Migrer le schéma et les données depuis Teradata
La combinaison du service de transfert de données BigQuery et d'un agent de migration spécial vous permet de copier vos données d'une instance d'entrepôt de données sur site Teradata vers BigQuery. Ce document décrit le processus détaillé de migration des données depuis Teradata à l'aide du service de transfert de données BigQuery.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Visionneuse de journaux (
roles/logging.viewer) - Administrateur BigQuery (
roles/storage.admin) ou un rôle personnalisé qui accorde les autorisations suivantes :storage.objects.createstorage.objects.getstorage.objects.list
- Administrateur BigQuery (
roles/bigquery.admin) ou rôle personnalisé qui accorde les autorisations suivantes :bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- L'agent de migration utilise une connexion JDBC avec l'instance Teradata et les API Google Cloud . Vérifiez que l'accès au réseau n'est pas bloqué par un pare-feu.
- Assurez-vous que l'environnement d'exécution Java 8 ou version ultérieure est installé.
- Assurez-vous de disposer de suffisamment d'espace de stockage pour la méthode d'extraction que vous avez choisie, comme décrit dans la section Méthode d'extraction.
- Si vous avez décidé d'utiliser l'extraction Teradata Parallel Transporter (TPT), assurez-vous que l'utilitaire
tbuildest installé. Pour en savoir plus sur le choix d'une méthode d'extraction, consultez la section Méthode d'extraction. Assurez-vous de disposer du nom d'utilisateur et du mot de passe d'un utilisateur Teradata disposant d'un accès en lecture aux tables système et aux tables en cours de migration.
Assurez-vous de disposer du nom d'hôte et du numéro de port pour vous connecter à l'instance Teradata.
client_emailprivate_key: copie tous les caractères entre-----BEGIN PRIVATE KEY-----et-----END PRIVATE KEY-----, y compris tous les caractères/net sans les guillemets doubles.ACCESS_ID: ID de clé d'accès ou valeurclient_emaildans le fichier de clé de votre compte de service.ACCESS_KEY: clé d'accès secrète ou valeurprivate_keydans le fichier de clé de votre compte de service.Dans la console Google Cloud , accédez à la page "BigQuery".
Cliquez sur Transferts de données.
Cliquez sur Créer un transfert.
Dans la section Type de source, procédez comme suit :
- Sélectionnez Migration: Teradata (Migration : Teradata).
- Pour Nom de la configuration de transfert, entrez un nom à afficher pour le transfert, tel que
My Migration. Le nom à afficher peut correspondre à n'importe quelle valeur permettant d'identifier facilement le transfert si vous devez le modifier par la suite. - Facultatif : Pour les options de programmation, vous pouvez conserver la valeur par défaut Daily (en fonction de l'heure de création) ou choisir une autre valeur si vous souhaitez un transfert incrémentiel récurrent. Sinon, choisissez À la demande pour le transfert ponctuel.
Pour Destination settings (Paramètres de destination), sélectionnez l'ensemble de données approprié.
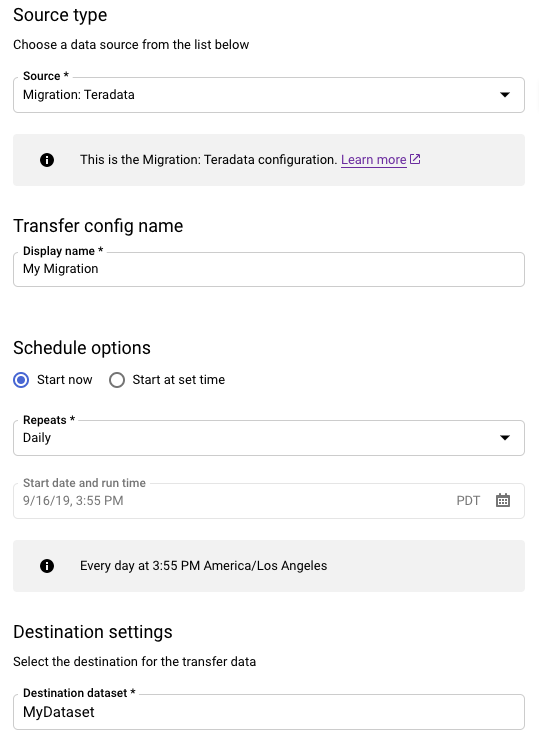
Dans la section Détails de la source de données, poursuivez avec les détails spécifiques à votre transfert Teradata.
- Dans le champ Database type (Type de base de données), sélectionnez Teradata.
- Dans le champ Cloud Storage bucket (Bucket Cloud Storage), recherchez le nom du bucket Cloud Storage pour la préproduction des données de migration. Ne saisissez pas de préfixe
gs://: saisissez uniquement le nom du bucket. - Dans le champ Database name (Nom de la base de données), saisissez le nom de la base de données source dans Teradata.
Dans le champ Table name patterns (Modèles de nom de table), saisissez un ou plusieurs modèles pour faire correspondre les noms de tables dans la base de données source. Vous pouvez utiliser des expressions régulières pour spécifier le modèle. Exemple :
sales|expensesrenvoie les tables nomméessalesetexpenses..*renvoie toutes les tables.
Dans le champ Service account email (Adresse e-mail du compte de service), saisissez l'adresse e-mail associée aux identifiants du compte de service utilisés par un agent de migration.
Facultatif : Pour Chemin d'accès au fichier du schéma, saisissez le chemin d'accès et le nom d'un fichier de schéma personnalisé. Pour en savoir plus sur la création d'un fichier de schéma personnalisé, consultez Fichier de schéma personnalisé. Vous pouvez laisser ce champ vide pour que BigQuery détecte automatiquement le schéma de votre table source.
Facultatif : Pour Répertoire racine de sortie de la traduction, saisissez le chemin d'accès et le nom du fichier de mappage de schéma fournis par le moteur de traduction BigQuery. Pour en savoir plus sur la génération d'un fichier de mappage de schéma, consultez Utiliser la sortie du moteur de traduction pour le schéma (Aperçu). Vous pouvez laisser ce champ vide pour que BigQuery détecte automatiquement le schéma de votre table source.
Facultatif : Pour Activer le déchargement direct vers GCS, cochez la case pour activer le module d'accès pour Cloud Storage.
Dans le menu Compte de service, sélectionnez un compte de service parmi ceux associés à votre projetGoogle Cloud . Vous pouvez associer un compte de service à votre transfert au lieu d'utiliser vos identifiants utilisateur. Pour en savoir plus sur l'utilisation des comptes de service pour les transferts de données, consultez Utiliser des comptes de service.
- Si vous vous êtes connecté avec une identité fédérée, vous devez disposer d'un compte de service pour créer un transfert. Si vous vous êtes connecté avec un compte Google, un compte de service pour le transfert est facultatif.
- Le compte de service doit disposer des autorisations requises.
Facultatif : dans la section Options de notification, procédez comme suit :
- Activez l'option Notifications par e-mail si vous souhaitez que l'administrateur des transferts reçoive une notification par e-mail en cas d'échec de l'exécution du transfert.
- Activez l'option Notifications Pub/Sub pour configurer les notifications d'exécution Pub/Sub pour votre transfert. Pour le champ Sélectionnez un sujet Pub/Sub, choisissez le nom de votre sujet ou cliquez sur Créer un sujet.
Cliquez sur Enregistrer.
Sur la page Détails du transfert, cliquez sur l'onglet Configuration.
Notez le nom de ressource pour ce transfert, car vous en aurez besoin pour exécuter l'agent de migration.
--data_source--display_name--target_dataset--params- project ID est l'ID de votre projet. Si vous ne fournissez pas de
--project_idafin de spécifier un projet particulier, le projet par défaut est utilisé. - dataset est le jeu de données que vous souhaitez cibler (
--target_dataset) pour la configuration de transfert. - name est le nom à afficher (
--display_name) pour la configuration de transfert. Le nom à afficher du transfert peut correspondre à n'importe quelle valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement. - service_account est le nom du compte de service utilisé pour authentifier le transfert. Le compte de service doit appartenir au même
project_idque celui utilisé pour créer le transfert et doit disposer de toutes les autorisations requises répertoriées. - parameters contient les paramètres (
--params) de la configuration de transfert créée au format JSON. Par exemple :--params='{"param":"param_value"}'.- Pour les migrations Teradata, utilisez les paramètres suivants :
bucketest le bucket Cloud Storage qui servira de zone de préproduction pendant la migration.database_typeest Teradata.agent_service_accountest l'adresse e-mail associée au compte de service que vous avez créé.database_nameest le nom de la base de données source dans Teradata.table_name_patternscorrespond à un ou plusieurs modèle(s) permettant de faire correspondre les noms de tables dans la base de données source. Vous pouvez utiliser des expressions régulières pour spécifier le modèle. Le modèle doit suivre la syntaxe d'expression régulière Java. Exemple :sales|expensesrenvoie les tables nomméessalesetexpenses..*renvoie toutes les tables.
is_direct_gcs_unload_enabledest un indicateur booléen permettant d'activer le déchargement direct vers Cloud Storage.
- Pour les migrations Teradata, utilisez les paramètres suivants :
- data_source correspond à la source de données (
--data_source) :on_premises. Ouvrez une nouvelle session. Sur la ligne de commande, exécutez la commande d'initialisation, qui adopte la syntaxe suivante :
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
L'exemple suivant illustre la commande d'initialisation lorsque les fichiers JAR du pilote JDBC et de l'agent de migration se trouvent dans un répertoire
migrationlocal :Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copiez tous les fichiers dans le dossier
C:\migration(ou ajustez les chemins d'accès dans la commande), puis exécutez la commande suivante :java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Lorsque vous y êtes invité, configurez les options suivantes :
- Choisissez d'enregistrer ou non le modèle Teradata Parallel Transporter (TPT) sur disque. Si vous prévoyez d'utiliser la méthode d'extraction TPT, vous pouvez modifier le modèle enregistré avec des paramètres adaptés à votre instance Teradata.
- Saisissez le chemin d'accès à un répertoire local que la tâche de transfert peut utiliser pour l'extraction de fichiers. Assurez-vous que vous disposez de l'espace de stockage minimal recommandé, comme décrit dans la section Méthode d'extraction.
- Saisissez le nom d'hôte de la base de données.
- Saisissez le port de la base de données.
- Définissez si Teradata Parallel Transporter (TPT) doit être utilisé comme méthode d'extraction.
- Facultatif : saisissez le chemin d'accès à un fichier d'identifiants de base de données.
Choisissez de spécifier ou non un nom de configuration pour le Service de transfert de données BigQuery.
Si vous initialisez l'agent de migration pour un transfert que vous avez déjà configuré, procédez comme suit :
- Saisissez le nom de ressource du transfert. Vous le trouverez dans l'onglet Configuration de la page Détails du transfert concernant le transfert.
- Lorsque vous y êtes invité, saisissez un chemin d'accès et un nom de fichier pour le fichier de configuration de l'agent de migration qui sera créé. Il est fait référence à ce fichier lorsque vous exécutez l'agent de migration pour démarrer le transfert.
- Vous pouvez ignorer les autres étapes.
Si vous utilisez l'agent de migration pour configurer un transfert, appuyez sur Entrée pour passer à l'invite suivante.
Saisissez l'ID du projet Google Cloud .
Saisissez le nom de la base de données source dans Teradata.
Entrez un modèle pour faire correspondre les noms des tables dans la base de données source. Vous pouvez utiliser des expressions régulières pour spécifier le modèle. Exemple :
sales|expensesrenvoie les tables nomméessalesetexpenses..*renvoie toutes les tables.
(Facultatif) Saisissez le chemin d'accès à un fichier de schéma JSON local. Cette option est fortement recommandée pour les transferts récurrents.
Si vous n'utilisez pas de fichier de schéma, ou si vous souhaitez que l'agent de migration en crée un, appuyez sur Entrée pour passer à l'invite suivante.
Définissez si un fichier de schéma doit être créé.
Si vous souhaitez créer un fichier de schéma :
- Tapez
yes. - Saisissez le nom d'utilisateur d'un utilisateur Teradata disposant d'un accès en lecture aux tables système et aux tables que vous souhaitez migrer.
Saisissez le mot de passe de cet utilisateur.
L'agent de migration crée le fichier de schéma et génère son emplacement.
Modifiez le fichier de schéma pour marquer le partitionnement, le clustering, les clés primaires et les colonnes de suivi des modifications, et vérifiez que vous souhaitez utiliser ce schéma pour la configuration de transfert. Consultez la section Fichier de schéma personnalisé pour obtenir des conseils.
Appuyez sur
Enterpour passer à l'invite suivante.
Si vous ne souhaitez pas créer de fichier de schéma, saisissez
no.- Tapez
Saisissez le nom du bucket Cloud Storage cible pour la préproduction des données de migration avant de les charger dans BigQuery. Si vous avez utilisé l'agent de migration pour créer un fichier de schéma personnalisé, il est également importé dans ce bucket.
Entrez le nom de l'ensemble de données de destination dans BigQuery.
Saisissez le nom à afficher pour la configuration de transfert.
Saisissez le chemin d'accès et le nom du fichier de configuration de l'agent de migration qui sera créé.
Après avoir entré tous les paramètres demandés, l'agent de migration crée un fichier de configuration et le génère dans le chemin local que vous avez spécifié. Reportez-vous à la section suivante pour découvrir plus en détail le contenu du fichier de configuration.
transfer-configuration: informations sur cette configuration de transfert dans BigQuery.teradata-config: informations spécifiques à cette extraction Teradata :connection: informations sur le nom d'hôte et le portlocal-processing-space: dossier d'extraction dans lequel l'agent va extraire les données de tables, avant de les importer dans Cloud Storage.database-credentials-file-path: (facultatif) chemin d'accès à un fichier qui contient les identifiants permettant de se connecter automatiquement à la base de données Teradata. Le fichier doit contenir deux lignes pour les identifiants. Vous pouvez utiliser un nom d'utilisateur/mot de passe, comme illustré dans l'exemple suivant :username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: quantité maximale d'espace de stockage local à utiliser pour l'extraction dans le répertoire de préproduction spécifié. La valeur par défaut est50GB. Le format accepté est le suivant :numberKB|MB|GB|TB.Dans tous les modes d'extraction, les fichiers sont supprimés de votre répertoire de transfert local après avoir été téléchargés sur Cloud Storage.
use-tpt: demande à l'agent de migration d'utiliser Teradata Parallel Transporter (TPT) comme méthode d'extraction.Pour chaque table, l'agent de migration génère un script TPT, démarre un processus
tbuildet attend la fin. Une fois le processustbuildterminé, l'agent répertorie et télécharge les fichiers extraits vers Cloud Storage, puis supprime le script TPT. Pour en savoir plus, consultez la section Méthode d'extraction.transfer-views: demande à l'agent de migration de transférer également des données à partir des vues. N'utilisez cela que lorsque vous avez besoin de personnaliser les données pendant la migration. Dans d'autres cas, migrez les vues vers BigQuery Views. Les conditions préalables suivantes s'appliquent à cette option :- Vous ne pouvez utiliser cette option qu'avec les versions 16.10 et ultérieures de Teradata.
- Une vue doit comporter une colonne d'entiers "partition" définie, pointant vers un ID de partition pour la ligne donnée dans la table sous-jacente.
max-sessions: spécifie le nombre maximal de sessions utilisées par la tâche d'extraction (FastExport ou TPT). S'il est défini sur 0, la base de données Teradata détermine le nombre maximal de sessions pour chaque tâche d'extraction.gcs-upload-chunk-size: un fichier volumineux est importé dans Cloud Storage par fragments. Ce paramètre ainsi quemax-parallel-uploadpermettent de contrôler la manière dont les données sont importées simultanément dans Cloud Storage. Par exemple, si la taille degcs-upload-chunk-sizeest de 64 Mo et que le paramètremax-parallel-uploadest défini sur 10 Mo, un agent de migration peut théoriquement importer 640 Mo (64 Mo x 10) de données simultanément. En cas d'échec d'importation du fragment, l'ensemble de ce fragment doit être relancé. La taille des fragments ne doit pas être trop importante.max-parallel-upload: cette valeur détermine le nombre maximal de threads utilisés par l'agent de migration pour importer des fichiers dans Cloud Storage. Si ce champ n'est pas spécifié, la valeur par défaut est définie sur le nombre de processeurs disponibles pour la machine virtuelle Java. La règle de base est de choisir la valeur en fonction du nombre de cœurs dont vous disposez dans la machine qui exécute l'agent. Ainsi, si vous disposez dencœurs, le nombre optimal de threads doit être den. Si les cœurs sont définis en hyper-threading, le nombre optimal doit être(2 * n). Vous devez également prendre en compte d'autres paramètres tels que la bande passante réseau lors de l'ajustement demax-parallel-upload. L'ajustement de ce paramètre peut améliorer les performances d'importation vers Cloud Storage.spool-mode: dans la plupart des cas, le mode NoSpool constitue la meilleure option.NoSpoolest la valeur par défaut dans la configuration de l'agent. Vous pouvez modifier ce paramètre si vous constatez dans votre situation l'un des inconvénients connus liés à NoSpool.max-unload-file-size: détermine la taille maximale du fichier extrait. Ce paramètre n'est pas appliqué pour les extractions TPT.max-parallel-extract-threads: cette configuration n'est utilisée qu'en mode FastExport. Elle détermine le nombre de threads parallèles utilisés pour extraire les données de Teradata. L'ajustement de ce paramètre peut améliorer les performances d'extraction.tpt-template-path: utilisez cette configuration pour fournir un script d'extraction TPT personnalisé en entrée. Vous pouvez utiliser ce paramètre pour appliquer des transformations à vos données de migration.schema-mapping-rule-path: (facultatif) chemin d'accès à un fichier de configuration contenant un mappage de schéma pour remplacer les règles de mappage par défaut. Certains types de mappage ne fonctionnent qu'avec le mode Teradata Parallel Transporter (TPT).Exemple : mappage du type Teradata
TIMESTAMPvers le type BigQueryDATETIME:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Attributs :
database: (facultatif)nameest une expression régulière définissant quelles bases de données doivent être incluses. Toutes les bases de données sont incluses par défaut.tables: (facultatif) contient un tableau de tables.nameest une expression régulière définissant quelles tables doivent être incluses. Toutes les tables sont incluses par défaut.match: (obligatoire)- Valeurs autorisées pour
type:COLUMN_TYPE. - Valeurs autorisées pour
value:TIMESTAMP,DATETIME.
- Valeurs autorisées pour
action: (obligatoire)- Valeurs autorisées pour
type:MAPPING. - Valeurs autorisées pour
value:TIMESTAMP,DATETIME.
- Valeurs autorisées pour
compress-output: (facultatif) détermine si les données doivent être compressées avant d'être stockées sur Cloud Storage. Ceci n'est appliqué qu'en mode tpt. La valeur par défaut estfalse.gcs-module-config-dir: (facultatif) chemin d'accès au fichier d'identifiants permettant d'accéder au bucket Cloud Storage. Le répertoire par défaut est$HOME/.gcs, mais vous pouvez utiliser ce paramètre pour le modifier.gcs-module-connection-count: (facultatif) spécifie le nombre de connexions TCP au service Cloud Storage. La valeur par défaut est 10.gcs-module-buffer-size: (facultatif) spécifie la taille des tampons à utiliser pour les connexions TCP. La valeur par défaut est de 8 Mo (8 388 608 octets). Pour faciliter l'utilisation, vous pouvez utiliser les multiplicateurs suivants :k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (facultatif) spécifie le nombre de tampons à utiliser avec les connexions TCP spécifiées pargcs-module-connection-count. Nous vous recommandons d'utiliser une valeur égale au double du nombre de connexions TCP au service Cloud Storage. La valeur par défaut est 2 *gcs-module-connection-count.gcs-module-max-object-size: (facultatif) Ce paramètre contrôle la taille des objets Cloud Storage. La valeur de ce paramètre peut être un entier ou un entier suivi, sans espace, de l'un des multiplicateurs suivants :k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (facultatif) Ce paramètre spécifie le nombre d'instances d'écriture Cloud Storage. La valeur par défaut est 1. Vous pouvez augmenter cette valeur pour accroître le débit lors de la phase d'écriture de l'exportation TPT.
Exécutez l'agent en spécifiant les chemins d'accès au pilote JDBC, à l'agent de migration et au fichier de configuration créé à l'étape précédente d'initialisation.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copiez tous les fichiers dans le dossier
C:\migration(ou ajustez les chemins d'accès dans la commande), puis exécutez la commande suivante :java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Si vous êtes prêt à poursuivre la migration, appuyez sur
Enter. L'agent procédera si le chemin d'accès aux classes fourni lors de l'initialisation est valide.Lorsque vous y êtes invité, entrez le nom d'utilisateur et le mot de passe pour la connexion à la base de données. Si le nom d'utilisateur et le mot de passe sont valides, la migration des données démarre.
Facultatif Dans la commande pour démarrer la migration, vous pouvez également utiliser un indicateur qui transmet un fichier d'informations d'identification à l'agent, au lieu d'entrer à chaque fois le nom d'utilisateur et le mot de passe. Voir le paramètre facultatif
database-credentials-file-pathdans le fichier de configuration de l'agent pour plus d'informations. Lorsque vous utilisez un fichier d'informations d'identification, prenez les mesures appropriées pour contrôler l'accès au dossier dans lequel vous le stockez sur le système de fichiers local, car il ne sera pas chiffré.Laissez cette session ouverte jusqu'à la fin de la migration. Si vous avez créé un transfert de migration récurrent, laissez cette session ouverte indéfiniment. Si cette session est interrompue, les exécutions de transfert actuelles et futures échoueront.
Vérifiez régulièrement si l'agent est en cours d'exécution. Si un transfert est en cours et qu'aucun agent ne répond dans les 24 heures, le transfert échoue.
Si l'agent de migration cesse de fonctionner pendant un transfert, ou une programmation de transfert, la console Google Cloud affiche l'état de l'erreur et vous invite à redémarrer l'agent. Pour redémarrer l'agent de migration, reprenez depuis le début de cette section, en saisissant la commande permettant d'exécuter l'agent de migration. Vous n'avez pas besoin de répéter la commande d'initialisation. Le transfert reprend au point auquel les tables n'ont pas été complétées.
- Essayez une migration de test de Teradata vers BigQuery.
- Obtenez plus d'informations sur le Service de transfert de données BigQuery.
- Migrez du code SQL avec la traduction SQL par lot.
Définir les autorisations requises
Assurez-vous que le compte principal qui crée le transfert dispose des rôles suivants dans le projet contenant la tâche de transfert :
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker vos données. Vous n'avez pas besoin de créer de tables.
Créer un bucket Cloud Storage
Créez un bucket Cloud Storage pour effectuer la préproduction des données pendant la tâche de transfert.
Préparer l'environnement local
Effectuez les tâches de cette section pour préparer votre environnement local pour le job de transfert.
Configuration requise pour la machine locale
Détails de connexion à Teradata
Télécharger le pilote JDBC
Téléchargez le fichier du pilote JDBC terajdbc4.jar depuis Teradata vers une machine pouvant se connecter à l'entrepôt de données.
Définir la variable GOOGLE_APPLICATION_CREDENTIALS
Définissez la variable d'environnement GOOGLE_APPLICATION_CREDENTIALS sur la clé de compte de service que vous avez téléchargée à la section Avant de commencer.
Mettre à jour la règle de sortie VPC Service Controls
Ajoutez un projet Google Cloud géré par le service de transfert de données BigQuery (numéro de projet : 990232121269) à la règle de sortie du périmètre VPC Service Controls.
Le canal de communication entre l'agent exécuté sur site et le service de transfert de données BigQuery consiste à publier des messages Pub/Sub dans un sujet dédié à chaque transfert. Le service de transfert de données BigQuery doit envoyer des commandes à l'agent pour extraire des données. L'agent doit publier des messages à destination du service de transfert de données BigQuery pour mettre à jour l'état et renvoyer les réponses d'extraction de données.
Créer un fichier de schéma personnalisé
Pour utiliser un fichier de schéma personnalisé au lieu de détecter automatiquement le schéma, créez-en un manuellement ou demandez à l'agent de migration d'en créer un pour vous lorsque vous initialisez l'agent.
Si vous créez un fichier de schéma manuellement et que vous souhaitez utiliser la console Google Cloud pour créer un transfert, importez le fichier de schéma dans un bucket Cloud Storage dans le projet que vous prévoyez d'utiliser pour le transfert.
Télécharger l'agent de migration
Téléchargez l'agent de migration sur une machine pouvant se connecter à l'entrepôt de données. Déplacez le fichier JAR de l'agent de migration dans le répertoire utilisé pour stocker le fichier JAR du pilote JDBC Teradata.
Configurer le fichier d'identifiants pour le module d'accès
Un fichier d'identifiants est requis si vous utilisez le module d'accès pour Cloud Storage avec l'utilitaire Teradata Parallel Transporter (TPT) pour l'extraction.
Avant de créer un fichier d'identifiants, vous devez créer une clé de compte de service. À partir du fichier de clé de compte de service que vous avez téléchargé, obtenez les informations suivantes :
Une fois que vous disposez des informations requises, créez un fichier d'identifiants. Voici un exemple de fichier d'identifiants avec un emplacement par défaut de $HOME/.gcs/credentials :
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
Remplacez les éléments suivants :
Configurer un transfert
Créez un transfert avec le service de transfert de données BigQuery.
Si vous souhaitez qu'un fichier de schéma personnalisé soit créé automatiquement, utilisez l'agent de migration pour configurer le transfert.
Vous ne pouvez pas créer un transfert à la demande à l'aide de l'outil de ligne de commande bq. Vous devez utiliser la console Google Cloud ou l'API du Service de transfert de données BigQuery.
Si vous créez un transfert récurrent, nous vous recommandons vivement de spécifier un fichier de schéma afin que les données des transferts ultérieurs puissent être correctement partitionnées lors de leur chargement dans BigQuery. Sans fichier de schéma, le Service de transfert de données BigQuery déduit le schéma de la table à partir des données sources en cours de transfert, et toutes les informations sur le partitionnement, le clustering, les clés primaires et le suivi des modifications sont perdues. En outre, les transferts ultérieurs vont ignorer les tables précédemment migrées après le transfert initial. Pour en savoir plus sur la création d'un fichier de schéma, consultez la page Fichier de schéma personnalisé.
Console
bq
Lorsque vous créez un transfert Cloud Storage à l'aide de l'outil bq, la configuration de transfert est définie pour se répéter toutes les 24 heures. Pour les transferts à la demande, utilisez la console Google Cloud ou l'API du service de transfert de données BigQuery.
Vous ne pouvez pas configurer de notifications à l'aide de l'outil bq.
Saisissez la commande
bq mk
puis spécifiez l'option de création de transfert
--transfer_config. Les paramètres suivants sont également requis :
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Où :
Par exemple, la commande suivante crée un transfert Teradata nommé My Transfer à l'aide du bucket Cloud Storage mybucket et de l'ensemble de données cible mydataset. Le transfert fera migrer toutes les tables de l'entrepôt de données Teradata mydatabase et le fichier de schéma facultatif est myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
Après avoir exécuté la commande, vous recevez un message de ce type :
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Suivez les instructions et collez le code d'authentification sur la ligne de commande.
API
Utilisez la méthode projects.locations.transferConfigs.create et fournissez une instance de la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Agent de migration
Vous pouvez éventuellement configurer le transfert directement à partir de l'agent de migration. Pour en savoir plus, consultez la section Initialiser l'agent de migration.
Initialiser l'agent de migration
Vous devez initialiser l'agent de migration pour un nouveau transfert. L'initialisation n'est requise qu'une seule fois pour un transfert, que celui-ci soit récurrent ou non. L'initialisation ne configure que l'agent de migration, elle ne procède pas au démarrage du transfert.
Si vous souhaitez utiliser l'agent de migration pour créer un fichier de schéma personnalisé, assurez-vous de disposer d'un répertoire avec accès en écriture dans votre répertoire de travail, portant le même nom que le projet que vous souhaitez utiliser pour le transfert. C'est là que l'agent de migration crée le fichier de schéma.
Par exemple, si vous travaillez dans /home et que vous configurez le transfert dans le projet myProject, créez le répertoire /home/myProject et assurez-vous qu'il est accessible en écriture aux utilisateurs.
Fichier de configuration pour l'agent de migration
Le fichier de configuration créé à l'étape d'initialisation ressemble à l'exemple suivant :
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Options des tâches de transfert dans le fichier de configuration de l'agent de migration
Exécuter l'agent de migration
Après avoir initialisé l'agent de migration et créé le fichier de configuration, procédez comme suit pour exécuter l'agent et démarrer la migration :
Suivre la progression de la migration
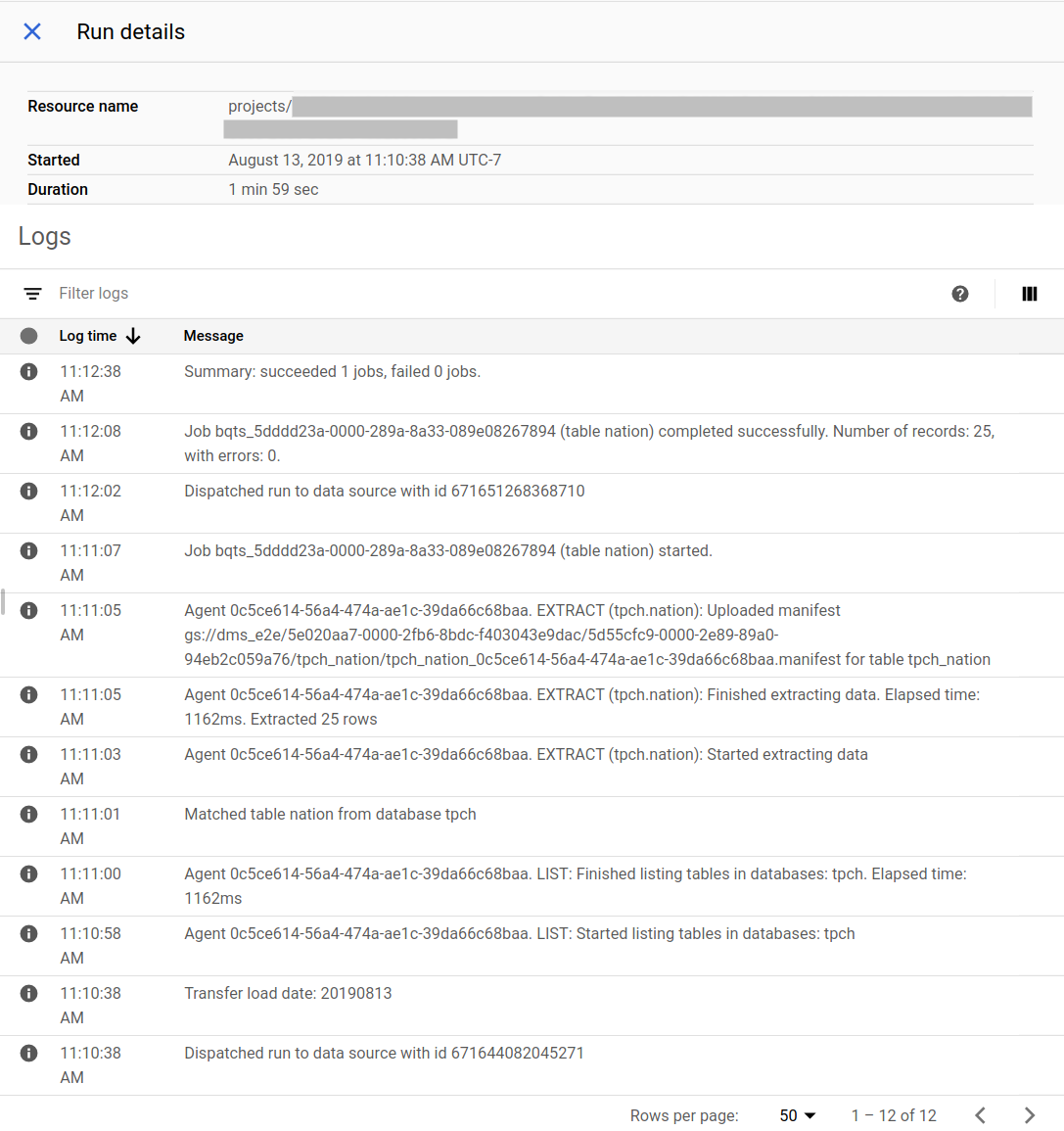
Vous pouvez afficher l'état de la migration dans la console Google Cloud . Vous pouvez également configurer des notifications Pub/Sub ou par e-mail. Consultez Notifications du service de transfert de données BigQuery.
Le service de transfert de données BigQuery planifie et lance une exécution de transfert selon un calendrier spécifié lors de la création de la configuration de transfert. Il est important que l'agent de migration s'exécute lorsqu'une exécution de transfert est active. S'il n'y a aucune mise à jour du côté de l'agent dans les 24 heures, une exécution de transfert échoue.
Exemple d'état de la migration dans la console Google Cloud :
Mettre à jour l'agent de migration
En cas de publication d'une nouvelle version de l'agent de migration, vous devez mettre à jour celui-ci manuellement. Pour recevoir des notifications sur le service de transfert de données BigQuery, abonnez-vous aux notes de version.