Amazon Redshift から BigQuery への移行: 概要
このドキュメントでは、次のトピックを中心として、Amazon Redshift から BigQuery への移行に関するガイダンスを説明します。
- 移行に関する戦略
- クエリの最適化とデータ モデリングのベストプラクティス
- トラブルシューティングのヒント
- ユーザー導入ガイダンス
このドキュメントの目的は次のとおりです。
- Amazon Redshift から BigQuery に移行する組織を対象とした全体的なガイダンスを提供します。これには、BigQuery を最大限に活用するための既存のデータ パイプラインの見直しのサポートも含まれます。
- BigQuery と Amazon Redshift のアーキテクチャを比較できるように支援します。これにより、移行中に既存の機能を実装する方法を把握できます。このガイドの目標は、Redshift と BigQuery の機能を対応付けて 1 つずつ説明することではなく、BigQuery で利用できる新しい機能を紹介することです。
このドキュメントは、エンタープライズ アーキテクト、データベース管理者、アプリケーション デベロッパー、IT セキュリティ スペシャリストを対象としています。これは、Amazon Redshift に精通していることを前提としています。
また、バッチ SQL 変換を使用して複数の SQL スクリプトを一括で移行することも、インタラクティブ SQL 変換を使用してアドホック クエリ変換することもできます。Amazon Redshift SQL は、両方の SQL 変換サービスで完全にサポートされています。
移行前のタスク
データ ウェアハウスの移行を確実に成功させるため、プロジェクトのタイムラインの早期の段階で移行戦略の計画を始めてください。このようなアプローチを取ることで、ニーズに適した Google Cloud 機能を評価することができます。
キャパシティ プランニング
BigQuery ではスロットを使用して分析スループットを測定します。BigQuery スロットとは、SQL クエリの実行に必要なコンピューティング能力を表す Google 独自の単位です。BigQuery では、クエリの実行に必要なスロット数が継続的に計算されますが、スロットはフェア スケジューラに基づいて割り当てられます。
BigQuery スロットのキャパシティ プランニングでは、次の料金モデルのいずれかを選択できます。
- オンデマンド料金: オンデマンド料金では、BigQuery は処理したバイト数(データサイズ)に基づいて課金されるため、実行したクエリに対してのみ支払いが発生します。BigQuery のデータサイズを決定する方法については、データサイズの計算を参照してください。基本となる計算容量はスロットで決まるため、BigQuery の使用に対する支払いは、処理したバイト数ではなく必要なスロットの数を単位とします。デフォルトでは、すべてのGoogle Cloud プロジェクトは最大 2,000 スロットまでに制限されています。BigQuery が、クエリを高速化するためにこの上限を超えてバーストする場合がありますが、バーストについては保証いたしません。
- 容量ベースの料金: 容量ベースの料金では、実行するクエリによって処理されたバイト数に対して料金を支払うのではなく、BigQuery スロットの予約(最低 100 個)を購入します。エンタープライズ データ ウェアハウスのワークロードには容量ベースの料金をおすすめします。このようなワークロードでは通常、消費量が予測可能な多数の同時レポートや抽出 / 読み込み / 変換(ELT)クエリが発生します。
スロットの見積もりを行う場合は、Cloud Monitoring を使用した BigQuery のモニタリングおよび BigQuery を使用した監査ログの分析をセットアップすることをおすすめします。Looker Studio(Looker Studio ダッシュボードのオープンソース例)または Looker を使用して、BigQuery の監査ログデータ(特に、クエリやプロジェクトにまたがるスロット使用状況)を可視化できます。また、BigQuery のシステム テーブルデータを利用して、ジョブと予約でのスロットの使用状況をモニタリングできます(Looker Studio ダッシュボードのオープンソースの例)。スロットの使用状況を定期的にモニタリングし、分析することで、組織の成長に合わせて Google Cloudで必要となる合計スロット数を見積もることができます。
たとえば、最初に 4,000 個の BigQuery スロットを予約して、複雑さが中程度の 100 個のクエリを同時実行すると仮定します。クエリの実行プランの待機時間が長く、ダッシュボードで表示されるスロット使用率が高い場合、ワークロードをサポートするために BigQuery スロットが追加で必要になる可能性があります。1 年間または 3 年間の契約でスロットの購入をご希望の場合、Google Cloud コンソールまたは bq コマンドライン ツールを使用して BigQuery Reservations を開始できます。ワークロード管理、クエリ実行、BigQuery アーキテクチャの詳細については、Google Cloudへの移行: 詳細をご覧ください。
Google Cloudのセキュリティ
次のセクションでは、Amazon Redshift の一般的なセキュリティ管理と、Google Cloud 環境でデータ ウェアハウスを確実に保護する方法について説明します。
Identity and Access Management
Amazon Redshift でアクセス制御を設定するには、Amazon Redshift API 権限ポリシーを作成し、Identity and Access Management(IAM)の ID に接続する必要があります。Amazon Redshift API 権限ではクラスタレベルのアクセスが提供されますが、クラスタよりも詳細なアクセスレベルは提供されません。テーブルやビューなどのリソースに対してより詳細なアクセス権が必要な場合は、Amazon Redshift データベースのユーザー アカウントを使用します。
BigQuery は、IAM を使用することで、リソースへのアクセスをより詳細なレベルで管理します。BigQuery で使用できるリソースは、組織、プロジェクト、データセット、テーブル、列、ビューです。IAM ポリシー階層では、データセットはプロジェクトの子リソースになります。テーブルに対する権限は、そのテーブルを含むデータセットから継承されます。
リソースへのアクセス権を付与するには、ユーザー、グループ、サービス アカウントのいずれかに IAM のロールを 1 つ以上割り当てます。組織とプロジェクトのロールは、ジョブの実行またはプロジェクトの管理に関して可能な操作を制御します。データセットのロールは、プロジェクト内のデータへのアクセスまたは変更に関して可能な操作を制御します。
IAM には次のタイプのロールがあります。
BigQuery は、IAM 内でテーブルレベルのアクセス制御を提供します。テーブルレベルの権限により、テーブルまたはビューにアクセスできるユーザー、グループ、サービス アカウントが決まります。ユーザーに完全なデータセットへのアクセス権を与えることなく、特定のテーブルまたはビューへのアクセス権を付与できます。よりきめ細かなアクセスのためには、次のセキュリティ メカニズムを 1 つ以上実装することを検討できます。
- 列レベルのアクセス制御: データのポリシータグ(型ベースの分類)を使用し、機密性の高い列に対してきめ細かいアクセスを行うことができます。
- 列レベルの動的データ マスキング: ユーザー グループに対して列データを選択的に難読化し、かつ列へのアクセスを許可します。
- 行レベルのセキュリティ: データのフィルタリングや、アクセスを許可するユーザー条件に基づくテーブル内の特定の行へのアクセスが可能になります。
フルディスク暗号化
Identity and Access Management に加え、暗号化によってデータを保護するための防御層が追加されます。データが漏洩した場合、暗号化されたデータは読み取り不能です。
Amazon Redshift では、保存データと転送データの両方の暗号化がデフォルトで有効になっていません。保存データの暗号化は、クラスタの起動時に明示的に有効にするか、AWS Key Management Service の暗号化を使用するよう既存のクラスタを変更する必要があります。転送中のデータの暗号化も、明示的に有効にする必要があります。
BigQuery は、ソースやその他の条件に関係なく、すべての保存データと転送中のデータをデフォルトで暗号化します。これはオフにできません。Cloud Key Management Service で鍵暗号鍵を制御および管理する場合、BigQuery では顧客管理の暗号鍵(CMEK)もサポートされています。
Google Cloudでの暗号化の詳細については、保存データの暗号化および転送中データの暗号化に関するホワイトペーパーをご覧ください。
Google Cloud上で転送中のデータの場合、データは Google または Google の代理者が管理する物理的な境界の外に移動する際に暗号化され、認証が行われます。これらの境界内で転送中のデータは認証の対象となりますが、暗号化されるとは限りません。
データ損失防止(DLP)
コンプライアンス要件により、Google Cloudに保存できるデータが制限される場合があります。Sensitive Data Protectionを使用して BigQuery テーブルをスキャンし、機密データを検出して分類できます。機密データが検出された場合は、Sensitive Data Protection の匿名化変換によりデータのマスキング、削除、難読化などを行えます。
Google Cloudへの移行: 基本
このセクションでは、ツールとパイプラインを使用して移行をサポートする方法について説明します。
移行ツール
BigQuery Data Transfer Service には、Amazon Redshift から BigQuery にスキーマとデータの両方を直接移行するための自動ツールが用意されています。次の表に、Amazon Redshift から BigQuery への移行に役立つその他のツールを示します。
| ツール | 目的 |
|---|---|
| BigQuery Data Transfer Service | このフルマネージド サービスを使用して、Amazon Redshift から BigQuery へのデータの自動バッチテンス尾を実行します。 |
| Storage Transfer Service | このフルマネージド サービスを使用して、Amazon S3 データを Cloud Storage に迅速にインポートし、データを転送するための繰り返しスケジュールを設定します。 |
gcloud |
このコマンドライン ツールを使用して、Amazon S3 ファイルを Cloud Storage にコピーします。 |
| bq コマンドライン ツール | このコマンドライン ツールを使用して、BigQuery を操作します。一般的な操作には、BigQuery テーブル スキーマの作成、Cloud Storage データのテーブルへの読み込み、クエリの実行が含まれます。 |
| Cloud Storage クライアント ライブラリ | Cloud Storage クライアント ライブラリで構築されたカスタムツールを使用して、Amazon S3 ファイルを Cloud Storage にコピーします。 |
| BigQuery クライアント ライブラリ | BigQuery クライアント ライブラリで構築されたカスタムツールを使用して、BigQuery を操作します。 |
| BigQuery Query Scheduler | この BigQuery 組み込み機能を使用して、定期的に繰り返し実行する SQL クエリをスケジュールします。 |
| Cloud Composer | このフルマネージドの Apache Airflow 環境を使用して、変換と BigQuery の読み込みジョブをオーケストレートします。 |
| Apache Sqoop | Sqoop と Amazon Redshift の JDBC ドライバを使用して Hadoop ジョブを送信し、データを Amazon Redshift から HDFS または Cloud Storage に抽出します。Sqoop は Dataproc 環境で動作します。 |
BigQuery Data Transfer Service の使用方法については、Amazon Redshift からスキーマとデータを移行するをご覧ください。
パイプラインを使用した移行
Amazon Redshift から BigQuery へのデータの移行は、利用可能な移行ツールに応じてさまざまな方法で行われます。このセクションのリストはすべてを網羅しているわけではありませんが、データを移動する際に使用できるさまざまなデータ パイプラインのパターンを確認できます。
パイプラインを使用して BigQuery にデータを移行する方法の概要については、データ パイプラインの移行をご覧ください。
抽出と読み込み(EL)
BigQuery Data Transfer Service を使用すると、EL パイプラインを完全に自動化できます。このサービスは、テーブルのスキーマとデータを Amazon Redshift クラスタから BigQuery に自動的にコピーできます。データ パイプラインのステップをより細かく制御する場合は、次のセクションで説明するオプションを使用してパイプラインを作成できます。
Amazon Redshift のファイル抽出を使用する
- Amazon Redshift のデータを Amazon S3 にエクスポートします。
次のいずれかのオプションを使用してデータを Amazon S3 から Cloud Storage にコピーします。
次のいずれかのオプションを使用してデータを Cloud Storage から BigQuery に読み込みます。
Amazon Redshift JDBC 接続を使用する
Amazon Redshift JDBC ドライバを使用して Amazon Redshift データをエクスポートするには、次のいずれかの Google Cloud プロダクトを使用します。
-
- Google-が提供するテンプレート: JDBC to BigQuery
-
Sqoop と Amazon Redshift JDBC ドライバを使用して、Amazon Redshift から Cloud Storage にデータを抽出する。
抽出、変換、読み込み(ETL)
BigQuery に読み込む前に一部のデータを変換する場合は、抽出と読み込み(EL)で説明されているパイプラインの推奨事項に従います。その場合、BigQuery に読み込む前にデータを変換する手順を追加します。
Amazon Redshift のファイル抽出を使用する
次のいずれかのオプションを使用してデータを Amazon S3 から Cloud Storage にコピーします。
次のいずれかのオプションを使用してデータを変換し、BigQuery に読み込みます。
-
- Cloud Storage から読み取る
- BigQuery に書き込む
- Google 提供のテンプレート: Cloud Storage Text to BigQuery
Amazon Redshift JDBC 接続を使用する
抽出と読み込み(EL)セクションで説明されているいずれかのプロダクトを使用し、BigQuery に読み込む前にデータを変換する手順を追加します。BigQuery に書き込む前に、データを変換する 1 つ以上の手順を導入するようにパイプラインを変更します。
-
- JDBC to BigQuery テンプレート コードのクローンを作成し、このテンプレートを変更して Apache Beam 変換を追加します。
-
- CDAP プラグインを使用してデータを変換します。
抽出、読み込み、変換(ELT)
BigQuery 自体を使用してデータを変換し、いずれかの抽出と読み込み(EL)オプションを使用してデータをステージング テーブルに読み込むことができます。SQL クエリを使用してステージング テーブル内のデータを変換し、クエリの結果を最終本番環境のテーブルに書き込みます。
変更データ キャプチャ(CDC)
変更データ キャプチャは、データの変更追跡に適用されるさまざまなソフトウェア設計パターンのうちの 1 つです。データ ウェアハウジングでは、通常は CDC が使用されています。データ ウェアハウスは、各種のソースシステムから一定期間にわたるデータとその変更を照合して追跡するために使用されるためです。
データ移行のためのパートナー ツール
抽出、変換、読み込み(ETL)の分野には数多くのベンダーが存在します。主要なパートナーと、パートナーが提供するソリューションの一覧については、BigQuery パートナー ウェブサイトをご覧ください。
Google Cloudへの移行: 詳細
このセクションでは、データ ウェアハウスのアーキテクチャ、スキーマ、SQL 言語が移行に与える影響について詳しく説明します。
アーキテクチャの比較
BigQuery と Amazon Redshift は、どちらも超並列処理(MPP)アーキテクチャを採用しています。クエリの実行を高速化するために、クエリは複数のサーバーに分散されます。システム アーキテクチャに関する Amazon Redshift と BigQuery の主な違いは、データの保存方法とクエリの実行方法です。BigQuery では基盤となるハードウェアと構成は抽象化されており、ストレージとコンピューティングによって、ユーザーの介入なしにデータ ウェアハウスを拡張できます。
コンピューティング、メモリ、ストレージ
Amazon Redshift ドキュメントのこの図に示されているように、Amazon Redshift では、CPU、メモリ、ディスク ストレージがコンピューティング ノードによって互いに結びついています。クラスタのパフォーマンスとストレージ容量はコンピューティング ノードのタイプと数で決まります。ノードのタイプと数の両方を構成する必要があります。コンピューティングまたはストレージを変更するにはクラスタのサイズ変更が必要となり、そのために新しいクラスタを作成し、データをコピーするプロセスは数時間、2 日、またはそれ以上の時間がかかります。Amazon Redshift は、コンピューティングとストレージを分離できるマネージド ストレージを備えた RA3 ノードも提供しています。RA3 カテゴリの最大のノードでは、各ノードのマネージド ストレージの上限は 64 TB です。
BigQuery では初めから、コンピューティングング、メモリ、ストレージを、結び付きのないものとして個別に扱います。
BigQuery のコンピューティングは、スロット(クエリの実行に必要な演算能力の単位)で定義されます。Google ではスロットによってカプセル化されたインフラストラクチャ全体を管理することで、BigQuery のワークロードにとって適切なスロット数を選択すること以外の作業をすべて排除しています。データ ウェアハウス用に購入するスロット数の決定については、キャパシティ プランニングをご覧ください。BigQuery のメモリを提供するのはリモート分散サービスです。このサービスは Google のペタビット ネットワークを介してコンピューティング ノードとつながっており、すべてを Google が管理しています。
BigQuery と Amazon Redshift はどちらもカラム型ストレージを使用していますが、BigQuery ではカラム型ストレージにバリエーションと改良を加えています。列のエンコード中は、データに関するさまざまな統計情報が保持され、後でクエリの実行時に最適なプランのコンパイルや効率的なランタイム アルゴリズムの選択のために使用されます。BigQuery ではデータを Google の分散ファイル システムに保存し、データの圧縮、暗号化、複製、分散は自動的に行われます。これらの作業は、クエリに使用できる処理能力に影響しません。ストレージをコンピューティングから切り離すことで、高価なコンピューティング リソースを追加することなく、ストレージを最大数十ペタバイトまでシームレスにスケールアップできます。コンピューティングとストレージを切り離すことのメリットは他にもあります。
スケールアップまたはスケールダウン
Amazon Redshift でストレージまたはコンピューティングが制約を受けると、クラスタ内のノードの数とタイプを変更することでクラスタのサイズを変更する必要があります。
Amazon Redshift クラスタのサイズを変更する方法は次の 2 つです。
- 従来のサイズ変更: Amazon Redshift では、データのコピー先となるクラスタが作成されます。データが大量にある場合、このコピーに数時間、2 日、またはそれ以上の時間がかかります。
- 伸縮自在なサイズ変更: ノードの数のみを変更した場合、クエリは一時的に停止し、接続は可能であれば開かれたままになります。サイズ変更の処理が終わるまで、クラスタは読み取り専用です。伸縮自在なサイズ変更には通常 10~15 分かかりますが、構成によってはこの方法でサイズ変更できないことがあります。
BigQuery は Platform as a Service(PaaS)なので、決める必要があるのは、組織で使用するために予約する BigQuery スロットの数だけです。BigQuery スロットは予約領域に確保し、その後プロジェクトを予約領域に割り当てます。これらの予約の設定方法については、キャパシティ プランニングをご覧ください。
クエリ実行
BigQuery の実行エンジンは、クエリをステップ(クエリプラン)に分割し、ステップを(可能であれば同時に)実行した後に結果を再構成することでクエリをオーケストレートするという点で Amazon Redshift に似ています。Amazon Redshift では静的クエリプランを生成しますが、BigQuery ではクエリの実行時にクエリプランを動的に最適化します。BigQuery ではリモート メモリサービスを使用してデータをシャッフルしますが、Amazon Redshift ではローカルのコンピューティング ノードのメモリを使用してデータをシャッフルします。クエリプランのさまざまなステージにある中間データを BigQuery のストレージに保存する方法については、Google BigQuery によるインメモリ クエリの実行をご覧ください。
BigQuery でのワークロード管理
BigQuery でワークロードの管理(WLM)用に提供されている管理機能は次のとおりです。
- インタラクティブ クエリ: 可能な限り早く実行されます(デフォルト設定)。
- バッチクエリ: ユーザーに代わってクエリをキューに格納し、アイドル状態のリソースが BigQuery 共有リソースプールで使用可能になり次第、クエリを開始します。
容量ベースの料金によるスロットの予約。クエリに対してオンデマンドで課金する代わりに、予約と呼ばれるスロットのバケットを動的に作成および管理して、プロジェクト、フォルダー、または組織をこれらの予約に割り当てることができます。BigQuery のスロット コミットメント(100 個以上)は、Flex 単位、月単位、年単位で購入できるため、費用を最小限に抑えることができます。デフォルトでは、予約で実行されるクエリは、他の予約のアイドル スロットを自動的に使用します。
次の図に示すように、データ サイエンス、ELT、ビジネス インテリジェンス(BI)の 3 つのワークロード タイプで共有する合計 1,000 スロットのコミットメント容量を購入したとします。これらのワークロードをサポートするには、次の予約を作成します。
- 500 個のスロットで予約 ds を作成し、すべてのGoogle Cloud データ サイエンス プロジェクトをその予約に割り当てることができます。
- 300 個のスロットで予約 elt を作成し、ELT ワークロードに使用するプロジェクトをその予約に割り当てることができます。
- 200 個のスロットで予約 bi を作成し、BI ツールに接続されているプロジェクトをその予約に割り当てることができます。
次の図に、この設定を示します。
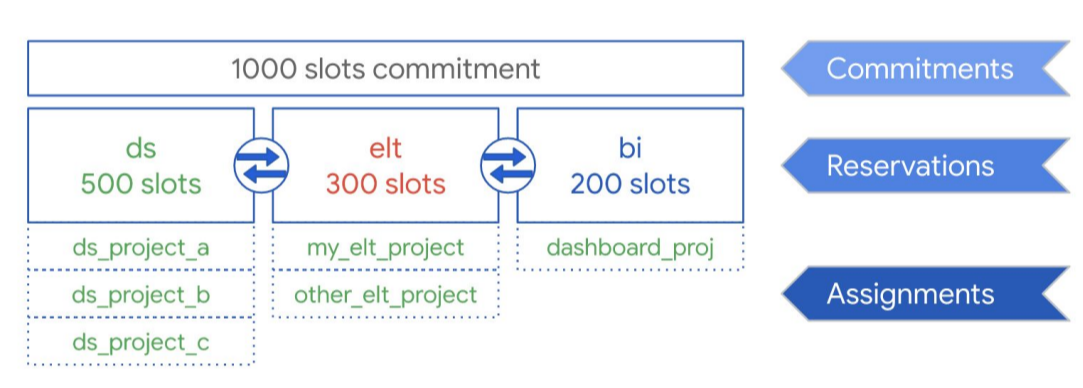
予約を組織のワークロード(本番環境やテスト環境など)に分散させる代わりに、ユースケースに応じて個別のチームや部門に予約を割り当てることもできます。
詳細については、Reservations を使用したワークロード管理をご覧ください。
Amazon Redshift でのワークロード管理
Amazon Redshift では、次の 2 種類のワークロード管理(WLM)を利用できます。
- 自動: Amazon Redshift では、自動 WLM を使用してクエリの同時実行とメモリ割り当てを管理します。最大 8 本のキューが作成され、100~107 のサービスクラス ID が各キューに割り当てられます。自動 WLM では、クエリに必要なリソースの量が判断され、ワークロードを基準に同時実行が調整されます。詳細については、クエリの優先度に関する説明をご覧ください。
- 手動: 一方、手動 WLM では、クエリの同時実行とメモリの割り当てに対して値を設定する必要があります。デフォルトではクエリの同時実行数は 5 で、メモリは 5 個のクエリに均等に分割されます。
Amazon Redshift で同時実行スケーリングを有効化すると、同時に実行する読み取りクエリの増加に対応するためにクラスタ容量が必要になった場合に、自動的に容量が追加されます。同時実行スケーリングにはリージョンとクエリに関する考慮事項があります。詳細については、同時実行スケーリングの候補に関する説明をご覧ください。
データセットとテーブルの構成
BigQuery には、データとテーブルを構成するために、パーティショニング、クラスタリング、データの局所性などの数多くの方法が提供されています。これらを使用して構成すると、大きなテーブルを維持し、クエリでの全体的なデータの読み込みと応答の時間を減らすことができるため、データ ワークロードの運用効率が向上します。
パーティショニング
パーティション分割テーブルは、パーティションと呼ばれるセグメントに分割されたテーブルです。このテーブルを使用すると、データの管理や照会が簡単になります。ユーザーは通常、大きなテーブルを多数のパーティションに分割します。各パーティションには 1 日分のデータが格納されます。特定の日付範囲でクエリを実行すると、クエリごとに BigQuery がスキャンするデータ量を減らせるため、パーティション管理は BigQuery のパフォーマンスとコストを決定する重要な要因です。
BigQuery には次の 3 種類のテーブル分割があります。
- 取り込み時間で分割されたテーブル: データの取り込み時間に基づいてテーブルが分割されます。
- 列で分割されたテーブル:
TIMESTAMPまたはDATE列に基づいてテーブルが分割されます。 - 整数範囲で分割されたテーブル: 整数列に基づいて分割されたテーブルです。
列ベースで時間ごとにパーティション分割したテーブルでは、バインディングされた列の既存のデータ フィルタリングから独立したパーティションを意識する必要はありません。列ベースで時間ごとにパーティション分割したテーブルに書き込まれた新しいデータは、データの値に基づいて適切なパーティションに自動的に配信されます。同様に、パーティション分割する列のフィルタを表現するクエリを使用することでスキャンするデータの全体量を減らし、オンデマンド クエリのパフォーマンス向上とコスト削減が可能になります。
BigQuery の列ベースのパーティショニングは Amazon Redshift の列ベースのパーティショニングと類似していますが、理由は少し異なります。Amazon Redshift では列ベースのキー分散を使用することで、関連するデータを同一のコンピューティング ノード内に保存し、最終的に結合や集計で生じるデータ シャッフルを最小限にとどめようとします。BigQuery ではストレージをコンピューティングと分離することで、列ベースのパーティショニングを活用し、スロットがディスクから読み込むデータ量を最小限にとどめます。
スロット ワーカーがディスクからデータを読み込むと、BigQuery が最適なデータ シャーディングを自動的に判断し、BigQuery のメモリ内シャッフル サービスを使用してデータのパーティションを再設定します。
詳細については、パーティション分割テーブルの概要をご覧ください。
クラスタリングと並べ替えキー
Amazon Redshift では、テーブル列を指定するために複合並べ替えキーまたはインターリーブ並べ替えキーを使用できます。BigQuery では、テーブルをクラスタリングすることで、複合並べ替えキーを指定できます。BigQuery のクラスタ化テーブルでは、テーブルのスキーマで指定された列を最大 4 列まで使用してテーブルのデータを自動的に並べ替えるため、クエリのパフォーマンスが向上します。指定された列は、関連するデータを同じクラスタ内に配置するために使用されます。データの並べ替え順序は指定したクラスタリング列の順序で決まるので、クラスタリング列の順序は重要です。
クラスタリングは、フィルタ句を使用するクエリやデータを集計するクエリなど、特定タイプのクエリのパフォーマンスを向上させることができます。クエリジョブまたは読み込みジョブによってデータがクラスタ化テーブルに書き込まれると、BigQuery はクラスタリング列の値を使用してデータを自動的に並べ替えます。これらの値は、BigQuery ストレージ内の複数のブロックにデータを整理するために使用されます。クラスタリング列に基づいてデータをフィルタする句を含むクエリを送信すると、BigQuery は並べ替えられたブロックを使用して不要なデータのスキャンを省略します。
同様に、クラスタリング列の値に基づいてデータを集計するクエリを送信すると、ブロックの並べ替えによって類似の値を持つ行が同じ場所に配置されるため、パフォーマンスが向上します。
次の状況では、クラスタリングを使用します。
- Amazon Redshift テーブルに複合並べ替えキーを構成している。
- クエリで、特定の列に対するフィルタリングまたは集計を構成している。
クラスタリングとパーティショニングを併用すると、データは日付列、タイムスタンプ列、または整数列でパーティション分割された後、異なる列のセットにクラスタ化されます(クラスタ化される列は最大 4 列)。この場合、各パーティション内のデータはクラスタリング列の値に基づいてクラスタ化されます。
Amazon Redshift でテーブルの並べ替えキーを指定すると、システムの負荷に応じて、クラスタのコンピューティング容量を使用して並べ替えが自動的に開始されます。大量のデータを読み込んだ後のように、テーブルデータをできる限り早く完全に並べ替えたい場合は、VACUUM コマンドの手動での実行も必要になることがあります。BigQuery では、この並べ替えが自動的に処理され、割り当てられた BigQuery スロットは使用されないため、クエリのパフォーマンスに影響はありません。
クラスタ化テーブルの操作について詳しくは、クラスタ化テーブルの概要をご覧ください。
分散キー
Amazon Redshift では、クエリを実行するデータブロックの場所を分散キーによって最適化します。BigQuery では、クエリの実行中にクエリプランにステージを決定、追加することで、クエリワーカー全体のデータ分散が向上するため、分散キーは使用しません。
外部ソース
Amazon Redshift Spectrum を使用して Amazon S3 のデータをクエリしている場合は、同じように BigQuery の外部データソース機能を使用して、Cloud Storage 上のファイルからデータを直接クエリできます。
BigQuery では、Cloud Storage 内のデータをクエリするだけでなく、次のプロダクトから直接クエリするために連携クエリ関数が提供されています。
- Cloud SQL(フルマネージドの MySQL または PostgreSQL)
- Bigtable(フルマネージド NoSQL)
- Google ドライブ(CSV、JSON、Avro、スプレッドシート)
データの局所性
BigQuery ではリージョンとマルチリージョンのどちらのロケーションにもデータベースを作成できますが、Amazon Redshift で使用できるロケーションはリージョンのみです。BigQuery ではリクエストで参照されるデータセットに基づいて、読み込み、クエリ、抽出を実行するロケーションを決定します。リージョン データセットとマルチリージョン データセットの操作について詳しくは、BigQuery のロケーションに関する考慮事項をご覧ください。
BigQuery データ型のマッピング
Amazon Redshift のデータ型は、BigQuery のデータ型と異なります。BigQuery のデータ型の詳細については、公式ドキュメントをご覧ください。
BigQuery は次のデータ型もサポートしています。これらのデータ型に直接対応する Amazon Redshift データ型はありません。
SQL の比較
GoogleSQL は SQL 2011 標準に対応しており、ネストされたデータと繰り返しデータのクエリをサポートする拡張機能があります。Amazon Redshift SQL は PostgreSQL に基づいていますが、異なる点もあります。詳細については Amazon Redshift のドキュメントをご覧ください。Amazon Redshift と GoogleSQL の構文と関数の詳細な比較については、Amazon Redshift SQL 変換ガイドをご覧ください。
バッチ SQL トランスレータを使用して、スクリプトやその他の SQL コードを現在のプラットフォームから BigQuery に変換できます。
移行後
BigQuery を念頭に置いて設計されていないスクリプトを移行した場合は、ここで BigQuery 向けにクエリのパフォーマンスを最適化するテクニックを使用できます。詳細については、クエリ パフォーマンスの最適化の概要をご覧ください。