Introdução às tabelas particionadas
Uma tabela particionada é dividida em segmentos, denominados partições, que facilitam a gestão e a consulta dos seus dados. Ao dividir uma tabela grande em partições mais pequenas, pode melhorar o desempenho das consultas e controlar os custos reduzindo o número de bytes lidos por uma consulta. Particione tabelas especificando uma coluna de partição que é usada para segmentar a tabela.
Se uma consulta usar um filtro de qualificação no valor da coluna particionada, o BigQuery pode analisar as partições que correspondem ao filtro e ignorar as partições restantes. Este processo é denominado eliminação.
Numa tabela particionada, os dados são armazenados em blocos físicos, cada um dos quais contém uma partição de dados. Cada tabela particionada mantém vários metadados sobre as propriedades de ordenação em todas as operações que a modificam. Os metadados permitem ao BigQuery estimar com maior precisão o custo de uma consulta antes de a executar.
Quando usar a partição
Considere a partição de uma tabela nos seguintes cenários:
- Quer melhorar o desempenho das consultas apenas analisando uma parte de uma tabela.
- A operação de tabela excede uma quota de tabela padrão e pode restringir as operações de tabela a valores de colunas de partição específicos, o que permite quotas de tabelas particionadas mais elevadas.
- Quer determinar os custos das consultas antes de uma consulta ser executada. O BigQuery fornece estimativas de custos de consultas antes de a consulta ser executada numa tabela particionada. Calcule uma estimativa de custo de consulta reduzindo uma tabela particionada e, em seguida, emitindo um teste de execução de consulta para estimar os custos de consulta.
- Quiser qualquer uma das seguintes funcionalidades de gestão ao nível da partição:
- Defina um prazo de validade da partição para eliminar automaticamente partições inteiras após um período especificado.
- Escrever dados numa partição específica usando tarefas de carregamento sem afetar outras partições na tabela.
- Eliminar partições específicas sem analisar toda a tabela.
Considere agrupar uma tabela em vez de a particionar nas seguintes circunstâncias:
- Precisa de uma granularidade superior à permitida pela partição.
- As suas consultas usam frequentemente filtros ou agregação em várias colunas.
- A cardinalidade do número de valores numa coluna ou num grupo de colunas é elevada.
- Não precisa de estimativas de custos rigorosas antes da execução da consulta.
- A partição resulta numa pequena quantidade de dados por partição (aproximadamente inferior a 10 GB). A criação de muitas partições pequenas aumenta os metadados da tabela e pode afetar os tempos de acesso aos metadados quando consulta a tabela.
- A partição resulta num grande número de partições, excedendo os limites das tabelas particionadas.
- As suas operações DML modificam frequentemente (por exemplo, a cada poucos minutos) a maioria das partições na tabela.
Nesses casos, o agrupamento em tabelas permite-lhe acelerar as consultas agrupando dados em colunas específicas com base em propriedades de ordenação definidas pelo utilizador.
Também pode combinar a agrupagem e a partição de tabelas para conseguir uma ordenação mais detalhada. Para mais informações sobre esta abordagem, consulte o artigo Combinar tabelas particionadas e agrupadas.
Tipos de particionamento
Esta secção descreve as diferentes formas de dividir uma tabela.
Particionamento de intervalo de números inteiros
Pode particionar uma tabela com base em intervalos de valores numa INTEGERcoluna específica. Para criar uma tabela particionada por intervalo de números inteiros, fornece:
- A coluna de partição.
- O valor inicial da partição por intervalo (inclusive).
- O valor final da partição por intervalo (exclusivo).
- O intervalo de cada intervalo na partição.
Por exemplo, suponha que cria uma partição de intervalo de números inteiros com a seguinte especificação:
| Argumento | Valor |
|---|---|
| nome da coluna | customer_id |
| iniciar | 0 |
| fim | 100 |
| intervalo | 10 |
A tabela está particionada na coluna customer_id em intervalos de 10.
Os valores de 0 a 9 entram numa partição, os valores de 10 a 19 entram na partição seguinte, etc., até 99. Os valores fora deste intervalo entram numa partição
denominada __UNPARTITIONED__. Todas as linhas em que customer_id é NULL são colocadas numa partição denominada __NULL__.
Para obter informações sobre tabelas particionadas por intervalo de números inteiros, consulte o artigo Crie uma tabela particionada por intervalo de números inteiros.
Partição de colunas de unidades de tempo
Pode particionar uma tabela numa coluna DATE, TIMESTAMP ou DATETIME na tabela. Quando escreve dados na tabela, o BigQuery coloca automaticamente os dados na partição correta com base nos valores da coluna.
Para as colunas TIMESTAMP e DATETIME, as partições podem ter um nível de detalhe horário, diário, mensal ou anual. Para colunas DATE, as partições podem ter um nível de detalhe diário, mensal ou anual. Os limites das partições baseiam-se na hora UTC.
Por exemplo, suponha que particiona uma tabela numa coluna DATETIME com
partição mensal. Se inserir os seguintes valores na tabela, as linhas são escritas nas seguintes partições:
| Valor da coluna | Partição (mensal) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
Além disso, são criadas duas partições especiais:
__NULL__: contém linhas com valoresNULLna coluna de partição.__UNPARTITIONED__: contém linhas em que o valor da coluna de partição é anterior a 01/01/1960 ou posterior a 31/12/2159.
Para obter informações sobre tabelas particionadas por colunas de unidades de tempo, consulte o artigo Crie uma tabela particionada por colunas de unidades de tempo.
Particionamento por tempo de carregamento
Quando cria uma tabela particionada por tempo de ingestão, o BigQuery atribui automaticamente linhas a partições com base na hora em que o BigQuery ingere os dados. Pode escolher o nível de detalhe por hora, dia, mês ou ano para as partições. Os limites das partições baseiam-se na hora UTC.
Se os seus dados puderem atingir o número máximo de partições por tabela quando usar uma granularidade de tempo mais detalhada, use uma granularidade mais grosseira. Por exemplo, pode fazer a partição por mês em vez de por dia para reduzir o número de partições. Também pode agrupar a coluna de partição para melhorar ainda mais o desempenho.
Uma tabela particionada por tempo de ingestão tem uma pseudocoluna denominada _PARTITIONTIME.
O valor desta coluna é a hora de carregamento de cada linha, truncada para o limite da partição (por exemplo, por hora ou por dia). Por exemplo, suponha que cria uma tabela particionada por tempo de ingestão com partição por hora e envia dados nos seguintes horários:
| Hora do carregamento | _PARTITIONTIME |
Partição (por hora) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
Uma vez que a tabela neste exemplo usa a partição por hora, o valor de
_PARTITIONTIME é truncado para um limite de hora. O BigQuery usa este valor para determinar a partição correta para os dados.
Também pode escrever dados numa partição específica. Por exemplo, pode querer carregar dados do histórico ou ajustar os fusos horários. Pode usar qualquer data válida entre 01/01/0001 e 31/12/9999. No entanto, as declarações DML não podem fazer referência a datas anteriores a 01-01-1970 nem posteriores a 31-12-2159. Para mais informações, consulte o artigo Escreva dados numa partição específica.
Em vez de usar _PARTITIONTIME, também pode usar
_PARTITIONDATE.
A pseudocoluna _PARTITIONDATE contém a data UTC correspondente ao valor
na pseudocoluna _PARTITIONTIME.
Selecione a partição diária, por hora, mensal ou anual
Quando particiona uma tabela por coluna de unidade de tempo ou tempo de carregamento, escolhe se as partições têm um nível de detalhe diário, por hora, mensal ou anual.
A partição diária é o tipo de partição predefinido. A partição diária é uma boa opção quando os dados estão distribuídos por um vasto intervalo de datas ou se os dados são adicionados continuamente ao longo do tempo.
Escolha a partição por hora se as suas tabelas tiverem um volume elevado de dados que abranja um curto intervalo de datas, normalmente, menos de seis meses de valores de data/hora. Se escolher a partição por hora, certifique-se de que a quantidade de partições permanece dentro dos limites de partições.
Escolha a partição mensal ou anual se as suas tabelas tiverem uma quantidade relativamente pequena de dados para cada dia, mas abrangerem um intervalo de datas amplo. Esta opção também é recomendada se o seu fluxo de trabalho exigir a atualização frequente ou a adição de linhas que abranjam um vasto intervalo de datas (por exemplo, mais de 500 datas). Nestes cenários, use a partição mensal ou anual juntamente com a agrupamento na coluna de partição para alcançar o melhor desempenho. Para mais informações, consulte Combinar tabelas particionadas e agrupadas neste documento.
Combinar tabelas particionadas e agrupadas
Pode combinar a partição de tabelas com a agrupamento de tabelas para conseguir uma ordenação detalhada para uma maior otimização das consultas.
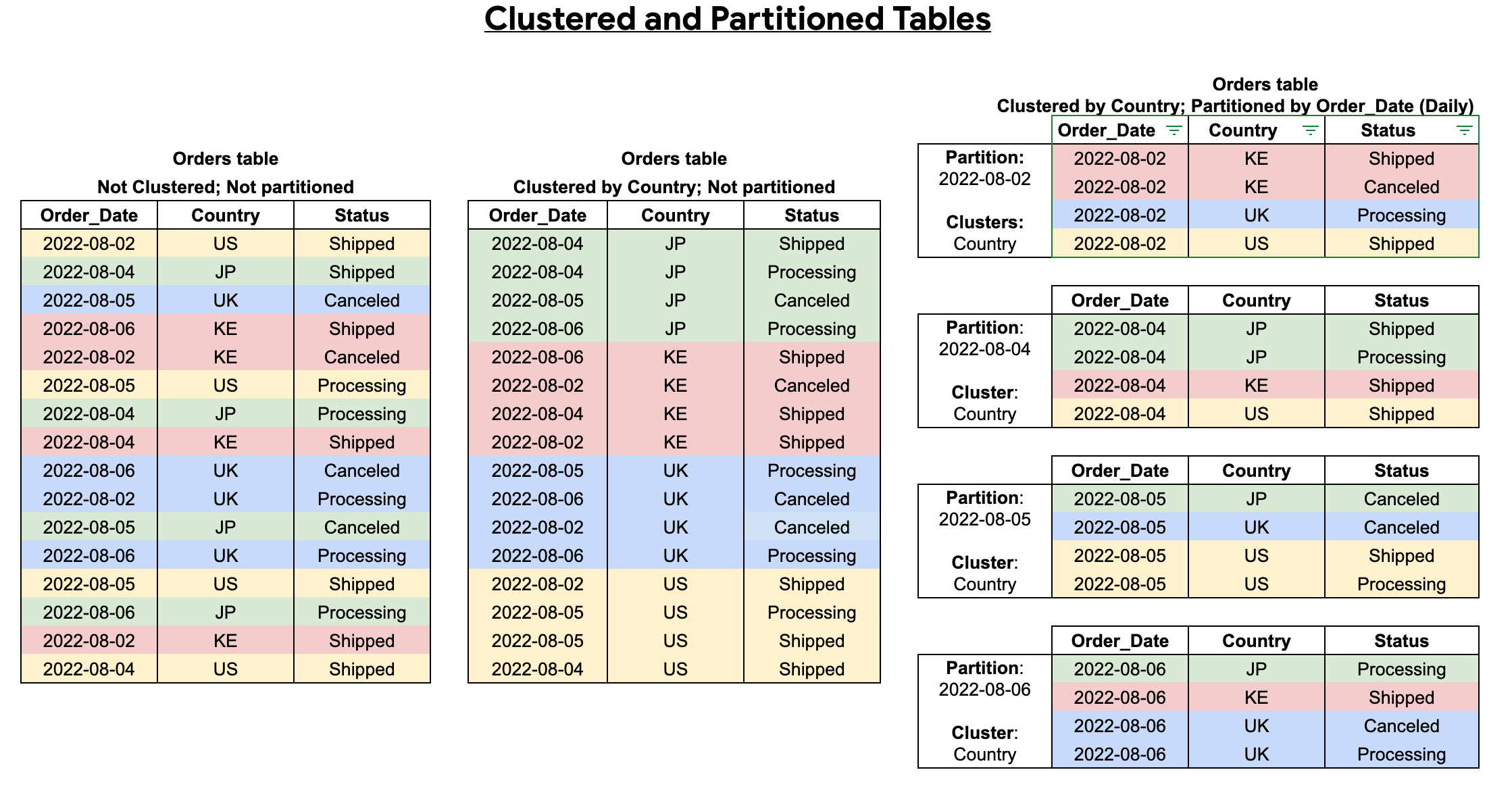
Uma tabela agrupada contém colunas agrupadas que ordenam os dados com base em propriedades de ordenação definidas pelo utilizador. Os dados destas colunas agrupadas são ordenados em blocos de armazenamento com tamanho adaptável com base no tamanho da tabela. Quando executa uma consulta que filtra pela coluna de clustering, o BigQuery analisa apenas os blocos relevantes com base nas colunas de clustering, em vez de analisar toda a tabela ou partição da tabela. Numa abordagem combinada que usa a partição de tabelas e a agrupamento, primeiro segmenta os dados da tabela em partições e, em seguida, agrupa os dados em cada partição pelas colunas de agrupamento.
Quando cria uma tabela agrupada e particionada, pode conseguir uma ordenação mais detalhada, como mostra o diagrama seguinte:
Partição versus divisão
A divisão de tabelas é a prática de armazenar dados em várias tabelas, usando um prefixo de nomenclatura, como [PREFIX]_YYYYMMDD.
A partição é recomendada em vez da divisão de tabelas, porque as tabelas particionadas têm um melhor desempenho. Com as tabelas fragmentadas, o BigQuery tem de manter uma cópia do esquema e dos metadados para cada tabela. O BigQuery também pode ter de validar as autorizações de cada tabela consultada. Esta prática também aumenta a sobrecarga de consultas e afeta o desempenho das consultas.
Se criou anteriormente tabelas divididas por datas, pode convertê-las numa tabela particionada por tempo de carregamento. Para mais informações, consulte o artigo Converta tabelas divididas por data em tabelas particionadas por tempo de ingestão.
Decoradores de partições
Os decoradores de partições permitem-lhe fazer referência a uma partição numa tabela. Por exemplo, pode usá-las para escrever dados numa partição específica.
Um decorador de partição tem o formato table_name$partition_id, em que o formato do segmento partition_id depende do tipo de partição:
| Tipo de partição | Formato | Exemplo |
|---|---|---|
| De hora em hora | yyyymmddhh |
my_table$2021071205 |
| Diariamente | yyyymmdd |
my_table$20210712 |
| Mensalmente | yyyymm |
my_table$202107 |
| Anual | yyyy |
my_table$2021 |
| Intervalo de números inteiros | range_start |
my_table$40 |
Explore os dados numa partição
Para procurar os dados numa partição especificada, use o comando
bq head com um
decorador de partição.
Por exemplo, o comando seguinte apresenta todos os campos nas primeiras 10 linhas de my_dataset.my_table na partição 2018-02-24:
bq head --max_rows=10 'my_dataset.my_table$20180224'
Exporte dados de tabelas
A exportação de todos os dados de uma tabela particionada é o mesmo processo que a exportação de dados de uma tabela não particionada. Para mais informações, consulte o artigo Exportar dados de tabelas.
Para exportar dados de uma partição individual, use o comando bq extract e anexe o decorador de partição ao nome da tabela. Por exemplo, my_table$20160201. Também pode exportar dados das partições __NULL__ e __UNPARTITIONED__ anexando os nomes das partições ao nome da tabela. Por exemplo,
my_table$__NULL__ ou my_table$__UNPARTITIONED__.
Limitações
As tabelas particionadas têm as seguintes limitações:
Não pode usar o SQL antigo para consultar tabelas particionadas nem para escrever resultados de consultas em tabelas particionadas.
O BigQuery não suporta a partição por várias colunas. Só é possível usar uma coluna para particionar uma tabela.
Não pode converter diretamente uma tabela não particionada existente numa tabela particionada. A estratégia de partição é definida quando a tabela é criada. Em alternativa, use a declaração
CREATE TABLEpara criar uma nova tabela particionada consultando os dados na tabela existente.As tabelas particionadas por colunas de unidades de tempo estão sujeitas às seguintes limitações:
- A coluna de partição tem de ser uma coluna escalar
DATE,TIMESTAMPouDATETIME. Embora o modo da coluna possa serREQUIREDouNULLABLE, não pode serREPEATED(com base em matrizes). - A coluna de particionamento tem de ser um campo de nível superior. Não pode usar um campo de folha de uma
RECORD(STRUCT) como coluna de partição.
Para obter informações sobre tabelas particionadas por colunas de unidades de tempo, consulte o artigo Crie uma tabela particionada por colunas de unidades de tempo.
- A coluna de partição tem de ser uma coluna escalar
As tabelas particionadas por intervalo de números inteiros estão sujeitas às seguintes limitações:
- A coluna de partição tem de ser uma coluna
INTEGER. Embora o modo da coluna possa serREQUIREDouNULLABLE, não pode serREPEATED(com base em matrizes). - A coluna de particionamento tem de ser um campo de nível superior. Não pode usar um campo de folha de uma
RECORD(STRUCT) como coluna de partição.
Para obter informações sobre tabelas particionadas por intervalo de números inteiros, consulte o artigo Crie uma tabela particionada por intervalo de números inteiros.
- A coluna de partição tem de ser uma coluna
Quotas e limites
As tabelas particionadas têm limites definidos no BigQuery.
As quotas e os limites também se aplicam aos diferentes tipos de tarefas que pode executar em tabelas particionadas, incluindo:
- Carregar dados (tarefas de carregamento)
- Exportar dados (tarefas de exportação)
- Consultar dados (tarefas de consulta)
- Copiar tabelas (tarefas de cópia)
Para mais informações sobre todas as quotas e limites, consulte o artigo Quotas e limites.
Preços das mesas
Quando cria e usa tabelas particionadas no BigQuery, os seus custos baseiam-se na quantidade de dados armazenados nas partições e nas consultas que executa nos dados:
- Para ver informações sobre os preços de armazenamento, consulte o artigo Preços de armazenamento.
- Para ver informações sobre os preços das consultas, consulte o artigo Preços das consultas.
Muitas operações de tabelas particionadas são gratuitas, incluindo o carregamento de dados em partições, a cópia de partições e a exportação de dados de partições. Embora sejam gratuitas, estas operações estão sujeitas às quotas e aos limites do BigQuery. Para informações sobre todas as operações gratuitas, consulte Operações gratuitas na página de preços.
Para ver as práticas recomendadas para controlar os custos no BigQuery, consulte o artigo Controlar os custos no BigQuery
Segurança da mesa
O controlo de acesso para tabelas particionadas é igual ao controlo de acesso para tabelas padrão. Para mais informações, consulte o artigo Introdução aos controlos de acesso a tabelas.
O que se segue?
- Para saber como criar tabelas particionadas, consulte o artigo Criar tabelas particionadas.
- Para saber como gerir e atualizar tabelas particionadas, consulte o artigo Gerir tabelas particionadas.
- Para obter informações sobre como consultar tabelas particionadas, consulte o artigo Consultar tabelas particionadas.