Anleitung zur Migration von Teradata zu BigQuery
In diesem Dokument wird beschrieben, wie Sie mithilfe von Beispieldaten von Teradata zu BigQuery migrieren. Es bietet ein Proof of Concept, das Sie durch die Übertragung von Schemas und Daten von einem Teradata Data Warehouse nach BigQuery führt.
Ziele
- Generieren Sie synthetische Daten und laden Sie sie in Teradata hoch.
- Migrieren Sie das Schema und die Daten mit dem BigQuery Data Transfer Service (BQDT) zu BigQuery.
- Stellen Sie sicher, dass Abfragen für Teradata und BigQuery dieselben Ergebnisse liefern.
Kosten
In dieser Kurzanleitung werden die folgenden kostenpflichtigen Komponenten von Google Cloudverwendet:
- BigQuery: Im Rahmen dieser Anleitung werden fast 1 GB Daten in BigQuery gespeichert und weniger als 2 GB für einmaliges Ausführen der Abfragen verarbeitet. Im Rahmen der kostenlosenGoogle Cloud -Stufe bietet BigQuery einige Ressourcen bis zu einem bestimmten Limit kostenlos an. Diese kostenlosen Nutzungskontingente sind während des Testzeitraums und auch danach verfügbar. Wenn Sie diese Nutzungskontingente überschreiten und der kostenlose Testzeitraum abgelaufen ist, fallen die auf der Seite BigQuery-Preise genannten Gebühren an.
Mit dem Preisrechner können Sie eine Kostenschätzung für die geplante Nutzung durchführen.
Vorbereitung
- Sorgen Sie dafür, dass Sie über Schreib- und Ausführungsberechtigungen auf einem Computer mit Internetzugang verfügen, damit Sie das Datengenerierungstool herunterladen und ausführen können.
- Sorgen Sie dafür, dass Sie eine Verbindung zu einer Teradata-Datenbank herstellen können.
Achten Sie darauf, dass auf dem Computer die Teradata-Clienttools BTEQ und FastLoad installiert sind. Sie können die Teradata-Clienttools von der Teradata-Website herunterladen. Wenn Sie Hilfe bei der Installation dieser Tools benötigen, wenden Sie sich an Ihren Systemadministrator, um Informationen zur Installation, Konfiguration und Ausführung der Tools zu erhalten. Alternativ oder zusätzlich zu BTEQ können Sie Folgendes tun:
- Installieren Sie ein Tool mit einer grafischen Oberfläche wie DBeaver.
- Installieren Sie den Teradata SQL-Treiber für Python zur Skripterstellung für Interaktionen mit der Teradata-Datenbank.
Der Computer muss eine Netzwerkverbindung zuGoogle Cloud haben, damit der BigQuery Data Transfer Service-Agent mit BigQuery kommunizieren und das Schema sowie die Daten übertragen kann.
Einführung
Diese Kurzanleitung führt Sie durch ein Proof of Concept zur Migration. Während des Schnellstarts generieren Sie synthetische Daten und laden sie in Teradata hoch. Anschließend verwenden Sie den BigQuery Data Transfer Service, um das Schema und die Daten in BigQuery zu verschieben. Schließlich führen Sie Abfragen auf beiden Seiten aus, um die Ergebnisse zu vergleichen. Der Endzustand ist, dass das Schema und die Daten von Teradata einzeln in BigQuery abgebildet werden.
Diese Kurzanleitung richtet sich an Data Warehouse-Administratoren, Entwickler und Datenexperten im Allgemeinen, die an praktischen Erfahrungen mit einem Schema und einer Datenmigration mittels BigQuery Data Transfer Service interessiert sind.
Daten generieren
Der Transaction Processing Performance Council (TPC) ist eine gemeinnützige Organisation, die Benchmarking-Spezifikationen veröffentlicht. Diese Spezifikationen sind tatsächlich Industriestandards für die Ausführung datenbezogener Benchmarks geworden.
Die TPC-H-Spezifikation ist eine Benchmark, die sich auf die Entscheidungsunterstützung konzentriert. In dieser Kurzanleitung werden Teile dieser Spezifikation verwendet, um Tabellen zu erstellen und synthetische Daten als Modell eines realen Data Warehouse zu generieren. Obwohl die Spezifikation für das Benchmarking erstellt wurde, wird das Modell in dieser Kurzanleitung als Teil des Proof of Concept zur Migration und nicht für Benchmarking-Aufgaben verwendet.
- Verwenden Sie auf dem Computer, auf dem Sie eine Verbindung zu Teradata herstellen möchten, einen Webbrowser, um die neueste verfügbare Version der TPC-H-Tools von der TPC-Website herunterzuladen.
- Öffnen Sie ein Befehlsterminal und wechseln Sie in das Verzeichnis, in das Sie die Tools heruntergeladen haben.
Extrahieren Sie die heruntergeladene ZIP-Datei. Ersetzen Sie file-name durch den Namen der heruntergeladenen Datei:
unzip file-name.zip
Ein Verzeichnis, dessen Name die Versionsnummer des Tools enthält, wird extrahiert. Dieses Verzeichnis enthält den TPC-Quellcode für das DBGEN-Datengenerierungstool und die TPC-H-Spezifikation selbst.
Wechseln Sie in das Unterverzeichnis
dbgen. Verwenden Sie, wie im folgenden Beispiel, den Namen des übergeordneten Verzeichnisses, der Ihrer Version entspricht:cd 2.18.0_rc2/dbgenErstellen Sie ein Makefile mit der mitgelieferten Vorlage:
cp makefile.suite makefileBearbeiten Sie das Makefile mit einem Texteditor. Verwenden Sie zum Beispiel vi, um die Datei zu bearbeiten:
vi makefileÄndern Sie im Makefile die Werte für die folgenden Variablen:
CC = gcc # TDAT -> TERADATA DATABASE = TDAT MACHINE = LINUX WORKLOAD = TPCHAbhängig von Ihrer Umgebung können die C Compiler (
CC)- oderMACHINE-Werte unterschiedlich sein. Fragen Sie gegebenenfalls Ihren Systemadministrator.Speichern Sie die Änderungen und schließen Sie die Datei.
Verarbeiten Sie das Makefile:
makeGenerieren Sie die TPC-H-Daten mit dem
dbgen-Tool:dbgen -vDie Datengenerierung dauert einige Minuten. Das Flag
-v(verbose) bewirkt, dass der Befehl den Fortschritt meldet. Nach Abschluss der Datengenerierung finden Sie im aktuellen Ordner 8 ASCII-Dateien mit der Erweiterung.tbl. Sie enthalten durch Pipes getrennte synthetische Daten, die in jede der TPC-H-Tabellen geladen werden sollen.
Beispieldaten in Teradata hochladen
In diesem Abschnitt laden Sie die generierten Daten in Ihre Teradata-Datenbank hoch.
TPC-H-Datenbank erstellen
Der Teradata-Client mit der Bezeichnung Basic Teradata Query (BTEQ) wird zur Kommunikation mit einem oder mehreren Teradata-Datenbankservern und zur Ausführung von SQL-Abfragen auf diesen Systemen verwendet. In diesem Abschnitt erstellen Sie mit BTEQ eine neue Datenbank für die TPC-H-Tabellen.
Öffnen Sie den Teradata BTEQ-Client:
bteqMelden Sie sich bei Teradata an. Ersetzen Sie teradata-ip und teradata-user durch die entsprechenden Werte für Ihre Umgebung.
.LOGON teradata-ip/teradata-user
Erstellen Sie eine Datenbank namens
tpchmit 2 GB zugewiesenem Speicherplatz:CREATE DATABASE tpch AS PERM=2e+09;Beenden Sie BTEQ:
.QUIT
Generierte Daten laden
In diesem Abschnitt erstellen Sie ein FastLoad-Skript zum Erstellen und Laden der Beispieltabellen. Die Tabellendefinitionen sind in Abschnitt 1.4 der TPC-H-Spezifikation beschrieben. Abschnitt 1.2 enthält ein Entity-Relationship-Modell des gesamten Datenbankschemas.
Der folgende Vorgang zeigt, wie Sie die Tabelle lineitem erstellen. Dies ist die größte und komplexeste der TPC-H-Tabellen. Nachdem Sie die Tabelle lineitem erstellt haben, wiederholen Sie diesen Vorgang für die übrigen Tabellen.
Erstellen Sie mit einem Texteditor eine neue Datei mit dem Namen
fastload_lineitem.fl:vi fastload_lineitem.flKopieren Sie das folgende Skript in die Datei. Damit wird eine Verbindung zur Teradata-Datenbank hergestellt und eine Tabelle mit dem Namen
lineitemerstellt.Ersetzen Sie im Befehl
logondie Variablen teradata-ip, teradata-user und teradata-pwd durch Ihre Verbindungsdetails.logon teradata-ip/teradata-user,teradata-pwd; drop table tpch.lineitem; drop table tpch.error_1; drop table tpch.error_2; CREATE multiset TABLE tpch.lineitem, NO FALLBACK, NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO ( L_ORDERKEY INTEGER NOT NULL, L_PARTKEY INTEGER NOT NULL, L_SUPPKEY INTEGER NOT NULL, L_LINENUMBER INTEGER NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_LINESTATUS CHAR(1) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_COMMITDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_RECEIPTDATE DATE FORMAT 'yyyy-mm-dd' NOT NULL, L_SHIPINSTRUCT CHAR(25) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_SHIPMODE CHAR(10) CHARACTER SET LATIN CASESPECIFIC NOT NULL, L_COMMENT VARCHAR(44) CHARACTER SET LATIN CASESPECIFIC NOT NULL) PRIMARY INDEX ( L_ORDERKEY ) PARTITION BY RANGE_N(L_COMMITDATE BETWEEN DATE '1992-01-01' AND DATE '1998-12-31' EACH INTERVAL '1' DAY);Das Skript stellt erst sicher, dass die Tabelle
lineitemund die temporären Fehlertabellen nicht vorhanden sind, und erstellt dann die Tabellelineitem.Fügen Sie in derselben Datei den folgenden Code ein, der die Daten in die neu erstellte Tabelle lädt. Füllen Sie alle Tabellenfelder in den Blöcken (
define,insertundvalues), aus und verwenden Sievarcharals Datentyp zum Laden.begin loading tpch.lineitem errorfiles tpch.error_1, tpch.error_2; set record vartext; define in_ORDERKEY(varchar(50)), in_PARTKEY(varchar(50)), in_SUPPKEY(varchar(50)), in_LINENUMBER(varchar(50)), in_QUANTITY(varchar(50)), in_EXTENDEDPRICE(varchar(50)), in_DISCOUNT(varchar(50)), in_TAX(varchar(50)), in_RETURNFLAG(varchar(50)), in_LINESTATUS(varchar(50)), in_SHIPDATE(varchar(50)), in_COMMITDATE(varchar(50)), in_RECEIPTDATE(varchar(50)), in_SHIPINSTRUCT(varchar(50)), in_SHIPMODE(varchar(50)), in_COMMENT(varchar(50)) file = lineitem.tbl; insert into tpch.lineitem ( L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER, L_QUANTITY, L_EXTENDEDPRICE, L_DISCOUNT, L_TAX, L_RETURNFLAG, L_LINESTATUS, L_SHIPDATE, L_COMMITDATE, L_RECEIPTDATE, L_SHIPINSTRUCT, L_SHIPMODE, L_COMMENT ) values ( :in_ORDERKEY, :in_PARTKEY, :in_SUPPKEY, :in_LINENUMBER, :in_QUANTITY, :in_EXTENDEDPRICE, :in_DISCOUNT, :in_TAX, :in_RETURNFLAG, :in_LINESTATUS, :in_SHIPDATE, :in_COMMITDATE, :in_RECEIPTDATE, :in_SHIPINSTRUCT, :in_SHIPMODE, :in_COMMENT ); end loading; logoff;
Das FastLoad-Skript lädt die Daten aus einer Datei
lineitem.tbl, die Sie im vorherigen Abschnitt generiert haben und sich im selben Verzeichnis befindet.Speichern Sie die Änderungen und schließen Sie die Datei.
Führen Sie das FastLoad-Skript aus:
fastload < fastload_lineitem.flWiederholen Sie diesen Vorgang für die restlichen TPC-H-Tabellen, die in Abschnitt 1.4 der TPC-H-Spezifikation aufgeführt sind. Sorgen Sie dafür, dass Sie die Schritte für jede Tabelle anpassen.
Schemas und Daten zu BigQuery migrieren
Die Anweisungen zum Migrieren des Schemas und der Daten zu BigQuery finden Sie in einer separaten Anleitung: Daten aus Teradata migrieren. In diesem Abschnitt erfahren Sie, wie Sie mit bestimmten Schritten dieser Kurzanleitung fortfahren. Wenn Sie die Schritte der Anleitung ausgeführt haben, kehren Sie zu diesem Dokument zurück und fahren mit dem nächsten Abschnitt Abfrageergebnisse überprüfen fort.
BigQuery-Dataset erstellen
Während der ersten Google Cloud Konfigurationsschritte werden Sie aufgefordert, ein Dataset in BigQuery zu erstellen, in dem die Tabellen nach der Migration gespeichert werden. Benennen Sie das Dataset tpch. Die Abfragen am Ende dieser Kurzanleitung gehen von diesem Namen aus und erfordern keine Änderung.
# Use the bq utility to create the dataset
bq mk --location=US tpch
Dienstkonto erstellen
Außerdem müssen Sie im Rahmen der Google Cloud -Konfigurationsschritte ein IAM-Dienstkonto (Identity and Access Management) erstellen. Dieses Dienstkonto wird verwendet, um die Daten in BigQuery zu schreiben und um temporäre Daten in Cloud Storage zu speichern.
# Set the PROJECT variable
export PROJECT=$(gcloud config get-value project)
# Create a service account
gcloud iam service-accounts create tpch-transfer
Gewähren Sie dem Dienstkonto Berechtigungen, mit denen BigQuery-Datasets und der Staging-Bereich in Cloud Storage verwaltet werden können:
# Set TPCH_SVC_ACCOUNT = service account email
export TPCH_SVC_ACCOUNT=tpch-transfer@${PROJECT}.iam.gserviceaccount.com
# Bind the service account to the BigQuery Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/bigquery.admin
# Bind the service account to the Storage Admin role
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${TPCH_SVC_ACCOUNT} \
--role roles/storage.admin
Staging-Bucket in Cloud Storage erstellen
Eine zusätzliche Aufgabe bei der Google Cloud -Konfiguration ist die Erstellung eines Cloud Storage-Bucket. Dieser Bucket wird vom BigQuery Data Transfer Service als Staging-Bereich für Datendateien verwendet, die in BigQuery aufgenommen werden sollen.
# Use gcloud storage to create the bucket
gcloud storage buckets create gs://${PROJECT}-tpch --location=us-central1
Tabellennamenmuster spezifizieren
Während der Konfiguration einer neuen Übertragung im BigQuery Data Transfer Service werden Sie aufgefordert, einen Ausdruck zu spezifizieren, der angibt, welche Tabellen übertragen werden sollen. In dieser Kurzanleitung werden alle Tabellen der tpch-Datenbank übertragen.
Das Format des Ausdrucks ist database.table und der Tabellenname kann durch einen Platzhalter ersetzt werden. Da Platzhalter in Java mit zwei Punkten beginnen, lautet der Ausdruck zur Übertragung aller Tabellen aus der tpch-Datenbank so:
tpch..*
Beachten Sie die zwei Punkte.
Abfrageergebnisse überprüfen
Sie haben bereits Beispieldaten erstellt, die Daten in Teradata hochgeladen und sie dann mit dem BigQuery Data Transfer Service in BigQuery migriert, wie es in der separaten Anleitung beschrieben wird. In diesem Abschnitt führen Sie zwei der TPC-H-Standardabfragen aus, um sicherzustellen, dass die Ergebnisse in Teradata und BigQuery identisch sind.
Abfrage für den Preiszusammenfassungsbericht ausführen
Die erste Abfrage ist die Abfrage für den Preiszusammenfassungsbericht (Abschnitt 2.4.1 der TPC-H-Spezifikation). Diese Abfrage gibt die Anzahl der Artikel an, die ab einem bestimmten Datum in Rechnung gestellt, versendet und zurückgesandt wurden.
Die folgende Auflistung zeigt die vollständige Abfrage:
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice*(1-l_discount)) AS sum_disc_price,
SUM(l_extendedprice*(1-l_discount)*(1+l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM tpch.lineitem
WHERE l_shipdate BETWEEN '1996-01-01' AND '1996-01-10'
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
Führen Sie die Abfrage in Teradata aus:
- Führen Sie BTEQ aus und stellen Sie eine Verbindung zu Teradata her. Weitere Informationen finden Sie weiter oben in diesem Dokument unter TPC-H-Datenbank erstellen.
Ändern Sie die Anzeigebreite der Ausgabe auf 500 Zeichen:
.set width 500Kopieren Sie die Abfrage und fügen Sie sie in die BTEQ-Eingabeaufforderung ein.
Das Ergebnis sieht ungefähr so aus:
L_RETURNFLAG L_LINESTATUS sum_qty sum_base_price sum_disc_price sum_charge avg_qty avg_price avg_disc count_order ------------ ------------ ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------------- ----------- N O 629900.00 943154565.63 896323924.4600 932337245.114003 25.45 38113.41 .05 24746
Führen Sie dieselbe Abfrage in BigQuery aus:
Wechseln Sie zur BigQuery-Konsole:
Kopieren Sie die Abfrage in den Abfrageeditor.
Sorgen Sie dafür, dass der Datasetname in der
FROM-Zeile korrekt ist.Klicken Sie auf Ausführen.
Das Ergebnis ist dasselbe wie das Ergebnis von Teradata.
Optional können Sie größere Zeitintervalle in der Abfrage auswählen, um sicherzugehen, dass alle Zeilen in der Tabelle gescannt werden.
Abfrage für das lokale Lieferantenvolumen ausführen
Die zweite Beispielabfrage ist der Abfragebericht für das lokale Lieferantenvolumen (Abschnitt 2.4.5 der TPC-H-Spezifikation). Diese Abfrage gibt den Umsatz für jede Nation einer Region an, der durch jede Position erzielt wurde, in der sich der Kunde und der Lieferant dieser Nation befanden. Diese Ergebnisse sind nützlich, um beispielsweise zu planen, wo Verteilungszentren platziert werden sollen.
Die folgende Auflistung zeigt die vollständige Abfrage:
SELECT
n_name AS nation,
SUM(l_extendedprice * (1 - l_discount) / 1000) AS revenue
FROM
tpch.customer,
tpch.orders,
tpch.lineitem,
tpch.supplier,
tpch.nation,
tpch.region
WHERE c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND l_suppkey = s_suppkey
AND c_nationkey = s_nationkey
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND o_orderdate >= '1996-01-01'
AND o_orderdate < '1997-01-01'
GROUP BY
n_name
ORDER BY
revenue DESC;
Führen Sie die Abfrage wie im vorherigen Abschnitt beschrieben in Teradata BTEQ und in der BigQuery-Konsole aus.
Das ist das Ergebnis von Teradata:
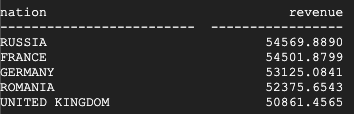
Das ist das Ergebnis von BigQuery:
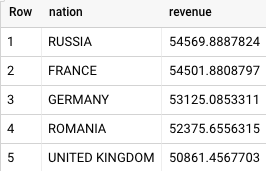
Sowohl Teradata als auch BigQuery kommen zu denselben Ergebnissen.
Produkttyp-Profit-Measure-Abfrage ausführen
Der letzte Test zur Überprüfung der Migration ist die Abfrage des letzten Beispiels für die Produkttyp-Measure-Abfrage (Abschnitt 2.4.9 der TPC-H-Spezifikation). Diese Abfrage ermittelt für jede Nation und jedes Jahr den Gewinn für alle in diesem Jahr bestellten Teile. Die Ergebnisse werden nach einer Teilzeichenfolge in den Teilenamen und nach einem bestimmten Lieferanten gefiltert.
Die folgende Auflistung zeigt die vollständige Abfrage:
SELECT
nation,
o_year,
SUM(amount) AS sum_profit
FROM (
SELECT
n_name AS nation,
EXTRACT(YEAR FROM o_orderdate) AS o_year,
(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity)/1e+3 AS amount
FROM
tpch.part,
tpch.supplier,
tpch.lineitem,
tpch.partsupp,
tpch.orders,
tpch.nation
WHERE s_suppkey = l_suppkey
AND ps_suppkey = l_suppkey
AND ps_partkey = l_partkey
AND p_partkey = l_partkey
AND o_orderkey = l_orderkey
AND s_nationkey = n_nationkey
AND p_name like '%blue%' ) AS profit
GROUP BY
nation,
o_year
ORDER BY
nation,
o_year DESC;
Führen Sie die Abfrage wie im vorherigen Abschnitt beschrieben in Teradata BTEQ und in der BigQuery-Konsole aus.
Das ist das Ergebnis von Teradata:
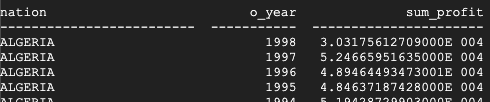
Das ist das Ergebnis von BigQuery:
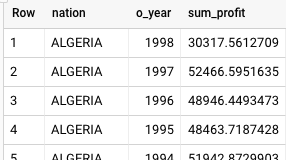
Sowohl Teradata als auch BigQuery kommen zu denselben Ergebnissen, obwohl Teradata für die Summe die wissenschaftliche Schreibweise verwendet.
Zusätzliche Abfragen
Optional können Sie die restlichen TPC-H-Abfragen ausführen, die in Abschnitt 2.4 der TPC-H-Spezifikation definiert sind.
Sie können auch Abfragen gemäß dem TPC-H-Standard mit dem QGEN-Tool generieren, das sich im selben Verzeichnis wie das DBGEN-Tool befindet. QGEN wird mit demselben Makefile wie DBGEN erstellt. Wenn Sie also Make zum Kompilieren von dbgen ausführen, generieren Sie auch die ausführbare Datei qgen.
Weitere Informationen zu beiden Tools und ihren Befehlszeilenoptionen finden Sie in der jeweiligen README-Datei der Tools.
Bereinigen
Entfernen Sie die in dieser Anleitung verwendeten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud Konto dafür Gebühren berechnet werden.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten, wenn Sie das für die Anleitung erstellte Projekt löschen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Schritt-für-Schritt-Anleitung zum Migrieren von Teradata zu BigQuery ansehen