테이블 스키마에 중첩 및 반복 열 지정
이 페이지에서는 BigQuery에서 중첩 및 반복 열이 있는 테이블 스키마를 정의하는 방법을 설명합니다. 테이블 스키마 개요는 스키마 지정을 참조하세요.
중첩 및 반복 열 정의
중첩 데이터가 있는 열을 만들려면 열의 데이터 유형을 스키마에서 RECORD로 설정합니다. RECORD는 GoogleSQL에서 STRUCT 유형으로 액세스될 수 있습니다. STRUCT는 정렬된 필드의 컨테이너입니다.
반복 데이터가 있는 열을 만들려면 열의 모드를 스키마에서 REPEATED로 설정합니다.
반복 필드는 GoogleSQL에서 ARRAY 유형으로 액세스될 수 있습니다.
RECORD 열에는 STRUCT 유형의 배열로 표시되는 REPEATED 모드가 포함될 수 있습니다. 또한 ARRAY를 포함하는 STRUCT로 표현되는 레코드 내 필드가 반복될 수 있습니다. 배열은 또 다른 배열을 직접 포함할 수 없습니다. 자세한 내용은 ARRAY 유형 선언을 참조하세요.
제한사항
중첩 및 반복 스키마에는 다음과 같은 제한사항이 적용됩니다.
- 스키마는 중첩된
RECORD유형을 15개 수준 이상 포함할 수 없습니다. RECORD유형 열은 하위 레코드로 불리는 중첩된RECORD유형을 포함할 수 있습니다. 최대 중첩 깊이 제한은 15개 수준입니다. 이 제한은RECORD가 스칼라 또는 배열 기반(반복)인지와 관계가 없습니다.
RECORD 유형은 UNION, INTERSECT, EXCEPT DISTINCT, SELECT DISTINCT와 호환되지 않습니다.
스키마 예시
다음 예는 샘플 중첩 및 반복 데이터를 보여줍니다. 이 테이블에는 여러 사람에 대한 정보가 포함되어 있습니다. 이 테이블은 다음과 같은 필드로 구성됩니다.
idfirst_namelast_namedob(생년월일)addresses(중첩 및 반복 필드)addresses.status(현재 또는 이전)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(주소 연도)
JSON 데이터 파일은 다음과 같습니다. 주소 열에 값 배열([ ]로 표시)이 포함되는 것에 주의하세요. 배열의 여러 주소가 반복 데이터입니다. 각 주소 내의 여러 필드는 중첩 데이터입니다.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
이 테이블의 스키마는 다음과 같습니다.
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
예시의 중첩 및 반복 열 지정
이전 중첩 열과 반복 열을 사용하여 새 테이블을 만들려면 다음 옵션 중 하나를 선택합니다.
콘솔
중첩 및 반복 addresses 열을 지정합니다.
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 프로젝트를 펼치고 데이터 세트를 클릭한 다음 데이터 세트를 선택합니다.
세부정보 창에서 테이블 만들기를 클릭합니다.
테이블 만들기 페이지에서 다음 세부정보를 지정합니다.
- 다음 항목으로 테이블 만들기 필드에서 소스에 빈 테이블을 선택합니다.
대상 섹션에서 다음 필드를 지정합니다.
- 데이터 세트에서 테이블을 만들 데이터 세트를 선택합니다.
- 테이블에 만들 테이블의 이름을 입력합니다.
스키마에서 필드 추가를 클릭하고 다음 테이블 스키마를 입력합니다.
- 필드 이름에
addresses를 입력합니다. - 유형에 RECORD를 선택합니다.
- 모드에 REPEATED를 선택합니다.
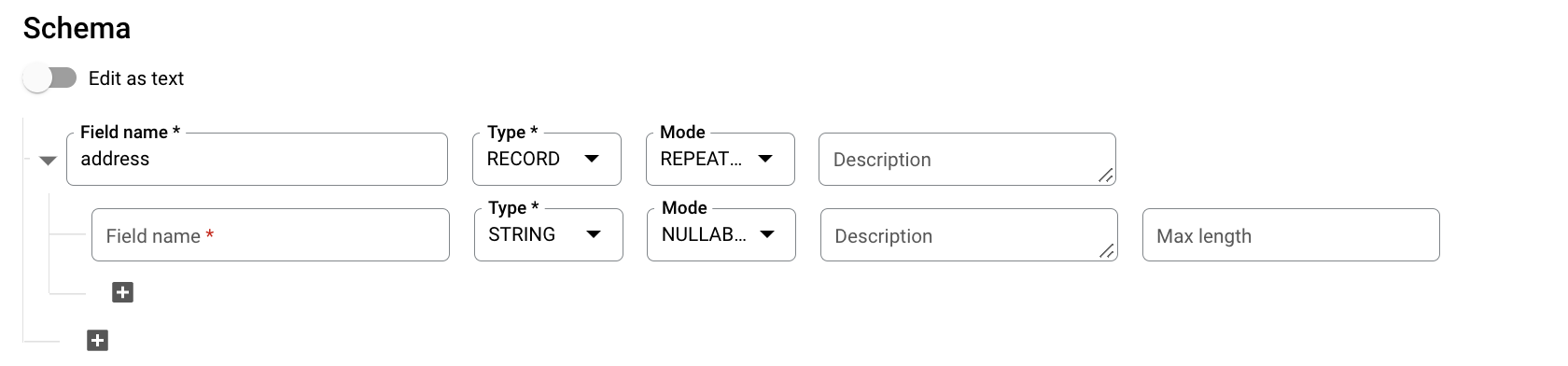
중첩 필드에 다음 필드를 지정합니다.
- 필드 이름 필드에
status를 입력합니다. - 유형에 STRING을 선택합니다.
- 모드 값은 NULLABLE로 설정된 상태로 둡니다.
필드 추가를 클릭하여 다음 필드를 추가합니다.
필드 이름 유형 모드 addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
또는 텍스트로 수정을 클릭하고 스키마를 JSON 배열로 지정합니다.
- 필드 이름 필드에
- 필드 이름에
SQL
CREATE TABLE 문을 사용합니다.
열 옵션을 사용하여 스키마를 지정합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
JSON 스키마 파일에서 중첩 및 반복된 addresses 열을 지정하려면 텍스트 편집기를 사용하여 새 파일을 만듭니다. 위에 표시된 예시 스키마 정의를 붙여넣습니다.
JSON 스키마 파일을 만든 후 bq 명령줄 도구를 통해 제공할 수 있습니다. 자세한 내용은 JSON 스키마 파일 사용을 참조하세요.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Java
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
예시의 중첩 열에 데이터 삽입
다음 쿼리를 사용하여 RECORD 데이터 유형 열이 있는 테이블에 중첩 데이터 레코드를 삽입하세요.
예시 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
예시 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
중첩 및 반복 열 쿼리
특정 위치에서 ARRAY의 값을 선택하려면 배열 아래 첨자 연산자를 사용합니다.
STRUCT의 요소에 액세스하려면 점 연산자를 사용합니다.
다음 예시에서는 addresses 필드에 나열된 이름, 성 및 첫번 째 주소를 선택합니다.
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
결과는 다음과 같습니다.
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
ARRAY의 모든 요소를 추출하려면 CROSS JOIN과 함께 UNNEST 연산자를 사용합니다.
다음 예시에서는 뉴욕에 없는 모든 주소의 이름, 성, 주소 및 주를 선택합니다.
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
결과는 다음과 같습니다.
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
중첩 및 반복 열 수정
테이블의 스키마 정의에 중첩 열이나 중첩 및 반복 열을 추가한 후에는 다른 유형의 열과 마찬가지로 열을 수정할 수 있습니다. BigQuery는 레코드에 새 중첩 필드를 추가하거나 중첩 필드의 모드를 완화하는 등의 몇 가지 스키마 변경을 기본적으로 지원합니다. 자세한 내용은 테이블 스키마 수정을 참조하세요.
중첩 및 반복 열을 사용하는 경우
BigQuery는 데이터가 비정규화되었을 때 성능이 가장 뛰어납니다. 별표 또는 눈송이 스키마와 같은 관계형 스키마를 보존하는 대신, 데이터를 비정규화하고 중첩 및 반복 열을 활용하세요. 중첩 및 반복 열은 관계형(정규화) 스키마 유지로 인한 성능 영향 없이도 관계를 유지할 수 있습니다.
예를 들어 도서관 도서를 추적하기 위해 사용되는 관계형 데이터베이스는 모든 저자 정보를 별개의 테이블로 유지할 가능성이 높습니다. 도서를 저자와 연결하는 데 author_id와 같은 키가 사용됩니다.
BigQuery에서는 별개의 저자 테이블을 만들지 않아도 도서와 저자 사이의 관계를 보존할 수 있습니다. 대신 저자 열을 만들고 여기에 저자의 이름, 성, 생일 등과 같은 필드를 중첩할 수 있습니다. 한 도서의 저자가 여러 명인 경우 중첩된 저자 열을 반복 열로 만들 수 있습니다.
mydataset.books 테이블이 있다고 가정해 보세요.
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
또한 각 작성자 ID의 전체 정보가 포함된 mydataset.authors 테이블이 있습니다.
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
테이블이 큰 경우 정기적으로 조인하는 데 리소스를 많이 사용할 수 있습니다. 상황에 따라 모든 정보가 포함된 단일 테이블을 만드는 것이 유용할 수 있습니다.
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
결과 테이블은 다음과 같습니다.
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery는 JSON 파일, Avro 파일, Firestore 내보내기 파일, Datastore 내보내기 파일과 같은 객체 기반 스키마를 지원하는 소스 형식의 중첩 및 반복 데이터를 로드하는 기능을 지원합니다.
테이블에서 중복 레코드 삭제
다음 쿼리는 row_number() 함수를 사용하여 사용된 예시에서 last_name 및 first_name의 값이 동일한 중복 레코드를 식별하고 dob를 기준으로 정렬합니다.
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
테이블 보안
BigQuery에서 테이블에 대한 액세스를 제어하려면 IAM으로 리소스에 대한 액세스 제어를 참고하세요.
다음 단계
- 중첩 및 반복 열이 있는 행을 삽입 및 업데이트하려면 DML 문법을 참조하세요.