Migrer depuis IBM Netezza
Ce document fournit des conseils généraux sur la migration de Netezza vers BigQuery. Il décrit les différences d'architecture fondamentales entre Netezza et BigQuery, ainsi que les fonctionnalités supplémentaires offertes par BigQuery. Il montre également comment repenser votre modèle de données et vos processus ETL (extraction, transformation et chargement) existants afin de profiter au mieux des avantages de BigQuery.
Ce document est destiné aux architectes d'entreprise, aux administrateurs de bases de données, aux développeurs d'applications et aux professionnels de la sécurité informatique qui souhaitent migrer de Netezza vers BigQuery et résoudre les problèmes techniques liés au processus de migration. Ce document fournit des détails sur les phases suivantes du processus de migration :
- Exportation de données
- Ingérer des données
- Exploitation d'outils tiers
Vous pouvez également utiliser la traduction SQL par lot pour migrer vos scripts SQL de façon groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc. Le langage SQL/NZPLSQL d'IBM Netezza est compatible avec les deux outils en version bêta.
Comparaison des architectures
Netezza est un système puissant qui peut vous aider à stocker et à analyser de grandes quantités de données. Cependant, un système tel que Netezza nécessite d'importants investissements en matériel, en maintenance et en licences. Son évolutivité est limitée en raison des difficultés liées à la gestion des nœuds, au volume de données par source et aux coûts d'archivage. Avec Netezza, la capacité de stockage et de traitement est contrainte par les dispositifs matériels. Lorsque l'utilisation maximale est atteinte, le processus d'extension des capacités matérielles est complexe et parfois même impossible.
Avec BigQuery, vous n'avez pas à gérer l'infrastructure, et vous n'avez pas besoin d'un administrateur de base de données. BigQuery est un entrepôt de données sans serveur, entièrement géré et à l'échelle du pétaoctet, qui peut analyser des milliards de lignes, sans index, en quelques dizaines de secondes. Étant donné que BigQuery partage l'infrastructure de Google, il peut charger chaque requête en parallèle et l'exécuter simultanément sur des dizaines de milliers de serveurs. Les technologies principales suivantes démarquent BigQuery :
- Stockage en colonnes : les données sont stockées dans des colonnes plutôt que dans des lignes, ce qui permet d'atteindre un taux de compression et un débit d'analyse très élevés.
- Architecture sous forme d'arborescence : les requêtes sont distribuées, et les résultats sont agrégés sur des milliers de machines en quelques secondes.
Architecture de Netezza
Netezza est un dispositif avec accélération matérielle, qui est fourni avec une couche logicielle d'abstraction des données. La couche d'abstraction des données gère la distribution des données dans l'appareil et optimise les requêtes en répartissant le traitement des données entre les processeurs et FPGA sous-jacents.
Les modèles Netezza TwinFin et Striper sont arrivés en fin de compatibilité en juin 2019.
Le schéma suivant illustre les couches d'abstraction de données de Netezza :
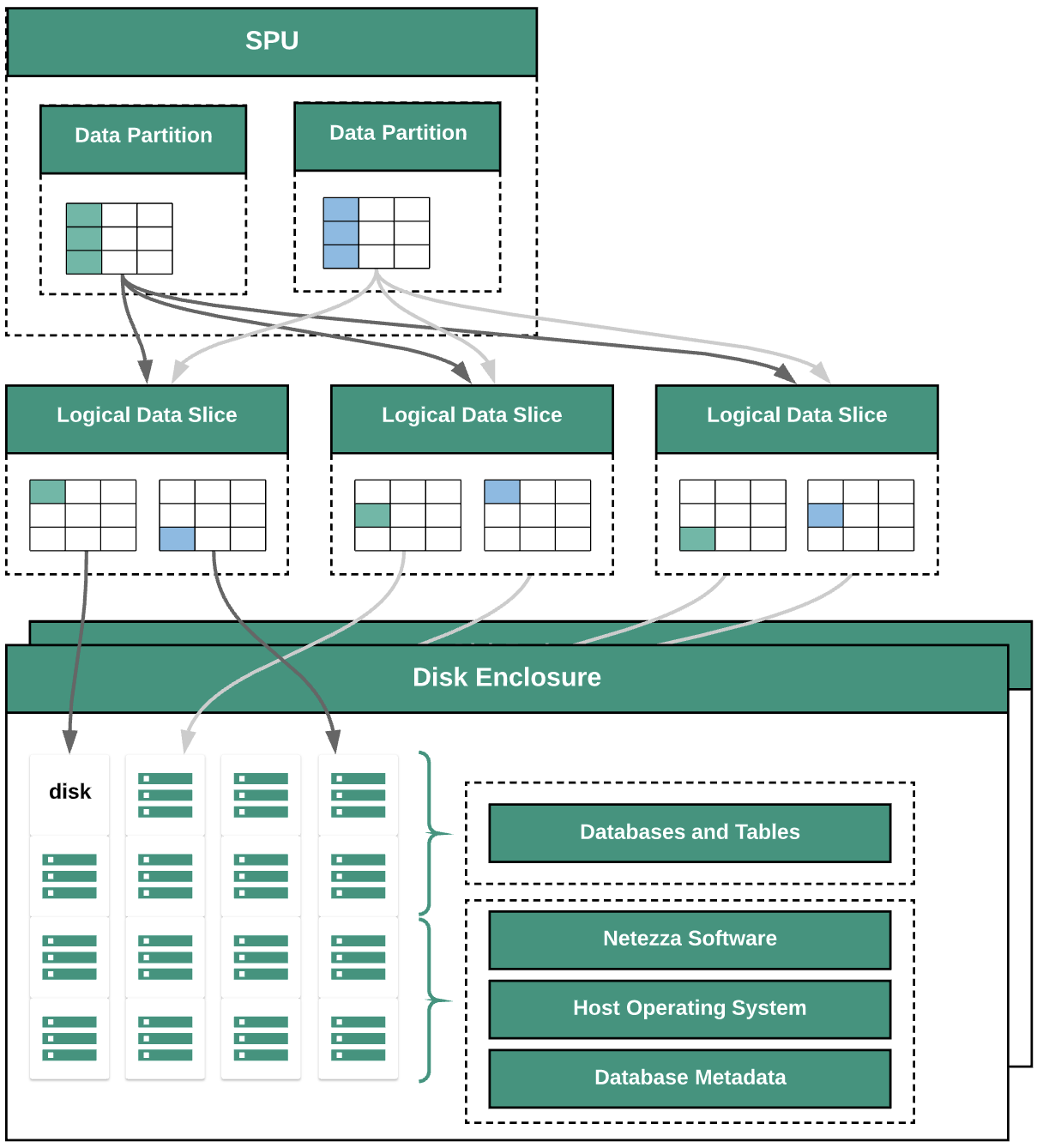
Le schéma présente les couches d'abstraction de données suivantes :
- Boîtier de disque. Espace physique à l'intérieur de l'appareil, où sont installés les disques.
- Disques. Disques physiques au sein des boîtiers, qui stockent les bases de données et les tables.
- Tranches de données. Représentation logique des données enregistrées sur un disque.
Les données sont réparties sur les tranches de données à l'aide d'une clé de distribution. Vous pouvez surveiller l'état des tranches de données à l'aide des commandes
nzds. - Partitions de données. Représentation logique d'une tranche de données gérée par des unités de traitement de fragment (SPU) spécifiques. Chaque SPU possède une ou plusieurs partitions de données contenant les données utilisateur dont le traitement lui incombe lors des requêtes.
Tous les composants du système sont connectés par le maillage réseau. Le dispositif Netezza exécute un protocole personnalisé basé sur les adresses IP.
Architecture de BigQuery
BigQuery est un entrepôt de données d'entreprise entièrement géré, qui vous aide à gérer et analyser vos données grâce à des fonctionnalités intégrées telles que le machine learning, l'analyse géospatiale et l'informatique décisionnelle. Pour en savoir plus, consultez la page Qu'est-ce que BigQuery ?
BigQuery gère le stockage et le calcul, fournissant ainsi un stockage des données durable et des performances élevées pour les réponses aux requêtes analytiques. Pour en savoir plus, consultez la présentation de BigQuery.
Pour en savoir plus sur la tarification de BigQuery, consultez la section Comprendre la capacité de scaling rapide et la tarification simple de BigQuery.
Pré-migration
Pour garantir la réussite de la migration de l'entrepôt de données, commencez par planifier votre stratégie de migration dès le début de votre projet. Pour en savoir plus sur la planification systématique de votre travail de migration, consultez la section Que faut-il migrer et comment procéder : le cadre de migration.
Planification de la capacité BigQuery
Dans BigQuery, le débit des analyses est mesuré en emplacements. Un emplacement BigQuery est l'unité propriétaire de Google représentant la capacité de calcul, de mémoire RAM et de débit réseau nécessaire à l'exécution de requêtes SQL. BigQuery calcule automatiquement le nombre d'emplacements requis par chaque requête, en fonction de la taille et de la complexité de cette requête.
Pour exécuter des requêtes dans BigQuery, sélectionnez l'un des modèles tarifaires suivants :
- À la demande. Modèle de tarification par défaut, dans lequel le nombre d'octets traités par chaque requête vous est facturé.
- Tarifs en fonction de la capacité : Vous achetez des emplacements, qui correspondent à des processeurs virtuels. Lorsque vous achetez des emplacements, vous vous procurez une capacité de traitement dédiée à l'exécution des requêtes. Les emplacements sont disponibles dans les forfaits suivants :
- Forfait annuel : engagement de 365 jours.
- Sur trois ans Vous vous engagez sur 365 x 3 jours.
Un emplacement BigQuery présente des similitudes avec les SPU de Netezza, telles que le processeur, la mémoire et le traitement des données. Cependant, ils ne représentent pas la même unité de mesure. Les SPU de Netezza présentent un mappage fixe avec les composants matériels sous-jacents, tandis que l'emplacement BigQuery représente un processeur virtuel utilisé pour exécuter les requêtes. Pour vous aider à estimer les emplacements, nous vous recommandons de configurer la surveillance BigQuery à l'aide de Cloud Monitoring et d'analyser vos journaux d'audit à l'aide de BigQuery. Pour visualiser l'utilisation des emplacements BigQuery, vous pouvez également utiliser des outils tels que Looker Studio ou Looker. Surveiller et analyser régulièrement l'utilisation des emplacements vous aide à estimer le nombre total d'emplacements dont votre organisation a besoin à mesure que vous développez sur Google Cloud.
Par exemple, supposons que vous réservez initialement 2 000 emplacements BigQuery pour exécuter simultanément 50 requêtes de complexité moyenne. Si l'exécution de vos requêtes prend toujours plus de quelques heures et que vos tableaux de bord indiquent une utilisation élevée des emplacements, il est possible que vos requêtes ne soient pas optimisées ou que vous ayez besoin d'emplacements BigQuery supplémentaires pour prendre en charge vos charges de travail. Pour acheter des emplacements vous-même via des engagements annuels ou de trois ans, vous pouvez créer des réservations BigQuery à l'aide de la console Google Cloud ou de l'outil de ligne de commande bq. Si vous avez souscrit un tarif basé sur la capacité par le biais d'un contrat hors connexion, votre forfait peut être différent de ceux décrits ici.
Pour en savoir plus sur le contrôle des coûts de stockage et des coûts de traitement des requêtes sur BigQuery, consultez la page Optimiser les charges de travail.
Sécurité dans Google Cloud
Les sections suivantes décrivent les contrôles de sécurité courants de Netezza et expliquent comment protéger votre entrepôt de données dans un environnement Google Cloud .
Gestion de l'authentification et des accès
La base de données Netezza contient un ensemble de fonctionnalités de contrôle des accès système entièrement intégrées qui permettent aux utilisateurs d'accéder aux ressources pour lesquelles ils possèdent des autorisations.
L'accès à Netezza est contrôlé via le réseau vers le dispositif Netezza par une gestion des comptes utilisateur Linux autorisés à se connecter au système d'exploitation. L'accès à la base de données, aux objets et aux tâches Netezza est géré à l'aide des comptes utilisateur de la base de données Netezza autorisés à établir des connexions SQL avec le système.
BigQuery utilise l'outil Identity and Access Management (IAM) de Google pour gérer l'accès aux ressources. Les types de ressources disponibles dans BigQuery sont les organisations, les projets, les ensembles de données, les tables les vues. Dans la hiérarchie des stratégies IAM, les ensembles de données sont des ressources enfants des projets. Une table hérite des autorisations de l'ensemble de données qui la contient.
Pour accorder l'accès à une ressource, attribuez un ou plusieurs rôles à un utilisateur, un groupe ou un compte de service. Les rôles au niveau de l'organisation et du projet contrôlent l'accès permettant d'exécuter des tâches ou de gérer le projet, tandis que les rôles pour les ensembles de données contrôlent l'accès permettant d'afficher ou de modifier les données contenues dans un projet.
IAM fournit les types de rôles suivants :
- Rôles prédéfinis : pour les cas d'utilisation courants et les modèles de contrôle des accès.
- Rôles de base : incluent les rôles "Propriétaire", "Éditeur" et "Lecteur". Les rôles prédéfinis fournissent un accès précis à un service spécifique et sont gérés par Google Cloud.
- Rôles personnalisés : fournissent un accès précis en fonction d'une liste d'autorisations spécifiée par l'utilisateur.
Lorsque vous attribuez des rôles prédéfinis et des rôles de base à un utilisateur, les autorisations accordées correspondent à une combinaison des autorisations de chaque rôle individuel.
Sécurité au niveau des lignes
La sécurité à plusieurs niveaux est un modèle de sécurité abstrait, qui permet à Netezza de définir des règles de contrôle d'accès aux tables de lignes sécurisées (RST). Une table de lignes sécurisées est une table de base de données dont les lignes présentent des libellés de sécurité servant à filtrer les utilisateurs qui ne disposent pas des droits appropriés. Les résultats renvoyés sur les requêtes diffèrent en fonction des privilèges de l'utilisateur qui effectue la requête.
Pour établir une sécurité au niveau des lignes dans BigQuery, vous pouvez utiliser les vues autorisées et des règles d'accès au niveau des lignes. Pour en savoir plus sur la conception et la mise en œuvre de ces stratégies, consultez la page Présentation de la sécurité au niveau des lignes de BigQuery.
Chiffrement des données
Les dispositifs Netezza utilisent des disques à chiffrement automatique (SED) pour améliorer la sécurité et la protection des données stockées sur l'appareil. Les SED chiffrent les données lorsqu'elles sont écrites sur le disque. Chaque disque possède une clé de chiffrement de disque (DEK) définie en usine et stockée sur le disque. Le disque utilise la DEK pour chiffrer les données lors de leur écriture, puis pour les déchiffrer lors de leur lecture. Le fonctionnement du disque, ainsi que son chiffrement et son déchiffrement, sont transparents pour les utilisateurs qui lisent et écrivent des données. Ce mode de chiffrement et de déchiffrement par défaut est appelé mode d'effacement sécurisé.
En mode d'effacement sécurisé, vous n'avez pas besoin d'une clé d'authentification ni d'un mot de passe pour déchiffrer et lire des données. Les disques SED offrent des fonctionnalités améliorées pour un effacement sécurisé simple et rapide, dans les cas où les disques doivent être reconditionnés ou renvoyés pour des raisons d'assistance ou de garantie.
Netezza utilise un chiffrement symétrique. Si vos données sont chiffrées au niveau du champ, la fonction de déchiffrement suivante peut vous aider à lire et à exporter les données :
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Toutes les données stockées dans BigQuery sont chiffrées au repos. Si vous souhaitez contrôler vous-même le chiffrement, vous pouvez utiliser des clés gérées par le client (CMEK, Customer-Managed Encryption Keys) pour BigQuery. Avec CMEK, au lieu de laisser Google gérer les clés de chiffrement de clés qui protègent vos données, c'est vous qui vous chargez de cette tâche dans Cloud Key Management Service. Pour en savoir plus, consultez la page Chiffrement au repos.
Analyse comparative des performances
Pour suivre les progrès et les améliorations tout au long du processus de migration, il est important d'établir des performances de référence pour l'environnement Netezza actuel. Pour établir la référence, sélectionnez un ensemble de requêtes représentatives, capturées à partir des applications consommatrices (telles que Tableau ou Cognos).
| Environnement | Netezza | BigQuery |
|---|---|---|
| Taille des données | taille To | - |
| Requête 1 : nom (analyse complète de la table) | mm:ss.ms | - |
| Requête 2 : nom | mm:ss.ms | - |
| Requête 3 : nom | mm:ss.ms | - |
| Total | mm:ss.ms | - |
Configuration de base du projet
Avant de provisionner des ressources de stockage pour la migration des données, vous devez réaliser la configuration de votre projet.
- Pour configurer des projets et activer IAM au niveau du projet, consultez le Google Cloud Well-Architected Framework.
- Pour concevoir les ressources de base qui permettront un déploiement cloud de niveau entreprise, consultez la page Conception de zone de destination dans Google Cloud.
- Pour en savoir plus sur la gouvernance des données et les contrôles dont vous avez besoin lorsque vous migrez votre entrepôt de données sur site vers BigQuery, consultez la page Présentation de la sécurité et de la gouvernance des données.
Connectivité réseau
Une connexion réseau fiable et sécurisée est requise entre le centre de données sur site (hébergeant l'instance Netezza) et l'environnement Google Cloud. Pour savoir comment sécuriser votre connexion, consultez Présentation de la gouvernance des données dans BigQuery. Lorsque vous importez des extractions de données, la bande passante réseau peut être un facteur limitant. Pour savoir comment respecter les exigences des transferts de données, consultez Augmenter la bande passante réseau.
Types et propriétés de données pris en charge
Les types de données Netezza diffèrent des types de données BigQuery. Pour en savoir plus sur les types de données BigQuery, consultez la section Types de données. Pour obtenir une comparaison détaillée des types de données respectifs de Netezza et BigQuery, consultez le Guide de traduction SQL d'IBM Netezza.
Comparaison SQL
Le langage SQL de Netezza est constitué du LDD, du LMD et du langage de contrôle de données (LCD) propre à Netezza, qui sont différents du langage GoogleSQL. GoogleSQL est conforme à la norme SQL 2011 et inclut des extensions permettant d'interroger des données imbriquées et répétées. Si vous utilisez l'ancien SQL de BigQuery, consultez la page Fonctions et opérateurs de l'ancien SQL. Pour obtenir une comparaison détaillée entre les fonctions SQL Netezza et SQL BigQuery, consultez le guide de traduction SQL d'IBM Netezza.
Pour faciliter la migration de votre code SQL, utilisez la traduction SQL par lot afin de migrer votre code SQL de manière groupée, ou la traduction SQL interactive pour traduire des requêtes ad hoc.
Comparaison des fonctions
Il est important de comprendre la correspondance entre les fonctions de Netezza et celles de BigQuery. Par exemple, la fonction Netezza Months_Between génère une valeur décimale, tandis que la fonction BigQuery DateDiff génère un entier. Par conséquent, vous devez utiliser une fonction définie par l'utilisateur (UDF) personnalisée pour générer le type de données approprié. Pour obtenir une comparaison détaillée des fonctions SQL Netezza et GoogleSQL, consultez le guide de traduction du langage SQL d'IBM Netezza.
Migration de données
Pour migrer des données de Netezza vers BigQuery, vous devez exporter les données hors de Netezza, les transférer et les stocker en préproduction sur Google Cloud, puis les charger dans BigQuery. Cette section vous offre une vue d'ensemble du processus de migration de données. Pour obtenir une description détaillée du processus de migration de données, consultez Processus de migration du schéma et des données. Pour obtenir une comparaison détaillée des types de données compatibles respectivement avec Netezza et BigQuery, consultez le Guide de traduction SQL d'IBM Netezza.
Exporter les données hors de Netezza
Pour explorer les données des tables de base de données Netezza, nous vous recommandons de les exporter vers une table externe au format CSV. Pour en savoir plus, consultez la section Décharger des données dans un système client distant. Vous pouvez également lire des données à l'aide de systèmes tiers comme Informatica (ou d'un ETL personnalisé) en utilisant des connecteurs JDBC/ODBC pour produire des fichiers CSV.
Netezza permet uniquement l'exportation de fichiers plats non compressés (CSV) pour chaque table.
Toutefois, si vous exportez des tables volumineuses, le fichier CSV non compressé peut devenir très volumineux. Si possible, envisagez de convertir le fichier CSV dans un format tenant compte du schéma, tel que Parquet, Avro ou ORC, ce qui permet de réduire la taille des fichiers d'exportation avec une meilleure fiabilité. Si CSV est le seul format disponible, nous vous recommandons de compresser les fichiers d'exportation afin de réduire leur taille avant leur importation dans Google Cloud.
Réduire la taille du fichier permet d'accélérer l'importation et d'augmenter la fiabilité du transfert. Si vous transférez des fichiers vers Cloud Storage, vous pouvez utiliser l'indicateur --gzip-local dans une commande gcloud storage cp, qui compresse les fichiers avant de les importer.
Transfert et stockage des données en préproduction
Une fois les données exportées, elles doivent être transférées et stockées en préproduction surGoogle Cloud. Plusieurs options sont disponibles pour le transfert des données, suivant la quantité de données que vous transférez et la bande passante réseau disponible. Pour en savoir plus, consultez la présentation du transfert de schéma et de données.
Lorsque vous utilisez Google Cloud CLI, vous pouvez automatiser et paralléliser le transfert de fichiers vers Cloud Storage. Limitez la taille des fichiers à 4 To (non compressés) pour un chargement plus rapide dans BigQuery. Cependant, vous devez préalablement exporter le schéma. C'est une bonne opportunité d'optimiser BigQuery à l'aide du partitionnement et du clustering.
Utilisez gcloud storage bucket create pour créer les buckets de préproduction servant à stocker les données exportées, et gcloud storage cp pour transférer les fichiers d'exportation des données vers les buckets Cloud Storage.
gcloud CLI effectue automatiquement l'opération de copie en utilisant une combinaison de multithreading et de multitraitement.
Charger des données dans BigQuery
Une fois les données en préproduction dans Google Cloud, plusieurs options s'offrent à vous pour les charger dans BigQuery. Pour en savoir plus, consultez Charger le schéma et les données dans BigQuery.
Outils et assistance proposés par les partenaires
Vous pouvez bénéficier de l'assistance de partenaires pour votre parcours de migration. Pour faciliter la migration de votre code SQL, utilisez la traduction SQL par lot afin de migrer votre code SQL de manière groupée.
De nombreux Google Cloud partenaires proposent également des services de migration d'entrepôts de données. Pour obtenir la liste des partenaires et des solutions qu'ils proposent, consultez Collaborez avec un partenaire pour profiter de son expertise de BigQuery.
Post-migration
Une fois la migration des données terminée, vous pouvez commencer à optimiser votre utilisation deGoogle Cloud pour répondre à vos besoins métier. Cela peut inclure l'utilisation des outils d'exploration et de visualisation deGoogle Cloudafin de dégager des insights pour les acteurs métier, optimiser les requêtes peu performantes ou développer un programme visant à faciliter l'adoption des utilisateurs.
Se connecter aux API BigQuery sur Internet
Le schéma suivant montre comment une application externe peut se connecter à BigQuery à l'aide de l'API :
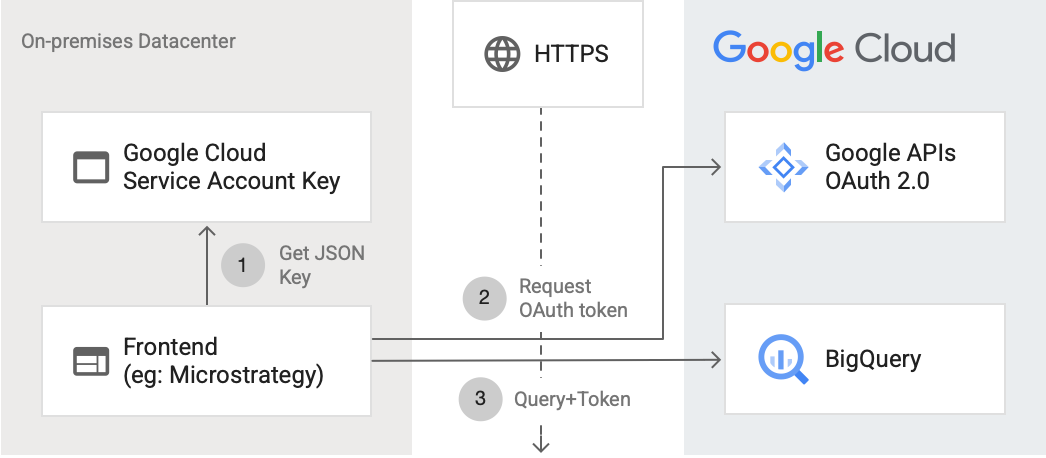
Le schéma montre les étapes suivantes :
- Dans Google Cloud, un compte de service est créé avec des autorisations IAM. La clé du compte de service est générée au format JSON et copiée vers le serveur d'interface (par exemple, MicroStrategy).
- L'interface lit la clé et demande un jeton OAuth aux API Google sur HTTPS.
- L'interface envoie ensuite les requêtes BigQuery ainsi que le jeton à BigQuery.
Pour en savoir plus, consultez la section Autoriser les requêtes API.
Optimisations pour BigQuery
GoogleSQL est conforme à la norme SQL 2011 et inclut des extensions permettant d'interroger des données imbriquées et répétées. L'optimisation des requêtes pour BigQuery est essentielle pour améliorer les performances et les temps de réponse.
Remplacer la fonction Months_Between dans BigQuery par une fonction définie par l'utilisateur
Netezza traite le nombre de jours d'un mois comme étant 31. La fonction UDF personnalisée suivante recrée la fonction Netezza avec une grande précision, et vous pouvez l'appeler dans vos requêtes :
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Migrer les procédures stockées Netezza
Si vous utilisez des procédures stockées Netezza dans des charges de travail ETL pour créer des tables de faits, vous devez passer ces procédures stockées en requêtes SQL compatibles avec BigQuery. Netezza utilise le langage de script NZPLSQL pour travailler avec des procédures stockées. NZPLSQL est basé sur le langage PL/pgSQL de Postgres. Pour en savoir plus, consultez le guide de traduction SQL d'IBM Netezza.
Fonction UDF personnalisée servant à émuler la fonction Netezza ASCII
La fonction UDF personnalisée pour BigQuery ci-dessous corrige les erreurs d'encodage dans les colonnes :
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
Étapes suivantes
- Découvrez comment optimiser les charges de travail afin d'optimiser les performances globales et de réduire les coûts.
- Découvrez comment optimiser le stockage dans BigQuery.
- Consultez le guide de traduction SQL d'IBM Netezza.