Teradata에서 스키마 및 데이터 마이그레이션
BigQuery Data Transfer Service와 특수 마이그레이션 에이전트를 함께 사용하면 Teradata 온프레미스 데이터웨어 하우스 인스턴스에서 BigQuery로 데이터를 복사할 수 있습니다. 이 문서에서는 BigQuery Data Transfer Service를 사용하여 Teradata에서 데이터를 마이그레이션하는 단계별 절차에 대해 설명합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- 로그 뷰어(
roles/logging.viewer) - 스토리지 관리자(
roles/storage.admin) 또는 다음 권한을 부여하는 커스텀 역할:storage.objects.createstorage.objects.getstorage.objects.list
- BigQuery 관리자(
roles/bigquery.admin) 또는 다음 권한을 부여하는 커스텀 역할:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- 마이그레이션 에이전트는 Teradata 인스턴스 및 Google Cloud API에 JDBC 연결을 사용합니다. 네트워크 액세스가 방화벽으로 차단되지 않았는지 확인하세요.
- Java 런타임 환경 8 이상이 설치되어 있는지 확인하세요.
- 추출 방법에 설명된 대로 선택한 추출 방법을 위한 저장공간이 충분한지 확인합니다.
- Teradata Parallel Transporter(TPT) 추출을 사용하기로 한 경우
tbuild유틸리티가 설치되어 있는지 확인하세요. 추출 방법 선택에 대한 상세 설명은 추출 방법을 참조하세요. 마이그레이션 중인 시스템 테이블 및 테이블에 대한 읽기 액세스 권한이 있는 Teradata 사용자의 사용자 이름과 비밀번호가 있어야 합니다.
Teradata 인스턴스에 연결할 호스트 이름과 포트 번호를 알고 있어야 합니다.
client_emailprivate_key:-----BEGIN PRIVATE KEY-----및-----END PRIVATE KEY-----내의 모든 문자를 복사합니다. 모든/n문자를 포함하며 묶는 큰따옴표는 제외됩니다.ACCESS_ID: 액세스 키 ID 또는 서비스 계정 키 파일의client_email값입니다.ACCESS_KEY: 보안 비밀 액세스 키 또는 서비스 계정 키 파일의private_key값입니다.Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
데이터 전송을 클릭합니다.
전송 만들기를 클릭합니다.
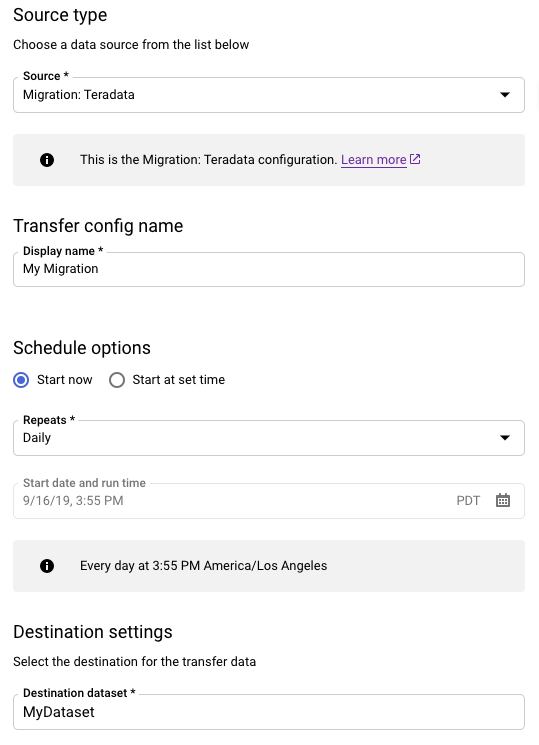
소스 유형 섹션에서 다음을 수행합니다.
- 마이그레션: Teradata를 선택합니다.
- 전송 구성 이름에 전송의 표시 이름을 입력하세요(예:
My Migration). 표시 이름은 나중에 수정해야 할 경우를 대비해 전송을 간편하게 식별할 수 있는 값이면 됩니다. - 선택사항: 일정 옵션에서 기본값인 매일(만든 시간 기준)을 그대로 두거나 반복 증분 전송을 원하는 경우 다른 시간을 선택합니다. 그 밖의 경우에는 일회성 전송에 주문형을 선택합니다.
목적지 설정에 적절한 데이터 세트를 선택하세요.
데이터 소스 세부정보 섹션에서 Teradata 전송에 대한 구체적인 세부정보를 계속 작성합니다.
- 데이터베이스 유형에 대해 Teradata를 선택하세요.
- Cloud Storage 버킷에서는 마이그레이션 데이터 준비를 위한 Cloud Storage 버킷 이름을 찾습니다. 접두사
gs://을 입력하지 말고 버킷 이름만 입력하세요. - 데이터베이스 이름의 경우, Teradata에 소스 데이터베이스의 이름을 입력하세요.
테이블 이름 패턴에는 소스 데이터베이스의 테이블 이름과 일치하는 패턴을 입력하세요. 정규 표현식을 사용하여 패턴을 지정할 수 있습니다. 예를 들면 다음과 같습니다.
sales|expenses는sales및expenses라는 테이블과 일치합니다..*은 모든 테이블을 찾습니다.
서비스 계정 이메일에 이전 에이전트가 사용하는 서비스 계정 사용자 인증 정보와 연결된 이메일 주소를 입력합니다.
선택사항: 스키마 파일 경로에 맞춤 스키마 파일의 경로와 파일 이름을 입력합니다. 커스텀 스키마 파일 만들기에 대한 자세한 내용은 커스텀 스키마 파일을 참고하세요. 이 필드를 비워 두면 BigQuery에서 소스 테이블 스키마를 자동으로 감지합니다.
(선택사항) 변환 출력 루트 디렉터리에 BigQuery 변환 엔진에서 제공하는 스키마 매핑 파일의 경로와 파일 이름을 입력합니다. 스키마 매핑 파일 생성에 대한 자세한 내용은 스키마에 번역 엔진 출력 사용(미리보기)을 참고하세요. 이 필드를 비워 두면 BigQuery가 소스 테이블 스키마를 자동으로 감지합니다.
선택사항: TPT로 Cloud Storage 액세스 모듈을 사용 설정하려면 체크박스를 선택합니다.
서비스 계정 메뉴에서Google Cloud 프로젝트와 연결된 서비스 계정에서 서비스 계정을 선택합니다. 사용자 인증 정보를 사용하는 대신 서비스 계정을 전송에 연결할 수 있습니다. 데이터 전송에서 서비스 계정을 사용하는 방법에 관한 자세한 내용은 서비스 계정 사용을 참조하세요.
(선택사항) 알림 옵션 섹션에서 다음을 수행합니다.
저장을 클릭합니다.
전송 세부정보 페이지에서 구성 탭을 클릭합니다.
마이그레이션 에이전트를 실행하는 데 필요하므로 이 전송의 리소스 이름을 기록해 둡니다.
--data_source--display_name--target_dataset--params- project ID는 프로젝트 ID입니다. 특정 프로젝트를 지정하는
--project_id가 입력되지 않으면 기본 프로젝트가 사용됩니다. - dataset는 전송 구성의 대상으로 하려는 데이터 세트(
--target_dataset)입니다. - name은 전송 구성의 표시 이름(
--display_name)입니다. 전송 표시 이름은 나중에 수정해야 할 경우를 대비해 간편하게 전송을 식별할 수 있는 값이면 됩니다. - service_account은 전송을 인증하는 데 사용되는 서비스 계정 이름입니다. 서비스 계정은 전송을 만드는 데 사용한 것과 동일한
project_id가 소유해야 하며 나열된 모든 필수 권한이 있어야 합니다. - parameters에는 JSON 형식으로 생성된 전송 구성의 매개변수(
--params)가 있습니다. 예를 들면--params='{"param":"param_value"}'입니다.- Teradata 마이그레이션의 경우 다음 매개변수를 사용하세요.
bucket은 마이그레이션 중에 스테이징 영역으로 작동하는 Cloud Storage 버킷입니다.database_type은 Teradata입니다.agent_service_account은 생성한 서비스 계정과 연결된 이메일 주소입니다.database_name은 Teradata의 소스 데이터베이스 이름입니다.table_name_patterns은 소스 데이터베이스에서 테이블 이름을 일치시키기 위한 패턴입니다. 정규 표현식을 사용하여 패턴을 지정할 수 있습니다. 이 패턴은 자바 정규 표현식 문법을 따라야 합니다. 예를 들면 다음과 같습니다.sales|expenses는sales및expenses라는 테이블과 일치합니다..*은 모든 테이블을 찾습니다.
- Teradata 마이그레이션의 경우 다음 매개변수를 사용하세요.
- data_source는 데이터 소스(
--data_source)입니다.on_premises 새 세션을 엽니다. 명령줄에서 다음 형식의 초기화 명령어를 실행합니다.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
다음 예시는 JDBC 드라이버 및 마이그레이션 에이전트 JAR 파일이 로컬
migration디렉터리에 있는 경우의 초기화 명령어를 보여줍니다.유닉스, 리눅스, 맥 OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
모든 파일을
C:\migration폴더에 복사하거나 명령에서 경로를 조정한 후 다음을 실행하세요.java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
메시지가 표시되면 다음 옵션을 구성합니다.
- Teradata Parallel Transporter(TPT) 템플릿을 디스크에 저장할지 여부를 선택합니다. TPT 추출 방법을 사용하려는 경우 Teradata 인스턴스에 적합한 매개변수로 저장된 템플릿을 수정할 수 있습니다.
- 전송 작업에서 파일 추출에 사용할 수 있는 로컬 디렉터리의 경로를 입력합니다. 추출 방법에 설명된 최소 권장 저장공간이 있는지 확인합니다.
- 데이터베이스 호스트 이름을 입력합니다.
- 데이터베이스 포트를 입력합니다.
- Teradata Parallel Transporter(TPT)를 추출 방법으로 사용할지 선택합니다.
- (선택사항) 데이터베이스 사용자 인증 정보 파일의 경로를 입력합니다.
BigQuery Data Transfer Service 구성 이름을 지정할지 선택합니다.
이미 설정한 전송의 마이그레이션 에이전트를 초기화하는 경우 다음을 수행합니다.
- 전송의 리소스 이름을 입력합니다. 전송의 전송 세부정보 페이지의 구성 탭에서 확인할 수 있습니다.
- 메시지가 표시되면 생성할 마이그레이션 에이전트 구성 파일의 경로와 파일 이름을 입력합니다. 전송을 시작하기 위해 마이그레이션 에이전트를 실행할 때 이 파일을 참조합니다.
- 나머지 단계는 건너뛰세요.
마이그레이션 에이전트를 사용하여 전송을 설정하는 경우 Enter 키를 눌러 다음 프롬프트로 건너뜁니다.
Google Cloud 프로젝트 ID를 입력합니다.
Teradata에 소스 데이터베이스의 이름을 입력하세요.
소스 데이터베이스에서 테이블 이름과 일치하는 패턴을 입력하세요. 정규 표현식을 사용하여 패턴을 지정할 수 있습니다. 예를 들면 다음과 같습니다.
sales|expenses는sales및expenses라는 테이블과 일치합니다..*은 모든 테이블을 찾습니다.
선택사항: 로컬 JSON 스키마 파일의 경로를 입력합니다. 반복되는 전송에는 이 방법을 사용하는 것이 좋습니다.
스키마 파일을 사용하지 않거나 마이그레이션 에이전트가 스키마 파일을 만들도록 하려면 Enter 키를 눌러 다음 프롬프트로 건너뜁니다.
새 스키마 파일을 만들지 선택합니다.
스키마 파일을 만들려면 다음 단계를 따르세요.
yes를 입력합니다.- 시스템 테이블 및 마이그레이션할 테이블에 대한 읽기 액세스 권한이 있는 Teradata 사용자의 사용자 이름을 입력합니다.
이 사용자의 비밀번호를 입력합니다.
마이그레이션 에이전트가 스키마 파일을 만들고 해당 위치를 출력합니다.
파티션 나누기, 클러스터링, 기본 키, 변경 내용 추적 열을 표시하도록 스키마 파일을 수정하고 전송 구성에 이 스키마를 사용하려는지 확인하세요. 도움말은 커스텀 스키마 파일을 참조하세요.
다음 프롬프트로 건너뛰려면
Enter키를 누릅니다.
스키마 파일을 만들지 않으려면
no를 입력합니다.BigQuery에 로드하기 전에 마이그레이션 데이터를 스테이징할 대상 Cloud Storage 버킷의 이름을 입력합니다. 마이그레이션 에이전트가 커스텀 스키마 파일을 만들도록 했으면 해당 파일도 이 버킷에 업로드됩니다.
BigQuery에 대상 데이터 세트의 이름을 입력하세요.
전송 구성의 표시 이름을 입력합니다.
생성할 마이그레이션 에이전트 구성 파일의 경로와 파일 이름을 입력합니다.
요청된 모든 매개변수를 입력하면 마이그레이션 에이전트가 구성 파일을 만들어 사용자가 지정한 로컬 경로로 출력합니다. 구성 파일에 대한 자세한 내용은 다음 섹션을 참조하세요.
transfer-configuration: BigQuery에서 이 전송 구성에 대한 정보teradata-config: 이 Teradata 추출과 관련된 정보connection: 호스트 이름 및 포트 관련 정보local-processing-space: 에이전트가 Cloud Storage에 테이블 데이터를 업로드하기 전에 테이블 데이터를 추출할 추출 폴더.database-credentials-file-path: (선택 사항) Teradata 데이터베이스에 자동으로 연결하기 위한 자격 증명가 포함된 파일 경로. 파일에는 사용자 인증 정보를 위한 두 줄이 포함되어야 합니다. 다음 예시에 표시된 것처럼 사용자 이름/비밀번호를 사용할 수 있습니다.username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: 지정된 스테이징 디렉터리에서 추출에 사용할 로컬 스토리지의 최대 용량입니다. 기본값은50GB입니다. 지원되는 형식은numberKB|MB|GB|TB입니다.모든 추출 모드에서 파일은 Cloud Storage에 업로드된 후 로컬 스테이징 디렉터리에서 삭제됩니다.
use-tpt: 마이그레이션 에이전트가 Teradata Parallel Transporter(TPT)를 추출 방법으로 사용하도록 지시합니다.각 테이블에 대해 마이그레이션 에이전트는 TPT 스크립트를 생성하고
tbuild프로세스를 시작한 후 완료를 기다립니다.tbuild프로세스가 완료되면 에이전트는 추출된 파일을 나열하고 Cloud Storage에 업로드한 다음 TPT 스크립트를 삭제합니다. 자세한 내용은 추출 방법을 참고하세요.transfer-views: 또한 마이그레이션 에이전트가 뷰에서 데이터를 전송하도록 지시합니다. 마이그레이션 중에 데이터 맞춤설정이 필요한 경우에만 사용하세요. 다른 경우에는 뷰를 BigQuery 뷰로 이전하세요. 이 옵션에는 다음과 같은 기본 요건이 있습니다.- 이 옵션은 Teradata 버전 16.10 이상에서만 사용할 수 있습니다.
- 뷰에는 기본 테이블의 지정된 행에 대한 파티션 ID를 가리키는 정수 열 'partition'이 정의되어 있어야 합니다.
max-sessions: 내보내기 작업에서 사용하는 최대 세션 수(FastExport 또는 TPT)를 지정합니다. 0으로 설정하면 Teradata 데이터베이스는 각 내보내기 작업에 대한 최대 세션 수를 결정합니다.gcs-upload-chunk-size: 큰 파일이 청크로 Cloud Storage에 업로드됩니다. 이 매개변수와max-parallel-upload는 Cloud Storage에 동시에 업로드되는 데이터의 양을 제어하는 데 사용됩니다. 예를 들어gcs-upload-chunk-size가 64MB이고max-parallel-upload가 10MB라면 이론적으로 마이그레이션 에이전트는 640MB(64MB * 10)의 데이터를 동시에 업로드할 수 있습니다. 청크 업로드가 실패하면 전체 청크에 대해 업로드를 다시 시도해야 합니다. 청크 크기는 작아야 합니다.max-parallel-upload: 이 값은 마이그레이션 에이전트가 Cloud Storage에 파일을 업로드하는 데 사용하는 최대 스레드 수를 결정합니다. 지정되지 않은 경우 기본값은 자바 가상 머신에 사용할 수 있는 프로세서의 수입니다. 일반적으로 에이전트를 실행하는 머신에 있는 코어 수에 따라 값을 선택합니다. 따라서 코어가n개인 경우 최적의 스레드 수는n이어야 합니다. 코어가 하이퍼 스레딩된 경우 최적 숫자는(2 * n)여야 합니다.max-parallel-upload를 조정하는 동안 고려해야 하는 네트워크 대역폭과 같은 다른 설정도 있습니다. 이 매개변수를 조정하면 Cloud Storage에 업로드하는 성능을 개선할 수 있습니다.spool-mode: 대부분의 경우 NoSpool 모드가 이 가장 적합한 옵션입니다.NoSpool은 에이전트 구성의 기본값입니다. 사용 사례에 NoSpool의 단점이 해당되는 경우 이 매개변수를 변경할 수 있습니다.max-unload-file-size: 추출되는 파일의 최대 크기를 결정합니다. TPT 추출에는 이 매개변수가 적용되지 않습니다.max-parallel-extract-threads: 이 구성은 FastExport 모드에서만 사용됩니다. Teradata에서 데이터를 추출하는 데 사용되는 동시 스레드 수를 결정합니다. 이 매개변수를 조정하면 추출 성능이 향상될 수 있습니다.tpt-template-path: 이 구성을 사용하여 커스텀 TPT 추출 스크립트를 입력으로 제공합니다. 이 매개변수를 사용하여 마이그레이션 데이터에 변환을 적용할 수 있습니다.schema-mapping-rule-path: (선택 사항) 기본 매핑 규칙을 재정의하는 스키마 매핑이 포함된 구성 파일의 경로입니다. 일부 매핑 유형은 Teradata Parallel Transporter(TPT) 모드에서만 작동합니다.예시: Teradata 형식
TIMESTAMP에서 BigQuery 형식DATETIME으로 매핑{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
속성:
database: (선택사항)name은 데이터베이스에 포함할 정규 표현식입니다. 기본적으로 모든 데이터베이스가 포함됩니다.tables: (선택사항) 테이블 배열이 포함됩니다.name은 포함할 테이블의 정규 표현식입니다. 기본적으로 모든 테이블이 포함됩니다.match: (필수)type지원 값:COLUMN_TYPE.value지원 값:TIMESTAMP,DATETIME.
action: (필수)type지원 값:MAPPING.value지원 값:TIMESTAMP,DATETIME.
compress-output: (선택사항) Cloud Storage에 저장하기 전에 데이터를 압축해야 하는지 여부를 나타냅니다. 이는 tpt-mode에서만 적용됩니다. 기본적으로 이 값은false입니다.gcs-module-config-dir: (선택사항) Cloud Storage 버킷에 액세스하기 위한 인증 파일의 경로입니다. 기본 디렉터리는$HOME/.gcs이지만 이 매개변수를 사용하여 디렉터리를 변경할 수 있습니다.gcs-module-connection-count: (선택사항) Cloud Storage 서비스에 대한 TCP 연결 수를 지정합니다. 기본값은 10입니다.gcs-module-buffer-size: (선택사항) TCP 연결에 사용할 버퍼의 크기를 지정합니다. 기본값은 8MB (8388608바이트)입니다. 사용 편의성을 위해 다음 승수를 사용할 수 있습니다.k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (선택사항)gcs-module-connection-count로 지정된 TCP 연결에 사용할 버퍼 수를 지정합니다. Cloud Storage 서비스에 대한 TCP 연결 수의 두 배와 같은 값을 사용하는 것이 좋습니다. 기본값은 2 *gcs-module-connection-count입니다.gcs-module-max-object-size: (선택사항) 이 매개변수는 Cloud Storage 객체의 크기를 제어합니다. 이 매개변수의 값은 정수 또는 정수 뒤에 공백 없이 다음 승수 중 하나가 올 수 있습니다.k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (선택사항) 이 매개변수는 Cloud Storage writer 인스턴스 수를 지정합니다. 기본값은 1입니다. 이 값을 늘려 TPT 내보내기의 쓰기 단계에서 처리량을 늘릴 수 있습니다.
JDBC 드라이버, 마이그레이션 에이전트, 이전 초기화 단계에서 생성된 구성 파일의 경로를 지정하여 에이전트를 실행합니다.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
유닉스, 리눅스, 맥 OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
모든 파일을
C:\migration폴더에 복사하거나 명령에서 경로를 조정한 후 다음을 실행하세요.java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
마이그레이션을 진행할 준비가 완료되면
Enter를 누릅니다. 그러면 초기화 중에 제공된 클래스 경로가 유효한 경우 에이전트가 진행됩니다.메시지가 표시되면 데이터베이스 연결을 위한 사용자 이름과 비밀번호를 입력합니다. 사용자 이름과 비밀번호가 유효하면 데이터 마이그레이션이 시작됩니다.
선택 사항 마이그레이션을 시작하는 명령에서 매번 사용자 이름과 비밀번호를 입력하는 대신 자격 증명 파일을 에이전트에 전달하는 플래그를 사용할 수도 있습니다. 자세한 정보는 에이전트 구성 파일에서 선택적 매개변수
database-credentials-file-path를 참조하세요. 자격 증명 파일을 사용하는 경우 암호화되지 않으므로 로컬 파일 시스템에 파일을 저장하는 폴더에 대한 액세스를 제어하는 적절한 단계를 수행하세요.마이그레이션이 완료될 때까지 이 세션을 열어두세요. 반복되는 마이그레이션 전송을 만든 경우, 이 세션을 무기한 열어둡니다. 이 세션이 중단되면 현재 및 이후 전송 실행이 실패합니다.
에이전트가 실행 중인지 정기적으로 모니터링하세요. 전송 실행이 진행 중이고 24시간 내에 에이전트가 응답하지 않으면 전송 실행이 실패합니다.
전송이 진행 중이거나 예약된 상태에서 마이그레이션 에이전트가 작동을 중지하면 Google Cloud 콘솔에 오류 상태가 표시되고 에이전트를 다시 시작하라는 메시지가 표시됩니다. 마이그레이션 에이전트를 시작하려면 이 섹션의 시작 부분에서 재개하고 마이그레이션 에이전트 실행을 위한 명령어로 마이그레이션 에이전트를 실행합니다. 초기화 명령어는 반복할 필요가 없습니다. 테이블이 완료되지 않은 지점에서부터 전송이 재개됩니다.
- Teradata에서 BigQuery로 테스트 마이그레이션해보기
- BigQuery Data Transfer Service 자세히 알아보기
- SQL 일괄 변환으로 SQL 코드 마이그레이션
필수 권한 설정
전송을 만드는 주 구성원에게 전송 작업이 포함된 다음 역할이 있는지 확인하세요.
데이터 세트 만들기
데이터를 저장할 BigQuery 데이터 세트를 만듭니다. 테이블을 만들 필요는 없습니다.
Cloud Storage 버킷 만들기
전송 작업 중에 데이터를 스테이징하기 위한 Cloud Storage 버킷을 만듭니다.
로컬 환경 준비
이 섹션의 태스크를 완료하여 전송 작업을 위한 로컬 환경을 준비하세요.
로컬 머신 요구 사항
Teradata 연결 세부정보
JDBC 드라이버 다운로드
Teradata에서 데이터 웨어하우스에 연결할 수 있는 머신으로 terajdbc4.jar JDBC 드라이버 파일을 다운로드합니다.
GOOGLE_APPLICATION_CREDENTIALS 변수 설정
시작하기 전에 섹션에서 다운로드한 서비스 계정 키로 환경 변수 GOOGLE_APPLICATION_CREDENTIALS를 설정합니다.
VPC 서비스 제어 이그레스 규칙 업데이트
BigQuery Data Transfer Service 관리형 Google Cloud 프로젝트 (프로젝트 번호: 990232121269)를 VPC 서비스 제어 경계의 이그레스 규칙에 추가합니다.
온프레미스에서 실행되는 에이전트와 BigQuery Data Transfer Service 간의 통신 채널은 Pub/Sub 메시지를 전송별 주제에 게시하는 것입니다. BigQuery Data Transfer Service는 데이터를 추출하기 위해 에이전트에 명령을 보내야 하고, 에이전트는 다시 BigQuery Data Transfer Service에 메시지를 게시하여 상태를 업데이트하고 데이터 추출 응답을 반환해야 합니다.
맞춤 스키마 파일 만들기
자동 스키마 감지 대신 커스텀 스키마 파일을 사용하려면 수동으로 커스텀 스키마 파일을 만들거나, 에이전트를 초기화할 때 마이그레이션 에이전트가 자동으로 만들게 하세요.
스키마 파일을 수동으로 만들고 Google Cloud 콘솔을 사용하여 전송을 생성할 의향이라면 전송에 사용할 동일한 프로젝트의 Cloud Storage 버킷에 스키마 파일을 업로드하세요.
마이그레이션 에이전트 다운로드
데이터 웨어하우스에 연결할 수 있는 머신에 마이그레이션 에이전트를 다운로드합니다. 마이그레이션 에이전트 JAR 파일을 Teradata JDBC 드라이버 JAR 파일과 동일한 디렉터리로 이동합니다.
액세스 모듈의 사용자 인증 정보 파일 설정
추출에 Teradata Parallel Transporter (TPT) 유틸리티와 함께 Cloud Storage 액세스 모듈을 사용하는 경우 사용자 인증 정보 파일이 필요합니다.
사용자 인증 정보 파일을 만들기 전에 서비스 계정 키를 만들어야 합니다. 다운로드한 서비스 계정 키 파일에서 다음 정보를 가져옵니다.
필요한 정보가 있으면 사용자 인증 정보 파일을 만듭니다. 다음은 기본 위치가 $HOME/.gcs/credentials인 사용자 인증 정보 파일의 예시입니다.
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
다음을 바꿉니다.
전송 설정
BigQuery Data Transfer Service로 전송을 만드세요.
커스텀 스키마 파일을 자동으로 만들려면 마이그레이션 에이전트를 사용하여 전송을 설정합니다.
bq 명령줄 도구를 사용하여 주문형 전송을 만들 수 없습니다. 대신 Google Cloud 콘솔 또는 BigQuery Data Transfer Service API를 사용해야 합니다.
반복 전송을 만들 경우 BigQuery에 로드할 때 후속 전송의 데이터에 대한 파티션을 올바르게 나눌 수 있도록 스키마 파일을 지정하는 것이 좋습니다. 스키마 파일이 없으면 BigQuery Data Transfer Service는 전송 중인 소스 데이터에서 테이블 스키마를 추론하며 파티셔닝, 클러스터링, 기본 키, 변경 추적에 대한 모든 정보가 손실됩니다. 또한 후속 전송에서는 초기 전송 후 이전에 마이그레이션된 테이블을 건너뜁니다. 스키마 파일을 만드는 방법에 대한 자세한 내용은 커스텀 스키마 파일을 참고하세요.
콘솔
bq
bq 도구를 사용하여 Cloud Storage 전송을 만들면 전송 구성이 24시간마다 반복되도록 설정됩니다. 주문형 전송의 경우 Google Cloud 콘솔 또는 BigQuery Data Transfer Service API를 사용합니다.
bq 도구를 사용하여 알림을 구성할 수 없습니다.
bq mk 명령어를 입력하고 전송 생성 플래그 --transfer_config를 지정합니다. 다음 플래그도 필요합니다.
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
각 항목의 의미는 다음과 같습니다.
예를 들어 다음 명령은 Cloud Storage 버킷 mybucket 및 대상 데이터 세트 mydataset를 사용하는, 이름이 My Transfer인 Teradata 전송을 생성합니다. 전송은 Teradata 데이터 웨어하우스 mydatabase에서 모든 테이블을 마이그레이션하며 선택적 스키마 파일은 myschemafile.json입니다.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json"}' \ --data_source=on_premises
명령어를 실행한 후 다음과 같은 메시지가 수신됩니다.
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
안내에 따라 인증 코드를 명령줄에 붙여넣습니다.
API
projects.locations.transferConfigs.create 메서드를 사용하고 TransferConfig 리소스의 인스턴스를 지정합니다.
자바
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
마이그레이션 에이전트
원하는 경우 마이그레이션 에이전트에서 직접 전송을 설정할 수 있습니다. 자세한 내용은 이전 에이전트 초기화를 참고하세요.
마이그레이션 에이전트 초기화
새 전송의 마이그레이션 에이전트를 초기화해야 합니다. 반복 여부에 관계없이 전송마다 초기화가 한 번씩 필요합니다. 초기화는 마이그레이션 에이전트만 구성하며 전송을 시작하지는 않습니다.
마이그레이션 에이전트를 사용하여 커스텀 스키마 파일을 만들려면 전송에 사용할 프로젝트와 동일한 이름의 작업 디렉터리 아래에 쓰기 가능한 디렉터리가 있어야 합니다. 여기에서 마이그레이션 에이전트가 스키마 파일을 만듭니다.
예를 들어 /home에서 작업 중이며 myProject 프로젝트에서 전송을 설정하는 경우 /home/myProject 디렉터리를 만들고 사용자가 쓸 수 있는지 확인합니다.
마이그레이션 에이전트 구성 파일
초기화 단계에서 생성된 구성 파일은 다음 예시와 유사합니다.
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
마이그레이션 에이전트 구성 파일의 전송 작업 옵션
마이그레이션 에이전트 실행
마이그레이션 에이전트를 초기화하고 구성 파일을 작성한 후 다음 단계를 사용하여 에이전트를 실행하고 마이그레이션을 시작하세요.
마이그레이션 진행 상황 추적
Google Cloud 콘솔에서 마이그레이션 상태를 볼 수 있습니다. Pub/Sub 또는 이메일 알림도 설정할 수 있습니다. BigQuery Data Transfer Service 알림을 참고하세요.
BigQuery Data Transfer Service는 전송 구성 작성시 지정된 일정에 따라 전송 실행을 일정 예약하고 시작합니다. 전송 실행이 활성화되어 있을 때 마이그레이션 에이전트가 실행되고 있어야 합니다. 24시간 내에 에이전트 측에서 업데이트가 없으면 전송 실행이 실패합니다.
Google Cloud 콘솔의 마이그레이션 상태 예시:
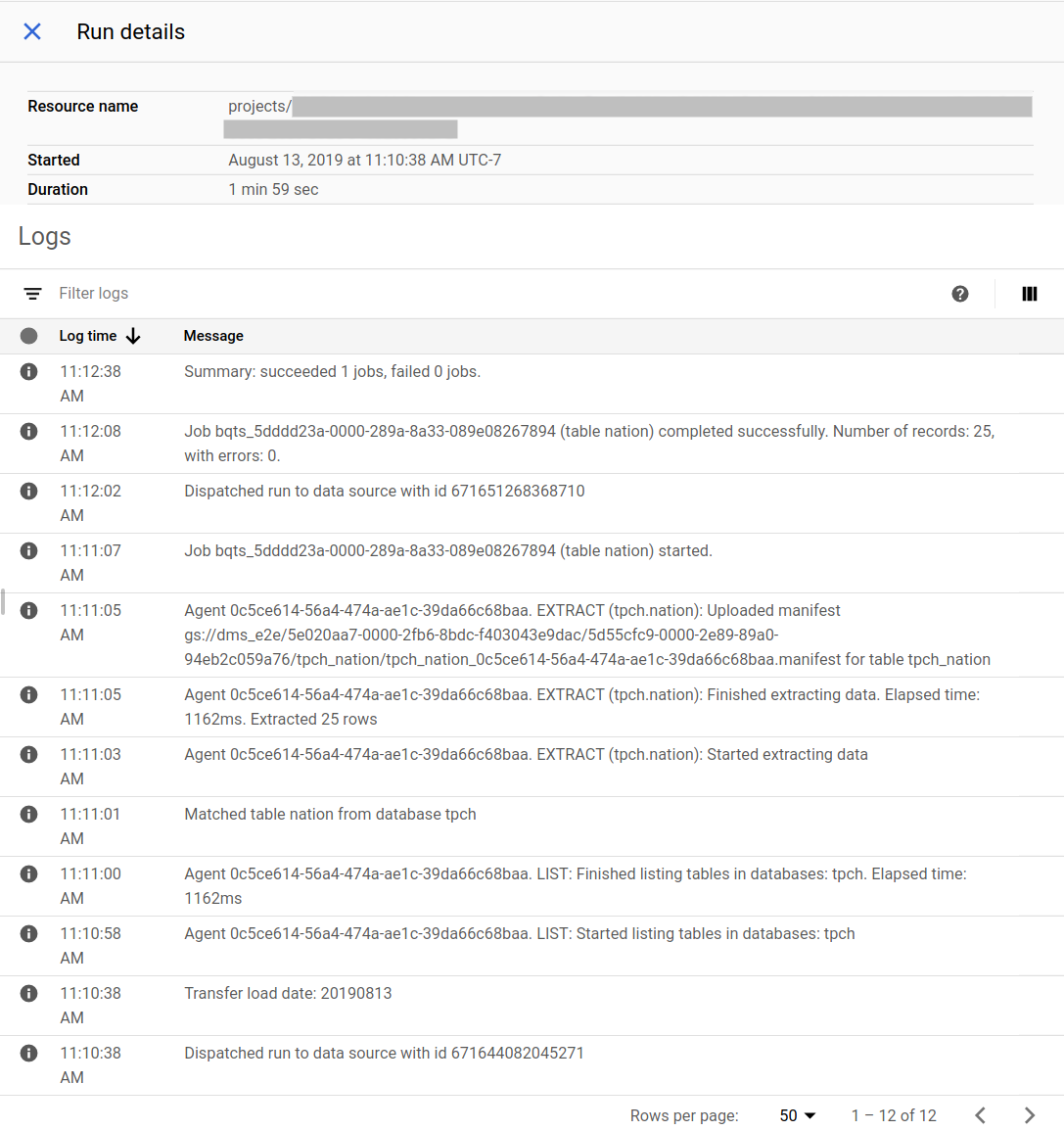
마이그레이션 에이전트 업그레이드
새 버전의 마이그레이션 에이전트를 사용할 수 있는 경우 마이그레이션 에이전트를 수동으로 업데이트해야 합니다. BigQuery Data Transfer Service에 대한 알림을 받으려면 출시 노트를 구독하세요.