Migração do Snowflake para o BigQuery: visão geral
Neste documento, mostramos como migrar seus dados do Snowflake para o BigQuery.
Para um framework geral de migração de outros data warehouses para o BigQuery, consulte Visão geral: migrar data warehouses para o BigQuery.
Visão geral da migração do Snowflake para o BigQuery
Para uma migração do Snowflake, recomendamos configurar uma arquitetura de migração que afete minimamente as operações atuais. O exemplo a seguir mostra uma arquitetura em que é possível reutilizar ferramentas e processos atuais enquanto descarrega outras cargas de trabalho no BigQuery.
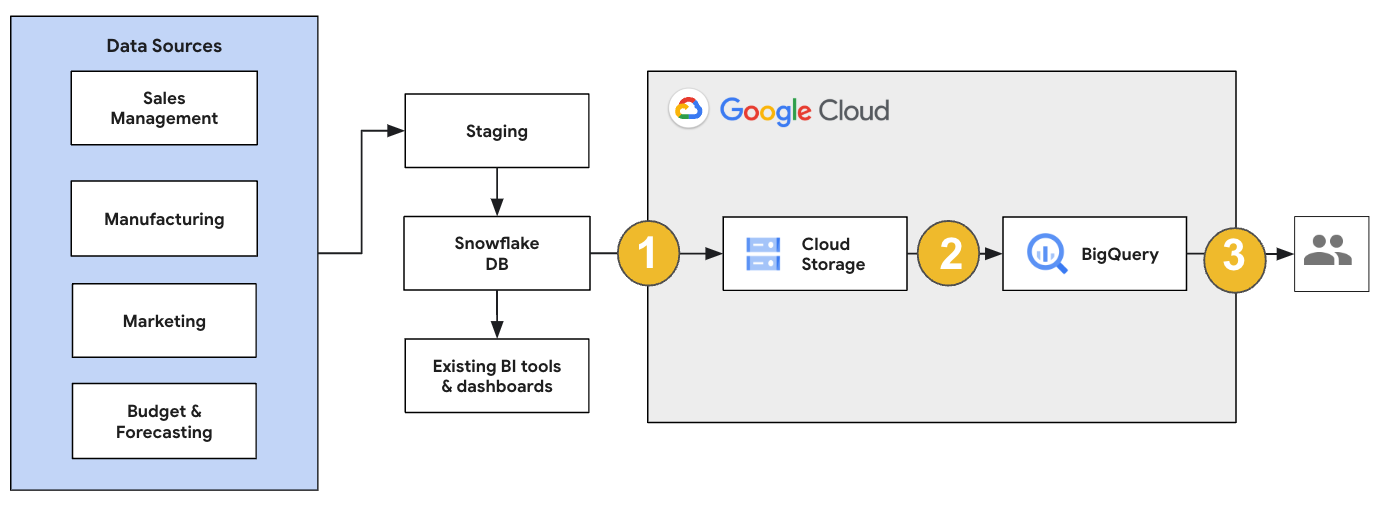
Também é possível validar relatórios e painéis em relação a versões anteriores. Para mais informações, consulte Como migrar armazenamentos de dados para o BigQuery: verificar e validar.
Migrar cargas de trabalho individuais
Ao planejar a migração do Snowflake, recomendamos migrar as seguintes cargas de trabalho individualmente na ordem a seguir:
Migrar esquema
Comece replicando os esquemas necessários do seu ambiente do Snowflake para o BigQuery. Recomendamos usar o BigQuery Migration Service para migrar seu esquema. O serviço de migração do BigQuery é compatível com uma ampla variedade de padrões de design de modelo de dados, como esquema em estrela ou esquema em floco de neve, o que elimina a necessidade de atualizar seus pipelines de dados upstream para um novo esquema. O serviço de migração do BigQuery também oferece migração de esquema automatizada, incluindo recursos de extração e tradução de esquema, para simplificar o processo de migração.
Migrar consultas SQL
Para migrar suas consultas SQL, o serviço de migração do BigQuery oferece vários recursos de tradução de SQL para automatizar a conversão das consultas SQL do Snowflake para o GoogleSQL, como o tradutor de SQL em lote para traduzir consultas em massa, o tradutor de SQL interativo para traduzir consultas individuais e a API de tradução de SQL. Esses serviços também incluem a funcionalidade aprimorada do Gemini para simplificar ainda mais o processo de migração de consulta SQL.
Ao traduzir suas consultas SQL, revise com cuidado as consultas traduzidas para verificar se os tipos de dados e as estruturas de tabela estão sendo processados corretamente. Para isso, recomendamos criar uma ampla variedade de casos de teste com diferentes cenários e dados. Em seguida, execute esses casos de teste no BigQuery para comparar os resultados com os originais do Snowflake. Se houver diferenças, analise e corrija as consultas convertidas.
Migrar dados
Há várias maneiras de configurar seu pipeline de migração de dados para transferir dados para o BigQuery. Em geral, esses pipelines seguem o mesmo padrão:
Extrair os dados da origem: copie os arquivos extraídos da origem para o armazenamento de preparo no ambiente local. Para mais informações, consulte Como migrar armazenamentos de dados para o BigQuery: como extrair os dados de origem.
Transferir dados para um bucket temporário do Cloud Storage: depois de extrair dados da origem, transfira-os para um bucket temporário no Cloud Storage. Dependendo da quantidade de dados a ser transferida e da largura de banda da rede disponível, você tem várias opções.
É importante verificar se o local do conjunto de dados do BigQuery e sua fonte de dados externa ou seu bucket do Cloud Storage estão na mesma região.
Carregar dados do bucket do Cloud Storage no BigQuery:os dados agora estão em um bucket do Cloud Storage. Há várias opções para fazer o upload dos dados no BigQuery. Essas opções dependem de quanto os dados precisam ser transformados. Outra possibilidade é transformar seus dados no BigQuery seguindo a abordagem de ELT.
Quando você importa dados em massa de um arquivo JSON, Avro ou CSV, o BigQuery detecta o esquema automaticamente. Portanto, não é necessário predefini-lo. Para uma visão geral detalhada do processo de migração de esquema para cargas de trabalho de EDW, consulte Processo de migração de esquema e dados.
Para uma lista de ferramentas que oferecem suporte a uma migração de dados do Snowflake, consulte Ferramentas de migração.
Para exemplos completos de como configurar um pipeline de migração de dados do Snowflake, consulte Exemplos de pipeline de migração do Snowflake.
Otimizar esquema e consultas
Após a migração do esquema, é possível testar o desempenho e fazer otimizações com base nos resultados. Por exemplo, é possível introduzir o particionamento para tornar os dados mais eficientes para gerenciar e consultar. O particionamento de tabelas permite melhorar o desempenho da consulta e o controle de custos por particionamento por tempo de ingestão, carimbo de data/hora ou intervalo de números inteiros. Para mais informações, consulte Introdução às tabelas particionadas.
As tabelas em cluster são outra otimização de esquema. É possível agrupar as tabelas para organizar os dados com base no conteúdo do esquema, melhorando o desempenho das consultas que usam cláusulas de filtro ou agregam dados. Para mais informações, consulte Introdução às tabelas em cluster.
Tipos de dados, propriedades e formatos de arquivo suportados
O Snowflake e o BigQuery são compatíveis com a maioria dos mesmos tipos de dados, embora às vezes usem nomes diferentes. Para uma lista completa dos tipos de dados aceitos no Snowflake e no BigQuery, consulte Tipos de dados. Você também pode usar ferramentas de tradução de SQL, como o tradutor de SQL interativo, a API de tradução de SQL ou o tradutor de SQL em lote, para traduzir diferentes dialetos de SQL para o GoogleSQL.
Para mais informações sobre os tipos de dados compatíveis com o BigQuery, consulte Tipos de dados do GoogleSQL.
O Snowflake pode exportar dados nos seguintes formatos de arquivo. É possível carregar os seguintes formatos diretamente no BigQuery:
- Como carregar dados CSV do Cloud Storage.
- Como carregar dados Parquet do Cloud Storage.
- Como carregar dados JSON do Cloud Storage.
- Consultar dados do Apache Iceberg.
Ferramentas de migração
Na lista a seguir, descrevemos as ferramentas que podem ser usadas para migrar dados do Snowflake para o BigQuery. Para exemplos de como essas ferramentas podem ser usadas juntas em um pipeline de migração do Snowflake, consulte Exemplos de pipeline de migração do Snowflake.
- Comando
COPY INTO <location>:use esse comando no Snowflake para extrair dados de uma tabela do Snowflake diretamente para um bucket especificado do Cloud Storage. Para ver um exemplo completo, consulte Snowflake para o BigQuery (snowflake2bq) no GitHub. - Apache Sqoop: para extrair dados do Snowflake para o HDFS ou o Cloud Storage, envie jobs do Hadoop com o driver JDBC do Sqoop e do Snowflake. O Sqoop é executado em um ambiente Dataproc.
- JDBC do Snowflake: use esse driver com a maioria das ferramentas ou aplicativos cliente que suportam JDBC.
Você pode usar as seguintes ferramentas genéricas para migrar dados do Snowflake para o BigQuery:
- Conector do serviço de transferência de dados do BigQuery para Snowflake Prévia: execute uma transferência automatizada em lote dos dados do Cloud Storage para o BigQuery.
- A CLI do Google Cloud: copie os arquivos do Snowflake transferidos por download para o Cloud Storage com essa ferramenta de linha de comando.
- Ferramenta de linha de comando bq:interaja com o BigQuery usando essa ferramenta. Os casos de uso comuns incluem a criação de esquemas de tabelas do BigQuery, o carregamento de dados do Cloud Storage em tabelas e a execução de consultas.
- Bibliotecas de cliente do Cloud Storage: copie os arquivos do Snowflake transferidos por download para o Cloud Storage com uma ferramenta personalizada que usa as bibliotecas de cliente do Cloud Storage.
- Bibliotecas de cliente do BigQuery: interaja com o BigQuery com uma ferramenta personalizada criada sobre a biblioteca de cliente do BigQuery.
- Programador de consultas do BigQuery:programe consultas SQL recorrentes com esse recurso integrado do BigQuery.
- Cloud Composer: use esse ambiente Apache Airflow totalmente gerenciado para orquestrar transformações e jobs de carregamento do BigQuery.
Para mais informações sobre como carregar dados no BigQuery, consulte Como carregar dados no BigQuery.
Exemplos de pipeline de migração do Snowflake
As seções a seguir mostram exemplos de como migrar seus dados do Snowflake para o BigQuery usando três processos diferentes: ELT, ETL e ferramentas de parceiros.
Extração, carregamento e transformação
É possível configurar um processo de extração, carregamento e transformação (ELT) com dois métodos:
- Usar um pipeline para extrair dados do Snowflake e carregá-los no BigQuery
- Extraia dados do Snowflake usando outros produtos Google Cloud .
Usar um pipeline para extrair dados do Snowflake
Para extrair dados do Snowflake e carregar diretamente no Cloud Storage, use a ferramenta snowflake2bq.
Em seguida, carregue os dados do Cloud Storage para o BigQuery usando uma das seguintes ferramentas:
- O conector do serviço de transferência de dados do BigQuery para o Cloud Storage
- O comando
LOADusando a ferramenta de linha de comando bq - Bibliotecas de cliente da API BigQuery
Outras ferramentas para extrair dados do Snowflake
Você também pode usar as seguintes ferramentas para extrair dados do Snowflake:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Conector do Apache Spark no BigQuery
- Conector do Snowflake para Apache Spark
- Conector do Hadoop do BigQuery
- O driver JDBC do Snowflake e do Sqoop para extrair dados do Snowflake para o Cloud Storage:
Outras ferramentas para carregar dados no BigQuery
Também é possível usar as seguintes ferramentas para carregar dados no BigQuery:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
Extrair, transformar e carregar
Se você quiser transformar os dados antes de carregá-los no BigQuery, considere as seguintes ferramentas:
- Dataflow
- Clone o código do modelo JDBC para BigQuery e modifique o modelo para adicionar transformações do Apache Beam.
- Cloud Data Fusion
- Crie um pipeline reutilizável e transforme seus dados usando plug-ins do CDAP.
- Dataproc
- Transforme os dados usando o Spark SQL ou um código personalizado em qualquer uma das linguagens Spark compatíveis, como Scala, Java, Python ou R.
Ferramentas de parceiros para migração
Há vários fornecedores especializados no espaço de migração de EDW. Para ver uma lista dos principais parceiros e das soluções que eles oferecem, consulte Parceiros do BigQuery.
Tutorial de exportação do Snowflake
O tutorial a seguir mostra um exemplo de exportação de dados do Snowflake para
o BigQuery que usa o comando COPY INTO <location> do Snowflake.
Para um processo passo a passo detalhado que inclua exemplos de código, consulte
a ferramenta de serviços profissionais do Snowflake para BigQuery.Google Cloud
Preparar para exportação
Para preparar os dados do Snowflake para uma exportação, extraia-os para um bucket do Cloud Storage ou do Amazon Simple Storage Service (Amazon S3) seguindo estas etapas:
Cloud Storage
Este tutorial prepara o arquivo no formato PARQUET.
Use instruções SQL do Snowflake para criar uma especificação de formato de arquivo nomeada.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Substitua
NAMED_FILE_FORMATpor um nome para o formato de arquivo. Por exemplo,my_parquet_unload_format.Crie uma integração com o comando
CREATE STORAGE INTEGRATION.create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Substitua:
INTEGRATION_NAME: um nome para a integração de armazenamento. Por exemplo,gcs_intBUCKET_NAME: o caminho para o bucket do Cloud Storage. Por exemplo,gcs://mybucket/extract/
Recupere a conta de serviço do Cloud Storage para o Snowflake com o comando
DESCRIBE INTEGRATION.desc storage integration INTEGRATION_NAME;
O resultado será assim:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Conceda à conta de serviço listada como
STORAGE_GCP_SERVICE_ACCOUNTacesso de leitura e gravação ao bucket especificado no comando de integração do armazenamento. Neste exemplo, conceda à conta de serviçoservice-account-id@acesso de leitura e gravação ao bucket<var>UNLOAD_BUCKET</var>.Crie um estágio externo do Cloud Storage que faça referência à integração criada anteriormente.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Substitua:
STAGE_NAME: um nome para o objeto de estágio do Cloud Storage. Por exemplo,my_ext_unload_stage
Amazon S3
O exemplo a seguir mostra como mover dados de uma tabela do Snowflake para um bucket do Amazon S3:
No Snowflake, configure um objeto de integração de armazenamento para permitir que o Snowflake grave em um bucket do Amazon S3 referenciado em um estágio externo do Cloud Storage.
Nesta etapa, é necessário configurar permissões de acesso no bucket do Amazon S3, criar o papel do IAM da Amazon Web Services (AWS) e criar uma integração de armazenamento no Snowflake com o comando
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Substitua:
INTEGRATION_NAME: um nome para a integração de armazenamento. Por exemplo,s3_intBUCKET_NAME: o caminho para o bucket do Amazon S3 em que os arquivos serão carregados. Por exemplo,s3://unload/files/
Recupere o usuário do IAM da AWS com o comando
DESCRIBE INTEGRATIONdesc integration INTEGRATION_NAME;
O resultado será assim:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Crie uma função com o privilégio
CREATE STAGEpara o esquema e o privilégioUSAGEpara a integração de armazenamento:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Substitua
ROLE_NAMEpor um nome para a função. Por exemplo,myrole.Conceda as permissões de usuário do IAM da AWS para acessar o bucket do Amazon S3 e crie um estágio externo com o comando
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Substitua:
STAGE_NAME: um nome para o objeto de estágio do Cloud Storage. Por exemplo,my_ext_unload_stage
Exportar dados do Snowflake
Depois de preparar os dados, você pode movê-los para Google Cloud.
Use o comando COPY INTO para copiar dados da tabela do banco de dados do Snowflake para um bucket do Cloud Storage ou do Amazon S3 especificando o objeto de estágio externo, STAGE_NAME.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Substitua TABLE_NAME pelo nome da tabela do banco de dados do Snowflake.
Como resultado desse comando, os dados da tabela são copiados para o objeto de estágio, que está vinculado ao bucket do Cloud Storage ou do Amazon S3. O arquivo inclui o prefixo d1.
Outros métodos de exportação
Para usar o Azure Blob Storage nas exportações de dados, siga as etapas detalhadas em Como descarregar no Microsoft Azure. Em seguida, transfira os arquivos exportados para o Cloud Storage usando o Serviço de transferência do Cloud Storage.
Preços
Ao planejar a migração do Snowflake, considere o custo de transferir e armazenar dados e usar serviços no BigQuery. Para mais informações, consulte Preços.
Pode haver custos de saída para mover dados do Snowflake ou da AWS. Também pode haver custos adicionais ao transferir dados entre regiões ou entre diferentes provedores de nuvem.