Migração do Amazon Redshift para o BigQuery: visão geral
Neste documento, apresentamos orientações sobre a migração do Amazon Redshift para o BigQuery, com foco nos seguintes tópicos:
- Estratégias de migração
- Práticas recomendadas para a otimização de consultas e modelagem dos dados
- Dicas de solução de problemas
- Orientações para a adoção do usuário
Os objetivos deste documento são os seguintes:
- Fornecer orientação de alto nível para organizações que estão migrando do Amazon Redshift para o BigQuery, incluindo a ajuda para repensar data pipelines existentes para aproveitar o BigQuery ao máximo.
- Ajudar a comparar as arquiteturas do BigQuery e o Amazon Redshift para determinar como implementar recursos e funcionalidades durante a migração. O objetivo aqui é mostrar novos recursos disponíveis para sua organização por meio do BigQuery, e não mapear os recursos um para um com o Redshift.
Este documento é destinado a arquitetos corporativos, administradores de bancos de dados, desenvolvedores de aplicativos e especialistas em segurança de TI. Este guia supõe que você esteja familiarizado com o Amazon Redshift.
Também é possível usar tradução de SQL em lote para migrar os scripts SQL em massa ou a tradução de SQL interativo para traduzir consultas ad hoc. O SQL do Amazon Redshift é totalmente compatível com os dois serviços de tradução de SQL.
Tarefas anteriores à migração
Para ajudar a garantir uma migração bem-sucedida de data warehouses, comece a planejar sua estratégia de migração antecipadamente, no cronograma do seu projeto. Essa abordagem permite que você avalie os recursos do Google Cloud que atendam às suas necessidades.
Planejamento de capacidade
O BigQuery usa slots para medir a capacidade de análise. Um slot do BigQuery é a unidade reservada de capacidade computacional do Google necessária para executar consultas SQL. O BigQuery calcula continuamente quantos slots são necessários para as consultas enquanto elas são executadas, mas aloca slots para consultas com base em um programador justo.
É possível escolher entre os seguintes modelos de preços ao planejar a capacidade dos slots do BigQuery:
- Preços sob demanda: o BigQuery cobra pelo número de bytes processados (tamanho dos dados) sob demanda, então você paga apenas pelas consultas que executa. Para mais informações sobre como o BigQuery determina o tamanho dos dados, consulte Cálculo do tamanho dos dados. Como os slots determinam a capacidade computacional subjacente, é possível pagar pelo uso do BigQuery de acordo com o número de slots necessários, em vez de por bytes processados. Por padrão, todos os projetos do Google Cloud têm um limite máximo de 2.000 slots. O BigQuery pode ultrapassar esse limite para acelerar suas consultas, embora não haja garantia de bursting.
- Preços baseados em capacidade : Com preços baseados em capacidade, você compra reservas de Slot do BigQuery (no mínimo 100), em vez de pagar pelos bytes processados pelas consultas executadas. Recomendamos o preço baseado em capacidade para cargas de trabalho de data warehouse corporativas, que geralmente têm várias consultas simultâneas de relatório e de extração-carregamento-transformação (ELT) com consumo previsível.
Para ajudar na estimativa de slots, recomendamos configurar o monitoramento do BigQuery usando o Cloud Monitoring e analisar seus registros de auditoria usando o BigQuery. Use o Looker Studio (veja um exemplo de código aberto de um painel do Looker Studio) ou Looker para visualizar dados de registro de auditoria do BigQuery, especificamente para uso de slots em consultas e projetos. Também é possível usar os dados de tabelas do sistema do BigQuery para monitorar o uso de slots em jobs e reservas. Veja o exemplo de código aberto de um painel do Looker Studio. Monitorar e analisar regularmente a utilização de slots ajuda a estimar o número total de slots de que sua organização precisa à medida que seu uso do Google Cloud aumenta.
Por exemplo, suponha que você reserve inicialmente 4.000 slots do BigQuery para executar 100 consultas de média complexidade simultaneamente. Se você perceber que há longos tempos de espera nos planos de execução das consultas e os painéis mostram uma alta taxa de utilização de slots, talvez você precise de mais slots do BigQuery para dar suporte às cargas de trabalho. Se você quiser comprar slots por conta própria com compromissos anuais ou de três anos, comece a usar as reservas do BigQuery usando o console do Google Cloud ou a ferramenta de linha de comando bq. Para mais detalhes sobre o gerenciamento de cargas de trabalho, a execução de consultas e a arquitetura do BigQuery, consulte Migração para o Google Cloud: uma visualização detalhada.
Security in Google Cloud
As seções a seguir descrevem controles de segurança comuns do Amazon Redshift e como ajudar a garantir a proteção do data warehouse em um ambiente do Google Cloud.
Gestão de identidade e acesso
A configuração de controles de acesso no Amazon Redshift envolve a criação de políticas de permissões da API Amazon Redshift e a anexação delas a identidades do Identity and Access Management (IAM). As permissões da API Amazon Redshift fornecem acesso no nível do cluster, mas não fornecem níveis de acesso mais granulares que o cluster. Se o objetivo for um acesso mais granular a recursos como tabelas ou visualizações, use as contas de usuário no banco de dados do Amazon Redshift.
O BigQuery usa o IAM para gerenciar o acesso a recursos em um nível mais granular. Os tipos de recursos disponíveis no BigQuery são organizações, projetos, conjuntos de dados, tabelas, colunas e visualizações. Na hierarquia de políticas de IAM, conjuntos de dados são recursos filhos de projetos. Uma tabela herda permissões do conjunto de dados que a contém.
Para conceder acesso a um recurso, atribua um ou mais papéis de IAM a um usuário, um grupo ou uma conta de serviço. Os papéis de organização e de projeto afetam a capacidade de executar jobs ou gerenciar o projeto. Por outro lado, os papéis de conjunto de dados afetam a capacidade de acessar ou modificar os dados dentro de um projeto.
O IAM fornece estes tipos de papéis:
- Papéis predefinidos, que oferecem suporte a casos de uso comuns e padrões de controle de acesso.
- Papéis personalizados, que fornecem acesso granular conforme uma lista de permissões especificada pelo usuário.
No IAM, o BigQuery fornece o controle de acesso no nível da tabela. As permissões no nível da tabela determinam os usuários, grupos e contas de serviço que podem acessar uma tabela ou visualização. É possível conceder a um usuário acesso a tabelas ou visualizações específicas sem expandir isso ao inteiro conjunto de dados. Para um acesso mais granular, também é possível implementar um ou mais dos seguintes mecanismos de segurança:
- Controle de acesso no nível da coluna, que fornece acesso detalhado a colunas confidenciais usando tags de política ou classificação de dados baseada em tipos.
- Mascaramento dinâmico de dados no nível da coluna, que permite ocultar os dados da coluna seletivamente para grupos de usuários, além de permitir o acesso à coluna.
- Segurança no nível da linha, que permite filtrar dados e acessar linhas específicas em uma tabela, com base nas condições de qualificação do usuário.
Criptografia de disco completo
Além do gerenciamento de identidade e acesso, a criptografia adiciona uma camada extra de defesa para proteger os dados. No caso de exposição, os dados criptografados ficam ilegíveis.
No Amazon Redshift, a criptografia de dados em repouso e em trânsito não está ativada por padrão. A criptografia de dados em repouso precisa ser ativada explicitamente quando um cluster é iniciado, ou modificando um cluster atual para que ele use a criptografia do Serviço de gerenciamento de chaves AWS. A criptografia de dados em trânsito também precisa ser ativada explicitamente.
O BigQuery criptografa todos os dados em repouso e em trânsito por padrão, independentemente da origem ou de qualquer outra condição, e isso não pode ser desativado. O BigQuery também oferece suporte a chaves de criptografia gerenciadas pelo cliente (CMEK), se o objetivo é controlar e gerenciar chaves de criptografia no Cloud Key Management Service.
Para mais informações sobre criptografia no Google Cloud, consulte os artigos sobre criptografia de dados em repouso e criptografia de dados em trânsito.
Para dados em trânsito no Google Cloud, os dados são criptografados e autenticados quando saem dos limites físicos controlados pelo Google ou em nome dele. Dentro desses limites, em geral, os dados em trânsito são autenticados, mas não necessariamente criptografados.
Prevenção contra perda de dados
Talvez os requisitos de conformidade limitem quais dados podem ser armazenados no Google Cloud. Use a Proteção de dados confidenciais para verificar as tabelas do BigQuery e detectar e classificar dados confidenciais. Se dados confidenciais forem detectados, as transformações de desidentificação da Proteção de dados confidenciais poderão mascarar, excluir ou ocultar esses dados.
Migração para o Google Cloud: noções básicas
Use esta seção para saber mais sobre como usar ferramentas e pipelines para ajudar na migração.
Ferramentas de migração
O serviço de transferência de dados do BigQuery fornece uma ferramenta automatizada para migrar diretamente esquemas e dados do Amazon Redshift para o BigQuery. A tabela a seguir lista outras ferramentas para ajudar na migração do Amazon Redshift para o BigQuery:
| Ferramenta | Objetivo |
|---|---|
| Serviço de transferência de dados do BigQuery | Faça uma transferência em lote automatizada dos dados do Amazon Redshift para o BigQuery usando esse serviço totalmente gerenciado. |
| Serviço de transferência do Cloud Storage | Importe rapidamente os dados do Amazon S3 para o Cloud Storage e configure uma programação recorrente para transferir dados usando esse serviço totalmente gerenciado. |
gcloud |
Copie arquivos do Amazon S3 para o Cloud Storage usando essa ferramenta de linha de comando. |
| Ferramenta de linha de comando bq | Interaja com o BigQuery usando essa ferramenta de linha de comando. As interações comuns incluem a criação de esquemas de tabelas do BigQuery, o carregamento de dados do Cloud Storage em tabelas e a execução de consultas. |
| Bibliotecas de cliente do Cloud Storage | Copie arquivos do Amazon S3 para o Cloud Storage usando uma ferramenta personalizada, criada com base na biblioteca de cliente do Cloud Storage. |
| Bibliotecas de cliente do BigQuery | Interaja com o BigQuery usando uma ferramenta personalizada, criada com base na biblioteca de cliente do BigQuery. |
| Programador de consultas do BigQuery | Programe consultas SQL recorrentes usando o recurso integrado do BigQuery. |
| Cloud Composer | Faça a orquestração de transformações e jobs de carregamento do BigQuery usando esse ambiente totalmente gerenciado do Apache Airflow. |
| Apache Sqoop | Envie jobs do Hadoop usando o driver JDBC do Sqoop e do Amazon Redshift para extrair dados do Amazon Redshift para o HDFS ou Cloud Storage. O Sqoop é executado em um ambiente Dataproc. |
Para mais informações sobre como usar o serviço de transferência de dados do BigQuery, consulte Migrar esquema e dados do Amazon Redshift.
Migração usando pipelines
A migração de dados do Amazon Redshift para o BigQuery pode seguir caminhos diferentes, com base nas ferramentas de migração disponíveis. Embora a lista desta seção não seja completa, ela fornece uma noção dos diferentes padrões de pipeline disponíveis ao mover os dados.
Para mais informações de alto nível sobre a migração de dados para o BigQuery usando pipelines, consulte Migrar data pipelines.
Extração e carregamento (EL)
É possível automatizar totalmente um pipeline EL usando o serviço de transferência de dados do BigQuery, que pode copiar automaticamente os esquemas e dados de tabelas do cluster do Amazon Redshift para o BigQuery. Se o objetivo for mais controle sobre as etapas do pipeline, crie um pipeline usando as opções descritas nas seções a seguir.
Usar extratos de arquivos do Amazon Redshift
- Exportar dados do Amazon Redshift para o Amazon S3.
Copie os dados do Amazon S3 para o Cloud Storage usando uma das seguintes opções:
Carregue os dados do Cloud Storage no BigQuery usando qualquer uma das seguintes opções:
Usar uma conexão JDBC do Amazon Redshift
Use um dos seguintes produtos do Google Cloud para exportar dados do Amazon Redshift usando o driver JDBC do Amazon Redshift:
-
- Modelo fornecido pelo Google: JDBC para BigQuery
-
Conecte-se ao Amazon Redshift com o JDBC usando o Apache Spark
Usar o Sqoop e o driver JDBC do Amazon Redshift para extrair dados do Amazon Redshift para o Cloud Storage
Extração, transformação e carregamento (ETL)
Se você quiser transformar alguns dados antes de carregá-los no BigQuery, siga as mesmas recomendações de pipeline descritas na seção Extrair e carregar (EL), adicionando uma etapa para transformar os dados antes de carregá-los no BigQuery.
Usar extratos de arquivos do Amazon Redshift
Copie os dados do Amazon S3 para o Cloud Storage usando uma das seguintes opções:
Transforme e carregue seus dados no BigQuery usando qualquer uma das opções a seguir:
-
- Ler do Cloud Storage
- gravar no BigQuery
- Modelo fornecido pelo Google: Texto do Cloud Storage para o BigQuery
Usar uma conexão JDBC do Amazon Redshift
Use qualquer um dos produtos descritos na seção Extrair e carregar (EL), adicionando uma etapa para transformar os dados antes de carregá-los no BigQuery. Modifique o pipeline para introduzir uma ou mais etapas para transformar os dados antes de gravá-los no BigQuery.
-
- Clone o código do modelo JDBC para BigQuery e modifique o modelo para adicionar transformações do Apache Beam.
-
- Transforme seus dados usando qualquer um dos plug-ins do CDAP.
Extração, carregamento e transformação (ELT)
Transforme seus dados usando o próprio BigQuery, com o uso de qualquer uma das opções Extrair e carregar (EL) para carregar os dados em uma tabela de preparo. Em seguida, transforme os dados nessa tabela de preparo usando as consultas SQL que gravam a saída delas na tabela de produção final.
Captura de dados alterados (CDC)
A captura de dados alterados é um dos vários padrões de design de software usados para acompanhar alterações de dados. Muitas vezes, ela é usada para armazenamento em data warehouse, já que este serve para agrupar e acompanhar dados e suas alterações de vários sistemas de origem ao longo do tempo.
Ferramentas de parceiros para a migração de dados
Há vários fornecedores na área de extração, transformação e carregamento (ETL). Consulte o site de parceiro do BigQuery para ver uma lista dos principais parceiros e as soluções que oferecem.
Migração para o Google Cloud: uma visualização detalhada
Use esta seção para saber mais sobre como a arquitetura do data warehouse, o esquema e o dialeto SQL afetam a migração.
Comparação da arquitetura
Tanto o BigQuery quanto o Amazon Redshift são baseados em uma arquitetura de processamento paralelo em massa (MPP). As consultas são distribuídas em vários servidores para acelerar a execução. Em relação à arquitetura do sistema, o Amazon Redshift e o BigQuery diferem principalmente em como os dados são armazenados e como as consultas são executadas. No BigQuery, o hardware e as configurações subjacentes são abstraídos. O armazenamento e computação permitem que seu data warehouse cresça sem nenhuma intervenção.
Computação, memória e armazenamento
No Amazon Redshift, o armazenamento de CPU, memória e disco é interligado por meio de nós de computação, conforme ilustrado no diagrama da documentação do Amazon Redshift. O desempenho do cluster e a capacidade de armazenamento são determinados pelo tipo e pela quantidade dos nós de computação, que precisam ser configurados. Para alterar a capacidade de computação ou armazenamento, é necessário redimensionar o cluster usando um processo (de algumas horas ou até dois dias ou mais) que cria um novo cluster e copia os dados para ele. O Amazon Redshift também oferece nós RA3 com armazenamento gerenciado que ajudam a separar a computação do armazenamento. O maior nó na categoria RA3 limita a 64 TB o armazenamento gerenciado para cada nó.
Desde o início, o BigQuery não vincula computação, memória e armazenamento, mas trata cada um separadamente.
A computação do BigQuery é definida por slots, uma unidade que expressa a capacidade computacional necessária para executar consultas. O Google gerencia toda a infraestrutura incorporada em um slot, deixando para você apenas a tarefa de escolher a quantidade adequada de slots para as cargas de trabalho do BigQuery. Consulte o planejamento de capacidade para saber como decidir quantos slots são necessários para seu data warehouse. A memória do BigQuery é fornecida por um serviço distribuído remotamente, conectado a slots de computação pela rede de petabits do Google, que é responsável pelo gerenciamento de tudo.
Tanto o BigQuery quanto o Amazon Redshift usam o armazenamento em colunas, mas o BigQuery usa variações e avanços nesse tipo de armazenamento. Durante a codificação das colunas, várias estatísticas sobre os dados são mantidas e, posteriormente, usadas durante a execução da consulta, para compilar planos ideais e escolher o algoritmo de ambiente de execução mais eficiente. O BigQuery armazena os dados no sistema de arquivos distribuídos do Google, onde eles são compactados, criptografados, replicados e distribuídos automaticamente. Tudo isso sem afetar a capacidade de computação disponível para as consultas. Separar o armazenamento da computação permite escalonar verticalmente dezenas de petabytes de armazenamento sem complicações ou necessidade de outros recursos de computação caros. Há também vários outros benefícios de separar a computação do armazenamento.
Escalonamento vertical ou decrescente
Quando houver uma restrição no armazenamento ou computação, os clusters do Amazon Redshift precisam ser redimensionados modificando a quantidade ou os tipos de nós no cluster.
Quando você redimensiona um cluster do Amazon Redshift, há duas abordagens:
- Redimensionamento clássico: o Amazon Redshift cria um cluster onde os dados são copiados, em um processo que pode levar algumas horas ou até dois dias ou mais, no caso de grandes quantidades de dados.
- Redimensionamento elástico: se apenas o número de nós forem alterados, as consultas serão pausadas temporariamente e as conexões serão mantidas abertas, se possível. Durante a operação de redimensionamento, o cluster ficará disponível somente para leitura. O redimensionamento elástico normalmente leva de 10 a 15 minutos, mas pode não estar disponível para todas as configurações.
Como o BigQuery é uma plataforma como serviço (PaaS), você só precisa se preocupar com o número de slots dele que quer reservar para sua organização. Os slots do BigQuery disponibilizados em reservas, onde é possível atribuir projetos. Para saber como configurar essas reservas, consulte Planejamento de capacidade.
Execução da consulta
O mecanismo de execução do BigQuery é semelhante ao do Amazon Redshift, visto que os dois organizam a consulta ao dividi-la em etapas (um plano de consulta), executando essas etapas (ao mesmo tempo, quando possível) e, em seguida, remontando os resultados. O Amazon Redshift gera um plano de consulta estático, diferente do BigQuery, que otimiza dinamicamente os planos de consulta à medida que a consulta é executada. O BigQuery embaralha os dados usando o serviço de memória remota, enquanto o Amazon Redshift faz isso usando a memória local do nó de computação. Para saber mais sobre o armazenamento de dados intermediários do BigQuery a partir dos vários estágios do seu plano de consulta, veja Execução de consultas na memória do Google BigQuery.
Gerenciamento de cargas de trabalho no BigQuery
O BigQuery oferece os seguintes controles para o gerenciamento de cargas de trabalho (WLM):
- Consultas interativas, que são executadas assim que possível (essa é a configuração padrão).
- Consultas em lote, que aguardam na fila em seu nome e são iniciadas assim que os recursos inativos ficam disponíveis no pool de recursos compartilhados do BigQuery.
Reservas de slots por meio de preços baseados em capacidade. Em vez de pagar por consultas sob demanda, é possível criar e gerenciar dinamicamente buckets de slots chamados reservas e atribuir projetos, pastas ou organizações a essas reservas. É possível comprar compromissos de slots do BigQuery (a partir de no mínimo 100) em compromissos flexíveis, mensais ou anuais para ajudar a minimizar custos. Por padrão, as consultas em execução em uma reserva usam automaticamente slots ociosos de outras reservas.
Considerando o diagrama a seguir, suponha que você tenha comprado uma capacidade de compromisso total de 1.000 slots para compartilhar entre três tipos de cargas de trabalho: ciência de dados, ELT e Business Intelligence (BI). Para oferecer suporte a essas cargas de trabalho, você pode fazer o seguinte:
- criar uma reserva ds com 500 slots e atribuir todos os projetos de ciência de dados do Google Cloud a ela;
- criar uma reserva elt com 300 slots e atribuir os projetos em que cargas de trabalho de ELT são utilizadas a ela;
- criar uma reserva bi com 200 slots e atribuir projetos conectados às suas ferramentas de BI a ela.
Veja essa configuração no gráfico abaixo:
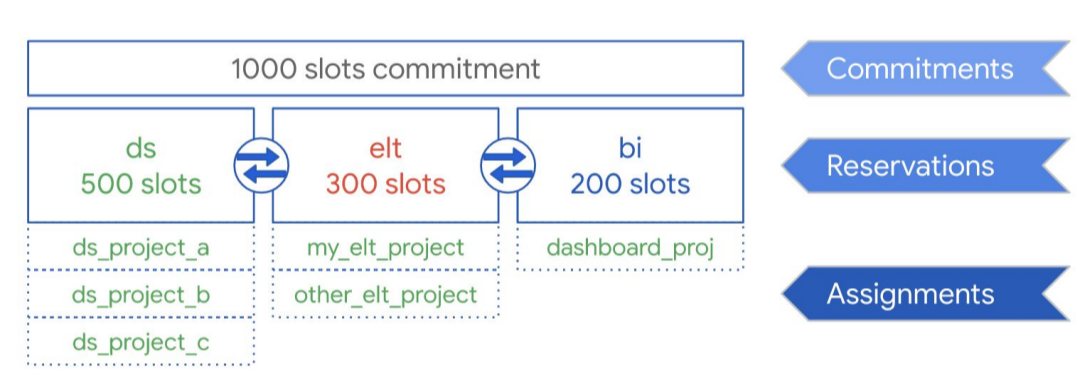
Em vez de distribuir reservas para as cargas de trabalho da sua organização, como produção e teste, por exemplo, atribua reservas a equipes ou departamentos individuais, dependendo do caso de uso.
Para mais informações, consulte Gerenciamento de carga de trabalho usando as reservas.
Gerenciamento de cargas de trabalho no Amazon Redshift
O Amazon Redshift oferece dois tipos de gerenciamento de cargas de trabalho (WLM):
- Automático: com o WLM automático, o Amazon Redshift gerencia a simultaneidade das consultas e a alocação de memória. Até oito filas são criadas com os identificadores de classe de serviço, de 100 a 107. O WLM automático determina a quantidade de recursos necessários para as consultas e ajusta a simultaneidade com base na carga de trabalho. Para mais informações, consulte Prioridade de consultas.
- Manual: o WLM manual exige que você especifique valores para a simultaneidade das consultas e alocação de memória. O padrão para o WLM manual é a simultaneidade de cinco consultas, e a memória é dividida igualmente entre elas.
Quando o escalonamento de simultaneidade está ativado, o Amazon Redshift adicionará automaticamente uma capacidade de cluster extra quando for necessário processar um aumento nas consultas de leitura simultâneas. O escalonamento de simultaneidade tem algumas considerações regionais e de consulta. Para mais informações, consulte Candidatos ao escalonamento de simultaneidade.
Configurações de conjuntos de dados e tabelas
O BigQuery oferece várias maneiras de configurar dados e tabelas, como particionamento, clustering e localidade de dados. Essas configurações podem ajudar a manter tabelas grandes e a reduzir o tempo geral de carregamento dos dados e de resposta das consultas, aumentando assim a eficiência operacional das cargas de trabalho dos dados.
Particionamento
Uma tabela particionada é dividida em segmentos, chamados de partições, que facilitam a consulta e o gerenciamento dos dados. Normalmente, os usuários dividem tabelas grandes em várias partições menores, cada um contendo os dados referentes a um dia. O gerenciamento de partições é um fator determinante para o desempenho e o custo do BigQuery quando consultas são feitas ao longo de um período específico, porque isso ajuda o BigQuery a verificar menos dados por consulta.
Há três tipos de particionamento de tabelas no BigQuery:
- Tabelas particionadas por tempo de ingestão: particionamento com base no tempo de ingestão de dados.
- Tabelas particionadas por coluna:
particionamento com base em uma coluna
TIMESTAMPouDATE. - Tabelas particionadas por intervalo de números inteiros: particionamento com base em uma coluna de número inteiro.
Uma tabela particionada por tempo com base em colunas elimina a necessidade de manter o reconhecimento de partição independente da filtragem de dados atual na coluna vinculada. Os dados gravados em uma tabela particionada por tempo com base em colunas são entregues automaticamente à partição adequada, com base no valor dos dados. Da mesma forma, as consultas que expressam filtros na coluna de particionamento podem reduzir a quantidade geral de dados verificados, o que pode melhorar o desempenho e reduzir o custo das consultas sob demanda.
O particionamento baseado em colunas do BigQuery é semelhante ao seu equivalente do Amazon Redshift, com uma motivação um pouco diferente. O Amazon Redshift usa a distribuição de chaves com base em colunas para tentar manter os dados relacionados armazenados no mesmo nó de computação, minimizando o embaralhamento de dados que ocorre durante as mesclagens e agregações. O BigQuery separa o armazenamento da computação. Portanto, ele aproveita o particionamento baseado em colunas para minimizar a quantidade de dados que os slots leem do disco.
Depois que os workers do slot leem os dados do disco, o BigQuery pode determinar automaticamente o nível ideal de fragmentação dos dados e reparticioná-los rapidamente usando o serviço de embaralhamento na memória do BigQuery.
Para mais informações, consulte Introdução a tabelas particionadas.
Clustering e chaves de classificação
O Amazon Redshift oferece suporte à especificação de colunas de tabela como chaves de classificação compostas ou intercaladas. No BigQuery, é possível especificar chaves de classificação compostas fazendo o clustering de uma tabela. As tabelas em cluster do BigQuery melhoram o desempenho da consulta porque os dados da tabela são classificados automaticamente com base no conteúdo de até quatro colunas especificadas no esquema da tabela. Essas colunas são usadas para colocalizar dados relacionados. A ordem do clustering de colunas especificada é importante porque determina a ordem de classificação dos dados.
O clustering melhora o desempenho de determinados tipos de consultas, como as que usam cláusulas de filtro e as que agregam dados. Numa tabela em cluster, quando os dados são gravados por um job de consulta ou carregamento, o BigQuery os classifica automaticamente pelos valores no clustering de colunas. Esses valores são usados para organizar os dados em diversos blocos no armazenamento do BigQuery. Em uma consulta com cláusula que filtra dados de acordo com o clustering de colunas, o BigQuery usa os blocos classificados para eliminar verificações de dados desnecessários.
Da mesma forma, em uma consulta de dados agregados baseada nos valores no clustering de colunas, há uma melhora no desempenho porque os blocos classificados colocalizam linhas com valores semelhantes.
Use o clustering nas seguintes circunstâncias:
- Chaves de classificação compostas estão configuradas nas tabelas do Amazon Redshift.
- A filtragem ou a agregação estão configuradas em colunas específicas nas consultas.
Ao usar em conjunto o clustering e o particionamento, os dados são particionados por uma coluna de data, carimbo de data/hora ou número inteiro e, depois, agrupados em um conjunto diferente de colunas (até quatro colunas em cluster no total). Nesse caso, os dados de cada partição são agrupados no cluster com base nos valores das colunas de clustering.
Quando chaves de classificação são especificadas em tabelas do Amazon Redshift, dependendo da carga no sistema, o Amazon Redshift inicia a classificação automaticamente usando a capacidade de computação do próprio cluster. Talvez seja necessário até executar manualmente o comando
VACUUM
se o objetivo for classificar totalmente os dados da tabela o mais rápido possível, por exemplo, depois do carregamento de um grande volume de dados. O BigQuery
gerencia automaticamente essa classificação sem utilizar os slots alocados, o que não afeta o desempenho de nenhuma das consultas.
Para mais informações sobre como trabalhar com tabelas em cluster, consulte Introdução às tabelas em cluster.
Chaves de distribuição
O Amazon Redshift usa chaves de distribuição para otimizar a localização dos blocos de dados para executar as consultas. O BigQuery não usa chaves de distribuição porque automaticamente determina e adiciona estágios em um plano de consulta enquanto a consulta está em execução, para melhorar a distribuição de dados em todos os workers de consulta.
Origens externas
Se você usa o Amazon Redshift Spectrum para consultar dados no Amazon S3, o recurso de fonte de dados externa do BigQuery pode ser similarmente utilizado para consultar dados diretamente dos arquivos no Cloud Storage.
Além de consultar dados no Cloud Storage, o BigQuery oferece funções de consulta federada para consultar diretamente dos seguintes produtos:
- Cloud SQL (MySQL ou PostgreSQL totalmente gerenciado)
- Bigtable (NoSQL totalmente gerenciado)
- Google Drive (CSV, JSON, Avro, Planilhas)
Localidade dos dados
É possível criar os conjuntos de dados do BigQuery em locais regionais e multirregionais, enquanto o Amazon Redshift só oferece a opção de locais regionais. O BigQuery determina o local onde executar os jobs de carregamento, consulta ou exportação com base nos conjuntos de dados referenciados na solicitação. Consulte as considerações sobre localização no BigQuery para ver dicas sobre como trabalhar com conjuntos de dados regionais e multirregionais.
Mapeamento do tipo de dados no BigQuery
Os tipos de dados do Amazon Redshift diferem dos do BigQuery. Para mais detalhes sobre os tipos de dados do BigQuery, consulte a documentação oficial.
O BigQuery também é compatível com os seguintes tipos de dados, que não têm um análogo direto do Amazon Redshift:
Comparação do SQL
O GoogleSQL está em conformidade com o padrão SQL 2011 e tem extensões compatíveis com a consulta de dados aninhados e repetidos. O SQL do Amazon Redshift é baseado no PostgreSQL, mas tem várias diferenças, que são detalhadas na documentação do Amazon Redshift. Para ver uma comparação detalhada entre as sintaxes e funções do Amazon Redshift e do GooglSQL, consulte o Guia de tradução do SQL do Amazon Redshift.
É possível usar o tradutor de SQL em lote para converter scripts e outros códigos SQL da plataforma atual no BigQuery.
Pós-migração
Se scripts não projetados com o BigQuery em mente forem migrados, é possível implementar técnicas para otimizar o desempenho da consulta no BigQuery. Para mais informações, consulte Introdução à otimização do desempenho da consulta.
A seguir
- Veja instruções passo a passo para migrar o esquema e os dados do Amazon Redshift.
- Veja instruções detalhadas para migrar o Amazon Redshift para o BigQuery com a VPC.