Spécifier des colonnes imbriquées et répétées dans des schémas de table
Cette page explique comment définir un schéma de table avec des colonnes imbriquées et répétées dans BigQuery. Pour une présentation des schémas de table, consultez la page Spécifier un schéma.
Définir les colonnes imbriquées et répétées
Pour créer une colonne avec des données imbriquées, définissez le type de données de la colonne sur RECORD dans le schéma. Un RECORD est accessible en tant que type STRUCT en GoogleSQL. Un type STRUCT est un conteneur de champs numérotés.
Pour créer une colonne avec des données répétées, définissez le mode de la colonne sur REPEATED dans le schéma.
Un champ répété est accessible en tant que type ARRAY en GoogleSQL.
Une colonne RECORD peut avoir le mode REPEATED, représenté sous la forme d'un tableau de types STRUCT. De plus, un champ d'un enregistrement peut être répété, ce qui est représenté sous la forme d'un type STRUCT contenant un élément ARRAY. Un tableau ne peut pas contenir directement un autre tableau. Pour plus d'informations, consultez la section Déclarer un type ARRAY.
Limites
Les schémas imbriqués et répétés sont sujets aux limites suivantes :
- Un schéma ne peut pas contenir plus de 15 niveaux de types
RECORDimbriqués. - Les colonnes de type
RECORDpeuvent contenir des typesRECORDimbriqués, également appelés enregistrements enfants. La limite de profondeur des données imbriquées est de 15 niveaux. Cette limite est indépendante du fait que les valeursRECORDsoient scalaires ou basées sur des tableaux (répétitions).
Le type RECORD n'est pas compatible avec UNION, INTERSECT, EXCEPT DISTINCT et SELECT DISTINCT.
Exemple de schéma
L'exemple suivant présente un échantillon de données imbriquées et répétées. La table contient des informations sur des personnes. Elle comporte les champs suivants :
idfirst_namelast_namedob(date de naissance)addresses(champ imbriqué et répété)addresses.status(actuel ou précédent)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(années à l'adresse)
Le fichier de données JSON ressemblerait à ce qui suit. Vous remarquerez que la colonne d'adresses contient un tableau de valeurs (indiqué par [ ]). Les multiples adresses du tableau sont les données répétées. Les champs multiples contenus dans chaque adresse sont les données imbriquées.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
Le schéma de la table se présente comme suit :
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
Spécifier les colonnes imbriquées et répétées de l'exemple
Pour créer une table avec les colonnes imbriquées et répétées précédentes, sélectionnez l'une des options suivantes :
Console
Spécifiez la colonne imbriquée et répétée addresses :
Dans la console Google Cloud , ouvrez la page "BigQuery".
Dans le panneau Explorateur, développez votre projet et sélectionnez un ensemble de données.
Dans le panneau de détails, cliquez sur Créer une table.
Sur la page Créer une table, spécifiez les détails suivants :
- Pour Source, sélectionnez Table vide dans le champ Créer une table à partir de.
Dans la section Destination, spécifiez les champs suivants :
- Pour Ensemble de données, sélectionnez l'ensemble de données dans lequel vous souhaitez créer la table.
- Pour le champ Table, saisissez le nom de la table que vous souhaitez créer.
Pour le champSchéma, cliquez sur Ajouter un champ et saisissez le schéma de table suivant :
- Dans le champ Nom du champ, saisissez
addresses. - Dans le champ Type, sélectionnez RECORD.
- Dans le champ Mode, choisissez REPEATED.
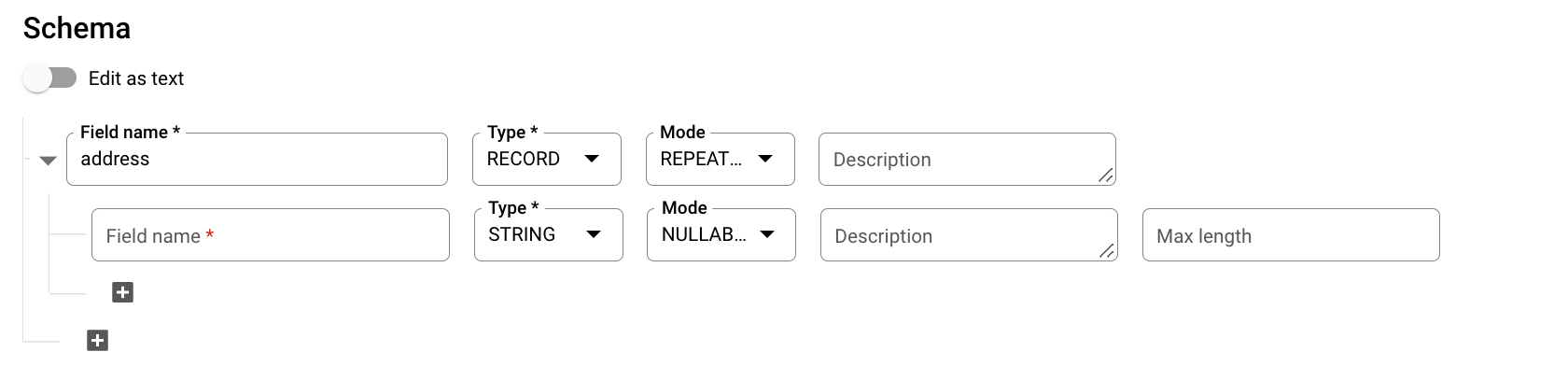
Spécifiez les champs suivants pour un champ imbriqué :
- Dans le champ Nom du champ, saisissez
status. - Dans le champ Type, choisissez STRING.
- Dans le champ Mode, conservez la valeur NULLABLE.
Cliquez sur Ajouter un champ pour ajouter les champs suivants :
Nom du champ Type Mode addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
Vous pouvez également cliquer sur Modifier sous forme de texte et spécifier le schéma dans un tableau JSON.
- Dans le champ Nom du champ, saisissez
- Dans le champ Nom du champ, saisissez
SQL
Utilisez l'instruction CREATE TABLE.
Spécifiez le schéma en utilisant l'option column :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
bq
Pour spécifier la colonne d'adresses (addresses) imbriquées et répétées dans un fichier de schéma JSON, utilisez un éditeur de texte pour créer un fichier. Collez l'exemple de définition de schéma présenté ci-dessus.
Après avoir créé votre fichier de schéma JSON, vous pouvez le fournir via l'outil de ligne de commande bq. Pour en savoir plus, consultez la section Utiliser un fichier de schéma JSON.
Go
Avant d'essayer cet exemple, suivez les instructions de configuration pour Go du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Go.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Insérer des données dans des colonnes imbriquées dans l'exemple
Utilisez les requêtes suivantes pour insérer des enregistrements de données imbriqués dans des tables contenant des colonnes de type de données RECORD.
Exemple 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
Exemple 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
Interroger des colonnes imbriquées et répétées
Pour sélectionner la valeur d'un élément ARRAY à un emplacement spécifique, utilisez un opérateur indice de tableau.
Pour accéder aux éléments d'une classe STRUCT, utilisez l'opérateur dot.
L'exemple suivant sélectionne le prénom, le nom et la première adresse répertoriés dans le champ addresses :
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
Le résultat est le suivant :
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
Pour extraire tous les éléments d'un ARRAY, utilisez l'opérateur UNNEST avec un CROSS JOIN.
L'exemple suivant sélectionne le prénom, le nom, l'adresse et l'état de toutes les adresses qui ne se trouvent pas à New York :
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
Le résultat est le suivant :
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modifier des colonnes imbriquées et répétées
Lorsque vous ajoutez une colonne imbriquée ou une colonne imbriquée et répétée à la définition de schéma d'une table, vous pouvez ensuite la modifier comme vous le feriez pour n'importe quel type de colonne. BigQuery accepte de manière native plusieurs modifications de schéma, comme l'ajout d'un nouveau champ imbriqué à un enregistrement ou l'assouplissement du mode d'un champ imbriqué. Pour en savoir plus, consultez la page Modifier des schémas de table.
Quand utiliser des colonnes imbriquées et répétées ?
BigQuery fonctionne mieux lorsque vos données sont dénormalisées. Plutôt que de conserver un schéma relationnel en étoile ou en flocon, dénormalisez vos données et utilisez des colonnes imbriquées et répétées. Les colonnes imbriquées et répétées permettent de maintenir des relations et d'éviter l'altération des performances inhérente à un schéma relationnel (normalisé).
Par exemple, une base de données relationnelle servant à gérer le fonds documentaire d'une bibliothèque conserverait probablement toutes les informations sur l'auteur dans une table distincte. Une clé de type author_id serait utilisée pour lier le livre à son ou ses auteurs.
Dans BigQuery, vous pouvez préserver la relation entre livre et auteur sans créer de table d'auteurs distincte. Vous créez plutôt une colonne auteur et y imbriquez des champs comme le prénom, le nom, la date de naissance de l'auteur, etc. Si un livre a plusieurs auteurs, vous pouvez répéter la colonne auteur imbriquée.
Supposons que vous disposiez du tableau mydataset.books :
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
Vous disposez également du tableau suivant, mydataset.authors, qui contient des informations complètes pour chaque ID d'auteur :
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
Si les tableaux sont volumineux, leur jointure régulière peut nécessiter beaucoup de ressources. Selon votre situation, il peut être utile de créer un seul tableau contenant toutes les informations :
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
La table obtenue ressemble à ceci :
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery accepte le chargement de données imbriquées et répétées à partir de formats sources compatibles avec les schémas basés sur des objets, comme les fichiers JSON, Avro et les fichiers d'exportation Firestore et Datastore.
Dédupliquer les enregistrements en double dans une table
La requête suivante utilise la fonction row_number() pour identifier les enregistrements en double ayant les mêmes valeurs pour last_name et first_name dans les exemples utilisés, et les trie en fonction de leur dob :
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
Sécurité des tables
Pour savoir comment contrôler l'accès aux tables dans BigQuery, consultez Contrôler l'accès aux ressources avec IAM.
Étapes suivantes
- Pour insérer et mettre à jour des lignes avec des colonnes imbriquées et répétées, consultez la page Syntaxe du langage de manipulation de données.