Présentation des tables partitionnées
Une table partitionnée est divisée en segments, appelés partitions, qui permettent de gérer et d'interroger facilement les données. En divisant une grande table en partitions plus petites, vous pouvez améliorer les performances des requêtes et maîtriser les coûts, car le nombre d'octets traités par une requête est réduit. Pour partitionner les tables, spécifiez une colonne de partition permettant de les segmenter.
Si une requête utilise un filtre éligible sur la valeur de la colonne de partitionnement, BigQuery peut analyser les partitions correspondant au filtre et ignorer les partitions restantes. Ce processus est appelé élimination.
Dans une table partitionnée, les données sont stockées dans des blocs physiques, chacun contenant une partition de données. Chaque table partitionnée conserve diverses métadonnées relatives aux propriétés de tri pour toutes les opérations qui la modifient. Les métadonnées permettent à BigQuery d'estimer plus précisément le coût d'une requête avant son exécution.
Quand utiliser le partitionnement
Envisagez de partitionner une table dans les scénarios suivants :
- Vous souhaitez améliorer les performances des requêtes en analysant uniquement une partie d'une table.
- Votre opération de table dépasse un quota de table standard et vous pouvez limiter les opérations de table à des valeurs de colonne de partition spécifiques, ce qui autorise des quotas de tables partitionnées plus élevés.
- Vous souhaitez déterminer le coût des requêtes avant leur exécution. BigQuery fournit des estimations du coût de la requête avant que celle-ci ne soit exécutée sur une table partitionnée. Estimez les coûts des requêtes en éliminant une table partitionnée, puis en exécutant une simulation de requête pour estimer les coûts des requêtes.
- Vous souhaitez utiliser l'une des fonctionnalités de gestion suivantes au niveau de la partition :
- Définir un délai d'expiration de partition pour supprimer automatiquement des partitions entières après un certain délai.
- Écrire des données dans une partition spécifique à l'aide de jobs de chargement sans affecter les autres partitions de la table.
- Supprimer des partitions spécifiques sans analyser l'intégralité de la table.
Envisagez le clustering d'une table plutôt que de la partitionner dans les cas suivants :
- Vous avez besoin de plus de précision que le partitionnement ne le permet.
- Vos requêtes utilisent généralement des filtres ou des agrégations sur plusieurs colonnes.
- La cardinalité du nombre de valeurs dans une colonne ou dans un groupe de colonnes est importante.
- Vous n'avez pas besoin d'estimations de coût strictes avant d'exécuter la requête.
- Le partitionnement génère une petite quantité de données par partition (moins de 10 Go, environ). La création de nombreuses petites partitions augmente les métadonnées de la table et peut affecter les temps d'accès aux métadonnées lors de l'interrogation de la table.
- Le partitionnement entraîne un grand nombre de partitions au-delà des limites imposées sur les tables partitionnées.
- Vos opérations LMD modifient fréquemment (par exemple, toutes les quelques minutes) la plupart des partitions de la table.
Dans ce cas, le clustering de tables vous permet d'accélérer les requêtes en mettant en cluster les données dans des colonnes spécifiques en fonction des propriétés de tri définies par l'utilisateur.
Vous pouvez également combiner le clustering et le partitionnement de tables pour obtenir un tri plus précis. Pour en savoir plus sur cette approche, consultez la page Combiner des tables en cluster et des partitions.
Types de partitionnement
Cette section décrit les différentes façons de partitionner une table.
Partitionnement par plages d'entiers
Vous pouvez partitionner une table en fonction de plages de valeurs dans une colonne INTEGER spécifique. Pour créer une table partitionnée par plages d'entiers, vous devez fournir :
- La colonne de partitionnement.
- La valeur de début pour le partitionnement de la plage (inclusive).
- La valeur de fin pour le partitionnement de la plage (exclusive).
- L'intervalle de chaque plage dans la partition.
Par exemple, supposons que vous créez une partition par plages d'entiers avec la spécification suivante :
| Argument | Valeur |
|---|---|
| nom de la colonne | customer_id |
| start | 0 |
| fin | 100 |
| intervalle | 10 |
La table est partitionnée en fonction de la colonne customer_id par plages d'intervalle de 10.
Les valeurs 0 à 9 vont dans une partition, les valeurs 10 à 19 vont dans la partition suivante, et ainsi de suite jusqu'à 99. Les valeurs situées en dehors de cette plage sont incluses dans une partition nommée __UNPARTITIONED__. Toutes les lignes où customer_id correspond à NULL vont dans une partition nommée __NULL__.
Pour plus d'informations sur les tables partitionnées par plages d'entiers, consultez la page Créer une table partitionnée par plages d'entiers.
Partitionnement par colonnes d'unités de temps
Vous pouvez partitionner une table sur une colonne DATE, TIMESTAMP ou DATETIME de la table. Lorsque vous écrivez des données dans la table, BigQuery les enregistre automatiquement dans la partition appropriée en fonction des valeurs dans la colonne.
Pour les colonnes TIMESTAMP et DATETIME, les partitions peuvent avoir une précision horaire, quotidienne, mensuelle ou annuelle. Pour les colonnes DATE, les partitions peuvent avoir une précision quotidienne, mensuelle ou annuelle. Les limites des partitions sont basées sur l'heure UTC.
Par exemple, supposons que vous partitionnez une table sur une colonne DATETIME avec partitionnement mensuel. Si vous insérez les valeurs suivantes dans la table, les lignes sont écrites dans les partitions suivantes :
| Valeur de la colonne | Partition (par mois) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
En outre, deux partitions spéciales sont créées :
__NULL__: contient les lignes avec des valeursNULLdans la colonne de partitionnement.__UNPARTITIONED__: contient les lignes pour lesquelles la valeur de la colonne de partitionnement est antérieure au 01-01-1960 ou ultérieure au 31-12-2159.
Pour en savoir plus sur les tables partitionnées par colonne d'unité de temps, consultez la page Créer une table partitionnée par colonne d'unité de temps.
Partitionnement par date d'ingestion
Lorsque vous créez une table partitionnée par date d'ingestion, BigQuery attribue automatiquement les lignes aux partitions en fonction de la date d'ingestion des données par BigQuery. Vous pouvez définir une précision horaire, quotidienne, mensuelle ou annuelle pour les partitions. Les limites des partitions sont basées sur l'heure UTC.
Si vos données peuvent atteindre le nombre maximal de partitions par table lorsque vous utilisez une précision plus élevée, utilisez plutôt une précision plus faible. Par exemple, vous pouvez partitionner les données par mois plutôt que par jour afin de réduire le nombre de partitions. Vous pouvez également mettre en cluster la colonne de partition pour améliorer davantage les performances.
Une table partitionnée par date d'ingestion comprend une pseudo-colonne nommée _PARTITIONTIME.
La valeur de cette colonne correspond à la date d'ingestion de chaque ligne, tronquée à la limite de la partition (par exemple, à l'heure ou au jour près). Par exemple, supposons que vous créez une table partitionnée par date d'ingestion avec un partitionnement horaire et que vous envoyez des données aux heures suivantes :
| Date d'ingestion | _PARTITIONTIME |
Partition (par heure) |
|---|---|---|
| 2021-05-07 17:22:00 | 07-05-2021 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 07-05-2021 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 07-05-2021 18:00:00 | 2021050718 |
Comme la table de cet exemple utilise le partitionnement horaire, la valeur de _PARTITIONTIME est tronquée à l'heure près. BigQuery utilise cette valeur pour déterminer la partition appropriée pour les données.
Vous pouvez également écrire des données dans une partition spécifique. Par exemple, vous pouvez charger des données de l'historique ou ajuster les fuseaux horaires. Vous pouvez utiliser n'importe quelle date valide comprise entre le 01-01-0001 et le 31-12-9999. Toutefois, les instructions LMD ne peuvent pas faire référence à des dates antérieures au 01-01-1970 ou postérieures à 31-12-2159. Pour en savoir plus, consultez la section Écrire des données dans une partition spécifique.
Au lieu d'utiliser _PARTITIONTIME, vous pouvez également utiliser _PARTITIONDATE.
La pseudo-colonne _PARTITIONDATE contient la date UTC correspondant à la valeur de la pseudo-colonne _PARTITIONTIME.
Sélectionner le partitionnement quotidien, horaire, mensuel ou annuel
Lorsque vous partitionnez une table par colonnes d'unités de temps ou par date d'ingestion, vous pouvez choisir le type de partitionnement : quotidien, horaire, mensuel ou annuel.
Le partitionnement quotidien est le type de partitionnement par défaut. Le partitionnement quotidien est un bon choix lorsque vos données sont réparties sur une grande plage de dates ou si des données sont ajoutées en permanence au fil du temps.
Choisissez le partitionnement horaire si vos tables contiennent un volume élevé de données couvrant une courte période (généralement moins de six mois de valeurs d'horodatage). Si vous choisissez le partitionnement horaire, assurez-vous que le nombre de partitions respecte les limites de partition.
Choisissez le partitionnement mensuel ou annuel si vos tables contiennent une quantité de données relativement faible pour chaque jour mais s'appliquent à une grande plage de dates. Cette option de partitionnement est également recommandée si votre workflow nécessite de mettre à jour ou d'ajouter fréquemment des lignes qui couvrent une grande plage de dates (par exemple, plus de 500 dates). Dans de tels scénarios, utilisez le partitionnement mensuel ou annuel avec un clustering sur la colonne de partitionnement pour obtenir des performances optimales. Pour plus d'informations, consultez la section Combiner des tables en cluster et des partitions dans ce document.
Combiner des tables en cluster et partitionnées
Vous pouvez combiner le partitionnement de table avec un clustering de tables pour effectuer un tri précis afin d'optimiser davantage les requêtes.
Une table en cluster contient des colonnes en cluster qui trient les données en fonction des propriétés de tri définies par l'utilisateur. Les données de ces colonnes en cluster sont triées en blocs de stockage qui sont dimensionnés de manière adaptative en fonction de la taille de la table. Lorsque vous exécutez une requête qui filtre par colonne en cluster, BigQuery analyse uniquement les blocs pertinents en fonction des colonnes en cluster plutôt que de l'intégralité de la table ou de la partition de table. Dans une approche combinée utilisant le partitionnement et le clustering des tables, vous devez d'abord segmenter les données des tables en partitions, puis regrouper les données dans chaque partition par les colonnes de clustering.
Lorsque vous créez une table en cluster et partitionnée, vous pouvez effectuer un tri plus précis, comme le montre le schéma suivant :
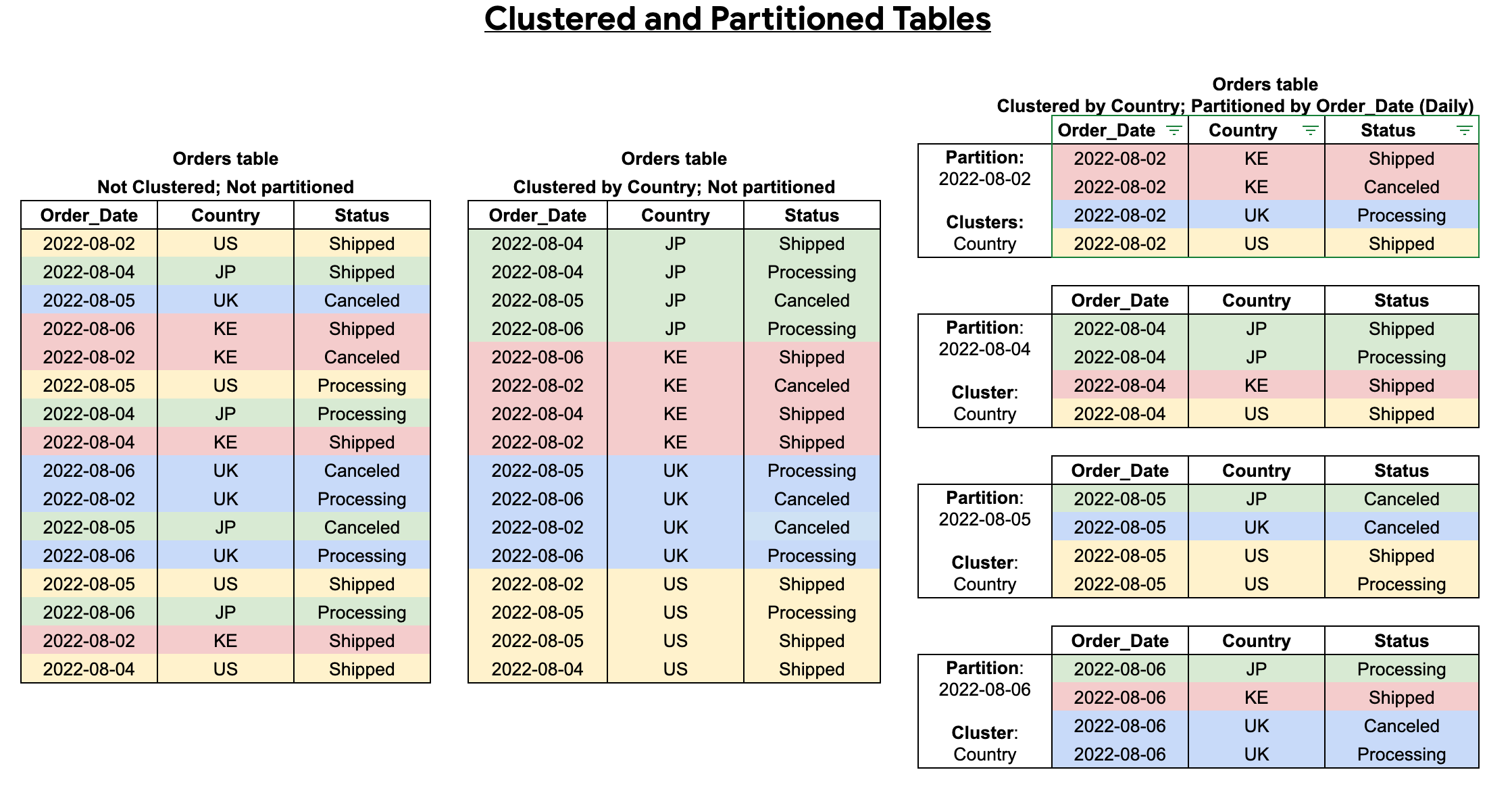
Partitionnement et segmentation
La segmentation des tables est la pratique qui consiste à stocker les données dans plusieurs tables en utilisant un préfixe de nom tel que [PREFIX]_YYYYMMDD.
Nous recommandons le partitionnement plutôt que la segmentation des tables car les tables partitionnées sont plus performantes. Avec les tables segmentées, BigQuery doit conserver une copie du schéma et des métadonnées pour chaque table. BigQuery devra peut-être également valider les autorisations pour chaque table interrogée. Cette pratique alourdit le traitement des requêtes et affecte les performances.
Si vous avez déjà créé des tables segmentées par date, vous pouvez les convertir en tables partitionnées par date d'ingestion. Pour plus d'informations, consultez la section Convertir des tables segmentées par date en tables partitionnées par date d'ingestion.
Décorateurs de partition
Les décorateurs de partition vous permettent de référencer une partition dans une table. Par exemple, vous pouvez les utiliser pour écrire des données dans une partition spécifique.
Un décorateur de partition se présente sous la forme table_name$partition_id, où le format du segment partition_id dépend du type de partitionnement :
| Type de partitionnement | Format | Exemple |
|---|---|---|
| Toutes les heures | yyyymmddhh |
my_table$2021071205 |
| Quotidien | yyyymmdd |
my_table$20210712 |
| Mensuel | yyyymm |
my_table$202107 |
| Annuel | yyyy |
my_table$2021 |
| Plage d'entiers | range_start |
my_table$40 |
Parcourir les données d'une partition
Pour parcourir les données dans une partition spécifiée, utilisez la commande bq head avec un décorateur de partition.
Par exemple, la commande suivante répertorie tous les champs des 10 premières lignes de my_dataset.my_table dans la partition 2018-02-24 :
bq head --max_rows=10 'my_dataset.my_table$20180224'
Les exporter
La procédure d'exportation de l'intégralité des données à partir d'une table partitionnée est identique à l'exportation de données à partir d'une table non partitionnée. Pour en savoir plus, consultez la page Exporter des données de table.
Pour exporter les données d'une partition individuelle, utilisez la commande bq extract et ajoutez le décorateur de partition au nom de la table. Par exemple, my_table$20160201. Vous pouvez également exporter les données des partitions __NULL__ et __UNPARTITIONED__ en ajoutant les noms des partitions au nom de la table. Par exemple, my_table$__NULL__ ou my_table$__UNPARTITIONED__.
Limites
Les tables partitionnées présentent les limites suivantes :
Vous ne pouvez pas utiliser l'ancien SQL pour interroger des tables partitionnées ou pour écrire des résultats de requêtes dans des tables partitionnées.
BigQuery n'est pas compatible avec le partitionnement par plusieurs colonnes. Une seule colonne peut être utilisée pour partitionner une table.
Vous ne pouvez pas convertir directement une table non partitionnée existante en table partitionnée. La stratégie de partitionnement est définie lors de la création de la table. Au lieu de cela, utilisez l'instruction
CREATE TABLEpour créer une table partitionnée en interrogeant les données de la table existante.Les tables partitionnées par colonnes d'unités de temps sont soumises aux limitations suivantes :
- La colonne de partitionnement doit être une colonne scalaire de type
DATE,TIMESTAMPouDATETIME. Le mode de la colonne peut être de typeREQUIREDouNULLABLE, mais pasREPEATED(basé sur des tableaux). - La colonne de partitionnement doit être un champ de niveau supérieur. Vous ne pouvez pas utiliser un champ feuille d'un élément
RECORD(STRUCT) comme colonne de partitionnement.
Pour en savoir plus sur les tables partitionnées par colonne d'unité de temps, consultez la page Créer une table partitionnée par colonne d'unité de temps.
- La colonne de partitionnement doit être une colonne scalaire de type
Les tables partitionnées par plages d'entiers sont soumises aux limitations suivantes :
- La colonne de partitionnement doit être de type
INTEGER. Le mode de la colonne peut être de typeREQUIREDouNULLABLE, mais pasREPEATED(basé sur des tableaux). - La colonne de partitionnement doit être un champ de niveau supérieur. Vous ne pouvez pas utiliser un champ feuille d'un élément
RECORD(STRUCT) comme colonne de partitionnement.
Pour plus d'informations sur les tables partitionnées par plages d'entiers, consultez la page Créer une table partitionnée par plages d'entiers.
- La colonne de partitionnement doit être de type
Quotas et limites
Les tables partitionnées sont soumises à certaines limites dans BigQuery.
Ces quotas et limites s'appliquent également aux différents types de tâches que vous pouvez exécuter sur des tables partitionnées :
- Chargement de données (tâches de chargement)
- Exporter des données (tâches d'exportation)
- Interroger des données (tâches de requête)
- Copier des tables (tâches de copie)
Pour plus d'informations sur tous les quotas et limites, consultez la page Quotas et limites.
Tarifs des tables
Lorsque vous créez et utilisez des tables partitionnées dans BigQuery, vos frais sont basés sur la quantité de données stockées dans les partitions et sur les requêtes que vous exécutez sur les données :
- Pour en savoir plus sur la tarification relative au stockage, consultez la section Tarifs du stockage.
- Pour en savoir plus sur la tarification relative aux requêtes, consultez la section Tarifs des requêtes.
De nombreuses opérations de table partitionnée sont gratuites, en particulier le chargement de données dans des partitions, la copie de partitions et l'exportation de données à partir de partitions. Bien que gratuites, ces opérations sont soumises aux quotas et limites de BigQuery. Pour en savoir plus sur toutes les opérations gratuites, consultez la section Opérations gratuites sur la page des tarifs.
Pour connaître les bonnes pratiques en matière de contrôle des coûts dans BigQuery, consultez la page Contrôler les coûts dans BigQuery.
Sécurité des tables
Le contrôle d'accès des tables partitionnées est identique à celui des tables standards. Pour plus d'informations, consultez la page Présentation des contrôles d'accès aux tables.
Étape suivante
- Pour apprendre à créer des tables partitionnées, consultez la page Créer des tables partitionnées.
- Pour savoir comment gérer et mettre à jour des tables partitionnées, consultez la page Gérer des tables partitionnées.
- Pour en savoir plus sur l'interrogation des tables partitionnées, consultez la page Interroger des tables partitionnées.