Introducción a las tablas particionadas
Las tablas particionadas se dividen en segmentos, denominados particiones, que facilitan la administración y la consulta de los datos. Dividir una tabla grande en particiones más pequeñas puede mejorar el rendimiento de las consultas y ayudarlo a controlar sus costos, ya que se reduce la cantidad de bytes que lee una consulta. Para particionar las tablas, especifica una columna de partición que se usará para segmentar la tabla.
Si una consulta usa un filtro apto en el valor de la columna de partición, BigQuery puede analizar las particiones que coinciden con el filtro y omitir las particiones restantes. Este proceso se conoce como reducción.
En una tabla particionada, los datos se almacenan en bloques físicos, y cada uno de ellos contiene una partición de datos. Cada tabla particionada mantiene varios metadatos sobre las propiedades de orden en todas las operaciones que la modifican. Los metadatos permiten que BigQuery calcule con mayor precisión un costo de consulta antes de ejecutar la consulta.
Cuándo usar la partición
Considera particionar una tabla en las siguientes situaciones:
- Deseas mejorar el rendimiento de las consultas mediante el análisis de una parte de una tabla.
- La operación de tu tabla supera una cuota de tabla estándar y puedes definir el alcance de las operaciones de tabla a valores de columna de partición específicos que permiten cuotas de tablas particionadas más altas.
- Deseas determinar los costos de consulta antes de que esta se ejecute. BigQuery proporciona estimaciones de costos de consulta antes de que se ejecute la consulta en una tabla particionada. Calcula una estimación de costos de consulta mediante la reducción de una tabla particionada y, luego, la emisión de una prueba de validación de la consulta para estimar los costos de consulta.
- Deseas usar cualquiera de las siguientes funciones de administración a nivel de partición:
- Establece un tiempo de vencimiento de la partición para borrar de forma automática todas las particiones después de un período específico.
- Escribir datos en una partición específica mediante trabajos de carga sin afectar otras particiones de la tabla.
- Borra particiones específicas sin analizar toda la tabla.
Considera agrupar en clústeres una tabla en lugar de particionar una tabla en las circunstancias siguientes:
- Cuando necesites un nivel de detalle mayor que el que permite la partición.
- Por lo general, tus consultas usan filtros o agregación en varias columnas.
- La cardinalidad del número de valores en una columna o grupo de columnas es grande.
- Cuando no necesitas estimaciones de costos estrictas antes de la ejecución de la consulta.
- La partición da como resultado una pequeña cantidad de datos por partición (aproximadamente menos de 10 GB). La creación de muchas particiones pequeñas aumenta los metadatos de la tabla y puede afectar los tiempos de acceso a los metadatos cuando se consulta la tabla.
- La partición genera una gran cantidad de particiones más allá de los límites de las tablas particionadas.
- Tus operaciones DML modifican con frecuencia (por ejemplo, cada pocos minutos) la mayoría de las particiones de la tabla.
En esos casos, el agrupamiento en clústeres de las tablas te permite acelerar las consultas mediante la agrupación de datos en columnas específicas según las propiedades de orden definidas por el usuario.
También puedes combinar el agrupamiento en clústeres y la partición de tablas para lograr una clasificación más detallada. Para obtener más información sobre este enfoque, consulta Combina tablas agrupadas en clústeres y particionadas.
Tipos de particiones:
En esta sección, se describen las diferentes formas de particionar una tabla.
Partición por rangos de números enteros
Puedes particionar una tabla en función de rangos de valores en una columna INTEGER específica. Para crear una tabla particionada por rangos de números enteros, debes proporcionar lo siguiente:
- La columna de partición
- El valor inicial para la partición de rangos (inclusivo)
- El valor final para la partición de rangos (exclusivo)
- El intervalo de cada rango dentro de la partición
Por ejemplo, supongamos que creas una partición por rangos de números enteros con la siguiente especificación:
| Argumento | Valor |
|---|---|
| nombre de la columna | customer_id |
| iniciar | 0 |
| finalizar | 100 |
| intervalo | 10 |
La tabla está particionada en la columna customer_id en rangos de intervalo 10.
Los valores del 0 al 9 van a una partición, los valores del 10 al 19 van a la siguiente partición, etc., hasta 99. Los valores fuera de este rango van a una partición llamada __UNPARTITIONED__. Cualquier fila en la que customer_id sea NULL van a una partición llamada __NULL__.
Para obtener información sobre las tablas particionadas por rango de número entero, consulta Crea una tabla particionada por rango de número entero.
Partición de columnas por unidad de tiempo
Puedes particionar una tabla en una columna DATE, TIMESTAMP o DATETIME en la tabla. Cuando escribes datos en la tabla, BigQuery coloca los datos en la partición correcta de forma automática, según los valores de la columna.
Para las columnas TIMESTAMP y DATETIME, las particiones pueden tener un nivel de detalle por hora, diario, mensual o anual. Para las columnas DATE, las particiones pueden tener un nivel de detalle diario, mensual o anual. Los límites de partición se basan en la hora UTC.
Por ejemplo, supongamos que particionas una tabla en una columna DATETIME con partición mensual. Si insertas los siguientes valores en la tabla, las filas se escriben en las siguientes particiones:
| Valor de columna | Partición (mensual) |
|---|---|
DATETIME("2019-01-01") |
201901 |
DATETIME("2019-01-15") |
201901 |
DATETIME("2019-04-30") |
201904 |
Además, se crean dos particiones especiales:
__NULL__contiene filas con valoresNULLen la columna de partición.__UNPARTITIONED__: Contiene filas en las que el valor de la columna de partición es anterior al 01/01/1960 o posterior al 31/12/2159.
Para obtener información sobre las tablas particionadas por columnas de unidad de tiempo, consulta Crea una tabla particionada por columnas de unidad de tiempo.
Partición por tiempo de transferencia
Cuando creas una tabla particionada por tiempo de transferencia, BigQuery asigna de forma automática filas a las particiones en función del momento en que BigQuery transfiere los datos. Puedes elegir el nivel de detalle por hora, día, mes o año para las particiones. Los límites de partición se basan en la hora UTC.
Si tus datos pueden alcanzar la cantidad máxima de particiones por tabla cuando usas un nivel de detalle mayor, usa un nivel de detalle más amplio. Por ejemplo, puedes realizar particiones por mes en lugar de días a fin de reducir la cantidad de particiones. También puedes agrupar en clústeres la columna de partición para mejorar aún más el rendimiento.
Una tabla particionada por tiempo de transferencia tiene una seudocolumna llamada _PARTITIONTIME.
El valor de esta columna es el tiempo de transferencia para cada fila, truncado al límite de partición (como por hora o por día). Por ejemplo, supongamos que creas una tabla particionada por tiempo de transferencia con partición por hora y envías datos en los siguientes momentos:
| Tiempo de transferencia | _PARTITIONTIME |
Partición (por hora) |
|---|---|---|
| 2021-05-07 17:22:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 17:40:00 | 2021-05-07 17:00:00 | 2021050717 |
| 2021-05-07 18:31:00 | 2021-05-07 18:00:00 | 2021050718 |
Debido a que en la tabla de este ejemplo se usa la partición por hora, el valor de _PARTITIONTIME se trunca a un límite de hora. BigQuery usa este valor a fin de determinar la partición correcta para los datos.
También puedes escribir datos en una partición específica. Por ejemplo, es posible que desees cargar datos históricos o ajustarlos para zonas horarias. Puedes usar cualquier fecha válida entre el 01/01/0001 y el 31/12/9999. Sin embargo, las declaraciones DML no pueden hacer referencia a fechas anteriores al 01/01/1970 o posteriores al 31/12/2159. Para obtener más información, consulta Escribe datos en una partición específica.
En lugar de _PARTITIONTIME, también puedes usar _PARTITIONDATE.
La seudocolumna _PARTITIONDATE contiene la fecha UTC correspondiente al valor de la seudocolumna _PARTITIONTIME.
Elige particiones diarias, por hora, mensuales o anuales
Cuando particionas una tabla por columna de unidad de tiempo o tiempo de transferencia, eliges si las particiones tienen un nivel de detalle por día, hora, mes o año.
La partición diaria es el tipo de partición predeterminado. La partición diaria es una buena opción cuando tus datos se distribuyen en un amplio rango de fechas o si se agregan de forma continua en el tiempo.
Elige la partición por hora si las tablas tienen un gran volumen de datos que abarca un período corto (por lo general, menos de seis meses de valores de marca de tiempo). Si eliges la partición por hora, asegúrate de que el recuento de particiones permanezca dentro de los límites de partición.
Elige la partición mensual o anual si tus tablas tienen una cantidad de datos relativamente pequeña por cada día, pero abarcan un período amplio. Esta opción también se recomienda si el flujo de trabajo requiere actualizar o agregar con frecuencia filas que abarquen un período amplio (por ejemplo, más de 500 fechas). En estas situaciones, usa la partición mensual o anual junto con el agrupamiento en clústeres en la columna de partición para lograr el mejor rendimiento. Para obtener más información, consulta Combina tablas agrupadas en clústeres y particionadas en este documento.
Combina tablas agrupadas en clústeres y particionadas
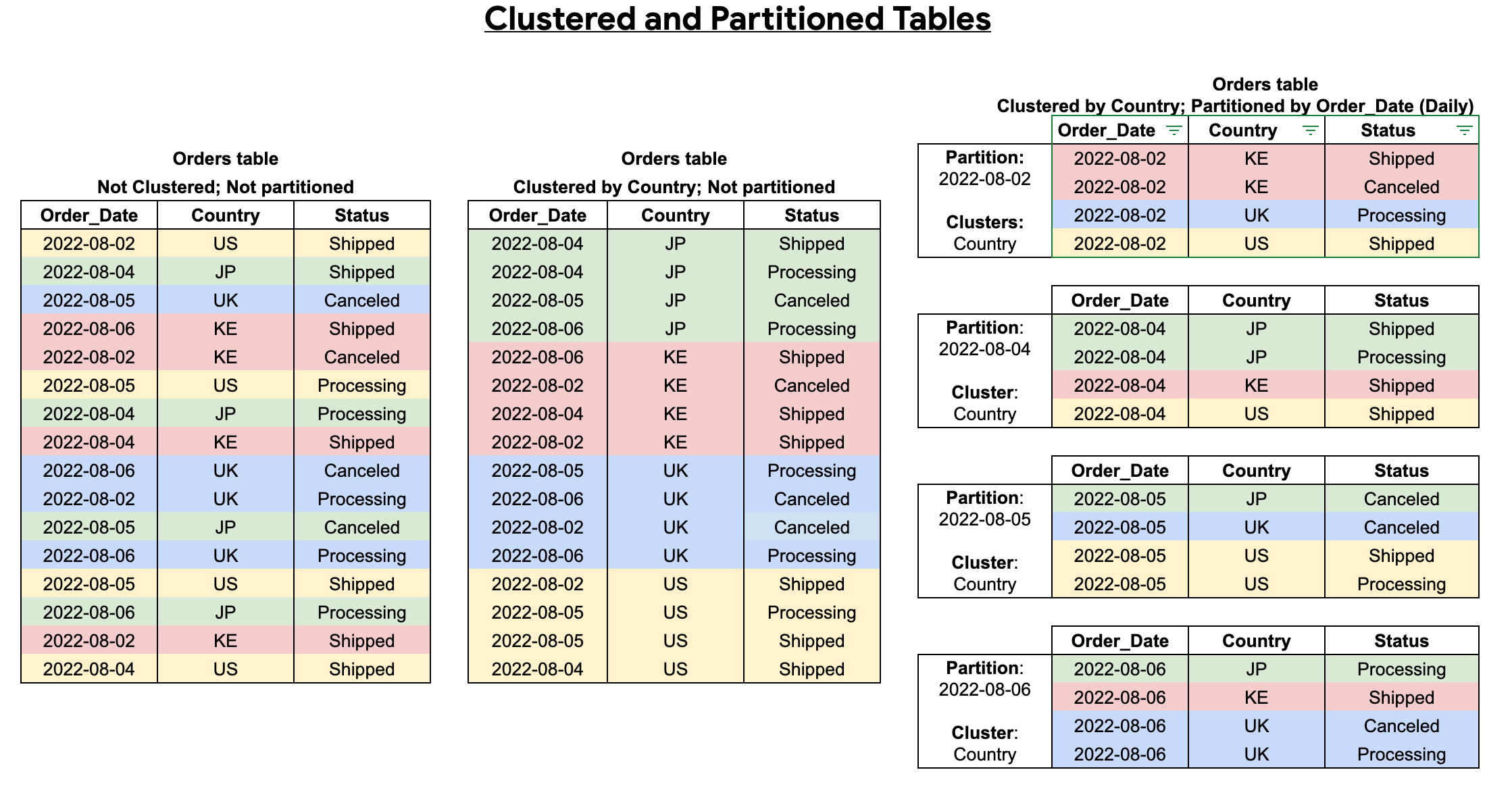
Puedes combinar la partición de tablas con el agrupamiento en clústeres de tablas para lograr una clasificación detallada a fin de optimizar más las consultas.
Una tabla agrupada en clústeres contiene columnas agrupadas en clústeres que ordenan los datos según las propiedades de orden definidas por el usuario. Los datos de estas columnas agrupadas se ordenan en bloques de almacenamiento que tienen un tamaño adaptable según el tamaño de la tabla. Cuando ejecutas una consulta que filtra por la columna agrupada en clústeres, BigQuery solo analiza los bloques relevantes en función de las columnas agrupadas en clústeres, en lugar de la tabla completa o la partición de la tabla. En un enfoque combinado en el que se usan la partición de tablas y el agrupamiento en clústeres, primero segmentas los datos de las tablas en particiones y, luego, agrupas en clústeres los datos en cada partición según las columnas de agrupamiento en clústeres.
Cuando creas una tabla agrupada y particionada, puedes lograr una clasificación más detallada, como se muestra en el siguiente diagrama:
Partición en comparación con fragmentación
La fragmentación de tablas es la práctica de almacenar datos en varias tablas mediante un prefijo de nombres, como [PREFIX]_YYYYMMDD.
Se recomienda realizar particiones en lugar de fragmentación de tabla, puesto que las tablas particionadas tienen un mejor rendimiento. Con las tablas fragmentadas, BigQuery debe mantener una copia del esquema y los metadatos para cada tabla. BigQuery también podría verificar los permisos para cada tabla consultada. Esta práctica también aumenta la sobrecarga de la búsqueda y afecta su rendimiento.
Si ya creaste tablas fragmentadas por fecha, puedes convertirlas en una tabla particionada por tiempo de transferencia. Para obtener más información, consulta la sección sobre cómo convertir tablas fragmentadas por fecha en tablas particionadas por tiempo de transferencia.
Decoradores de particiones
Los decoradores de particiones te permiten hacer referencia a una partición en una tabla. Por ejemplo, puedes usarlos para escribir datos en una partición específica.
Un decorador de partición tiene el formato table_name$partition_id, en el que el formato del segmento partition_id depende del tipo de partición:
| Tipo de partición | Formato | Ejemplo |
|---|---|---|
| Por hora | yyyymmddhh |
my_table$2021071205 |
| Por día | yyyymmdd |
my_table$20210712 |
| Mensual | yyyymm |
my_table$202107 |
| Anual | yyyy |
my_table$2021 |
| Rango de números enteros | range_start |
my_table$40 |
Explora los datos en una partición
Para explorar los datos de una partición específica, usa el comando bq head con un decorador de partición.
Por ejemplo, en el siguiente comando, se enumeran todos los campos en las primeras 10 filas de
my_dataset.my_table en la partición 2018-02-24:
bq head --max_rows=10 'my_dataset.my_table$20180224'
Exportar datos de tablas
En la exportación de todos los datos de una tabla particionada se realiza el mismo proceso que en la exportación de datos de una tabla no particionada. Para obtener más información, consulta Exporta datos de tablas.
Para exportar datos de una partición individual, usa el comando bq extract y agrega el decorador de partición al nombre de la tabla. Un ejemplo es my_table$20160201. También puedes exportar datos de las particiones __NULL__ y __UNPARTITIONED__ si agregas los nombres de las particiones al nombre de la tabla. Por ejemplo, my_table$__NULL__ o my_table$__UNPARTITIONED__.
Limitaciones
Las tablas particionadas tienen las siguientes limitaciones:
No puedes usar SQL heredado para consultar tablas particionadas o escribir resultados de consultas en ellas.
BigQuery no admite la partición con varias columnas. Solo se puede usar una columna para particionar una tabla.
No puedes convertir directamente una tabla existente sin particiones en una tabla particionada. La estrategia de partición se define cuando se crea la tabla. En cambio, usa la declaración
CREATE TABLEpara crear una tabla particionada nueva consultando los datos de la tabla existente.Las tablas particionadas por columnas de unidad de tiempo están sujetas a las siguientes limitaciones:
- La columna de partición debe consistir en una columna escalar de
DATE,TIMESTAMPoDATETIME. El modo de la columna puede serREQUIREDoNULLABLE, pero noREPEATED(basada en arreglo). - La columna de partición debe ser un campo de nivel superior. No puedes usar un campo de hoja de un
RECORD(STRUCT) como columna de partición.
Para obtener información sobre las tablas particionadas por columnas de unidad de tiempo, consulta Crea una tabla particionada por columnas de unidad de tiempo.
- La columna de partición debe consistir en una columna escalar de
Las tablas particionadas por rango de números enteros están sujetas a las siguientes limitaciones:
- La columna de partición debe ser una columna
INTEGER. El modo de la columna puede serREQUIREDoNULLABLE, pero no puede serREPEATED(basada en arreglo). - La columna de partición debe ser un campo de nivel superior. No puedes usar un campo de hoja de un
RECORD(STRUCT) como columna de partición.
Para obtener información sobre las tablas particionadas por rango de número entero, consulta Crea una tabla particionada por rango de número entero.
- La columna de partición debe ser una columna
Cuotas y límites
Las tablas particionadas definieron límites en BigQuery.
Las cuotas y los límites se aplican a los diferentes tipos de trabajos que puedes ejecutar en las tablas de partición, incluidos los siguientes:
- Cargar datos (cargar trabajos)
- Exportar datos (trabajos de extracción)
- Consultar datos (trabajos de consultas)
- Copiar tablas (trabajos de copia)
Para obtener más información sobre todas las cuotas y límites, consulta Cuotas y límites.
Precios de las tablas
Cuando creas y usas tablas de partición en BigQuery, el cobro se basa en la cantidad de datos almacenados en las particiones y en las consultas que ejecutas en ellos.
- Si deseas obtener información sobre precios de almacenamiento, consulta Precios de almacenamiento.
- Para obtener información sobre los precios de las consultas, visita Precios de consultas.
Muchas operaciones en tablas de partición son gratuitas, como subir datos a particiones, copiarlas y exportar datos desde ellas. A pesar de esto, estas operaciones están sujetas a las Cuotas y límites de BigQuery. Para obtener información sobre todas las operaciones gratuitas, consulta Operaciones gratuitas en la página de precios.
Si deseas conocer las prácticas recomendadas para controlar los costos en BigQuery, consulta Controla costos en BigQuery.
Seguridad de las tablas
El control de acceso para las tablas particionadas es el mismo que el de las tablas estándar. Para obtener más información, consulta Introducción a los controles de acceso a tablas.
¿Qué sigue?
- Para aprender cómo crear tablas particionadas, consulta Crea tablas particionadas.
- Para aprender a administrar y actualizar tablas particionadas, consulta Administra tablas particionadas.
- Para obtener información acerca de cómo consultar tablas particionadas, lee Consulta tablas particionadas.