spark-bigquery-connector digunakan dengan Apache Spark untuk membaca dan menulis data dari dan ke BigQuery. Konektor ini memanfaatkan BigQuery Storage API saat membaca data dari BigQuery.
Tutorial ini memberikan informasi tentang ketersediaan konektor yang telah diinstal sebelumnya, dan menunjukkan cara membuat versi konektor tertentu tersedia untuk tugas Spark. Contoh kode menunjukkan cara menggunakan konektor Spark BigQuery dalam aplikasi Spark.
Menggunakan konektor yang sudah diinstal
Konektor Spark BigQuery telah diinstal sebelumnya dan tersedia untuk tugas Spark yang dijalankan di cluster Dataproc yang dibuat dengan versi image 2.1 dan yang lebih baru. Versi konektor yang telah diinstal sebelumnya tercantum di setiap halaman rilis versi gambar. Misalnya, baris BigQuery Connector di halaman
versi rilis image 2.2.x
menampilkan versi konektor yang diinstal pada rilis image 2.2 terbaru.
Menyediakan versi konektor tertentu untuk tugas Spark
Jika Anda ingin menggunakan versi konektor yang berbeda dari versi yang telah diinstal sebelumnya di cluster versi image 2.1 atau yang lebih baru, atau jika Anda ingin menginstal konektor di cluster versi image sebelum 2.1, ikuti petunjuk di bagian ini.
Penting: Versi spark-bigquery-connector harus kompatibel dengan
versi image cluster Dataproc. Lihat
Matriks Kompatibilitas Image Connector ke Dataproc.
Cluster versi image 2.1 dan yang lebih baru
Saat Anda membuat cluster Dataproc
dengan versi image 2.1 atau yang lebih baru, tentukan
versi konektor sebagai metadata cluster.
Contoh gcloud CLI:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
Catatan:
SPARK_BQ_CONNECTOR_VERSION: Tentukan versi konektor. Versi konektor Spark BigQuery tercantum di halaman spark-bigquery-connector/releases di GitHub.
Contoh:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: Tentukan URL yang mengarah ke jar di Cloud Storage. Anda dapat menentukan URL konektor yang tercantum di kolom link di Mendownload dan Menggunakan Konektor di GitHub atau jalur ke lokasi Cloud Storage tempat Anda menempatkan JAR konektor kustom.
Contoh:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 dan cluster versi gambar sebelumnya
Anda dapat menyediakan konektor Spark BigQuery untuk aplikasi Anda dengan salah satu cara berikut:
Instal spark-bigquery-connector di direktori jar Spark setiap node menggunakan tindakan inisialisasi konektor Dataproc saat Anda membuat cluster.
Berikan URL jar konektor saat Anda mengirimkan tugas ke cluster menggunakan Google Cloud konsol, gcloud CLI, atau Dataproc API.
Konsol
Gunakan item file Jar tugas Spark di halaman Kirim tugas Dataproc.
gcloud
Gunakan flag
gcloud dataproc jobs submit spark --jars.API
Gunakan kolom
SparkJob.jarFileUris.Cara menentukan file JAR konektor saat menjalankan tugas Spark di cluster versi image sebelum 2.0
- Tentukan JAR konektor dengan mengganti informasi versi Scala dan konektor dalam string URI berikut:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Menggunakan Scala
2.12dengan versi image Dataproc1.5+gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- Gunakan Scala
2.11dengan versi image Dataproc1.4dan yang lebih lama:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- Tentukan JAR konektor dengan mengganti informasi versi Scala dan konektor dalam string URI berikut:
Sertakan jar konektor dalam aplikasi Scala atau Java Spark Anda sebagai dependensi (lihat Mengompilasi terhadap konektor).
Menghitung biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
- Dataproc
- BigQuery
- Cloud Storage
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Membaca dan menulis data dari dan ke BigQuery
Contoh ini membaca data dari BigQuery ke dalam DataFrame Spark untuk melakukan penghitungan kata menggunakan API sumber data standar.
Konektor menulis data ke BigQuery dengan
terlebih dahulu melakukan buffering semua data ke tabel sementara Cloud Storage. Kemudian, pipeline ini akan menyalin semua data dari ke BigQuery dalam satu operasi. Konektor akan mencoba menghapus file sementara setelah operasi pemuatan BigQuery berhasil dan sekali lagi saat aplikasi Spark dihentikan.
Jika tugas gagal, hapus file Cloud Storage sementara yang tersisa. Biasanya, file BigQuery sementara berada di gs://[bucket]/.spark-bigquery-[jobid]-[UUID].
Mengonfigurasi penagihan
Secara default, project yang terkait dengan kredensial atau akun layanan akan
ditagih untuk penggunaan API. Untuk menagih project lain, tetapkan konfigurasi berikut: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Token ini juga dapat ditambahkan ke operasi baca atau tulis, sebagai berikut:
.option("parentProject", "<BILLED-GCP-PROJECT>").
Menjalankan kode
Sebelum menjalankan contoh ini, buat set data bernama "wordcount_dataset" atau ubah set data output dalam kode ke set data BigQuery yang ada di projectGoogle Cloud Anda.
Gunakan perintah
bq untuk membuat
wordcount_dataset:
bq mk wordcount_dataset
Gunakan perintah Google Cloud CLI untuk membuat bucket Cloud Storage, yang akan digunakan untuk mengekspor ke BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- Periksa kode dan ganti placeholder [bucket] dengan
bucket Cloud Storage yang Anda buat sebelumnya.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- Jalankan kode di cluster Anda
- Gunakan SSH untuk terhubung ke node master cluster Dataproc
- Buka halaman
Dataproc Clusters
di konsol Google Cloud , lalu klik nama cluster Anda
- Di halaman >Cluster details, pilih tab VM Instances. Kemudian, klik
SSHdi sebelah kanan nama node master cluster>
Jendela browser akan terbuka di direktori beranda Anda di node masterConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Buka halaman
Dataproc Clusters
di konsol Google Cloud , lalu klik nama cluster Anda
- Buat
wordcount.scaladengan editor teksvi,vim, ataunanobawaan, lalu tempel kode Scala dari listingan kode Scalanano wordcount.scala
- Luncurkan REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- Jalankan wordcount.scala dengan perintah
:load wordcount.scalauntuk membuat tabelwordcount_outputBigQuery. Output daftar menampilkan 20 baris dari output wordcount.:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Untuk melihat pratinjau tabel output, buka halamanBigQuery, pilih tabelwordcount_output, lalu klik Pratinjau.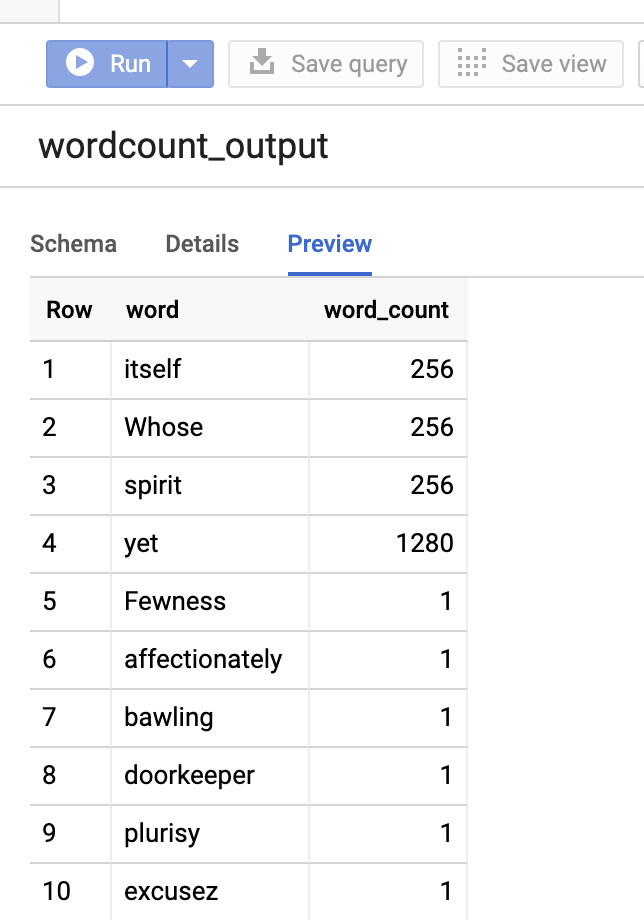
- Gunakan SSH untuk terhubung ke node master cluster Dataproc
PySpark
- Periksa kode dan ganti placeholder [bucket] dengan
bucket Cloud Storage yang Anda buat sebelumnya.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Jalankan kode di cluster Anda
- Gunakan SSH untuk terhubung ke node master cluster Dataproc
- Buka halaman
Dataproc Clusters
di konsol Google Cloud , lalu klik nama cluster Anda
- Di halaman Cluster details, pilih tab VM Instances. Kemudian, klik
SSHdi sebelah kanan nama node master cluster
Jendela browser akan terbuka di direktori beranda Anda di node masterConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Buka halaman
Dataproc Clusters
di konsol Google Cloud , lalu klik nama cluster Anda
- Buat
wordcount.pydengan editor teksvi,vim, ataunanoyang telah diinstal sebelumnya, lalu tempelkan kode PySpark dari daftar kode PySparknano wordcount.py
- Jalankan wordcount dengan
spark-submituntuk membuat tabel BigQuerywordcount_output. Daftar output menampilkan 20 baris dari output wordcount.spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Untuk melihat pratinjau tabel output, buka halamanBigQuerypilih tabelwordcount_output, lalu klik Pratinjau.
- Gunakan SSH untuk terhubung ke node master cluster Dataproc
Tips pemecahan masalah
Anda dapat memeriksa log tugas di Cloud Logging dan di BigQuery Jobs Explorer untuk memecahkan masalah tugas Spark yang menggunakan konektor BigQuery.
Log driver Dataproc berisi entri
BigQueryClientdengan metadata BigQuery yang mencakupjobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} Tugas BigQuery berisi label
Dataproc_job_iddanDataproc_job_uuid:- Logging:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- BigQuery Jobs Explorer: Klik ID tugas untuk melihat detail tugas di bagian Label dalam Informasi tugas.
- Logging:
Langkah berikutnya
- Lihat BigQuery Storage & Spark SQL - Python.
- Pelajari cara membuat file definisi tabel untuk sumber data eksternal.
- Pelajari cara membuat kueri data yang dipartisi secara eksternal.
- Lihat Tips penyesuaian tugas Spark.