les premières lignes de la table. - À côté de l'onglet names_2024, cliquez sur l'option Requête SQL. Un nouvel onglet de l'éditeur s'ouvre.
- Dans l'éditeur de requête, collez la requête suivante. Cette requête permet de récupérer les cinq premiers prénoms donnés aux bébés qui ont été désignés hommes à la naissance aux États-Unis en 2024.
SELECT name, count FROM `babynames.names_2024` WHERE assigned_sex_at_birth = 'M' ORDER BY count DESC LIMIT 5; - Cliquez sur
Exécuter . Les résultats sont affichés dans la section Résultats de la requête.
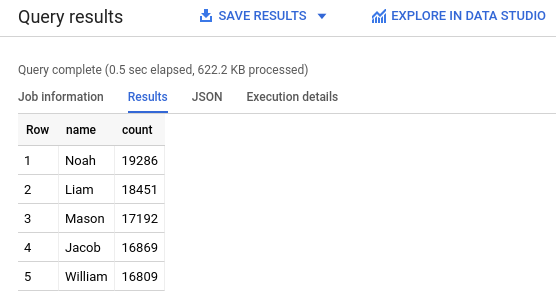
- Dans la console Google Cloud , ouvrez la page "BigQuery". Accéder à BigQuery
- Dans le panneau de gauche, cliquez sur Explorer.
- Dans le volet Explorateur, cliquez sur Ensembles de données, puis sur l'ensemble de données
babynamesque vous avez créé. - Développez l'option Afficher les actions, puis cliquez sur Supprimer.
- Dans la boîte de dialogue Supprimer l'ensemble de données, confirmez la commande de suppression en saisissant le mot
deleteavant de cliquer sur Supprimer. - Pour en savoir plus sur le chargement de données dans BigQuery, consultez la section Présentation du chargement des données.
- Pour en savoir plus sur l'interrogation des données, consultez Présentation des analyses BigQuery.
- Pour savoir comment charger un fichier JSON avec des données imbriquées et répétées, consultez la section Charger des données JSON imbriquées et répétées.
- Pour en savoir plus sur l'accès automatisé à BigQuery, consultez la documentation de référence de l'API REST ou la page Bibliothèques clientes BigQuery.
Créer un ensemble de données BigQuery
Vous pouvez créer un ensemble de données permettant de stocker les données à l'aide de la console Google Cloud . Vous créez votre ensemble de données dans l'emplacement multirégional US. Pour en savoir plus sur les régions et les emplacements multirégionaux BigQuery, consultez Emplacements.
Télécharger le fichier contenant les données sources
Le fichier que vous téléchargez contient environ 7 Mo de données correspondant aux prénoms populaires donnés aux bébés. Il provient de l'Administration de la sécurité sociale des États-Unis.Pour en savoir plus sur les données, consultez les informations générales sur les prénoms populaires de l'Administration de la sécurité sociale.
Charger des données dans une table
Ensuite, chargez les données dans une table.
name:string,assigned_sex_at_birth:string,count:integerPrévisualiser les données de la table
Pour prévisualiser les données de la table, procédez comme suit :
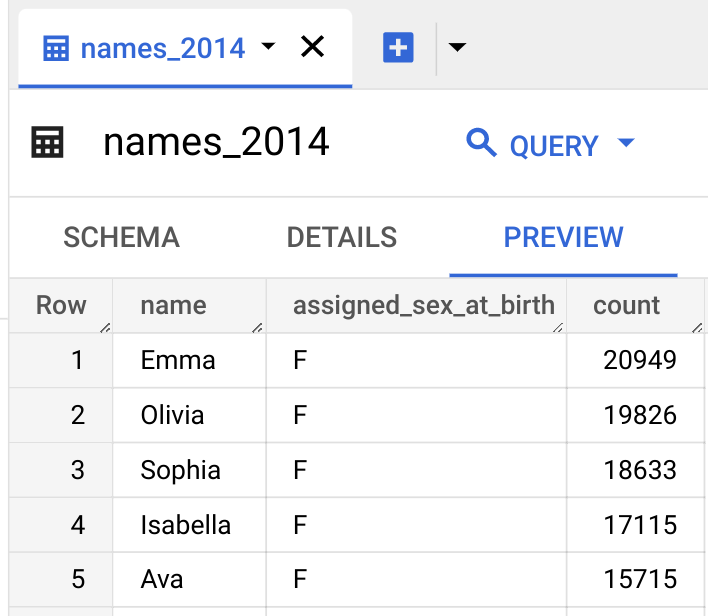
Interroger les données de la table
Vous allez maintenant interroger la table.
Vous avez interrogé une table dans un ensemble de données public, puis chargé vos exemples de données dans BigQuery à l'aide de la console Google Cloud .
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre compte Google Cloud , procédez comme suit :