Migrasi Amazon Redshift ke BigQuery: Ringkasan
Dokumen ini memberikan panduan tentang migrasi dari Amazon Redshift ke BigQuery, yang berfokus pada topik berikut:
- Strategi untuk migrasi
- Praktik terbaik untuk pengoptimalan kueri dan pemodelan data
- Tips pemecahan masalah
- Panduan adopsi pengguna
Tujuan dokumen ini adalah sebagai berikut:
- Memberikan panduan tingkat tinggi untuk organisasi yang bermigrasi dari Amazon Redshift ke BigQuery, termasuk membantu Anda memikirkan kembali pipeline data yang ada untuk mendapatkan hasil maksimal dari BigQuery.
- Membantu Anda membandingkan arsitektur BigQuery dan Amazon Redshift sehingga Anda dapat menentukan cara menerapkan fitur dan kemampuan yang ada selama migrasi. Tujuannya adalah menunjukkan kemampuan baru yang tersedia untuk organisasi Anda melalui BigQuery, bukan untuk memetakan fitur satu per satu dengan Amazon Redshift.
Dokumen ini ditujukan untuk arsitek perusahaan, administrator database, developer aplikasi, dan spesialis keamanan IT. Anda dianggap sudah familier dengan Amazon Redshift.
Anda juga dapat menggunakan batch terjemahan SQL untuk memigrasikan skrip SQL secara massal, atau terjemahan SQL interaktif untuk menerjemahkan kueri ad hoc singkat ini. Amazon Redshift SQL sepenuhnya didukung oleh kedua layanan terjemahan SQL.
Tugas pramigrasi
Untuk membantu memastikan keberhasilan migrasi data warehouse, mulailah merencanakan strategi migrasi lebih awal dari linimasa project Anda. Dengan pendekatan ini, Anda dapat mengevaluasi fitur Google Cloud yang sesuai dengan kebutuhan Anda.
Perencanaan kapasitas
BigQuery menggunakan slot untuk mengukur throughput analisis. Slot BigQuery adalah unit milik Google untuk kapasitas komputasi yang diperlukan untuk menjalankan kueri SQL. BigQuery terus menghitung jumlah slot yang diperlukan oleh kueri saat kueri dijalankan, tetapi BigQuery mengalokasikan slot ke kueri berdasarkan fair scheduler.
Anda dapat memilih di antara model harga berikut saat perencanaan kapasitas untuk slot BigQuery:
- Harga sesuai permintaan: Dengan harga sesuai permintaan, BigQuery mengenakan biaya untuk jumlah byte yang diproses (ukuran data), sehingga Anda hanya membayar untuk kueri yang dijalankan. Untuk mengetahui informasi lebih lanjut tentang cara BigQuery menentukan ukuran data, baca Penghitungan ukuran data. Karena slot menentukan kapasitas komputasi yang mendasarinya, Anda dapat membayar penggunaan BigQuery, bergantung pada jumlah slot yang Anda butuhkan (bukan byte yang diproses). Secara default, semua projectGoogle Cloud dibatasi maksimum 2.000 slot. BigQuery mungkin melampaui batas ini untuk mempercepat kueri Anda, tetapi bursting tidak dijamin.
- Harga berdasarkan kapasitas : Dengan harga berdasarkan kapasitas, Anda membeli slot pemesanan BigQuery (minimal 100) dan bukan membayar byte yang diproses oleh kueri yang Anda jalankan. Kami merekomendasikan harga berdasarkan kapasitas untuk workload data warehouse perusahaan, yang umumnya mengalami banyak kueri pelaporan serentak dan ekstrak, transformasi, pemuatan (ELT) dengan penggunaan yang dapat diprediksi.
Untuk membantu estimasi slot, sebaiknya siapkan pemantauan BigQuery menggunakan Cloud Monitoring dan analisis log audit Anda menggunakan BigQuery. Anda dapat menggunakan Looker Studio (berikut adalah contoh open source dasbor Looker Studio) atau Looker untuk memvisualisasikan data log audit BigQuery, khususnya untuk penggunaan slot di seluruh kueri dan project. Anda juga dapat menggunakan data tabel sistem BigQuery untuk memantau pemanfaatan slot di berbagai tugas dan pemesanan (berikut adalah contoh open source dasbor Looker Studio). Memantau dan menganalisis penggunaan slot secara rutin membantu Anda memperkirakan jumlah total slot yang dibutuhkan organisasi saat Anda berkembang di Google Cloud.
Misalnya, anggaplah Anda awalnya mencadangkan 4.000 slot BigQuery untuk menjalankan 100 kueri dengan kompleksitas sedang secara bersamaan. Jika Anda melihat waktu tunggu yang tinggi dalam rencana eksekusi kueri, dan dasbor Anda menunjukkan penggunaan slot yang tinggi, hal ini dapat menunjukkan bahwa Anda memerlukan slot BigQuery tambahan untuk membantu mendukung workload. Jika Anda ingin membeli slot sendiri melalui komitmen tahunan atau tiga tahun, Anda dapat memulai pemesanan BigQuery menggunakan konsolGoogle Cloud atau alat command line bq. Untuk mengetahui detail selengkapnya tentang pengelolaan workload, eksekusi kueri, dan arsitektur BigQuery, lihat Migrasi ke Google Cloud: Tampilan mendalam.
Keamanan di Google Cloud
Bagian berikut menjelaskan kontrol keamanan umum Amazon Redshift dan cara membantu memastikan bahwa data warehouse Anda tetap terlindungi di lingkungan Google Cloud .
Pengelolaan akses dan identitas
Menyiapkan kontrol akses di Amazon Redshift melibatkan penulisan kebijakan izin Amazon Redshift API dan melampirkannya ke identitas Identity and Access Management (IAM). Izin Amazon Redshift API menyediakan akses tingkat cluster, tetapi tidak memberikan tingkat akses yang lebih terperinci daripada cluster. Jika ingin akses yang lebih terperinci ke resource seperti tabel atau tampilan, Anda dapat menggunakan akun pengguna di database Amazon Redshift.
BigQuery menggunakan IAM untuk mengelola akses ke resource pada tingkat yang lebih terperinci. Jenis resource yang tersedia di BigQuery adalah organisasi, project, set data, tabel, kolom, dan tampilan. Dalam hierarki kebijakan IAM, set data adalah resource turunan dari project. Tabel mewarisi izin dari set data yang berisi tabel tersebut.
Untuk memberikan akses ke resource, tetapkan satu atau beberapa peran IAM ke pengguna, grup, atau akun layanan. Peran organisasi dan project memengaruhi kemampuan untuk menjalankan tugas atau mengelola project, sedangkan peran set data memengaruhi kemampuan untuk mengakses atau memodifikasi data di dalam project.
IAM menyediakan jenis peran berikut:
- Peran yang telah ditetapkan, yang dimaksudkan untuk mendukung kasus penggunaan umum dan pola kontrol akses.
- Peran khusus, yang memberikan akses terperinci sesuai dengan daftar izin yang ditentukan pengguna.
Dalam IAM, BigQuery menyediakan kontrol akses tingkat tabel. Izin tingkat tabel menentukan pengguna, grup, dan akun layanan yang dapat mengakses tabel atau tampilan. Anda dapat memberi pengguna akses ke tabel atau tampilan tertentu tanpa memberi pengguna akses ke set data lengkap. Untuk akses yang lebih terperinci, Anda juga dapat mencoba menerapkan satu atau beberapa mekanisme keamanan berikut:
- Kontrol akses tingkat kolom, yang memberikan akses terperinci ke kolom sensitif menggunakan tag kebijakan, atau klasifikasi data berbasis jenis.
- Penyamaran data dinamis tingkat kolom, yang memungkinkan Anda menyamarkan data kolom secara selektif untuk sekelompok pengguna, sekaligus tetap mengizinkan akses ke kolom tersebut.
- Keamanan tingkat baris, yang memungkinkan Anda memfilter data dan mengaktifkan akses ke baris tertentu dalam tabel berdasarkan kondisi pengguna yang memenuhi syarat.
Enkripsi disk penuh
Selain pengelolaan akses dan identitas, enkripsi data menambahkan lapisan pertahanan ekstra untuk melindungi data. Dalam kasus eksposur data, data yang dienkripsi tidak dapat dibaca.
Di Amazon Redshift, enkripsi untuk data dalam penyimpanan dan data dalam pengiriman tidak diaktifkan secara default. Enkripsi untuk data dalam penyimpanan harus diaktifkan secara eksplisit saat cluster diluncurkan atau dengan mengubah cluster yang ada untuk menggunakan enkripsi AWS Key Management Service. Enkripsi untuk data dalam pengiriman juga harus diaktifkan secara eksplisit.
BigQuery secara default mengenkripsi semua data dalam penyimpanan dan dalam pengiriman, terlepas dari sumbernya atau kondisi lainnya, dan ini tidak dapat dimatikan. BigQuery juga mendukung kunci enkripsi yang dikelola pelanggan (CMEK) jika Anda ingin mengontrol dan mengelola kunci enkripsi kunci di Cloud Key Management Service.
Untuk mengetahui informasi selengkapnya tentang enkripsi di Google Cloud, lihat laporan resmi tentang enkripsi data dalam penyimpanan dan enkripsi data dalam transit.
Untuk data dalam pengiriman di Google Cloud, data dienkripsi dan diautentikasi saat data dipindahkan ke luar batas fisik yang dikontrol oleh Google atau atas nama Google. Di dalam batas ini, data dalam pengiriman umumnya diautentikasi, tetapi tidak harus dienkripsi.
Pencegahan kebocoran data
Persyaratan kepatuhan dapat membatasi data yang dapat disimpan di Google Cloud. Anda dapat menggunakan Perlindungan Data Sensitif untuk memindai tabel BigQuery guna mendeteksi dan mengklasifikasikan data sensitif. Jika data sensitif terdeteksi, transformasi de-identifikasi Sensitive Data Protection dapat menyamarkan, menghapus, atau mengaburkan data tersebut.
Migrasi ke Google Cloud: Dasar-dasar
Gunakan bagian ini untuk mempelajari lebih lanjut cara menggunakan alat dan pipeline untuk membantu migrasi.
Solusi migrasi
BigQuery Data Transfer Service menyediakan alat otomatis untuk memigrasikan skema dan data dari Amazon Redshift ke BigQuery secara langsung. Tabel berikut mencantumkan alat tambahan untuk membantu bermigrasi dari Amazon Redshift ke BigQuery:
| Alat | Tujuan |
|---|---|
| BigQuery Data Transfer Service | Lakukan transfer batch otomatis atas data Amazon Redshift ke BigQuery menggunakan layanan terkelola sepenuhnya ini. |
| Storage Transfer Service | Impor data Amazon S3 dengan cepat ke Cloud Storage dan siapkan jadwal berulang untuk mentransfer data menggunakan layanan terkelola sepenuhnya ini. |
gcloud |
Salin file Amazon S3 ke Cloud Storage menggunakan alat command line ini. |
| alat command line bq | Berinteraksilah dengan BigQuery menggunakan alat command line ini. Interaksi umum meliputi pembuatan skema tabel BigQuery, memuat data Cloud Storage ke dalam tabel, dan menjalankan kueri. |
| Library klien Cloud Storage | Salin file Amazon S3 ke Cloud Storage menggunakan alat kustom Anda, yang dibuat di atas library klien Cloud Storage. |
| Library klien BigQuery | Berinteraksilah dengan BigQuery menggunakan alat kustom, yang dibuat berdasarkan library klien BigQuery. |
| Scheduler kueri BigQuery | Jadwalkan kueri SQL berulang menggunakan fitur BigQuery bawaan ini. |
| Cloud Composer | Orkestrasikan transformasi dan tugas pemuatan BigQuery menggunakan lingkungan Apache Airflow yang terkelola sepenuhnya ini. |
| Apache Sqoop | Kirim tugas Hadoop menggunakan Sqoop dan driver JDBC Amazon Redshift untuk mengekstrak data dari Amazon Redshift ke HDFS atau Cloud Storage. Sqoop berjalan di lingkungan Dataproc. |
Untuk informasi lebih lanjut tentang penggunaan BigQuery Data Transfer Service, lihat Memigrasikan skema dan data dari Amazon Redshift.
Migrasi menggunakan pipeline
Migrasi data Anda dari Amazon Redshift ke BigQuery dapat mengambil jalur yang berbeda berdasarkan alat migrasi yang tersedia. Meskipun daftar di bagian ini tidak lengkap, daftar ini memberikan gambaran tentang berbagai pola pipeline data yang tersedia saat memindahkan data Anda.
Untuk mengetahui informasi lengkap tentang cara memigrasikan data ke BigQuery menggunakan pipeline, baca artikel Memigrasikan pipeline data.
Mengekstrak dan memuat (EL)
Anda dapat mengotomatiskan pipeline EL sepenuhnya menggunakan BigQuery Data Transfer Service, yang dapat otomatis menyalin skema dan data tabel Anda dari cluster Amazon Redshift ke BigQuery. Jika menginginkan kontrol lebih besar atas langkah-langkah pipeline data, Anda dapat membuat pipeline menggunakan opsi yang dijelaskan di bagian berikut.
Menggunakan ekstrak file Amazon Redshift
- Mengekspor data Amazon Redshift ke Amazon S3.
Salin data dari Amazon S3 ke Cloud Storage menggunakan salah satu opsi berikut:
- Storage Transfer Service (direkomendasikan)
- gcloud CLI
- Library klien Cloud Storage
Memuat data Cloud Storage ke BigQuery menggunakan salah satu opsi berikut:
Menggunakan koneksi JDBC Amazon Redshift
Gunakan salah satu produk Google Cloud berikut untuk mengekspor data Amazon Redshift menggunakan driver JDBC Amazon Redshift:
-
- Template yang disediakan Google: JDBC ke BigQuery
-
Terhubung ke Amazon Redshift melalui JDBC menggunakan Apache Spark
Gunakan Sqoop dan driver JDBC Amazon Redshift untuk mengekstrak data dari Amazon Redshift ke Cloud Storage
Mengekstrak, mentransformasi, dan memuat (ETL)
Jika Anda ingin mengubah beberapa data sebelum memuatnya ke BigQuery, ikuti rekomendasi pipeline yang sama seperti yang dijelaskan di bagian Ekstraksi dan Muat (EL), dengan menambahkan langkah untuk mengubah data Anda sebelum memuatnya ke BigQuery.
Menggunakan ekstrak file Amazon Redshift
Salin data dari Amazon S3 ke Cloud Storage menggunakan salah satu opsi berikut:
- Storage Transfer Service (direkomendasikan)
- gcloud CLI
- Library klien Cloud Storage
Transformasikan dan muat data Anda ke BigQuery menggunakan salah satu opsi berikut:
-
- Membaca dari Cloud Storage
- Menulis ke BigQuery
- Template yang disediakan Google: Teks Cloud Storage ke BigQuery
Menggunakan koneksi JDBC Amazon Redshift
Gunakan salah satu produk yang dijelaskan di bagian Ekstrak dan Muat (EL), tambahkan langkah tambahan untuk mengubah data Anda sebelum memuat ke BigQuery. Ubah pipeline Anda untuk memperkenalkan satu atau beberapa langkah guna mengubah data Anda sebelum menulis ke BigQuery.
-
- Clone kode template JDBC ke BigQuery, lalu ubah template untuk menambahkan transformasi Apache Beam.
-
- Transformasi data Anda menggunakan salah satu plugin CDAP.
Mengekstrak, memuat, dan mentransformasi (ELT)
Anda dapat mengubah data tersebut menggunakan BigQuery sendiri, menggunakan salah satu opsi Ekstrak dan Muat (EL) untuk memuat data ke dalam tabel staging. Kemudian, ubah data dalam tabel staging ini menggunakan kueri SQL yang menuliskan outputnya ke dalam tabel produksi akhir.
Mengubah pengambilan data (CDC)
Mengubah pengambilan data adalah salah satu dari beberapa pola desain software yang digunakan untuk melacak perubahan data. Data warehouse sering digunakan dalam data warehousing karena data warehouse digunakan untuk mengumpulkan dan melacak data serta perubahannya dari berbagai sistem sumber dari waktu ke waktu.
Alat partner untuk migrasi data
Ada beberapa vendor di ruang ekstrak, transformasi, dan pemuatan (ETL). Buka Situs partner BigQuery untuk melihat daftar partner utama dan solusi yang mereka sediakan.
Migrasi ke Google Cloud: Pandangan mendalam
Gunakan bagian ini untuk mempelajari lebih lanjut pengaruh arsitektur, skema, dan dialek SQL terhadap migrasi Anda.
Perbandingan arsitektur
BigQuery dan Amazon Redshift didasarkan pada arsitektur pemrosesan paralel (MPP) secara masif. Kueri didistribusikan ke beberapa server untuk mempercepat eksekusinya. Dalam hal arsitektur sistem, Amazon Redshift dan BigQuery terutama memiliki perbedaan dalam cara data disimpan dan cara kueri dijalankan. Di BigQuery, hardware dan konfigurasi dasar diabstraksi; penyimpanan dan komputasinya memungkinkan data warehouse Anda berkembang tanpa intervensi apa pun dari Anda.
Komputasi, memori, dan penyimpanan
Di Amazon Redshift, CPU, memori, dan penyimpanan disk saling terhubung melalui node komputasi, seperti yang diilustrasikan dalam diagram dari dokumentasi Amazon Redshift ini. Performa cluster dan kapasitas penyimpanan ditentukan oleh jenis dan jumlah node komputasi, yang keduanya harus dikonfigurasi. Untuk mengubah komputasi atau penyimpanan, Anda perlu mengubah ukuran cluster melalui suatu proses (selama beberapa jam, atau hingga dua hari atau lebih) yang membuat cluster baru dan menyalin data tersebut. Amazon Redshift juga menawarkan node RA3 dengan penyimpanan terkelola yang membantu memisahkan komputasi dan penyimpanan. Node terbesar dalam kategori RA3 membatasi penyimpanan terkelola sebesar 64 TB untuk setiap node.
Sejak awal, BigQuery tidak menggabungkan komputasi, memori, dan penyimpanan, tetapi memperlakukan masing-masing secara terpisah.
Komputasi BigQuery ditentukan oleh slot, satu unit kapasitas komputasi yang diperlukan untuk menjalankan kueri. Google mengelola seluruh infrastruktur yang dienkapsulasi oleh slot, sehingga menghilangkan semua tugas, kecuali untuk memilih kuantitas slot yang tepat untuk workload BigQuery Anda. Lihat perencanaan kapasitas untuk membantu memutuskan jumlah slot yang akan Anda beli untuk data warehouse. Memori BigQuery disediakan oleh layanan terdistribusi jarak jauh, yang terhubung ke slot komputasi oleh jaringan petabit Google, yang semuanya dikelola oleh Google.
BigQuery dan Amazon Redshift menggunakan penyimpanan berdasarkan kolom, tetapi BigQuery menggunakan variasi dan kemajuan pada penyimpanan berbasis kolom. Saat kolom dienkode, berbagai statistik tentang data akan dipertahankan dan kemudian digunakan selama eksekusi kueri untuk mengompilasi rencana yang optimal dan memilih algoritma runtime yang paling efisien. BigQuery menyimpan data Anda di sistem file terdistribusi Google, yang otomatis dikompresi, dienkripsi, direplikasi, dan didistribusikan. Semua ini dilakukan tanpa memengaruhi daya komputasi yang tersedia untuk kueri Anda. Dengan memisahkan penyimpanan dari komputasi, Anda dapat meningkatkan skala hingga banyak petabyte dalam penyimpanan dengan lancar, tanpa memerlukan resource komputasi tambahan yang mahal. Terdapat juga sejumlah manfaat lain dari memisahkan komputasi dan penyimpanan.
Meningkatkan atau menurunkan skala
Saat penyimpanan atau komputasi menjadi terbatas, cluster Amazon Redshift harus diubah ukurannya dengan mengubah jumlah atau jenis node dalam cluster.
Saat Anda mengubah ukuran cluster Amazon Redshift, ada dua pendekatan:
- Pengubahan ukuran klasik: Amazon Redshift membuat cluster tempat data disalin, sebuah proses yang dapat memerlukan waktu beberapa jam atau dua hari atau lebih lama untuk data dalam jumlah besar.
- Pengubahan ukuran elastis: Jika Anda hanya mengubah jumlah node, kueri akan dijeda untuk sementara dan koneksi akan ditahan jika memungkinkan. Selama operasi mengubah ukuran, cluster bersifat hanya baca. Pengubahan ukuran elastis biasanya memerlukan waktu 10 hingga 15 menit, tetapi mungkin tidak tersedia untuk semua konfigurasi.
Karena BigQuery adalah platform as a service (PaaS), Anda hanya perlu khawatir tentang jumlah slot BigQuery yang ingin Anda pesan untuk organisasi Anda. Anda mencadangkan slot BigQuery dalam pemesanan, lalu menetapkan project ke pemesanan ini. Untuk mempelajari cara menyiapkan pemesanan ini, lihat Perencanaan kapasitas.
Eksekusi kueri
Mesin eksekusi BigQuery mirip dengan Amazon Redshift karena keduanya mengatur kueri Anda dengan membaginya menjadi beberapa langkah (paket kueri), menjalankan langkah-langkahnya (secara serentak jika memungkinkan), lalu menyusun ulang hasilnya. Amazon Redshift membuat paket kueri statis, tetapi BigQuery tidak melakukannya karena mengoptimalkan rencana kueri secara dinamis saat kueri Anda dijalankan. BigQuery melakukan shuffle data menggunakan layanan memori jarak jauh, sedangkan Amazon Redshift mengacak data menggunakan memori node komputasi lokal. Untuk mengetahui informasi lebih lanjut tentang penyimpanan data menengah BigQuery dari berbagai tahap paket kueri Anda, lihat Eksekusi kueri dalam memori di Google BigQuery.
Pengelolaan workload di BigQuery
BigQuery menawarkan kontrol berikut untuk pengelolaan workload (WLM):
- Kueri interaktif, yang dijalankan sesegera mungkin (ini adalah setelan default).
- Kueri batch, yang diantrekan atas nama Anda, akan dimulai segera setelah resource yang tidak ada aktivitas tersedia di kumpulan resource bersama BigQuery.
Pemesanan slot melalui harga berbasis kapasitas. Daripada membayar kueri sesuai permintaan, Anda dapat membuat dan mengelola bucket slot secara dinamis yang disebut pemesanan dan menetapkan project, folder, atau organisasi ke pemesanan ini. Anda dapat membeli komitmen slot BigQuery (mulai minimum 100) dalam komitmen fleksibel, bulanan, atau tahunan untuk membantu meminimalkan biaya. Secara default, kueri yang berjalan di pemesanan akan otomatis menggunakan slot yang tidak memiliki aktivitas dari pemesanan lainnya.
Seperti yang diilustrasikan dalam diagram berikut, misalkan Anda membeli total kapasitas komitmen sebanyak 1.000 slot untuk digunakan bersama di tiga jenis workload: data science, ELT, dan business intelligence (BI). Untuk mendukung workload ini, Anda dapat membuat pemesanan berikut:
- Anda dapat membuat pemesanan ds dengan 500 slot, dan menetapkan semua project data scienceGoogle Cloud ke pemesanan tersebut.
- Anda dapat membuat pemesanan elt dengan 300 slot, dan menetapkan project yang Anda gunakan untuk workload ELT ke pemesanan tersebut.
- Anda dapat membuat pemesanan bi dengan 200 slot, dan menetapkan project yang terhubung ke alat BI Anda ke pemesanan tersebut.
Penyiapan ini ditunjukkan dalam grafik berikut:
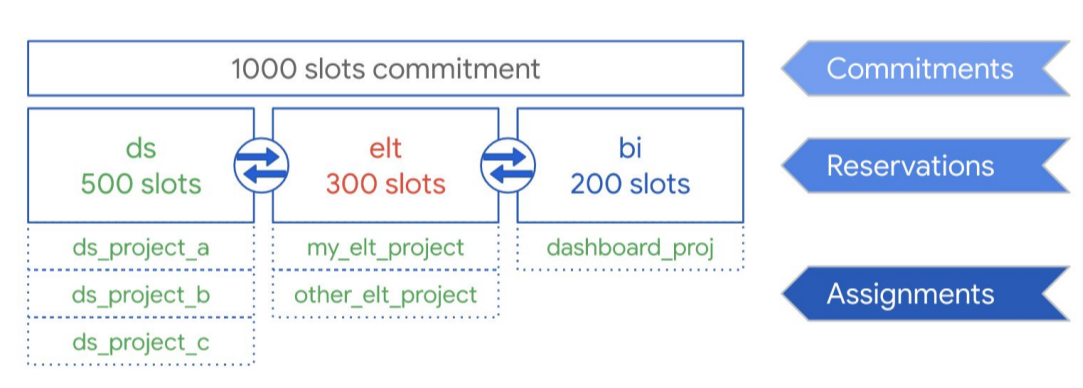
Daripada mendistribusikan reservasi ke workload organisasi Anda, misalnya ke produksi dan pengujian, Anda dapat memilih untuk menetapkan reservasi ke masing-masing tim atau departemen, bergantung pada kasus penggunaan Anda.
Untuk mengetahui informasi selengkapnya, lihat Pengelolaan workload menggunakan Pemesanan.
Pengelolaan workload di Amazon Redshift
Amazon Redshift menawarkan dua jenis pengelolaan workload (WLM):
- Otomatis: Dengan WLM otomatis, Amazon Redshift mengelola konkurensi kueri dan alokasi memori. Hingga delapan antrean dibuat dengan ID class layanan 100–107. WLM otomatis menentukan jumlah resource yang diperlukan kueri dan menyesuaikan konkurensi berdasarkan workload. Untuk mengetahui informasi selengkapnya, lihat Prioritas kueri.
- Manual: Sebaliknya, WLM manual mengharuskan Anda menentukan nilai untuk kueri konkurensi dan alokasi memori. Default untuk WLM manual adalah konkurensi dari lima kueri, dan memori dibagi secara merata untuk kelima kueri.
Jika penskalaan konkurensi diaktifkan, Amazon Redshift akan otomatis menambahkan kapasitas cluster tambahan saat Anda membutuhkannya untuk memproses peningkatan kueri baca serentak. Penskalaan konkurensi memiliki pertimbangan regional dan kueri tertentu. Untuk informasi selengkapnya, lihat Kandidat penskalaan konkurensi.
Konfigurasi set data dan tabel
BigQuery menawarkan sejumlah cara untuk mengonfigurasi data dan tabel Anda, seperti partisi, pengelompokan, dan lokalitas data. Konfigurasi ini dapat membantu mempertahankan tabel yang besar dan mengurangi waktu respons dan pemuatan data secara keseluruhan untuk kueri Anda, sehingga meningkatkan efisiensi operasional workload data Anda.
Membuat partisi
Tabel yang dipartisi adalah tabel yang dibagi menjadi segmen, yang disebut partisi, yang mempermudah pengelolaan dan kueri data Anda. Pengguna biasanya membagi tabel besar menjadi beberapa partisi yang lebih kecil, yang setiap partisinya berisi data selama satu hari. Pengelolaan partisi adalah penentu utama performa dan biaya BigQuery saat membuat kueri selama rentang tanggal tertentu karena membantu BigQuery memindai lebih sedikit data per kueri.
Ada tiga jenis partisi tabel di BigQuery:
- Tabel yang dipartisi menurut waktu penyerapan: Tabel dipartisi berdasarkan waktu penyerapan data.
- Tabel dipartisi menurut kolom:
Tabel dipartisi berdasarkan kolom
TIMESTAMPatauDATE. - Tabel yang dipartisi menurut rentang bilangan bulat: Tabel dipartisi berdasarkan kolom bilangan bulat.
Tabel berbasis kolom yang dipartisi oleh waktu menghilangkan kebutuhan untuk mempertahankan awareness partisi yang independen dari pemfilteran data yang ada di kolom terikat. Data yang ditulis ke tabel berbasis kolom yang dipartisi oleh waktu akan otomatis dikirim ke, partisi yang sesuai berdasarkan nilai data. Demikian pula, kueri yang mengekspresikan filter pada kolom partisi dapat mengurangi keseluruhan data yang dipindai, sehingga dapat menghasilkan peningkatan performa dan pengurangan biaya kueri untuk kueri sesuai permintaan.
Partisi berbasis kolom BigQuery mirip dengan partisi berbasis kolom Amazon Redshift, dengan motivasi yang sedikit berbeda. Amazon Redshift menggunakan distribusi kunci berbasis kolom untuk mencoba menyimpan data terkait yang disimpan bersama dalam node komputasi yang sama, yang pada akhirnya meminimalkan pengacakan data yang terjadi selama penggabungan dan agregasi. BigQuery memisahkan penyimpanan dari komputasi, sehingga memanfaatkan partisi berbasis kolom untuk meminimalkan jumlah data yang dibaca slot dari disk.
Setelah pekerja slot membaca data mereka dari disk, BigQuery dapat otomatis menentukan sharding data yang lebih optimal dan dengan cepat mempartisi ulang data menggunakan layanan acak dalam memori BigQuery.
Untuk informasi selengkapnya, lihat Pengantar tabel berpartisi.
Kunci pengurutan dan pengelompokan
Amazon Redshift mendukung penentuan kolom tabel sebagai kunci pengurutan gabungan atau sisipan. Di BigQuery, Anda dapat menentukan kunci urutan gabungan dengan mengelompokkan tabel Anda. Tabel yang dikelompokkan dalam BigQuery meningkatkan performa kueri karena data tabel diurutkan secara otomatis berdasarkan isi hingga empat kolom yang ditentukan dalam skema tabel. Kolom-kolom ini digunakan untuk menempatkan data terkait. Urutan kolom pengelompokan yang Anda tentukan penting karena akan menentukan tata urutan data.
Pengelompokan dapat meningkatkan performa jenis kueri tertentu, seperti kueri yang menggunakan klausa filter dan kueri yang menggabungkan data. Ketika data ditulis ke tabel yang dikelompokkan berdasarkan tugas kueri atau tugas pemuatan, BigQuery akan otomatis mengurutkan data menggunakan nilai dalam kolom pengelompokan. Nilai ini digunakan untuk mengatur data menjadi beberapa blok pada penyimpanan BigQuery. Saat Anda mengirimkan kueri yang berisi klausa yang memfilter data berdasarkan kolom pengelompokan, BigQuery akan menggunakan blok yang diurutkan untuk menghapus pemindaian data yang tidak diperlukan.
Demikian pula, saat Anda mengirimkan kueri yang menggabungkan data berdasarkan nilai dalam kolom pengelompokan, performa akan meningkat karena blok yang diurutkan tersebut memblokir baris dengan nilai serupa.
Gunakan pengelompokan dalam keadaan berikut:
- Kunci urutan gabungan dikonfigurasi di tabel Amazon Redshift Anda.
- Pemfilteran atau agregasi dikonfigurasi terhadap kolom tertentu di kueri Anda.
Jika Anda menggunakan pengelompokan dan partisi secara bersamaan, data dapat dipartisi berdasarkan kolom tanggal, stempel waktu, atau bilangan bulat, lalu dikelompokkan pada kumpulan kolom yang berbeda (hingga total empat kolom yang dikelompokkan). Dalam hal ini, data di setiap partisi dikelompokkan berdasarkan nilai kolom pengelompokan.
Saat Anda menentukan kunci pengurutan dalam tabel di Amazon Redshift, bergantung pada beban
pada sistem, Amazon Redshift akan otomatis memulai pengurutan menggunakan
kapasitas komputasi cluster Anda sendiri. Anda bahkan mungkin perlu menjalankan perintah VACUUM secara manual jika ingin mengurutkan sepenuhnya data tabel sesegera mungkin, misalnya setelah data berukuran besar pemuatan halaman. BigQuery secara otomatis menangani pengurutan ini untuk Anda dan tidak menggunakan slot BigQuery yang dialokasikan, sehingga tidak memengaruhi performa kueri apa pun.
Untuk mengetahui informasi selengkapnya tentang cara menggunakan tabel yang dikelompokkan, lihat Pengantar tabel yang dikelompokkan.
Kunci distribusi
Amazon Redshift menggunakan kunci distribusi untuk mengoptimalkan lokasi blok data untuk menjalankan kuerinya. BigQuery tidak menggunakan kunci distribusi karena secara otomatis menentukan dan menambahkan tahapan dalam paket kueri (saat kueri berjalan) untuk meningkatkan distribusi data di seluruh pekerja kueri.
Sumber eksternal
Jika menggunakan Amazon Redshift Spectrum untuk membuat kueri data di Amazon S3, Anda juga dapat menggunakan fitur sumber data eksternal BigQuery untuk mengkueri data secara langsung dari file di Cloud Storage.
Selain membuat kueri data di Cloud Storage, BigQuery menawarkan fungsi kueri gabungan untuk menjalankan kueri secara langsung dari produk berikut:
- Cloud SQL ( MySQL atau PostgreSQL yang terkelola sepenuhnya)
- Bigtable (NoSQL yang terkelola sepenuhnya)
- Google Drive (CSV, JSON, Avro, Spreadsheet)
Lokalitas data
Anda dapat membuat set data BigQuery di lokasi regional dan multi-regional, sedangkan Amazon Redshift hanya menawarkan lokasi regional. BigQuery menentukan lokasi untuk menjalankan tugas pemuatan, kueri, atau ekspor berdasarkan set data yang dirujuk dalam permintaan. Lihat pertimbangan lokasi BigQuery untuk mendapatkan tips tentang cara menggunakan set data regional dan multi-regional.
Pemetaan jenis data di BigQuery
Jenis data Amazon Redshift berbeda dengan jenis data BigQuery. Untuk mengetahui detail selengkapnya tentang jenis data BigQuery, baca dokumentasi resmi.
BigQuery juga mendukung jenis data berikut, yang tidak memiliki analog Amazon Redshift langsung:
Perbandingan SQL
GoogleSQL mendukung kepatuhan terhadap standar SQL 2011 dan memiliki ekstensi yang mendukung kueri data bertingkat dan berulang. Amazon Redshift SQL didasarkan pada PostgreSQL, tetapi memiliki beberapa perbedaan yang dijelaskan dalam dokumentasi Amazon Redshift. Untuk perbandingan mendetail antara sintaksis dan fungsi Amazon Redshift serta GoogleSQL, lihat Panduan penerjemahan Amazon Redshift SQL.
Anda dapat menggunakan penerjemah SQL batch untuk mengonversi skrip dan kode SQL lainnya dari platform Anda saat ini ke BigQuery.
Pascamigrasi
Karena Anda telah memigrasikan skrip yang tidak didesain dengan mempertimbangkan BigQuery, Anda dapat memilih untuk menerapkan teknik guna mengoptimalkan performa kueri di BigQuery. Untuk informasi selengkapnya, lihat Pengantar cara mengoptimalkan performa kueri.
Langkah berikutnya
- Dapatkan petunjuk langkah demi langkah untuk memigrasikan skema dan data dari Amazon Redshift.
- Dapatkan petunjuk langkah demi langkah untuk memigrasikan Amazon Redshift ke BigQuery dengan VPC.