Migrer du code avec le traducteur SQL par lot
Ce document explique comment utiliser le traducteur SQL par lot dans BigQuery pour traduire des scripts écrits dans d'autres dialectes SQL en requêtes GoogleSQL. Ce document est destiné aux utilisateurs qui connaissent déjà la consoleGoogle Cloud .
Avant de commencer
Avant d'envoyer une tâche de traduction, procédez comme suit :
- Assurez-vous de disposer des autorisations requises.
- Activez l'API BigQuery Migration.
- Collectez les fichiers sources contenant les scripts et les requêtes SQL à traduire.
- Facultatif. Créez un fichier de métadonnées pour améliorer la précision de la traduction.
- Facultatif. Déterminez si vous devez mapper les noms d'objets SQL dans les fichiers sources aux nouveaux noms dans BigQuery. Déterminez les règles de mappage de noms à utiliser si nécessaire.
- Choisissez la méthode à utiliser pour envoyer la tâche de traduction.
- Importez les fichiers source dans Cloud Storage.
Autorisations requises
Vous devez disposer des autorisations suivantes sur le projet pour activer le service de migration BigQuery :
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
Vous devez disposer des autorisations suivantes sur le projet pour accéder au service de migration BigQuery et l'utiliser :
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listVous pouvez également utiliser les rôles suivants pour obtenir les mêmes autorisations :
bigquerymigration.viewer- Accès en lecture seulebigquerymigration.editor- Accès en lecture/écriture
Pour accéder aux buckets Cloud Storage pour les fichiers d'entrée et de sortie, procédez comme suit :
storage.objects.getsur le bucket Cloud Storage sourcestorage.objects.listsur le bucket Cloud Storage sourcestorage.objects.createsur le bucket Cloud Storage de destination
Vous pouvez disposer de toutes les autorisations Cloud Storage nécessaires ci-dessus à partir des rôles suivants :
roles/storage.objectAdminroles/storage.admin
Activer l'API BigQuery Migration
Si votre projet Google Cloud CLI a été créé avant le 15 février 2022, activez l'API BigQuery Migration comme suit :
Dans la console Google Cloud , accédez à la page API BigQuery Migration.
Cliquez sur Activer.
Collecter les fichiers sources
Les fichiers source doivent être des fichiers texte contenant un langage SQL valide pour le dialecte source. Les fichiers sources peuvent également inclure des commentaires. Faites de votre mieux pour vous assurer que le langage SQL est valide, en utilisant les méthodes à votre disposition.
Créer des fichiers de métadonnées
Pour aider le service à générer des résultats de traduction plus précis, nous vous recommandons de fournir des fichiers de métadonnées. Toutefois, ce n'est pas obligatoire.
Vous pouvez utiliser l'outil de ligne de commande dwh-migration-dumper pour générer les informations de métadonnées ou fournir vos propres fichiers de métadonnées. Une fois les fichiers de métadonnées préparés, vous pouvez les inclure avec les fichiers sources dans le dossier source de la traduction. Le traducteur les détecte automatiquement et les utilise pour traduire les fichiers sources. Vous n'avez pas besoin de configurer de paramètres supplémentaires pour l'activer.
Pour générer des informations de métadonnées à l'aide de l'outil dwh-migration-dumper, consultez la page Générer des métadonnées pour la traduction.
Pour fournir vos propres métadonnées, collectez les instructions LDD (langage de définition de données) des objets SQL de votre système source dans des fichiers texte distincts.
Choisir le mode d'envoi de la tâche de traduction
Vous disposez de trois options pour envoyer une tâche de traduction par lot :
Client de traduction par lot : configurez une tâche en modifiant les paramètres dans un fichier de configuration et en envoyant la tâche à l'aide de la ligne de commande. Cette approche ne nécessite pas l'importation de fichiers sources dans Cloud Storage. Le client utilise toujours Cloud Storage pour stocker les fichiers lors du traitement des tâches de traduction.
L'ancien client de traduction par lot est un client Python Open Source qui vous permet de traduire les fichiers sources situés sur votre ordinateur local, puis d'obtenir les fichiers traduits en sortie dans un répertoire local. Configurez le client pour une utilisation de base en modifiant quelques paramètres dans son fichier de configuration. Si vous le souhaitez, vous pouvez également configurer le client pour traiter des tâches plus complexes telles que le remplacement de macros, et le pré et post-traitement des entrées et des sorties de traduction. Pour en savoir plus, consultez le fichier readme du client de traduction par lot.
ConsoleGoogle Cloud : configurez et envoyez un job à l'aide d'une interface utilisateur. Cette approche nécessite l'importation de fichiers sources dans Cloud Storage.
Créer des fichiers YAML de configuration
Vous pouvez éventuellement créer et utiliser des fichiers de configuration YAML pour personnaliser vos traductions par lots. Ces fichiers peuvent être utilisés pour transformer votre sortie de traduction de différentes manières. Par exemple, vous pouvez créer un fichier YAML de configuration pour modifier la casse d'un objet SQL lors de la traduction.
Si vous souhaitez utiliser la console Google Cloud ou l'API BigQuery Migration pour un job de traduction par lot, vous pouvez importer le fichier YAML de configuration dans le bucket Cloud Storage contenant les fichiers sources.
Si vous souhaitez utiliser le client de traduction par lot, vous pouvez placer le fichier de configuration YAML dans le dossier d'entrée de traduction local.
Importer des fichiers d'entrée dans Cloud Storage
Si vous souhaitez utiliser la console Google Cloud ou l'API BigQuery Migration pour effectuer une tâche de traduction, vous devez importer les fichiers sources contenant les requêtes et les scripts à traduire dans Cloud Storage. Vous pouvez également importer des fichiers de métadonnées ou des fichiers YAML de configuration dans le même bucket et répertoire Cloud Storage contenant les fichiers sources. Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez Créer des buckets et Importer des objets à partir d'un système de fichiers.
Dialectes SQL pris en charge
La traduction SQL par lot fait partie du service de migration BigQuery. Le traducteur SQL par lot peut traduire les dialectes SQL suivants en langage GoogleSQL :
- Amazon Redshift SQL
- CLI Apache HiveQL et Beeline
- IBM Netezza SQL et NZPLSQL
- Teradata et Teradata Vantage
- SQL
- Basic Teradata Query (BTEQ)
- Teradata Parallel Transport (TPT)
De plus, la traduction des dialectes SQL suivants est disponible en version bêta :
- Apache Spark SQL
- Azure Snapse T-SQL
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL, PL/SQL et Exadata
- PostgreSQL SQL
- Trino ou PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
Gérer les fonctions SQL non compatibles avec des fonctions définies par l'utilisateur d'assistance
Lorsque vous traduisez du code SQL d'un dialecte source vers BigQuery, certaines fonctions peuvent ne pas avoir d'équivalent direct. Pour résoudre ce problème, le service de migration BigQuery (et la communauté BigQuery au sens large) fournit des fonctions définies par l'utilisateur (UDF) d'assistance qui reproduisent le comportement de ces fonctions de dialecte source non compatibles.
Ces UDF se trouvent souvent dans l'ensemble de données public bqutil, ce qui permet aux requêtes traduites de les référencer initialement au format bqutil.<dataset>.<function>(). Par exemple, bqutil.fn.cw_count().
Voici quelques remarques importantes concernant les environnements de production :
Bien que bqutil offre un accès pratique à ces UDF d'assistance pour la traduction et les tests initiaux, il n'est pas recommandé de s'appuyer directement sur bqutil pour les charges de travail de production pour plusieurs raisons :
- Contrôle des versions : le projet
bqutilhéberge la dernière version de ces UDF, ce qui signifie que leurs définitions peuvent changer au fil du temps. S'appuyer directement surbqutilpeut entraîner un comportement inattendu ou des modifications incompatibles dans vos requêtes de production si la logique d'une UDF est mise à jour. - Isolation des dépendances : le déploiement d'UDF dans votre propre projet isole votre environnement de production des modifications externes.
- Personnalisation : vous devrez peut-être modifier ou optimiser ces UDF pour mieux les adapter à votre logique métier ou à vos exigences de performances spécifiques. Cela n'est possible que s'ils se trouvent dans votre propre projet.
- Sécurité et gouvernance : les règles de sécurité de votre organisation peuvent restreindre l'accès direct aux ensembles de données publics tels que
bqutilpour le traitement des données de production. La copie des UDF dans votre environnement contrôlé est conforme à ces règles.
Déployer des UDF d'assistance dans votre projet :
Pour une utilisation fiable et stable en production, vous devez déployer ces UDF d'assistance dans votre propre projet et ensemble de données. Vous contrôlez ainsi totalement leur version, leur personnalisation et leur accès. Pour obtenir des instructions détaillées sur le déploiement de ces UDF, consultez le guide de déploiement des UDF sur GitHub. Ce guide fournit les scripts et les étapes nécessaires pour copier les UDF dans votre environnement.
Emplacements
La traduction SQL par lot est disponible dans les emplacements de traitement suivants :
| Description de la région | Nom de la région | Détail | |
|---|---|---|---|
| Asie-Pacifique | |||
| Delhi | asia-south2 |
||
| Hong Kong | asia-east2 |
||
| Jakarta | asia-southeast2 |
||
| Melbourne | australia-southeast2 |
||
| Mumbai | asia-south1 |
||
| Osaka | asia-northeast2 |
||
| Séoul | asia-northeast3 |
||
| Singapour | asia-southeast1 |
||
| Sydney | australia-southeast1 |
||
| Taïwan | asia-east1 |
||
| Tokyo | asia-northeast1 |
||
| Europe | |||
| Belgique | europe-west1 |
|
|
| Berlin | europe-west10 |
||
| UE (multirégional) | eu |
||
| Finlande | europe-north1 |
|
|
| Francfort | europe-west3 |
||
| Londres | europe-west2 |
|
|
| Madrid | europe-southwest1 |
|
|
| Milan | europe-west8 |
||
| Pays-Bas | europe-west4 |
|
|
| Paris | europe-west9 |
|
|
| Stockholm | europe-north2 |
|
|
| Turin | europe-west12 |
||
| Varsovie | europe-central2 |
||
| Zurich | europe-west6 |
|
|
| Amériques | |||
| Columbus, Ohio | us-east5 |
||
| Dallas | us-south1 |
|
|
| Iowa | us-central1 |
|
|
| Las Vegas | us-west4 |
||
| Los Angeles | us-west2 |
||
| Mexique | northamerica-south1 |
||
| Virginie du Nord | us-east4 |
||
| Oregon | us-west1 |
|
|
| Québec | northamerica-northeast1 |
|
|
| São Paulo | southamerica-east1 |
|
|
| Salt Lake City | us-west3 |
||
| Santiago | southamerica-west1 |
|
|
| Caroline du Sud | us-east1 |
||
| Toronto | northamerica-northeast2 |
|
|
| États-Unis (multirégional) | us |
||
| Afrique | |||
| Johannesburg | africa-south1 |
||
| MiddleEast | |||
| Dammam | me-central2 |
||
| Doha | me-central1 |
||
| Israël | me-west1 |
||
Envoyer une tâche de traduction
Procédez comme suit pour démarrer une tâche de traduction, afficher sa progression et consulter les résultats.
Console
Cette procédure suppose que vous avez déjà importé des fichiers sources dans un bucket Cloud Storage.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Outils et guide.
Dans le panneau Traduire le code SQL, cliquez sur Traduire > Traduction par lot.
La page de configuration de la traduction s'ouvre. Saisissez les informations suivantes :
- Dans le champ Nom à afficher, saisissez le nom du job de traduction. Le nom peut contenir des lettres, des chiffres ou des traits de soulignement.
- Dans le champ Emplacement de traitement, sélectionnez l'emplacement où vous souhaitez exécuter la tâche de traduction. Par exemple, si vous êtes en Europe et que vous ne souhaitez pas que vos données dépassent les limites de l'emplacement, sélectionnez la région
eu. La tâche de traduction est plus performante lorsque vous choisissez le même emplacement que le bucket de fichiers source. - Pour le champ Dialecte source, sélectionnez le dialecte SQL que vous souhaitez traduire.
- Pour le champ Dialecte cible, sélectionnez BigQuery.
Cliquez sur Suivant.
Pour Emplacement source, spécifiez le chemin d'accès au dossier Cloud Storage contenant les fichiers à traduire. Vous pouvez saisir le chemin d'accès au format
bucket_name/folder_name/ou utiliser l'option Parcourir.Cliquez sur Suivant.
Pour Emplacement cible, spécifiez le chemin d'accès au dossier Cloud Storage de destination pour les fichiers traduits. Vous pouvez saisir le chemin d'accès au format
bucket_name/folder_name/ou utiliser l'option Parcourir.Si vous effectuez des traductions qui n'ont pas besoin de noms d'objet par défaut ni de mappage de noms source-cible, passez à l'étape 11. Sinon, cliquez sur Suivant.
Renseignez les paramètres facultatifs dont vous avez besoin.
Facultatif. Dans le champ Base de données par défaut, saisissez un nom de base de données par défaut à utiliser avec les fichiers sources. Le traducteur utilise ce nom de base de données par défaut pour résoudre les noms complets des objets SQL dont le nom de base de données est manquant.
Facultatif. Dans le champ Chemin de recherche de schéma, spécifiez un schéma à rechercher lorsque le traducteur doit résoudre les noms complets des objets SQL dans les fichiers sources où le nom de schéma est manquant. Si les fichiers sources utilisent un certain nombre de noms de schémas différents, cliquez sur Ajouter un nom de schéma, puis ajoutez une valeur pour chaque nom de schéma pouvant être référencé.
Le traducteur effectue une recherche dans les fichiers de métadonnées que vous avez fournis pour valider les tables avec leurs noms de schéma. Si aucune option définitive ne peut être déterminée à partir des métadonnées, le premier nom de schéma que vous saisissez est utilisé par défaut. Pour en savoir plus sur l'utilisation du nom de schéma par défaut, consultez la section Schéma par défaut.
Facultatif. Si vous souhaitez spécifier des règles de mappage de noms pour renommer les objets SQL entre le système source et BigQuery lors de la traduction, vous pouvez fournir un fichier JSON contenant la paire de mappage de noms, ou spécifier les valeurs à mapper à l'aide de la consoleGoogle Cloud .
Pour utiliser un fichier JSON :
- Cliquez sur Importer un fichier JSON pour le mappage des noms.
Accédez à l'emplacement d'un fichier de mappage de noms au format approprié, sélectionnez-le, puis cliquez sur Ouvrir.
Notez que la taille du fichier doit être inférieure à 5 Mo.
Pour utiliser la console Google Cloud :
- Cliquez sur Ajouter une paire de mappage de noms.
- Ajoutez les parties appropriées du nom de l'objet source dans les champs Base de données, Schéma, Relation et Attribut de la colonne Source.
- Ajoutez les parties du nom d'objet cible dans BigQuery dans les champs de la colonne Cible.
- Pour Type, sélectionnez un type décrivant l'objet que vous mappez.
- Répétez les étapes 1 à 4 jusqu'à ce que vous ayez spécifié toutes les paires de mappage de noms dont vous avez besoin. Notez que vous ne pouvez spécifier que 25 paires de mappages de noms maximum lorsque vous utilisez la console Google Cloud .
Facultatif. Pour générer des suggestions de traduction par IA à l'aide du modèle Gemini, cochez la case Suggestions d'IA Gemini. Les suggestions sont basées sur le fichier YAML de configuration se terminant par
.ai_config.yamlet situé dans le répertoire Cloud Storage. Chaque type de suggestion est enregistré dans son propre sous-répertoire du dossier de sortie, selon le modèle de dénominationREWRITETARGETSUGGESTION_TYPE_suggestion. Par exemple, les suggestions de personnalisation du code SQL cible amélioré par Gemini sont stockées danstarget_sql_query_customization_suggestion, et l'explication de la traduction générée par Gemini est stockée danstranslation_explanation_suggestion. Pour savoir comment écrire le fichier YAML de configuration pour les suggestions d'IA, consultez Créer un fichier YAML de configuration basé sur Gemini.
Cliquez sur Créer pour démarrer la tâche de traduction.
Une fois la tâche de traduction créée, vous pouvez consulter son état dans la liste des tâches.
Client de traduction par lot
Installez le client de traduction par lot et Google Cloud CLI.
Dans le répertoire d'installation du client de traduction par lot, utilisez l'éditeur de texte de votre choix pour ouvrir le fichier
config.yamlet modifier les paramètres suivants :project_number: saisissez le numéro du projet que vous souhaitez utiliser pour la tâche de traduction par lot. Vous le trouverez dans le volet Informations sur le projet de la page d'accueil de la consoleGoogle Cloud du projet.gcs_bucket: saisissez le nom du bucket Cloud Storage que le client de traduction par lot utilise pour stocker les fichiers lors du traitement de la tâche de traduction.input_directory: saisissez le chemin absolu ou relatif au répertoire contenant les fichiers sources et les fichiers de métadonnées.output_directory: saisissez le chemin absolu ou relatif au répertoire cible pour les fichiers traduits.
Enregistrez les modifications et fermez le fichier
config.yaml.Placez vos fichiers source et de métadonnées dans le répertoire d'entrée.
Exécutez le client de traduction par lot à l'aide de la commande suivante :
bin/dwh-migration-clientUne fois la tâche de traduction créée, vous pouvez consulter son état dans la liste des tâches de traduction de la console Google Cloud .
Facultatif. Une fois la tâche de traduction terminée, supprimez les fichiers créés par la tâche dans le bucket Cloud Storage afin d'éviter des frais de stockage.
Explorer le résultat de la traduction
Une fois la tâche de traduction exécutée, vous pouvez afficher des informations sur cette tâche dans la console Google Cloud . Si vous avez utilisé la console Google Cloud pour exécuter le job, vous pouvez afficher les résultats du job dans le bucket Cloud Storage de destination que vous avez spécifié. Si vous avez utilisé le client de traduction par lot pour exécuter la tâche, vous pouvez afficher les résultats de la tâche dans le répertoire de sortie que vous avez spécifié. Le traducteur SQL par lot renvoie les fichiers suivants à la destination spécifiée :
- Fichiers traduits.
- Rapport de synthèse sur la traduction au format CSV.
- Mappage de nom de sortie consommé au format JSON.
- Fichiers de suggestions de l'IA.
Sortie de la consoleGoogle Cloud
Pour afficher les détails d'une tâche de traduction, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des jobs de traduction, recherchez le job dont vous souhaitez afficher les détails. Cliquez ensuite sur le nom du job de traduction. Vous pouvez voir une visualisation Sankey qui illustre la qualité globale du job, le nombre de lignes de code d'entrée (à l'exclusion des lignes vides et des commentaires) et une liste des problèmes survenus lors du processus de traduction. Vous devez traiter les corrections de gauche à droite. Les problèmes à un stade précoce peuvent entraîner des problèmes supplémentaires aux étapes suivantes.
Pointez sur les barres d'erreur ou d'avertissement, puis examinez les suggestions pour déterminer les prochaines étapes de débogage du job de traduction.
Sélectionnez l'onglet Résumé du journal pour afficher un résumé des problèmes de traduction, y compris les catégories de problèmes, les actions suggérées et la fréquence à laquelle chaque problème s'est produit. Vous pouvez cliquer sur les barres de visualisation Sankey pour filtrer les problèmes. Vous pouvez également sélectionner une catégorie de problème pour afficher les messages de journal associés.
Sélectionnez l'onglet Messages de journal pour afficher plus de détails sur chaque problème de traduction, y compris la catégorie de problème, le message spécifique associé et un lien vers le fichier dans lequel le problème s'est produit. Vous pouvez cliquer sur les barres de visualisation Sankey pour filtrer les problèmes. Vous pouvez sélectionner un problème dans l'onglet Messages de journal pour ouvrir l'onglet Code dans lequel les fichiers d'entrée et de sortie sont affichés, le cas échéant.
Cliquez sur l'onglet Informations sur le job pour afficher les détails de la configuration du job de traduction.
Rapport récapitulatif
Le rapport récapitulatif est un fichier CSV contenant une table de tous les messages d'avertissement et d'erreur rencontrés lors de la tâche de traduction.
Pour afficher le fichier de résumé dans la console Google Cloud , procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des jobs de traduction, recherchez celui qui vous intéresse, puis cliquez sur son nom ou sur Autres options > Afficher les détails.
Dans l'onglet Informations sur le job, dans la section Rapport de traduction, cliquez sur translation_report.csv.
Sur la page Détails de l'objet, cliquez sur la valeur de la ligne URL authentifiée pour afficher le fichier dans votre navigateur.
Le tableau suivant décrit les colonnes du fichier de récapitulatif :
| Colonne | Description |
|---|---|
| Horodatage | Horodatage du problème. |
| Chemin d'accès du fichier | Chemin d'accès au fichier source auquel le problème est associé. |
| Nom du fichier | Le nom du fichier source auquel le problème est associé. |
| Ligne de script | Numéro de la ligne où le problème s'est produit. |
| Colonne de script | Numéro de la colonne où le problème s'est produit. |
| Composant du transpileur | Composant interne du moteur de traduction à l'origine de l'avertissement ou de l'erreur. Cette colonne peut être vide. |
| Environnement | Environnement de dialecte de traduction associé à l'avertissement ou à l'erreur. Cette colonne peut être vide. |
| Nom de l'objet | Objet SQL du fichier source associé à l'avertissement ou à l'erreur. Cette colonne peut être vide. |
| Gravité | Niveau de gravité du problème (avertissement ou erreur). |
| Catégorie | Catégorie du problème de traduction. |
| SourceType | Source de ce problème. La valeur de cette colonne peut être SQL (ce qui indique un problème dans les fichiers SQL d'entrée) ou METADATA (ce qui indique un problème dans le package de métadonnées). |
| Message | Message d'avertissement ou d'erreur de traduction. |
| ScriptContext | Extrait SQL du fichier source associé au problème. |
| Action | L'action que nous vous recommandons d'effectuer pour résoudre le problème. |
Onglet Code
L'onglet "Code" vous permet de consulter des informations supplémentaires sur les fichiers d'entrée et de sortie d'un job de traduction donné. Dans l'onglet "Code", vous pouvez examiner les fichiers utilisés dans un job de traduction, comparer un fichier d'entrée et sa traduction à la recherche d'inexactitudes, et afficher les résumés et les messages de journal d'un fichier spécifique dans un job.
Pour accéder à l'onglet "Code", procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des jobs de traduction, recherchez celui qui vous intéresse, puis cliquez sur son nom ou sur Autres options > Afficher les détails.
Sélectionnez l'onglet Code. L'onglet "Code" se compose des panneaux suivants :
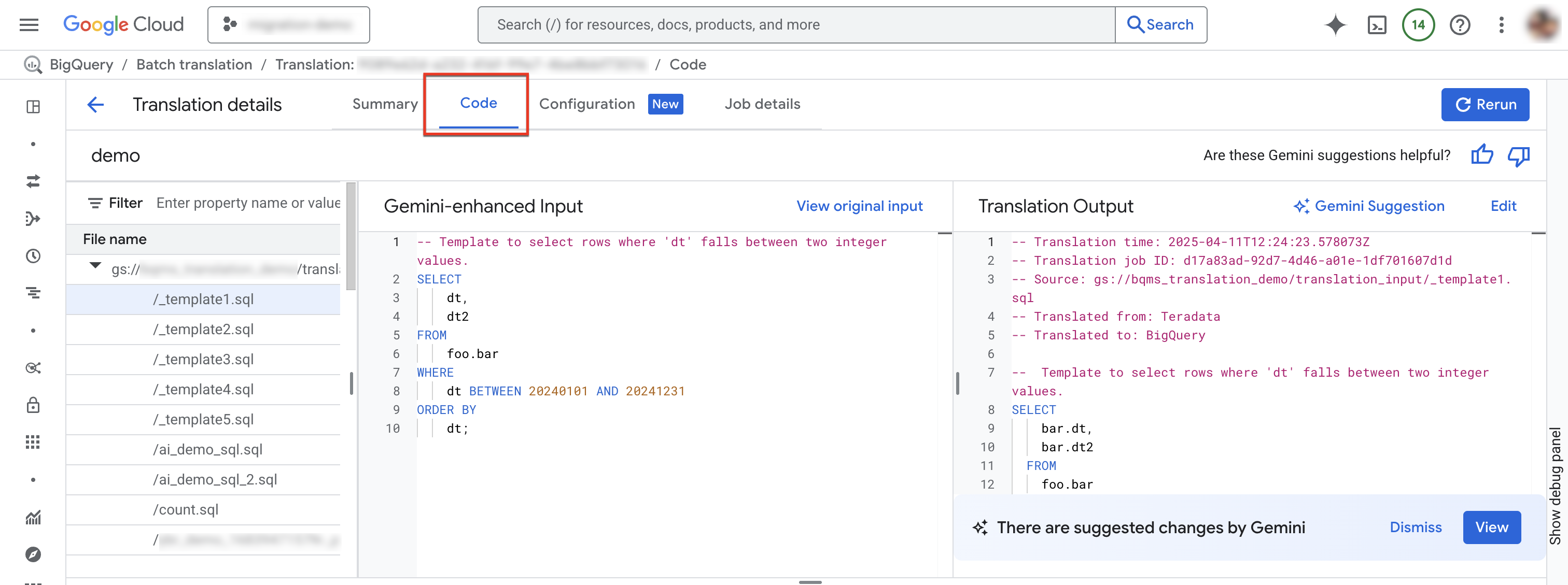
- Explorateur de fichiers : contient tous les fichiers SQL utilisés pour la traduction. Cliquez sur un fichier pour afficher son entrée et sa sortie de traduction, ainsi que les éventuels problèmes de traduction.
- Entrée optimisée par Gemini : code SQL d'entrée qui a été traduit par le moteur de traduction. Si vous avez spécifié des règles de personnalisation Gemini pour le code SQL source dans la configuration Gemini, le traducteur transforme d'abord l'entrée d'origine, puis traduit l'entrée améliorée par Gemini. Pour afficher l'entrée d'origine, cliquez sur Afficher l'entrée d'origine.
- Sortie de traduction : résultat de la traduction. Si vous avez spécifié des règles de personnalisation Gemini pour le code SQL cible dans la configuration Gemini, la transformation est appliquée au résultat traduit en tant que sortie améliorée par Gemini. Si une sortie optimisée par Gemini est disponible, vous pouvez cliquer sur le bouton Suggestion Gemini pour l'examiner.
Facultatif : Pour afficher un fichier d'entrée et son fichier de sortie dans le traducteur SQL interactif de BigQuery, cliquez sur Modifier. Vous pouvez modifier les fichiers et enregistrer le fichier de sortie dans Cloud Storage.
Onglet "Configuration"
Vous pouvez ajouter, renommer, afficher ou modifier vos fichiers YAML de configuration dans l'onglet Configuration.L'explorateur de schéma affiche la documentation des types de configuration compatibles pour vous aider à rédiger vos fichiers YAML de configuration. Après avoir modifié les fichiers YAML de configuration, vous pouvez réexécuter le job pour utiliser la nouvelle configuration.
Pour accéder à l'onglet "Configuration", procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des jobs de traduction, recherchez celui qui vous intéresse, puis cliquez sur son nom ou sur Autres options > Afficher les détails.
Dans la fenêtre Détails de la traduction, cliquez sur l'onglet Configuration.
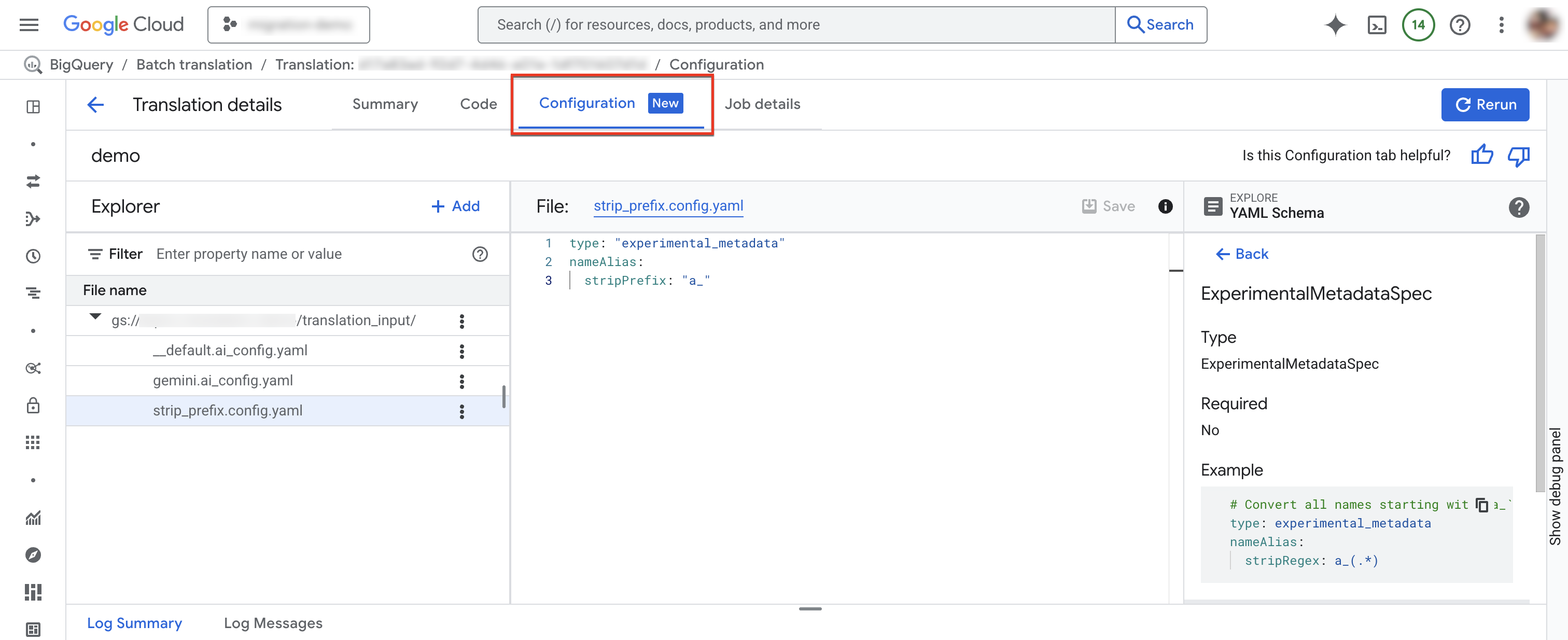
Pour ajouter un fichier de configuration :
- Cliquez sur more_vert Autres options > Créer un fichier YAML de configuration.
- Un panneau s'affiche, dans lequel vous pouvez choisir le type, l'emplacement et le nom du nouveau fichier YAML de configuration.
- Cliquez sur Créer.
Pour modifier un fichier de configuration existant :
- Cliquez sur le fichier YAML de configuration.
- Modifiez le fichier, puis cliquez sur Enregistrer.
- Cliquez sur Exécuter à nouveau pour exécuter un nouveau job de traduction qui utilise les fichiers YAML de configuration modifiés.
Vous pouvez renommer un fichier de configuration existant en cliquant sur more_vert Plus d'options > Renommer.
Fichier de mappage de noms de sortie utilisé
Ce fichier JSON contient les règles de mappage des noms de sortie utilisées par la tâche de traduction Les règles de ce fichier peuvent différer des règles de mappage des noms de sortie que vous avez spécifiées pour la tâche de traduction, en raison de conflits dans les règles de mappage des noms ou de l'absence de ces règles pour les objets SQL identifiés lors de la traduction. Consultez ce fichier pour déterminer si les règles de mappage des noms doivent être corrigées. Si tel est le cas, créez des règles de mappage des noms de sortie pour résoudre les problèmes que vous identifiez, puis exécutez une nouvelle tâche de traduction.
Fichiers traduits
Un fichier de sortie correspondant à chaque fichier d'entrée est généré dans le chemin de destination. Le fichier de sortie contient la requête traduite.
Déboguer des requêtes SQL traduites par lot avec le traducteur SQL interactif
Vous pouvez utiliser le traducteur SQL interactif de BigQuery pour examiner ou déboguer une requête SQL en utilisant les mêmes métadonnées ou informations de mappage d'objets que votre base de données source. Une fois que vous avez terminé une tâche de traduction par lot, BigQuery génère un ID de configuration de traduction contenant des informations sur les métadonnées de la tâche, le mappage d'objets ou le chemin de recherche de schéma, selon le cas de la requête. Vous utilisez l'ID de configuration de traduction par lot avec le traducteur SQL interactif pour exécuter des requêtes SQL avec la configuration spécifiée.
Pour démarrer une traduction SQL interactive à l'aide d'un ID de configuration de traduction par lot, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des jobs de traduction, recherchez celui qui vous intéresse, puis cliquez sur Autres options > Ouvrir la traduction interactive.
La traduction SQL interactive BigQuery s'ouvre désormais avec l'ID de configuration de traduction par lot correspondant. Pour afficher l'ID de configuration de traduction de la traduction interactive, cliquez sur Plus > Paramètres de traduction dans le traducteur SQL interactif.
Pour déboguer un fichier de traduction par lot dans le traducteur SQL interactif, procédez comme suit :
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Traduction SQL.
Dans la liste des tâches de traduction, recherchez celle qui vous intéresse, puis cliquez sur son nom ou sur Autres options > Afficher les détails.
Dans la fenêtre Détails de la traduction, cliquez sur l'onglet Code.
Dans l'explorateur de fichiers, cliquez sur le nom du fichier pour l'ouvrir.
À côté du nom du fichier de sortie, cliquez sur Modifier pour ouvrir les fichiers dans le traducteur SQL interactif (Aperçu).
Les fichiers d'entrée et de sortie sont renseignés dans le traducteur SQL interactif, qui utilise désormais l'ID de configuration de traduction par lot correspondant.
Pour enregistrer le fichier de sortie modifié dans Cloud Storage, cliquez sur Enregistrer> Enregistrer dans GCS dans le traducteur SQL interactif.
Limites
Le traducteur ne peut pas traduire les fonctions définies par l'utilisateur depuis des langages autres que SQL, car il ne peut pas les analyser pour déterminer leurs types de données d'entrée et de sortie. Cela entraîne une traduction inexacte des instructions SQL faisant référence à ces fonctions définies par l'utilisateur. Pour vous assurer que les UDF (fonctions définies par l'utilisateur) non-SQL sont correctement référencées lors de la traduction, utilisez un langage SQL valide pour créer des UDF ayant les mêmes signatures.
Par exemple, supposons que vous ayez une UDF écrite en C qui calcule la somme de deux entiers. Pour vous assurer que les instructions SQL faisant référence à cette UDF sont correctement traduites, créez une UDF SQL d'espace réservé qui partage la même signature que l'UDF en C, comme illustré dans l'exemple suivant :
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
Enregistrez cette UDF dans un fichier texte et incluez ce fichier en tant que fichier source pour la tâche de traduction. Cela permet au traducteur d'apprendre à définir l'UDF et d'identifier les types de données d'entrée et de sortie attendus.
Quota et limites
- Les quotas de l'API BigQuery Migration s'appliquent.
- Chaque projet peut comporter au maximum 10 tâches de traduction active.
- Bien qu'il n'existe aucune limite stricte pour le nombre total de fichiers sources et de métadonnées, nous vous recommandons de limiter ce nombre à 1 000 pour de meilleures performances.
Résoudre les erreurs de traduction
Problèmes de traduction RelationNotFound ou AttributeNotFound
La traduction fonctionne mieux avec des LDD de métadonnées. Lorsque les définitions d'objets SQL sont introuvables, le moteur de traduction génère des erreurs RelationNotFound ou AttributeNotFound. Nous vous recommandons d'utiliser l'extracteur de métadonnées pour générer des packages de métadonnées afin de vous assurer que toutes les définitions d'objets sont présentes. L'ajout de métadonnées est la première étape recommandée pour résoudre la plupart des erreurs de traduction, car cela permet souvent de corriger de nombreuses autres erreurs causées indirectement par un manque de métadonnées.
Pour en savoir plus, consultez la page Générer des métadonnées pour la traduction et l'évaluation.
Tarifs
L'utilisation du traducteur SQL par lot est gratuite. En revanche, le stockage des fichiers d'entrée et de sortie entraîne des frais normaux. Pour en savoir plus, consultez les tarifs de stockage.
Étapes suivantes
Découvrez les étapes suivantes de la migration d'entrepôts de données :
- Présentation de la migration
- Évaluation de la migration
- Présentation du transfert de schéma et de données
- Pipelines de données
- Traduction SQL interactive
- Sécurité et gouvernance des données
- Outil de validation des données