Migre o esquema e os dados do Teradata
A combinação do Serviço de transferência de dados do BigQuery e de um agente de migração especial permite-lhe copiar os seus dados de uma instância de armazém de dados nas instalações do Teradata para o BigQuery. Este documento descreve o processo passo a passo de migração de dados do Teradata através do Serviço de transferência de dados do BigQuery.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Visualizador de registos (
roles/logging.viewer) - Administrador de armazenamento (
roles/storage.admin) ou uma função personalizada que conceda as seguintes autorizações:storage.objects.createstorage.objects.getstorage.objects.list
- Administrador do BigQuery (
roles/bigquery.admin) ou uma função personalizada que conceda as seguintes autorizações:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- O agente de migração usa uma ligação JDBC com a instância do Teradata e as APIs Google Cloud . Certifique-se de que o acesso à rede não está bloqueado por uma firewall.
- Certifique-se de que o Java Runtime Environment 8 ou posterior está instalado.
- Certifique-se de que tem espaço de armazenamento suficiente para o método de extração que escolheu, conforme descrito em Método de extração.
- Se decidiu usar a extração do Teradata Parallel Transporter (TPT),
certifique-se de que a utilidade
tbuildestá instalada. Para mais informações sobre como escolher um método de extração, consulte Método de extração. Certifique-se de que tem o nome de utilizador e a palavra-passe de um utilizador do Teradata com acesso de leitura às tabelas do sistema e às tabelas que estão a ser migradas.
Certifique-se de que conhece o nome de anfitrião e o número da porta para estabelecer ligação à instância do Teradata.
client_emailprivate_key: Copia todos os carateres entre-----BEGIN PRIVATE KEY-----e-----END PRIVATE KEY-----, incluindo todos os carateres/ne sem as aspas.ACCESS_ID: o ID da chave de acesso ou o valorclient_emailno ficheiro de chave da conta de serviço.ACCESS_KEY: a chave de acesso secreta ou o valorprivate_keyno ficheiro de chave da conta de serviço.Na Google Cloud consola, aceda à página do BigQuery.
Clique em Transferências de dados.
Clique em Criar transferência.
Na secção Tipo de origem, faça o seguinte:
- Escolha Migração: Teradata.
- Para Nome da configuração de transferência, introduza um nome a apresentar para a transferência, como
My Migration. O nome a apresentar pode ser qualquer valor que lhe permita identificar facilmente a transferência se precisar de a modificar mais tarde. - Opcional: para Opções de agendamento, pode deixar o valor predefinido de Diariamente (com base na hora de criação) ou escolher outra hora se quiser uma transferência recorrente e incremental. Caso contrário, escolha A pedido para uma transferência única.
Para Definições de destino, escolha o conjunto de dados adequado.
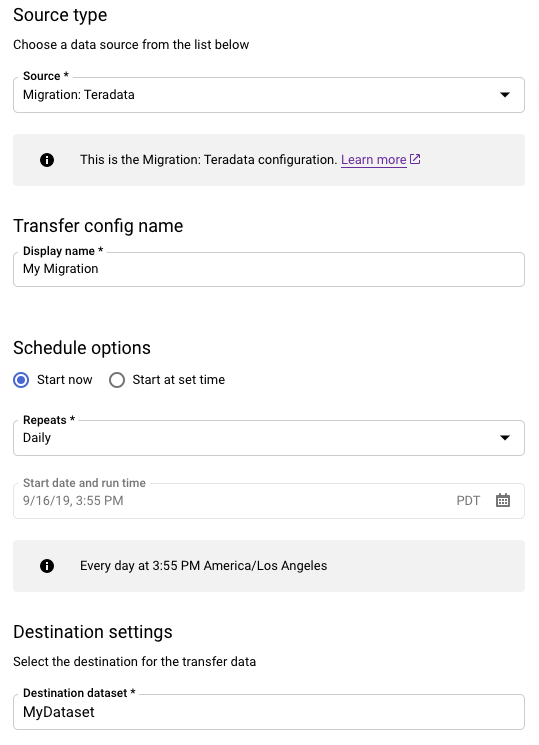
Na secção Detalhes da origem de dados, continue com detalhes específicos para a sua transferência do Teradata.
- Para Tipo de base de dados, escolha Teradata.
- Para Contentor do Cloud Storage, procure o nome do contentor do Cloud Storage
para preparar os dados de migração. Não escreva o prefixo
gs://. Introduza apenas o nome do contentor. - Para Nome da base de dados, introduza o nome da base de dados de origem no Teradata.
Para Padrões de nomes de tabelas, introduza um padrão para fazer corresponder os nomes das tabelas na base de dados de origem. Pode usar expressões regulares para especificar o padrão. Por exemplo:
sales|expensescorresponde a tabelas com os nomessaleseexpenses..*corresponde a todas as tabelas.
Para o Email da conta de serviço, introduza o endereço de email associado às credenciais da conta de serviço usadas por um agente de migração.
Opcional: para Caminho do ficheiro de esquema, introduza o caminho e o nome do ficheiro de um ficheiro de esquema personalizado. Para mais informações sobre como criar um ficheiro de esquema personalizado, consulte o artigo Ficheiro de esquema personalizado. Pode deixar este campo em branco para que o BigQuery detete automaticamente o esquema da tabela de origem.
Opcional: para Diretório raiz de saída da tradução, introduza o caminho e o nome do ficheiro do ficheiro de mapeamento do esquema fornecido pelo motor de tradução do BigQuery. Para mais informações sobre como gerar um ficheiro de mapeamento de esquemas, consulte o artigo Usar o resultado do motor de tradução para o esquema (pré-visualização). Pode deixar este campo em branco para que o BigQuery detete automaticamente o esquema da tabela de origem.
Opcional: para ativar o módulo de acesso para o Cloud Storage com o TPT, selecione a caixa de verificação.
No menu Conta de serviço, selecione uma conta de serviço das contas de serviço associadas ao seu Google Cloud projeto. Pode associar uma conta de serviço à sua transferência em vez de usar as suas credenciais de utilizador. Para mais informações sobre a utilização de contas de serviço com transferências de dados, consulte o artigo Utilize contas de serviço.
- Se iniciou sessão com uma identidade federada, é necessária uma conta de serviço para criar uma transferência. Se tiver iniciado sessão com uma Conta Google, uma conta de serviço para a transferência é opcional.
- A conta de serviço tem de ter as autorizações necessárias.
Opcional: na secção Opções de notificação, faça o seguinte:
- Clique no botão Notificações por email se quiser que o administrador da transferência receba uma notificação por email quando uma execução de transferência falhar.
- Clique no botão Notificações do Pub/Sub para configurar as notificações de execução do Pub/Sub para a transferência. Para Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar um tópico.
Clique em Guardar.
Na página Detalhes da transferência, clique no separador Configuração.
Tome nota do nome do recurso desta transferência, pois precisa dele para executar o agente de migração.
--data_source--display_name--target_dataset--params- project ID é o ID do seu projeto. Se não for fornecido
--project_idpara especificar um projeto em particular, é usado o projeto predefinido. - dataset é o conjunto de dados que quer segmentar (
--target_dataset) para a configuração de transferência. - name é o nome a apresentar (
--display_name) da configuração de transferência. O nome a apresentar da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde. - service_account é o nome da conta de serviço usado para autenticar a sua transferência. A conta de serviço deve ser propriedade do mesmo
project_idusado para criar a transferência e deve ter todas as autorizações necessárias indicadas. - parameters contém os parâmetros (
--params) para a configuração de transferência criada no formato JSON. Por exemplo:--params='{"param":"param_value"}'.- Para migrações do Teradata, use os seguintes parâmetros:
bucketé o contentor do Cloud Storage que vai funcionar como uma área de preparação durante a migração.database_typeé o Teradata.agent_service_accounté o endereço de email associado à conta de serviço que criou.database_nameé o nome da base de dados de origem no Teradata.table_name_patternsé um ou mais padrões para fazer corresponder os nomes das tabelas na base de dados de origem. Pode usar expressões regulares para especificar o padrão. O padrão deve seguir a sintaxe de expressão regular Java. Por exemplo:sales|expensescorresponde a tabelas com os nomessaleseexpenses..*corresponde a todas as tabelas.
- Para migrações do Teradata, use os seguintes parâmetros:
- data_source é a origem de dados (
--data_source):on_premises. Abra uma nova sessão. Na linha de comandos, emita o comando de inicialização, que segue este formato:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
O exemplo seguinte mostra o comando de inicialização quando os ficheiros JAR do controlador JDBC e do agente de migração estão num diretório
migrationlocal:Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copie todos os ficheiros para a pasta
C:\migration(ou ajuste os caminhos no comando) e, em seguida, execute:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Quando lhe for pedido, configure as seguintes opções:
- Escolha se quer guardar o modelo do Teradata Parallel Transporter (TPT) no disco. Se planeia usar o método de extração de TPT, pode modificar o modelo guardado com parâmetros adequados à sua instância do Teradata.
- Escreva o caminho para um diretório local que a tarefa de transferência possa usar para a extração de ficheiros. Certifique-se de que tem o espaço de armazenamento mínimo recomendado, conforme descrito no método de extração.
- Escreva o nome do anfitrião da base de dados.
- Introduza a porta da base de dados.
- Escolha se quer usar o Teradata Parallel Transporter (TPT) como o método de extração.
- Opcional: escreva o caminho para um ficheiro de credenciais da base de dados.
Escolha se quer especificar um nome de configuração do Serviço de transferência de dados do BigQuery.
Se estiver a inicializar o agente de migração para uma transferência que já configurou, faça o seguinte:
- Introduza o nome do recurso da transferência. Pode encontrar esta opção no separador Configuração da página Detalhes da transferência para a transferência.
- Quando lhe for pedido, escreva um caminho e um nome de ficheiro para o ficheiro de configuração do agente de migração que vai ser criado. Refere-se a este ficheiro quando executa o agente de migração para iniciar a transferência.
- Ignore os passos restantes.
Se estiver a usar o agente de migração para configurar uma transferência, prima Enter para avançar para o comando seguinte.
Escreva o Google Cloud ID do projeto.
Escreva o nome da base de dados de origem no Teradata.
Introduza um padrão para fazer corresponder os nomes das tabelas na base de dados de origem. Pode usar expressões regulares para especificar o padrão. Por exemplo:
sales|expensescorresponde a tabelas com os nomessaleseexpenses..*corresponde a todas as tabelas.
Opcional: escreva o caminho para um ficheiro de esquema JSON local. Esta opção é vivamente recomendada para transferências recorrentes.
Se não estiver a usar um ficheiro de esquema ou quiser que o agente de migração crie um para si, prima Enter para avançar para o comando seguinte.
Escolha se pretende criar um novo ficheiro de esquema.
Se quiser criar um ficheiro de esquema:
- Escreva
yes. - Introduza o nome de utilizador de um utilizador do Teradata que tenha acesso de leitura às tabelas do sistema e às tabelas que quer migrar.
Introduza a palavra-passe desse utilizador.
O agente de migração cria o ficheiro de esquema e gera a respetiva localização.
Modifique o ficheiro de esquema para marcar as colunas de particionamento, agrupamento, chaves primárias e acompanhamento de alterações, e verifique se quer usar este esquema para a configuração de transferência. Consulte o ficheiro de esquema personalizado para ver sugestões.
Prima
Enterpara avançar para o comando seguinte.
Se não quiser criar um ficheiro de esquema, escreva
no.- Escreva
Escreva o nome do contentor do Cloud Storage de destino para preparar os dados de migração antes de os carregar para o BigQuery. Se o agente de migração tiver criado um ficheiro de esquema personalizado, este também é carregado para este contentor.
Escreva o nome do conjunto de dados de destino no BigQuery.
Escreva um nome a apresentar para a configuração de transferência.
Escreva um caminho e um nome de ficheiro para o ficheiro de configuração do agente de migração que vai ser criado.
Depois de introduzir todos os parâmetros pedidos, o agente de migração cria um ficheiro de configuração e envia-o para o caminho local que especificou. Consulte a secção seguinte para ver mais detalhes sobre o ficheiro de configuração.
transfer-configuration: Informações sobre esta configuração de transferência no BigQuery.teradata-config: informações específicas para esta extração do Teradata:connection: informações sobre o nome do anfitrião e a portalocal-processing-space: a pasta de extração para a qual o agente vai extrair os dados de tabelas antes de os carregar para o Cloud Storage.database-credentials-file-path: (Opcional) O caminho para um ficheiro que contém credenciais para estabelecer ligação à base de dados Teradata automaticamente. O ficheiro deve conter duas linhas para as credenciais. Pode usar um nome de utilizador/palavra-passe, como mostrado no exemplo seguinte:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: A quantidade máxima de armazenamento local a usar para a extração no diretório de preparação especificado. O valor predefinido é50GB. O formato suportado é:numberKB|MB|GB|TB.Em todos os modos de extração, os ficheiros são eliminados do diretório de preparação local depois de serem carregados para o Cloud Storage.
use-tpt: direciona o agente de migração para usar o Teradata Parallel Transporter (TPT) como método de extração.Para cada tabela, o agente de migração gera um script TPT, inicia um processo
tbuilde aguarda a conclusão. Quando o processotbuildestiver concluído, o agente lista e carrega os ficheiros extraídos para o Cloud Storage e, em seguida, elimina o script TPT. Para mais informações, consulte o artigo Método de extração.transfer-views: Direciona o agente de migração para também transferir dados das vistas. Use esta opção apenas quando precisar de personalizar os dados durante a migração. Noutros casos, migre as visualizações para visualizações do BigQuery. Esta opção tem os seguintes pré-requisitos:- Só pode usar esta opção com as versões 16.10 e superiores do Teradata.
- Uma vista deve ter uma coluna de números inteiros "partition" definida, que aponta para um ID de partição para a linha especificada na tabela subjacente.
max-sessions: especifica o número máximo de sessões usadas pela tarefa de exportação (FastExport ou TPT). Se estiver definido como 0, a base de dados Teradata determina o número máximo de sessões para cada tarefa de exportação.gcs-upload-chunk-size: um ficheiro grande é carregado para o Cloud Storage em partes. Este parâmetro, juntamente commax-parallel-upload, é usado para controlar a quantidade de dados carregados para o Cloud Storage em simultâneo. Por exemplo, se ogcs-upload-chunk-sizefor de 64 MB e omax-parallel-uploadfor de 10 MB, teoricamente, um agente de migração pode carregar 640 MB (64 MB * 10) de dados ao mesmo tempo. Se o carregamento do fragmento falhar, tem de tentar novamente o carregamento de todo o fragmento. O tamanho do fragmento tem de ser pequeno.max-parallel-upload: este valor determina o número máximo de threads usados pelo agente de migração para carregar ficheiros para o Cloud Storage. Se não for especificado, o valor predefinido é o número de processadores disponíveis para a máquina virtual Java. A regra geral é escolher o valor com base no número de núcleos que tem na máquina que executa o agente. Assim, se tivernnúcleos, o número ideal de threads deve sern. Se os núcleos tiverem hyperthreading, o número ideal deve ser(2 * n). Também existem outras definições, como a largura de banda da rede, que tem de considerar ao ajustarmax-parallel-upload. Ajustar este parâmetro pode melhorar o desempenho do carregamento para o Cloud Storage.spool-mode: na maioria dos casos, o modo NoSpool é a melhor opção.NoSpoolé o valor predefinido na configuração do agente. Pode alterar este parâmetro se alguma das desvantagens de NoSpool se aplicar ao seu caso.max-unload-file-size: determina o tamanho máximo do ficheiro extraído. Este parâmetro não é aplicado para extrações de TPT.max-parallel-extract-threads: esta configuração é usada apenas no modo FastExport. Determina o número de threads paralelos usados para extrair os dados do Teradata. Ajustar este parâmetro pode melhorar o desempenho da extração.tpt-template-path: use esta configuração para fornecer um script de extração de TPT personalizado como entrada. Pode usar este parâmetro para aplicar transformações aos dados de migração.schema-mapping-rule-path: (Opcional) O caminho para um ficheiro de configuração que contém um mapeamento de esquema para substituir as regras de mapeamento predefinidas. Alguns tipos de mapeamento só funcionam com o modo Teradata Parallel Transporter (TPT).Exemplo: mapeamento do tipo
TIMESTAMPdo Teradata para o tipoDATETIMEdo BigQuery:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Atributos:
database: (Opcional)nameé uma expressão regular para bases de dados a incluir. Por predefinição, todas as bases de dados estão incluídas.tables: (Opcional) contém uma matriz de tabelas.nameé uma expressão regular para as tabelas a incluir. Por predefinição, todas as tabelas estão incluídas.match: (Obrigatório)- Valores suportados de
type:COLUMN_TYPE. - Valores suportados de
value:TIMESTAMP,DATETIME.
- Valores suportados de
action: (Obrigatório)- Valores suportados de
type:MAPPING. - Valores suportados de
value:TIMESTAMP,DATETIME.
- Valores suportados de
compress-output: (Opcional) determina se os dados devem ser comprimidos antes de serem armazenados no Cloud Storage. Isto só é aplicado no tpt-mode. Por predefinição, este valor éfalse.gcs-module-config-dir: (Opcional) o caminho para o ficheiro de credenciais para aceder ao contentor do Cloud Storage. O diretório predefinido é$HOME/.gcs, mas pode usar este parâmetro para alterar o diretório.gcs-module-connection-count: (Opcional) especifica o número de ligações TCP ao serviço Cloud Storage. O valor predefinido é 10.gcs-module-buffer-size: (Opcional) Especifica o tamanho das memórias intermédias a usar para as ligações TCP. A predefinição é 8 MB (8388608 bytes). Para facilitar a utilização, pode usar os seguintes multiplicadores:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (Opcional) especifica o número de buffers a usar com as ligações TCP especificadas porgcs-module-connection-count. Recomendamos que use um valor igual ao dobro do número de ligações TCP ao serviço Cloud Storage. O valor predefinido é 2 *gcs-module-connection-count.gcs-module-max-object-size: (Opcional) Este parâmetro controla os tamanhos dos objetos do Cloud Storage. O valor deste parâmetro pode ser um número inteiro ou um número inteiro seguido, sem um espaço, de um dos seguintes multiplicadores:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (Opcional) Este parâmetro especifica o número de instâncias de gravação do Cloud Storage. Por predefinição, o valor é 1. Pode aumentar este valor para aumentar a taxa de transferência durante a fase de gravação da exportação de TPT.
Execute o agente especificando os caminhos para o controlador JDBC, o agente de migração e o ficheiro de configuração que foi criado no passo de inicialização anterior.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copie todos os ficheiros para a pasta
C:\migration(ou ajuste os caminhos no comando) e, em seguida, execute:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Se quiser continuar com a migração, prima
Entere o agente continua se o caminho de classe fornecido durante a inicialização for válido.Quando lhe for pedido, escreva o nome de utilizador e a palavra-passe para a ligação à base de dados. Se o nome de utilizador e a palavra-passe forem válidos, a migração de dados é iniciada.
Opcional No comando para iniciar a migração, também pode usar uma flag que transmita um ficheiro de credenciais ao agente, em vez de introduzir o nome de utilizador e a palavra-passe de cada vez. Consulte o parâmetro opcional
database-credentials-file-pathno ficheiro de configuração do agente para mais informações. Quando usar um ficheiro de credenciais, tome as medidas adequadas para controlar o acesso à pasta onde o armazena no sistema de ficheiros local, porque não é encriptado.Mantenha esta sessão aberta até a migração estar concluída. Se criou uma transferência de migração recorrente, mantenha esta sessão aberta indefinidamente. Se esta sessão for interrompida, as execuções de transferência atuais e futuras falham.
Monitorize periodicamente se o agente está em execução. Se uma execução de transferência estiver em curso e nenhum agente responder no prazo de 24 horas, a execução de transferência falha.
Se o agente de migração deixar de funcionar enquanto a transferência estiver em curso ou agendada, a consola mostra o estado de erro e pede-lhe para reiniciar o agente. Google Cloud Para iniciar novamente o agente de migração, retome a partir do início desta secção, executando o agente de migração, com o comando para executar o agente de migração. Não precisa de repetir o comando de inicialização. A transferência é retomada a partir do ponto em que as tabelas não foram concluídas.
- Experimente uma migração de teste do Teradata para o BigQuery.
- Saiba mais acerca do Serviço de transferência de dados do BigQuery.
- Migre código SQL com a tradução de SQL em lote.
Defina as autorizações necessárias
Certifique-se de que o principal que está a criar a transferência tem as seguintes funções no projeto que contém a tarefa de transferência:
Crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar os seus dados. Não tem de criar tabelas.
Crie um contentor do Cloud Storage
Crie um contentor do Cloud Storage para preparar os dados durante a tarefa de transferência.
Prepare o ambiente local
Conclua as tarefas nesta secção para preparar o seu ambiente local para a tarefa de transferência.
Requisitos do computador local
Detalhes da ligação do Teradata
Transfira o controlador JDBC
Transfira o ficheiro do controlador JDBC do Teradata
para um computador que se possa ligar ao armazém de dados.terajdbc4.jar
Defina a variável GOOGLE_APPLICATION_CREDENTIALS
Defina a variável de ambiente GOOGLE_APPLICATION_CREDENTIALS
para a chave da conta de serviço que transferiu na secção
Antes de começar.
Atualize a regra de saída dos VPC Service Controls
Adicione um Google Cloud projeto gerido do Serviço de transferência de dados do BigQuery (número do projeto: 990232121269) à regra de saída no perímetro do VPC Service Controls.
O canal de comunicação entre o agente em execução nas instalações e o Serviço de transferência de dados do BigQuery é através da publicação de mensagens do Pub/Sub num tópico por transferência. O Serviço de transferência de dados do BigQuery tem de enviar comandos ao agente para extrair dados, e o agente tem de publicar mensagens de volta para o Serviço de transferência de dados do BigQuery para atualizar o estado e devolver respostas de extração de dados.
Crie um ficheiro de esquema personalizado
Para usar um ficheiro de esquema personalizado em vez da deteção automática de esquemas, crie um manualmente ou peça ao agente de migração para criar um para si quando inicializar o agente.
Se criar um ficheiro de esquema manualmente e pretender usar a consola para criar uma transferência, carregue o ficheiro de esquema para um contentor do Cloud Storage no mesmo projeto que planeia usar para a transferência. Google Cloud
Transfira o agente de migração
Transfira o agente de migração para um computador que se possa ligar ao armazém de dados. Mova o ficheiro JAR do agente de migração para o mesmo diretório que o ficheiro JAR do controlador JDBC do Teradata.
Configure o ficheiro de credenciais para o módulo de acesso
É necessário um ficheiro de credenciais se estiver a usar o módulo de acesso para o Cloud Storage com o utilitário Teradata Parallel Transporter (TPT) para extração.
Antes de criar um ficheiro de credenciais, tem de criar uma chave de conta de serviço. A partir do ficheiro de chave de conta de serviço transferido, obtenha as seguintes informações:
Depois de ter as informações necessárias, crie um ficheiro de credenciais. Segue-se um exemplo de um ficheiro de credenciais com uma localização predefinida de $HOME/.gcs/credentials:
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
Substitua o seguinte:
Configure uma transferência
Crie uma transferência com o Serviço de transferência de dados do BigQuery.
Se quiser que um ficheiro de esquema personalizado seja criado automaticamente, use o agente de migração para configurar a transferência.
Não pode criar uma transferência a pedido através da ferramenta de linha de comandos bq; em alternativa, tem de usar a Google Cloud consola ou a API do Serviço de transferência de dados do BigQuery.
Se estiver a criar uma transferência recorrente, recomendamos vivamente que especifique um ficheiro de esquema para que os dados de transferências subsequentes possam ser particionados corretamente quando forem carregados para o BigQuery. Sem um ficheiro de esquema, o Serviço de transferência de dados do BigQuery infere o esquema da tabela a partir dos dados de origem que estão a ser transferidos, e todas as informações sobre a partição, o agrupamento, as chaves primárias e a monitorização de alterações são perdidas. Além disso, as transferências subsequentes ignoram as tabelas migradas anteriormente após a transferência inicial. Para mais informações sobre como criar um ficheiro de esquema, consulte o artigo Ficheiro de esquema personalizado.
Consola
bq
Quando cria uma transferência do Cloud Storage através da ferramenta bq, a configuração de transferência é definida para ocorrer a cada 24 horas. Para transferências a pedido, use a Google Cloud consola ou a API do Serviço de transferência de dados do BigQuery.
Não pode configurar notificações através da ferramenta bq.
Introduza o comando
bq mk
e forneça a flag de criação de transferência
--transfer_config. Os seguintes indicadores também são obrigatórios:
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Onde:
Por exemplo, o comando seguinte cria uma transferência do Teradata denominada My Transfer usando o contentor do Cloud Storage mybucket e o conjunto de dados de destino mydataset. A transferência migra todas as tabelas do data warehouse do Teradata mydatabase e o ficheiro de esquema opcional é myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json"}' \ --data_source=on_premises
Depois de executar o comando, recebe uma mensagem semelhante à seguinte:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Siga as instruções e cole o código de autenticação na linha de comandos.
API
Use o método projects.locations.transferConfigs.create
e forneça uma instância do recurso TransferConfig.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Agente de migração
Opcionalmente, pode configurar a transferência diretamente a partir do agente de migração. Para mais informações, consulte o artigo Inicialize o agente de migração.
Inicialize o agente de migração
Tem de inicializar o agente de migração para uma nova transferência. A inicialização é necessária apenas uma vez para uma transferência, seja recorrente ou não. A inicialização apenas configura o agente de migração. Não inicia a transferência.
Se vai usar o agente de migração para criar um ficheiro de esquema personalizado,
certifique-se de que tem um diretório gravável no seu
diretório de trabalho com o mesmo nome do projeto que quer usar para a
transferência. É aqui que o agente de migração cria o ficheiro de esquema.
Por exemplo, se estiver a trabalhar no /home e a configurar a transferência no projeto myProject, crie o diretório /home/myProject e certifique-se de que os utilizadores podem escrever nele.
Ficheiro de configuração do agente de migração
O ficheiro de configuração criado no passo de inicialização tem um aspeto semelhante ao deste exemplo:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Opções da tarefa de transferência no ficheiro de configuração do agente de migração
Execute o agente de migração
Depois de inicializar o agente de migração e criar o ficheiro de configuração, use os seguintes passos para executar o agente e iniciar a migração:
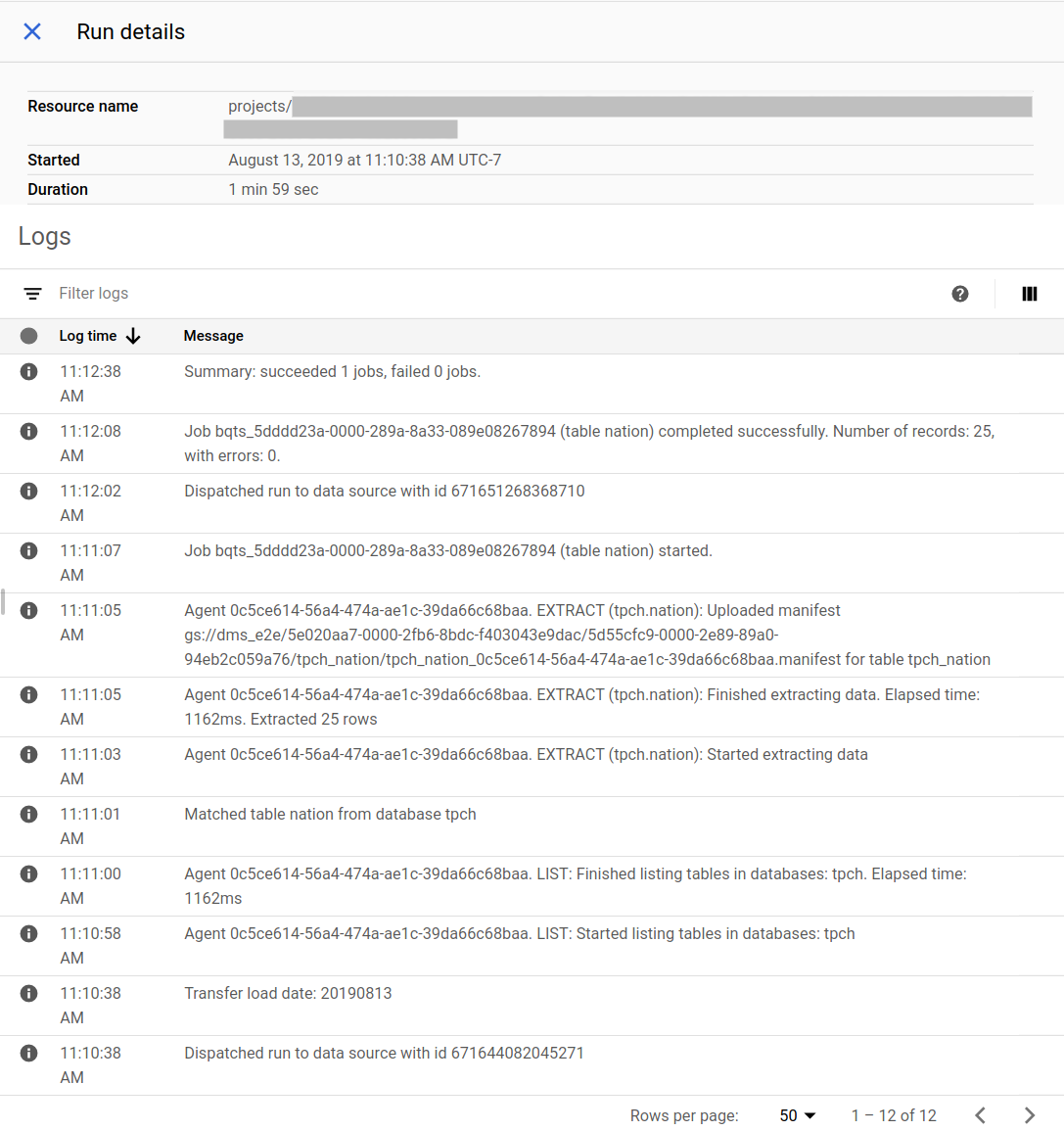
Acompanhe o progresso da migração
Pode ver o estado da migração na Google Cloud consola. Também pode configurar notificações por email ou do Pub/Sub. Consulte as notificações do Serviço de transferência de dados do BigQuery.
O Serviço de transferência de dados do BigQuery agenda e inicia uma execução de transferência de acordo com um agendamento especificado no momento da criação da configuração de transferência. É importante que o agente de migração esteja em execução quando uma execução de transferência estiver ativa. Se não houver atualizações do lado do agente no prazo de 24 horas, a execução da transferência falha.
Exemplo do estado da migração na Google Cloud consola:
Atualize o agente de migração
Se estiver disponível uma nova versão do agente de migração, tem de atualizar manualmente o agente de migração. Para receber avisos sobre o Serviço de transferência de dados do BigQuery, subscreva as notas de lançamento.