Migrar esquemas y datos desde Teradata
Gracias a la combinación de BigQuery Data Transfer Service y un agente de migración especial, puedes copiar tus datos de una instancia de almacén de datos on‐premise de Teradata a BigQuery. En este documento se describe el proceso paso a paso para migrar datos de Teradata mediante BigQuery Data Transfer Service.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Visualizador de registros (
roles/logging.viewer) - Administrador de almacenamiento (
roles/storage.admin) o un rol personalizado que conceda los siguientes permisos:storage.objects.createstorage.objects.getstorage.objects.list
- Administrador de BigQuery (
roles/bigquery.admin) o un rol personalizado que conceda los siguientes permisos:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.transfers.getbigquery.transfers.update
- El agente de migración usa una conexión JDBC con la instancia de Teradata y las APIs de Google Cloud . Asegúrate de que un cortafuegos no bloquee el acceso a la red.
- Asegúrate de que Java Runtime Environment 8 o una versión posterior esté instalado.
- Asegúrate de que tienes suficiente espacio de almacenamiento para el método de extracción que has elegido, tal como se describe en Método de extracción.
- Si has decidido usar la extracción de Teradata Parallel Transporter (TPT),
asegúrate de que la utilidad
tbuildesté instalada. Para obtener más información sobre cómo elegir un método de extracción, consulta Método de extracción. Asegúrate de tener el nombre de usuario y la contraseña de un usuario de Teradata con acceso de lectura a las tablas del sistema y a las tablas que se van a migrar.
Asegúrate de conocer el nombre de host y el número de puerto para conectarte a la instancia de Teradata.
client_emailprivate_key: copia todos los caracteres entre-----BEGIN PRIVATE KEY-----y-----END PRIVATE KEY-----, incluidos todos los caracteres/ny sin las comillas dobles que los delimitan.ACCESS_ID: el ID de clave de acceso o el valorclient_emailde tu archivo de clave de cuenta de servicio.ACCESS_KEY: la clave de acceso secreta o el valorprivate_keydel archivo de claves de tu cuenta de servicio.En la Google Cloud consola, ve a la página BigQuery.
Haz clic en Transferencias de datos.
Haz clic en Crear transferencia.
En la sección Tipo de fuente, haga lo siguiente:
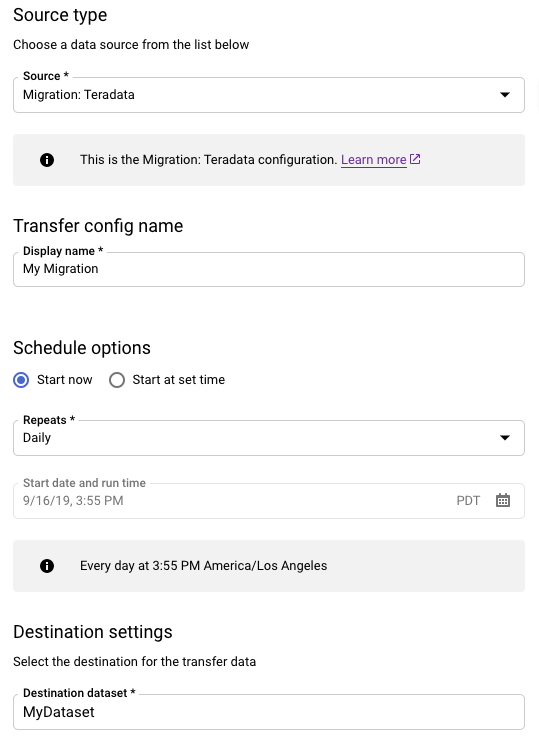
- Elige Migración: Teradata.
- En Transfer config name (Nombre de la configuración de transferencia), introduce un nombre visible para la transferencia, como
My Migration. El nombre visible puede ser cualquier valor que te permita identificar fácilmente la transferencia si necesitas modificarla más adelante. - Opcional: En Opciones de programación, puedes dejar el valor predeterminado Diario (basado en la hora de creación) o elegir otra hora si quieres que la transferencia se repita y sea incremental. De lo contrario, elige Bajo demanda para hacer una transferencia única.
En Ajustes de destino, elija el conjunto de datos adecuado.
En la sección Detalles de la fuente de datos, indica los detalles específicos de tu transferencia de Teradata.
- En Tipo de base de datos, elige Teradata.
- En Segmento de Cloud Storage, busca el nombre del segmento de Cloud Storage en el que se almacenarán temporalmente los datos de migración. No escribas el prefijo
gs://, solo el nombre del segmento. - En Database name (Nombre de la base de datos), introduce el nombre de la base de datos de origen en Teradata.
En Patrones de nombres de tabla, introduzca un patrón para que coincida con los nombres de tabla de la base de datos de origen. Puedes usar expresiones regulares para especificar el patrón. Por ejemplo:
sales|expensescoincide con las tablas llamadassalesyexpenses..*coincide con todas las tablas.
En Correo de la cuenta de servicio, introduce la dirección de correo asociada a las credenciales de la cuenta de servicio que usa un agente de migración.
Opcional: En Ruta del archivo de esquema, introduce la ruta y el nombre de un archivo de esquema personalizado. Para obtener más información sobre cómo crear un archivo de esquema personalizado, consulte Archivo de esquema personalizado. Puedes dejar este campo en blanco para que BigQuery detecte automáticamente el esquema de la tabla de origen.
Opcional: En Directorio raíz de salida de la traducción, introduce la ruta y el nombre del archivo de asignación de esquemas proporcionado por el motor de traducción de BigQuery. Para obtener más información sobre cómo generar un archivo de asignación de esquemas, consulta Usar la salida del motor de traducción para el esquema (vista previa). Puedes dejar este campo en blanco para que BigQuery detecte automáticamente el esquema de la tabla de origen.
Opcional: En Habilitar descarga directa en GCS, marca la casilla para habilitar el módulo de acceso para Cloud Storage.
En el menú Cuenta de servicio, selecciona una cuenta de servicio de las asociadas a tu proyecto deGoogle Cloud . Puedes asociar una cuenta de servicio a tu transferencia en lugar de usar tus credenciales de usuario. Para obtener más información sobre el uso de cuentas de servicio con transferencias de datos, consulta el artículo Usar cuentas de servicio.
- Si has iniciado sesión con una identidad federada, debes tener una cuenta de servicio para crear una transferencia. Si has iniciado sesión con una cuenta de Google, no es obligatorio tener una cuenta de servicio para la transferencia.
- La cuenta de servicio debe tener los permisos necesarios.
Opcional: En la sección Opciones de notificación, haz lo siguiente:
- Haga clic en el interruptor Notificaciones por correo electrónico si quiere que el administrador de la transferencia reciba una notificación por correo cuando falle una transferencia.
- Haz clic en el botón Notificaciones de Pub/Sub para configurar las notificaciones de Pub/Sub sobre la transferencia. En Selecciona un tema de Pub/Sub, elige el nombre del tema o haz clic en Crear un tema.
Haz clic en Guardar.
En la página Detalles de la transferencia, haga clic en la pestaña Configuración.
Anota el nombre de recurso de esta transferencia, ya que lo necesitarás para ejecutar el agente de migración.
--data_source--display_name--target_dataset--params- project ID es el ID del proyecto. Si no se proporciona
--project_idpara especificar un proyecto concreto, se usará el proyecto predeterminado. - dataset es el conjunto de datos al que quieres orientar la configuración de la transferencia (
--target_dataset). - name es el nombre visible (
--display_name) de la configuración de transferencia. El nombre visible de la transferencia puede ser cualquier valor que te permita identificarla si necesitas modificarla más adelante. - service_account es el nombre de la cuenta de servicio que se usa para autenticar tu transferencia. La cuenta de servicio debe ser propiedad del mismo
project_idque se usó para crear la transferencia y debe tener todos los permisos necesarios. - parameters contiene los parámetros (
--params) de la configuración de transferencia creada en formato JSON. Por ejemplo:--params='{"param":"param_value"}'.- En las migraciones de Teradata, usa los siguientes parámetros:
bucketes el segmento de Cloud Storage que actuará como área de almacenamiento temporal durante la migración.database_typees Teradata.agent_service_accountes la dirección de correo asociada a la cuenta de servicio que has creado.database_namees el nombre de la base de datos de origen en Teradata.table_name_patternses un patrón o patrones para buscar coincidencias con los nombres de las tablas de la base de datos de origen. Puedes usar expresiones regulares para especificar el patrón. El patrón debe seguir la sintaxis de expresiones regulares de Java. Por ejemplo:sales|expensescoincide con las tablas llamadassalesyexpenses..*coincide con todas las tablas.
is_direct_gcs_unload_enabledes un indicador booleano para habilitar la descarga directa en Cloud Storage.
- En las migraciones de Teradata, usa los siguientes parámetros:
- data_source es la fuente de datos (
--data_source):on_premises. Abre una nueva sesión. En la línea de comandos, ejecuta el comando de inicialización, que tiene este formato:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
En el ejemplo siguiente se muestra el comando de inicialización cuando los archivos JAR del controlador JDBC y del agente de migración se encuentran en un directorio
migrationlocal:Unix, Linux y Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Copia todos los archivos en la carpeta
C:\migration(o ajusta las rutas en el comando) y, a continuación, ejecuta lo siguiente:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Cuando se te solicite, configura las siguientes opciones:
- Elige si quieres guardar la plantilla de Teradata Parallel Transporter (TPT) en el disco. Si tienes previsto usar el método de extracción de TPT, puedes modificar la plantilla guardada con los parámetros que se adapten a tu instancia de Teradata.
- Escribe la ruta de un directorio local que la tarea de transferencia pueda usar para extraer archivos. Asegúrate de que tienes el espacio de almacenamiento mínimo recomendado, tal como se describe en la sección Método de extracción.
- Escribe el nombre de host de la base de datos.
- Escribe el puerto de la base de datos.
- Elige si quieres usar Teradata Parallel Transporter (TPT) como método de extracción.
- Opcional: Escribe la ruta a un archivo de credenciales de la base de datos.
Elige si quieres especificar un nombre de configuración de BigQuery Data Transfer Service.
Si vas a inicializar el agente de migración para una transferencia que ya has configurado, haz lo siguiente:
- Escribe el nombre de recurso de la transferencia. Puedes encontrarlo en la pestaña Configuración de la página Detalles de la transferencia.
- Cuando se te solicite, escribe la ruta y el nombre del archivo de configuración del agente de migración que se va a crear. Haces referencia a este archivo cuando ejecutas el agente de migración para iniciar la transferencia.
- Sáltate los pasos restantes.
Si usas el agente de migración para configurar una transferencia, pulsa Intro para ir a la siguiente petición.
Escribe el Google Cloud ID de proyecto.
Escribe el nombre de la base de datos de origen en Teradata.
Escribe un patrón para que coincidan los nombres de las tablas de la base de datos de origen. Puedes usar expresiones regulares para especificar el patrón. Por ejemplo:
sales|expensescoincide con las tablas llamadassalesyexpenses..*coincide con todas las tablas.
Opcional: Escribe la ruta a un archivo de esquema JSON local. Se recomienda encarecidamente para las transferencias periódicas.
Si no usas un archivo de esquema o quieres que el agente de migración cree uno por ti, pulsa Intro para ir a la siguiente petición.
Elige si quieres crear un archivo de esquema.
Si quieres crear un archivo de esquema:
- Escribe
yes. - Escribe el nombre de usuario de un usuario de Teradata que tenga acceso de lectura a las tablas del sistema y a las tablas que quieras migrar.
Escribe la contraseña de ese usuario.
El agente de migración crea el archivo de esquema y muestra su ubicación.
Modifica el archivo de esquema para marcar las columnas de partición, clustering, claves principales y seguimiento de cambios, y verifica que quieres usar este esquema en la configuración de la transferencia. Consulta los consejos sobre archivos de esquema personalizado.
Pulsa
Enterpara ir a la siguiente petición.
Si no quieres crear un archivo de esquema, escribe
no.- Escribe
Escribe el nombre del segmento de Cloud Storage de destino para la migración provisional de datos antes de cargarlos en BigQuery. Si el agente de migración ha creado un archivo de esquema personalizado, también se subirá a este contenedor.
Escribe el nombre del conjunto de datos de destino en BigQuery.
Escribe un nombre visible para la configuración de transferencia.
Escriba la ruta y el nombre del archivo de configuración del agente de migración que se va a crear.
Después de introducir todos los parámetros solicitados, el agente de migración crea un archivo de configuración y lo envía a la ruta local que hayas especificado. En la siguiente sección se explica con más detalle el archivo de configuración.
transfer-configuration: información sobre esta configuración de transferencia en BigQuery.teradata-config: Información específica de esta extracción de Teradata:connection: información sobre el nombre de host y el puertolocal-processing-space: carpeta de extracción en la que el agente extraerá los datos de la tabla antes de subirlos a Cloud Storage.database-credentials-file-path: (Opcional) Ruta a un archivo que contiene las credenciales para conectarse automáticamente a la base de datos de Teradata. El archivo debe contener dos líneas para las credenciales. Puedes usar un nombre de usuario y una contraseña, como se muestra en el siguiente ejemplo:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: cantidad máxima de almacenamiento local que se va a usar para la extracción en el directorio de almacenamiento provisional especificado. El valor predeterminado es50GB. El formato admitido esnumberKB|MB|GB|TB.En todos los modos de extracción, los archivos se eliminan del directorio de almacenamiento temporal local después de subirse a Cloud Storage.
use-tpt: indica al agente de migración que use Teradata Parallel Transporter (TPT) como método de extracción.En cada tabla, el agente de migración genera una secuencia de comandos TPT, inicia un proceso
tbuildy espera a que se complete. Una vez que se haya completado eltbuildproceso , el agente mostrará una lista de los archivos extraídos, los subirá a Cloud Storage y, a continuación, eliminará la secuencia de comandos TPT. Para obtener más información, consulta Método de extracción.transfer-views: indica al agente de migración que también transfiera datos de las vistas. Úsalo solo cuando necesites personalizar los datos durante la migración. En otros casos, migra las vistas a vistas de BigQuery. Esta opción tiene los siguientes requisitos previos:- Solo puedes usar esta opción con las versiones 16.10 y posteriores de Teradata.
- Una vista debe tener definida una columna de números enteros "partition" (partición) que apunte a un ID de partición de la fila correspondiente en la tabla subyacente.
max-sessions: especifica el número máximo de sesiones que usa el trabajo de extracción (FastExport o TPT). Si se define como 0, la base de datos de Teradata determinará el número máximo de sesiones de cada tarea de extracción.gcs-upload-chunk-size: se sube un archivo de gran tamaño a Cloud Storage en fragmentos. Este parámetro, junto conmax-parallel-upload, se usa para controlar la cantidad de datos que se suben a Cloud Storage al mismo tiempo. Por ejemplo, sigcs-upload-chunk-sizees de 64 MB ymax-parallel-uploades de 10 MB, un agente de migración puede subir 640 MB (64 MB * 10) de datos al mismo tiempo. Si no se puede subir el fragmento, se debe volver a intentar subir todo el fragmento. El tamaño del fragmento debe ser pequeño.max-parallel-upload: este valor determina el número máximo de subprocesos que utiliza el agente de migración para subir archivos a Cloud Storage. Si no se especifica, se utiliza de forma predeterminada el número de procesadores disponibles para la máquina virtual Java. Por lo general, se recomienda elegir el valor en función del número de núcleos que tenga el ordenador en el que se ejecuta el agente. Por lo tanto, si tienesnnúcleos, el número óptimo de subprocesos debería sern. Si los núcleos tienen hiperproceso, el número óptimo debe ser(2 * n). También hay otros ajustes, como el ancho de banda de la red, que debes tener en cuenta al ajustarmax-parallel-upload. Ajustar este parámetro puede mejorar el rendimiento de las subidas a Cloud Storage.spool-mode: en la mayoría de los casos, el modo NoSpool es la mejor opción.NoSpooles el valor predeterminado en la configuración del agente. Puedes cambiar este parámetro si se da alguna de las desventajas de NoSpool en tu caso.max-unload-file-size: determina el tamaño máximo del archivo extraído. Este parámetro no se aplica a las extracciones de TPT.max-parallel-extract-threads: esta configuración solo se usa en el modo FastExport. Determina el número de hilos paralelos que se utilizan para extraer los datos de Teradata. Ajustar este parámetro podría mejorar el rendimiento de la extracción.tpt-template-path: usa esta configuración para proporcionar una secuencia de comandos de extracción de TPT personalizada como entrada. Puede usar este parámetro para aplicar transformaciones a los datos de migración.schema-mapping-rule-path: (Opcional) Ruta a un archivo de configuración que contiene una asignación de esquemas para anular las reglas de asignación predeterminadas. Algunos tipos de asignación solo funcionan con el modo Teradata Parallel Transporter (TPT).Ejemplo: asignación del tipo
TIMESTAMPde Teradata al tipoDATETIMEde BigQuery:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Atributos
database: (Opcional)namees una expresión regular para las bases de datos que se van a incluir. Todas las bases de datos se incluyen de forma predeterminada.tables: (opcional) contiene un array de tablas.namees una expresión regular de las tablas que se van a incluir. Todas las tablas se incluyen de forma predeterminada.match: (Obligatorio)- Valores admitidos de
type:COLUMN_TYPE. - Valores admitidos de
value:TIMESTAMPyDATETIME.
- Valores admitidos de
action: (Obligatorio)- Valores admitidos de
type:MAPPING. - Valores admitidos de
value:TIMESTAMPyDATETIME.
- Valores admitidos de
compress-output: (Opcional) indica si los datos se deben comprimir antes de almacenarlos en Cloud Storage. Esto solo se aplica en tpt-mode. De forma predeterminada, este valor esfalse.gcs-module-config-dir: (Opcional) la ruta al archivo de credenciales para acceder al segmento de Cloud Storage. El directorio predeterminado es$HOME/.gcs, pero puedes usar este parámetro para cambiarlo.gcs-module-connection-count: (Opcional) Especifica el número de conexiones TCP al servicio Cloud Storage. El valor predeterminado es 10.gcs-module-buffer-size: (Opcional) Especifica el tamaño de los búferes que se usarán para las conexiones TCP. El valor predeterminado es 8 MB (8388608 bytes). Para que te resulte más fácil, puedes usar los siguientes multiplicadores:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (Opcional) Especifica el número de búferes que se van a usar con las conexiones TCP especificadas porgcs-module-connection-count. Te recomendamos que uses un valor igual al doble del número de conexiones TCP al servicio Cloud Storage. El valor predeterminado es 2 *gcs-module-connection-count.gcs-module-max-object-size: (Opcional) Este parámetro controla el tamaño de los objetos de Cloud Storage. El valor de este parámetro puede ser un número entero o un número entero seguido, sin espacio, de uno de los siguientes multiplicadores:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (Opcional) Este parámetro especifica el número de instancias de escritura de Cloud Storage. El valor predeterminado es 1. Puedes aumentar este valor para aumentar el rendimiento durante la fase de escritura de la exportación de TPT.
Ejecuta el agente especificando las rutas al controlador JDBC, al agente de migración y al archivo de configuración que se creó en el paso de inicialización anterior.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux y Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Copia todos los archivos en la carpeta
C:\migration(o ajusta las rutas en el comando) y, a continuación, ejecuta lo siguiente:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Si quieres continuar con la migración, pulsa
Enter. El agente continuará si la ruta de clases proporcionada durante la inicialización es válida.Cuando se te pida, escribe el nombre de usuario y la contraseña de la conexión de la base de datos. Si el nombre de usuario y la contraseña son válidos, se iniciará la migración de datos.
Opcional: En el comando para iniciar la migración, también puedes usar una marca que transfiera un archivo de credenciales al agente en lugar de introducir el nombre de usuario y la contraseña cada vez. Para obtener más información, consulta el parámetro opcional
database-credentials-file-pathen el archivo de configuración del agente. Si utilizas un archivo de credenciales, toma las medidas oportunas para controlar el acceso a la carpeta en la que lo almacenes en el sistema de archivos local, ya que no estará cifrado.Deja esta sesión abierta hasta que se complete la migración. Si has creado una transferencia de migración periódica, mantén esta sesión abierta indefinidamente. Si se interrumpe esta sesión, se producirá un error en las transferencias actuales y futuras.
Monitoriza periódicamente si el agente se está ejecutando. Si una transferencia está en curso y ningún agente responde en un plazo de 24 horas, la transferencia fallará.
Si el agente de migración deja de funcionar mientras la transferencia está en curso o programada, la consola muestra el estado de error y te pide que reinicies el agente. Google Cloud Para volver a iniciar el agente de migración, empieza de nuevo esta sección, ejecuta el agente de migración y usa el comando para ejecutar el agente de migración. No es necesario que repitas el comando de inicialización. La transferencia se reanuda en el punto en el que no se completaron las tablas.
- Prueba a hacer una migración de prueba de Teradata a BigQuery.
- Más información sobre BigQuery Data Transfer Service
- Migra código SQL con la traducción de SQL por lotes.
Definir los permisos necesarios
Asegúrate de que la entidad de seguridad que crea la transferencia tenga los siguientes roles en el proyecto que contiene la tarea de transferencia:
Crear conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tus datos. No es necesario que crees ninguna tabla.
Crea un segmento de Cloud Storage
Crea un segmento de Cloud Storage para almacenar provisionalmente los datos durante la tarea de transferencia.
Preparar el entorno local
Completa las tareas de esta sección para preparar tu entorno local para el trabajo de transferencia.
Requisitos del equipo local
Detalles de la conexión de Teradata
Descargar el controlador JDBC
Descarga el archivo del controlador JDBC de terajdbc4.jar de Teradata en una máquina que pueda conectarse al almacén de datos.
Definir la variable GOOGLE_APPLICATION_CREDENTIALS
Define la variable de entorno GOOGLE_APPLICATION_CREDENTIALS con la clave de la cuenta de servicio que has descargado en la sección Antes de empezar.
Actualizar la regla de salida de Controles de Servicio de VPC
Añade un proyecto gestionado de BigQuery Data Transfer Service (número de proyecto: 990232121269) a la regla de salida del perímetro de Controles de Servicio de VPC. Google Cloud
El canal de comunicación entre el agente que se ejecuta en las instalaciones y BigQuery Data Transfer Service se establece publicando mensajes de Pub/Sub en un tema por transferencia. BigQuery Data Transfer Service necesita enviar comandos al agente para extraer datos, y el agente necesita publicar mensajes en BigQuery Data Transfer Service para actualizar el estado y devolver respuestas de extracción de datos.
Crear un archivo de esquema personalizado
Para usar un archivo de esquema personalizado en lugar de la detección automática de esquemas, crea uno manualmente o pide al agente de migración que cree uno por ti cuando inicialices el agente.
Si creas un archivo de esquema manualmente y quieres usar la consola para crear una transferencia, sube el archivo de esquema a un segmento de Cloud Storage en el mismo proyecto que vayas a usar para la transferencia. Google Cloud
Descargar el agente de migración
Descarga el agente de migración en una máquina que pueda conectarse al almacén de datos. Mueve el archivo JAR del agente de migración al mismo directorio que el archivo JAR del controlador JDBC de Teradata.
Configurar el archivo de credenciales para el módulo de acceso
Se necesita un archivo de credenciales si utilizas el módulo de acceso para Cloud Storage con la utilidad Teradata Parallel Transporter (TPT) para la extracción.
Antes de crear un archivo de credenciales, debes crear una clave de cuenta de servicio. En el archivo de clave de cuenta de servicio que has descargado, obtén la siguiente información:
Cuando tengas la información necesaria, crea un archivo de credenciales. A continuación, se muestra un ejemplo de archivo de credenciales con una ubicación predeterminada de $HOME/.gcs/credentials:
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
Haz los cambios siguientes:
Configurar una transferencia
Crea una transferencia con BigQuery Data Transfer Service.
Si quieres que se cree automáticamente un archivo de esquema personalizado, usa el agente de migración para configurar la transferencia.
No puedes crear una transferencia bajo demanda con la herramienta de línea de comandos bq. En su lugar, debes usar la consola de Google Cloud o la API de BigQuery Data Transfer Service.
Si vas a crear una transferencia periódica, te recomendamos que especifiques un archivo de esquema para que los datos de las transferencias posteriores se puedan particionar correctamente cuando se carguen en BigQuery. Si no hay ningún archivo de esquema, BigQuery Data Transfer Service deduce el esquema de la tabla a partir de los datos de origen que se transfieren, y se pierde toda la información sobre las particiones, los clústeres, las claves principales y el seguimiento de cambios. Además, las transferencias posteriores omiten las tablas migradas anteriormente después de la transferencia inicial. Para obtener más información sobre cómo crear un archivo de esquema, consulta Archivo de esquema personalizado.
Consola
bq
Cuando creas una transferencia de Cloud Storage con la herramienta bq, la configuración de la transferencia se establece para que se repita cada 24 horas. Para las transferencias bajo demanda, usa la Google Cloud consola o la API de BigQuery Data Transfer Service.
No puedes configurar las notificaciones con la herramienta bq.
Introduce el comando
bq mk
y proporciona la marca de creación de transferencia
--transfer_config. También se necesitan las siguientes marcas:
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Donde:
Por ejemplo, el siguiente comando crea una transferencia de Teradata llamada My Transfer con el segmento de Cloud Storage mybucket y el conjunto de datos de destino mydataset. La transferencia migrará todas las tablas del almacén de datos de Teradata mydatabase y el archivo de esquema opcional es myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
Después de ejecutar el comando, recibirás un mensaje como el siguiente:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Sigue las instrucciones y pega el código de autenticación en la línea de comandos.
API
Usa el método projects.locations.transferConfigs.create y proporciona una instancia del recurso TransferConfig.
Java
Antes de probar este ejemplo, sigue las Javainstrucciones de configuración de la guía de inicio rápido de BigQuery con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Java de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación para bibliotecas de cliente.
Agente de migración
También puedes configurar la transferencia directamente desde el agente de migración. Para obtener más información, consulta Inicializar el agente de migración.
Inicializar el agente de migración
Debes inicializar el agente de migración para una nueva transferencia. La inicialización solo es necesaria una vez por transferencia, ya sea periódica o no. La inicialización solo configura el agente de migración, no inicia la transferencia.
Si vas a usar el agente de migración para crear un archivo de esquema personalizado, asegúrate de que tienes un directorio en el que se pueda escribir en tu directorio de trabajo con el mismo nombre que el proyecto que quieras usar para la transferencia. Aquí es donde el agente de migración crea el archivo de esquema.
Por ejemplo, si estás trabajando en /home y vas a configurar la transferencia en el proyecto myProject, crea el directorio /home/myProject y asegúrate de que los usuarios puedan escribir en él.
Archivo de configuración del agente de migración
El archivo de configuración creado en el paso de inicialización tiene un aspecto similar al de este ejemplo:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Opciones de tareas de transferencia en el archivo de configuración del agente de migración
Ejecutar el agente de migración
Después de inicializar el agente de migración y crear el archivo de configuración, sigue estos pasos para ejecutar el agente e iniciar la migración:
Hacer un seguimiento del progreso de la migración
Puede consultar el estado de la migración en la Google Cloud consola. También puedes configurar notificaciones de Pub/Sub o por correo electrónico. Consulta las notificaciones de BigQuery Data Transfer Service.
BigQuery Data Transfer Service programa e inicia una ejecución de transferencia según la programación especificada al crear la configuración de transferencia. Es importante que el agente de migración se esté ejecutando cuando una transferencia esté activa. Si no hay novedades por parte del agente en un plazo de 24 horas, la transferencia fallará.
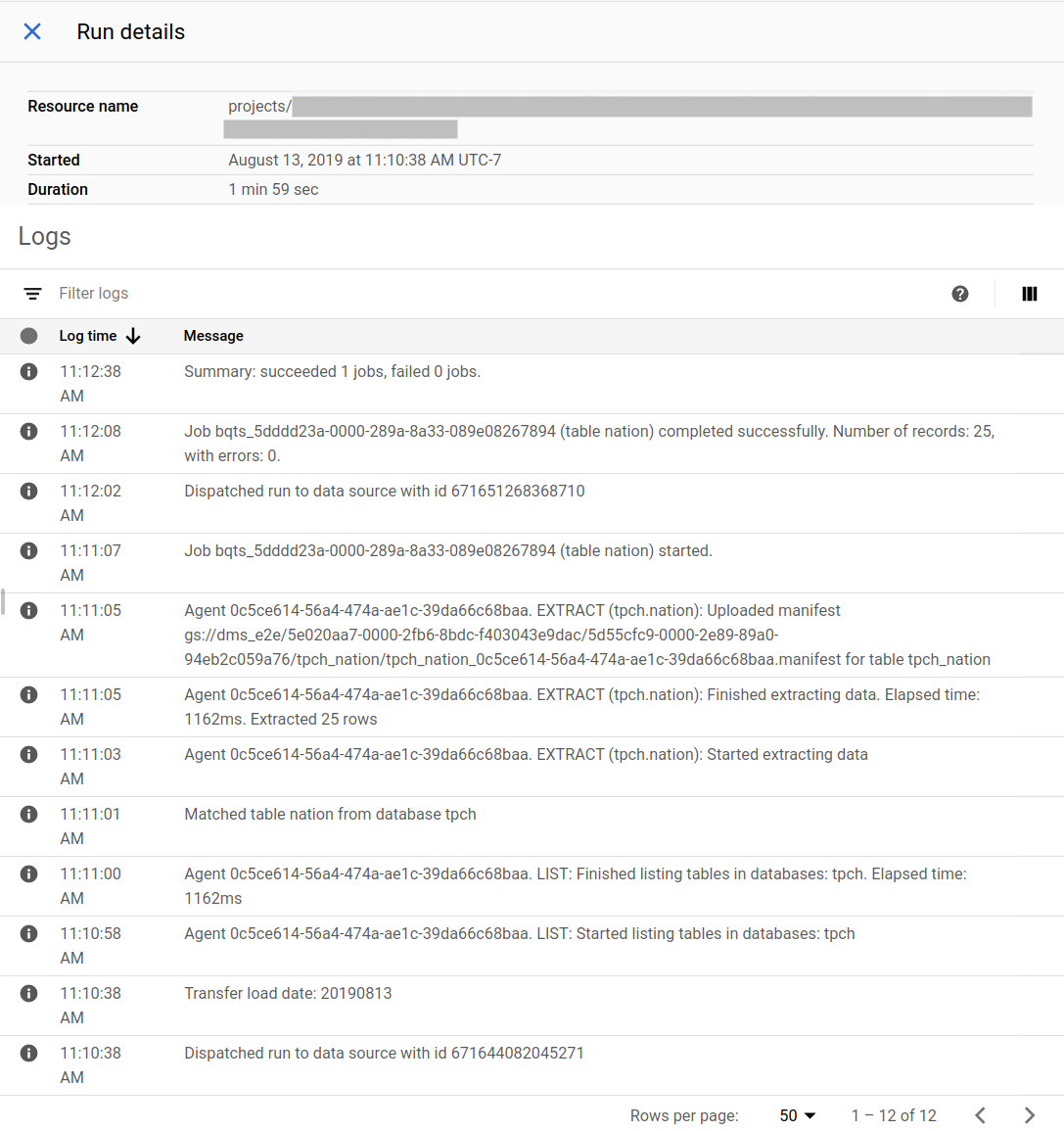
Ejemplo de estado de migración en la consola de Google Cloud :
Actualizar el agente de migración
Si hay una nueva versión del agente de migración disponible, debes actualizarlo manualmente. Para recibir avisos sobre BigQuery Data Transfer Service, suscríbete a las notas de la versión.