プログラマティック分析ツール
このドキュメントでは、BigQuery で管理されるデータを分析するための、さまざまなコードの記述方法について説明します。
SQL は強力なクエリ言語ですが、Python、Java、R などのプログラミング言語では、特定の種類のデータ分析に役立つ構文や、組み込みの統計関数が提供されています。
同様に、スプレッドシートは広く使用されていますが、ノートブックなどのプログラミング環境では、複雑なデータ分析や探索のためのフレキシブル環境が提供される場合があります。
Colab Enterprise ノートブック
BigQuery で Colab Enterprise ノートブックを使用すると、SQL、Python などの一般的なパッケージと API を利用して分析と機械学習(ML)ワークフローを完了できます。ノートブックでは、次の手段によりコラボレーションと管理が向上します。
- Identity and Access Management(IAM)を使用して、特定のユーザーやグループとの間でノートブックを共有する。
- ノートブックの変更履歴を確認する。
- 以前のノートブック バージョンに戻すか、前のバージョンから分岐させる。
ノートブックは、Dataform が提供する BigQuery Studio コードアセットです。ただし、ノートブックは Dataform に表示されません。保存したクエリもコードアセットです。すべてのコードアセットは、デフォルトのリージョンに保存されます。デフォルト リージョンを更新すると、それ以降に作成されるすべてのコードアセットのリージョンが変更されます。
ノートブックの機能は Google Cloud コンソールでのみ使用できます。
BigQuery のノートブックには、次の利点があります。
- BigQuery DataFrames はノートブックに統合されているため、設定が不要です。BigQuery DataFrames は Python API であり、pandas DataFrameおよびscikit-learn API を使用して BigQuery データを大規模に分析するために使用できます。
- Gemini の生成 AI による支援コード開発。
- BigQuery エディタと同様の SQL ステートメントの予測入力機能。
- ノートブックのバージョンを保存、共有、管理する機能。
- matplotlib、seaborn などの一般的なライブラリを使用して、ワークフローの任意の時点でデータを可視化できます。
- ノートブックの Python 変数を参照できるセルで SQL を記述して実行する機能。
- 集計とカスタマイズをサポートするインタラクティブな DataFrame の可視化。
ノートブック ギャラリーのテンプレートを使用して、ノートブックの使用を開始できます。詳細については、ノートブック ギャラリーを使用してノートブックを作成するをご覧ください。
BigQuery DataFrames
BigQuery DataFrames は、使い慣れた Python API を使用して BigQuery データ処理を活用できるオープンソースの Python ライブラリ群です。BigQuery DataFrames は、SQL 変換を通じて処理を BigQuery にプッシュダウンすることで、pandas API と scikit-learn API を実装します。この設計により、BigQuery を使用してテラバイト単位のデータの探索と処理、ML モデルのトレーニングを行えます。これらの処理ではすべて Python API を使用します。
BigQuery DataFrames には、次のような利点があります。
- BigQuery API と BigQuery ML API への透過的な SQL 変換を通じて実装された 750 以上の pandas API と scikit-learn API。
- パフォーマンス向上のためのクエリの遅延実行。
- ユーザー定義の Python 関数でデータ変換を拡張し、クラウドでデータを処理できるようにします。これらの関数は、BigQuery のリモート関数として自動的にデプロイされます。
- Vertex AI とのインテグレーションにより、Gemini モデルを使用してテキストを生成できます。
その他のプログラマティック分析ソリューション
BigQuery では、次のプログラマティック分析ソリューションも使用できます。
Jupyter ノートブック
Jupyter は、ライブコード、テキスト記述、可視化を含むノートブックを公開するオープンソースのウェブ アプリケーションです。このプラットフォームは、データ サイエンティスト、ML の専門家、学生がデータのクリーニングと変換、数値シミュレーション、統計モデリング、データの可視化、ML などのタスクを行う際によく利用しています。
Jupyter ノートブックは、強力な対話型シェルである IPython カーネル上に構築されています。これは BigQuery 用 IPython マジックを使用して BigQuery を直接操作できます。また、利用可能な BigQuery クライアント ライブラリをインストールして、Jupyter ノートブック インスタンスから BigQuery にアクセスすることも可能です。Jupyter ノートブックで GeoJSON 拡張機能を使用して、BigQuery GIS データを可視化できます。BigQuery の統合の詳細は、Jupyter ノートブックでの BigQuery データの可視化に関するチュートリアルを参照してください。
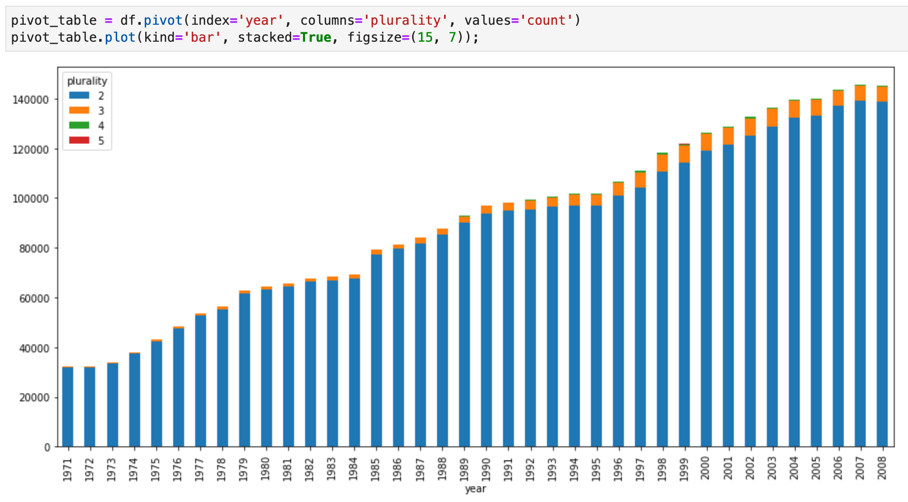
JupyterLab は、Jupyter ノートブック、テキスト エディタ、ターミナル、カスタム コンポーネントなどのドキュメントやアクティビティを管理するウェブベースのインターフェースです。JupyterLab では、複数のドキュメントやアクティビティを、タブと分割線を使って、作業領域に配置できます。
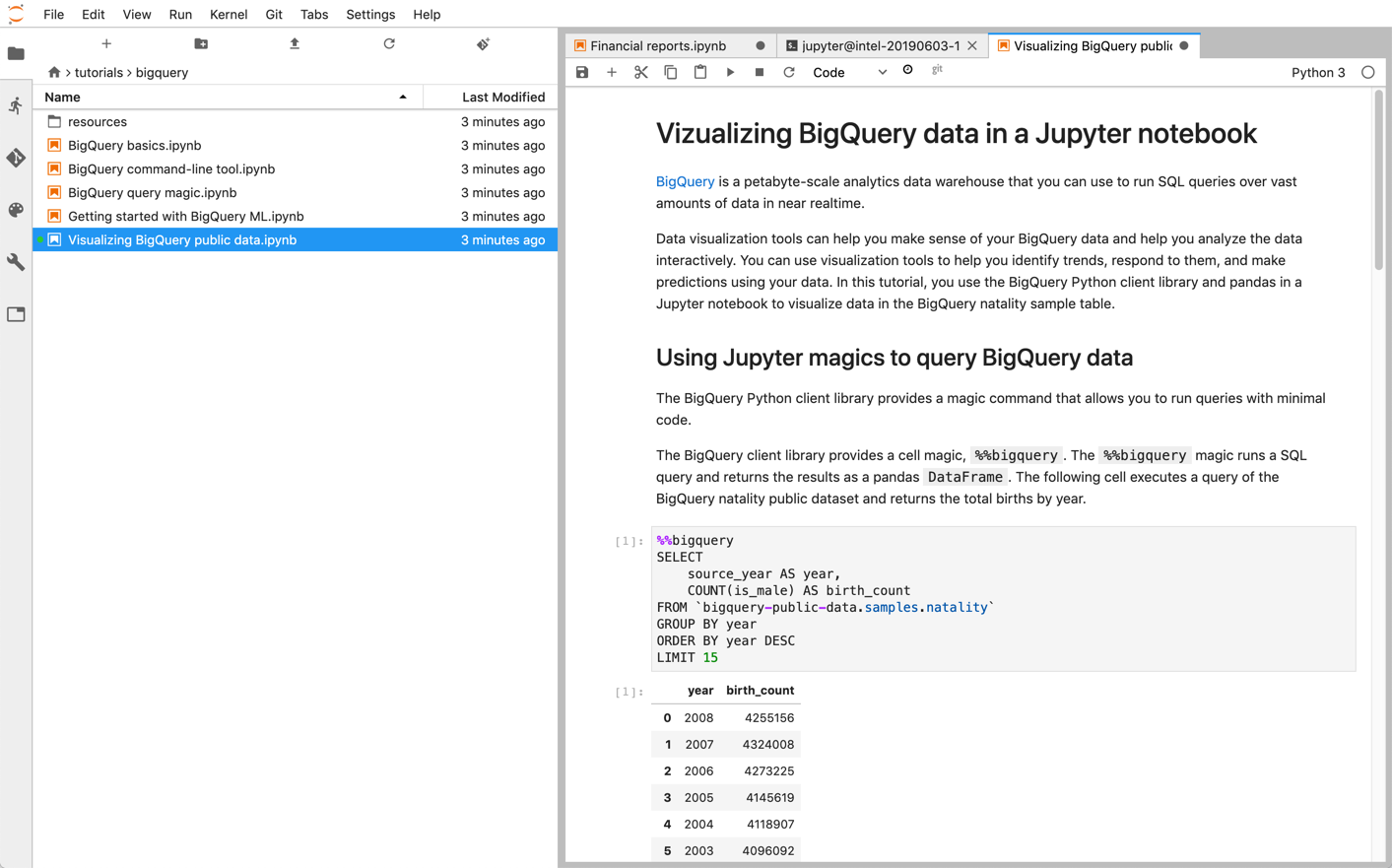
Google Cloud に Jupyter ノートブックと JupyterLab 環境をデプロイするには、次のいずれかのプロダクトを使用します。
- Vertex AI Workbench インスタンスは、ML デベロッパーとデータ サイエンティストが、最新のデータ サイエンスと ML フレームワークを利用できる、統合 JupyterLab 環境を提供するサービスです。Vertex AI Workbench では、BigQuery などの他の Google Cloud データ プロダクトと連携し、データの取り込みから前処理、データ探索、そして最終的なモデルのトレーニングとデプロイに至るまでを、スムーズに進めることができます。詳細については、Vertex AI Workbench インスタンスの概要をご覧ください。
- Dataproc は、Apache Spark と Apache Hadoop のクラスタを簡単かつ低コストで実行できる、高速で使いやすいフルマネージド サービスです。Jupyter のオプション コンポーネントを使用して Dataproc クラスタに、Jupyter ノートブックと JupyterLab をインストールできます。このコンポーネントには、PySpark コードを実行する Python カーネルが用意されています。デフォルトでは、Dataproc はノートブックを自動的に Cloud Storage に保存するように構成して、同じノートブック ファイルを他のクラスタからアクセスできるようにします。既存のノートブックを Dataproc に移行する場合、移行するノートブックの依存関係が、サポートされている Dataproc バージョンの対象となるかを確認するにはこちらをご覧ください。カスタム ソフトウェアをインストールする必要がある場合は、独自の Dataproc イメージを作成する、独自の初期化アクションを作成する、またはカスタム Python パッケージの要件を指定するオプションを検討してください。まず、Dataproc クラスタで Jupyter ノートブックをインストールして実行するチュートリアルを参照してください。
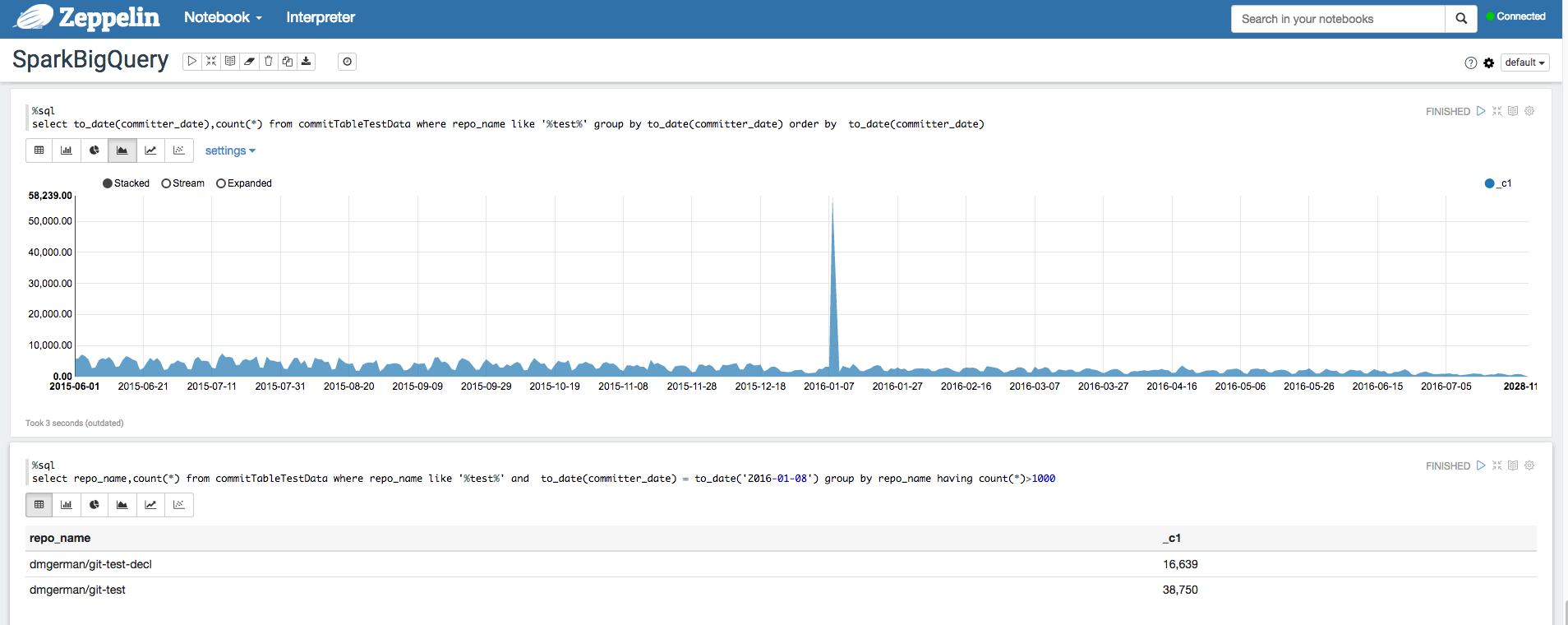
Apache Zeppelin
Apache Zeppelin は、データ分析にウェブベースのノートブックを提供するオープンソース プロジェクトです。Zeppelin のオプション コンポーネントをインストールすることにより、Dataproc に Apache Zeppelin のインスタンスをデプロイできます。デフォルトでは、ノートブックは Dataproc ステージング バケット内の Cloud Storage に保存されます。保存先バケットは、クラスタの作成時にユーザーが指定するか、指定がなければ自動作成されます。ノートブックの場所は、クラスタの作成時に zeppelin:zeppelin.notebook.gcs.dir というプロパティを追加して変更できます。Apache Zeppelin のインストールと構成の詳細については、Zeppelin コンポーネント ガイドをご覧ください。例については、Apache Zeppelin 向け BigQuery Interpreter インタープリタを使用した BigQuery データセットの分析をご覧ください。
Apache Hadoop、Apache Spark、Apache Hive
データ分析パイプラインの移行の一環として、データ ウェアハウスから直接データを処理する必要がある以前の Apache Hadoop、Apache Spark、Apache Hive ジョブを移行することもできます。たとえば、ML ワークロードの機能を抽出できます。
Dataproc を使用すると、フルマネージドの Hadoop クラスタと Spark クラスタを効率的かつコスト効果の高い方法でデプロイできます。Dataproc は、オープンソースの BigQuery コネクタと統合されています。これらのコネクタは BigQuery Storage API を使用し、gRPC を介して BigQuery から直接並列でデータをストリーミングします。
既存の Hadoop ワークロードと Spark ワークロードを Dataproc に移行する場合、移行するワークロードの依存関係が、サポートされている Dataproc バージョンの対象となるかを確認するにはこちらをご覧ください。カスタム ソフトウェアをインストールする必要がある場合は、独自の Dataproc イメージを作成する、独自の初期化アクションを作成する、またはカスタム Python パッケージの要件を指定するオプションを検討してください。
ご利用にあたっては、Dataproc クイックスタート ガイドと BigQuery コネクタのコードサンプルをご覧ください。
Apache Beam
Apache Beam は、ウィンドウ処理とセッション分析のプリミティブが豊富に用意されているだけでなく、ソースとシンクのコネクタからなるエコシステムも提供しているオープンソース フレームワークです。これには BigQuery 用のコネクタも含まれます。Apache Beam を使用して、ストリーミング(リアルタイム)モードのデータとバッチ(履歴)モードのデータを同等の信頼性と明瞭度で変換、拡充できます。
Dataflow は、Apache Beam ジョブを大規模に実行するためのフルマネージド サービスです。Dataflow のサーバーレス アプローチは、パフォーマンス、スケーリング、可用性、セキュリティ、コンプライアンスに自動的に対処することによって、運用上のオーバーヘッドを取り除きます。つまり、ユーザーはサーバー クラスタの管理ではなく、プログラミングに専念できるということです。
![複合変換(MakeMapView)が展開された実行グラフ。副入力を作成するサブ変換(CreateDataflowView)が選択されていて、[ステップ] タブに、そのサブ変換での副入力の指標が表示されています。](https://cloud.google.com/static/bigquery/images/dw2bq-reporting-and-analysis-apache-beam.png?authuser=4&hl=ja)
Dataflow ジョブは、コマンドライン インターフェース、Java SDK または Python SDK のいずれかを使用してさまざまな方法で送信できます。
データクエリとパイプラインを他のフレームワークから Apache Beam と Dataflow に移植するには、Apache Beam プログラミング モデルの詳細を確認して、公式の Dataflow ドキュメントをご覧ください。
その他のリソース
BigQuery は、Java、Go、Python、JavaScript、PHP、Ruby などの複数のプログラミング言語で、多数のクライアント ライブラリを提供します。pandas などのデータ分析フレームワークでは、BigQuery と直接やり取りするプラグインを提供しています。実用的な例については、Jupyter ノートブックで BigQuery データを可視化するチュートリアルをご覧ください。
最後に、シェル環境でプログラムを作成する場合は、bq コマンドライン ツールを使用します。