Migration von Oracle zu BigQuery
Dieses Dokument bietet eine allgemeine Anleitung für die Migration von Oracle zu BigQuery. Es werden die grundlegenden Architekturunterschiede beschrieben und Möglichkeiten für die Migration zu BigQuery von Data Warehouses und Data-Marts vorgeschlagen, die auf Oracle RDBMS (einschließlich Exadata) ausgeführt werden. Dieses Dokument enthält Details, die auch auf Exadata, ExaCC und Oracle Autonomous Data Warehouse angewendet werden können, da sie kompatible Oracle-Software verwenden.
Dieses Dokument richtet sich an Unternehmensarchitekten, Datenbankadministratoren, Anwendungsentwickler und IT-Sicherheitsexperten, die von Oracle zu BigQuery migrieren und technische Herausforderungen im Migrationsprozess lösen möchten.
Verwenden Sie die Batch-SQL-Übersetzung, um Ihre SQL-Skripts im Bulk zu migrieren, oder die interaktive SQL-Übersetzung, um Ad-hoc-Abfragen zu übersetzen. Oracle SQL, PL/SQL und Exadata werden von beiden Tools in der Vorabversion unterstützt.
Vor der Migration
Um eine erfolgreiche Data Warehouse-Migration zu gewährleisten, sollten Sie Ihre Migrationsstrategie frühzeitig im Zeitplan Ihres Projekts planen. Weitere Informationen zur systematischen Planung Ihrer Migration finden Sie unter Was und wie migrieren: der Migrations-Framework.
BigQuery-Kapazitätsplanung
Der Analysedurchsatz in BigQuery wird in Slots gemessen. Ein BigQuery-Slot ist die proprietäre Rechenkapazität von Google, die zum Ausführen von SQL-Abfragen erforderlich ist.
BigQuery berechnet kontinuierlich, wie viele Slots von den Abfragen benötigt werden, während es Abfragen ausführt. Es ordnet aber basierend auf einem fairen Planer Slots zu.
Bei der Kapazitätsplanung für BigQuery-Slots können Sie zwischen den folgenden Preismodellen wählen:
On-Demand-Preis: Bei On-Demand-Preisen berechnet BigQuery die Anzahl der verarbeiteten Byte (Datengröße), sodass Sie nur für die ausgeführten Abfragen zahlen. Weitere Informationen dazu, wie BigQuery die Datengröße bestimmt, finden Sie unter Datengrößenberechnung. Da Slots die zugrunde liegende Rechenkapazität bestimmen, können Sie für die BigQuery-Nutzung abhängig von der Anzahl der benötigten Slots (statt der verarbeiteten Byte) bezahlen. Standardmäßig sind Google Cloud Projekte auf maximal 2.000 Slots beschränkt.
Kapazitätsbasierte Preise: Bei kapazitätsbasierten Preisen erwerben Sie BigQuery-Slot-Reservierungen (mindestens 100), statt für die Byte zu bezahlen, die von ausgeführten Abfragen verarbeitet werden. Wir empfehlen kapazitätsbasierte für Data Warehouse-Arbeitslasten in Unternehmen, bei denen häufig viele Abfragen für gleichzeitige Berichterstellung und ELT (Extract-Load-Transform) vorliegen, die vorhersehbar sind.
Um die Slot-Schätzung zu unterstützen, empfehlen wir die Einrichtung von BigQuery-Monitoring mit Cloud Monitoring und die Analyse Ihrer Audit-Logs mit BigQuery. Viele Kunden nutzen Looker Studio (sehen Sie sich etwa ein Open Source-Beispiel eines Looker Studio-Dashboards an), Looker oder Tableau als Front-Ends zur Visualisierung von BigQuery-Audit-Logdaten, insbesondere für die Slot-Nutzung über Abfragen und Projekte hinweg. Außerdem können Sie die Systemtabellendaten von BigQuery verwenden, um die Slot-Auslastung für Jobs und Reservierungen zu überwachen. Sehen Sie sich zur Verdeutlichung ein Open Source-Beispiel eines Looker Studio-Dashboards an.
Durch regelmäßiges Monitoring und Analyse der Slot-Auslastung können Sie abschätzen, wie viele Slots Ihr Unternehmen benötigt, während Sie in Google Cloudwachsen.
Beispiel: Sie reservieren zuerst 4.000 BigQuery-Slots, um 100 Abfragen mit mittlerer Komplexität gleichzeitig auszuführen. Wenn Sie in den Ausführungsplänen Ihrer Abfragen hohe Wartezeiten feststellen und Ihre Dashboards eine hohe Slot-Auslastung zeigen, kann dies darauf hindeuten, dass Sie zusätzliche BigQuery-Slots benötigen, um Ihre Arbeitslasten zu unterstützen. Wenn Sie Slots selbst über jährliche oder dreijährige Zusicherungen erwerben möchten, können Sie mit den BigQuery-Reservierungen in der Google Cloud -Konsole oder dem bq-Befehlszeilentool beginnen.
Wenden Sie sich bei Fragen zu Ihrem aktuellen Tarif und den vorherigen Optionen an Ihren Vertriebsmitarbeiter.
Sicherheit in Google Cloud
In den folgenden Abschnitten werden allgemeine Oracle-Sicherheitskontrollen beschrieben und wie Sie dafür sorgen können, dass Ihr Data Warehouse in einer Google Cloud-Umgebung geschützt ist.
Identity and Access Management (IAM)
Oracle bietet Nutzer, Berechtigungen, Rollen und Profile, um den Zugriff auf Ressourcen zu verwalten.
BigQuery verwendet die Identitäts- und Zugriffsverwaltung (Identity and Access Management, IAM), um den Zugriff auf Ressourcen zu verwalten. Außerdem bietet sie eine zentrale Zugriffsverwaltung für Ressourcen und Aktionen. In BigQuery stehen folgende Ressourcentypen zur Verfügung: Organisationen, Projekte, Datasets, Tabellen und Ansichten. In der Richtlinienhierarchie von IAM sind die Datasets die untergeordneten Ressourcen von Projekten. Eine Tabelle übernimmt die Berechtigungen des Datasets, das sie enthält.
Wenn Sie Zugriff auf eine Ressource gewähren möchten, weisen Sie einem Nutzer, einer Gruppe oder einem Dienstkonto eine oder mehrere Rollen zu. Die Rollen "Organisation" und "Projekt" wirken sich auf die Fähigkeit zum Ausführen von Jobs oder Verwalten des Projekts aus. Die Rolle "Dataset" wiederum wirkt sich auf die Fähigkeit aus, auf die Daten in einem Projekt zuzugreifen oder sie zu bearbeiten.
IAM bietet folgende Rollentypen:
- Vordefinierte Rollen sollen allgemeine Anwendungsfälle und Zugriffskontrollmuster unterstützen. Vordefinierte Rollen ermöglichen einen genau definierten Zugriff auf einen bestimmten Dienst und werden von Google Cloudverwaltet.
Zu einfachen Rollen gehören die Rollen „Inhaber“, „Bearbeiter“ und „Betrachter“.
Benutzerdefinierte Rollen ermöglichen einen genau definierten Zugriff gemäß einer vom Nutzer angegebenen Liste von Berechtigungen.
Wenn Sie einem Nutzer sowohl vordefinierte als auch einfache Rollen zuweisen, werden ihm die Berechtigungen beider Rollen gewährt.
Sicherheit auf Zeilenebene
Mit Oracle Label Security (OLS) können Sie den Datenzugriff Zeile für Zeile einschränken. Ein typischer Anwendungsfall für die Sicherheit auf Zeilenebene ist die Beschränkung des Zugriffs eines Vertriebsmitarbeiters auf die von ihm verwalteten Konten. Wenn Sie die Sicherheit auf Zeilenebene implementieren, erhalten Sie eine detaillierte Zugriffssteuerung.
Um die Sicherheit auf Zeilenebene in BigQuery zu erlangen, können Sie autorisierte Ansichten und Zugriffsrichtlinien auf Zeilenebene verwenden. Weitere Informationen zum Entwerfen und Implementieren dieser Richtlinien finden Sie unter Einführung in die BigQuery-Sicherheit auf Zeilenebene.
Festplattenverschlüsselung
Oracle bietet Transparente Datenverschlüsselung (Transparent Data Encryption, TDE) und Netzwerkverschlüsselung für die Verschlüsselung ruhender Daten und Daten während der Übertragung. Für TDE ist die Option „Erweiterte Sicherheit“ erforderlich, die separat lizenziert wird.
BigQuery verschlüsselt standardmäßig alle ruhenden Daten und Daten während der Übertragung unabhängig von der Quelle oder einer anderen Bedingung. Dies kann nicht deaktiviert werden. BigQuery unterstützt auch vom Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEK) für Nutzer, die Schlüsselverschlüsselungsschlüssel im Cloud Key Management Service steuern und verwalten möchten. Weitere Informationen zur Verschlüsselung in Google Cloudfinden Sie unter Standardverschlüsselung ruhender Daten und Verschlüsselung bei der Übertragung.
Datenmaskierung und ‑entfernung
Oracle verwendet die Datenmaskierung in Real Application Testing sowie die Datenentfernung, mit der Sie Daten maskieren (entfernen) können, die von Abfragen zurückgegeben werden, die von Anwendungen ausgegeben werden.
BigQuery unterstützt die dynamische Datenmaskierung auf Spaltenebene. Sie können die Datenmaskierung nutzen, um Spaltendaten für Nutzergruppen selektiv zu verdecken und dennoch Zugriff auf die Spalte zuzulassen.
Mit Sensitive Data Protection können Sie vertrauliche personenidentifizierbare Informationen (PII) in BigQuery identifizieren und entfernen.
BigQuery und Oracle im Vergleich
In diesem Abschnitt werden die wichtigsten Unterschiede zwischen BigQuery und Oracle beschrieben. Diese Hervorhebungen helfen Ihnen, Hürden bei der Migration zu identifizieren und die erforderlichen Änderungen einzuplanen.
Systemarchitektur
Einer der Hauptunterschiede zwischen Oracle und BigQuery liegt darin, dass BigQuery ein serverloses Cloud-EDW mit separaten Speicher- und Computing-Ebenen ist, die basierend auf den Anforderungen der Abfrage skaliert werden können. Aufgrund der Beschaffenheit des serverlosen BigQuery-Angebots sind Sie nicht durch Hardwareentscheidungen eingeschränkt. Stattdessen können Sie über Reservierungen mehr Ressourcen für Ihre Abfragen und Nutzer anfordern. BigQuery erfordert auch keine Konfiguration der zugrunde liegenden Software und Infrastruktur wie dem Betriebssystem, den Netzwerksystemen und Speichersystemen, einschließlich Skalierung und Hochverfügbarkeit. BigQuery kümmert sich um Skalierbarkeit, Verwaltung und administrative Vorgänge. Das folgende Diagramm veranschaulicht die BigQuery-Speicherhierarchie.
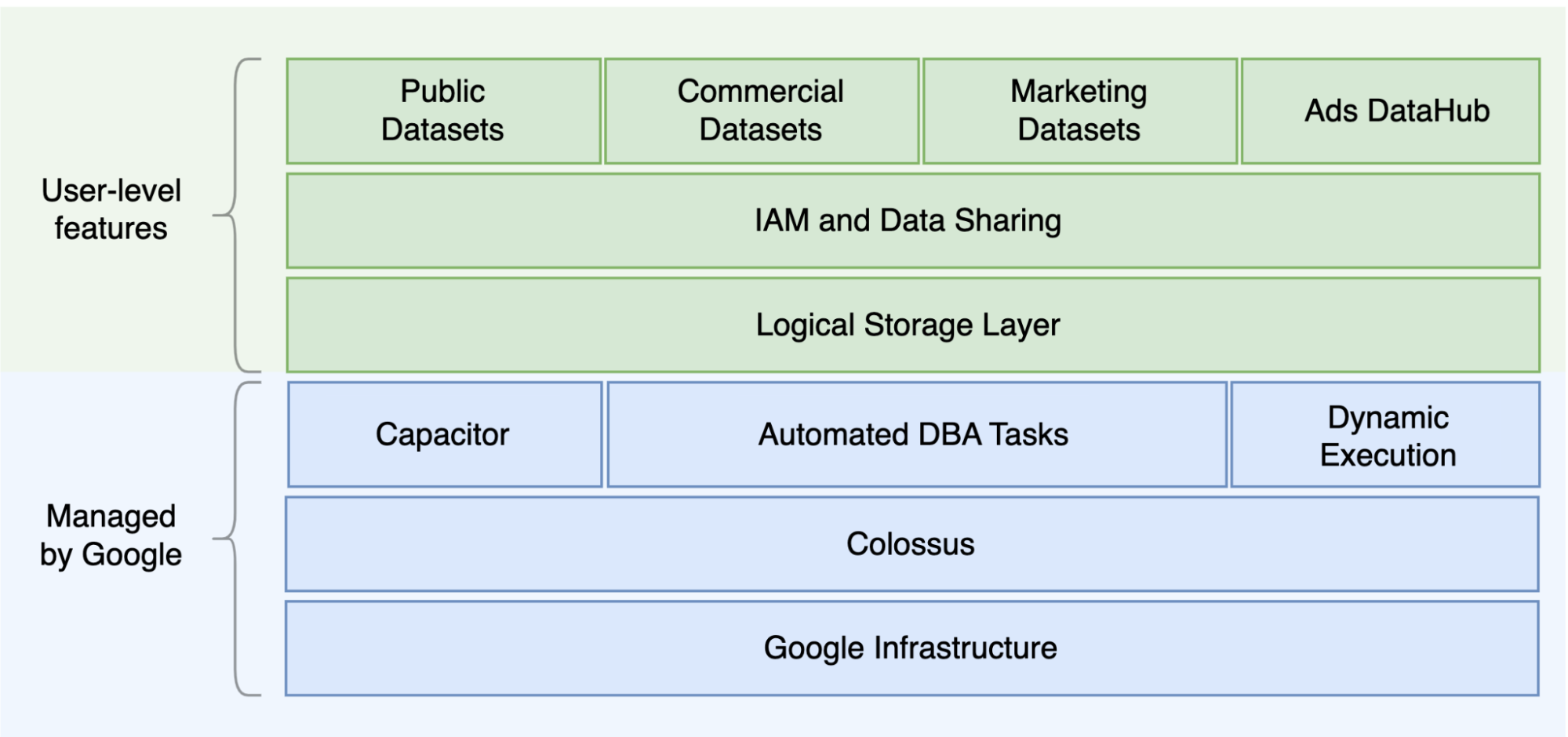
Wenn Sie die zugrunde liegende Architektur für Speicher und Abfrageverarbeitung kennen, z. B. die Trennung zwischen Speicher (Colossus) und Abfrageausführung (Dremel) und wieGoogle Cloud Ressourcen zuweist (Borg), können Sie Verhaltensunterschiede besser nachvollziehen und die Abfrageleistung und Kosteneffizienz optimieren. Weitere Informationen finden Sie in den Referenzarchitekturen für BigQuery, Oracle und Exadata.
Daten- und Speicherarchitektur
Die Daten- und Speicherstruktur ist ein wichtiger Bestandteil eines jeden Datenanalysesystems, da sie die Abfrageleistung, Kosten, Skalierbarkeit und Effizienz beeinflusst.
BigQuery entkoppelt Datenspeicher und Computing und speichert Daten in Colossus, wo Daten komprimiert und in einem Spaltenformat namens Capacitor gespeichert werden.
BigQuery arbeitet direkt mit komprimierten Daten, ohne sie mithilfe von Capacitor zu dekomprimieren. In BigQuery werden Datasets als Abstraktion der obersten Ebene verwendet, um den Zugriff auf Tabellen zu organisieren, wie im vorherigen Diagramm dargestellt. Schemas und Labels können für eine weitere Organisation von Tabellen verwendet werden. BigQuery bietet die Partitionierung, um die Abfrageleistung und die Kosten zu verbessern und den Informationslebenszyklus zu verwalten. Speicherressourcen werden nach Ihrem Verbrauch zugeordnet und wieder entfernt, wenn Sie Daten löschen oder Tabellen verwerfen.
Oracle speichert Daten im Zeilenformat mit dem Oracle-Blockformat, das in Segmente unterteilt ist. Schemas (die Nutzern gehören) werden zum Organisieren von Tabellen und anderen Datenbankobjekten verwendet. Ab Oracle 12c wird Mehrinstanzenfähigkeit verwendet, um modulare Datenbanken innerhalb einer Datenbankinstanz zur weiteren Isolierung zu erstellen. Mit Partitionierung lässt sich die Abfrageleistung und die Lebensdauer von Informationen verbessern. Oracle bietet mehrere Speicheroptionen für eigenständige Datenbanken und Real Application Clusters (RAC)-Datenbanken wie ASM, ein Dateisystem des Betriebssystems, und ein Clusterdateisystem.
Exadata bietet eine optimierte Speicherinfrastruktur in Speicherzellenservern und ermöglicht Oracle-Servern den transparenten Zugriff auf diese Daten mithilfe von ASM. Exadata bietet Optionen für die hybride spaltenbasierte Komprimierung (HCC), mit denen Nutzer Tabellen und Partitionen komprimieren können.
Oracle erfordert eine vorab bereitgestellte Speicherkapazität, eine sorgfältige Größenanpassung und Konfigurationen für das automatische Inkrementieren von Segmenten, Datendateien und Tabellenspeichern.
Abfrageausführung und Leistung
BigQuery verwaltet die Leistung und skaliert auf Abfrageebene, um die Leistung bei möglichst niedrigen Kosten zu maximieren. BigQuery verwendet viele Optimierungen, z. B.:
- In-Memory-Abfrageausführung
- Mehrstufige Baumarchitektur auf der Grundlage der Dremel-Ausführungsengine
- Automatische Speicheroptimierung in Capacitor
- Insgesamt 1 Petabit pro Sekunde an geteilter Bandbreite mit Jupiter
- Automatische Skalierung der Ressourcenverwaltung, um schnelle Abfragen im Petabyte-Bereich zu ermöglichen
BigQuery sammelt beim Laden der Daten Spaltenstatistiken und enthält Diagnoseinformationen zu Abfrageplänen und zeitlichen Abläufen. Abfrageressourcen werden nach Abfragetyp und Komplexität zugeordnet. Jede Abfrage verwendet eine bestimmte Anzahl an Slots, bei denen es sich um Berechnungseinheiten handelt, die eine gewisse CPU- und RAM-Größe umfassen.
Oracle bietet Jobs zum Erfassen von Daten-Statistiken. Der Datenbank-Optimierer verwendet Statistiken, um optimale Ausführungspläne bereitzustellen. Indexe sind möglicherweise für schnelle Zeilensuchvorgänge und Join-Vorgänge erforderlich. Oracle bietet außerdem einen In-Memory-Spaltenspeicher für In-Memory-Analysen an. Exadata bietet mehrere Leistungsverbesserungen wie Smart Scan für Zellen, Speicherindexe, Flash-Cache und InfiniBand-Verbindungen zwischen Speicher- und Datenbankservern. Real Application Clusters (RAC) können verwendet werden, um Hochverfügbarkeit von Servern zu erreichen und CPU-intensive Datenbankanwendungen mit demselben zugrunde liegenden Speicher zu skalieren.
Für die Optimierung der Abfrageleistung mit Oracle müssen diese Optionen und Datenbankparameter sorgfältig berücksichtigt werden. Oracle bietet mehrere Tools, darunter Active Session History (ASH), Automatic Database Diagnostic Monitor (ADDM), AWR-Berichte (Automatic Workload Repository), der Advisor für SQL-Monitoring und -Optimierung sowie Advisors für das Rückgängigmachen und die Arbeitsspeicheroptimierung zur Leistungsoptimierung.
Agile Analysen
In BigQuery können Sie verschiedene Projekte, Nutzer und Gruppen aktivieren, um Datasets in verschiedenen Projekten abzufragen. Durch die Trennung der Abfrageausführung können autonome Teams in ihren Projekten arbeiten, ohne dass sich dies auf andere Nutzer und Projekte auswirkt, indem Slot-Kontingente getrennt und die Abrechnung von anderen Projekten und den Projekten, die die Datasets hosten, abgefragt wird.
Hochverfügbarkeit, Sicherungen und Notfallwiederherstellung
Oracle bietet Data Guard als Lösung für Notfallwiederherstellung und Datenbankreplizierung an. Real Application Clusters (RAC) können für die Serververfügbarkeit konfiguriert werden. Recovery Manager (RMAN)-Sicherungen können für Datenbank- und Archivelog-Sicherungen konfiguriert und auch für Wiederherstellungsvorgänge verwendet werden. Die Funktion Flashback-Datenbank kann für Datenbank-Flashbacks verwendet werden, um die Datenbank auf einen bestimmten Zeitpunkt zurückzusetzen. Der Rückgängigmachen-Tablespace enthält Tabellen-Snapshots. Es ist möglich, alte Snapshots mit der Flashback-Abfrage und den „as of“-Abfrageklauseln abzufragen. Dies hängt von den zuvor ausgeführten DML-/DDL-Vorgängen und den Einstellungen zur Rückgängigmachen-Aufbewahrung ab. In Oracle sollte die gesamte Integrität der Datenbank in Tablespaces verwaltet werden, die von den Systemmetadaten, dem Rückgängigmachen und den entsprechenden Tablespaces abhängen, da strikte Konsistenz für Oracle-Sicherungen wichtig ist und Wiederherstellungsverfahren die vollständigen Primärdaten enthalten sollten. Sie können Exporte auf Tabellenschema-Ebene planen, wenn in Oracle keine Wiederherstellung zu einem bestimmten Zeitpunkt erforderlich ist.
BigQuery ist vollständig verwaltet und unterscheidet sich in seinen vollständigen Sicherungsfunktionen von herkömmlichen Datenbanksystemen. Sie müssen keine Server- und Speicherfehler, Systemfehler und physischen Datenfehler berücksichtigen. BigQuery repliziert Daten über verschiedene Rechenzentren hinweg, je nach Dataset-Standort, um die Zuverlässigkeit und Verfügbarkeit zu maximieren. Die multiregionale Funktion von BigQuery repliziert Daten in verschiedenen Regionen und schützt vor Nichtverfügbarkeit einer einzelnen Zone innerhalb der Region. Die BigQuery-Funktionalität mit einer einzelnen Region repliziert Daten über verschiedene Zonen hinweg innerhalb derselben Region.
Mit BigQuery können Sie mithilfe von Zeitreisen Verlaufs-Snapshots von Tabellen bis zu sieben Tage lang abfragen und gelöschte Tabellen innerhalb von zwei Tagen wiederherstellen.
Sie können eine gelöschte Tabelle (zur Wiederherstellung) kopieren. Verwenden Sie dazu die Snapshot-Syntax (dataset.table@timestamp). Sie können Daten aus BigQuery-Tabellen für zusätzliche Sicherungsanforderungen exportieren, z. B. zur Wiederherstellung nach versehentlichen Nutzervorgängen. Eine bewährte Sicherungsstrategie und Zeitpläne, die für vorhandene Data Warehouse-Systeme (DWH) genutzt werden, können für Sicherungen verwendet werden.
Batch-Vorgänge und die Snapshot-Technologie ermöglichen unterschiedliche Sicherungsstrategien für BigQuery. So müssen Sie unveränderte Tabellen und Partitionen nicht häufig exportieren. Nach dem Abschluss des Lade- oder ETL-Vorgangs ist eine einzelne Exportsicherung der Partition oder Tabelle ausreichend. Um die Sicherungskosten zu senken, können Sie Exportdateien in Nearline Storage oder Coldline Storage von Cloud Storage speichern und eine Lebenszyklusrichtlinie definieren, um Dateien nach einer bestimmten Zeit zu löschen, abhängig von den Anforderungen an die Datenaufbewahrung.
Caching
BigQuery bietet einen Cache pro Nutzer. Wenn sich die Daten nicht ändern, werden die Abfrageergebnisse etwa 24 Stunden lang im Cache gespeichert. Wenn die Ergebnisse aus dem Cache abgerufen werden, ist die Abfrage kostenlos.
Oracle bietet mehrere Caches für Daten und Abfrageergebnisse an, wie den Zwischenspeichercache, den Ergebniscache, den Exadata Flash Cache und den In-Memory-Spaltenspeicher.
Verbindungen
BigQuery übernimmt die Verbindungsverwaltung und erfordert von Ihnen keine serverseitige Konfiguration. BigQuery bietet JDBC- und ODBC-Treiber. Sie können die Google Cloud Console oder das bq command-line tool für interaktive Abfragen verwenden. Sie können REST-APIs und Clientbibliotheken verwenden, um programmatisch mit BigQuery zu interagieren. Sie können Google Tabellen direkt mit BigQuery verbinden und ODBC- und JDBC-Treiber verwenden, um mit Excel zu verbinden. Wenn Sie einen Desktop-Client suchen, gibt es kostenlose Tools wie DBeaver.
Oracle bietet Listener, Dienste, Dienst-Handler, mehrere Konfigurations- und Feinabstimmungs-Parameter sowie freigegebene und dedizierte Server für die Verarbeitung von Datenbank-Verbindungen. Oracle bietet JDBC, JDBC Thin, ODBC-Treiber, Oracle Client und TNS-Verbindungen. Scan-Listener, Scan-IP-Adressen und scan-name sind für RAC-Konfigurationen erforderlich.
Preise und Lizenzierung
Oracle erfordert Lizenz- und Supportgebühren auf der Grundlage der Anzahl der Kerne für Datenbankversionen und Datenbankoptionen wie RAC, Mehrinstanzenfähigkeit, Active Data Guard, Partitionierung, In-Memory, Real Application Testing, GoldenGate sowie Spatial und Graph.
BigQuery bietet flexible Preismodelle basierend auf der Nutzung von Speicher, Abfragen und Streaming-Insert-Anweisungen. BigQuery bietet kapazitätsbasierte Preise für Kunden, die in bestimmten Regionen vorhersehbare Kosten benötigen. Slots, die zum Streamen von Insert- und Ladevorgängen verwendet werden, werden nicht auf die Slot-Kapazität des Projekts angerechnet. Mehr Informationen, die Ihnen bei der Entscheidung helfen, wie viele Slots Sie für Ihr Data Warehouse erwerben sollten, finden Sie unter BigQuery-Kapazitätsplanung.
BigQuery verringert auch automatisch die Speicherkosten für unveränderte Daten um die Hälfte, wenn diese mehr als 90 Tage gespeichert sind.
Labeling
BigQuery-Datasets, -Tabellen und -Ansichten können mithilfe von Schlüssel/Wert-Paaren mit Labels versehen werden. Mit Labels können Speicherkosten und interne Kostenaufschläge unterschieden werden.
Monitoring und Audit-Logging
Oracle bietet verschiedene Ebenen und Arten vonDatenbankprüfungs-Optionen undAudit Vault und Datenbankfirewall-Features, die separat lizenziert sind. Oracle bietet Enterprise Manager für das Datenbank-Monitoring.
Bei BigQuery werden Cloud-Audit-Logs sowohl für Datenzugriffs- als auch für Audit-Logs verwendet, die standardmäßig aktiviert sind. Die Datenzugriffslogs sind 30 Tage lang verfügbar, die anderen Systemereignis- und Administratoraktivitätslogs sind 400 Tage lang verfügbar. Wenn Sie eine längere Aufbewahrung benötigen, können Sie Logs nach BigQuery, Cloud Storage oder Pub/Sub exportieren, wie unter Sicherheitsloganalysen in Google Cloud beschrieben. Wenn eine Integration in ein vorhandenes Tool zur Überwachung von Vorfällen erforderlich ist, kann Pub/Sub für Exporte verwendet werden und benutzerdefinierte Entwicklungen sollten mit dem vorhandenen Tool durchgeführt werden, damit Logs aus Pub/Sub gelesen werden.
Audit-Logs enthalten alle API-Aufrufe, Abfrageanweisungen und Jobstatus. Mit Cloud Monitoring können Sie die Slotzuweisung, die in Abfragen gescannten und gespeicherten Byte sowie andere BigQuery-Messwerte überwachen. Mit Abfrageplänen und Zeitachsen von BigQuery können Analysephasen und Leistung analysiert werden.
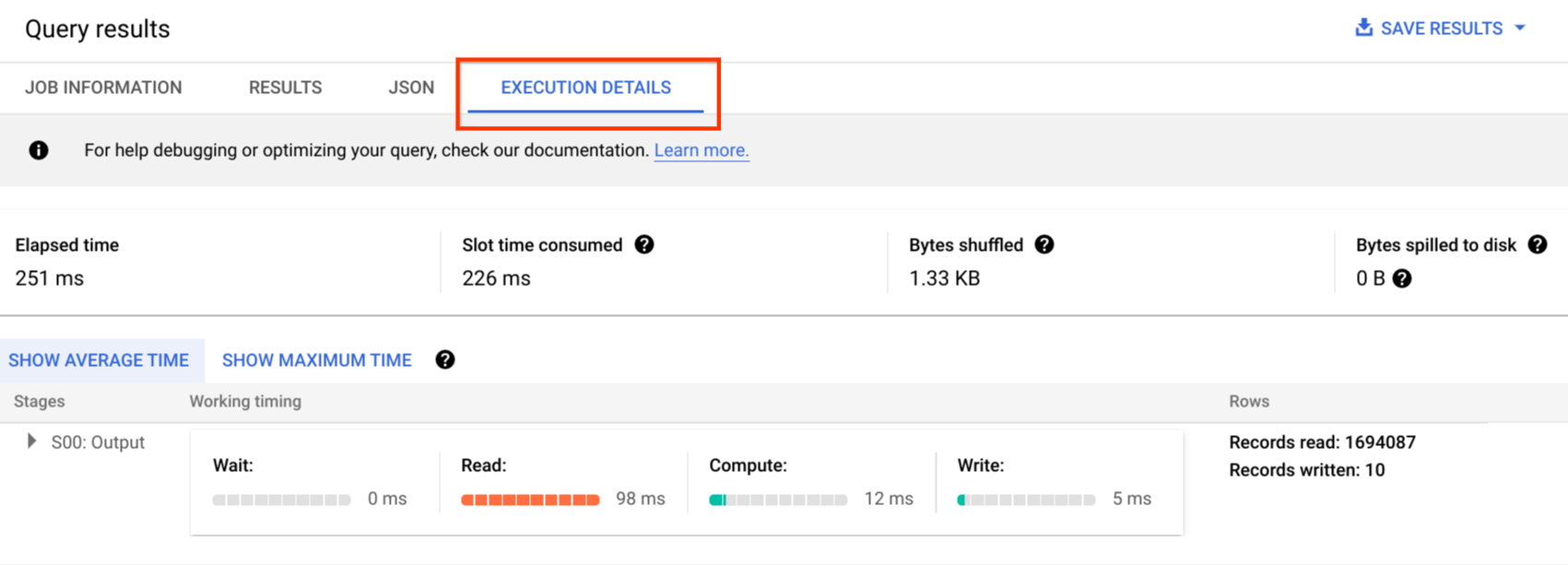
Sie können die Tabelle mit Fehlermeldungen zur Fehlerbehebung bei Abfragejob- und API-Fehlern verwenden. Um die Slot-Zuweisungen pro Abfrage oder Job zu unterscheiden, können Sie dieses Dienstprogramm verwenden. Es ist nützlich für Kunden, die kapazitätsbasierte Preise verwenden und über viele Projekte verfügen, die auf mehrere Teams verteilt sind.
Wartung, Upgrades und Versionen
BigQuery ist ein vollständig verwalteter Dienst und erfordert keine Wartung oder Upgrades von Ihnen. BigQuery bietet keine unterschiedlichen Versionen. Upgrades sind kontinuierlich, erfordern keine Ausfallzeiten und beeinträchtigen nicht die Systemleistung. Weitere Informationen finden Sie in den Versionshinweisen.
Oracle und Exadata erfordern, dass Sie Patches, Upgrades und Wartungen auf Ebene der Datenbank und der zugrunde liegenden Infrastruktur ausführen. Es gibt viele Versionen von Oracle und die Veröffentlichung einer neuen Hauptversion ist für jedes Jahr geplant. Neue Versionen sind zwar abwärtskompatibel, aber die Abfrageleistung, der Kontext und die Funktionen können sich ändern.
Es kann Anwendungen geben, für die bestimmte Versionen wie 10g, 11g oder 12c erforderlich sind. Für größere Datenbank-Upgrades sind sorgfältige Planung und Tests erforderlich. Die Migration von verschiedenen Versionen kann unterschiedliche technische Anforderungen an die Umwandlung von Abfragesätzen und Datenbankobjekten erfordern.
Arbeitslasten
Oracle Exadata unterstützt gemischte Arbeitslasten, einschließlich OLTP-Arbeitslasten. BigQuery ist für Analysen und nicht für OLTP-Arbeitslasten konzipiert. OLTP-Arbeitslasten, die dieselbe Oracle-Instanz verwenden, sollten imGoogle Cloud-Jahr zu Cloud SQL, Spanner oder Firestore migriert werden. Oracle bietet zusätzliche Optionen wie Advanced Analytics und Spatial and Graph. Diese Arbeitslasten müssen möglicherweise für die Migration zu BigQuery neu geschrieben werden. Weitere Informationen finden Sie unter Oracle-Optionen migrieren.
Parameter und Einstellungen
Oracle bietet und erfordert viele Parameter, die auf der Betriebssystem-, Datenbank-, RAC-, ASM- und Listener-Ebene für verschiedene Arbeitslasten und Anwendungen konfiguriert und abgestimmt werden müssen. BigQuery ist ein vollständig verwalteter Dienst und erfordert von Ihnen keine Konfiguration von Initialisierungsparametern.
Limits und Kontingente
Oracle hat basierend auf Infrastruktur, Hardwarekapazität, Parametern, Softwareversionen und Lizenzierung harte und weiche Limits. In BigQuery gelten Kontingente und Limits für bestimmte Aktionen und Objekte.
BigQuery-Bereitstellung
BigQuery ist ein PaaS-Dienst (Platform as a Service) und ein Data Warehouse zur massiv parallelen Datenverarbeitung in der Cloud. Seine Kapazität wird ohne Eingreifen des Nutzers hoch- und herunterskaliert, da Google das Backend verwaltet. Daher ist es im Gegensatz zu vielen RDBMS-Systemen nicht erforderlich, dass Sie bei BigQuery Ressourcen bereitstellen, bevor Sie es verwenden können. BigQuery weist Speicher- und Abfrageressourcen basierend auf Ihren Nutzungsmustern dynamisch zu. Speicherressourcen werden nach Ihrem Verbrauch zugeordnet und wieder entfernt, wenn Sie Daten löschen oder Tabellen verwerfen. Abfrageressourcen werden nach Abfragetyp und Komplexität zugeordnet Jede Abfrage verwendet Slots. Es wird ein Planer für finale Gleichmäßigkeit verwendet. Daher kann es zu kurzen Zeiträumen kommen, in denen einige Abfragen einen höheren Anteil an Slots erhalten, aber der Planer korrigiert dies im Endeffekt.
In der herkömmlichen VM-Begrifflichkeit deckt BigQuery beide Aspekte ab:
- Sekundengenaue Abrechnung
- Sekundenschnelle Skalierung
Um diese Aufgabe zu erledigen, tut BigQuery Folgendes:
- Umfangreiche Ressourcen werden bereitgestellt, um nicht schnell skalieren zu müssen.
- Mehrinstanzenfähige Ressourcen werden verwendet, um große Blöcke sofort für jeweils wenige Sekunden zuzuweisen.
- Ressourcen werden effizient für alle Nutzer mit Skaleneffekten zugewiesen.
- Ihnen werden nur die von Ihnen ausgeführten Jobs und nicht die bereitgestellten Ressourcen in Rechnung gestellt, sodass Sie nur für die von Ihnen verwendeten Ressourcen zahlen.
Weitere Informationen zu den Preisen finden Sie unter Kenntnis der schnellen Skalierung und einfachen Preise von BigQuery.
Schema-Migration
Wenn Sie Daten von Oracle zu BigQuery migrieren möchten, müssen Sie die Oracle-Datentypen und BigQuery-Zuordnungen kennen.
Oracle-Datentypen und BigQuery-Zuordnungen
Oracle-Datentypen unterscheiden sich von BigQuery-Datentypen. Weitere Informationen zu BigQuery-Datentypen finden Sie in der offiziellen Dokumentation.
Einen detaillierten Vergleich der Datentypen von Oracle und BigQuery finden Sie im Oracle SQL-Übersetzungsleitfaden.
Indexe
Bei vielen Analysearbeitslasten werden statt Zeilenspeichern spaltenbasierte Tabellen verwendet. Dadurch werden die spaltenbasierten Vorgänge erheblich erhöht und die Verwendung von Indexen für Batchanalysen entfällt. BigQuery speichert Daten auch in einem Spaltenformat, sodass in BigQuery keine Indexe benötigt werden. Wenn für die Analysearbeitslast ein einzelner, kleiner zeilenbasierter Zugriffssatz erforderlich ist, ist Bigtable möglicherweise die bessere Alternative. Wenn für eine Arbeitslast eine Transaktionsverarbeitung mit strikten relationalen Konsistenzen erforderlich ist, sind Spanner oder Cloud SQL möglicherweise die besseren Alternativen.
Zusammenfassend lässt sich sagen, dass für Batchanalysen in BigQuery keine Indexe erforderlich sind und angeboten werden. Sie können Partitionierung oder Clustering verwenden. Weitere Informationen zur Feinabstimmung und Verbesserung der Abfrageleistung in BigQuery finden Sie unter Einführung in die Optimierung der Abfrageleistung.
Aufrufe
Ähnlich wie Oracle ermöglicht BigQuery das Erstellen benutzerdefinierter Ansichten. Ansichten in BigQuery unterstützen jedoch keine DML-Anweisungen.
Materialisierte Ansichten
Materialisierte Ansichten werden häufig verwendet, um die Berichts-Renderingzeit in Bericht- und Workloadarten mit einem Schreib- und vielen Lesezugriffen zu verbessern.
Materialisierte Ansichten werden in Oracle angeboten, um die Ansichtsleistung zu erhöhen, indem einfach eine Tabelle für das Abfrageergebnis-Dataset erstellt und verwaltet wird. Es gibt zwei Möglichkeiten, materialisierte Ansichten in Oracle zu aktualisieren: on-commit und on-demand.
Die Funktionen für materialisierte Ansichten sind auch in BigQuery verfügbar. BigQuery nutzt vorausberechnete Ergebnisse aus materialisierten Ansichten und liest nach Möglichkeit nur Deltaänderungen aus der Basistabelle, um aktuelle Ergebnisse zu berechnen.
Mit Caching-Funktionen in Looker Studio oder anderen modernen BI-Tools lässt sich auch die Leistung verbessern und die Abfrage muss nicht noch einmal ausgeführt werden, was Kosten spart.
Tabellenpartitionierung
Die Tabellenpartitionierung wird in Oracle-Data-Warehouses häufig verwendet. Im Gegensatz zu Oracle unterstützt BigQuery keine hierarchische Partitionierung.
BigQuery implementiert drei Arten der Tabellenpartitionierungen, mit denen Abfragen Prädikatfilter basierend auf der Partitionierungsspalte angeben können, um die Menge der gescannten Daten zu verringern.
- Nach Aufnahmezeit partitionierte Tabellen: Tabellen werden basierend auf der Aufnahmezeit der Daten partitioniert.
- Nach Spalte partitionierte Tabellen: Tabellen werden basierend auf der Spalte
TIMESTAMPoderDATEpartitioniert. - Nach Ganzzahlbereich partitionierte Tabellen: Tabellen werden nach einer Spalte mit Ganzzahlen partitioniert.
Weitere Informationen zu Limits und Kontingenten für partitionierte Tabellen in BigQuery finden Sie unter Einführung in partitionierte Tabellen.
Wenn die BigQuery-Einschränkungen die Funktionalität der migrierten Datenbank beeinträchtigen, sollten Sie anstelle der Partitionierung eine Fragmentierung erwägen.
Außerdem werden in BigQuery weder EXCHANGE PARTITION noch SPLIT PARTITION unterstützt. Auch die Umwandlung einer nicht partitionierten Tabelle in eine partitionierte Tabelle ist nicht möglich.
Clustering
Cluster helfen dabei, Daten, die in mehreren Spalten gespeichert sind und auf die häufig gemeinsam zugegriffen wird, effizient zu organisieren und abzurufen. Für Oracle und BigQuery sind es jedoch jeweils unterschiedliche Umstände, unter denen das Clustering am besten funktioniert. Wenn in BigQuery eine Tabelle häufig mit bestimmten Spalten gefiltert und aggregiert wird, verwenden Sie Clustering. Clustering kann für die Migration von über Listen partitionierten oder über Indexe organisierten Tabellen von Oracle in Betracht gezogen werden.
Temporäre Tabellen
Temporäre Tabellen werden häufig in Oracle-ETL-Pipelines verwendet. Eine temporäre Tabelle enthält Daten während einer Nutzersitzung. Diese Daten werden am Ende der Sitzung automatisch gelöscht.
BigQuery verwendet temporäre Tabellen, um Abfrageergebnisse im Cache zu speichern, die nicht in eine permanente Tabelle geschrieben wurden. Nachdem eine Abfrage abgeschlossen ist, bestehen die temporären Tabellen noch bis zu 24 Stunden. Die Tabellen werden in einem speziellen Dataset erstellt und nach dem Zufallsprinzip benannt. Sie können auch temporäre Tabellen zur eigenen Verwendung erstellen. Weitere Informationen finden Sie unter Temporäre Tabellen.
Externe Tabellen
Ähnlich wie Oracle können Sie mit BigQuery externe Datenquellen abfragen. BigQuery unterstützt das Abfragen von Daten direkt aus den folgenden externen Datenquellen:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Datenmodellierung
Stern- oder Schneeflocken-Datenmodelle können für die Analysespeicherung effizient sein und werden häufig für Data Warehouses in Oracle Exadata verwendet.
Denormalisierte Tabellen eliminieren teure Join-Vorgänge und bieten in den meisten Fällen eine bessere Leistung für Analysen in BigQuery. Stern- und Schneeflocken-Datenmodelle werden auch von BigQuery unterstützt. Weitere Informationen zum Data-Warehouse-Design in BigQuery finden Sie unter Schema entwerfen.
Zeilenformat versus Spaltenformat und Serverlimits versus Serverlos
Oracle verwendet ein Zeilenformat, in dem die Tabellenzeile in Datenblöcken gespeichert wird. Unnötige Spalten werden daher innerhalb des Blocks für die analytischen Abfragen abgerufen, basierend auf dem Filtern und der Aggregation bestimmter Spalten.
Oracle hat eine Shared-Everything-Architektur, bei der feste Hardware-Ressourcenabhängigkeiten, wie Arbeitsspeicher und Speicherplatz, dem Server zugewiesen sind. Dies sind die beiden Hauptfaktoren, die den meisten Datenmodellierungstechniken zugrunde liegen, mit denen sich die Effizienz der Speicherung und Leistung von Analyseabfragen verbessert hat. Stern- und Schneeflocken-Schemas sowie Data Vault-Modellierungen gehören dazu.
BigQuery verwendet zum Speichern von Daten ein Spaltenformat und hat keine festen Speicherplatz- und Arbeitsspeicherlimits. Mit dieser Architektur können Sie Schemas basierend auf Lesevorgängen und Geschäftsanforderungen weiter denormalisieren und entwerfen, wodurch die Komplexität verringert und die Flexibilität, Skalierbarkeit und Leistung verbessert wird.
Denormalisierung
Eines der Hauptziele der Normalisierung relationaler Datenbanken besteht darin, die Datenredundanz zu reduzieren. Dieses Modell eignet sich am besten für eine relationale Datenbank, die ein Zeilenformat verwendet. Für spaltenorientierte Datenbanken ist jedoch die Daten-Denormalisierung zu bevorzugen. Weitere Informationen zu den Vorteilen der Daten-Denormalisierung und anderen Strategien zur Abfrageoptimierung in BigQuery finden Sie unter Denormalisierung.
Methoden zum Flachstellen Ihres vorhandenen Schemas
Die BigQuery-Technologie nutzt eine Kombination aus spaltenorientiertem Datenzugriff, spaltenorientierter Datenverarbeitung, In-Memory-Speicher und verteilter Verarbeitung, um eine hochwertige Abfrageleistung zu gewährleisten.
Beim Entwerfen eines BigQuery-DWH-Schemas ist die Erstellung einer Faktentabelle in einer flachen Tabellenstruktur (bei der alle Dimensionstabellen in einem einzigen Datensatz in der Faktentabelle konsolidiert werden) besser für die Speicherauslastung geeignet als die Verwendung mehrerer DWH-Dimensionstabellen. Neben einer geringeren Speichernutzung führt eine flache Tabelle in BigQuery auch zu einer geringeren JOIN-Nutzung. Das folgende Diagramm zeigt ein Beispiel für die Flattening-Methode.
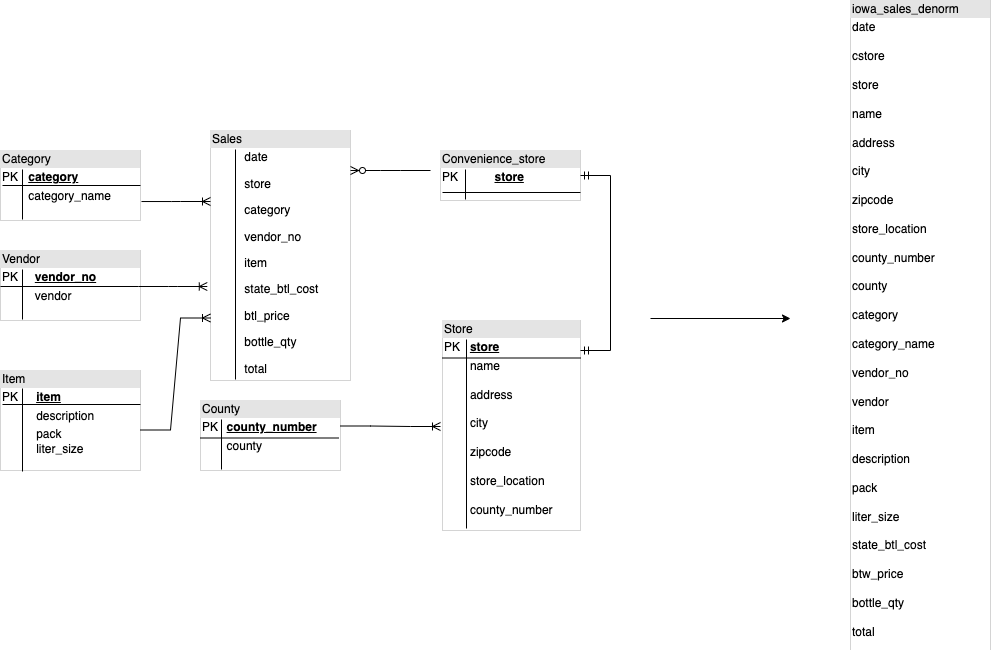
Beispiel für die Flattening-Methode bei einem Sternschema
Abbildung 1 zeigt eine fiktive Vertriebsmanagement-Datenbank, die vier Tabellen enthält:
- Tabelle zu Bestellungen/Verkäufen (Faktentabelle)
- Mitarbeitertabelle
- Standorttabelle
- Kundentabelle
Der Primärschlüssel für die Verkaufstabelle ist OrderNum, der auch Fremdschlüssel zu den anderen drei Tabellen enthält.
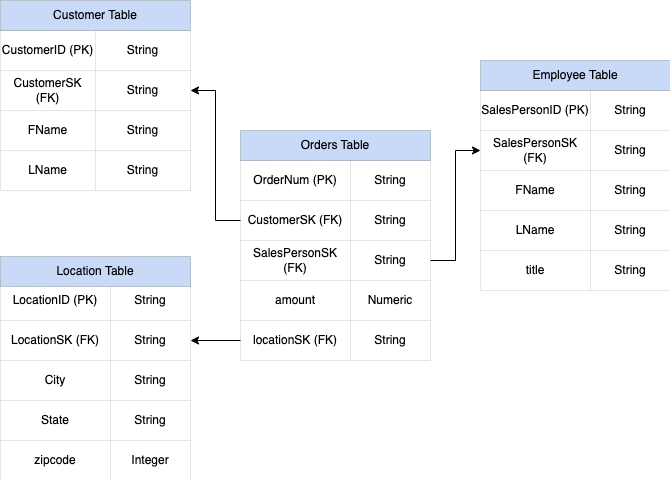
Abbildung 1: Beispiel für Verkaufsdaten in einem Sternschema
Beispieldaten
Inhalt der Bestellungs-/Faktentabelle
| OrderNum | CustomerID | SalesPersonID | Menge | Standort |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
Inhalt der Mitarbeitertabelle
| SalesPersonID | FName | LName | Titel |
| 1 | Alex | Smith | Sales Associate |
| 4 | Lisa | Mustermann | Sales Associate |
| 12 | John | Mustermann | Sales Associate |
Inhalt der Kundentabelle
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Inhalt der Standorttabelle
| Standort | Ort | Ort | Ort |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Abfrage zum Zusammenführen der Daten mit LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Ausgabe der flachen Daten
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | Menge | Standort | Ort | state | Postleitzahl |
| O-1 | 1234 | Amanda | Lee | 12 | John | Doe | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Sowa | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | John | Doe | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Doe | 182.00 | 26 | Berg
View |
CA | 90210 |
Verschachtelte und wiederkehrende Felder
In BigQuery werden die Funktionen für verschachtelte und wiederkehrende Felder vorgestellt, um ein DWH-Schema aus einem relationalen Schema zu entwerfen und zu erstellen (z. B. Stern- und Schneeflocken-Schemas mit Dimensions- und Faktentabellen). Daher können Beziehungen auf ähnliche Weise beibehalten werden wie bei einem relationalen (oder teilweise normalisiertes) DWH-Schema, ohne dass dies Auswirkungen auf die Leistung hat. Weitere Informationen finden Sie unter Best Practices für die Leistung.
Um die Implementierung verschachtelter und wiederkehrender Felder besser zu verstehen, sehen Sie sich ein einfaches relationales Schema einer CUSTOMERS-Tabelle und einer ORDER/SALES-Tabelle an. Es gibt zwei verschiedene Tabellen, eine für jede Entität, und die Beziehungen werden während der Abfrage mit JOINs mithilfe eines Schlüssels, etwa eines Primärschlüssels, und eines Fremdschlüssels als Verknüpfung zwischen den Tabellen definiert. Mit verschachtelten und wiederkehrenden Feldern in BigQuery können Sie die Beziehung zwischen den Entitäten in einer einzigen Tabelle beibehalten. Dies kann durch die Bereitstellung aller Kundendaten und das Verschachteln der Bestelldaten für jeden Kunden implementiert werden. Weitere Informationen finden Sie unter Verschachtelte und wiederkehrende Spalten angeben.
Um die flache Struktur in ein verschachteltes oder wiederkehrendes Schema zu konvertieren, verschachteln Sie die Felder so:
CustomerID,FName,LNameverschachtelt in einem neuen Feld namensCustomer.SalesPersonID,FName,LNameverschachtelt in einem neuen Feld namensSalesperson.LocationID,city,state,zip codeverschachtelt in einem neuen Feld namensLocation.
Die Felder OrderNum und amount sind nicht verschachtelt, da sie eindeutige Elemente darstellen.
Sorgen Sie dafür, dass Sie das Schema flexibel genug machen, damit jede Bestellung mehr als einen Kunden haben kann: einen primären und einen sekundären. Das Kundenfeld ist als wiederholt gekennzeichnet. Das resultierende Schema ist in Abbildung 2 dargestellt. Dort sind verschachtelte und wiederkehrende Felder zu sehen.
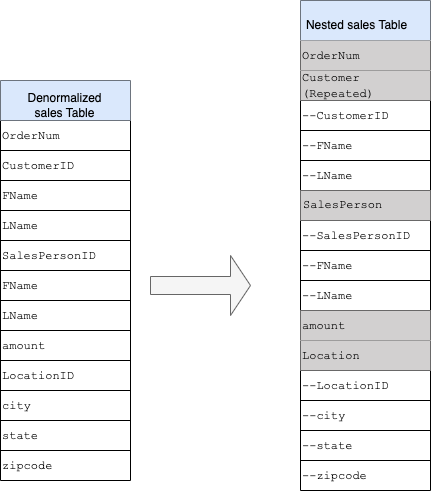
Abbildung 2: Logische Darstellung einer verschachtelten Struktur
In einigen Fällen führt die Denormalisierung mit verschachtelten und wiederkehrenden Feldern nicht zu Leistungsverbesserungen. Weitere Informationen zu Einschränkungen finden Sie unter Verschachtelte und wiederkehrende Spalten in Tabellenschemas angeben.
Ersatzschlüssel
Es ist gängig, Zeilen mit eindeutigen Schlüsseln in den Tabellen zu identifizieren. Sequenzen werden bei Oracle häufig zum Erstellen dieser Schlüssel verwendet. In BigQuery können Sie mit den Funktionen row_number und partition by Surrogateschlüssel erstellen. Weitere Informationen finden Sie unter BigQuery- und Ersatzschlüssel: Ein praktischer Ansatz.
Änderungen und Verlauf im Blick behalten
Berücksichtigen Sie bei der Planung einer BigQuery-DWH-Migration das Konzept der sich langsam ändernden Dimensionen (slowly changing dimensions, SCD). Im Allgemeinen beschreibt der Begriff SCD den Prozess, Änderungen (DML-Vorgänge) in den Dimensionstabellen vorzunehmen.
Aus unterschiedlichen Gründen verwenden herkömmliche Data Warehouses unterschiedliche Typen für den Umgang mit Datenänderungen und die Speicherung von Verlaufsdaten in sich langsam ändernden Dimensionen. Diese Typennutzungen werden von den zuvor beschriebenen Hardwarebeschränkungen und Effizienzanforderungen benötigt. Da der Speicher viel günstiger als Computing und unendlich skalierbar ist, wird die Datenredundanz und -duplizierung empfohlen, wenn dies zu schnelleren Abfragen in BigQuery führt. Sie können Methoden zum Erstellen von Daten-Snapshots verwenden, bei denen alle Daten in neue tägliche Partitionen geladen werden.
Rollen- und nutzerspezifische Ansichten
Verwenden Sie rollen- und nutzerspezifische Ansichten, wenn Nutzer zu verschiedenen Teams gehören und nur die Daten und Ergebnisse sehen sollen, die sie benötigen.
BigQuery unterstützt Sicherheit auf Spalten- und Zeilenebene. Die Sicherheit auf Spaltenebene bietet mithilfe von Richtlinien-Tags oder typbasierter Klassifizierung von Daten einen detailgenauen Zugriff auf vertrauliche Spalten. Mit der Sicherheit auf Zeilenebene können Sie Daten filtern und den Zugriff auf bestimmte Zeilen in einer Tabelle anhand bestimmter Nutzerbedingungen ermöglichen.
Datenmigration
Dieser Abschnitt enthält Informationen zur Datenmigration von Oracle zu BigQuery, einschließlich anfänglichen Ladevorgängen, Change Data Capture (CDC) und ETL/ELT-Tools und -Ansätzen.
Migrationsaktivitäten
Wir empfehlen, die Migration in Phasen durchzuführen und geeignete Anwendungsfälle für die Migration zu identifizieren. Es gibt mehrere Tools und Dienste, mit denen Sie Daten von Oracle zu Google Cloudmigrieren können. Diese Liste ist nicht vollständig. Sie bietet aber einen Einblick in die Größe und den Umfang des Migrationsvorgangs.
Daten aus Oracle exportieren:Weitere Informationen finden Sie unter Anfängliches Laden und CDC und Streaming-Aufnahme von Oracle nach BigQuery. Für das erste Laden können ETL-Tools verwendet werden.
Data Staging (in Cloud Storage): Cloud Storage ist der empfohlene Landebereich (Staging-Bereich) für aus Oracle exportierte Daten. Cloud Storage wurde für die schnelle und flexible Aufnahme strukturierter oder unstrukturierter Daten entwickelt.
ETL-Prozess:Weitere Informationen finden Sie unter ETL/ELT-Migration.
Daten direkt in BigQuery laden: Sie können Daten direkt aus Cloud Storage laden, durch Dataflow oder durch Echtzeitstreaming. Verwenden Sie Dataflow, wenn eine Datentransformation erforderlich ist.
Anfänglicher Ladevorgang
Die Migration der anfänglichen Daten vom vorhandenen Oracle-Data Warehouse zu BigQuery kann je nach Datengröße und Netzwerkbandbreite von den inkrementellen ETL-/ELT-Pipelines abweichen. Dieselben ETL-/ELT-Pipelines können verwendet werden, wenn die Datengröße einige Terabyte beträgt.
Wenn die Daten bis zu einigen Terabyte groß sind, kann das Auslesen der Daten und die Verwendung von gcloud storage für die Übertragung viel effizienter sein als die JdbcIO-ähnliche programmatische Methode der Extraktion von Datenbanken, da bei programmatischen Ansätzen möglicherweise eine viel detailliertere Leistungsoptimierung erforderlich ist. Wenn die Datengröße mehr als einige Terabyte beträgt und die Daten in Cloud- oder Onlinespeichern (z. B. Amazon Simple Storage Service (Amazon S3)) gespeichert sind, ziehen Sie in Betracht, den BigQuery Data Transfer Service zu verwenden Für umfangreiche Übertragungen (insbesondere Übertragungen mit begrenzter Netzwerkbandbreite) ist Transfer Appliance eine nützliche Option.
Einschränkungen beim anfänglichen Ladevorgang
Berücksichtigen Sie bei der Planung der Datenmigration Folgendes:
- Oracle-DWH-Datengröße: Die Quellgröße Ihres Schemas ist für die Auswahl der Datenübertragungsmethode von entscheidender Bedeutung, insbesondere wenn die Datengröße umfangreich ist (Terabyte und darüber). Wenn die Datengröße relativ klein ist, kann der Prozess der Datenübertragung in weniger Schritten abgeschlossen werden. Der Umgang mit umfangreichen Datengrößen führt zu einem komplexeren Gesamtprozess.
Ausfallzeit: Die Entscheidung, ob Ausfallzeiten für Ihre Migration zu BigQuery eine Option darstellen, ist wichtig. Zur Reduzierung der Ausfallzeiten können Sie die stabilen Verlaufsdaten im Bulk laden und eine CDC-Lösung einsetzen, um mit Änderungen gleichzuziehen, die während des Übertragungsprozesses eintreten.
Preise: In einigen Szenarien benötigen Sie möglicherweise Tools zur Integration von Drittanbietern (z. B. ETL- oder Replikationstools), die zusätzliche Lizenzen erfordern.
Anfängliche Datenübertragung (Batch)
Die Datenübertragung mithilfe einer Batchmethode gibt an, dass der Datenexport konsistent in einem einzigen Prozess passieren würden (z. B. das Exportieren der Oracle-DWH-Schemadaten in CSV-, Avro- oder Parquet-Dateien oder der Import in Cloud Storage, um Datasets in BigQuery zu erstellen). Alle ETL-Tools und ‑Konzepte, die unter ETL/ELT-Migration erläutert werden, können für das erste Laden verwendet werden.
Wenn Sie kein ETL/ELT-Tool für den anfänglichen Ladevorgang verwenden möchten, können Sie benutzerdefinierte Skripts schreiben, um Daten in Dateien (CSV, Avro oder Parquet) zu exportieren und diese in Cloud Storage mithilfe von gcloud storage, BigQuery Data Transfer Service oder Transfer Appliance hochzuladen. Weitere Informationen zur Leistungsoptimierung großer Datenübertragungen und zu Übertragungsoptionen finden Sie unter Große Datasets übertragen. Laden Sie dann die Daten aus Cloud Storage in BigQuery.
Cloud Storage eignet sich ideal, um die anfängliche Landung von Daten zu verarbeiten. Cloud Storage ist ein hochverfügbarer und langlebiger Objektspeicherdienst ohne Einschränkungen für die Anzahl von Dateien. Außerdem bezahlen Sie nur für den Speicher, den Sie verwenden. Der Dienst ist für die Verwendung mit anderen Google Cloud Diensten wie BigQuery und Dataflow optimiert.
CDC und Streaming-Aufnahme von Oracle zu BigQuery
Es gibt mehrere Möglichkeiten, die geänderten Daten aus Oracle zu erfassen. Jede Option hat Vor- und Nachteile, vor allem hinsichtlich der Auswirkungen auf die Leistung des Quellsystems, Entwicklungs- und Konfigurationsanforderungen sowie der Preise und Lizenzierung.
Logbasiertes CDC
Oracle GoldenGate ist das von Oracle empfohlene Tool zum Extrahieren von Redo-Logs. Sie können GoldenGate for Big Data zum Streamen von Logs in BigQuery verwenden. Für GoldenGate ist eine Lizenzierung pro CPU erforderlich. Informationen zum Preis finden Sie in der globalen Preisliste zu Oracle-Technologie. Wenn Oracle GoldenGate for Big Data verfügbar ist (wenn Lizenzen bereits erworben wurden), kann die Verwendung von GoldenGate eine gute Wahl sein, um Datenpipelines zur Übertragung von Daten (anfänglicher Ladevorgang) zu erstellen und dann alle Datenänderungen zu synchronisieren.
Oracle XStream
Oracle speichert jeden Commit in Wiederherstellungs-Logdateien. Diese Wiederherstellungsdateien können für die kontinuierliche Datenübernahme verwendet werden. Oracle XStream Out basiert auf LogMiner und wird von Drittanbietertools wie Debezium (ab Version 0.8) oder kommerziell bei der Verwendung von Tools wie Striim bereitgestellt. Für die Verwendung von XStream APIs ist der Kauf einer Lizenz für Oracle GoldenGate erforderlich, auch wenn GoldenGate nicht installiert ist und verwendet wird. Mit XStream können Sie Streams-Nachrichten effizient zwischen Oracle und anderer Software weitergeben.
Oracle LogMiner
Für LogMiner ist keine spezielle Lizenz erforderlich. Sie können die LogMiner-Option im Debezium-Community-Connector verwenden. Sie ist auch kommerziell über die Verwendung von Tools wie Attunity, Striim oder StreamSets verfügbar. LogMiner kann sich auf die Leistung einer sehr aktiven Quelldatenbank auswirken und sollte mit Bedacht verwendet werden, wenn das Volumen der Änderungen (die Redo-Größe) mehr als 10 GB pro Stunde beträgt, je nach CPU, Arbeitsspeicher und E/A-Kapazität und -Auslastung des Servers.
SQL-basiertes CDC
Dies ist der inkrementelle ETL-Ansatz, bei dem SQL-Abfragen die Quelltabellen kontinuierlich nach Änderungen abfragen, die von einem kontinuierlich steigenden Schlüssel und einer Zeitstempelspalte abhängig sind, die das Datum der letzten Änderung oder Einfügung enthält. Wenn es keinen monoton ansteigenden Schlüssel gibt, kann die Verwendung der Zeitstempelspalte (Datum der Änderung) mit einer geringen Genauigkeit (Sekunden) je nach Volumen und Vergleichsoperator, z. B. > oder >=, zu doppelten Einträgen oder fehlenden Daten führen.
Zur Lösung solcher Probleme können Sie eine höhere Genauigkeit in Zeitstempelspalten verwenden, z. B. sechs Nachkommastellen (Mikrosekunden – die maximal unterstützte Genauigkeit in BigQuery), oder Sie können Deduplizierungsaufgaben in Ihren ETL-/ELT-Code aufnehmen, je nach Geschäftsschlüssel und Dateneigenschaften.
Die Schlüssel- oder Zeitstempelspalte sollte einen Index enthalten, um die Extrahierleistung zu verbessern und die Auswirkungen auf die Quelldatenbank zu reduzieren. Löschvorgänge stellen eine Herausforderung für diese Methode dar, da sie in der Quellanwendung im Sinne eines vorläufigen Löschens verarbeitet werden sollten, z. B. durch Einsatz eines gelöschten Flags und Aktualisieren des last_modified_date. Eine alternative Lösung besteht darin, diese Vorgänge mithilfe eines Triggers in einer anderen Tabelle zu protokollieren.
Trigger
Datenbanktrigger können für Quelltabellen erstellt werden, um Änderungen in Schatten-Journaltabellen zu protokollieren. Journaltabellen können ganze Zeilen enthalten, um alle Spaltenänderungen zu verfolgen, oder sie können nur den Primärschlüssel mit dem Vorgangstyp (Einfügen, Aktualisieren oder Löschen) behalten. Anschließend können geänderte Daten mit einem SQL-basierten Ansatz erfasst werden, der unter SQL-basiertes CDC beschrieben wird. Die Verwendung von Triggern kann sich auf die Transaktionsleistung auswirken und die Latenz eines einzeiligen DML-Vorgangs verdoppeln, wenn eine vollständige Zeile gespeichert wird. Wenn nur der Primärschlüssel gespeichert wird, kann dieser Mehraufwand reduziert werden. In diesem Fall ist jedoch in der SQL-basierten Extraktion ein JOIN-Vorgang mit der ursprünglichen Tabelle erforderlich, bei dem die Zwischenänderung nicht erfasst wird.
ETL-/ELT-Migration
Es gibt viele Möglichkeiten, ETL/ELT auf Google Cloudzu verarbeiten. Technische Anleitungen zu bestimmten ETL-Arbeitslastumwandlungen fallen nicht in den Geltungsbereich dieses Dokuments. Sie können einen Lift-and-Shift-Ansatz in Betracht ziehen oder Ihre Datenintegrationsplattform umgestalten, abhängig von Einschränkungen wie Kosten und Zeit. Weitere Informationen zur Migration Ihrer Datenpipelines zu Google Cloud und zu vielen anderen Migrationskonzepten finden Sie unter Datenpipelines migrieren.
Lift-and-Shift-Ansatz
Wenn Ihre vorhandene Plattform BigQuery unterstützt und Sie Ihr vorhandenes Tool zur Datenintegration weiterhin verwenden möchten, gehen Sie so vor:
- Sie können die ETL-/ELT-Plattform unverändert lassen und die erforderlichen Speicherphasen in Ihren ETL-/ELT-Jobs durch BigQuery ersetzen.
- Wenn Sie auch die ETL-/ELT-Plattform zu Google Cloud migrieren möchten, können Sie Ihren Anbieter fragen, ob sein Tool in Google Cloudlizenziert ist. Wenn dies der Fall ist, können Sie es in Compute Engine installieren oder den Google Cloud Marketplace prüfen.
Informationen zu den Anbietern von Lösungen für die Datenintegration finden Sie unter BigQuery-Partner.
ETL-/ELT-Plattform neu konzipieren
Wenn Sie Ihre Datenpipelines neu strukturieren möchten, empfehlen wir Ihnen dringend, Google Cloud Dienste zu verwenden.
Cloud Data Fusion
Cloud Data Fusion ist ein verwaltetes CDAP in Google Cloud , das eine visuelle Benutzeroberfläche mit vielen Plug-ins für Aufgaben wie Drag-and-drop und Pipelineentwicklungen bietet. Cloud Data Fusion kann zum Erfassen von Daten aus vielen verschiedenen Arten von Quellsystemen verwendet werden und bietet Funktionen für die Batch- und Streaming-Replikation. Mit Cloud Data Fusion- oder Oracle-Plug-ins können Daten aus einer Oracle-Datenbank erfasst werden. Mit einem BigQuery-Plug-in können Sie die Daten in BigQuery laden und Schemaupdates verarbeiten.
Sowohl für Quell- als auch für Senken-Plug-ins ist kein Ausgabeschema definiert. Außerdem wird im Quell-Plug-in auch select * from verwendet, um neue Spalten zu replizieren.
Sie können das Cloud Data Fusion Wrangle-Feature für die Datenbereinigung und -vorbereitung verwenden.
Dataflow
Dataflow ist eine serverlose Datenverarbeitungsplattform, die Autoscaling sowie Batch- und Streaming-Datenverarbeitung ausführen kann. Dataflow kann eine gute Wahl für Python- und Java-Entwickler sein, die ihre Datenpipelines codieren und denselben Code für Streaming- und Batch-Arbeitslasten verwenden möchten. Verwenden Sie die Vorlage "JDBC zu BigQuery", um Daten aus Ihren Oracle- oder anderen relationalen Datenbanken zu extrahieren und in BigQuery zu laden.
Cloud Composer
Cloud Composer ist ein Google Cloud vollständig verwalteter Dienst für die Workflow-Orchestrierung, der auf Apache Airflow basiert. Sie können damit Pipelines erstellen, planen und überwachen, die sich über Cloud-Umgebungen und lokale Rechenzentren erstrecken. Cloud Composer bietet Operatoren und Beiträge, mit denen Multi-Cloud-Technologien für solche Anwendungsfälle ausgeführt werden können wie Extrahieren und Laden, Transformationen von ELT und REST API-Aufrufe.
Cloud Composer verwendet gerichtete azyklische Graphen (Directed Acyclic Graphs, DAGs) zum Planen und Orchestrating von Workflows. Allgemeine Informationen zu Airflow-Konzepten finden Sie unter Airflow-Apache-Konzepte. Weitere Informationen zu DAGs finden Sie unter DAGs (Workflows) schreiben. Beispiele für ETL-Best-Practices mit Apache Airflow finden Sie unter Dokumentationswebsite für ETL-Best-Practices mit Airflow. Sie können den Hive-Operator in diesem Beispiel durch den BigQuery-Operator ersetzen und es wären die gleichen Konzepte anwendbar.
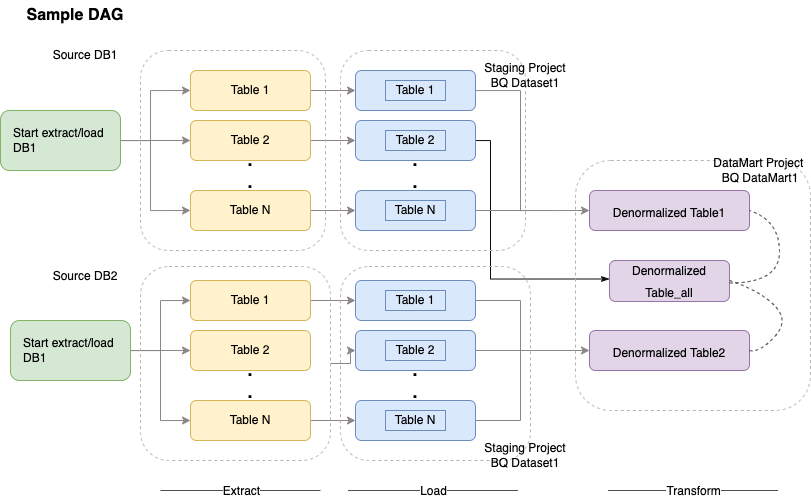
Der folgende Beispielcode ist ein grober Überblick über einen Beispiel-DAG für das vorherige Diagramm:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
Der vorherige Code dient nur zu Demonstrationszwecken und kann nicht unverändert verwendet werden.
Dataprep by Trifacta
Dataprep ist ein Datendienst für die visuelle Erkundung, Bereinigung und Vorbereitung von strukturierten und unstrukturierten Daten für Analysen, Berichte und maschinelles Lernen. Sie exportieren die Quelldaten in JSON- oder CSV-Dateien, transformieren sie mit Dataprep und laden sie mit Dataflow. Ein Beispiel finden Sie unter Oracle-Daten (ETL) mit Dataflow und Dataprep in BigQuery laden.
Dataproc
Dataproc ist ein von Google verwalteter Hadoop-Dienst. Sie können Sqoop verwenden, um Daten aus Oracle und vielen relationalen Datenbanken als Avro-Dateien in Cloud Storage zu exportieren, und dann können Sie Avro-Dateien mit bq tool in BigQuery laden. Es ist sehr verbreitet, ETL-Tools wie CDAP on Hadoop zu installieren, die JDBC zum Extrahieren von Daten und Apache Spark oder MapReduce für die Transformationen der Daten verwenden.
Partnertools für die Datenmigration
Im ETL-Bereich (Extract, Transform and Load) gibt es mehrere Anbieter. ETL-Marktführer wie Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran und Striim sind tief in BigQuery und Oracle eingebunden und können dabei helfen, Daten zu extrahieren, zu transformieren und zu laden sowie Verarbeitungsworkflows zu verwalten.
ETL-Tools gibt es schon seit vielen Jahren. Für einige Organisationen ist es möglicherweise sinnvoll, eine vorhandene Investition in vertrauenswürdige ETL-Scripts zu nutzen. Einige der wichtigsten Partnerlösungen finden Sie auf der BigQuery-Partnerwebsite. Die Entscheidung, wann Partnertools gegenüber denGoogle Cloud vorinstallierten Dienstprogrammen vorgezogen werden, hängt von Ihrer aktuellen Infrastruktur und den Kenntnissen Ihres IT-Teams bei der Entwicklung von Datenpipelines in Java- oder Python-Code ab.
Migration des Business Intelligence-Tools (BI)
BigQuery unterstützt eine flexible Suite von Business Intelligence-Lösungen (BI) für die Berichterstellung und Analyse, die Sie nutzen können. Weitere Informationen zur Migration des BI-Tools und zur BigQuery-Einbindung finden Sie unter Übersicht über BigQuery-Analysen.
Abfrageübersetzung (SQL)
GoogleSQL von BigQuery ist mit dem SQL 2011-Standard kompatibel und bietet Erweiterungen, die die Abfrage verschachtelter und wiederholter Daten unterstützen. Alle ANSI-konformen SQL-Funktionen und -Operatoren können mit minimalen Änderungen verwendet werden. Einen detaillierten Vergleich zwischen der Syntax und den Funktionen von Oracle und BigQuery SQL finden Sie in der Referenz zur Übersetzung von Oracle zu BigQuery SQL.
Verwenden Sie die Batch-SQL-Übersetzung, um Ihren SQL-Code im Bulk zu migrieren, oder die interaktive SQL-Übersetzung, um Ad-hoc-Abfragen zu übersetzen.
Oracle-Optionen migrieren
In diesem Abschnitt werden Architekturempfehlungen und Referenzen zu Konvertierungen von Anwendungen vorgestellt, die Oracle Data Mining-, R- sowie Spatial and Graph-Funktionen verwenden.
Oracle Advanced Analytics-Option
Oracle bietet erweiterte Analyseoptionen für Data Mining, grundlegende Algorithmen für maschinelles Lernen und R-Nutzung. Für die Advanced Analytics-Option ist eine Lizenzierung erforderlich. Sie können aus einer umfassenden Liste von Google AI-/ML-Produkten wählen, abhängig von Ihren Anforderungen von der Entwicklung bis zur Produktion in großem Umfang.
Oracle R Enterprise
Mit Oracle R Enterprise (ORE), einer Komponente der Oracle Advanced Analytics-Option, lässt sich die Open-Source-Programmiersprache R in Oracle Database integrieren. Bei standardmäßigen ORE-Bereitstellungen wird R auf einem Oracle-Server installiert.
Bei sehr großen Datenmengen oder bei Ansätzen für das Data Warehouse ist die Einbindung von R in BigQuery die ideale Lösung. Mit der Open-Source-R-Bibliothek bigrquery können Sie R in BigQuery einbinden.
Google arbeitet mit RStudio zusammen, um die hochmodernen Tools des Gebiets für Nutzer verfügbar zu machen. RStudio kann für den Zugriff auf Terabyte an Daten in BigQuery-geeigneten Modellen in TensorFlow verwendet werden und mit AI Platform Modelle für maschinelles Lernen in großem Maßstab ausführen. In Google Cloudkann R umfassend in der Compute Engine installiert werden.
Oracle Data Mining
Mit Oracle Data Mining (ODM), einer Komponente der Oracle Advanced Analytics-Option, können Entwickler ML-Modelle mit Oracle PL/SQL Developer auf Oracle erstellen.
Mit BigQuery ML können Entwickler viele verschiedene Arten von Modellen ausführen, z. B. lineare Regression, binäre logistische Regression, logistische Mehrklassen-Regression, k-Means-Clustering und TensorFlow-Modellimporte. Weitere Informationen finden Sie unter Einführung in BigQuery ML.
Für die Konvertierung von ODM-Jobs muss der Code möglicherweise neu geschrieben werden. Sie können zwischen umfassenden Google KI-Produkten wie BigQuery ML, AI APIs (Speech-to-Text,Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision, Timeseries Insights API und mehr) und Vertex AI wählen.
Vertex AI Workbench kann als Entwicklungsumgebung für Data Scientists verwendet werden und Vertex AI Training kann zum Ausführen von Trainings- und Bewertungsarbeitslasten in großem Maßstab verwendet werden.
Spatial and Graph-Option
Oracle bietet die Spatial and Graph-Option zum Abfragen von Geometrien und Grafiken und erfordert eine Lizenzierung für diese Option. Sie können die Geometriefunktionen in BigQuery ohne zusätzliche Kosten oder Lizenzen und andere Graphdatenbanken in Google Cloudverwenden.
Räumlich
BigQuery bietet Funktionen und Datentypen für raumbezogene Analysen. Weitere Informationen finden Sie unter Mit raumbezogenen Analysedaten arbeiten. Oracle Spatial-Datentypen und -Funktionen können in geografische Funktionen in BigQuery-Standard-SQL konvertiert werden. Durch geografische Funktionen werden keine Kosten zusätzlich zu den BigQuery-Standardpreisen verursacht.
Grafik
JanusGraph ist eine Open-Source-Graphdatenbank-Lösung, die Bigtable als Speicher-Backend verwenden kann. Weitere Informationen finden Sie unter JanusGraph in GKE mit Bigtable ausführen.
Neo4j ist eine weitere Graphdatenbank-Lösung, die als Google Cloud Dienst in der Google Kubernetes Engine (GKE) bereitgestellt wird.
Oracle Application Express
Oracle Application Express-Anwendungen (APEX) sind eigene Anwendungen von Oracle und müssen neu geschrieben werden. Funktionen zur Berichterstellung und Datenvisualisierung können mit Looker Studio oder BI-Engine entwickelt werden. Funktionen auf Anwendungsebene wie das Erstellen und Bearbeiten von Zeilen können hingegen ohne Codierung in AppSheet unter Verwendung von Cloud SQL entwickelt werden.
Nächste Schritte
- Erfahren Sie, wie Sie Arbeitslasten optimieren, um die Gesamtleistung zu optimieren und Kosten zu reduzieren.
- Erfahren Sie, wie Sie Speicher in BigQuery optimieren.
- Informationen zu BigQuery-Aktualisierungen finden Sie in den Versionshinweisen.
- Sehen Sie sich die Oracle SQL-Übersetzungsanleitung an.