Avaliação da migração
A avaliação da migração do BigQuery permite-lhe planear e rever a migração do seu armazém de dados existente para o BigQuery. Pode executar a avaliação da migração do BigQuery para gerar um relatório que avalie o custo de armazenamento dos seus dados no BigQuery, ver como o BigQuery pode otimizar a sua carga de trabalho existente para poupar custos e preparar um plano de migração que descreva o tempo e o esforço necessários para concluir a migração do armazém de dados para o BigQuery.
Este documento descreve como usar a avaliação da migração do BigQuery e as diferentes formas de rever os resultados da avaliação. Este documento destina-se a utilizadores que estão familiarizados com a Google Cloud consola e o tradutor de SQL em lote.
Antes de começar
Para preparar e executar uma avaliação de migração do BigQuery, siga estes passos:
Extraia metadados e registos de consultas do seu armazém de dados através da ferramenta
dwh-migration-dumper.Carregue os seus metadados e registos de consultas para o seu contentor do Cloud Storage.
Opcional: consulte os resultados da avaliação para encontrar informações de avaliação detalhadas ou específicas.
Extraia metadados e consulte registos do seu armazém de dados
São necessários metadados e registos de consultas para preparar a avaliação com recomendações.
Para extrair os metadados e os registos de consultas necessários para executar a avaliação, selecione o seu data warehouse:
Teradata
Requisitos
- Um computador ligado ao seu data warehouse de dados Teradata (O Teradata 15 e versões posteriores são suportados)
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados
- Um conjunto de dados do BigQuery vazio para armazenar os resultados
- Autorizações de leitura no conjunto de dados para ver os resultados
- Recomendado: direitos de acesso ao nível de administrador à base de dados de origem quando usar a ferramenta de extração para aceder às tabelas do sistema
Requisito: ative o registo
A ferramenta dwh-migration-dumper extrai três tipos de registos: registos de consultas, registos de utilitários e registos de utilização de recursos. Tem de ativar o registo para os seguintes tipos de registos para ver estatísticas mais detalhadas:
- Registos de consultas: extraídos da vista
dbc.QryLogVe da tabeladbc.DBQLSqlTbl. Ative o registo especificando a opçãoWITH SQL. - Registos de utilidade: extraídos da tabela
dbc.DBQLUtilityTbl. Ative o registo especificando a opçãoWITH UTILITYINFO. - Registos de utilização de recursos: extraídos das tabelas
dbc.ResUsageScpuedbc.ResUsageSpma. Ative o registo RSS para estas duas tabelas.
Execute a ferramenta dwh-migration-dumper
Transfira a ferramenta dwh-migration-dumper.
Transfira o ficheiro
SHA256SUMS.txt
e execute o seguinte comando para verificar se o ZIP está correto:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Substitua RELEASE_ZIP_FILENAME pelo nome do ficheiro ZIP transferido da versão da ferramenta de extração de linhas de comando dwh-migration-dumper, por exemplo, dwh-migration-tools-v1.0.52.zip
O resultado True confirma a validação da soma de verificação bem-sucedida.
O resultado False indica um erro de validação. Certifique-se de que os ficheiros ZIP e de soma de verificação são transferidos da mesma versão de lançamento e colocados no mesmo diretório.
Para ver detalhes sobre como configurar e usar a ferramenta de extração, consulte o artigo Gere metadados para tradução e avaliação.
Use a ferramenta de extração para extrair registos e metadados do seu armazém de dados do Teradata como dois ficheiros ZIP. Execute os seguintes comandos numa máquina com acesso ao data warehouse de origem para gerar os ficheiros.
Gere o ficheiro ZIP de metadados:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: a flag --database é opcional para o conector teradata. Se for omitido, são extraídos os metadados de todas as bases de dados. Este sinalizador só é válido para o conector teradata e não pode ser usado com teradata-logs.
Gere o ficheiro ZIP com os registos de consultas:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: a flag --database não é usada quando extrai registos de consultas com o conector teradata-logs. Os registos de consultas são sempre extraídos para todas as bases de dados.
Substitua o seguinte:
PATH: o caminho absoluto ou relativo para o ficheiro JAR do controlador a usar para esta ligaçãoVERSION: a versão do seu controladorHOST: o endereço do anfitriãoUSER: o nome de utilizador a usar para a ligação à base de dadosDATABASES: (opcional) a lista separada por vírgulas dos nomes das bases de dados a extrair. Se não for fornecido, todas as bases de dados são extraídas.PASSWORD: (opcional) a palavra-passe a usar para a ligação à base de dados. Se este campo não for preenchido, é pedida a palavra-passe ao utilizador.
Por predefinição, os registos de consultas são extraídos
da vista dbc.QryLogV e da tabela dbc.DBQLSqlTbl. Se precisar de
extrair os registos de consultas de uma localização alternativa, pode
especificar os nomes das tabelas ou das vistas através das flags
-Dteradata-logs.query-logs-table e -Dteradata-logs.sql-logs-table.
Por predefinição, os registos de utilitários são extraídos da tabela
dbc.DBQLUtilityTbl. Se precisar de extrair os registos de utilidade de uma localização alternativa, pode especificar o nome da tabela através da flag -Dteradata-logs.utility-logs-table.
Por predefinição, os registos de utilização de recursos são extraídos das tabelas dbc.ResUsageScpu e dbc.ResUsageSpma. Se precisar de extrair os registos de utilização de recursos de uma localização alternativa, pode especificar os nomes das tabelas através das flags -Dteradata-logs.res-usage-scpu-table e -Dteradata-logs.res-usage-spma-table.
Por exemplo:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
Por predefinição, a ferramenta dwh-migration-dumper extrai os últimos sete dias de registos de consultas.
A Google recomenda que forneça, pelo menos, duas semanas de registos de consultas para poder ver estatísticas mais detalhadas. Pode especificar um intervalo de tempo personalizado usando as flags --query-log-start e --query-log-end. Por exemplo:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
Também pode gerar vários ficheiros ZIP com registos de consultas que abrangem diferentes períodos e fornecê-los todos para avaliação.
Redshift
Requisitos
- Um computador ligado ao seu data warehouse do Amazon Redshift de origem
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados
- Um conjunto de dados do BigQuery vazio para armazenar os resultados
- Autorizações de leitura no conjunto de dados para ver os resultados
- Recomendado: acesso de superutilizador à base de dados quando usar a ferramenta de extração para aceder a tabelas do sistema
Execute a ferramenta dwh-migration-dumper
Transfira a dwh-migration-dumper ferramenta de extração de linhas de comando.
Transfira o ficheiro
SHA256SUMS.txt
e execute o seguinte comando para verificar se o ZIP está correto:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Substitua RELEASE_ZIP_FILENAME pelo nome do ficheiro ZIP transferido da versão da ferramenta de extração de linhas de comando dwh-migration-dumper, por exemplo, dwh-migration-tools-v1.0.52.zip
O resultado True confirma a validação da soma de verificação bem-sucedida.
O resultado False indica um erro de validação. Certifique-se de que os ficheiros ZIP e de soma de verificação são transferidos da mesma versão de lançamento e colocados no mesmo diretório.
Para ver detalhes sobre como usar a ferramenta dwh-migration-dumper, consulte a página gerar metadados.
Use a ferramenta dwh-migration-dumper para extrair registos e metadados do seu armazém de dados do Amazon Redshift como dois ficheiros ZIP.
Execute os seguintes comandos numa máquina com acesso ao data warehouse de origem para gerar os ficheiros.
Gere o ficheiro ZIP de metadados:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Gere o ficheiro ZIP com os registos de consultas:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Substitua o seguinte:
DATABASE: o nome da base de dados à qual se ligarPATH: o caminho absoluto ou relativo para o ficheiro JAR do controlador a usar para esta ligaçãoVERSION: a versão do seu controladorUSER: o nome de utilizador a usar para a ligação à base de dadosIAM_PROFILE_NAME: o nome do perfil de IAM do Amazon Redshift. Obrigatório para a autenticação do Amazon Redshift e para o acesso à API AWS. Para obter a descrição dos clusters do Amazon Redshift, use a API AWS.
Por predefinição, o Amazon Redshift armazena registos de consultas de três a cinco dias.
Por predefinição, a ferramenta dwh-migration-dumper extrai os últimos sete dias de registos de consultas.
A Google recomenda que faculte, pelo menos, duas semanas de registos de consultas para poder ver estatísticas mais detalhadas. Pode ter de executar a
ferramenta de extração algumas vezes
ao longo de duas semanas para obter os melhores resultados. Pode especificar um intervalo personalizado através das flags --query-log-start e --query-log-end.
Por exemplo:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
Também pode gerar vários ficheiros ZIP com registos de consultas que abrangem diferentes períodos e fornecê-los todos para avaliação.
Redshift sem servidor
Requisitos
- Um computador ligado ao seu data warehouse Amazon Redshift Serverless de origem
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados
- Um conjunto de dados do BigQuery vazio para armazenar os resultados
- Autorizações de leitura no conjunto de dados para ver os resultados
- Recomendado: acesso de superutilizador à base de dados quando usar a ferramenta de extração para aceder a tabelas do sistema
Execute a ferramenta dwh-migration-dumper
Transfira a dwh-migration-dumper ferramenta de extração de linhas de comando.
Para ver detalhes sobre como usar a ferramenta dwh-migration-dumper, consulte a página
Gere metadados.
Use a ferramenta dwh-migration-dumper para extrair registos de utilização e metadados do seu espaço de nomes sem servidor do Amazon Redshift como dois ficheiros ZIP. Execute os seguintes comandos numa máquina com acesso ao data warehouse de origem para gerar os ficheiros.
Gere o ficheiro ZIP de metadados:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Gere o ficheiro ZIP com os registos de consultas:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Substitua o seguinte:
DATABASE: o nome da base de dados à qual se ligarPATH: o caminho absoluto ou relativo para o ficheiro JAR do controlador a usar para esta ligaçãoVERSION: a versão do seu controladorUSER: o nome de utilizador a usar para a ligação à base de dadosIAM_PROFILE_NAME: o nome do perfil de IAM do Amazon Redshift. Obrigatório para a autenticação do Amazon Redshift e para o acesso à API AWS. Para obter a descrição dos clusters do Amazon Redshift, use a API AWS.
O Amazon Redshift Serverless armazena registos de utilização durante sete dias. Se for necessário um intervalo mais amplo, a Google recomenda que extraia dados várias vezes durante um período mais longo.
Floco de neve
Requisitos
Tem de cumprir os seguintes requisitos para extrair metadados e registos de consultas do Snowflake:
- Uma máquina que pode estabelecer ligação às suas instâncias do Snowflake.
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados.
- Um conjunto de dados do BigQuery vazio para armazenar os resultados. Em alternativa, pode criar um conjunto de dados do BigQuery quando criar a tarefa de avaliação através da Google Cloud IU da consola.
- Utilizador do Snowflake com acesso
IMPORTED PRIVILEGESna base de dadosSnowflake. Recomendamos que crie umSERVICEutilizador com uma autenticação baseada num par de chaves. Isto fornece o método seguro para aceder à plataforma de dados do Snowflake sem necessidade de gerar tokens de MFA.- Para criar um novo utilizador do serviço, siga o guia oficial do Snowflake. Tem de gerar o par de chaves RSA e atribuir a chave pública ao utilizador do Snowflake.
- O utilizador do serviço deve ter a função
ACCOUNTADMINou ser-lhe concedida uma função com os privilégiosIMPORTED PRIVILEGESna base de dadosSnowflakepor um administrador da conta. - Em alternativa à autenticação por par de chaves, pode usar a autenticação baseada em palavra-passe. No entanto, a partir de agosto de 2025, a Snowflake vai aplicar a MFA a todos os utilizadores baseados em palavras-passe. Isto requer que aprove a notificação push da MFA quando usar a nossa ferramenta de extração.
Execute a ferramenta dwh-migration-dumper
Transfira a dwh-migration-dumper ferramenta de extração de linhas de comando.
Transfira o ficheiro
SHA256SUMS.txt
e execute o seguinte comando para verificar se o ZIP está correto:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Substitua RELEASE_ZIP_FILENAME pelo nome do ficheiro ZIP transferido da versão da ferramenta de extração de linhas de comando dwh-migration-dumper, por exemplo, dwh-migration-tools-v1.0.52.zip
O resultado True confirma a validação da soma de verificação bem-sucedida.
O resultado False indica um erro de validação. Certifique-se de que os ficheiros ZIP e de soma de verificação são transferidos da mesma versão de lançamento e colocados no mesmo diretório.
Para ver detalhes sobre como usar a ferramenta dwh-migration-dumper, consulte a página gerar metadados.
Use a ferramenta dwh-migration-dumper para extrair registos e metadados do seu armazém de dados do Snowflake como dois ficheiros ZIP. Execute os seguintes comandos numa máquina com acesso ao data warehouse de origem para gerar os ficheiros.
Gere o ficheiro ZIP de metadados:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Gere o ficheiro ZIP com os registos de consultas:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Substitua o seguinte:
HOST_NAME: o nome do anfitrião da sua instância do Snowflake.USER_NAME: o nome de utilizador a usar para a ligação à base de dados, em que o utilizador tem de ter as autorizações de acesso detalhadas na secção de requisitos.PRIVATE_KEY_PATH: o caminho para a chave privada RSA usada para autenticação.PRIVATE_KEY_PASSWORD: (Opcional) a palavra-passe que foi usada quando criou a chave privada RSA. Só é necessário se a chave privada estiver encriptada.ROLE_NAME: (opcional) a função do utilizador quando executa a ferramentadwh-migration-dumper, por exemplo,ACCOUNTADMIN.WAREHOUSE: o armazém usado para executar as operações de descarga. Se tiver vários armazéns virtuais, pode especificar qualquer armazém para executar esta consulta. A execução desta consulta com as autorizações de acesso detalhadas na secção de requisitos extrai todos os artefactos do armazém nesta conta.STARTING_DATE: (opcional) usado para indicar a data de início num intervalo de datas dos registos de consultas, escrito no formatoYYYY-MM-DD.ENDING_DATE: (opcional) usado para indicar a data de conclusão num intervalo de datas dos registos de consultas, escrito no formatoYYYY-MM-DD.
Também pode gerar vários ficheiros ZIP com registos de consultas que abrangem períodos não sobrepostos e fornecê-los todos para avaliação.
Oracle
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Requisitos
Tem de cumprir os seguintes requisitos para extrair metadados e consultar registos do Oracle:
- A sua base de dados Oracle tem de ser a versão 11g R1 ou superior.
- Uma máquina que pode estabelecer ligação às suas instâncias do Oracle.
- Java 8 ou superior.
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados.
- Um conjunto de dados do BigQuery vazio para armazenar os resultados. Em alternativa, pode criar um conjunto de dados do BigQuery quando criar a tarefa de avaliação através da Google Cloud IU da consola.
- Um utilizador comum do Oracle com privilégios SYSDBA.
Execute a ferramenta dwh-migration-dumper
Transfira a dwh-migration-dumper ferramenta de extração de linhas de comando.
Transfira o ficheiro
SHA256SUMS.txt
e execute o seguinte comando para verificar se o ZIP está correto:
sha256sum --check SHA256SUMS.txt
Para ver detalhes sobre como usar a ferramenta dwh-migration-dumper, consulte a página gerar metadados.
Use a ferramenta dwh-migration-dumper para extrair metadados e estatísticas de desempenho para o ficheiro ZIP. Por predefinição, as estatísticas são extraídas do Oracle AWR, que requer o Oracle Tuning and Diagnostics Pack. Se estes dados não estiverem disponíveis, a função dwh-migration-dumper usa o STATSPACK.
Para bases de dados multiinquilino, a ferramenta dwh-migration-dumper tem de ser executada
no contentor raiz. A execução numa das bases de dados conectáveis resulta
em estatísticas de desempenho e metadados em falta sobre outras bases de dados
conectáveis.
Gere o ficheiro ZIP de metadados:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Substitua o seguinte:
HOST_NAME: o nome do anfitrião da sua instância do Oracle.PORT: o número da porta de ligação. O valor predefinido é 1521.SERVICE_NAME: o nome do serviço Oracle a usar para a ligação.JDBC_DRIVER_PATH: o caminho absoluto ou relativo para o ficheiro JAR do controlador. Pode transferir este ficheiro a partir da página Transferências do controlador JDBC da Oracle. Deve selecionar a versão do controlador compatível com a versão da sua base de dados.USER_NAME: nome do utilizador usado para estabelecer ligação à sua instância do Oracle. O utilizador tem de ter as autorizações de acesso conforme detalhado na secção de requisitos.
Hadoop / Cloudera
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Requisitos
Tem de ter o seguinte para extrair metadados do Cloudera:
- Uma máquina que possa estabelecer ligação à API Cloudera Manager.
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados.
- Um conjunto de dados do BigQuery vazio para armazenar os resultados. Em alternativa, pode criar um conjunto de dados do BigQuery quando criar a tarefa de avaliação.
Execute a ferramenta dwh-migration-dumper
Transfira a
dwh-migration-dumperferramenta de extração de linhas de comando.Transfira o ficheiro
SHA256SUMS.txt.No ambiente de linha de comandos, verifique se o ficheiro ZIP está correto:
sha256sum --check SHA256SUMS.txt
Para ver detalhes sobre como usar a ferramenta
dwh-migration-dumper, consulte o artigo Gere metadados para tradução e avaliação.Use a
dwh-migration-dumperferramenta para extrair metadados e estatísticas de desempenho para o ficheiro ZIP:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Substitua o seguinte:
USER_NAME: o nome do utilizador para estabelecer ligação à sua instância do Cloudera Manager.PASSWORD: a palavra-passe da sua instância do Cloudera Manager.URL_PATH: o caminho do URL para a Cloudera Manager API, por exemplo,https://localhost:7183/api/v55/.APP_TYPES(opcional): os tipos de aplicações YARN separados por vírgulas que são transferidos do cluster. O valor predefinido éMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(opcional): o número de registos por resposta do Cloudera. O valor predefinido é1000.START_DATE(opcional): a data de início da exportação do histórico no formato ISO 8601, por exemplo,2025-05-29. O valor predefinido é 90 dias antes da data atual.END_DATE(opcional): a data de fim da exportação do histórico no formato ISO 8601, por exemplo,2025-05-30. O valor predefinido é a data atual.
Use o Oozie no seu cluster Cloudera
Se usar o Oozie no seu cluster Cloudera, pode transferir o histórico de tarefas do Oozie com o conetor do Oozie. Pode usar o Oozie com a autenticação Kerberos ou a autenticação básica.
Para a autenticação Kerberos, execute o seguinte:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Substitua o seguinte:
URL_PATH(opcional): o caminho do URL do servidor Oozie. Se não especificar o caminho do URL, este é retirado daOOZIE_URLvariável de ambiente.
Para a autenticação básica, execute o seguinte:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Substitua o seguinte:
USER_NAME: o nome do utilizador do Oozie.PASSWORD: a palavra-passe do utilizador.URL_PATH(opcional): o caminho do URL do servidor Oozie. Se não especificar o caminho do URL, este é retirado daOOZIE_URLvariável de ambiente.
Use o Airflow no seu cluster Cloudera
Se usar o Airflow no seu cluster Cloudera, pode transferir o histórico de DAGs com o conetor do Airflow:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Substitua o seguinte:
USER_NAME: o nome do utilizador do AirflowPASSWORD: a palavra-passe do utilizadorURL: a string JDBC para a base de dados do AirflowDRIVER_PATH: o caminho para o controlador JDBCSTART_DATE(opcional): a data de início da exportação do histórico no formato ISO 8601END_DATE(opcional): a data de fim da exportação do histórico no formato ISO 8601
Use o Hive no seu cluster Cloudera
Para usar o conector do Hive, consulte o separador Apache Hive.
Apache Hive
Requisitos
- Um computador ligado ao seu armazém de dados Apache Hive de origem (A avaliação da migração do BigQuery suporta o Hive no Tez e o MapReduce, e suporta as versões do Apache Hive entre 2.2 e 3.1, inclusive)
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados
- Um conjunto de dados do BigQuery vazio para armazenar os resultados
- Autorizações de leitura no conjunto de dados para ver os resultados
- Acesso ao seu armazém de dados do Apache Hive de origem para configurar a extração de registos de consultas
- Estatísticas de tabelas, partições e colunas atualizadas
A avaliação da migração do BigQuery usa estatísticas de tabelas, partições e colunas para
compreender melhor o seu armazém de dados do Apache Hive e fornecer
estatísticas detalhadas. Se a definição de configuração hive.stats.autogather estiver definida como false no seu data warehouse do Apache Hive de origem, a Google recomenda que a ative ou atualize as estatísticas manualmente antes de executar a ferramenta dwh-migration-dumper.
Execute a ferramenta dwh-migration-dumper
Transfira a dwh-migration-dumper ferramenta de extração de linhas de comando.
Transfira o ficheiro
SHA256SUMS.txt
e execute o seguinte comando para verificar se o ZIP está correto:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Substitua RELEASE_ZIP_FILENAME pelo nome do ficheiro ZIP transferido da versão da ferramenta de extração de linhas de comando dwh-migration-dumper, por exemplo, dwh-migration-tools-v1.0.52.zip
O resultado True confirma a validação da soma de verificação bem-sucedida.
O resultado False indica um erro de validação. Certifique-se de que os ficheiros ZIP e de soma de verificação são transferidos da mesma versão de lançamento e colocados no mesmo diretório.
Para ver detalhes sobre como usar a ferramenta dwh-migration-dumper, consulte o artigo
Gere metadados para tradução e avaliação.
Use a ferramenta dwh-migration-dumper para gerar metadados do seu armazém de dados do Hive como um ficheiro ZIP.
Sem autenticação
Para gerar o ficheiro ZIP de metadados, execute o seguinte comando numa máquina que tenha acesso ao data warehouse de origem:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Com a autenticação Kerberos
Para autenticar no metastore, inicie sessão como um utilizador que tenha acesso ao metastore do Apache Hive e gere um pedido do Kerberos. Em seguida, gere o ficheiro ZIP de metadados com o seguinte comando:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Substitua o seguinte:
DATABASES: a lista separada por vírgulas dos nomes das bases de dados a extrair. Se não for fornecido, todas as bases de dados são extraídas.PRINCIPAL: o principal do Kerberos ao qual a permissão é emitidaHOST: o nome do anfitrião Kerberos para o qual a permissão é emitidahadoop.rpc.protection: a qualidade de proteção (QOP) do nível de configuração da camada de autenticação e segurança simples (SASL), igual ao valor do parâmetrohadoop.rpc.protectionno ficheiro/etc/hadoop/conf/core-site.xml, com um dos seguintes valores:authenticationintegrityprivacy
Extraia registos de consultas com o gancho de registo hadoop-migration-assessment
Para extrair registos de consultas, siga estes passos:
- Carregue o
hadoop-migration-assessmentgancho de registo. - Configure as propriedades do gancho de registo.
- Valide o gancho de registo.
Carregue o hadoop-migration-assessment logging hook
Transfira o
hadoop-migration-assessmentgancho de registo de extração de registos de consultas que contém o ficheiro JAR do gancho de registo do Hive.Extraia o ficheiro JAR.
Se precisar de auditar a ferramenta para garantir que cumpre os requisitos de conformidade, reveja o código fonte do
hadoop-migration-assessmentrepositório do GitHub do gancho de registo e compile o seu próprio ficheiro binário.Copie o ficheiro JAR para a pasta da biblioteca auxiliar em todos os clusters onde planeia ativar o registo de consultas. Consoante o fornecedor, tem de localizar a pasta da biblioteca auxiliar nas definições do cluster e transferir o ficheiro JAR para a pasta da biblioteca auxiliar no cluster do Hive.
Configure propriedades de configuração para o gancho de registo
hadoop-migration-assessment. Consoante o fornecedor do Hadoop, tem de usar a consola da IU para editar as definições do cluster. Modifique o ficheiro/etc/hive/conf/hive-site.xmlou aplique a configuração com o Configuration Manager.
Configure propriedades
Se já tiver outros valores para as seguintes chaves de configuração, acrescente as definições com uma vírgula (,). Para configurar o gancho de registo hadoop-migration-assessment, são necessárias as seguintes definições de configuração:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: inclua o caminho para o ficheiro JAR do gancho de registo, por exemplo,file://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: caminho para a pasta de saída dos registos de consultas. Por exemplo,hdfs://tmp/logs/.Também pode definir as seguintes configurações opcionais:
dwhassessment.hook.queue.capacity: a capacidade da fila para os threads de registo de eventos de consulta. O valor predefinido é64.dwhassessment.hook.rollover-interval: a frequência com que a substituição do ficheiro tem de ser realizada. Por exemplo,600s. O valor predefinido é de 3600 segundos (1 hora).dwhassessment.hook.rollover-eligibility-check-interval: a frequência com que a verificação de elegibilidade da substituição de ficheiros é acionada em segundo plano. Por exemplo,600s. O valor predefinido é de 600 segundos (10 minutos).
Valide o gancho de registo
Depois de reiniciar o processo do hive-server2, execute uma consulta de teste e analise os registos de depuração. Pode ver a seguinte mensagem:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
O gancho de registo cria uma subpasta com partições de data na pasta configurada. O ficheiro Avro com eventos de consulta aparece nessa pasta após o intervalo de dwhassessment.hook.rollover-interval ou a terminação do processo hive-server2. Pode procurar mensagens semelhantes nos registos de depuração para ver o estado da operação de substituição:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
A transferência ocorre nos intervalos especificados ou quando o dia muda. Quando a data muda, o ponto de ligação de registo também cria uma nova subpasta para essa data.
A Google recomenda que forneça, pelo menos, duas semanas de registos de consultas para poder ver estatísticas mais detalhadas.
Também pode gerar pastas com registos de consultas de diferentes clusters do Hive e fornecê-las todas para uma única avaliação.
Informatica
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Requisitos
- Acesso ao cliente do Informatica PowerCenter Repository Manager
- Uma Google Cloud conta com um contentor do Cloud Storage para armazenar os dados.
- Um conjunto de dados do BigQuery vazio para armazenar os resultados. Em alternativa, pode criar um conjunto de dados do BigQuery quando criar a tarefa de avaliação através da Google Cloud consola.
Requisito: exporte ficheiros de objetos
Pode usar a GUI do Informatica PowerCenter Repository Manager para exportar os seus ficheiros de objetos. Para mais informações, consulte o artigo Passos para exportar objetos
Em alternativa, também pode executar o comando pmrep para exportar os seus ficheiros de objetos através dos seguintes passos:
- Execute o comando
pmrep connectpara estabelecer ligação ao repositório:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Substitua o seguinte:
REPOSITORY_NAME: nome do repositório ao qual quer estabelecer ligaçãoDOMAIN_NAME: nome do domínio do repositórioUSERNAME: nome de utilizador para estabelecer ligação ao repositórioPASSWORD: palavra-passe do nome de utilizador
- Depois de estabelecer ligação ao repositório, use o comando
pmrep objectexportpara exportar os objetos necessários:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Substitua o seguinte:
OBJECT_NAME: nome de um objeto específico a exportarOBJECT_TYPE: tipo de objeto do objeto especificadoFOLDER_NAME: nome da pasta que contém o objeto a exportarOUTPUT_FILE_NAME: nome do ficheiro XML que contém as informações do objeto
Carregue metadados e registos de consultas para o Cloud Storage
Depois de extrair os metadados e os registos de consultas do seu data warehouse, pode carregar os ficheiros para um contentor do Cloud Storage para prosseguir com a avaliação da migração.
Teradata
Carregue os metadados e um ou mais ficheiros ZIP que contenham registos de consultas para o seu contentor do Cloud Storage. Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros. O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP de metadados é de 50 GB.
As entradas em todos os ficheiros ZIP que contêm registos de consultas estão divididas da seguinte forma:
- Ficheiros do histórico de consultas com o prefixo
query_history_. - Ficheiros de intervalos temporais com os prefixos
utility_logs_,dbc.ResUsageScpu_edbc.ResUsageSpma_.
O limite para o tamanho total não comprimido de todos os ficheiros do histórico de consultas é de 5 TB. O limite para o tamanho total não comprimido de todos os ficheiros de séries cronológicas é de 1 TB.
Caso os registos de consultas sejam arquivados numa base de dados diferente, consulte a descrição das flags -Dteradata-logs.query-logs-table e -Dteradata-logs.sql-logs-table anteriormente nesta secção, que explica como fornecer uma localização alternativa para os registos de consultas.
Redshift
Carregue os metadados e um ou mais ficheiros ZIP que contenham registos de consultas para o seu contentor do Cloud Storage. Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros. O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP de metadados é de 50 GB.
As entradas em todos os ficheiros ZIP que contêm registos de consultas estão divididas da seguinte forma:
- Ficheiros do histórico de consultas com os prefixos
querytext_eddltext_. - Ficheiros de intervalos temporais com os prefixos
query_queue_info_,wlm_query_equerymetrics_.
O limite para o tamanho total não comprimido de todos os ficheiros do histórico de consultas é de 5 TB. O limite para o tamanho total não comprimido de todos os ficheiros de séries cronológicas é de 1 TB.
Redshift sem servidor
Carregue os metadados e um ou mais ficheiros ZIP que contenham registos de consultas para o seu contentor do Cloud Storage. Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros.
Floco de neve
Carregue os metadados e os ficheiros ZIP que contêm registos de consultas e históricos de utilização para o seu contentor do Cloud Storage. Quando carregar estes ficheiros para o Cloud Storage, tem de cumprir os seguintes requisitos:
- O tamanho total não comprimido de todos os ficheiros no ficheiro ZIP de metadados tem de ser inferior a 50 GB.
- O ficheiro ZIP de metadados e o ficheiro ZIP que contém os registos de consultas têm de ser carregados para uma pasta do Cloud Storage. Se tiver vários ficheiros ZIP com registos de consultas não sobrepostos, pode carregá-los todos.
- Tem de carregar todos os ficheiros para a mesma pasta do Cloud Storage.
- Tem de carregar todos os ficheiros ZIP de metadados e registos de consultas exatamente como
são gerados pela ferramenta
dwh-migration-dumper. Não extraia, combine nem modifique os dados de outra forma. - O tamanho total não comprimido de todos os ficheiros do histórico de consultas tem de ser inferior a 5 TB.
Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros.
Oracle
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Carregue o ficheiro ZIP com metadados e estatísticas de desempenho para um contentor do Cloud Storage. Por predefinição, o nome do ficheiro ZIP é
dwh-migration-oracle-stats.zip, mas pode personalizá-lo especificando-o
na flag --output. O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP é de 50 GB.
Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros.
Hadoop / Cloudera
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Carregue o ficheiro ZIP com metadados e estatísticas de desempenho para um contentor do Cloud Storage. Por predefinição, o nome do ficheiro ZIP é
dwh-migration-cloudera-manager-RUN_DATE.zip (por
exemplo, dwh-migration-cloudera-manager-20250312T145808.zip), mas pode
personalizá-lo com a flag --output. O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP é de 50 GB.
Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie um contentor e Carregue objetos a partir de um sistema de ficheiros.
Apache Hive
Carregue os metadados e as pastas que contêm registos de consultas de um ou mais clusters do Hive para o seu contentor do Cloud Storage. Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros.
O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP de metadados é de 50 GB.
Pode usar o conetor do Cloud Storage para copiar os registos de consultas diretamente para a pasta do Cloud Storage. As pastas que contêm subpastas com registos de consultas têm de ser carregadas para a mesma pasta do Cloud Storage onde o ficheiro ZIP de metadados é carregado.
As pastas de registos de consultas têm ficheiros do histórico de consultas com o prefixo dwhassessment_. O limite para o tamanho total não comprimido de todos os ficheiros do histórico de consultas é de 5 TB.
Informatica
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Carregue um ficheiro ZIP que contenha os objetos do repositório XML do Informatica para um contentor do Cloud Storage. Este ficheiro ZIP também tem de incluir um ficheiro compilerworks-metadata.yaml que contenha o seguinte:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
O limite para o tamanho total não comprimido de todos os ficheiros no ficheiro ZIP é de 50 GB.
Para mais informações sobre como criar contentores e carregar ficheiros para o Cloud Storage, consulte os artigos Crie contentores e Carregue objetos a partir de um sistema de ficheiros.
Execute uma avaliação de migração do BigQuery
Siga estes passos para executar a avaliação da migração do BigQuery. Estes passos pressupõem que carregou os ficheiros de metadados para um contentor do Cloud Storage, conforme descrito na secção anterior.
Autorizações necessárias
Para ativar o serviço de migração do BigQuery, precisa das seguintes autorizações de Identity and Access Management (IAM):
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Para aceder e usar o serviço de migração do BigQuery, precisa das seguintes autorizações no projeto:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Para executar o serviço de migração do BigQuery, precisa das seguintes autorizações adicionais.
Autorização para aceder aos contentores do Cloud Storage para ficheiros de entrada e saída:
storage.objects.getno contentor do Cloud Storage de origemstorage.objects.listno contentor do Cloud Storage de origemstorage.objects.createno contentor de destino do Cloud Storagestorage.objects.deleteno contentor de destino do Cloud Storagestorage.objects.updateno contentor de destino do Cloud Storagestorage.buckets.getstorage.buckets.list
Autorização para ler e atualizar o conjunto de dados do BigQuery onde o serviço de migração do BigQuery escreve os resultados:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Para partilhar o relatório do Looker Studio com um utilizador, tem de conceder as seguintes funções:
roles/bigquery.dataViewerroles/bigquery.jobUser
Para personalizar este documento de forma a usar o seu próprio projeto e utilizador nos comandos, edite estas variáveis:
PROJECT,
USER_EMAIL.
Crie uma função personalizada com as autorizações necessárias para usar a avaliação da migração do BigQuery:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Conceda a função personalizada BQMSrole a um utilizador:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Conceda as funções necessárias a um utilizador com o qual quer partilhar o relatório:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Localizações suportadas
A funcionalidade de avaliação da migração do BigQuery é suportada em dois tipos de localizações:
Uma região é um local geográfico específico, como Londres.
Uma multirregião é uma grande área geográfica, como os Estados Unidos, que contém duas ou mais regiões. As localizações multirregionais podem oferecer quotas maiores do que as regiões únicas.
Para mais informações sobre regiões e zonas, consulte o artigo Geografia e regiões.
Regiões
A tabela seguinte apresenta as regiões nas Américas onde a avaliação da migração do BigQuery está disponível.| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Carolina do Sul | us-east1 |
|
| Virgínia do Norte | us-east4 |
|
| Oregon | us-west1 |
|
| Los Angeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Singapura | asia-southeast1 |
|
| Tóquio | asia-northeast1 |
| Descrição da região | Nome da região | Detalhes |
|---|---|---|
| Bélgica | europe-west1 |
|
| Finlândia | europe-north1 |
|
| Frankfurt | europe-west3 |
|
| Londres | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Países Baixos | europe-west4 |
|
| Paris | europe-west9 |
|
| Turim | europe-west12 |
|
| Varsóvia | europe-central2 |
|
| Zurique | europe-west6 |
|
Várias regiões
A tabela seguinte lista as multirregiões onde a avaliação da migração do BigQuery está disponível.| Descrição multirregião | Nome multirregião |
|---|---|
| Centros de dados nos Estados-Membros da União Europeia | EU |
| Centros de dados nos Estados Unidos | US |
Antes de começar
Antes de executar a avaliação, tem de ativar a API BigQuery Migration e criar um conjunto de dados do BigQuery para armazenar os resultados da avaliação.
Ative a API BigQuery Migration
Ative a API BigQuery Migration da seguinte forma:
Na Google Cloud consola, aceda à página da API BigQuery Migration.
Clique em Ativar.
Crie um conjunto de dados para os resultados da avaliação
A avaliação da migração do BigQuery escreve os resultados da avaliação em tabelas no BigQuery. Antes de começar, crie um conjunto de dados para conter estas tabelas. Quando partilha o relatório do Looker Studio, também tem de conceder aos utilizadores autorização para ler este conjunto de dados. Para mais informações, consulte o artigo Disponibilize o relatório aos utilizadores.
Execute a avaliação da migração
Consola
Na Google Cloud consola, aceda à página BigQuery.
No menu de navegação, clique em Avaliação.
Clique em Iniciar avaliação.
Preencha a caixa de diálogo de configuração da avaliação.
- Em Nome a apresentar, introduza o nome que pode conter letras, números ou sublinhados. Este nome destina-se apenas a fins de apresentação e não tem de ser exclusivo.
Na lista Localização dos dados, escolha uma localização para a tarefa de avaliação. A tarefa de avaliação tem de estar localizada na mesma localização que o seu contentor do Cloud Storage de entrada de ficheiros extraídos e o seu conjunto de dados do BigQuery de saída. No entanto, se o contentor do Cloud Storage ou o conjunto de dados do BigQuery estiver localizado numa multirregião, a tarefa de avaliação tem de estar numa das regiões dentro desta multirregião.
Se a localização da avaliação for uma região múltipla
USouEU, então a localização do contentor do Cloud Storage e a localização do conjunto de dados do BigQuery têm de estar na mesma região múltipla ou na localização dentro desta região múltipla. Para mais informações sobre restrições de localização, consulte Considerações sobre a localização dos dados de carregamento do BigQuery .Para Origem de dados de avaliação, escolha o seu armazém de dados.
Para Caminho para ficheiros de entrada, introduza o caminho para o contentor do Cloud Storage que contém os seus ficheiros extraídos.
Para escolher como os resultados da avaliação são armazenados, selecione uma das seguintes opções:
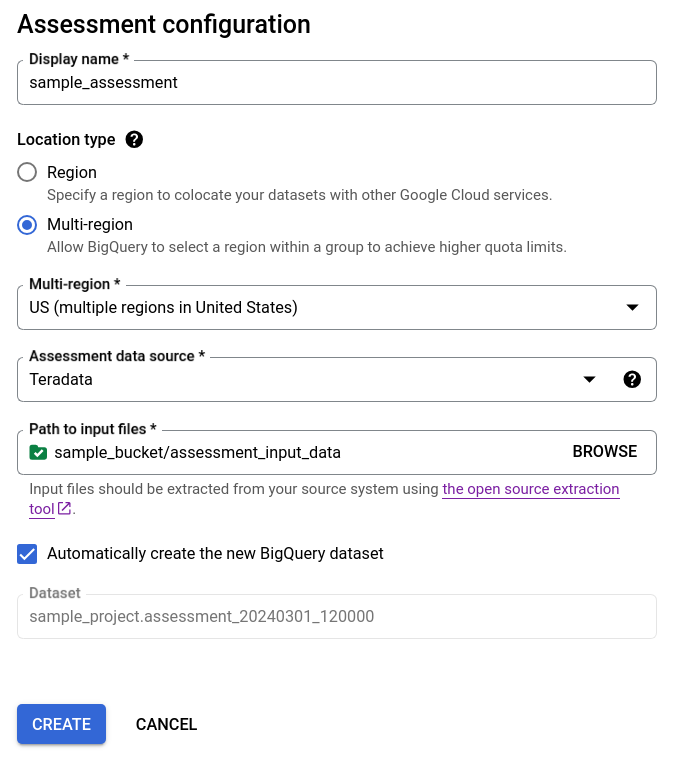
- Mantenha a caixa de verificação Criar automaticamente o novo conjunto de dados do BigQuery selecionada para que o conjunto de dados do BigQuery seja criado automaticamente. O nome do conjunto de dados é gerado automaticamente.
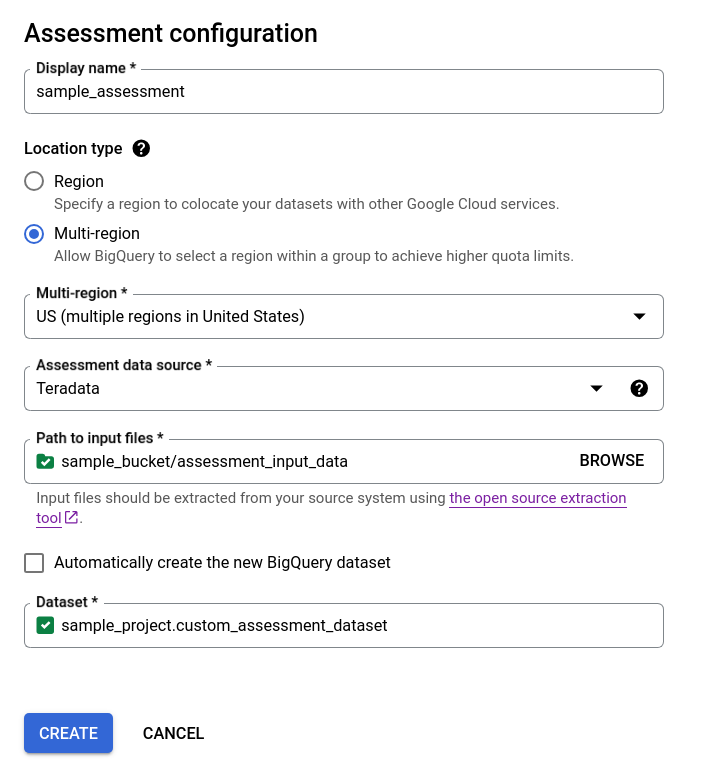
- Desmarque a caixa de verificação Criar automaticamente o novo conjunto de dados do BigQuery e escolha o conjunto de dados do BigQuery vazio existente através do formato
projectId.datasetIdou crie um novo nome de conjunto de dados. Nesta opção, pode escolher o nome do conjunto de dados do BigQuery.
Opção 1: geração automática do conjunto de dados do BigQuery (predefinição)
Opção 2: criação manual do conjunto de dados do BigQuery:
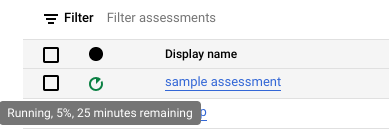
Clique em Criar. Pode ver o estado da tarefa na lista de tarefas de avaliação.
Enquanto a avaliação está em execução, pode verificar o respetivo progresso e o tempo estimado para a conclusão na sugestão do ícone de estado.
Enquanto a avaliação está em execução, pode clicar no link Ver relatório na lista de tarefas de avaliação para ver o relatório de avaliação com dados parciais no Looker Studio. O link Ver relatório pode demorar algum tempo a aparecer enquanto a avaliação está em execução. O relatório é aberto num novo separador.
O relatório é atualizado com novos dados à medida que são processados. Atualize o separador com o relatório ou clique novamente em Ver relatório para ver o relatório atualizado.
Após a conclusão da avaliação, clique em Ver relatório para ver o relatório de avaliação completo no Looker Studio. O relatório é aberto num novo separador.
API
Chame o método create
com um fluxo de trabalho definido.
Em seguida, chame o método start
para iniciar o fluxo de trabalho de avaliação.
A avaliação cria tabelas no conjunto de dados do BigQuery que criou anteriormente. Pode consultar estas tabelas para obter informações sobre as tabelas e as consultas usadas no seu data warehouse existente. Para obter informações sobre os ficheiros de saída da tradução, consulte o artigo Tradutor de SQL em lote.
Resultado da avaliação agregado partilhável
Para as avaliações do Amazon Redshift, Teradata e Snowflake, além do conjunto de dados do BigQuery criado anteriormente, o fluxo de trabalho cria outro conjunto de dados simples com o mesmo nome, mais o sufixo _shareableRedactedAggregate. Este conjunto de dados contém dados altamente agregados derivados do conjunto de dados de saída e não contém informações de identificação pessoal (IIP).
Para encontrar, inspecionar e partilhar de forma segura o conjunto de dados com outros utilizadores, consulte o artigo Consultar as tabelas de resultados da avaliação da migração.
A funcionalidade está ativada por predefinição, mas pode desativá-la através da API pública.
Detalhes da avaliação
Para ver a página de detalhes da avaliação, clique no nome a apresentar na lista de tarefas de avaliação.

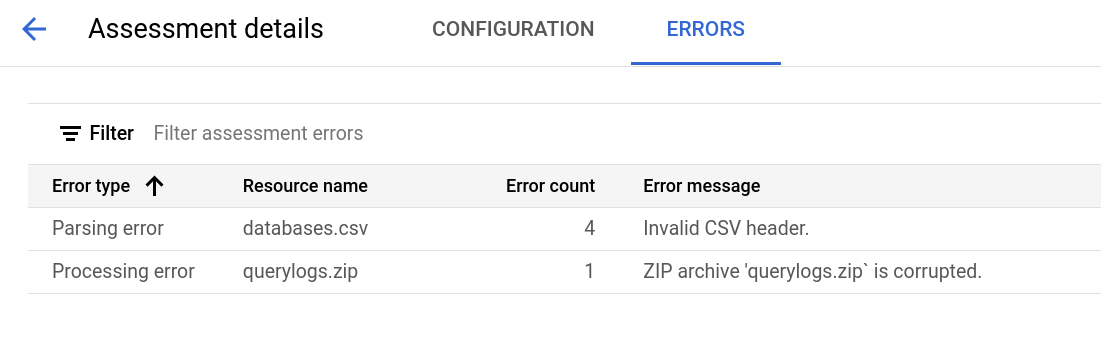
A página de detalhes da avaliação contém o separador Configuração, onde pode ver mais informações sobre uma tarefa de avaliação, e o separador Erros, onde pode rever quaisquer erros ocorridos durante o processamento da avaliação.
Consulte o separador Configuração para ver as propriedades da avaliação.
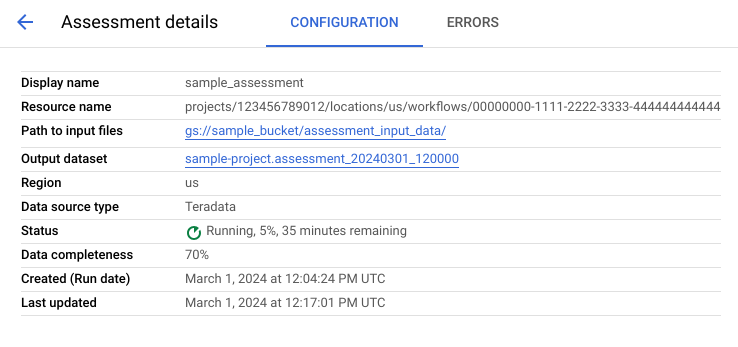
Consulte o separador Erros para ver os erros ocorridos durante o processamento da avaliação.
Reveja e partilhe o relatório do Looker Studio
Após a conclusão da tarefa de avaliação, pode criar e partilhar um relatório do Looker Studio dos resultados.
Reveja o relatório
Clique no link Ver relatório apresentado junto à tarefa de avaliação individual. O relatório do Looker Studio é aberto num novo separador, no modo de pré-visualização. Pode usar o modo de pré-visualização para rever o conteúdo do relatório antes de o partilhar mais.
O relatório tem um aspeto semelhante à seguinte captura de ecrã:
Para ver que vistas estão contidas no relatório, selecione o seu armazém de dados:
Teradata
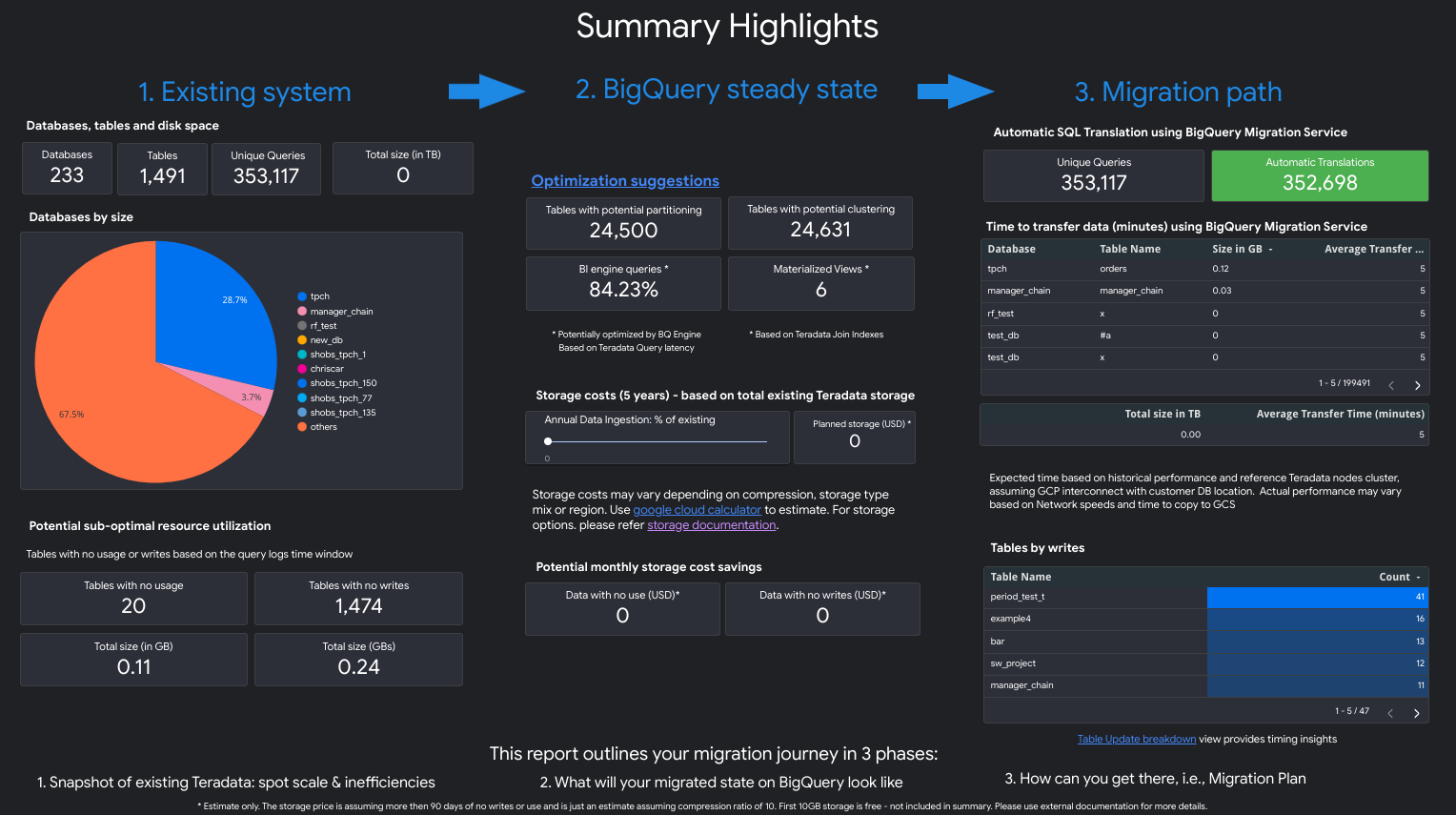
O relatório é uma narrativa de três partes precedida de uma página de destaques de resumo. Essa página inclui as seguintes secções:
- Sistema existente. Esta secção é uma vista geral do sistema e da utilização do Teradata existentes, incluindo o número de bases de dados, esquemas, tabelas e o tamanho total em TB. Também lista os esquemas por tamanho e indica uma potencial utilização de recursos abaixo do ideal (tabelas sem escritas ou com poucas leituras).
- Transformações de estado estável do BigQuery (sugestões). Esta secção mostra o aspeto do sistema no BigQuery após a migração. Inclui sugestões para otimizar as cargas de trabalho no BigQuery (e evitar o desperdício).
- Plano de migração. Esta secção fornece informações sobre o esforço de migração em si, por exemplo, a transição do sistema existente para o estado estável do BigQuery. Esta secção inclui a quantidade de consultas que foram traduzidas automaticamente e o tempo esperado para mover cada tabela para o BigQuery.
Os detalhes de cada secção incluem o seguinte:
Sistema existente
- Computação e consultas
- Utilização da CPU:
- Mapa térmico da utilização média da CPU por hora (vista geral da utilização de recursos do sistema)
- Consultas por hora e dia com utilização da CPU
- Consultas por tipo (leitura/escrita) com utilização da CPU
- Aplicações com utilização da CPU
- Sobreposição da utilização da CPU por hora com o desempenho das consultas por hora médio e o desempenho das aplicações por hora médio
- Histograma de consultas por tipo e durações das consultas
- Vista de detalhes das aplicações (app, utilizador, consultas únicas, relatórios versus discriminação de ETL)
- Utilização da CPU:
- Vista geral do armazenamento
- Bases de dados por volume, visualizações e taxas de acesso
- Tabelas com taxas de acesso por utilizadores, consultas, gravações e criações de tabelas temporárias
- Aplicações: taxas de acesso e endereços IP
Transformações de estado estável do BigQuery (sugestões)
- Índices de junção convertidos em vistas materializadas
- Agrupamento e divisão de candidatos com base em metadados e utilização
- Consultas de baixa latência identificadas como candidatas ao BigQuery BI Engine
- Colunas configuradas com valores predefinidos que usam a funcionalidade de descrição da coluna para armazenar valores predefinidos
- Índices únicos no Teradata
(para impedir linhas com chaves não únicas numa
tabela) use tabelas de preparação e uma declaração
MERGEpara inserir apenas registos únicos nas tabelas de destino e, em seguida, rejeitar duplicados - Consultas e esquema restantes traduzidos tal como estão
Plano de migração
- Vista detalhada com consultas traduzidas automaticamente
- Contagem do total de consultas com a capacidade de filtrar por utilizador, aplicação, tabelas afetadas, tabelas consultadas e tipo de consulta
- Recipientes de consultas com padrões semelhantes agrupados e apresentados em conjunto para que o utilizador possa ver a filosofia de tradução por tipos de consultas
- Consultas que requerem intervenção humana
- Consultas com violações da estrutura léxica do BigQuery
- Funções e procedimentos definidos pelo utilizador
- Palavras-chave reservadas do BigQuery
- Tabelas agendadas por escritas e leituras (para as agrupar para mover)
- Migração de dados com o Serviço de transferência de dados do BigQuery: Tempo estimado de migração por tabela
A secção Sistema existente contém as seguintes vistas:
- Vista geral do sistema
- A vista Vista geral do sistema apresenta as métricas de volume de nível elevado dos componentes principais no sistema existente durante um período especificado. A cronologia avaliada depende dos registos que foram analisados pela avaliação da migração do BigQuery. Esta vista dá-lhe estatísticas rápidas sobre a utilização do armazém de dados de origem, que pode usar para o planeamento da migração.
- Volume da tabela
- A vista Volume da tabela fornece estatísticas sobre as maiores tabelas e bases de dados encontradas pela avaliação da migração do BigQuery. Uma vez que as tabelas grandes podem demorar mais tempo a extrair do sistema de armazém de dados de origem, esta vista pode ser útil no planeamento e na sequenciação da migração.
- Utilização de tabelas
- A vista Utilização da tabela fornece estatísticas sobre as tabelas que são muito usadas no sistema de data warehouse de origem. As tabelas muito usadas podem ajudar a compreender que tabelas podem ter muitas dependências e exigir um planeamento adicional durante o processo de migração.
- Aplicações
- A vista Utilização de aplicações e a vista Padrões de aplicações fornecem estatísticas sobre as aplicações encontradas durante o processamento dos registos. Estas vistas permitem aos utilizadores compreender a utilização de aplicações específicas ao longo do tempo e o impacto na utilização de recursos. Durante uma migração, é importante visualizar o carregamento e o consumo de dados para compreender melhor as dependências do data warehouse e analisar o impacto da movimentação de várias aplicações dependentes em conjunto. A tabela de endereços IP pode ser útil para identificar a aplicação exata que usa o data warehouse através de ligações JDBC.
- Consultas
- A vista Consultas apresenta uma análise detalhada dos tipos de declarações SQL executadas e estatísticas da respetiva utilização. Pode usar o histograma de tipo de consulta e hora para identificar períodos de baixa utilização do sistema e horas do dia ideais para transferir dados. Também pode usar esta vista para identificar consultas executadas com frequência e os utilizadores que invocam essas execuções.
- Bases de dados
- A vista Bases de dados fornece métricas sobre o tamanho, as tabelas, as vistas e os procedimentos definidos no sistema de data warehouse de origem. Esta vista pode dar estatísticas sobre o volume de objetos que tem de migrar.
- Ligação da base de dados
- A vista de união de bases de dados oferece uma vista de alto nível das bases de dados e das tabelas acedidas em conjunto numa única consulta. Esta vista pode mostrar que tabelas e bases de dados são referenciadas com frequência e o que pode usar para o planeamento da migração.
A secção Estado estável do BigQuery contém as seguintes vistas:
- Tabelas sem utilização
- A vista Tabelas sem utilização apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar nenhuma utilização durante o período dos registos que foi analisado. A falta de utilização pode indicar que não precisa de transferir essa tabela para o BigQuery durante a migração ou que os custos de armazenamento de dados no BigQuery podem ser inferiores. Deve validar a lista de tabelas não usadas, uma vez que podem ter utilização fora do período dos registos, como uma tabela que só é usada uma vez a cada três ou seis meses.
- Tabelas sem gravações
- A vista Tabelas sem gravações apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar atualizações durante o período dos registos que foi analisado. A falta de gravações pode indicar onde pode reduzir os custos de armazenamento no BigQuery.
- Consultas de baixa latência
- A vista Consultas de baixa latência apresenta uma distribuição dos tempos de execução das consultas com base nos dados de registo analisados. Se o gráfico de distribuição da duração das consultas apresentar um grande número de consultas com um tempo de execução inferior a 1 segundo, pondere ativar o BigQuery BI Engine para acelerar a inteligência empresarial e outras cargas de trabalho de baixa latência.
- Vistas materializadas
- A vista materializada oferece sugestões de otimização adicionais para melhorar o desempenho no BigQuery.
- Clustering e particionamento
A vista Particionamento e clustering apresenta tabelas que beneficiariam do particionamento, do clustering ou de ambos.
As sugestões de metadados são alcançadas através da análise do esquema do armazém de dados de origem (como a partição e a chave primária na tabela de origem) e da procura do equivalente mais próximo no BigQuery para alcançar características de otimização semelhantes.
As sugestões de carga de trabalho são alcançadas através da análise dos registos de consultas de origem. A recomendação é determinada através da análise das cargas de trabalho, especialmente as cláusulas
WHEREouJOINnos registos de consultas analisados.- Recomendação de clustering
A vista Particionamento apresenta tabelas que podem ter mais de 10 000 partições, com base na respetiva definição de restrição de particionamento. Estas tabelas tendem a ser boas candidatas para a agrupamento do BigQuery, que permite partições de tabelas detalhadas.
- Restrições únicas
A vista Unique Constraints apresenta tabelas
SETe índices únicos definidos no data warehouse de origem. No BigQuery, é recomendado usar tabelas de preparação e uma declaraçãoMERGEpara inserir apenas registos únicos numa tabela de destino. Use o conteúdo desta vista para ajudar a determinar que tabelas pode ter de ajustar para a ETL durante a migração.- Valores predefinidos / restrições de verificação
Esta vista mostra tabelas que usam restrições de verificação para definir valores de colunas predefinidos. No BigQuery, consulte o artigo Especifique valores de colunas predefinidos.
A secção Caminho de migração do relatório contém as seguintes vistas:
- Tradução de SQL
- A vista Tradução de SQL apresenta a quantidade e os detalhes das consultas que foram convertidas automaticamente pela avaliação da migração do BigQuery e não requerem intervenção manual. Normalmente, a tradução automática de SQL alcança taxas de tradução elevadas se forem fornecidos metadados. Esta vista é interativa e permite a análise de consultas comuns e como estas são traduzidas.
- Esforço offline
- A vista Esforço offline capta as áreas que precisam de intervenção manual, incluindo UDFs específicas e potenciais violações da estrutura lexical e da sintaxe para tabelas ou colunas.
- Palavras-chave reservadas do BigQuery
- A vista Palavras-chave reservadas do BigQuery apresenta a utilização detetada
de palavras-chave que têm um significado especial na linguagem GoogleSQL
e não podem ser usadas como identificadores, a menos que estejam entre carateres de acento grave (
`). - Horário das atualizações de tabelas
- A vista de agendamento de atualizações de tabelas mostra quando e com que frequência as tabelas são atualizadas para ajudar a planear como e quando as mover.
- Migração de dados para o BigQuery
- A vista Migração de dados para o BigQuery descreve o caminho de migração com o tempo esperado para migrar os seus dados através do Serviço de transferência de dados do BigQuery. Para mais informações, consulte o guia do Serviço de transferência de dados do BigQuery para o Teradata.
A secção Apêndice contém as seguintes vistas:
- Sensibilidade a maiúsculas e minúsculas
- A vista Sensibilidade a maiúsculas e minúsculas mostra tabelas no data warehouse de origem que estão configuradas para fazer comparações insensíveis a maiúsculas e minúsculas. Por predefinição, as comparações de strings no BigQuery são sensíveis a maiúsculas e minúsculas. Para mais informações, consulte o artigo Ordenação.
Redshift
- Destaques da migração
- A vista Destaques da migração oferece um resumo executivo das três secções do relatório:
- O painel Sistema existente fornece informações sobre o número de bases de dados, esquemas, tabelas e o tamanho total do sistema Redshift existente. Também apresenta os esquemas por tamanho e potencial utilização de recursos abaixo do ideal. Pode usar estas informações para otimizar os seus dados removendo, dividindo ou agrupando as tabelas.
- O painel Estado estável do BigQuery fornece informações sobre o aspeto dos seus dados após a migração no BigQuery, incluindo o número de consultas que podem ser traduzidas automaticamente através do serviço de migração do BigQuery. Esta secção também mostra os custos de armazenamento dos seus dados no BigQuery com base na taxa de carregamento de dados anual, juntamente com sugestões de otimização para tabelas, aprovisionamento e espaço.
- O painel Caminho de migração fornece informações sobre o esforço de migração em si. Para cada tabela, mostra o tempo esperado para a migração, o número de linhas na tabela e o respetivo tamanho.
A secção Sistema existente contém as seguintes vistas:
- Consultas por tipo e programação
- A vista Consultas por tipo e programação categoriza as suas consultas em ETL/gravação e relatórios/agregação. Ver a combinação de consultas ao longo do tempo ajuda a compreender os padrões de utilização existentes e a identificar a variabilidade e o potencial aprovisionamento excessivo que podem afetar o custo e o desempenho.
- Colocação de consultas em fila
- A vista de colocação em fila de consultas fornece detalhes adicionais sobre a carga do sistema, incluindo o volume de consultas, a combinação e os impactos no desempenho devido à colocação em fila, como recursos insuficientes.
- Consultas e escalabilidade da GCL
- A vista Consultas e escalamento de WLM identifica o escalamento de concorrência como um custo adicional e uma complexidade de configuração. Mostra como o seu sistema Redshift encaminha as consultas com base nas regras especificadas e os impactos no desempenho devido ao processamento em fila, ao dimensionamento da concorrência e às consultas removidas.
- Colocação em fila e espera
- A vista de filas de espera e tempos de espera oferece uma análise mais detalhada dos tempos de espera das consultas ao longo do tempo.
- Classes e desempenho do WLM
- A vista Classes e desempenho do WLM oferece uma forma opcional de mapear as suas regras para o BigQuery. No entanto, recomendamos que permita que o BigQuery encaminhe automaticamente as suas consultas.
- Estatísticas de volume de consultas e tabelas
- A vista Estatísticas de volume de consultas e tabelas apresenta as consultas por tamanho, frequência e principais utilizadores. Isto ajuda a categorizar as origens de carga no sistema e a planear como migrar as suas cargas de trabalho.
- Bases de dados e esquemas
- A vista Bases de dados e esquemas fornece métricas sobre o tamanho, as tabelas, as vistas e os procedimentos definidos no sistema de armazém de dados de origem. Isto permite analisar o volume de objetos que têm de ser migrados.
- Volume da tabela
- A vista Volume da tabela fornece estatísticas sobre as maiores tabelas e bases de dados, mostrando como são acedidas. Uma vez que as tabelas grandes podem demorar mais tempo a extrair do sistema de armazém de dados de origem, esta vista ajuda a planear e sequenciar a migração.
- Utilização de tabelas
- A vista Utilização da tabela fornece estatísticas sobre as tabelas que são muito usadas no sistema de data warehouse de origem. As tabelas muito usadas podem ser usadas para compreender as tabelas que podem ter muitas dependências e justificar um planeamento adicional durante o processo de migração.
- Importadores e exportadores
- A vista Importadores e exportadores fornece informações sobre os dados e os utilizadores
envolvidos na importação de dados (através de
COPYconsultas) e na exportação de dados (através deUNLOADconsultas). Esta vista ajuda a identificar a camada de preparação e os processos relacionados com o carregamento e as exportações. - Utilização do cluster
- A vista de utilização do cluster fornece informações gerais sobre todos os clusters disponíveis e apresenta a utilização da CPU para cada cluster. Esta vista pode ajudar a compreender a reserva de capacidade do sistema.
A secção Estado estável do BigQuery contém as seguintes vistas:
- Agrupamento e particionamento
A vista Particionamento e clustering apresenta tabelas que beneficiariam do particionamento, do clustering ou de ambos.
As sugestões de metadados são alcançadas através da análise do esquema do data warehouse de dados de origem (como a chave de ordenação e a chave de distribuição na tabela de origem) e da procura do equivalente mais próximo no BigQuery para alcançar características de otimização semelhantes.
As sugestões de carga de trabalho são alcançadas através da análise dos registos de consultas de origem. A recomendação é determinada através da análise das cargas de trabalho, especialmente as cláusulas
WHEREouJOINnos registos de consultas analisados.Na parte inferior da página, encontra uma declaração de criação de tabela traduzida com todas as otimizações fornecidas. Todas as declarações DDL traduzidas também podem ser extraídas do conjunto de dados. As declarações DDL traduzidas são armazenadas na tabela
SchemaConversionna colunaCreateTableDDL.As recomendações no relatório são fornecidas apenas para tabelas com mais de 1 GB, porque as tabelas pequenas não beneficiam da agrupagem e da partição. No entanto, o DDL para todas as tabelas (incluindo tabelas com menos de 1 GB) está disponível na tabela
SchemaConversion.- Tabelas sem utilização
A vista Tabelas sem utilização apresenta tabelas onde a avaliação da migração do BigQuery não identificou nenhuma utilização durante o período dos registos analisados. A falta de utilização pode indicar que não precisa de transferir essa tabela para o BigQuery durante a migração ou que os custos de armazenamento de dados no BigQuery podem ser inferiores (faturados como armazenamento a longo prazo). Recomendamos que valide a lista de tabelas não usadas, uma vez que podem ter utilização fora do período dos registos, como uma tabela que só é usada uma vez a cada três ou seis meses.
- Tabelas sem gravações
A vista Tabelas sem gravações apresenta tabelas em que a avaliação da migração do BigQuery não identificou atualizações durante o período dos registos analisados. A falta de gravações pode indicar onde pode reduzir os custos de armazenamento no BigQuery (faturados como armazenamento a longo prazo).
- BigQuery BI Engine e vistas materializadas
O BigQuery BI Engine e as vistas materializadas oferecem mais sugestões de otimização para aumentar o desempenho no BigQuery.
A secção Caminho de migração contém as seguintes vistas:
- Tradução de SQL
- A vista Tradução de SQL apresenta a quantidade e os detalhes das consultas que foram convertidas automaticamente pela avaliação da migração do BigQuery e não requerem intervenção manual. Normalmente, a tradução automática de SQL alcança taxas de tradução elevadas se forem fornecidos metadados.
- Esforço offline de tradução de SQL
- A vista Esforço offline de tradução de SQL capta as áreas que precisam de intervenção manual, incluindo UDFs específicas e consultas com potenciais ambiguidades de tradução.
- Suporte de anexação de tabelas de alteração
- A vista Alter Table Append Support mostra detalhes sobre construções comuns de SQL do Redshift que não têm uma contrapartida direta no BigQuery.
- Apoio técnico para o comando de cópia
- A vista de apoio técnico do comando de cópia mostra detalhes sobre construções comuns de SQL do Redshift que não têm uma contrapartida direta no BigQuery.
- Avisos de SQL
- A vista Avisos de SQL capta áreas que são traduzidas com êxito, mas requerem uma revisão.
- Estrutura lexical e violações de sintaxe
- A vista Estrutura lexical e violações de sintaxe apresenta os nomes das colunas, das tabelas, das funções e dos procedimentos que violam a sintaxe do BigQuery.
- Palavras-chave reservadas do BigQuery
- A vista Palavras-chave reservadas do BigQuery apresenta a utilização detetada
de palavras-chave que têm um significado especial na linguagem GoogleSQL
e não podem ser usadas como identificadores, a menos que estejam entre carateres de acento grave (
`). - Ligação de esquemas
- A vista de associação de esquemas oferece uma vista de alto nível das bases de dados, dos esquemas e das tabelas que são acedidos em conjunto numa única consulta. Esta vista pode mostrar as tabelas, os esquemas e as bases de dados que são referenciados com frequência e o que pode usar para o planeamento da migração.
- Horário das atualizações de tabelas
- A vista Horário de atualizações das tabelas mostra quando e com que frequência as tabelas são atualizadas para ajudar a planear como e quando as mover.
- Escala da tabela
- A vista de escala da tabela apresenta as tabelas com o maior número de colunas.
- Migração de dados para o BigQuery
- A vista Migração de dados para o BigQuery descreve o caminho de migração com o tempo esperado para migrar os seus dados através do Serviço de transferência de dados do BigQuery. Para mais informações, consulte o guia do Serviço de transferência de dados do BigQuery para o Redshift.
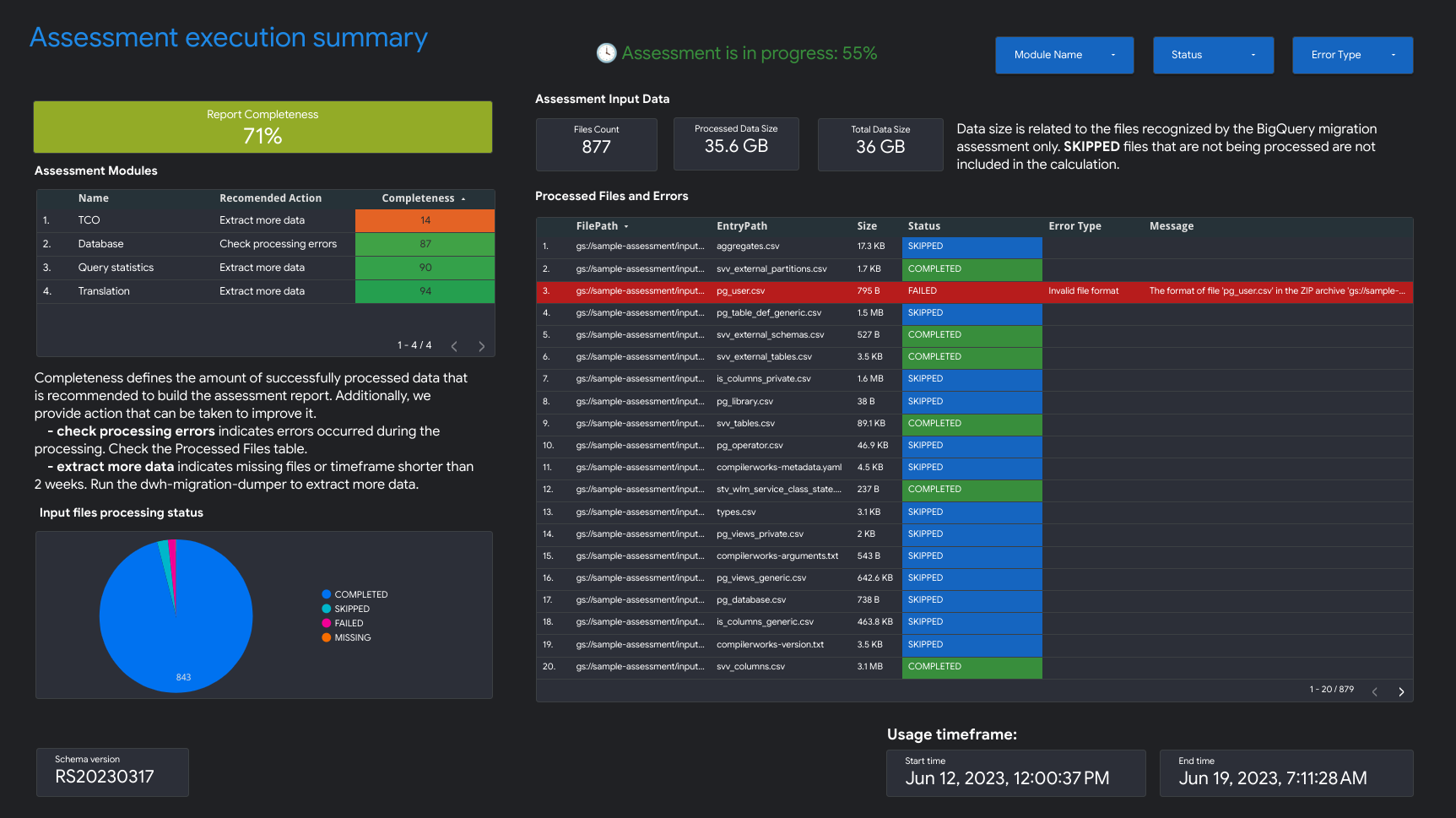
- Resumo da execução da avaliação
O resumo da execução da avaliação contém a integridade do relatório, o progresso da avaliação em curso e o estado dos ficheiros processados e dos erros.
A integridade do relatório representa a percentagem de dados processados com êxito que se recomenda apresentar para obter estatísticas significativas no relatório de avaliação. Se os dados de uma secção específica do relatório estiverem em falta, estas informações são apresentadas na tabela Módulos de avaliação no indicador Integridade do relatório.
A métrica progress indica a percentagem de dados processados até ao momento, juntamente com a estimativa do tempo restante para processar todos os dados. Após a conclusão do processamento, a métrica de progresso não é apresentada.
Redshift sem servidor
- Destaques da migração
- Esta página de relatório mostra o resumo das bases de dados sem servidor do Amazon Redshift existentes, incluindo o tamanho e o número de tabelas. Além disso, fornece a estimativa de alto nível do valor do contrato anual (ACV), ou seja, o custo de computação e armazenamento no BigQuery. A vista Destaques da migração oferece um resumo executivo das três secções do relatório.
A secção Sistema existente tem as seguintes vistas:
- Bases de dados e esquemas
- Fornece uma discriminação do tamanho total do armazenamento em GB para cada base de dados, esquema ou tabela.
- Bases de dados e esquemas externos
- Apresenta uma discriminação do tamanho total do armazenamento em GB para cada base de dados, esquema ou tabela externa.
- Utilização do sistema
- Fornece informações gerais sobre a utilização do sistema do histórico. Esta vista apresenta o histórico de utilização de RPUs (unidades de processamento do Amazon Redshift) e o consumo de armazenamento diário. Esta vista pode ajudar a compreender a reserva de capacidade do sistema.
A secção Estado estável do BigQuery fornece informações sobre o aspeto dos seus dados após a migração para o BigQuery, incluindo o número de consultas que podem ser traduzidas automaticamente através do serviço de migração do BigQuery. Esta secção também mostra os custos de armazenamento dos seus dados no BigQuery com base na taxa de ingestão de dados anual, juntamente com sugestões de otimização para tabelas, aprovisionamento e espaço. A secção Estado estável tem as seguintes vistas:
- Preços do Amazon Redshift Serverless versus BigQuery
- Oferece uma comparação dos modelos de preços do Amazon Redshift Serverless e do BigQuery para ajudar a compreender as vantagens e as potenciais poupanças de custos após a migração para o BigQuery.
- Custo de computação do BigQuery (CCT)
- Permite-lhe estimar o custo da computação no BigQuery. Existem quatro entradas manuais na calculadora: edição do BigQuery, região, período de compromisso e base. Por predefinição, a calculadora oferece compromissos de base ideais e rentáveis que pode substituir manualmente.
- Custo total de propriedade
- Permite-lhe estimar o valor do contrato anual (ACV), ou seja, o custo de computação e armazenamento no BigQuery. A calculadora também permite calcular o custo de armazenamento, que varia para o armazenamento ativo e o armazenamento a longo prazo, consoante as modificações da tabela durante o período analisado. Para mais informações, consulte os preços de armazenamento.
A secção Anexo contém esta vista:
- Resumo da execução da avaliação
- Fornece os detalhes da execução da avaliação, incluindo a lista de ficheiros processados, erros e integridade do relatório. Pode usar esta página para investigar dados em falta no relatório e para compreender melhor a integridade do relatório.
Floco de neve
O relatório é composto por diferentes secções que podem ser usadas separadamente ou em conjunto. O diagrama seguinte organiza estas secções em três objetivos comuns dos utilizadores para ajudar a avaliar as suas necessidades de migração:
Migração de vistas de destaques
A secção Destaques da migração contém as seguintes visualizações:
- Modelos de preços do Snowflake versus BigQuery
- Apresentação dos preços com diferentes níveis/edições. Também inclui uma ilustração de como o ajuste de escala automático do BigQuery pode ajudar a poupar mais custos em comparação com o Snowflake.
- Custo total de propriedade
- Tabela interativa que permite ao utilizador definir: edição do BigQuery, compromisso, compromisso de slots de base, percentagem de armazenamento ativo e percentagem de dados carregados ou alterados. Ajuda a estimar melhor o custo para caixas personalizadas.
- Realces de tradução automática
- Rácio de tradução agregado, agrupado por utilizador ou base de dados, ordenado por ordem ascendente ou descendente. Também inclui a mensagem de erro mais comum para a tradução automática com falhas.
Vistas do sistema existentes
A secção Sistema existente contém as seguintes vistas:
- Vista geral do sistema
- A vista geral do sistema apresenta as métricas de volume de nível elevado dos componentes principais no sistema existente durante um período especificado. A cronologia avaliada depende dos registos que foram analisados pela avaliação da migração do BigQuery. Esta vista oferece estatísticas rápidas sobre a utilização do armazém de dados de origem, que pode usar para o planeamento da migração.
- Vista geral dos armazéns virtuais
- Mostra o custo do Snowflake por armazém, bem como o reescalonamento baseado em nós ao longo do período.
- Volume da tabela
- A vista Volume da tabela fornece estatísticas sobre as maiores tabelas e bases de dados encontradas pela avaliação da migração do BigQuery. Uma vez que as tabelas grandes podem demorar mais tempo a extrair do sistema de armazém de dados de origem, esta vista pode ser útil no planeamento e na sequenciação da migração.
- Utilização de tabelas
- A vista Utilização da tabela fornece estatísticas sobre as tabelas que são muito usadas no sistema de data warehouse de origem. As tabelas muito usadas podem ajudar a compreender que tabelas podem ter muitas dependências e exigir planeamento adicional durante o processo de migração.
- Consultas
- A vista Consultas apresenta uma análise detalhada dos tipos de declarações SQL executadas e estatísticas da respetiva utilização. Pode usar o histograma de tipo de consulta e tempo para identificar períodos baixos de utilização do sistema e horas do dia ideais para transferir dados. Também pode usar esta vista para identificar consultas executadas com frequência e os utilizadores que invocam essas execuções.
- Bases de dados
- A vista Bases de dados fornece métricas sobre o tamanho, as tabelas, as vistas e os procedimentos definidos no sistema de data warehouse de origem. Esta vista fornece informações sobre o volume de objetos que tem de migrar.
Vistas de estado estável do BigQuery
A secção Estado estável do BigQuery contém as seguintes vistas:
- Tabelas sem utilização
- A vista Tabelas sem utilização apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar nenhuma utilização durante o período dos registos que foi analisado. Isto pode indicar que tabelas podem não precisar de ser transferidas para o BigQuery durante a migração ou que os custos de armazenamento de dados no BigQuery podem ser inferiores. Tem de validar a lista de tabelas não usadas, uma vez que podem ter utilização fora do período dos registos analisados, como uma tabela que só é usada uma vez por trimestre ou semestre.
- Tabelas sem gravações
- A vista Tabelas sem gravações apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar atualizações durante o período dos registos que foi analisado. Isto pode indicar que os custos de armazenamento de dados no BigQuery podem ser inferiores.
Visualizações do plano de migração
A secção Plano de migração do relatório contém as seguintes vistas:
- Tradução de SQL
- A vista Tradução de SQL apresenta a quantidade e os detalhes das consultas que foram convertidas automaticamente pela avaliação da migração do BigQuery e não requerem intervenção manual. Normalmente, a tradução automática de SQL alcança taxas de tradução elevadas se forem fornecidos metadados. Esta vista é interativa e permite a análise de consultas comuns e como estas são traduzidas.
- Esforço offline de tradução de SQL
- A vista Esforço offline capta as áreas que precisam de intervenção manual, incluindo UDFs específicas e potenciais violações da estrutura lexical e da sintaxe para tabelas ou colunas.
- Avisos de SQL – Para rever
- A vista Avisos a rever capta as áreas que estão maioritariamente traduzidas, mas requerem alguma inspeção humana.
- Palavras-chave reservadas do BigQuery
- A vista Palavras-chave reservadas do BigQuery apresenta a utilização detetada
de palavras-chave que têm um significado especial na linguagem GoogleSQL
e não podem ser usadas como identificadores, a menos que estejam entre carateres de acento grave (
`). - Associação de bases de dados e tabelas
- A vista de união de bases de dados oferece uma vista de alto nível das bases de dados e das tabelas acedidas em conjunto numa única consulta. Esta vista pode mostrar as tabelas e as bases de dados que são frequentemente referenciadas e o que pode ser usado para o planeamento da migração.
- Horário das atualizações de tabelas
- A vista Horário de atualizações das tabelas mostra quando e com que frequência as tabelas são atualizadas para ajudar a planear como e quando as mover.
Visualizações de validação de conceito
A secção PoC (prova de conceito) contém as seguintes vistas:
- PoC para demonstrar as poupanças do BigQuery em estado estacionário
- Inclui as consultas mais frequentes, as consultas que leem mais dados, as consultas mais lentas e as tabelas afetadas pelas consultas mencionadas acima.
- PoC para demonstrar o plano de migração do BigQuery
- Mostra como o BigQuery traduz as consultas mais complexas e as tabelas que afetam.
Oracle
Para pedir feedback ou apoio técnico para esta funcionalidade, envie um email para bq-edw-migration-support@google.com.
Destaques da migração
A secção Destaques da migração contém as seguintes visualizações:
- Sistema existente: uma captura do sistema Oracle existente e da utilização, incluindo o número de bases de dados, esquemas, tabelas e tamanho total em GB. Também fornece o resumo da classificação da carga de trabalho para cada base de dados para ajudar a decidir se o BigQuery é o destino de migração adequado.
- Compatibilidade: fornece informações sobre o esforço de migração propriamente dito. Para cada base de dados analisada, mostra o tempo esperado para a migração e o número de objetos da base de dados que podem ser migrados automaticamente com as ferramentas fornecidas pela Google.
- Estado estacionário do BigQuery: contém informações sobre o aspeto dos seus dados após a migração para o BigQuery, incluindo os custos de armazenamento dos dados no BigQuery com base na taxa de carregamento de dados anual e na estimativa de custos de computação. Além disso, fornece estatísticas sobre tabelas subutilizadas.
Sistema existente
A secção Sistema existente contém as seguintes vistas:
- Workloads Characteristic: descreve o tipo de carga de trabalho para cada base de dados com base nas métricas de desempenho analisadas. Cada base de dados é classificada como OLAP, mista ou OLTP. Estas informações podem ajudar a tomar uma decisão sobre que bases de dados podem ser migradas para o BigQuery.
- Bases de dados e esquemas: apresenta uma discriminação do tamanho total do armazenamento em GB para cada base de dados, esquema ou tabela. Além disso, pode usar esta vista para identificar vistas materializadas e tabelas externas.
- Funcionalidades e links da base de dados: mostra a lista de funcionalidades do Oracle usadas na sua base de dados, juntamente com as funcionalidades ou os serviços equivalentes do BigQuery que podem ser usados após a migração. Além disso, pode explorar os links da base de dados para compreender melhor as ligações entre as bases de dados.
- Ligações à base de dados: fornece estatísticas sobre as sessões da base de dados iniciadas pelo utilizador ou pela aplicação. A análise destes dados pode ajudar a identificar aplicações externas que podem exigir um esforço adicional durante a migração.
- Tipos de consultas: apresenta uma discriminação dos tipos de declarações SQL executadas e estatísticas da respetiva utilização. Pode usar o histograma por hora de execuções de consultas ou tempo de CPU de consultas para identificar períodos baixos de utilização do sistema e horas do dia ideais para transferir dados.
- Código fonte PL/SQL: fornece estatísticas sobre os objetos PL/SQL, como funções ou procedimentos, e o respetivo tamanho para cada base de dados e esquema. Além disso, o histograma de execuções por hora pode ser usado para identificar as horas de pico com mais execuções de PL/SQL.
- Utilização do sistema: fornece informações gerais sobre a utilização do sistema do histórico. Esta vista apresenta a utilização horária da CPU e o consumo de armazenamento diário. Esta vista pode ajudar a compreender a reserva de capacidade do sistema.
Estado estacionário do BigQuery
A secção Estado estacionário do BigQuery contém as seguintes vistas:
- Preços do Exadata versus BigQuery: fornece a comparação geral dos modelos de preços do Exadata e do BigQuery para ajudar a compreender as vantagens e as potenciais poupanças de custos após a migração para o BigQuery.
- Leituras/escritas na base de dados do BigQuery: fornece estatísticas sobre as operações de disco físico da base de dados. A análise destes dados pode ajudar a encontrar a melhor altura para fazer a migração de dados do Oracle para o BigQuery.
- Custo de computação do BigQuery: permite-lhe estimar o custo de computação no BigQuery. Existem quatro entradas manuais na calculadora: BigQuery Edition, Região, Período de compromisso e Base. Por predefinição, a calculadora oferece um compromisso base ideal e rentável que pode substituir manualmente. O valor Horas de intervalo da escalabilidade automática anual indica o número de horas de intervalo usadas fora do compromisso. Este valor é calculado com base na utilização do sistema. A explicação visual das relações entre a base, o dimensionamento automático e a utilização é fornecida no final da página. Cada estimativa mostra o número provável e um intervalo de estimativa.
- Custo total de propriedade (TCO): permite-lhe estimar o valor anual do contrato (ACV), ou seja, o custo de computação e armazenamento no BigQuery. A calculadora também permite calcular o custo de armazenamento. A calculadora também lhe permite calcular o custo de armazenamento, que varia para o armazenamento ativo e o armazenamento a longo prazo, dependendo das modificações da tabela durante o período analisado. Para mais informações sobre os preços de armazenamento, consulte o artigo Preços de armazenamento.
- Tabelas subutilizadas: fornece informações sobre tabelas não usadas e só de leitura com base nas métricas de utilização do período analisado. A falta de utilização pode indicar que não precisa de transferir a tabela para o BigQuery durante uma migração ou que os custos de armazenamento de dados no BigQuery podem ser mais baixos (faturados como armazenamento a longo prazo). Recomendamos que valide a lista de tabelas não usadas caso tenham utilização fora do período analisado.
Sugestões de migração
A secção Sugestões de migração contém as seguintes vistas:
- Compatibilidade de objetos de base de dados: fornece a vista geral da compatibilidade de objetos de base de dados com o BigQuery, incluindo o número de objetos que podem ser migrados automaticamente com ferramentas fornecidas pela Google ou que requerem ação manual. Estas informações são apresentadas para cada base de dados, esquema e tipo de objeto da base de dados.
- Esforço de migração de objetos da base de dados: mostra a estimativa do esforço de migração em horas para cada base de dados, esquema ou tipo de objeto da base de dados. Além disso, mostra a percentagem de objetos pequenos, médios e grandes com base no esforço de migração.
- Esforço de migração do esquema da base de dados: apresenta a lista de todos os tipos de objetos da base de dados detetados, o respetivo número, a compatibilidade com o BigQuery e o esforço de migração estimado em horas.
- Esforço de migração do esquema da base de dados detalhado: fornece estatísticas mais detalhadas sobre o esforço de migração do esquema da base de dados, incluindo as informações de cada objeto individual.
Visualizações de validação de conceito
A secção Visualizações de prova de conceito contém as seguintes visualizações:
- Migração de prova de conceito: mostra a lista sugerida de bases de dados com o menor esforço de migração que são boas candidatas para a migração inicial. Além disso, mostra as principais consultas que podem ajudar a demonstrar a poupança de tempo e custos, e o valor do BigQuery através de uma prova de conceito.
Anexo
A secção Apêndice contém as seguintes vistas:
- Resumo da execução da avaliação: fornece os detalhes da execução da avaliação, incluindo a lista de ficheiros processados, erros e a integridade do relatório. Pode usar esta página para investigar dados em falta no relatório e compreender melhor a integridade geral do relatório.
Apache Hive
O relatório composto por uma narrativa de três partes é precedido de uma página de destaques de resumo que inclui as seguintes secções:
Sistema existente: Apache Hive. Esta secção consiste numa imagem do sistema e da utilização do Apache Hive existentes, incluindo o número de bases de dados, tabelas, o respetivo tamanho total em GB e o número de registos de consultas processados. Esta secção também apresenta as bases de dados por tamanho e indica uma potencial utilização de recursos abaixo do ideal (tabelas sem escritas ou com poucas leituras) e aprovisionamento. Os detalhes desta secção incluem o seguinte:
- Calcular e consultar
- Utilização da CPU:
- Consultas por hora e dia com utilização da CPU
- Consultas por tipo (leitura/escrita)
- Filas e aplicações
- Sobreposição da utilização da CPU por hora com o desempenho das consultas por hora médio e o desempenho das aplicações por hora médio
- Histograma de consultas por tipo e durações das consultas
- Página de colocação em fila e espera
- Vista detalhada das filas (fila, utilizador, consultas únicas, relatórios versus análise detalhada de ETL, por métricas)
- Utilização da CPU:
- Vista geral do armazenamento
- Bases de dados por volume, visualizações e taxas de acesso
- Tabelas com taxas de acesso por utilizadores, consultas, gravações e criações de tabelas temporárias
- Filas e aplicações: taxas de acesso e endereços IP do cliente
- Calcular e consultar
Estado estacionário do BigQuery. Esta secção mostra o aspeto do sistema no BigQuery após a migração. Inclui sugestões para otimizar as cargas de trabalho no BigQuery (e evitar o desperdício). Os detalhes desta secção incluem o seguinte:
- Tabelas identificadas como candidatas a visualizações materializadas.
- Agrupamento e divisão de candidatos com base nos metadados e na utilização.
- Consultas de baixa latência identificadas como candidatas ao BigQuery BI Engine.
- Tabelas sem utilização de leitura nem de escrita.
- Tabelas particionadas com a assimetria de dados.
Plano de migração. Esta secção fornece informações sobre o esforço de migração propriamente dito. Por exemplo, passar do sistema existente para o estado estável do BigQuery. Esta secção contém destinos de armazenamento identificados para cada tabela, tabelas identificadas como significativas para a migração e a quantidade de consultas que foram traduzidas automaticamente. Os detalhes desta secção incluem o seguinte:
- Vista detalhada com consultas traduzidas automaticamente
- Contagem do total de consultas com a capacidade de filtrar por utilizador, aplicação, tabelas afetadas, tabelas consultadas e tipo de consulta.
- Recipientes de consultas com padrões semelhantes agrupados, o que permite aos utilizadores ver a filosofia de tradução por tipos de consultas.
- Consultas que requerem intervenção humana
- Consultas com violações da estrutura lexical do BigQuery
- Funções e procedimentos definidos pelo utilizador
- Palavras-chave reservadas do BigQuery
- Consulta que requer revisão
- Tabelas agendadas por escritas e leituras (para as agrupar para mover)
- Destino de armazenamento identificado para tabelas externas e geridas
- Vista detalhada com consultas traduzidas automaticamente
A secção Sistema existente – Hive contém as seguintes vistas:
- Vista geral do sistema
- Esta vista fornece as métricas de volume de alto nível dos componentes principais no sistema existente durante um período especificado. A cronologia avaliada depende dos registos que foram analisados pela avaliação da migração do BigQuery. Esta vista dá-lhe estatísticas rápidas sobre a utilização do armazém de dados de origem, que pode usar para o planeamento da migração.
- Volume da tabela
- Esta vista fornece estatísticas sobre as maiores tabelas e bases de dados encontradas pela avaliação da migração do BigQuery. Uma vez que as tabelas grandes podem demorar mais tempo a extrair do sistema de armazém de dados de origem, esta vista pode ser útil no planeamento e na sequenciação da migração.
- Utilização de tabelas
- Esta vista fornece estatísticas sobre as tabelas que são muito usadas no sistema de armazém de dados de origem. As tabelas muito usadas podem ajudar a compreender que tabelas podem ter muitas dependências e exigir um planeamento adicional durante o processo de migração.
- Utilização das filas
- Esta vista fornece estatísticas sobre a utilização de filas do YARN encontrada durante o processamento de registos. Estas vistas permitem aos utilizadores compreender a utilização de filas e aplicações específicas ao longo do tempo e o impacto na utilização de recursos. Estas vistas também ajudam a identificar e dar prioridade às cargas de trabalho para migração. Durante uma migração, é importante visualizar o carregamento e o consumo de dados para compreender melhor as dependências do data warehouse e analisar o impacto da movimentação de várias aplicações dependentes em conjunto. A tabela de endereços IP pode ser útil para identificar a aplicação exata que usa o data warehouse através de ligações JDBC.
- Métricas de filas
- Esta vista apresenta uma discriminação das diferentes métricas nas filas do YARN encontradas durante o processamento dos registos. Esta vista permite aos utilizadores compreender os padrões de utilização em filas específicas e o impacto na migração. Também pode usar esta vista para identificar associações entre tabelas acedidas em consultas e filas onde a consulta foi executada.
- Colocação em fila e espera
- Esta vista fornece informações sobre o tempo de colocação em fila de consultas no data warehouse de origem. Os tempos de fila indicam uma degradação do desempenho devido ao aprovisionamento insuficiente, e o aprovisionamento adicional requer um aumento dos custos de hardware e manutenção.
- Consultas
- Esta vista apresenta uma análise detalhada dos tipos de declarações SQL executadas e estatísticas da respetiva utilização. Pode usar o histograma de tipo de consulta e hora para identificar períodos de baixa utilização do sistema e horas do dia ideais para transferir dados. Também pode usar esta vista para identificar os motores de execução do Hive mais usados e as consultas executadas com frequência, juntamente com os detalhes do utilizador.
- Bases de dados
- Esta vista fornece métricas sobre o tamanho, as tabelas, as vistas e os procedimentos definidos no sistema de data warehouse de origem. Esta vista pode dar estatísticas sobre o volume de objetos que tem de migrar.
- Associação de bases de dados e tabelas
- Esta vista oferece uma vista geral das bases de dados e das tabelas acedidas em conjunto numa única consulta. Esta vista pode mostrar que tabelas e bases de dados são referenciadas com frequência e o que pode usar para o planeamento da migração.
A secção Estado estacionário do BigQuery contém as seguintes vistas:
- Tabelas sem utilização
- A vista Tabelas sem utilização apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar nenhuma utilização durante o período dos registos que foi analisado. A falta de utilização pode indicar que não precisa de transferir essa tabela para o BigQuery durante a migração ou que os custos de armazenamento de dados no BigQuery podem ser inferiores. Tem de validar a lista de tabelas não usadas porque podem ter utilização fora do período dos registos, como uma tabela que só é usada uma vez a cada três ou seis meses.
- Tabelas sem gravações
- A vista Tabelas sem gravações apresenta tabelas nas quais a avaliação da migração do BigQuery não conseguiu encontrar atualizações durante o período dos registos que foi analisado. A falta de gravações pode indicar onde pode reduzir os custos de armazenamento no BigQuery.
- Recomendações de clustering e particionamento
Esta vista apresenta tabelas que beneficiariam da partição, da agrupagem ou de ambas.
As sugestões de metadados são alcançadas através da análise do esquema do armazém de dados de origem (como a partição e a chave primária na tabela de origem) e da procura do equivalente mais próximo no BigQuery para alcançar características de otimização semelhantes.
As sugestões de carga de trabalho são alcançadas através da análise dos registos de consultas de origem. A recomendação é determinada através da análise das cargas de trabalho, especialmente as cláusulas
WHEREouJOINnos registos de consultas analisados.- Partições convertidas em clusters
Esta vista apresenta tabelas com mais de 10 000 partições, com base na respetiva definição de restrição de partição. Estas tabelas tendem a ser boas candidatas para a agrupamento do BigQuery, que permite partições de tabelas detalhadas.
- Partições enviesadas
A vista Partições enviesadas apresenta tabelas baseadas na análise de metadados e com enviesamento de dados numa ou várias partições. Estas tabelas são boas candidatas para a alteração do esquema, uma vez que as consultas em partições enviesadas podem não ter um bom desempenho.
- BI Engine e vistas materializadas
A vista Consultas de baixa latência e vistas materializadas apresenta uma distribuição dos tempos de execução de consultas com base nos dados de registo analisados e sugestões de otimização adicionais para aumentar o desempenho no BigQuery. Se o gráfico de distribuição da duração da consulta apresentar um grande número de consultas com um tempo de execução inferior a 1 segundo, considere ativar o BI Engine para acelerar a inteligência empresarial e outras cargas de trabalho de baixa latência.
A secção Plano de migração do relatório contém as seguintes vistas:
- Tradução de SQL
- A vista Tradução de SQL apresenta a quantidade e os detalhes das consultas que foram convertidas automaticamente pela avaliação da migração do BigQuery e não requerem intervenção manual. Normalmente, a tradução automática de SQL alcança taxas de tradução elevadas se forem fornecidos metadados. Esta vista é interativa e permite a análise de consultas comuns e como estas são traduzidas.
- Esforço offline de tradução de SQL
- A vista Esforço offline capta as áreas que precisam de intervenção manual, incluindo UDFs específicas e potenciais violações da estrutura lexical e da sintaxe para tabelas ou colunas.
- Avisos de SQL
- A vista Avisos de SQL capta áreas que são traduzidas com êxito, mas que requerem uma revisão.
- Palavras-chave reservadas do BigQuery
- A vista Palavras-chave reservadas do BigQuery apresenta a utilização detetada
de palavras-chave que têm um significado especial na linguagem GoogleSQL.
Não é possível usar estas palavras-chave como identificadores, a menos que estejam entre carateres de acento grave (
`). - Horário das atualizações de tabelas
- A vista de agendamento de atualizações de tabelas mostra quando e com que frequência as tabelas são atualizadas para ajudar a planear como e quando as mover.
- Tabelas externas do BigLake
- A vista de tabelas externas do BigLake descreve as tabelas que são identificadas como destinos para migração para o BigLake em vez do BigQuery.
A secção Apêndice do relatório contém as seguintes vistas:
- Análise detalhada do esforço offline de tradução de SQL
- A vista de análise detalhada do esforço offline oferece uma estatística adicional das áreas de SQL que requerem intervenção manual.
- Análise detalhada de avisos SQL
- A vista Análise detalhada de avisos fornece uma estatística adicional das áreas de SQL que foram traduzidas com êxito, mas que requerem uma revisão.
Partilhe o relatório
O relatório do Looker Studio é um painel de controlo de frontend para a avaliação da migração. Baseia-se nas autorizações de acesso ao conjunto de dados subjacente. Para partilhar o relatório, o destinatário tem de ter acesso ao próprio relatório do Looker Studio e ao conjunto de dados do BigQuery que contém os resultados da avaliação.
Quando abre o relatório a partir da Google Cloud consola, está a ver o relatório no modo de pré-visualização. Para criar e partilhar o relatório com outros utilizadores, siga estes passos:
- Clique em Editar e partilhar. O Looker Studio pede-lhe para anexar conetores do Looker Studio recém-criados ao novo relatório.
- Clique em Adicionar ao relatório. O relatório recebe um ID do relatório individual, que pode usar para aceder ao relatório.
- Para partilhar o relatório do Looker Studio com outros utilizadores, siga os passos indicados em Partilhe relatórios com visitantes e editores.
- Conceda aos utilizadores autorização para ver o conjunto de dados do BigQuery que foi usado para executar a tarefa de avaliação. Para mais informações, consulte o artigo Conceder acesso a um conjunto de dados.
Consulte as tabelas de resultados da avaliação da migração
Embora os relatórios do Looker Studio sejam a forma mais conveniente de ver os resultados da avaliação, também pode ver e consultar os dados subjacentes no conjunto de dados do BigQuery.
Exemplo de consulta
O exemplo seguinte obtém o número total de consultas únicas, o número de consultas cuja tradução falhou e a percentagem de consultas únicas cuja tradução falhou.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Partilhe o seu conjunto de dados com utilizadores noutros projetos
Depois de inspecionar o conjunto de dados, se quiser partilhá-lo com um utilizador que não esteja no seu projeto, pode fazê-lo através do fluxo de trabalho de publicador da partilha do BigQuery (anteriormente, o Analytics Hub).
Na Google Cloud consola, aceda à página BigQuery.
Clique no conjunto de dados para ver os respetivos detalhes.
Clique em Partilhar > Publicar como ficha.
Na caixa de diálogo apresentada, crie uma ficha conforme indicado.
Se já tiver uma troca de dados, ignore o passo 5.
Crie uma troca de dados e defina autorizações. Para permitir que um utilizador veja as suas fichas nesta troca, adicione-o à lista de Subscritores.
Introduza os detalhes da ficha.
O nome a apresentar é o nome desta ficha e é obrigatório. Os outros campos são opcionais.
Clique em Publicar.
É criada uma ficha privada.
Para a sua ficha, selecione Mais ações em Ações.
Clique em Copiar link de partilha.
Pode partilhar o link com os utilizadores que têm acesso por subscrição à sua bolsa de trocas ou ficha.
Esquemas das tabelas de avaliação
Para ver as tabelas e os respetivos esquemas que a avaliação da migração do BigQuery escreve no BigQuery, selecione o seu armazém de dados:
Teradata
AllRIChildren
Esta tabela fornece as informações de integridade referencial dos elementos secundários da tabela.
| Coluna | Tipo | Descrição |
|---|---|---|
IndexId |
INTEGER |
O número do índice de referência. |
IndexName |
STRING |
O nome do índice. |
ChildDB |
STRING |
O nome da base de dados de referência, convertido em minúsculas. |
ChildDBOriginal |
STRING |
O nome da base de dados de referência com a capitalização preservada. |
ChildTable |
STRING |
O nome da tabela de referência, convertido em minúsculas. |
ChildTableOriginal |
STRING |
O nome da tabela de referência com a capitalização preservada. |
ChildKeyColumn |
STRING |
O nome de uma coluna na chave de referência, convertido em minúsculas. |
ChildKeyColumnOriginal |
STRING |
O nome de uma coluna na chave de referência com a capitalização preservada. |
ParentDB |
STRING |
O nome da base de dados referenciada, convertido em minúsculas. |
ParentDBOriginal |
STRING |
O nome da base de dados referenciada com a capitalização preservada. |
ParentTable |
STRING |
O nome da tabela referenciada, convertido em minúsculas. |
ParentTableOriginal |
STRING |
O nome da tabela referenciada com a capitalização preservada. |
ParentKeyColumn |
STRING |
O nome da coluna numa chave referenciada, convertido em minúsculas. |
ParentKeyColumnOriginal |
STRING |
O nome da coluna numa chave referenciada com a capitalização preservada. |
AllRIParents
Esta tabela fornece as informações de integridade referencial dos pais da tabela.
| Coluna | Tipo | Descrição |
|---|---|---|
IndexId |
INTEGER |
O número do índice de referência. |
IndexName |
STRING |
O nome do índice. |
ChildDB |
STRING |
O nome da base de dados de referência, convertido em minúsculas. |
ChildDBOriginal |
STRING |
O nome da base de dados de referência com a capitalização preservada. |
ChildTable |
STRING |
O nome da tabela de referência, convertido em minúsculas. |
ChildTableOriginal |
STRING |
O nome da tabela de referência com a capitalização preservada. |
ChildKeyColumn |
STRING |
O nome de uma coluna na chave de referência, convertido em minúsculas. |
ChildKeyColumnOriginal |
STRING |
O nome de uma coluna na chave de referência com a capitalização preservada. |
ParentDB |
STRING |
O nome da base de dados referenciada, convertido em minúsculas. |
ParentDBOriginal |
STRING |
O nome da base de dados referenciada com a capitalização preservada. |
ParentTable |
STRING |
O nome da tabela referenciada, convertido em minúsculas. |
ParentTableOriginal |
STRING |
O nome da tabela referenciada com a capitalização preservada. |
ParentKeyColumn |
STRING |
O nome da coluna numa chave referenciada, convertido em minúsculas. |
ParentKeyColumnOriginal |
STRING |
O nome da coluna numa chave referenciada com a capitalização preservada. |
Columns
Esta tabela fornece informações sobre as colunas.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. |
TableNameOriginal |
STRING |
O nome da tabela com a capitalização preservada. |
ColumnName |
STRING |
O nome da coluna, convertido em minúsculas. |
ColumnNameOriginal |
STRING |
O nome da coluna com a capitalização preservada. |
ColumnType |
STRING |
O tipo do BigQuery da coluna, como STRING. |
OriginalColumnType |
STRING |
O tipo original da coluna, como VARCHAR. |
ColumnLength |
INTEGER |
O número máximo de bytes da coluna, como 30 para VARCHAR(30). |
DefaultValue |
STRING |
O valor predefinido, se existir. |
Nullable |
BOOLEAN |
Se a coluna permite valores nulos. |
DiskSpace
Esta tabela fornece informações sobre a utilização do espaço em disco para cada base de dados.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
MaxPerm |
INTEGER |
O número máximo de bytes atribuídos ao espaço permanente. |
MaxSpool |
INTEGER |
O número máximo de bytes atribuídos ao espaço de spool. |
MaxTemp |
INTEGER |
O número máximo de bytes atribuídos ao espaço temporário. |
CurrentPerm |
INTEGER |
O número de bytes atribuídos ao espaço permanente. |
CurrentSpool |
INTEGER |
O número de bytes atribuídos ao espaço de spool. |
CurrentTemp |
INTEGER |
O número de bytes atribuídos ao espaço temporário. |
PeakPerm |
INTEGER |
Número máximo de bytes usados desde a última reposição para o espaço permanente. |
PeakSpool |
INTEGER |
Número máximo de bytes usados desde a última reposição para o espaço de spool. |
PeakPersistentSpool |
INTEGER |
Número máximo de bytes usados desde a última reposição para o espaço persistente. |
PeakTemp |
INTEGER |
Número máximo de bytes usados desde a última reposição para o espaço temporário. |
MaxProfileSpool |
INTEGER |
O limite do espaço de spool para o utilizador. |
MaxProfileTemp |
INTEGER |
O limite de espaço temporário para o utilizador. |
AllocatedPerm |
INTEGER |
Atribuição atual de espaço permanente. |
AllocatedSpool |
INTEGER |
Atribuição atual do espaço de spool. |
AllocatedTemp |
INTEGER |
Atribuição atual de espaço temporário. |
Functions
Esta tabela fornece informações sobre as funções.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
FunctionName |
STRING |
O nome da função. |
LanguageName |
STRING |
O nome do idioma. |
Indices
Esta tabela fornece informações sobre os índices.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. |
TableNameOriginal |
STRING |
O nome da tabela com a capitalização preservada. |
IndexName |
STRING |
O nome do índice. |
ColumnName |
STRING |
O nome da coluna, convertido em minúsculas. |
ColumnNameOriginal |
STRING |
O nome da coluna com a capitalização preservada. |
OrdinalPosition |
INTEGER |
A posição da coluna. |
UniqueFlag |
BOOLEAN |
Indica se o índice aplica a unicidade. |
Queries
Esta tabela fornece informações sobre as consultas extraídas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
QueryText |
STRING |
O texto da consulta. |
QueryLogs
Esta tabela apresenta algumas estatísticas de execução sobre as consultas extraídas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryText |
STRING |
O texto da consulta. |
QueryHash |
STRING |
O hash da consulta. |
QueryId |
STRING |
O ID da consulta. |
QueryType |
STRING |
O tipo de consulta, Query ou DDL. |
UserId |
BYTES |
O ID do utilizador que executou a consulta. |
UserName |
STRING |
O nome do utilizador que executou a consulta. |
StartTime |
TIMESTAMP |
Data/hora em que a consulta foi enviada. |
Duration |
STRING |
Duração da consulta em milissegundos. |
AppId |
STRING |
O ID da aplicação que executou a consulta. |
ProxyUser |
STRING |
O utilizador proxy quando usado através de uma camada intermédia. |
ProxyRole |
STRING |
A função de proxy quando usada através de um nível intermédio. |
QueryTypeStatistics
Esta tabela fornece estatísticas sobre os tipos de consultas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
QueryType |
STRING |
O tipo de consulta. |
UpdatedTable |
STRING |
A tabela que foi atualizada pela consulta, se existir. |
QueriedTables |
ARRAY<STRING> |
Uma lista das tabelas que foram consultadas. |
ResUsageScpu
Esta tabela fornece informações sobre a utilização de recursos da CPU.
| Coluna | Tipo | Descrição |
|---|---|---|
EventTime |
TIMESTAMP |
A hora do evento. |
NodeId |
INTEGER |
ID do nó |
CabinetId |
INTEGER |
O número do armário físico do nó. |
ModuleId |
INTEGER |
O número do módulo físico do nó. |
NodeType |
STRING |
Tipo de nó. |
CpuId |
INTEGER |
ID da CPU neste nó. |
MeasurementPeriod |
INTEGER |
O período da medição expresso em centésimos de segundo. |
SummaryFlag |
STRING |
S: linha de resumo, N: linha sem resumo |
CpuFrequency |
FLOAT |
Frequência da CPU em MHz. |
CpuIdle |
FLOAT |
O tempo em que a CPU está inativa expresso em centésimos de segundo. |
CpuIoWait |
FLOAT |
O tempo que a CPU está a aguardar a E/S expresso em centisegundos. |
CpuUServ |
FLOAT |
O tempo que a CPU está a executar o código do utilizador expresso em centésimos de segundo. |
CpuUExec |
FLOAT |
O tempo que a CPU está a executar o código de serviço expresso em centésimos de segundo. |
Roles
Esta tabela fornece informações sobre as funções.
| Coluna | Tipo | Descrição |
|---|---|---|
RoleName |
STRING |
O nome da função. |
Grantor |
STRING |
O nome da base de dados que concedeu a função. |
Grantee |
STRING |
O utilizador ao qual é concedida a função. |
WhenGranted |
TIMESTAMP |
Quando a função foi concedida. |
WithAdmin |
BOOLEAN |
A opção de administrador está definida para a função concedida. |
SchemaConversion
Esta tabela fornece informações sobre conversões de esquemas relacionadas com o agrupamento e a partição.
| Nome da coluna | Tipo de coluna | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados de origem para a qual a sugestão é feita. Uma base de dados é mapeada para um conjunto de dados no BigQuery. |
TableName |
STRING |
O nome da tabela para a qual a sugestão é feita. |
PartitioningColumnName |
STRING |
O nome da coluna de partição sugerida no BigQuery. |
ClusteringColumnNames |
ARRAY |
Os nomes das colunas de agrupamento sugeridas no BigQuery. |
CreateTableDDL |
STRING |
O CREATE TABLE statement
para criar a tabela no BigQuery. |
TableInfo
Esta tabela fornece informações sobre tabelas.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. |
TableNameOriginal |
STRING |
O nome da tabela com a capitalização preservada. |
LastAccessTimestamp |
TIMESTAMP |
A última vez que a tabela foi acedida. |
LastAlterTimestamp |
TIMESTAMP |
A última vez que a tabela foi alterada. |
TableKind |
STRING |
O tipo de tabela. |
TableRelations
Esta tabela fornece informações sobre tabelas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta que estabeleceu a relação. |
DatabaseName1 |
STRING |
O nome da primeira base de dados. |
TableName1 |
STRING |
O nome da primeira tabela. |
DatabaseName2 |
STRING |
O nome da segunda base de dados. |
TableName2 |
STRING |
O nome da segunda tabela. |
Relation |
STRING |
O tipo de relação entre as duas tabelas. |
TableSizes
Esta tabela fornece informações sobre os tamanhos das tabelas.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. |
DatabaseNameOriginal |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. |
TableNameOriginal |
STRING |
O nome da tabela com a capitalização preservada. |
TableSizeInBytes |
INTEGER |
O tamanho da tabela em bytes. |
Users
Esta tabela fornece informações sobre os utilizadores.
| Coluna | Tipo | Descrição |
|---|---|---|
UserName |
STRING |
O nome do utilizador. |
CreatorName |
STRING |
O nome da entidade que criou este utilizador. |
CreateTimestamp |
TIMESTAMP |
A data/hora em que este utilizador foi criado. |
LastAccessTimestamp |
TIMESTAMP |
A data/hora em que este utilizador acedeu pela última vez a uma base de dados. |
Redshift
Columns
A tabela Columns provém de uma das seguintes tabelas:
SVV_COLUMNS,
INFORMATION_SCHEMA.COLUMNS
ou
PG_TABLE_DEF,
ordenadas por prioridade. A ferramenta tenta carregar primeiro os dados da tabela de prioridade mais alta. Se esta ação falhar, tenta carregar dados da tabela de prioridade seguinte mais alta. Consulte a documentação do Amazon Redshift ou do PostgreSQL para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados. |
SchemaName |
STRING |
O nome do esquema. |
TableName |
STRING |
O nome da tabela. |
ColumnName |
STRING |
O nome da coluna. |
DefaultValue |
STRING |
O valor predefinido, se disponível. |
Nullable |
BOOLEAN |
Se uma coluna pode ou não ter um valor nulo. |
ColumnType |
STRING |
O tipo da coluna, como VARCHAR. |
ColumnLength |
INTEGER |
O tamanho da coluna, como 30 para um
VARCHAR(30). |
CreateAndDropStatistic
Esta tabela fornece informações sobre a criação e a eliminação de tabelas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
DefaultDatabase |
STRING |
A base de dados predefinida. |
EntityType |
STRING |
O tipo de entidade, por exemplo, TABLE. |
EntityName |
STRING |
O nome da entidade. |
Operation |
STRING |
A operação: CREATE ou DROP. |
Databases
Esta tabela provém diretamente da tabela PG_DATABASE_INFO do Amazon Redshift. Os nomes dos campos originais da tabela PG são incluídos nas descrições. Consulte a documentação do Amazon Redshift e do PostgreSQL para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados. Nome da origem: datname |
Owner |
STRING |
O proprietário da base de dados. Por exemplo, o utilizador que criou a base de dados. Nome da origem: datdba |
ExternalColumns
Esta tabela contém informações da tabela SVV_EXTERNAL_COLUMNS do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
SchemaName |
STRING |
O nome do esquema externo. |
TableName |
STRING |
O nome da tabela externa. |
ColumnName |
STRING |
O nome da coluna externa. |
ColumnType |
STRING |
O tipo de coluna. |
Nullable |
BOOLEAN |
Se uma coluna pode ou não ter um valor nulo. |
ExternalDatabases
Esta tabela contém informações da tabela SVV_EXTERNAL_DATABASES do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados externa. |
Location |
STRING |
A localização da base de dados. |
ExternalPartitions
Esta tabela contém informações da tabela SVV_EXTERNAL_PARTITIONS do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
SchemaName |
STRING |
O nome do esquema externo. |
TableName |
STRING |
O nome da tabela externa. |
Location |
STRING |
A localização da partição. O tamanho da coluna está limitado a 128 carateres. Os valores mais longos são truncados. |
ExternalSchemas
Esta tabela contém informações da tabela SVV_EXTERNAL_SCHEMAS do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
SchemaName |
STRING |
O nome do esquema externo. |
DatabaseName |
STRING |
O nome da base de dados externa. |
ExternalTables
Esta tabela contém informações da tabela SVV_EXTERNAL_TABLES do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
SchemaName |
STRING |
O nome do esquema externo. |
TableName |
STRING |
O nome da tabela externa. |
Functions
Esta tabela contém informações da tabela PG_PROC do Amazon Redshift diretamente. Consulte a documentação do Amazon Redshift e do PostgreSQL para ver mais detalhes acerca do esquema e da utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
SchemaName |
STRING |
O nome do esquema. |
FunctionName |
STRING |
O nome da função. |
LanguageName |
STRING |
A linguagem de implementação ou a interface de chamadas desta função. |
Queries
Esta tabela é gerada com as informações da tabela QueryLogs. Ao contrário da tabela QueryLogs, cada linha na tabela Queries contém apenas uma declaração de consulta armazenada na coluna QueryText. Esta tabela fornece os dados de origem para gerar as tabelas de estatísticas e os resultados da tradução.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryText |
STRING |
O texto da consulta. |
QueryHash |
STRING |
O hash da consulta. |
QueryLogs
Esta tabela fornece informações sobre a execução de consultas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryText |
STRING |
O texto da consulta. |
QueryHash |
STRING |
O hash da consulta. |
QueryID |
STRING |
O ID da consulta. |
UserID |
STRING |
O ID do utilizador. |
StartTime |
TIMESTAMP |
A hora de início. |
Duration |
INTEGER |
Duração em milissegundos. |
QueryTypeStatistics
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
DefaultDatabase |
STRING |
A base de dados predefinida. |
QueryType |
STRING |
O tipo de consulta. |
UpdatedTable |
STRING |
A tabela atualizada. |
QueriedTables |
ARRAY<STRING> |
As tabelas consultadas. |
TableInfo
Esta tabela contém informações extraídas da tabela SVV_TABLE_INFO no Amazon Redshift.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados. |
SchemaName |
STRING |
O nome do esquema. |
TableId |
INTEGER |
O ID da tabela. |
TableName |
STRING |
O nome da tabela. |
SortKey1 |
STRING |
Primeira coluna na chave de ordenação. |
SortKeyNum |
INTEGER |
Número de colunas definidas como chaves de ordenação. |
MaxVarchar |
INTEGER |
Tamanho da maior coluna que usa um VARCHAR
tipo de dados. |
Size |
INTEGER |
Tamanho da tabela, em blocos de dados de 1 MB. |
TblRows |
INTEGER |
Número total de linhas na tabela. |
TableRelations
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta que estabeleceu a relação (por exemplo, uma consulta JOIN). |
DefaultDatabase |
STRING |
A base de dados predefinida. |
TableName1 |
STRING |
A primeira tabela da relação. |
TableName2 |
STRING |
A segunda tabela da relação. |
Relation |
STRING |
O tipo de relação. Assume um dos seguintes valores:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM ou
INSERT_INTO. |
Count |
INTEGER |
A frequência com que esta relação foi observada. |
TableSizes
Esta tabela fornece informações sobre os tamanhos das tabelas.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados. |
SchemaName |
STRING |
O nome do esquema. |
TableName |
STRING |
O nome da tabela. |
TableSizeInBytes |
INTEGER |
O tamanho da tabela em bytes. |
Tables
Esta tabela contém informações extraídas da tabela SVV_TABLES no Amazon Redshift. Consulte a documentação do Amazon Redshift para ver mais detalhes sobre o esquema e a utilização.
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados. |
SchemaName |
STRING |
O nome do esquema. |
TableName |
STRING |
O nome da tabela. |
TableType |
STRING |
O tipo de tabela. |
TranslatedQueries
Esta tabela fornece traduções de consultas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
TranslatedQueryText |
STRING |
Resultado da tradução do dialeto de origem para GoogleSQL. |
TranslationErrors
Esta tabela fornece informações sobre erros de tradução de consultas.
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
Severity |
STRING |
A gravidade do erro, como ERROR. |
Category |
STRING |
A categoria do erro, como
AttributeNotFound. |
Message |
STRING |
A mensagem com os detalhes sobre o erro. |
LocationOffset |
INTEGER |
A posição do caráter da localização do erro. |
LocationLine |
INTEGER |
O número da linha do erro. |
LocationColumn |
INTEGER |
O número da coluna do erro. |
LocationLength |
INTEGER |
O comprimento do caráter da localização do erro. |
UserTableRelations
| Coluna | Tipo | Descrição |
|---|---|---|
UserID |
STRING |
O ID do utilizador. |
TableName |
STRING |
O nome da tabela. |
Relation |
STRING |
A relação. |
Count |
INTEGER |
A contagem. |
Users
Esta tabela contém informações extraídas da tabela PG_USER no Amazon Redshift. Consulte a documentação do PostgreSQL para ver mais detalhes sobre o esquema e a utilização.
| Coluna | Tipo | Descrição | |
|---|---|---|---|
UserName |
STRING |
O nome do utilizador. | |
UserId |
STRING |
O ID do utilizador. |
Floco de neve
Warehouses
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
WarehouseName |
STRING |
O nome do armazém. | Sempre |
State |
STRING |
O estado do armazém. Valores possíveis: STARTED, SUSPENDED, RESIZING. |
Sempre |
Type |
STRING |
Tipo de armazém. Valores possíveis: STANDARD, SNOWPARK-OPTIMIZED. |
Sempre |
Size |
STRING |
Tamanho do armazém. Valores possíveis: X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Sempre |
Databases
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
O nome da base de dados, com a capitalização preservada. | Sempre |
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. | Sempre |
Schemata
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
O nome da base de dados à qual o esquema pertence, com a capitalização preservada. | Sempre |
DatabaseName |
STRING |
O nome da base de dados à qual o esquema pertence, convertido em letras minúsculas. | Sempre |
SchemaNameOriginal |
STRING |
O nome do esquema, com a capitalização preservada. | Sempre |
SchemaName |
STRING |
O nome do esquema, convertido em minúsculas. | Sempre |
Tables
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
O nome da base de dados à qual a tabela pertence, com a capitalização preservada. | Sempre |
DatabaseName |
STRING |
O nome da base de dados à qual a tabela pertence, convertido em minúsculas. | Sempre |
SchemaNameOriginal |
STRING |
O nome do esquema ao qual a tabela pertence, com a capitalização preservada. | Sempre |
SchemaName |
STRING |
O nome do esquema ao qual a tabela pertence, convertido em minúsculas. | Sempre |
TableNameOriginal |
STRING |
O nome da tabela, com a capitalização preservada. | Sempre |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. | Sempre |
TableType |
STRING |
Tipo da tabela (vista / vista materializada / tabela base). | Sempre |
RowCount |
BIGNUMERIC |
Número de linhas na tabela. | Sempre |
Columns
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
DatabaseName |
STRING |
O nome da base de dados, convertido em minúsculas. | Sempre |
DatabaseNameOriginal |
STRING |
O nome da base de dados, com a capitalização preservada. | Sempre |
SchemaName |
STRING |
O nome do esquema, convertido em minúsculas. | Sempre |
SchemaNameOriginal |
STRING |
O nome do esquema, com a capitalização preservada. | Sempre |
TableName |
STRING |
O nome da tabela, convertido em minúsculas. | Sempre |
TableNameOriginal |
STRING |
O nome da tabela com a capitalização preservada. | Sempre |
ColumnName |
STRING |
O nome da coluna, convertido em minúsculas. | Sempre |
ColumnNameOriginal |
STRING |
O nome da coluna com a capitalização preservada. | Sempre |
ColumnType |
STRING |
O tipo de coluna. | Sempre |
CreateAndDropStatistics
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryHash |
STRING |
O hash da consulta. | Sempre |
DefaultDatabase |
STRING |
A base de dados predefinida. | Sempre |
EntityType |
STRING |
O tipo de entidade, por exemplo, TABLE. |
Sempre |
EntityName |
STRING |
O nome da entidade. | Sempre |
Operation |
STRING |
A operação: CREATE ou DROP. |
Sempre |
Queries
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryText |
STRING |
O texto da consulta. | Sempre |
QueryHash |
STRING |
O hash da consulta. | Sempre |
QueryLogs
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryText |
STRING |
O texto da consulta. | Sempre |
QueryHash |
STRING |
O hash da consulta. | Sempre |
QueryID |
STRING |
O ID da consulta. | Sempre |
UserID |
STRING |
O ID do utilizador. | Sempre |
StartTime |
TIMESTAMP |
A hora de início. | Sempre |
Duration |
INTEGER |
Duração em milissegundos. | Sempre |
QueryTypeStatistics
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryHash |
STRING |
O hash da consulta. | Sempre |
DefaultDatabase |
STRING |
A base de dados predefinida. | Sempre |
QueryType |
STRING |
O tipo de consulta. | Sempre |
UpdatedTable |
STRING |
A tabela atualizada. | Sempre |
QueriedTables |
REPEATED STRING |
As tabelas consultadas. | Sempre |
TableRelations
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryHash |
STRING |
O hash da consulta que estabeleceu a relação (por exemplo, uma consulta JOIN). |
Sempre |
DefaultDatabase |
STRING |
A base de dados predefinida. | Sempre |
TableName1 |
STRING |
A primeira tabela da relação. | Sempre |
TableName2 |
STRING |
A segunda tabela da relação. | Sempre |
Relation |
STRING |
O tipo de relação. | Sempre |
Count |
INTEGER |
A frequência com que esta relação foi observada. | Sempre |
TranslatedQueries
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryHash |
STRING |
O hash da consulta. | Sempre |
TranslatedQueryText |
STRING |
Resultado da tradução do dialeto de origem para SQL do BigQuery. | Sempre |
TranslationErrors
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
QueryHash |
STRING |
O hash da consulta. | Sempre |
Severity |
STRING |
A gravidade do erro, por exemplo, ERROR. |
Sempre |
Category |
STRING |
A categoria do erro, por exemplo, AttributeNotFound. |
Sempre |
Message |
STRING |
A mensagem com os detalhes sobre o erro. | Sempre |
LocationOffset |
INTEGER |
A posição do caráter da localização do erro. | Sempre |
LocationLine |
INTEGER |
O número da linha do erro. | Sempre |
LocationColumn |
INTEGER |
O número da coluna do erro. | Sempre |
LocationLength |
INTEGER |
O comprimento do caráter da localização do erro. | Sempre |
UserTableRelations
| Coluna | Tipo | Descrição | Presença |
|---|---|---|---|
UserID |
STRING |
ID do utilizador. | Sempre |
TableName |
STRING |
O nome da tabela. | Sempre |
Relation |
STRING |
A relação. | Sempre |
Count |
INTEGER |
A contagem. | Sempre |
Apache Hive
Columns
Esta tabela fornece informações sobre as colunas:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela com a capitalização preservada. |
ColumnName |
STRING |
O nome da coluna com a capitalização preservada. |
ColumnType |
STRING |
O tipo do BigQuery da coluna, como STRING. |
OriginalColumnType |
STRING |
O tipo original da coluna, como VARCHAR. |
CreateAndDropStatistic
Esta tabela fornece informações sobre a criação e a eliminação de tabelas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
DefaultDatabase |
STRING |
A base de dados predefinida. |
EntityType |
STRING |
O tipo de entidade, por exemplo, TABLE. |
EntityName |
STRING |
O nome da entidade. |
Operation |
STRING |
A operação realizada na tabela (CREATE ou DROP). |
Databases
Esta tabela fornece informações sobre as bases de dados:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
Owner |
STRING |
O proprietário da base de dados. Por exemplo, o utilizador que criou a base de dados. |
Location |
STRING |
Localização da base de dados no sistema de ficheiros. |
Functions
Esta tabela fornece informações sobre as funções:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
FunctionName |
STRING |
O nome da função. |
LanguageName |
STRING |
O nome do idioma. |
ClassName |
STRING |
O nome da classe da função. |
ObjectReferences
Esta tabela fornece informações sobre os objetos referenciados nas consultas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
DefaultDatabase |
STRING |
A base de dados predefinida. |
Clause |
STRING |
A cláusula onde o objeto aparece. Por exemplo, SELECT. |
ObjectName |
STRING |
O nome do objeto. |
Type |
STRING |
O tipo de objeto. |
Subtype |
STRING |
O subtipo do objeto. |
PartitionKeys
Esta tabela fornece informações sobre as chaves de partição:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela com a capitalização preservada. |
ColumnName |
STRING |
O nome da coluna com a capitalização preservada. |
ColumnType |
STRING |
O tipo do BigQuery da coluna, como STRING. |
Partitions
Esta tabela fornece informações sobre as partições de tabelas:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela com a capitalização preservada. |
PartitionName |
STRING |
O nome da partição. |
CreateTimestamp |
TIMESTAMP |
A data/hora em que esta partição foi criada. |
LastAccessTimestamp |
TIMESTAMP |
A data/hora em que esta partição foi acedida pela última vez. |
LastDdlTimestamp |
TIMESTAMP |
A data/hora em que esta partição foi alterada pela última vez. |
TotalSize |
INTEGER |
O tamanho comprimido da partição em bytes. |
Queries
Esta tabela é gerada com as informações da tabela QueryLogs. Ao contrário da tabela QueryLogs, cada linha na tabela Queries contém apenas uma declaração de consulta armazenada na coluna QueryText. Esta tabela fornece os dados de origem para gerar as tabelas de estatísticas e os resultados da tradução:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
QueryText |
STRING |
O texto da consulta. |
QueryLogs
Esta tabela fornece algumas estatísticas de execução sobre as consultas extraídas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryText |
STRING |
O texto da consulta. |
QueryHash |
STRING |
O hash da consulta. |
QueryId |
STRING |
O ID da consulta. |
QueryType |
STRING |
O tipo de consulta, Query ou DDL. |
UserName |
STRING |
O nome do utilizador que executou a consulta. |
StartTime |
TIMESTAMP |
A data/hora em que a consulta foi enviada. |
Duration |
STRING |
A duração da consulta em milissegundos. |
QueryTypeStatistics
Esta tabela apresenta estatísticas sobre os tipos de consultas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
QueryType |
STRING |
O tipo de consulta. |
UpdatedTable |
STRING |
A tabela que foi atualizada pela consulta, se existir. |
QueriedTables |
ARRAY<STRING> |
Uma lista das tabelas que foram consultadas. |
QueryTypes
Esta tabela apresenta estatísticas sobre os tipos de consultas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
Category |
STRING |
A categoria da consulta. |
Type |
STRING |
O tipo de consulta. |
Subtype |
STRING |
O subtipo da consulta. |
SchemaConversion
Esta tabela fornece informações sobre conversões de esquemas relacionadas com o agrupamento e a partição:
| Nome da coluna | Tipo de coluna | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados de origem para a qual a sugestão é feita. Uma base de dados é mapeada para um conjunto de dados no BigQuery. |
TableName |
STRING |
O nome da tabela para a qual a sugestão é feita. |
PartitioningColumnName |
STRING |
O nome da coluna de partição sugerida no BigQuery. |
ClusteringColumnNames |
ARRAY |
Os nomes das colunas de agrupamento sugeridas no BigQuery. |
CreateTableDDL |
STRING |
O CREATE TABLE statement
para criar a tabela no BigQuery. |
TableRelations
Esta tabela fornece informações sobre tabelas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta que estabeleceu a relação. |
DatabaseName1 |
STRING |
O nome da primeira base de dados. |
TableName1 |
STRING |
O nome da primeira tabela. |
DatabaseName2 |
STRING |
O nome da segunda base de dados. |
TableName2 |
STRING |
O nome da segunda tabela. |
Relation |
STRING |
O tipo de relação entre as duas tabelas. |
TableSizes
Esta tabela fornece informações sobre os tamanhos das tabelas:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela com a capitalização preservada. |
TotalSize |
INTEGER |
O tamanho da tabela em bytes. |
Tables
Esta tabela fornece informações sobre tabelas:
| Coluna | Tipo | Descrição |
|---|---|---|
DatabaseName |
STRING |
O nome da base de dados com a capitalização preservada. |
TableName |
STRING |
O nome da tabela com a capitalização preservada. |
Type |
STRING |
O tipo de tabela. |
TranslatedQueries
Esta tabela fornece traduções de consultas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
TranslatedQueryText |
STRING |
O resultado da tradução do dialeto de origem para GoogleSQL. |
TranslationErrors
Esta tabela fornece informações sobre erros de tradução de consultas:
| Coluna | Tipo | Descrição |
|---|---|---|
QueryHash |
STRING |
O hash da consulta. |
Severity |
STRING |
A gravidade do erro, como ERROR. |
Category |
STRING |
A categoria do erro, como
AttributeNotFound. |
Message |
STRING |
A mensagem com os detalhes sobre o erro. |
LocationOffset |
INTEGER |
A posição do caráter da localização do erro. |
LocationLine |
INTEGER |
O número da linha do erro. |
LocationColumn |
INTEGER |
O número da coluna do erro. |
LocationLength |
INTEGER |
O comprimento do caráter da localização do erro. |
UserTableRelations
| Coluna | Tipo | Descrição |
|---|---|---|
UserID |
STRING |
O ID do utilizador. |
TableName |
STRING |
O nome da tabela. |
Relation |
STRING |
A relação. |
Count |
INTEGER |
A contagem. |
Resolução de problemas
Esta secção explica alguns problemas comuns e técnicas de resolução de problemas para migrar o seu armazém de dados para o BigQuery.
dwh-migration-dumper erros de ferramentas
Para resolver problemas de erros e avisos no resultado do terminal da ferramenta dwh-migration-dumper que ocorreram durante a extração de metadados ou registos de consultas, consulte o artigo gerar resolução de problemas de metadados.
Erros de migração do Hive
Esta secção descreve problemas comuns que pode encontrar quando planeia migrar o seu armazém de dados do Hive para o BigQuery.
O gancho de registo escreve mensagens de registo de depuração nos seus registos hive-server2. Se tiver problemas, reveja os registos de depuração do gancho de registo, que contêm a string MigrationAssessmentLoggingHook.
Resolva o erro ClassNotFoundException
O erro pode ser causado pela colocação incorreta do ficheiro JAR do gancho de registo. Certifique-se de que adicionou o ficheiro JAR à pasta auxlib no cluster do Hive. Em alternativa, pode especificar o caminho completo para o ficheiro JAR na propriedade hive.aux.jars.path, por exemplo, file://.
As subpastas não aparecem na pasta configurada
Este problema pode dever-se à configuração incorreta ou a problemas durante a inicialização do gancho de registo.
Pesquise nos seus registos de depuração hive-server2 as seguintes mensagens de gancho de registo:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Reveja os detalhes do problema e verifique se existe algo que precise de corrigir para resolver o problema.
Os ficheiros não aparecem na pasta
Este problema pode ser causado pelos problemas encontrados durante o processamento de um evento ou ao escrever num ficheiro.
Pesquise nos seus registos de depuração hive-server2 as seguintes mensagens de gancho de registo:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Reveja os detalhes do problema e verifique se existe algo que precise de corrigir para resolver o problema.
Alguns eventos de consulta são perdidos
Este problema pode ser causado pelo excesso de capacidade da fila de threads do gancho de registo.
Pesquise nos seus registos de depuração hive-server2 a seguinte mensagem de gancho de registo:
Writer queue is full. Ignoring event
Se existirem mensagens deste tipo, considere aumentar o parâmetro dwhassessment.hook.queue.capacity.
O que se segue?
Para mais informações sobre a dwh-migration-dumperferramenta, consulte
dwh-migration-tools.
Também pode saber mais acerca dos seguintes passos na migração do armazém de dados:
- Vista geral da migração
- Vista geral do esquema e da transferência de dados
- Data pipelines
- Tradução de SQL em lote
- Tradução interativa de SQL
- Segurança e governação de dados
- Ferramenta de validação de dados