Évaluation de la migration
L'évaluation de la migration BigQuery vous permet de planifier et d'examiner la migration de votre entrepôt de données existant vers BigQuery. Vous pouvez exécuter l'évaluation de la migration BigQuery pour générer un rapport afin d'évaluer le coût de stockage de vos données dans BigQuery, de voir comment BigQuery peut optimiser votre charge de travail existante en vue de réduire les coûts, et de préparer un plan de migration qui décrit le temps et les efforts nécessaires pour terminer la migration de votre entrepôt de données vers BigQuery.
Ce document explique comment utiliser l'évaluation de la migration BigQuery et les différentes manières d'examiner les résultats de l'évaluation. Ce document est destiné aux utilisateurs familiarisés avec la consoleGoogle Cloud et la traduction SQL par lot.
Avant de commencer
Procédez comme suit pour préparer et exécuter une évaluation de migration BigQuery :
Extrayez les métadonnées et les journaux de requêtes à partir de votre entrepôt de données à l'aide de l'outil
dwh-migration-dumper.Importez vos métadonnées et journaux de requêtes dans votre bucket Cloud Storage.
Facultatif : Interrogez les résultats de l'évaluation pour obtenir des informations détaillées ou spécifiques.
Extraire les métadonnées et interroger les journaux à partir de votre entrepôt de données
Les métadonnées et les journaux de requête sont nécessaires pour préparer l'évaluation à l'aide de recommandations.
Pour extraire les métadonnées et les journaux de requête nécessaires à l'exécution de l'évaluation, sélectionnez votre entrepôt de données :
Teradata
Conditions requises
- Une machine connectée à votre entrepôt de données Teradata source (la version 15 et les versions ultérieures de Teradata sont compatibles)
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données
- Un ensemble de données BigQuery vide pour stocker les résultats
- Des autorisations de lecture sur l'ensemble de données pour afficher les résultats
- Recommandé : droits d'accès de niveau administrateur à la base de données source lors de l'utilisation de l'outil d'extraction pour accéder aux tables système
Condition requise : Activer la journalisation
L'outil dwh-migration-dumper extrait trois types de journaux : les journaux de requêtes, les journaux utilitaires et les journaux d'utilisation des ressources. Afin d'afficher des insights plus approfondis, vous devez activer la journalisation pour les types de journaux suivants :
- Journaux de requête : extraits de la vue
dbc.QryLogVet de la tabledbc.DBQLSqlTbl. Activez la journalisation en spécifiant l'optionWITH SQL. - Journaux utilitaires : extraits de la table
dbc.DBQLUtilityTbl. Activez la journalisation en spécifiant l'optionWITH UTILITYINFO. - Journaux d'utilisation des ressources : extraits des tables
dbc.ResUsageScpuetdbc.ResUsageSpma. Activez la journalisation RSS pour ces deux tables.
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil dwh-migration-dumper.
Téléchargez le fichier SHA256SUMS.txt et exécutez la commande suivante pour vérifier l'exactitude du fichier ZIP :
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Remplacez RELEASE_ZIP_FILENAME par le nom du fichier ZIP téléchargé correspondant à la version de l'outil d'extraction en ligne de commande dwh-migration-dumper (par exemple, dwh-migration-tools-v1.0.52.zip).
Le résultat True confirme la réussite de la vérification de la somme de contrôle.
Le résultat False indique une erreur de validation. Assurez-vous que le fichier de somme de contrôle et le fichier ZIP ont été téléchargés à partir de la même version et placés dans le même répertoire.
Pour en savoir plus sur la configuration et l'utilisation de l'outil d'extraction, consultez la page Générer des métadonnées pour la traduction et l'évaluation.
Utilisez l'outil d'extraction pour extraire les journaux et les métadonnées de votre entrepôt de données Teradata sous la forme de deux fichiers ZIP. Exécutez les commandes suivantes sur une machine ayant accès à l'entrepôt de données source pour générer les fichiers.
Générez le fichier ZIP de métadonnées :
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Remarque : L'option --database est facultative pour le connecteur teradata. Si ce paramètre est omis, les métadonnées de toutes les bases de données sont extraites. Cette option n'est valide que pour le connecteur teradata et ne peut pas être utilisée avec teradata-logs.
Générez le fichier ZIP contenant les journaux de requête :
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Remarque : L'option --database n'est pas utilisée lors de l'extraction des journaux de requêtes avec le connecteur teradata-logs. Les journaux de requête sont toujours extraits pour toutes les bases de données.
Remplacez les éléments suivants :
PATH: chemin absolu ou relatif au fichier JAR du pilote à utiliser pour cette connexionVERSION: version de votre piloteHOST: adresse hôteUSER: nom d'utilisateur à utiliser pour la connexion à la base de donnéesDATABASES: (facultatif) liste de noms de bases de données à extraire, séparés par une virgule. Si ce paramètre n'est pas spécifié, toutes les bases de données sont extraites.PASSWORD: (facultatif) mot de passe à utiliser pour la connexion à la base de données. Si ce champ n'est pas renseigné, l'utilisateur est invité à saisir son mot de passe.
Par défaut, les journaux de requête sont extraits de la vue dbc.QryLogV et de la table dbc.DBQLSqlTbl. Si vous devez extraire les journaux de requête d'un autre emplacement, vous pouvez spécifier les noms des tables ou des vues à l'aide des options -Dteradata-logs.query-logs-table et -Dteradata-logs.sql-logs-table.
Par défaut, les journaux utilitaires sont extraits de la table dbc.DBQLUtilityTbl. Si vous devez extraire les journaux utilitaires d'un autre emplacement, vous pouvez spécifier le nom de la table à l'aide de l'option -Dteradata-logs.utility-logs-table.
Par défaut, les journaux d'utilisation des ressources sont extraits des tables dbc.ResUsageScpu et dbc.ResUsageSpma. Si vous devez extraire les journaux d'utilisation des ressources à partir d'un autre emplacement, vous pouvez spécifier les noms des tables à l'aide des options -Dteradata-logs.res-usage-scpu-table et -Dteradata-logs.res-usage-spma-table.
Par exemple :
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
Par défaut, l'outil dwh-migration-dumper extrait les sept derniers jours de journaux de requête.
Google vous recommande de fournir au moins deux semaines de journaux de requête afin de pouvoir afficher des insights plus approfondis. Vous pouvez spécifier une période personnalisée à l'aide des options --query-log-start et --query-log-end. Exemple :
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
Vous pouvez également générer plusieurs fichiers ZIP contenant des journaux de requête couvrant différentes périodes et tous les fournir à des fins d'évaluation.
Redshift
Conditions requises
- Une machine connectée à votre entrepôt de données Amazon Redshift source
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données
- Un ensemble de données BigQuery vide pour stocker les résultats
- Des autorisations de lecture sur l'ensemble de données pour afficher les résultats
- Recommandé : un accès super-utilisateur à la base de données lors de l'utilisation de l'outil d'extraction pour accéder aux tables système
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande dwh-migration-dumper.
Téléchargez le fichier SHA256SUMS.txt et exécutez la commande suivante pour vérifier l'exactitude du fichier ZIP :
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Remplacez RELEASE_ZIP_FILENAME par le nom du fichier ZIP téléchargé correspondant à la version de l'outil d'extraction en ligne de commande dwh-migration-dumper (par exemple, dwh-migration-tools-v1.0.52.zip).
Le résultat True confirme la réussite de la vérification de la somme de contrôle.
Le résultat False indique une erreur de validation. Assurez-vous que le fichier de somme de contrôle et le fichier ZIP ont été téléchargés à partir de la même version et placés dans le même répertoire.
Pour en savoir plus sur l'utilisation de l'outil dwh-migration-dumper, consultez la page Générer des métadonnées.
Utilisez l'outil dwh-migration-dumper pour extraire les journaux et les métadonnées de votre entrepôt de données Amazon Redshift sous la forme de deux fichiers ZIP.
Exécutez les commandes suivantes sur une machine ayant accès à l'entrepôt de données source pour générer les fichiers.
Générez le fichier ZIP de métadonnées :
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Générez le fichier ZIP contenant les journaux de requête :
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Remplacez les éléments suivants :
DATABASE: nom de la base de données à laquelle se connecterPATH: chemin absolu ou relatif au fichier JAR du pilote à utiliser pour cette connexionVERSION: version de votre piloteUSER: nom d'utilisateur à utiliser pour la connexion à la base de donnéesIAM_PROFILE_NAME: nom du profil IAM Amazon Redshift. Requis pour l'authentification Amazon Redshift et l'accès à l'API AWS. Pour obtenir la description des clusters Amazon Redshift, utilisez l'API AWS.
Par défaut, Amazon Redshift stocke entre trois et cinq jours de journaux de requête.
Par défaut, l'outil dwh-migration-dumper extrait les sept derniers jours de journaux de requête.
Google vous recommande de fournir au moins deux semaines de journaux de requête afin de pouvoir afficher des insights plus approfondis. Pour obtenir des résultats optimaux, vous devrez peut-être exécuter l'outil d'extraction plusieurs fois sur une période de deux semaines. Vous pouvez spécifier une plage personnalisée à l'aide des options --query-log-start et --query-log-end.
Exemple :
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
Vous pouvez également générer plusieurs fichiers ZIP contenant des journaux de requête couvrant différentes périodes et tous les fournir à des fins d'évaluation.
Redshift Serverless
Conditions requises
- Une machine connectée à votre entrepôt de données Amazon Redshift Serverless source
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données
- Un ensemble de données BigQuery vide pour stocker les résultats
- Des autorisations de lecture sur l'ensemble de données pour afficher les résultats
- Recommandé : un accès super-utilisateur à la base de données lors de l'utilisation de l'outil d'extraction pour accéder aux tables système
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande dwh-migration-dumper.
Pour en savoir plus sur l'utilisation de l'outil dwh-migration-dumper, consultez la page Générer des métadonnées.
Utilisez l'outil dwh-migration-dumper pour extraire les journaux d'utilisation et les métadonnées de votre espace de noms Amazon Redshift Serverless sous la forme de deux fichiers ZIP. Exécutez les commandes suivantes sur une machine ayant accès à l'entrepôt de données source pour générer les fichiers.
Générez le fichier ZIP de métadonnées :
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Générez le fichier ZIP contenant les journaux de requête :
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Remplacez les éléments suivants :
DATABASE: nom de la base de données à laquelle se connecterPATH: chemin absolu ou relatif au fichier JAR du pilote à utiliser pour cette connexionVERSION: version de votre piloteUSER: nom d'utilisateur à utiliser pour la connexion à la base de donnéesIAM_PROFILE_NAME: nom du profil IAM Amazon Redshift. Requis pour l'authentification Amazon Redshift et l'accès à l'API AWS. Pour obtenir la description des clusters Amazon Redshift, utilisez l'API AWS.
Amazon Redshift Serverless stocke les journaux d'utilisation pendant sept jours. Si une plage plus large est requise, Google recommande d'extraire les données plusieurs fois sur une période plus longue.
Snowflake
Conditions requises
Vous devez répondre aux exigences suivantes pour extraire les métadonnées et les journaux de requête de Snowflake :
- Une machine pouvant se connecter à vos instances Snowflake.
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données.
- Un ensemble de données BigQuery vide pour stocker les résultats. Vous pouvez également créer un ensemble de données BigQuery lorsque vous créez le job d'évaluation à l'aide de l'interface utilisateur de la console Google Cloud .
- Utilisateur Snowflake disposant d'un accès
IMPORTED PRIVILEGESà la base de donnéesSnowflake. Nous vous recommandons de créer un utilisateurSERVICEavec une authentification basée sur une paire de clés. Cela permet d'accéder de manière sécurisée à la plate-forme de données Snowflake sans avoir à générer de jetons MFA.- Pour créer un utilisateur de service, suivez le guide officiel de Snowflake. Vous devrez générer la paire de clés RSA et attribuer la clé publique à l'utilisateur Snowflake.
- L'utilisateur du service doit disposer du rôle
ACCOUNTADMINou d'un rôle avec les droitsIMPORTED PRIVILEGESsur la base de donnéesSnowflakeaccordé par un administrateur de compte. - Vous pouvez également utiliser l'authentification par mot de passe au lieu de l'authentification par paire de clés. Toutefois, à partir d'août 2025, Snowflake appliquera MFA à tous les utilisateurs qui se connectent avec un mot de passe. Cela vous oblige à approuver la notification push MFA lorsque vous utilisez notre outil d'extraction.
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande dwh-migration-dumper.
Téléchargez le fichier SHA256SUMS.txt et exécutez la commande suivante pour vérifier l'exactitude du fichier ZIP :
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Remplacez RELEASE_ZIP_FILENAME par le nom du fichier ZIP téléchargé correspondant à la version de l'outil d'extraction en ligne de commande dwh-migration-dumper (par exemple, dwh-migration-tools-v1.0.52.zip).
Le résultat True confirme la réussite de la vérification de la somme de contrôle.
Le résultat False indique une erreur de validation. Assurez-vous que le fichier de somme de contrôle et le fichier ZIP ont été téléchargés à partir de la même version et placés dans le même répertoire.
Pour en savoir plus sur l'utilisation de l'outil dwh-migration-dumper, consultez la page Générer des métadonnées.
L'outil dwh-migration-dumper vous permet d'extraire les journaux et les métadonnées de votre entrepôt de données Snowflake sous la forme de deux fichiers ZIP. Exécutez les commandes suivantes sur une machine ayant accès à l'entrepôt de données source pour générer les fichiers.
Générez le fichier ZIP de métadonnées :
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Générez le fichier ZIP contenant les journaux de requête :
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Remplacez les éléments suivants :
HOST_NAME: nom d'hôte de votre instance Snowflake.USER_NAME: nom d'utilisateur à utiliser pour la connexion à la base de données, où l'utilisateur doit disposer des autorisations d'accès décrites dans la section Conditions requises.PRIVATE_KEY_PATH: chemin d'accès à la clé privée RSA utilisée pour l'authentification.PRIVATE_KEY_PASSWORD: (facultatif) mot de passe utilisé lors de la création de la clé privée RSA. Il n'est requis que si la clé privée est chiffrée.ROLE_NAME: (facultatif) rôle utilisateur lors de l'exécution de l'outildwh-migration-dumper(par exemple,ACCOUNTADMIN).WAREHOUSE: entrepôt utilisé pour exécuter les opérations de vidage. Si vous disposez de plusieurs entrepôts virtuels, vous pouvez spécifier n'importe lequel pour exécuter cette requête. L'exécution de cette requête avec les autorisations d'accès détaillées dans la section Conditions requises extrait les artefacts de tous les entrepôts de ce compte.STARTING_DATE: (facultatif) permet d'indiquer la date de début dans une plage de dates des journaux de requête, au formatYYYY-MM-DD.ENDING_DATE: (facultatif) permet d'indiquer la date de fin dans une plage de dates des journaux de requête, au formatYYYY-MM-DD.
Vous pouvez également générer plusieurs fichiers ZIP contenant des journaux de requête couvrant des périodes qui ne se chevauchent pas et tous les fournir à des fins d'évaluation.
Oracle
Pour tout commentaire ou assistance pour cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Conditions requises
Vous devez répondre aux exigences suivantes pour extraire les métadonnées et les journaux de requête d'Oracle :
- Votre base de données Oracle doit être en version 11g R1 ou ultérieure.
- Une machine pouvant se connecter à vos instances Oracle.
- Java 8 ou version ultérieure.
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données.
- Un ensemble de données BigQuery vide pour stocker les résultats. Vous pouvez également créer un ensemble de données BigQuery lorsque vous créez le job d'évaluation à l'aide de l'interface utilisateur de la console Google Cloud .
- Un utilisateur Oracle commun disposant des droits SYSDBA.
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande dwh-migration-dumper.
Téléchargez le fichier SHA256SUMS.txt et exécutez la commande suivante pour vérifier l'exactitude du fichier ZIP :
sha256sum --check SHA256SUMS.txt
Pour en savoir plus sur l'utilisation de l'outil dwh-migration-dumper, consultez la page Générer des métadonnées.
Utilisez l'outil dwh-migration-dumper pour extraire les métadonnées et les statistiques de performances dans le fichier ZIP. Par défaut, les statistiques sont extraites d'Oracle AWR, qui nécessite le pack Oracle Tuning and Diagnostics. Si ces données ne sont pas disponibles, dwh-migration-dumper utilise STATSPACK à la place.
Pour les bases de données multilocataires, l'outil dwh-migration-dumper doit être exécuté dans le conteneur racine. Si vous l'exécutez dans l'une des bases de données enfichables, vous manquerez des statistiques de performances et des métadonnées sur les autres bases de données enfichables.
Générez le fichier ZIP de métadonnées :
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Remplacez les éléments suivants :
HOST_NAME: nom d'hôte de votre instance Oracle.PORT: numéro de port de la connexion. La valeur par défaut est 1521.SERVICE_NAME: nom du service Oracle à utiliser pour la connexion.JDBC_DRIVER_PATH: chemin absolu ou relatif au fichier JAR du pilote. Vous pouvez télécharger ce fichier sur la page Téléchargements du pilote Oracle JDBC. Vous devez sélectionner la version du pilote compatible avec la version de votre base de données.USER_NAME: nom de l'utilisateur utilisé pour se connecter à votre instance Oracle. L'utilisateur doit disposer des autorisations d'accès décrites dans la section des exigences.
Hadoop / Cloudera
Pour tout commentaire ou assistance pour cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Conditions requises
Pour extraire les métadonnées de Cloudera, vous devez disposer des éléments suivants :
- Une machine pouvant se connecter à l'API Cloudera Manager.
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données.
- Un ensemble de données BigQuery vide pour stocker les résultats. Vous pouvez également créer un ensemble de données BigQuery lorsque vous créez le job d'évaluation.
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande
dwh-migration-dumper.Téléchargez le fichier
SHA256SUMS.txt.Dans votre environnement de ligne de commande, vérifiez l'exactitude du fichier ZIP :
sha256sum --check SHA256SUMS.txt
Pour en savoir plus sur l'utilisation de l'outil
dwh-migration-dumper, consultez la section Générer des métadonnées pour la traduction et l'évaluation.Utilisez l'outil
dwh-migration-dumperpour extraire les métadonnées et les statistiques de performances dans le fichier ZIP :dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Remplacez les éléments suivants :
USER_NAME: nom de l'utilisateur à connecter à votre instance Cloudera Manager.PASSWORD: mot de passe de votre instance Cloudera Manager.URL_PATH: chemin d'URL vers l'API Cloudera Manager, par exemplehttps://localhost:7183/api/v55/.APP_TYPES(facultatif) : types d'application YARN séparés par une virgule qui sont extraits du cluster. La valeur par défaut estMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(facultatif) : nombre d'enregistrements par réponse Cloudera. La valeur par défaut est1000.START_DATE(facultatif) : date de début de votre vidage de l'historique au format ISO 8601, par exemple2025-05-29. La valeur par défaut est 90 jours avant la date actuelle.END_DATE(facultatif) : date de fin de votre vidage de l'historique au format ISO 8601, par exemple2025-05-30. La valeur par défaut est la date actuelle.
Utiliser Oozie dans votre cluster Cloudera
Si vous utilisez Oozie dans votre cluster Cloudera, vous pouvez vider l'historique des jobs Oozie avec le connecteur Oozie. Vous pouvez utiliser Oozie avec l'authentification Kerberos ou l'authentification de base.
Pour l'authentification Kerberos, exécutez la commande suivante :
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Remplacez les éléments suivants :
URL_PATH(facultatif) : chemin d'accès à l'URL du serveur Oozie. Si vous ne spécifiez pas le chemin d'accès à l'URL, il est extrait de la variable d'environnementOOZIE_URL.
Pour l'authentification de base, exécutez la commande suivante :
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Remplacez les éléments suivants :
USER_NAME: nom de l'utilisateur Oozie.PASSWORD: mot de passe de l'utilisateur.URL_PATH(facultatif) : chemin d'accès à l'URL du serveur Oozie. Si vous ne spécifiez pas le chemin d'accès à l'URL, il est extrait de la variable d'environnementOOZIE_URL.
Utiliser Airflow dans votre cluster Cloudera
Si vous utilisez Airflow dans votre cluster Cloudera, vous pouvez vider l'historique des DAG avec le connecteur Airflow :
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Remplacez les éléments suivants :
USER_NAME: nom de l'utilisateur AirflowPASSWORD: mot de passe de l'utilisateurURL: chaîne JDBC vers la base de données AirflowDRIVER_PATH: chemin d'accès au pilote JDBCSTART_DATE(facultatif) : date de début de votre vidage de l'historique au format ISO 8601END_DATE(facultatif) : date de fin de votre vidage de l'historique au format ISO 8601
Utiliser Hive dans votre cluster Cloudera
Pour utiliser le connecteur Hive, consultez l'onglet "Apache Hive".
Apache Hive
Conditions requises
- Une machine connectée à votre entrepôt de données Apache Hive source (l'évaluation de la migration BigQuery est compatible avec Hive sur Tez et MapReduce, et avec les versions 2.2 à 3.1 incluses d'Apache Hive)
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données
- Un ensemble de données BigQuery vide pour stocker les résultats
- Des autorisations de lecture sur l'ensemble de données pour afficher les résultats
- L'accès à votre entrepôt de données source Apache Hive afin de configurer l'extraction des journaux de requêtes
- Statistiques à jour sur les tables, les partitions et les colonnes
L'évaluation de la migration BigQuery utilise des tables, des partitions et des statistiques de colonne pour mieux comprendre votre entrepôt de données Apache Hive et fournir des insights précis. Si le paramètre de configuration hive.stats.autogather est défini sur false dans votre entrepôt de données source Apache Hive, Google recommande de l'activer ou de mettre à jour les statistiques manuellement avant d'exécuter l'outil dwh-migration-dumper.
Exécuter l'outil dwh-migration-dumper
Téléchargez l'outil d'extraction en ligne de commande dwh-migration-dumper.
Téléchargez le fichier SHA256SUMS.txt et exécutez la commande suivante pour vérifier l'exactitude du fichier ZIP :
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Remplacez RELEASE_ZIP_FILENAME par le nom du fichier ZIP téléchargé correspondant à la version de l'outil d'extraction en ligne de commande dwh-migration-dumper (par exemple, dwh-migration-tools-v1.0.52.zip).
Le résultat True confirme la réussite de la vérification de la somme de contrôle.
Le résultat False indique une erreur de validation. Assurez-vous que le fichier de somme de contrôle et le fichier ZIP ont été téléchargés à partir de la même version et placés dans le même répertoire.
Pour en savoir plus sur l'utilisation de l'outil dwh-migration-dumper, consultez la section Générer des métadonnées pour la traduction et l'évaluation.
Utilisez l'outil dwh-migration-dumper pour générer des métadonnées à partir de votre entrepôt de données Hive sous forme de fichier ZIP.
Sans authentification
Pour générer le fichier ZIP de métadonnées, exécutez la commande suivante sur une machine ayant accès à l'entrepôt de données source :
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Avec authentification Kerberos
Pour vous authentifier auprès du metastore, connectez-vous en tant qu'utilisateur ayant accès au metastore Apache Hive et générez un ticket Kerberos. Ensuite, générez le fichier ZIP de métadonnées à l'aide de la commande suivante :
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Remplacez les éléments suivants :
DATABASES: liste de noms de bases de données à extraire, séparés par une virgule. Si ce paramètre n'est pas spécifié, toutes les bases de données sont extraites.PRINCIPAL: compte principal kerberos pour lequel le ticket est émisHOST: nom d'hôte kerberos pour lequel le ticket est émishadoop.rpc.protection: qualité de protection (QOP) du niveau de configuration SASL (Simple Authentication and Security Layer), égale à la valeur du paramètrehadoop.rpc.protectiondans le fichier/etc/hadoop/conf/core-site.xml, avec l'une des valeurs suivantes :authenticationintegrityprivacy
Extraire les journaux de requêtes avec le hook de journalisation hadoop-migration-assessment
Procédez comme suit pour extraire les journaux de requêtes :
- Importez le hook de journalisation
hadoop-migration-assessment. - Configurez les propriétés du hook de journalisation.
- Vérifiez le hook de journalisation.
Importer le hook de journalisation hadoop-migration-assessment
Téléchargez le hook de journalisation d'extraction des journaux de requête
hadoop-migration-assessment, qui contient le fichier JAR du hook de journalisation Hive.Extrayez le fichier JAR.
Si vous devez procéder à un audit de l'outil afin de vous assurer qu'il répond aux exigences de conformité, examinez le code source à partir du dépôt GitHub de hook de journalisation
hadoop-migration-assessment, puis compilez votre propre binaire.Copiez le fichier JAR dans le dossier de la bibliothèque auxiliaire, sur tous les clusters dans lesquels vous prévoyez d'activer la journalisation des requêtes. Selon votre fournisseur, vous devrez localiser le dossier de la bibliothèque auxiliaire dans les paramètres du cluster et transférer le fichier JAR vers le dossier de la bibliothèque auxiliaire sur le cluster Hive.
Définissez les propriétés de configuration du hook de journalisation
hadoop-migration-assessment. Selon votre fournisseur Hadoop, vous devrez utiliser la console de l'interface utilisateur pour modifier les paramètres du cluster. Modifiez le fichier/etc/hive/conf/hive-site.xmlou appliquez la configuration à l'aide du gestionnaire de configuration.
Configurer les propriétés
Si vous disposez déjà d'autres valeurs pour les clés de configuration suivantes, ajoutez les paramètres à l'aide d'une virgule (,). Pour configurer le hook de journalisation hadoop-migration-assessment, les paramètres de configuration suivants sont requis :
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: incluez le chemin d'accès au fichier JAR du hook de journalisation, par exemplefile://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: chemin d'accès au dossier de sortie des journaux de requêtes. Par exemple,hdfs://tmp/logs/.Vous pouvez également définir les configurations facultatives suivantes :
dwhassessment.hook.queue.capacity: capacité de la file d'attente pour les threads de journalisation des événements de requête. La valeur par défaut est64.dwhassessment.hook.rollover-interval: fréquence à laquelle le roulement de fichiers doit être effectué. Par exemple,600s. La valeur par défaut est de 3 600 secondes (une heure).dwhassessment.hook.rollover-eligibility-check-interval: fréquence à laquelle la vérification de l'éligibilité au roulement de fichiers est déclenchée en arrière-plan. Par exemple,600s. La valeur par défaut est de 600 secondes (10 minutes).
Vérifier le hook de journalisation
Après avoir redémarré le processus hive-server2, exécutez une requête de test et analysez vos journaux de débogage. Le message suivant s'affiche :
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
Le hook de journalisation crée un sous-dossier partitionné par date dans le dossier configuré. Le fichier Avro contenant les événements de requête apparaît dans ce dossier à l'issue de l'intervalle dwhassessment.hook.rollover-interval ou après l'arrêt du processus hive-server2. Vous pouvez rechercher des messages similaires dans vos journaux de débogage pour voir l'état de l'opération de roulement :
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
Le roulement s'effectue aux intervalles spécifiés ou lors du passage d'un jour au suivant. Lorsque la date change, le hook de journalisation crée également un sous-dossier pour cette date.
Google vous recommande de fournir au moins deux semaines de journaux de requête afin de pouvoir afficher des insights plus approfondis.
Vous pouvez également générer des dossiers contenant les journaux de requêtes de différents clusters Hive et fournir l'ensemble de ces journaux pour une seule évaluation.
Informatica
Pour tout commentaire ou assistance pour cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Conditions requises
- Accès au client Informatica PowerCenter Repository Manager
- Un compte Google Cloud avec un bucket Cloud Storage pour stocker les données.
- Un ensemble de données BigQuery vide pour stocker les résultats. Vous pouvez également créer un ensemble de données BigQuery lorsque vous créez le job d'évaluation à l'aide de la console Google Cloud .
Exigence : exporter les fichiers d'objets
Vous pouvez utiliser l'interface utilisateur graphique du gestionnaire de dépôt Informatica PowerCenter pour exporter vos fichiers d'objets. Pour en savoir plus, consultez Étapes à suivre pour exporter des objets.
Vous pouvez également exécuter la commande pmrep pour exporter vos fichiers objet en procédant comme suit :
- Exécutez la commande
pmrep connectpour vous connecter au dépôt :
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Remplacez les éléments suivants :
REPOSITORY_NAME: nom du dépôt auquel vous souhaitez vous connecterDOMAIN_NAME: nom de domaine du dépôtUSERNAME: nom d'utilisateur pour se connecter au dépôtPASSWORD: mot de passe du nom d'utilisateur
- Une fois connecté au dépôt, utilisez la commande
pmrep objectexportpour exporter les objets requis :
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Remplacez les éléments suivants :
OBJECT_NAME: nom d'un objet spécifique à exporterOBJECT_TYPE: type d'objet de l'objet spécifiéFOLDER_NAME: nom du dossier contenant l'objet à exporterOUTPUT_FILE_NAME: nom du fichier XML contenant les informations sur l'objet
Importer des métadonnées et des journaux de requête dans Cloud Storage
Une fois que vous avez extrait les métadonnées et les journaux de requêtes de votre entrepôt de données, vous pouvez importer les fichiers dans un bucket Cloud Storage pour procéder à l'évaluation de la migration.
Teradata
Importez les métadonnées et un ou plusieurs fichiers ZIP contenant les journaux de requêtes dans votre bucket Cloud Storage. Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers. La taille totale non compressée de l'ensemble des fichiers présents dans le fichier ZIP de métadonnées est limitée à 50 Go.
Les entrées de tous les fichiers ZIP contenant les journaux de requête sont divisées comme suit :
- Les fichiers d'historique des requêtes portent le préfixe
query_history_. - Les fichiers de séries temporelles portent les préfixes
utility_logs_,dbc.ResUsageScpu_etdbc.ResUsageSpma_.
La taille totale non compressée de l'ensemble des fichiers d'historique des requêtes est limitée à 5 To. La taille totale non compressée de l'ensemble des fichiers de séries temporelles est limitée à 1 To.
Si les journaux de requête sont archivés dans une autre base de données, consultez la description des options -Dteradata-logs.query-logs-table et -Dteradata-logs.sql-logs-table plus haut dans cette section, qui explique comment fournir un autre emplacement pour les journaux de requêtes.
Redshift
Importez les métadonnées et un ou plusieurs fichiers ZIP contenant les journaux de requêtes dans votre bucket Cloud Storage. Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers. La taille totale non compressée de l'ensemble des fichiers présents dans le fichier ZIP de métadonnées est limitée à 50 Go.
Les entrées de tous les fichiers ZIP contenant les journaux de requête sont divisées comme suit :
- Les fichiers d'historique des requêtes portent les préfixes
querytext_etddltext_. - Les fichiers de séries temporelles portent les préfixes
query_queue_info_,wlm_query_etquerymetrics_.
La taille totale non compressée de l'ensemble des fichiers d'historique des requêtes est limitée à 5 To. La taille totale non compressée de l'ensemble des fichiers de séries temporelles est limitée à 1 To.
Redshift Serverless
Importez les métadonnées et un ou plusieurs fichiers ZIP contenant les journaux de requêtes dans votre bucket Cloud Storage. Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers.
Snowflake
Importez les métadonnées, les fichiers ZIP contenant les journaux de requête et les historiques d'utilisation dans votre bucket Cloud Storage. Lorsque vous importez ces fichiers dans Cloud Storage, les conditions suivantes doivent être remplies :
- La taille totale non compressée de tous les fichiers dans le fichier ZIP de métadonnées doit être inférieure à 50 Go.
- Le fichier ZIP de métadonnées et le fichier ZIP contenant les journaux de requête doivent être importés dans un dossier Cloud Storage. Si vous disposez de plusieurs fichiers ZIP contenant des journaux de requête qui ne se chevauchent pas, vous pouvez les importer tous.
- Vous devez importer tous les fichiers dans le même dossier Cloud Storage.
- Vous devez importer tous les fichiers ZIP de métadonnées et de journaux de requêtes exactement tels qu'ils sont générés par l'outil
dwh-migration-dumper. Vous ne devez pas les extraire, les combiner ni les modifier. - La taille totale non compressée de tous les fichiers de l'historique des requêtes doit être inférieure à 5 To.
Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers.
Oracle
Pour demander des commentaires ou de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Importez le fichier ZIP contenant les métadonnées et les statistiques de performances dans un bucket Cloud Storage. Par défaut, le nom du fichier ZIP est dwh-migration-oracle-stats.zip, mais vous pouvez le personnaliser en le spécifiant dans l'indicateur --output. La taille totale non compressée de l'ensemble des fichiers présents dans le fichier ZIP est limitée à 50 Go.
Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers.
Hadoop / Cloudera
Pour demander des conseils ou obtenir de l'aide pour cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Importez le fichier ZIP contenant les métadonnées et les statistiques de performances dans un bucket Cloud Storage. Par défaut, le nom du fichier ZIP est dwh-migration-cloudera-manager-RUN_DATE.zip (par exemple, dwh-migration-cloudera-manager-20250312T145808.zip), mais vous pouvez le personnaliser avec l'indicateur --output. La taille totale non compressée de tous les fichiers dans le fichier ZIP est limitée à 50 Go.
Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez Créer un bucket et Importer des objets à partir d'un système de fichiers.
Apache Hive
Importez les métadonnées et les dossiers contenant les journaux de requêtes d'un ou de plusieurs clusters Hive dans votre bucket Cloud Storage. Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers.
La taille totale non compressée de l'ensemble des fichiers présents dans le fichier ZIP de métadonnées est limitée à 50 Go.
Vous pouvez utiliser le connecteur Cloud Storage pour copier les journaux de requêtes directement dans le dossier Cloud Storage. Les dossiers contenant des sous-dossiers avec des journaux de requêtes doivent être importés dans le même dossier Cloud Storage que celui dans lequel est importé le fichier ZIP de métadonnées.
Les dossiers de journaux de requêtes contiennent des fichiers d'historique des requêtes comportant le préfixe dwhassessment_. La taille totale non compressée de l'ensemble des fichiers d'historique des requêtes est limitée à 5 To.
Informatica
Pour demander des commentaires ou de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Importez un fichier ZIP contenant vos objets de dépôt XML Informatica dans un bucket Cloud Storage. Ce fichier ZIP doit également inclure un fichier compilerworks-metadata.yaml contenant les éléments suivants :
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
La taille totale non compressée de tous les fichiers dans le fichier ZIP est limitée à 50 Go.
Pour en savoir plus sur la création de buckets et l'importation de fichiers dans Cloud Storage, consultez les pages Créer des buckets et Importer des objets à partir d'un système de fichiers.
Exécuter une évaluation de migration BigQuery
Suivez la procédure ci-dessous pour exécuter l'évaluation de la migration BigQuery. Ces étapes supposent que vous avez importé les fichiers de métadonnées dans un bucket Cloud Storage, comme décrit dans la section précédente.
Autorisations requises
Pour activer le service de migration BigQuery, vous devez disposer des autorisations Identity and Access Management (IAM) suivantes :
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Pour accéder au service de migration BigQuery et l'utiliser, vous devez disposer des autorisations suivantes sur le projet :
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Pour exécuter le service de migration BigQuery, vous devez disposer des autorisations supplémentaires suivantes.
Autorisation d'accéder aux buckets Cloud Storage pour les fichiers d'entrée et de sortie :
storage.objects.getsur le bucket Cloud Storage sourcestorage.objects.listsur le bucket Cloud Storage sourcestorage.objects.createsur le bucket Cloud Storage de destinationstorage.objects.deletesur le bucket Cloud Storage de destinationstorage.objects.updatesur le bucket Cloud Storage de destinationstorage.buckets.getstorage.buckets.list
Autorisation de lire et de mettre à jour l'ensemble de données BigQuery dans lequel le service de migration BigQuery écrit les résultats :
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Pour partager le rapport Looker Studio avec un utilisateur, vous devez attribuer les rôles suivants :
roles/bigquery.dataViewerroles/bigquery.jobUser
Pour personnaliser ce document afin d'utiliser votre propre projet et votre propre utilisateur dans les commandes, modifiez les variables suivantes : PROJECT, USER_EMAIL.
Créez un rôle personnalisé avec les autorisations nécessaires pour utiliser l'évaluation de la migration BigQuery :
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Attribuez le rôle personnalisé BQMSrole à un utilisateur :
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Attribuez les rôles requis à un utilisateur avec lequel vous souhaitez partager le rapport :
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Pays acceptés
La fonctionnalité d'évaluation de la migration BigQuery est compatible avec deux types d'emplacements :
Une région est un emplacement géographique spécifique, par exemple Londres.
Un emplacement multirégional correspond à un secteur géographique de grande étendue, par exemple les États-Unis, et comporte au moins deux régions. Les emplacements multirégionaux peuvent fournir des quotas plus élevés que les régions uniques.
Pour en savoir plus sur les régions et les zones, consultez la section Zones géographiques et régions.
Régions
Le tableau suivant répertorie les régions Amériques où l'évaluation de la migration BigQuery est disponible.| Description de la région | Nom de la région | Détails |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Caroline du Sud | us-east1 |
|
| Virginie du Nord | us-east4 |
|
| Oregon | us-west1 |
|
| Los Angeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Singapour | asia-southeast1 |
|
| Tokyo | asia-northeast1 |
| Description de la région | Nom de la région | Détails |
|---|---|---|
| Belgique | europe-west1 |
|
| Finlande | europe-north1 |
|
| Francfort | europe-west3 |
|
| Londres | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Pays-Bas | europe-west4 |
|
| Paris | europe-west9 |
|
| Turin | europe-west12 |
|
| Varsovie | europe-central2 |
|
| Zurich | europe-west6 |
|
Emplacements multirégionaux
Le tableau suivant répertorie les emplacements multirégionaux où l'évaluation de la migration BigQuery est disponible.| Description de la zone multirégionale | Nom de la zone multirégionale |
|---|---|
| Centres de données dans les États membres de l'Union européenne. | EU |
| Centres de données aux États-Unis | US |
Avant de commencer
Avant d'exécuter l'évaluation, vous devez activer l'API BigQuery Migration et créer un ensemble de données BigQuery pour stocker les résultats.
Activer l'API BigQuery Migration
Activez l'API BigQuery Migration comme suit :
Dans la console Google Cloud , accédez à la page API BigQuery Migration.
Cliquez sur Activer.
Créer un ensemble de données pour les résultats de l'évaluation
L'évaluation de la migration BigQuery écrit les résultats dans des tables dans BigQuery. Avant de commencer, créez un ensemble de données pour stocker ces tables. Lorsque vous partagez le rapport Looker Studio, vous devez également autoriser les utilisateurs à lire cet ensemble de données. Pour en savoir plus, consultez Rendre le rapport accessible aux utilisateurs.
Exécuter l'évaluation de la migration
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Évaluation.
Cliquez sur Démarrer l'évaluation.
Renseignez la boîte de dialogue de configuration de l'évaluation.
- Dans le champ Nom à afficher, saisissez le nom, qui peut contenir des lettres, des chiffres ou des traits de soulignement. Ce nom n'est utilisé qu'à des fins d'affichage et ne doit pas nécessairement être unique.
Dans la liste Emplacement des données, choisissez un emplacement pour la tâche d'évaluation. Le job d'évaluation doit se trouver au même emplacement que le bucket Cloud Storage d'entrée des fichiers extraits et l'ensemble de données BigQuery de sortie. Toutefois, si le bucket Cloud Storage ou l'ensemble de données BigQuery se trouve dans une région multirégionale, le job d'évaluation doit se trouver dans l'une des régions de cette région multirégionale.
Si l'emplacement de l'évaluation est une zone multirégionale
USouEU, l'emplacement du bucket Cloud Storage et l'emplacement de l'ensemble de données BigQuery doivent se trouver dans la même zone multirégionale ou dans l'emplacement de cette zone multirégionale. Pour en savoir plus sur les contraintes d'emplacement, consultez Considérations relatives à l'emplacement des données de chargement BigQuery.Dans le champ Source de données d'évaluation, choisissez votre entrepôt de données.
Dans le champ Chemin d'accès aux fichiers d'entrée, saisissez le chemin d'accès au bucket Cloud Storage contenant vos fichiers extraits.
Pour choisir comment stocker les résultats de votre évaluation, procédez comme suit :
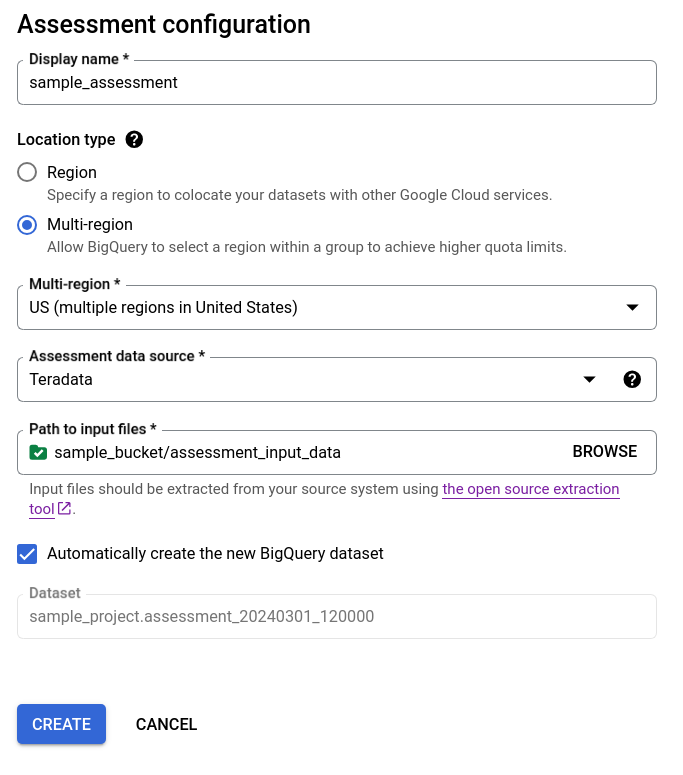
- Laissez la case Créer automatiquement l'ensemble de données BigQuery cochée pour que l'ensemble de données BigQuery soit créé automatiquement. Le nom de l'ensemble de données est généré automatiquement.
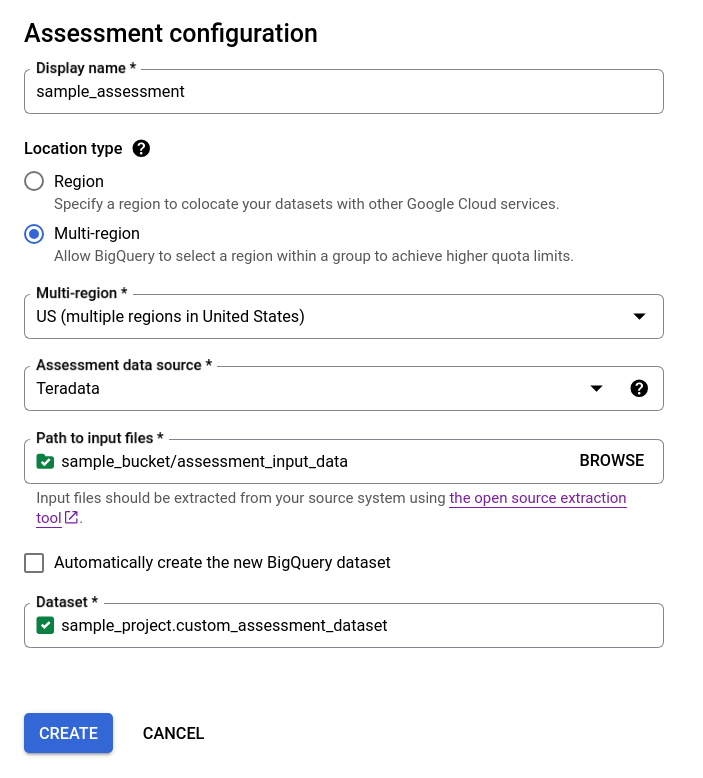
- Décochez la case Créer automatiquement l'ensemble de données BigQuery, puis choisissez l'ensemble de données BigQuery vide existant au format
projectId.datasetIdou créez un nom d'ensemble de données. Cette option vous permet de choisir le nom de l'ensemble de données BigQuery.
Option 1 : génération automatique de l'ensemble de données BigQuery (par défaut)
Option 2 : création manuelle d'un ensemble de données BigQuery :
Cliquez sur Créer. Vous pouvez voir l'état de la tâche dans la liste des tâches de traduction.
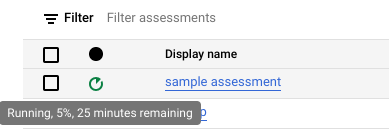
Pendant l'exécution de l'évaluation, vous pouvez vérifier sa progression et le temps estimé pour la terminer dans l'info-bulle de l'icône d'état.
Pendant l'exécution de l'évaluation, vous pouvez cliquer sur le lien Afficher le rapport dans la liste des tâches d'évaluation pour afficher le rapport d'évaluation avec des données partielles dans Looker Studio. Le lien Afficher le rapport peut mettre un certain temps à s'afficher pendant l'évaluation. Le rapport s'ouvre dans un nouvel onglet.
Le rapport est mis à jour avec les nouvelles données à mesure qu'elles sont traitées. Actualisez l'onglet contenant le rapport ou cliquez de nouveau sur Afficher le rapport pour voir le rapport mis à jour.
Une fois l'évaluation terminée, cliquez sur Afficher le rapport pour afficher le rapport d'évaluation complet dans Looker Studio. Le rapport s'ouvre dans un nouvel onglet.
API
Appelez la méthode create avec un workflow défini.
Appelez ensuite la méthode start pour démarrer le workflow d'évaluation.
L'évaluation crée des tables dans l'ensemble de données BigQuery que vous avez créé précédemment. Vous pouvez les interroger pour obtenir des informations sur les tables et les requêtes utilisées dans votre entrepôt de données. Pour en savoir plus sur les fichiers de sortie de la traduction, consultez la page Traduction SQL par lot.
Résultat d'évaluation agrégé partageable
Pour les évaluations Amazon Redshift, Teradata et Snowflake, en plus de l'ensemble de données BigQuery créé précédemment, le workflow crée un autre ensemble de données léger portant le même nom, avec le suffixe _shareableRedactedAggregate. Cet ensemble de données contient des données très agrégées qui sont dérivées de l'ensemble de données de sortie et ne contiennent aucune information permettant d'identifier personnellement l'utilisateur.
Pour trouver, inspecter et partager l'ensemble de données de manière sécurisée avec d'autres utilisateurs, consultez Interroger les tables de résultats de l'évaluation de la migration.
Cette fonctionnalité est activée par défaut, mais vous pouvez la désactiver à l'aide de l'API publique.
Détail des évaluations
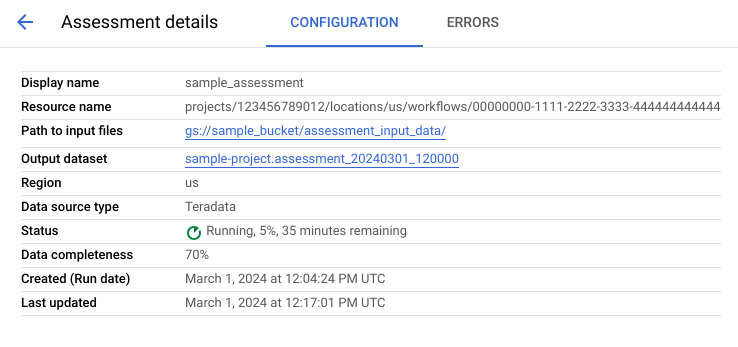
Pour afficher la page "Détails de l'évaluation", cliquez sur le nom à afficher dans la liste des tâches d'évaluation.

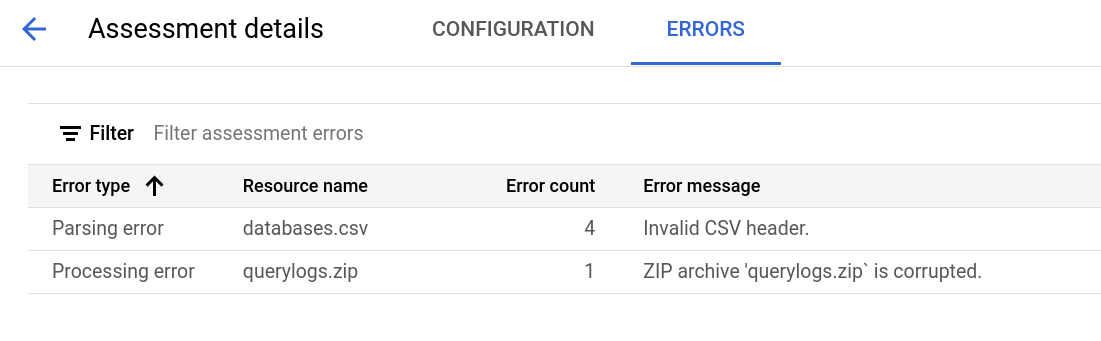
La page des détails de l'évaluation contient l'onglet Configuration, où vous pouvez afficher plus d'informations sur une tâche d'évaluation, et l'onglet Erreurs, où vous pouvez examiner les erreurs survenues lors du traitement de l'évaluation.
Consultez l'onglet Configuration pour afficher les propriétés de l'évaluation.
Consultez l'onglet Erreurs pour voir les erreurs survenues lors du traitement de l'évaluation.
Examiner et partager le rapport Looker Studio
Une fois la tâche d'évaluation terminée, vous pouvez créer et partager un rapport Looker Studio sur les résultats.
Consulter le rapport
Cliquez sur le lien Afficher le rapport situé à côté de votre tâche d'évaluation individuelle. Le rapport Looker Studio s'ouvre dans un nouvel onglet, en mode aperçu. Vous pouvez utiliser le mode aperçu pour examiner le contenu du rapport avant de le partager.
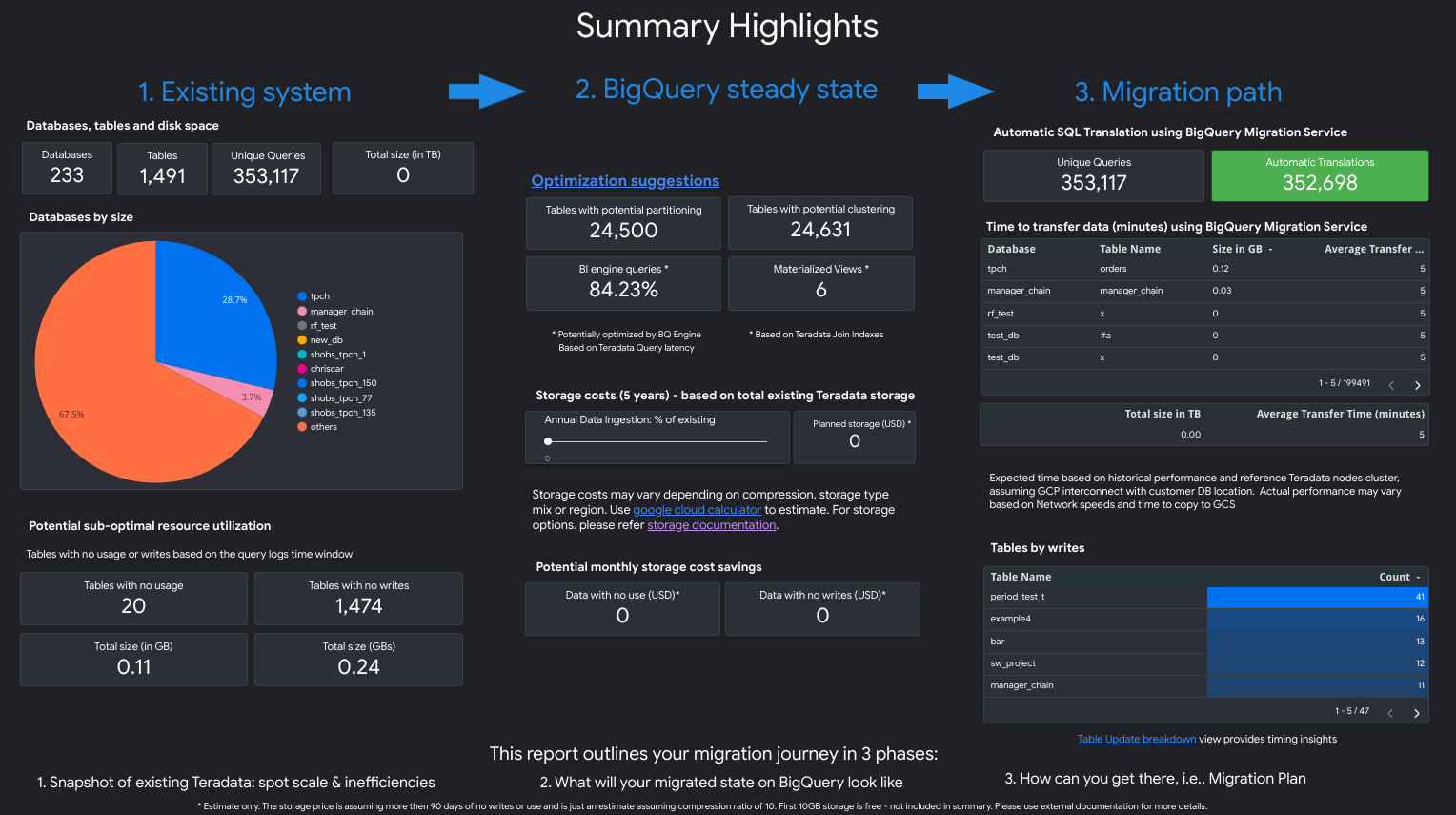
Le rapport ressemble à la capture d'écran suivante :
Pour afficher les vues contenues dans le rapport, sélectionnez votre entrepôt de données :
Teradata
Le rapport est constitué de trois parties précédées d'une page récapitulative. Cette page comprend les sections suivantes :
- Système existant. Cette section est un instantané du système Teradata existant et de son utilisation, y compris le nombre de bases de données, de schémas et de tables, et la taille totale en To. Il répertorie également les schémas par taille et pointe vers une utilisation potentiellement sous-optimale des ressources (tables sans écriture ou peu de lectures).
- Transformations vers l'état stable de BigQuery (suggestions). Cette section montre à quoi ressemblera le système sur BigQuery après la migration. Il inclut des suggestions pour optimiser les charges de travail sur BigQuery (et éviter les gaspillages).
- Plan de migration. Cette section fournit des informations sur les efforts de migration proprement dits, par exemple comment passer du système existant à l'état stable de BigQuery. Cette section inclut le nombre de requêtes traduites automatiquement, ainsi que le temps nécessaire pour déplacer chaque table vers BigQuery.
Les détails de chaque section incluent les éléments suivants :
Système existant
- Calculs et requêtes
- Utilisation du processeur :
- Carte de densité de l'utilisation horaire moyenne du processeur (vue globale de l'utilisation des ressources système)
- Requêtes par heure et par jour avec utilisation du processeur
- Requêtes par type (lecture/écriture) avec utilisation du processeur
- Applications avec utilisation du processeur
- Superposition de l'utilisation horaire du processeur avec les performances horaires moyennes des requêtes et les performances horaires moyennes des applications
- Histogramme des requêtes par type et par durée des requêtes
- Vue des détails des applications (application, utilisateur, requêtes uniques, création de rapports ou la répartition ETL)
- Utilisation du processeur :
- Vue d'ensemble du stockage
- Bases de données par volume, par vues et par taux d'accès
- Tables avec leurs taux d'accès par utilisateur, par requêtes, par écritures et par créations de tables temporaires
- Applications : taux d'accès et adresses IP
Transformations vers l'état stable de BigQuery (suggestions)
- Index de jointure convertis en vues matérialisées
- Candidats à la mise en cluster et au partitionnement en fonction de métadonnées et de l'utilisation
- Requêtes à faible latence identifiées comme candidates pour BigQuery BI Engine
- Colonnes configurées avec des valeurs par défaut qui utilisent la fonctionnalité de description de colonne pour stocker les valeurs par défaut
- Les index uniques de Teradata (pour éviter d'avoir des lignes contenant des clés non uniques dans une table) utilisent des tables de préproduction et une instruction
MERGEpour insérer uniquement des enregistrements uniques dans les tables cibles et supprimer les doublons - Les requêtes restantes et le schéma, traduits tels quels
Plan de migration
- Vue détaillée avec les requêtes traduites automatiquement
- Nombre total de requêtes avec possibilité de filtrer par utilisateur, application, tables concernées, tables interrogées et type de requête
- Buckets de requêtes ayant des modèles similaires regroupés et affichés ensemble afin que l'utilisateur puisse voir la philosophie de traduction par type de requête
- Requêtes nécessitant une intervention humaine
- Requêtes présentant des cas de non-respect de la structure lexicale de BigQuery
- Fonctions et procédures définies par l'utilisateur
- Mots clés réservés de BigQuery
- Programmations de tables par écritures et lectures (afin de les regrouper pour le déplacement)
- Migration de données avec le service de transfert de données BigQuery : durée estimée de la migration par table
La section Système existant contient les vues suivantes :
- Présentation du système
- La vue "Présentation du système" fournit les métriques de volume de haut niveau des composants clés du système existant pour une période spécifiée. La chronologie évaluée dépend des journaux analysés par l'évaluation de la migration BigQuery. Cette vue offre un aperçu rapide de l'utilisation de l'entrepôt de données source, que vous pouvez utiliser pour planifier la migration.
- Volume des tables
- La vue "Volume des tables" fournit des statistiques sur les plus grandes tables et bases de données trouvées lors de l'évaluation de la migration BigQuery. Étant donné que l'extraction de grandes tables depuis le système d'entrepôt de données source peut prendre plus de temps, cette vue peut être utile pour la planification et le séquençage de la migration.
- Utilisation des tables
- La vue "Utilisation des tables" fournit des statistiques sur les tables les plus utilisées dans l'entrepôt de données source. Les tables très utilisées peuvent vous aider à comprendre quelles tables peuvent présenter de nombreuses dépendances et nécessiter une planification supplémentaire pendant le processus de migration.
- Applications
- Les vues "Utilisation des applications" et "Modèles d'applications" fournissent des statistiques sur les applications trouvées lors du traitement des journaux. Ces vues permettent aux utilisateurs de comprendre l'utilisation d'applications spécifiques au fil du temps, ainsi que l'impact sur l'utilisation des ressources. Au cours d'une migration, il est important de visualiser l'ingestion et la consommation des données pour mieux comprendre les dépendances de l'entrepôt de données et pour analyser l'impact du déplacement conjoint de diverses applications dépendantes. La table d'adresses IP peut être utile pour identifier l'application exacte utilisant l'entrepôt de données via des connexions JDBC.
- Requêtes
- La vue "Requêtes" fournit une répartition des types d'instructions SQL exécutés et des statistiques concernant leur utilisation. Vous pouvez utiliser l'histogramme de Type et Durée de Requête pour identifier les périodes où le système est peu utilisé et les heures optimales de transfert des données. Vous pouvez également utiliser cette vue pour identifier les requêtes fréquemment exécutées et les utilisateurs qui appellent ces exécutions.
- Bases de données
- La vue "Bases de données" fournit des métriques sur la taille, les tables, les vues et les procédures définies dans le système d'entrepôt de données source. Cette vue offre un aperçu du volume des objets que vous devez migrer.
- Couplage des bases de données
- La vue "Couplage des bases de données" fournit une vue d'ensemble des bases de données et des tables faisant l'objet d'accès conjoints dans une même requête. Cette vue peut indiquer quelles tables et bases de données sont fréquemment référencées et ce que vous pouvez utiliser pour la planification de la migration.
La section État stable de BigQuery contient les vues suivantes :
- Tables ne présentant aucune utilisation
- La vue "Tables ne présentant aucune utilisation" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune utilisation au cours de la période de journaux analysée. Une absence d'utilisation peut indiquer que vous n'avez pas besoin de transférer cette table vers BigQuery pendant la migration ou que les coûts de stockage les données dans BigQuery peuvent être inférieurs. Vous devez valider la liste des tables inutilisées, car elles pourraient être utilisées en dehors de la période couverte par les journaux, par exemple une table utilisée une seule fois par trimestre ou moins.
- Tables ne présentant pas d'écritures
- La vue "Tables ne présentant pas d'écritures" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune mise à jour au cours de la période de journaux analysée. Une absence d'écritures peut suggérer une opportunité de réduire les coûts de stockage dans BigQuery.
- Requêtes à faible latence
- La vue "Requêtes à faible latence" affiche une distribution des environnements d'exécution de requête en fonction des données de journal analysées. Si le graphique de distribution de la durée des requêtes affiche un grand nombre de requêtes avec un temps d'exécution inférieur à une seconde, envisagez d'autoriser BigQuery BI Engine à accélérer l'informatique décisionnelle et d'autres charges de travail à faible latence.
- Vues matérialisées
- La vue matérialisée fournit des suggestions d'optimisation supplémentaires pour améliorer les performances sur BigQuery.
- Clustering et partitionnement
La vue "Clustering et partitionnement" affiche les tables qui pourraient bénéficier du clustering, du partitionnement ou des deux.
Les suggestions de métadonnées sont obtenues en analysant le schéma de l'entrepôt de données source (comme le partitionnement et la clé primaire dans la table source) et en recherchant l'équivalent BigQuery le plus proche pour obtenir des caractéristiques d'optimisation similaires.
Les suggestions de charges de travail sont obtenues en analysant les journaux des requêtes sources. La recommandation est déterminée en analysant les charges de travail, en particulier les clauses
WHEREouJOINdans les journaux de requêtes analysés.- Recommandation de clustering
La vue "Partitionnement" affiche les tables pouvant avoir plus de 10 000 partitions, en fonction de leur définition de contraintes de partitionnement. Ces tables sont généralement adaptées au clustering BigQuery, ce qui permet des partitions de tables précises.
- Contraintes uniques
La vue "Contraintes uniques" affiche à la fois les tables
SETet les index uniques définis dans l'entrepôt de données source. Dans BigQuery, il est recommandé d'utiliser des tables de préproduction et une instructionMERGEpour insérer uniquement des enregistrements uniques dans une table cible. Utilisez le contenu de cette vue pour déterminer les tables dont vous aurez besoin pour ajuster l'ETL pendant la migration.- Valeurs par défaut / Vérifier les contraintes
Cette vue affiche les tables qui utilisent des contraintes de vérification pour définir des valeurs de colonne par défaut. Dans BigQuery, consultez la section Spécifier les valeurs de colonne par défaut.
La section Processus de migration du rapport contient les vues suivantes :
- Traduction SQL
- La vue "SQL Translation" répertorie le nombre et les détails des requêtes converties automatiquement par l'évaluation de la migration BigQuery, qui ne nécessitent aucune intervention manuelle. L'automatisation de la traduction SQL permet généralement d'atteindre des taux de traduction élevés si des métadonnées sont fournies. Cette vue est interactive et permet d'analyser les requêtes courantes et leur traduction.
- Effort hors connexion
- La vue "Effort hors connexion" capture les domaines qui nécessitent une intervention manuelle, y compris des fonctions définies par l'utilisateur et des cas potentiels de non-respect de la structure et de la syntaxe par des tables ou des colonnes.
- Mots clés réservés de BigQuery
- La vue "Mots clés réservés de BigQuery" affiche l'utilisation détectée des mots clés ayant une signification particulière dans le langage GoogleSQL, qui ne peuvent donc pas être utilisés comme identifiants à moins d'être entourés d'accents graves (
`). - Programmation des mises à jour de la table
- La vue "Programmation des mises à jour de la table" indique quand et à quelle fréquence les tables sont mises à jour pour vous aider à planifier quand et comment les transférer.
- Migration de données vers BigQuery
- La vue "Migration de données vers BigQuery" décrit le chemin de migration avec la durée attendue pour migrer vos données à l'aide du Service de transfert de données BigQuery. Pour en savoir plus, consultez le guide du Service de transfert de données BigQuery pour Teradata.
La section "Annexe" contient les vues suivantes :
- Sensibilité à la casse
- La vue "Sensibilité à la casse" affiche les tables de l'entrepôt de données source configurées pour effectuer des comparaisons non sensibles à la casse. Par défaut, les comparaisons de chaînes dans BigQuery sont sensibles à la casse. Pour en savoir plus, consultez la section Classement.
Redshift
- Caractéristiques de la migration
- La vue "Caractéristiques de la migration" fournit un résumé des trois sections du rapport :
- Le panneau Système existant fournit des informations sur le nombre de bases de données, de schémas, de tables et de la taille totale du système Redshift existant. Il répertorie également les schémas par taille et par utilisation potentielle sous-optimale des ressources. Vous pouvez utiliser ces informations pour optimiser vos données en supprimant, en partitionnant ou en mettant en cluster vos tables.
- Le panneau État de la requête BigQuery fournit des informations sur l'apparence de vos données après la migration sur BigQuery, y compris le nombre de requêtes pouvant être traduites automatiquement à l'aide du service de migration BigQuery. Cette section indique également les coûts de stockage de vos données dans BigQuery en fonction de votre taux d'ingestion de données annuel, ainsi que des suggestions d'optimisation pour les tables, le provisionnement et l'espace.
- Le panneau Chemin de migration fournit des informations sur l'effort de migration lui-même. Pour chaque table, il indique la durée de migration, le nombre de lignes dans la table et la taille attendus.
La section Système existant contient les vues suivantes :
- Requêtes par type et par programmation
- La vue "Requêtes par type et programmation" classe vos requêtes dans les catégories ETL/Écriture et Création de rapports/Agrégation. L'analyse de votre ensemble de requêtes au fil du temps vous aide à comprendre vos modèles d'utilisation existants, et à identifier les pics d'activité et les risques de surprovisionnement, qui peuvent avoir un impact sur les coûts et les performances.
- Mise en file d'attente des requêtes
- La vue "Mise en file d'attente des requêtes" fournit des détails supplémentaires sur la charge du système, y compris le volume de requêtes, la combinaison et les impacts sur les performances liés à la mise en file d'attente, tels que des ressources insuffisantes.
- Requêtes et scaling WLM
- La vue "Requêtes et scaling WLM" identifie le scaling de la simultanéité comme un coût et une complexité de configuration supplémentaires. Elle montre comment votre système Redshift achemine les requêtes en fonction des règles que vous avez spécifiées, ainsi que l'impact sur les performances de la mise en file d'attente, du scaling de simultanéité et des requêtes évincées.
- Mise en file d'attente et temps d'attente
- La vue "Mise en file d'attente et temps d'attente" permettent d'examiner de plus près la file d'attente et les temps d'attente des requêtes au fil du temps.
- Classes et performances WLM
- La vue "Classes et performances WLM" offre la possibilité de mapper vos règles avec BigQuery. Nous vous conseillons toutefois de laisser BigQuery acheminer automatiquement vos requêtes.
- Insights sur le volume de requêtes et de tables
- La vue "Insights sur le volume de requêtes et de tables" répertorie les requêtes selon la taille, la fréquence et les principaux utilisateurs. Cela vous permet de classer les sources de la charge sur le système et de planifier la migration de vos charges de travail.
- Bases de données et schémas
- La vue "Bases de données et schémas" fournit des métriques sur la taille, les tables, les vues et les procédures définies dans le système d'entrepôt de données source. Vous obtenez ainsi des informations sur le volume d'objets à migrer.
- Volume des tables
- La vue "Volume des tables" fournit des statistiques sur les tables et les bases de données les plus volumineuses, ainsi que des informations d'accès. Étant donné que l'extraction de grandes tables depuis le système d'entrepôt de données source peut prendre plus de temps, cette vue peut être utile pour la planification et le séquençage de la migration.
- Utilisation des tables
- La vue "Utilisation des tables" fournit des statistiques sur les tables les plus utilisées dans l'entrepôt de données source. Les tables utilisées de manière intensive peuvent exploiter les tables susceptibles de présenter de nombreuses dépendances et nécessitent une planification supplémentaire pendant le processus de migration.
- Importateurs et exportateurs
- La vue "Importateurs et exportateurs" fournit des informations sur les données et les utilisateurs impliqués dans l'importation de données (à l'aide de requêtes
COPY) et l'exportation de données (à l'aide de requêtesUNLOAD). Cette vue permet d'identifier la couche de préproduction et les processus liés à l'ingestion et aux exportations. - Utilisation des clusters
- La vue "Utilisation des clusters" fournit des informations générales sur tous les clusters disponibles et affiche l'utilisation du processeur pour chaque cluster. Cette vue peut vous aider à comprendre la réserve de capacité du système.
La section État stable de BigQuery contient les vues suivantes :
- Clustering et partitionnement
La vue "Clustering et partitionnement" affiche les tables qui pourraient bénéficier du clustering, du partitionnement ou des deux.
Les suggestions de métadonnées sont obtenues en analysant le schéma de l'entrepôt de données source (comme "Sort Key" et "Dist Key" dans la table source) et en recherchant l'équivalent BigQuery le plus proche pour obtenir des caractéristiques d'optimisation similaires.
Les suggestions de charges de travail sont obtenues en analysant les journaux des requêtes sources. La recommandation est déterminée en analysant les charges de travail, en particulier les clauses
WHEREouJOINdans les journaux de requêtes analysés.En bas de la page, vous trouverez une instruction de création de table traduite avec toutes les optimisations fournies. Toutes les instructions LDD traduites peuvent également être extraites de l'ensemble de données. Les instructions LDD traduites sont stockées dans la table
SchemaConversion, dans la colonneCreateTableDDL.Les recommandations du rapport ne sont fournies que pour les tables de plus d'1 Go, car les petites tables ne bénéficient pas du clustering ni du partitionnement. Toutefois, le LDD pour toutes les tables (y compris les tables de moins de 1 Go) est disponible dans la table
SchemaConversion.- Tables ne présentant aucune utilisation
La vue "Tables ne présentant aucune utilisation" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a identifié aucune utilisation au cours de la période de journaux analysée. Une absence d'utilisation peut indiquer que vous n'avez pas besoin de transférer cette table vers BigQuery pendant la migration ou que les coûts de stockage des données dans BigQuery peuvent être inférieurs (facturés en tant que Stockage à long terme). Il est recommandé de valider la liste des tables inutilisées, car elles pourraient être utilisées en dehors de la période couverte par les journaux, par exemple une table utilisée une seule fois par trimestre ou par semestre.
- Tables ne présentant pas d'écritures
La vue "Tables ne présentant pas d'écritures" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a identifié aucune mise à jour au cours de la période de journaux analysée. Une absence d'écritures peut suggérer une opportunité de réduire les coûts de stockage dans BigQuery (facturés en tant que stockage à long terme).
- BigQuery BI Engine et vues matérialisées
La vue "BI Engine et vues matérialisées" fournit d'autres suggestions d'optimisation pour améliorer les performances sur BigQuery.
La section Chemin de migration contient les vues suivantes :
- Traduction SQL
- La vue "SQL Translation" répertorie le nombre et les détails des requêtes converties automatiquement par l'évaluation de la migration BigQuery, qui ne nécessitent aucune intervention manuelle. L'automatisation de la traduction SQL permet d'atteindre des taux de traduction élevés si des métadonnées sont fournies.
- Effort hors connexion pour la traduction SQL
- La vue "Effort hors connexion pour la traduction SQL" capture les domaines qui nécessitent une intervention manuelle, y compris des fonctions définies par l'utilisateur et des requêtes présentant des ambiguïtés de traduction potentielles.
- Prise en charge des ajouts de modification de table
- La vue "Prise en charge des ajouts de modification de table" affiche des détails sur les constructions SQL Redshift courantes qui n'ont pas d'équivalent BigQuery direct.
- Prise en charge des commandes de copie
- La vue "Prise en charge des commandes de copie" affiche des informations sur les constructions SQL Redshift courantes qui n'ont pas d'équivalent BigQuery direct.
- Avertissements SQL
- La vue "Avertissements SQL" capture les zones qui ont bien été traduites, mais qui nécessitent d'être examinées.
- Non-respects de la structure lexicale et de la syntaxe
- La vue "Non-respects de la structure lexicale et de la syntaxe" affiche les noms des colonnes, tables, fonctions et procédures qui ne respectent pas la Syntaxe BigQuery.
- Mots clés réservés de BigQuery
- La vue "Mots clés réservés de BigQuery" affiche l'utilisation détectée des mots clés ayant une signification particulière dans le langage GoogleSQL, qui ne peuvent donc pas être utilisés comme identifiants à moins d'être entourés d'accents graves (
`). - Couplage des schémas
- La vue "Couplage des schémas" fournit une vue d'ensemble des bases de données, des schémas et des tables accessibles ensemble dans une seule requête. Cette vue peut indiquer quelles tables, schémas et bases de données sont fréquemment référencées et ce que vous pouvez utiliser pour la planification de la migration.
- Programmation des mises à jour de la table
- La vue "Programmation des mises à jour de la table" indique quand et à quelle fréquence les tables sont mises à jour pour vous aider à planifier quand et comment les transférer.
- Échelle de la table
- La vue "Échelle de la table" répertorie vos tables avec le nombre maximal de colonnes.
- Migration de données vers BigQuery
- La vue "Migration de données vers BigQuery" décrit le chemin de migration avec la durée attendue pour migrer vos données à l'aide du Service de transfert de données pour la migration BigQuery. Pour en savoir plus, consultez le guide du Service de transfert de données BigQuery pour Redshift.
- Récapitulatif de l'exécution de l'évaluation
Le récapitulatif de l'exécution de l'évaluation contient l'exhaustivité du rapport, la progression de l'évaluation en cours, ainsi que l'état des fichiers et des erreurs traités.
L'exhaustivité du rapport représente le pourcentage de données traitées avec succès qui sont recommandées pour afficher des insights significatifs dans le rapport d'évaluation. Si les données d'une section spécifique du rapport sont manquantes, ces informations sont indiquées dans le tableau Modules d'évaluation sous l'indicateur Exhaustivité du rapport.
La métrique progression indique le pourcentage de données traitées jusqu'à présent, ainsi que l'estimation du temps restant pour traiter toutes les données. Une fois le traitement terminé, la métrique de progression ne s'affiche plus.
Redshift Serverless
- Caractéristiques de la migration
- Cette page de rapport affiche le récapitulatif des bases de données Amazon Redshift Serverless existantes, y compris leur taille et le nombre de tables. Il fournit également une estimation globale de la valeur annuelle du contrat (ACV, Annual Contract Value), c'est-à-dire le coût du calcul et du stockage dans BigQuery. La vue "Caractéristiques de la migration" fournit un résumé des trois sections du rapport.
La section Système existant contient les vues suivantes :
- Bases de données et schémas
- Fournit une répartition de la taille de stockage totale en Go pour chaque base de données, schéma ou table.
- Bases de données et schémas externes
- Fournit une répartition de la taille de stockage totale en Go pour chaque base de données, schéma ou table externe.
- Utilisation du système
- Fournit des informations générales sur l'utilisation historique du système. Cette vue affiche l'historique de l'utilisation des RPU (Amazon Redshift Processing Units) et la consommation de stockage quotidienne. Cette vue peut vous aider à comprendre la réserve de capacité du système.
La section État de la requête BigQuery fournit des informations sur l'apparence de vos données après la migration sur BigQuery, y compris le nombre de requêtes pouvant être traduites automatiquement à l'aide du service de migration BigQuery. Cette section indique également les coûts de stockage de vos données dans BigQuery en fonction de votre taux d'ingestion de données annuel, ainsi que des suggestions d'optimisation pour les tables, le provisionnement et l'espace. La section "État stable" contient les vues suivantes :
- Comparaison des tarifs d'Amazon Redshift Serverless et de BigQuery
- Compare les modèles de tarification d'Amazon Redshift Serverless et de BigQuery pour vous aider à comprendre les avantages et les économies potentielles après la migration vers BigQuery.
- Coût de calcul BigQuery (coût total de possession)
- : vous permet d'estimer le coût de calcul dans BigQuery. Le calculateur comporte quatre entrées manuelles : l'édition BigQuery, la région, la période d'engagement et la référence. Par défaut, le calculateur fournit des engagements de base optimaux et économiques que vous pouvez remplacer manuellement.
- Coût total de possession
- : vous permet d'estimer la valeur annuelle du contrat (ACV), c'est-à-dire le coût du calcul et du stockage dans BigQuery. Le calculateur vous permet également de calculer le coût de stockage, qui varie pour le stockage actif et le stockage à long terme, en fonction des modifications apportées aux tables au cours de la période analysée. Pour en savoir plus, consultez les tarifs de stockage.
La section Annexe contient la vue suivante :
- Récapitulatif de l'exécution de l'évaluation
- Fournit les détails de l'exécution de l'évaluation, y compris la liste des fichiers traités, les erreurs et l'exhaustivité du rapport. Vous pouvez utiliser cette page pour examiner les données manquantes dans le rapport et mieux comprendre son exhaustivité.
Snowflake
Le rapport se compose de différentes sections qui peuvent être utilisées ensemble ou séparément. Le schéma suivant organise ces sections en trois objectifs utilisateur courants pour vous aider à évaluer vos besoins en matière de migration :
Vues concernant les caractéristiques de la migration
La section Caractéristiques de la migration contient les vues suivantes :
- Modèles tarifaires de Snowflake et de BigQuery
- Liste des tarifs avec différents niveaux/éditions. Présente également comment l'autoscaling BigQuery peut vous aider à réduire davantage les coûts par rapport à l'autoscaling Snowflake.
- Coût total de possession
- Table interactive, qui permet à l'utilisateur de définir les éléments suivants : édition BigQuery, engagement, engagement d'emplacements de base, pourcentage de stockage actif et pourcentage de données chargées ou modifiées. Permet de mieux estimer le coût des cas personnalisés.
- Caractéristiques de la traduction automatique
- Ratio de traduction agrégé, regroupé par utilisateur ou base de données, par ordre croissant ou décroissant. Inclut également le message d'erreur le plus courant en cas d'échec de la traduction automatique.
Vues concernant le système existant
La section Système existant contient les vues suivantes :
- Présentation du système
- La vue "Présentation du système" fournit les métriques de volume de haut niveau des composants clés du système existant pour une période spécifiée. La chronologie évaluée dépend des journaux analysés par l'évaluation de la migration BigQuery. Cette vue offre un aperçu rapide de l'utilisation de l'entrepôt de données source, que vous pouvez utiliser pour planifier la migration.
- Présentation des entrepôts virtuels
- Indique le coût de Snowflake par entrepôt, ainsi que le rescaling basé sur les nœuds au cours de la période.
- Volume des tables
- La vue "Volume des tables" fournit des statistiques sur les plus grandes tables et bases de données trouvées lors de l'évaluation de la migration BigQuery. Étant donné que l'extraction de grandes tables depuis le système d'entrepôt de données source peut prendre plus de temps, cette vue peut être utile pour la planification et le séquençage de la migration.
- Utilisation des tables
- La vue "Utilisation des tables" fournit des statistiques sur les tables les plus utilisées dans l'entrepôt de données source. Les tables très utilisées peuvent vous aider à comprendre quelles tables peuvent présenter de nombreuses dépendances et nécessiter une planification supplémentaire pendant le processus de migration.
- Requêtes
- La vue "Requêtes" fournit une répartition des types d'instructions SQL exécutés et des statistiques concernant leur utilisation. Vous pouvez utiliser l'histogramme "Type de requête" et "Heure de la requête" pour identifier les périodes où le système est peu utilisé et les heures optimales de transfert des données. Vous pouvez également utiliser cette vue pour identifier les requêtes fréquemment exécutées et les utilisateurs qui appellent ces exécutions.
- Bases de données
- La vue "Bases de données" fournit des métriques sur la taille, les tables, les vues et les procédures définies dans le système d'entrepôt de données source. Cette vue fournit des informations sur le volume des objets que vous devez migrer.
Vues sur l'état stable de BigQuery
La section État stable de BigQuery contient les vues suivantes :
- Tables ne présentant aucune utilisation
- La vue "Tables ne présentant aucune utilisation" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune utilisation au cours de la période d'analyse des journaux. Elle peut indiquer les tables qui n'ont pas besoin d'être transférées vers BigQuery pendant la migration ou si les coûts de stockage des données dans BigQuery peuvent être inférieurs. Vous devez valider la liste des tables inutilisées, car elles pourraient être utilisées en dehors de la période d'analyse des journaux (par exemple, une table utilisée une seule fois par trimestre ou moins).
- Tables ne présentant pas d'écritures
- La vue "Tables ne présentant pas d'écritures" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune mise à jour au cours de la période de journaux analysée. Elle peut indiquer si les coûts de stockage des données dans BigQuery peuvent être inférieurs.
Vues concernant le plan de migration
La section Plan de migration du rapport contient les vues suivantes :
- Traduction SQL
- La vue "SQL Translation" répertorie le nombre et les détails des requêtes converties automatiquement par l'évaluation de la migration BigQuery, qui ne nécessitent aucune intervention manuelle. L'automatisation de la traduction SQL permet généralement d'atteindre des taux de traduction élevés si des métadonnées sont fournies. Cette vue est interactive et permet d'analyser les requêtes courantes et leur traduction.
- Effort hors connexion pour la traduction SQL
- La vue "Effort hors connexion" capture les domaines qui nécessitent une intervention manuelle, y compris des fonctions définies par l'utilisateur et des cas potentiels de non-respect de la structure et de la syntaxe par des tables ou des colonnes.
- Avertissements SQL – À examiner
- La vue "Avertissements à examiner" capture les zones qui sont principalement traduites, mais qui nécessitent une inspection humaine.
- Mots clés réservés de BigQuery
- La vue "Mots clés réservés de BigQuery" affiche l'utilisation détectée des mots clés ayant une signification particulière dans le langage GoogleSQL, qui ne peuvent donc pas être utilisés comme identifiants à moins d'être entourés d'accents graves (
`). - Couplage de bases de données et de tables
- La vue "Couplage des bases de données" fournit une vue d'ensemble des bases de données et des tables faisant l'objet d'accès conjoints dans une même requête. Cette vue peut indiquer les tables et bases de données fréquemment référencées, et ce que vous pouvez utiliser pour la planification de la migration.
- Programmation des mises à jour de la table
- La vue "Programmation des mises à jour de la table" indique quand et à quelle fréquence les tables sont mises à jour pour vous aider à planifier quand et comment les transférer.
Vues concernant la démonstration de faisabilité
La section Démonstration de faisabilité contient les vues suivantes :
- Démonstration de faisabilité présentant les économies réalisées avec BigQuery à l'état stable
- Inclut les requêtes les plus fréquentes, les requêtes lisant le plus de données, les requêtes les plus lentes et les tables affectées par ces requêtes.
- Démonstration de faisabilité présentant le plan de migration BigQuery
- Explique comment BigQuery traduit les requêtes les plus complexes et les tables qu'elles concernent.
Oracle
Pour demander des commentaires ou de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-edw-migration-support@google.com.
Caractéristiques de la migration
La section Caractéristiques de la migration contient les vues suivantes :
- Système existant : instantané du système Oracle existant et de son utilisation, y compris le nombre de bases de données, de schémas et de tables, et la taille totale en Go. Il fournit également le récapitulatif de la classification des charges de travail pour chaque base de données afin de vous aider à déterminer si BigQuery est la cible de migration appropriée.
- Compatibilité : fournit des informations sur l'effort de migration à proprement parler. Pour chaque base de données analysée, il indique la durée de migration attendue et le nombre d'objets de base de données qui peuvent être migrés automatiquement à l'aide des outils fournis par Google.
- État stable de BigQuery : contient des informations sur l'apparence de vos données après la migration sur BigQuery, y compris les coûts de stockage de vos données dans BigQuery en fonction de votre taux annuel d'ingestion de données et de l'estimation des coûts de calcul. Il fournit également des informations sur les tables sous-utilisées.
Système existant
La section Système existant contient les vues suivantes :
- Caractéristique des charges de travail : décrit le type de charge de travail pour chaque base de données en fonction des métriques de performances analysées. Chaque base de données est classée comme OLAP, mixte ou OLTP. Ces informations peuvent vous aider à décider quelles bases de données peuvent être migrées vers BigQuery.
- Bases de données et schémas : fournit une répartition de la taille de stockage totale en Go pour chaque base de données, schéma ou table. Vous pouvez également utiliser cette vue pour identifier les vues matérialisées et les tables externes.
- Fonctionnalités et liens de la base de données : affiche la liste des fonctionnalités Oracle utilisées dans votre base de données, ainsi que les fonctionnalités ou services BigQuery équivalents qui peuvent être utilisés après la migration. De plus, vous pouvez explorer les liens vers les bases de données pour mieux comprendre les connexions entre les bases de données.
- Connexions à la base de données : fournit des informations sur les sessions de base de données démarrées par l'utilisateur ou l'application. L'analyse de ces données peut vous aider à identifier les applications externes qui peuvent nécessiter des efforts supplémentaires lors de la migration.
- Types de requêtes : fournit une répartition des types d'instructions SQL exécutés et des statistiques concernant leur utilisation. Vous pouvez utiliser l'histogramme horaire des exécutions de requêtes ou du temps de processeur des requêtes pour identifier les périodes où le système est peu utilisé et les heures optimales de transfert des données.
- Code source PL/SQL : fournit des informations sur les objets PL/SQL, tels que les fonctions ou les procédures, et leur taille pour chaque base de données et chaque schéma. De plus, l'histogramme des exécutions horaires peut être utilisé pour identifier les heures de pointe avec le plus d'exécutions PL/SQL.
- Utilisation du système : fournit des informations générales sur l'historique d'utilisation du système. Cette vue affiche l'utilisation horaire du processeur et la consommation quotidienne de stockage. Cette vue peut vous aider à comprendre la réserve de capacité du système.
État stable de BigQuery
La section État stable de BigQuery contient les vues suivantes :
- Comparaison des tarifs d'Exadata et de BigQuery : fournit une comparaison générale des modèles tarifaires d'Exadata et de BigQuery pour vous aider à comprendre les avantages et les économies potentielles après la migration vers BigQuery.
- Lectures/écritures dans la base de données BigQuery : fournit des insights sur les opérations de disque physique de la base de données. L'analyse de ces données peut vous aider à trouver le meilleur moment pour migrer des données d'Oracle vers BigQuery.
- Coût de calcul BigQuery : vous permet d'estimer le coût de calcul dans BigQuery. Le calculateur comporte quatre entrées manuelles : Édition BigQuery, Région, Période d'engagement et Référence. Par défaut, le calculateur fournit un engagement de référence optimal et économique que vous pouvez remplacer manuellement. La valeur Heures d'emplacements d'autoscaling annuelles indique le nombre d'heures d'emplacements utilisées en dehors de l'engagement. Cette valeur est calculée à l'aide de l'utilisation du système. Une explication visuelle des relations entre la référence, l'autoscaling et l'utilisation est fournie à la fin de la page. Chaque estimation indique le nombre probable et une plage d'estimation.
- Coût total de possession (TCO) : vous permet d'estimer la valeur annuelle du contrat (ACV), c'est-à-dire le coût du calcul et du stockage dans BigQuery. Le simulateur vous permet également de calculer les coûts de stockage. Le calculateur vous permet également de calculer le coût de stockage, qui varie pour le stockage actif et le stockage à long terme, en fonction des modifications apportées aux tables au cours de la période analysée. Pour en savoir plus sur la tarification du stockage, consultez la section Tarifs de stockage.
- Tables sous-utilisées : fournit des informations sur les tables inutilisées et en lecture seule en fonction des métriques d'utilisation de la période analysée. Une absence d'utilisation peut indiquer que vous n'avez pas besoin de transférer la table vers BigQuery lors d'une migration ou que les coûts de stockage des données dans BigQuery peuvent être inférieurs (facturés en tant que stockage à long terme). Nous vous recommandons de valider la liste des tables inutilisées au cas où elles seraient utilisées en dehors de la période analysée.
Conseils de migration
La section Conseils de migration contient les vues suivantes :
- Compatibilité des objets de base de données : fournit un aperçu de la compatibilité des objets de base de données avec BigQuery, y compris le nombre d'objets pouvant être migrés automatiquement avec les outils fournis par Google ou nécessitant une action manuelle. Ces informations sont affichées pour chaque base de données, schéma et type d'objet de base de données.
- Effort de migration des objets de base de données : indique l'estimation de l'effort de migration en heures pour chaque base de données, schéma ou type d'objet de base de données. Il indique également le pourcentage d'objets de petite, moyenne et grande taille en fonction de l'effort de migration.
- Effort de migration du schéma de base de données : fournit la liste de tous les types d'objets de base de données détectés, leur nombre, leur compatibilité avec BigQuery et l'effort de migration estimé en heures.
- Effort de migration du schéma de base de données (détails) : fournit des informations plus approfondies sur l'effort de migration du schéma de base de données, y compris des informations sur chaque objet.
Vues concernant la démonstration de faisabilité
La section Vues de la démonstration de faisabilité contient les vues suivantes :
- Migration de démonstration de faisabilité : affiche la liste suggérée des bases de données dont la migration nécessite le moins d'efforts et qui sont de bons candidats pour la migration initiale. Il affiche également les principales requêtes qui peuvent aider à démontrer les économies de temps et de coûts, ainsi que la valeur de BigQuery à l'aide d'une preuve de concept.
Annexe
La section Annexe contient les vues suivantes :
- Récapitulatif de l'exécution de l'évaluation : fournit des informations détaillées sur l'exécution de l'évaluation, y compris la liste des fichiers traités, les erreurs et l'exhaustivité du rapport. Vous pouvez utiliser cette page pour examiner les données manquantes dans le rapport et mieux comprendre son exhaustivité globale.
Apache Hive
Le rapport se compose de trois parties, précédées d'une page récapitulative comprenant les sections suivantes :
Système existant : Apache Hive Cette section comprend un instantané du système Apache Hive existant et de son utilisation, y compris le nombre de bases de données, de tables, leur taille totale en Go et le nombre de journaux de requêtes traités. Cette section liste également les bases de données par taille et met en avant les contre-performances potentielles au niveau de l'utilisation des ressources (tables ne présentant pas d'écritures ou peu de lectures) et de leur provisionnement. Voici le contenu détaillé de cette section :
- Calcul et requêtes
- Utilisation du processeur :
- Requêtes par heure et par jour avec utilisation du processeur
- Requêtes par type (lecture/écriture)
- Files d'attente et applications
- Superposition de l'utilisation horaire du processeur avec les performances horaires moyennes des requêtes et les performances horaires moyennes des applications
- Histogramme des requêtes par type et par durée des requêtes
- Mise en file d'attente et page d'attente
- Vue détaillée des files d'attente (file d'attente, utilisateur, requêtes uniques, répartition rapports/ETL, par métrique)
- Utilisation du processeur :
- Présentation du stockage
- Bases de données par volume, par vues et par taux d'accès
- Tables avec leurs taux d'accès par utilisateur, par requêtes, par écritures et par créations de tables temporaires
- Files d'attente et applications : taux d'accès et adresses IP des clients
- Calcul et requêtes
État stable de BigQuery. Cette section montre à quoi ressemblera le système sur BigQuery après la migration. Il inclut des suggestions pour optimiser les charges de travail sur BigQuery (et éviter les gaspillages). Voici le contenu détaillé de cette section :
- Tables identifiées en tant que candidates pour les vues matérialisées.
- Candidats à la mise en cluster et au partitionnement en fonction de métadonnées et de l'utilisation.
- Requêtes à faible latence identifiées comme candidates pour BigQuery BI Engine.
- Tables sans utilisation en lecture ou écriture.
- Tables partitionnées avec un décalage des données.
Plan de migration. Cette section fournit des informations sur l'effort de migration à proprement parler. Par exemple, passer du système existant à l'état stable de BigQuery. Cette section contient les cibles de stockage identifiées pour chaque table, les tables identifiées comme importantes pour la migration et le nombre de requêtes qui ont été traduites automatiquement. Voici le contenu détaillé de cette section :
- Vue détaillée avec les requêtes traduites automatiquement
- Nombre total de requêtes avec possibilité de filtrer par utilisateur, application, tables concernées, tables interrogées et type de requête.
- Requêtes effectuées en regroupant les buckets présentant des modèles similaires, ce qui permet aux utilisateurs de voir la philosophie de traduction par type de requête.
- Requêtes nécessitant une intervention humaine
- Requêtes présentant des cas de non-respect de la structure lexicale de BigQuery
- Fonctions et procédures définies par l'utilisateur
- Mots clés réservés de BigQuery
- Requête nécessitant un examen
- Programmations de tables par écritures et lectures (afin de les regrouper pour le déplacement)
- Cible de stockage identifiée pour les tables externes et les tables gérées
- Vue détaillée avec les requêtes traduites automatiquement
La section Système existant - Hive contient les vues suivantes :
- Présentation du système
- Cette vue fournit les métriques de volume de haut niveau des composants clés du système existant pour une période spécifiée. La chronologie évaluée dépend des journaux analysés par l'évaluation de la migration BigQuery. Cette vue offre un aperçu rapide de l'utilisation de l'entrepôt de données source, que vous pouvez utiliser pour planifier la migration.
- Volume des tables
- Cette vue fournit des statistiques sur les plus grandes tables et bases de données trouvées lors de l'évaluation de la migration BigQuery. Étant donné que l'extraction de grandes tables depuis le système d'entrepôt de données source peut prendre plus de temps, cette vue peut être utile pour la planification et le séquençage de la migration.
- Utilisation des tables
- Cette vue fournit des statistiques sur les tables les plus utilisées dans l'entrepôt de données source. Les tables très utilisées peuvent vous aider à comprendre quelles tables peuvent présenter de nombreuses dépendances et nécessiter une planification supplémentaire pendant le processus de migration.
- Utilisation des files d'attente
- Cette vue fournit des statistiques sur l'utilisation des files d'attente YARN trouvées lors du traitement des journaux. Ces vues permettent aux utilisateurs de comprendre l'utilisation de files d'attente et d'applications spécifiques au fil du temps, ainsi que l'impact sur l'utilisation des ressources. Ces vues aident également à identifier et à hiérarchiser les charges de travail pour la migration. Au cours d'une migration, il est important de visualiser l'ingestion et la consommation des données pour mieux comprendre les dépendances de l'entrepôt de données et pour analyser l'impact du déplacement conjoint de diverses applications dépendantes. La table d'adresses IP peut être utile pour identifier l'application exacte utilisant l'entrepôt de données via des connexions JDBC.
- Métriques des files d'attente
- Cette vue fournit une répartition des différentes métriques sur les files d'attente YARN trouvées lors du traitement des journaux. Cette vue permet aux utilisateurs de comprendre les modèles d'utilisation dans des files d'attente spécifiques et l'impact sur la migration. Vous pouvez également utiliser cette vue pour identifier les connexions entre les tables qui ont fait l'objet d'accès dans les requêtes, et les files d'attente dans lesquelles la requête a été exécutée.
- Mise en file d'attente et temps d'attente
- Cette vue fournit des informations sur la durée de mise en file d'attente des requêtes dans l'entrepôt de données source. Les durées de mise en file d'attente indiquent une dégradation des performances en raison du sous-provisionnement, et le provisionnement supplémentaire suppose des coûts de matériel et de maintenance plus élevés.
- Requêtes
- Cette vue fournit une répartition des types d'instructions SQL exécutés et des statistiques concernant leur utilisation. Vous pouvez utiliser l'histogramme de Type et Durée de Requête pour identifier les périodes où le système est peu utilisé et les heures optimales de transfert des données. Vous pouvez également utiliser cette vue pour identifier les moteurs d'exécution Hive les plus utilisés et les requêtes fréquemment exécutées, ainsi que les détails relatifs aux utilisateurs.
- Bases de données
- Cette vue fournit des métriques sur la taille, les tables, les vues et les procédures définies dans le système d'entrepôt de données source. Cette vue offre un aperçu du volume des objets que vous devez migrer.
- Association de bases de données et de tables
- Cette vue fournit une vue d'ensemble des bases de données et des tables faisant l'objet d'accès conjoints dans une même requête. Cette vue peut indiquer quelles tables et bases de données sont fréquemment référencées et ce que vous pouvez utiliser pour la planification de la migration.
La section État stable de BigQuery contient les vues suivantes :
- Tables ne présentant aucune utilisation
- La vue "Tables ne présentant aucune utilisation" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune utilisation au cours de la période de journaux analysée. Une absence d'utilisation peut indiquer que vous n'avez pas besoin de transférer cette table vers BigQuery pendant la migration ou que les coûts de stockage les données dans BigQuery peuvent être inférieurs. Vous devez valider la liste des tables inutilisées, car elles pourraient être utilisées en dehors de la période couverte par les journaux, par exemple une table utilisée une seule fois par trimestre ou par semestre.
- Tables ne présentant pas d'écritures
- La vue "Tables ne présentant pas d'écritures" affiche les tables pour lesquelles l'évaluation de la migration BigQuery n'a trouvé aucune mise à jour au cours de la période de journaux analysée. Une absence d'écritures peut suggérer une opportunité de réduire les coûts de stockage dans BigQuery.
- Recommandations pour le clustering et le partitionnement
Cette vue affiche les tables qui pourraient bénéficier du partitionnement, du clustering ou des deux.
Les suggestions de métadonnées sont obtenues en analysant le schéma de l'entrepôt de données source (comme le partitionnement et la clé primaire dans la table source) et en recherchant l'équivalent BigQuery le plus proche pour obtenir des caractéristiques d'optimisation similaires.
Les suggestions de charges de travail sont obtenues en analysant les journaux des requêtes sources. La recommandation est déterminée en analysant les charges de travail, en particulier les clauses
WHEREouJOINdans les journaux de requêtes analysés.- Partitions converties en clusters
Cette vue affiche les tables comportant plus de 10 000 partitions, en fonction de la définition de leur contrainte de partitionnement. Ces tables sont généralement adaptées au clustering BigQuery, ce qui permet des partitions de tables précises.
- Décalage de partitions
La vue "Décalage de partitions" affiche les tables basées sur l'analyse des métadonnées et qui présentent un décalage des données sur une ou plusieurs partitions. Ces tables conviennent à un changement de schéma, car les requêtes portant sur des partitions ayant subi un décalage peuvent ne pas fonctionner correctement.
- BI Engine et vues matérialisées
La vue "Requêtes à faible latence et vues matérialisées" affiche une distribution des environnements d'exécution de requête en fonction des données de journal analysées et d'autres suggestions d'optimisation pour améliorer les performances sur BigQuery. Si le graphique de distribution de la durée des requêtes affiche un grand nombre de requêtes avec un temps d'exécution inférieur à une seconde, envisagez d'autoriser BI Engine à accélérer l'informatique décisionnelle et d'autres charges de travail à faible latence.
La section Plan de migration du rapport contient les vues suivantes :
- Traduction SQL
- La vue "SQL Translation" répertorie le nombre et les détails des requêtes converties automatiquement par l'évaluation de la migration BigQuery, qui ne nécessitent aucune intervention manuelle. L'automatisation de la traduction SQL permet généralement d'atteindre des taux de traduction élevés si des métadonnées sont fournies. Cette vue est interactive et permet d'analyser les requêtes courantes et leur traduction.
- Effort hors connexion pour la traduction SQL
- La vue "Effort hors connexion" capture les domaines qui nécessitent une intervention manuelle, y compris des fonctions définies par l'utilisateur et des cas potentiels de non-respect de la structure et de la syntaxe par des tables ou des colonnes.
- Avertissements SQL
- La vue "Avertissements SQL" capture les zones qui ont bien été traduites, mais qui nécessitent d'être examinées.
- Mots clés réservés de BigQuery
- La vue "Mots clés réservés de BigQuery" affiche l'utilisation détectée de mots clés ayant une signification particulière dans le langage GoogleSQL.
Ces mots clés ne peuvent être utilisés comme identifiants, sauf s'ils sont délimités par des accents graves (
`). - Programmation des mises à jour de la table
- La vue "Programmation des mises à jour de la table" indique quand et à quelle fréquence les tables sont mises à jour pour vous aider à planifier quand et comment les transférer.
- Tables externes BigLake
- La vue "Tables externes BigLake" décrit les tables identifiées comme des cibles à migrer vers BigLake plutôt que BigQuery.
La section Annexe du rapport contient les vues suivantes :
- Analyse détaillée des efforts de traduction SQL hors connexion
- La vue détaillée "Analyse détaillée des efforts de traduction SQL hors connexion" fournit des insights supplémentaires sur les zones SQL qui nécessitent une intervention manuelle.
- Analyse détaillée des avertissements SQL
- La vue "Analyse détaillée des avertissements SQL" fournit des insights supplémentaires sur les zones SQL qui ont bien été traduites, mais qui nécessitent un examen.
Partager le rapport
Le rapport Looker Studio est un tableau de bord d'interface pour l'évaluation de la migration. Il repose sur les autorisations d'accès aux ensembles de données sous-jacents. Pour partager le rapport, le destinataire doit avoir accès à la fois au rapport Looker Studio lui-même et à l'ensemble de données BigQuery contenant les résultats de l'évaluation.
Lorsque vous ouvrez le rapport depuis la console Google Cloud , il s'affiche en mode aperçu. Pour créer et partager le rapport avec d'autres utilisateurs, procédez comme suit :
- Cliquez sur Modifier et partager. Looker Studio vous invite à associer des connecteurs Looker nouvellement créés au nouveau rapport.
- Cliquez sur Ajouter au rapport. Le rapport reçoit un ID de rapport individuel, que vous pouvez utiliser pour y accéder.
- Pour partager le rapport Looker Studio avec d'autres utilisateurs, suivez les étapes décrites dans la section Partager des rapports avec des lecteurs et des éditeurs.
- Accordez aux utilisateurs l'autorisation d'afficher l'ensemble de données BigQuery utilisé pour exécuter la tâche d'évaluation. Pour en savoir plus, consultez la section Accorder l'accès à un ensemble de données.
Interroger les tables de sortie de l'évaluation de la migration
Bien que les rapports Looker Studio soient le moyen le plus pratique d'afficher les résultats de l'évaluation, vous pouvez également afficher et interroger les données sous-jacentes dans l'ensemble de données BigQuery.
Exemple de requête
L'exemple suivant permet d'obtenir le nombre total de requêtes uniques, le nombre de requêtes dont la traduction a échoué, et le pourcentage de requêtes uniques dont la traduction a échoué.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Partager votre ensemble de données avec des utilisateurs d'autres projets
Après avoir inspecté l'ensemble de données, si vous souhaitez le partager avec un utilisateur qui ne fait pas partie de votre projet, vous pouvez le faire en utilisant le workflow de l'éditeur du partage BigQuery (anciennement Analytics Hub).
Dans la console Google Cloud , accédez à la page BigQuery.
Cliquez sur l'ensemble de données pour afficher ses détails.
Cliquez sur Partage > Publier sous forme de liste.
Dans la boîte de dialogue qui s'ouvre, créez une fiche comme indiqué.
Si vous avez déjà un échange de données, passez l'étape 5.
Créer un échange de données et définir des autorisations Pour autoriser un utilisateur à afficher vos fiches dans cet échange, ajoutez-le à la liste des abonnés.
Saisissez les informations de la fiche.
Le nom à afficher correspond au nom de cette fiche et est obligatoire. Les autres champs sont facultatifs.
Cliquez sur Publier.
Une fiche privée est créée.
Pour votre fiche, sélectionnez Autres actions sous Actions.
Cliquez sur Copier le lien de partage.
Vous pouvez partager le lien avec les utilisateurs qui ont accès à votre plate-forme ou fiche via un abonnement.
Schémas des tables d'évaluation
Pour afficher les tables et leur schéma que l'évaluation de la migration BigQuery écrit dans BigQuery, sélectionnez votre entrepôt de données :
Teradata
AllRIChildren
Le tableau suivant fournit des informations sur l'intégrité référentielle des enfants de la table.
| Colonne | Type | Description |
|---|---|---|
IndexId |
INTEGER |
Numéro de l'index de référence. |
IndexName |
STRING |
Nom de l'index. |
ChildDB |
STRING |
Nom de la base de données à l'origine de la référence, converti en minuscules. |
ChildDBOriginal |
STRING |
Nom de la base de données à l'origine de la référence, avec la casse préservée. |
ChildTable |
STRING |
Nom de la table à l'origine de la référence, converti en minuscules. |
ChildTableOriginal |
STRING |
Nom de la table à l'origine de la référence, avec la casse préservée. |
ChildKeyColumn |
STRING |
Nom d'une colonne dans la clé à l'origine de la référence, converti en minuscules. |
ChildKeyColumnOriginal |
STRING |
Nom d'une colonne dans la clé à l'origine de la référence, avec la casse préservée. |
ParentDB |
STRING |
Nom de la base de données référencée, converti en minuscules. |
ParentDBOriginal |
STRING |
Nom de la base de données référencée, avec la casse préservée. |
ParentTable |
STRING |
Nom de la table référencée, converti en minuscules. |
ParentTableOriginal |
STRING |
Nom de la table référencée, avec la casse préservée. |
ParentKeyColumn |
STRING |
Nom de la colonne dans une clé référencée, converti en minuscules. |
ParentKeyColumnOriginal |
STRING |
Nom de la colonne dans une clé référencée, avec la casse préservée. |
AllRIParents
Le tableau suivant fournit les informations sur l'intégrité référentielle des parents de la table.
| Colonne | Type | Description |
|---|---|---|
IndexId |
INTEGER |
Numéro de l'index de référence. |
IndexName |
STRING |
Nom de l'index. |
ChildDB |
STRING |
Nom de la base de données à l'origine de la référence, converti en minuscules. |
ChildDBOriginal |
STRING |
Nom de la base de données à l'origine de la référence, avec la casse préservée. |
ChildTable |
STRING |
Nom de la table à l'origine de la référence, converti en minuscules. |
ChildTableOriginal |
STRING |
Nom de la table à l'origine de la référence, avec la casse préservée. |
ChildKeyColumn |
STRING |
Nom d'une colonne dans la clé à l'origine de la référence, converti en minuscules. |
ChildKeyColumnOriginal |
STRING |
Nom d'une colonne dans la clé à l'origine de la référence, avec la casse préservée. |
ParentDB |
STRING |
Nom de la base de données référencée, converti en minuscules. |
ParentDBOriginal |
STRING |
Nom de la base de données référencée, avec la casse préservée. |
ParentTable |
STRING |
Nom de la table référencée, converti en minuscules. |
ParentTableOriginal |
STRING |
Nom de la table référencée, avec la casse préservée. |
ParentKeyColumn |
STRING |
Nom de la colonne dans une clé référencée, converti en minuscules. |
ParentKeyColumnOriginal |
STRING |
Nom de la colonne dans une clé référencée, avec la casse préservée. |
Columns
Le tableau suivant fournit des informations sur les colonnes.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, converti en minuscules. |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. |
ColumnName |
STRING |
Nom de la colonne, converti en minuscules. |
ColumnNameOriginal |
STRING |
Nom de la colonne, avec la casse préservée. |
ColumnType |
STRING |
Type BigQuery de la colonne, par exemple STRING. |
OriginalColumnType |
STRING |
Type original de la colonne, par exemple VARCHAR. |
ColumnLength |
INTEGER |
Nombre maximal d'octets de la colonne, par exemple 30 pour VARCHAR(30). |
DefaultValue |
STRING |
Valeur par défaut, le cas échéant. |
Nullable |
BOOLEAN |
Indique si la colonne peut avoir une valeur nulle. |
DiskSpace
Le tableau suivant fournit des informations sur l'utilisation de l'espace disque pour chaque base de données.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
MaxPerm |
INTEGER |
Nombre maximal d'octets alloués à l'espace permanent. |
MaxSpool |
INTEGER |
Nombre maximal d'octets alloués à l'espace de spool. |
MaxTemp |
INTEGER |
Nombre maximal d'octets alloués à l'espace temporaire. |
CurrentPerm |
INTEGER |
Nombre d'octets alloués à l'espace permanent. |
CurrentSpool |
INTEGER |
Nombre d'octets alloués à l'espace de spool. |
CurrentTemp |
INTEGER |
Nombre d'octets alloués à l'espace temporaire. |
PeakPerm |
INTEGER |
Nombre maximal d'octets utilisés depuis la dernière réinitialisation pour l'espace permanent. |
PeakSpool |
INTEGER |
Nombre maximal d'octets utilisés depuis la dernière réinitialisation pour l'espace de spool. |
PeakPersistentSpool |
INTEGER |
Nombre maximal d'octets utilisés depuis la dernière réinitialisation pour l'espace persistant. |
PeakTemp |
INTEGER |
Nombre maximal d'octets utilisés depuis la dernière réinitialisation pour l'espace temporaire. |
MaxProfileSpool |
INTEGER |
Limite d'espace de spool pour l'utilisateur. |
MaxProfileTemp |
INTEGER |
Limite de l'espace temporaire pour l'utilisateur. |
AllocatedPerm |
INTEGER |
Allocation actuelle de l'espace permanent. |
AllocatedSpool |
INTEGER |
Allocation actuelle de l'espace de spool. |
AllocatedTemp |
INTEGER |
Allocation actuelle de l'espace temporaire. |
Functions
Le tableau suivant fournit des informations sur les fonctions.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
FunctionName |
STRING |
Nom de la fonction. |
LanguageName |
STRING |
Nom de la langue. |
Indices
Le tableau suivant fournit des informations sur les index.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, converti en minuscules. |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. |
IndexName |
STRING |
Nom de l'index. |
ColumnName |
STRING |
Nom de la colonne, converti en minuscules. |
ColumnNameOriginal |
STRING |
Nom de la colonne, avec la casse préservée. |
OrdinalPosition |
INTEGER |
Position de la colonne. |
UniqueFlag |
BOOLEAN |
Indique si l'index applique l'unicité. |
Queries
Le tableau suivant fournit des informations sur les requêtes extraites.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
QueryText |
STRING |
Texte de la requête. |
QueryLogs
Le tableau suivant fournit quelques statistiques d'exécution sur les requêtes extraites.
| Colonne | Type | Description |
|---|---|---|
QueryText |
STRING |
Texte de la requête. |
QueryHash |
STRING |
Hachage de la requête. |
QueryId |
STRING |
ID de la requête. |
QueryType |
STRING |
Type de la requête, Query ou LDD. |
UserId |
BYTES |
ID de l'utilisateur qui a exécuté la requête. |
UserName |
STRING |
Nom de l'utilisateur qui a exécuté la requête. |
StartTime |
TIMESTAMP |
Horodatage au moment de l'envoi de la requête. |
Duration |
STRING |
Durée de la requête en millisecondes. |
AppId |
STRING |
ID de l'application qui a exécuté la requête. |
ProxyUser |
STRING |
Utilisateur du proxy lorsqu'il est utilisé via un niveau intermédiaire. |
ProxyRole |
STRING |
Rôle du proxy lorsqu'il est utilisé via un niveau intermédiaire. |
QueryTypeStatistics
Le tableau suivant fournit des statistiques sur les types de requêtes.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
QueryType |
STRING |
Type de la requête. |
UpdatedTable |
STRING |
Table mise à jour par la requête, le cas échéant. |
QueriedTables |
ARRAY<STRING> |
Liste des tables interrogées. |
ResUsageScpu
Le tableau suivant fournit des informations sur l'utilisation de la ressource de processeur.
| Colonne | Type | Description |
|---|---|---|
EventTime |
TIMESTAMP |
Heure de l'événement. |
NodeId |
INTEGER |
Identifiant du nœud |
CabinetId |
INTEGER |
Numéro de l'armoire physique du nœud. |
ModuleId |
INTEGER |
Numéro du module physique du nœud. |
NodeType |
STRING |
Type de nœud. |
CpuId |
INTEGER |
ID du processeur dans ce nœud. |
MeasurementPeriod |
INTEGER |
Période de la mesure, exprimée en centisecondes. |
SummaryFlag |
STRING |
S – ligne récapitulative, N – ligne non récapitulative |
CpuFrequency |
FLOAT |
Fréquence du CPU en MHz. |
CpuIdle |
FLOAT |
Temps d'inactivité du CPU, exprimé en centisecondes. |
CpuIoWait |
FLOAT |
Temps d'attente du CPU pour les E/S, exprimé en centisecondes. |
CpuUServ |
FLOAT |
Temps d'exécution de code utilisateur par le CPU, exprimé en centisecondes. |
CpuUExec |
FLOAT |
Temps d'exécution de code de service par le CPU, exprimé en centisecondes. |
Roles
Le tableau suivant fournit des informations sur les rôles.
| Colonne | Type | Description |
|---|---|---|
RoleName |
STRING |
Nom du rôle. |
Grantor |
STRING |
Nom de la base de données ayant attribué le rôle. |
Grantee |
STRING |
Utilisateur disposant du rôle. |
WhenGranted |
TIMESTAMP |
Date d'attribution du rôle. |
WithAdmin |
BOOLEAN |
Est l'option Administrateur définie pour le rôle accordé. |
Conversion de schéma
Cette table fournit des informations sur les conversions de schéma liées au clustering et au partitionnement.
| Nom de la colonne | Type de colonne | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données source pour laquelle la suggestion est effectuée. Une base de données est mappée sur un ensemble de données dans BigQuery. |
TableName |
STRING |
Nom de la table pour laquelle la suggestion est effectuée. |
PartitioningColumnName |
STRING |
Nom de la colonne de partitionnement suggérée dans BigQuery. |
ClusteringColumnNames |
ARRAY |
Noms des colonnes de clustering suggérées dans BigQuery. |
CreateTableDDL |
STRING |
Instruction CREATE TABLE statement permettant de créer la table dans BigQuery. |
TableInfo
Le tableau suivant fournit des informations sur les tables.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, converti en minuscules. |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. |
LastAccessTimestamp |
TIMESTAMP |
Date de la dernière utilisation de la table. |
LastAlterTimestamp |
TIMESTAMP |
Date de la dernière modification de la table. |
TableKind |
STRING |
Type de table. |
TableRelations
Le tableau suivant fournit des informations sur les tables.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête qui a établi la relation. |
DatabaseName1 |
STRING |
Nom de la première base de données. |
TableName1 |
STRING |
Nom de la première table. |
DatabaseName2 |
STRING |
Nom de la deuxième base de données. |
TableName2 |
STRING |
Nom de la deuxième table. |
Relation |
STRING |
Type de relation entre les deux tables. |
TableSizes
Le tableau suivant fournit des informations sur les tailles des tables.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, converti en minuscules. |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. |
TableSizeInBytes |
INTEGER |
Taille de la table en octets. |
Users
Le tableau suivant fournit des informations sur les utilisateurs.
| Colonne | Type | Description |
|---|---|---|
UserName |
STRING |
Nom de l'utilisateur. |
CreatorName |
STRING |
Nom de l'entité qui a créé cet utilisateur. |
CreateTimestamp |
TIMESTAMP |
Horodatage de la création de cet utilisateur. |
LastAccessTimestamp |
TIMESTAMP |
Horodatage de la dernière connexion de cet utilisateur à une base de données. |
Redshift
Columns
La table Columns provient de l'une des tables suivantes : SVV_COLUMNS, INFORMATION_SCHEMA.COLUMNS ou PG_TABLE_DEF, classées par ordre de priorité. L'outil tente d'abord de charger les données de la table ayant la priorité la plus élevée. Si cette opération échoue, il tente de charger les données de la table de priorité suivante. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift ou PostgreSQL.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données. |
SchemaName |
STRING |
Nom du schéma. |
TableName |
STRING |
Nom de la table. |
ColumnName |
STRING |
Nom de la colonne. |
DefaultValue |
STRING |
Valeur par défaut si disponible. |
Nullable |
BOOLEAN |
Indique si une colonne peut avoir une valeur nulle. |
ColumnType |
STRING |
Type de la colonne, par exemple VARCHAR. |
ColumnLength |
INTEGER |
Taille de la colonne, par exemple 30 pour une valeur VARCHAR(30). |
CreateAndDropStatistic
Cette table fournit des informations sur la création et la suppression de tables.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
DefaultDatabase |
STRING |
Base de données par défaut. |
EntityType |
STRING |
Type de l'entité (par exemple, TABLE). |
EntityName |
STRING |
Nom de l'entité. |
Operation |
STRING |
L'opération : CREATE ou DROP. |
Databases
Cette table provient directement de la table PG_DATABASE_INFO d'Amazon Redshift. Les noms de champs d'origine de la table PG sont inclus dans les descriptions. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift et PostgreSQL.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données. Nom de la source : datname |
Owner |
STRING |
Propriétaire de la base de données. Par exemple, l'utilisateur qui a créé la base de données. Nom de la source : datdba |
ExternalColumns
Cette table contient directement les informations de la table SVV_EXTERNAL_COLUMNS d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
SchemaName |
STRING |
Nom du schéma externe. |
TableName |
STRING |
Nom de la table externe. |
ColumnName |
STRING |
Nom de la colonne externe. |
ColumnType |
STRING |
Type de la colonne. |
Nullable |
BOOLEAN |
Indique si une colonne peut avoir une valeur nulle. |
ExternalDatabases
Cette table contient directement les informations de la table SVV_EXTERNAL_DATABASES d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données externe. |
Location |
STRING |
Emplacement de la base de données. |
ExternalPartitions
Cette table contient directement les informations de la table SVV_EXTERNAL_PARTITIONS d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
SchemaName |
STRING |
Nom du schéma externe. |
TableName |
STRING |
Nom de la table externe. |
Location |
STRING |
Emplacement de la partition. La taille des colonnes est limitée à 128 caractères. Les valeurs plus longues sont tronquées. |
ExternalSchemas
Cette table contient directement les informations de la table SVV_EXTERNAL_SCHEMAS d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
SchemaName |
STRING |
Nom du schéma externe. |
DatabaseName |
STRING |
Nom de la base de données externe. |
ExternalTables
Cette table contient directement les informations de la table SVV_EXTERNAL_TABLES d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
SchemaName |
STRING |
Nom du schéma externe. |
TableName |
STRING |
Nom de la table externe. |
Functions
Cette table contient directement les informations de la table PG_PROC d'Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift et PostgreSQL.
| Colonne | Type | Description |
|---|---|---|
SchemaName |
STRING |
Nom du schéma. |
FunctionName |
STRING |
Nom de la fonction. |
LanguageName |
STRING |
Langage d'implémentation ou interface d'appel de cette fonction. |
Queries
Cette table est générée à l'aide des informations de la table QueryLogs. Contrairement à la table QueryLogs, chaque ligne de la table Queries ne contient qu'une seule instruction de requête, stockée dans la colonne QueryText. Cette table fournit les données sources permettant de générer les tables de statistiques et les résultats de traduction.
| Colonne | Type | Description |
|---|---|---|
QueryText |
STRING |
Texte de la requête. |
QueryHash |
STRING |
Hachage de la requête. |
QueryLogs
Cette table fournit des informations sur l'exécution des requêtes.
| Colonne | Type | Description |
|---|---|---|
QueryText |
STRING |
Texte de la requête. |
QueryHash |
STRING |
Hachage de la requête. |
QueryID |
STRING |
ID de la requête. |
UserID |
STRING |
ID de l'utilisateur. |
StartTime |
TIMESTAMP |
Heure de début. |
Duration |
INTEGER |
Durée, en millisecondes. |
QueryTypeStatistics
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
DefaultDatabase |
STRING |
Base de données par défaut. |
QueryType |
STRING |
Type de la requête. |
UpdatedTable |
STRING |
Table mise à jour. |
QueriedTables |
ARRAY<STRING> |
Tables interrogées. |
TableInfo
Cette table contient des informations extraites de la table SVV_TABLE_INFO dans Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données. |
SchemaName |
STRING |
Nom du schéma. |
TableId |
INTEGER |
ID de la table. |
TableName |
STRING |
Nom de la table. |
SortKey1 |
STRING |
Première colonne de la clé de tri. |
SortKeyNum |
INTEGER |
Nombre de colonnes définies en tant que clés de tri. |
MaxVarchar |
INTEGER |
Taille de la plus grande colonne utilisant un type de données VARCHAR. |
Size |
INTEGER |
Taille de la table, en blocs de données de 1 Mo. |
TblRows |
INTEGER |
Nombre de lignes dans la table. |
TableRelations
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête qui a établi la relation (par exemple, une requête JOIN). |
DefaultDatabase |
STRING |
Base de données par défaut. |
TableName1 |
STRING |
Première table de la relation. |
TableName2 |
STRING |
Deuxième table de la relation. |
Relation |
STRING |
Type de relation. Prend l'une des valeurs suivantes : COMMA_JOIN, CROSS_JOIN, FULL_OUTER_JOIN, INNER_JOIN, LEFT_OUTER_JOIN, RIGHT_OUTER_JOIN, CREATED_FROM ou INSERT_INTO. |
Count |
INTEGER |
Fréquence à laquelle cette relation a été observée. |
TableSizes
Cette table fournit des informations sur les tailles des tables.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données. |
SchemaName |
STRING |
Nom du schéma. |
TableName |
STRING |
Nom de la table. |
TableSizeInBytes |
INTEGER |
Taille de la table en octets. |
Tables
Cette table contient des informations extraites de la table SVV_TABLES dans Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation Amazon Redshift.
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données. |
SchemaName |
STRING |
Nom du schéma. |
TableName |
STRING |
Nom de la table. |
TableType |
STRING |
Type de table. |
TranslatedQueries
Cette table fournit des traductions de requête.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
TranslatedQueryText |
STRING |
Résultat de la traduction du dialecte source vers GoogleSQL. |
TranslationErrors
Cette table fournit des informations sur les erreurs de traduction de requête.
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
Severity |
STRING |
Niveau de gravité de l'erreur, par exemple ERROR. |
Category |
STRING |
Catégorie de l'erreur, par exemple AttributeNotFound. |
Message |
STRING |
Message avec les détails de l'erreur. |
LocationOffset |
INTEGER |
Position du caractère de l'emplacement de l'erreur. |
LocationLine |
INTEGER |
Numéro de ligne de l'erreur. |
LocationColumn |
INTEGER |
Numéro de colonne de l'erreur. |
LocationLength |
INTEGER |
Longueur du caractère de l'emplacement de l'erreur. |
UserTableRelations
| Colonne | Type | Description |
|---|---|---|
UserID |
STRING |
ID utilisateur. |
TableName |
STRING |
Nom de la table. |
Relation |
STRING |
Relation. |
Count |
INTEGER |
Nombre. |
Users
Cette table contient des informations extraites de la table PG_USER dans Amazon Redshift. Pour en savoir plus sur le schéma et l'utilisation, consultez la documentation PostgreSQL.
| Colonne | Type | Description | |
|---|---|---|---|
UserName |
STRING |
Nom de l'utilisateur. | |
UserId |
STRING |
ID utilisateur. |
Snowflake
Warehouses
| Colonne | Type | Description | Présence |
|---|---|---|---|
WarehouseName |
STRING |
Nom de l'entrepôt. | Always |
State |
STRING |
État de l'entrepôt. Valeurs possibles : STARTED, SUSPENDED, RESIZING. |
Always |
Type |
STRING |
Type d'entrepôt. Valeurs possibles : STANDARD, SNOWPARK-OPTIMIZED. |
Always |
Size |
STRING |
Taille de l'entrepôt. Valeurs possibles : X-Small, Small, Medium, Large, X-Large, 2X-Large ... 6X-Large. |
Always |
Databases
| Colonne | Type | Description | Présence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. | Always |
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. | Always |
Schemata
| Colonne | Type | Description | Présence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nom de la base de données à laquelle appartient le schéma, avec la casse préservée. | Always |
DatabaseName |
STRING |
Nom de la base de données à laquelle appartient le schéma, converti en minuscules. | Always |
SchemaNameOriginal |
STRING |
Nom du schéma, avec la casse préservée. | Always |
SchemaName |
STRING |
Nom du schéma, converti en minuscules. | Always |
Tables
| Colonne | Type | Description | Présence |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
Nom de la base de données à laquelle la table appartient, avec la casse préservée. | Always |
DatabaseName |
STRING |
Nom de la base de données à laquelle la table appartient, converti en minuscules. | Always |
SchemaNameOriginal |
STRING |
Nom du schéma auquel la table appartient, avec la casse préservée. | Always |
SchemaName |
STRING |
Nom du schéma auquel la table appartient, converti en minuscules. | Always |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. | Always |
TableName |
STRING |
Nom de la table, converti en minuscules. | Always |
TableType |
STRING |
Type de la table (vue/vue matérialisée/table de base). | Always |
RowCount |
BIGNUMERIC |
Nombre de lignes dans la table. | Always |
Columns
| Colonne | Type | Description | Présence |
|---|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, converti en minuscules. | Always |
DatabaseNameOriginal |
STRING |
Nom de la base de données, avec la casse préservée. | Always |
SchemaName |
STRING |
Nom du schéma, converti en minuscules. | Always |
SchemaNameOriginal |
STRING |
Nom du schéma, avec la casse préservée. | Always |
TableName |
STRING |
Nom de la table, converti en minuscules. | Always |
TableNameOriginal |
STRING |
Nom de la table, avec la casse préservée. | Always |
ColumnName |
STRING |
Nom de la colonne, converti en minuscules. | Always |
ColumnNameOriginal |
STRING |
Nom de la colonne, avec la casse préservée. | Always |
ColumnType |
STRING |
Type de la colonne. | Always |
CreateAndDropStatistics
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryHash |
STRING |
Hachage de la requête. | Always |
DefaultDatabase |
STRING |
Base de données par défaut. | Always |
EntityType |
STRING |
Type de l'entité (par exemple, TABLE). |
Always |
EntityName |
STRING |
Nom de l'entité. | Always |
Operation |
STRING |
Opération : CREATE ou DROP. |
Always |
Queries
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryText |
STRING |
Texte de la requête. | Always |
QueryHash |
STRING |
Hachage de la requête. | Always |
QueryLogs
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryText |
STRING |
Texte de la requête. | Always |
QueryHash |
STRING |
Hachage de la requête. | Always |
QueryID |
STRING |
ID de la requête. | Always |
UserID |
STRING |
ID de l'utilisateur. | Always |
StartTime |
TIMESTAMP |
Heure de début. | Always |
Duration |
INTEGER |
Durée, en millisecondes. | Always |
QueryTypeStatistics
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryHash |
STRING |
Hachage de la requête. | Always |
DefaultDatabase |
STRING |
Base de données par défaut. | Always |
QueryType |
STRING |
Type de la requête. | Always |
UpdatedTable |
STRING |
Table mise à jour. | Always |
QueriedTables |
REPEATED STRING |
Tables interrogées. | Always |
TableRelations
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryHash |
STRING |
Hachage de la requête qui a établi la relation (par exemple, une requête JOIN). |
Always |
DefaultDatabase |
STRING |
Base de données par défaut. | Always |
TableName1 |
STRING |
Première table de la relation. | Always |
TableName2 |
STRING |
Deuxième table de la relation. | Always |
Relation |
STRING |
Type de relation. | Always |
Count |
INTEGER |
Fréquence à laquelle cette relation a été observée. | Always |
TranslatedQueries
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryHash |
STRING |
Hachage de la requête. | Always |
TranslatedQueryText |
STRING |
Résultat de la traduction du dialecte source vers BigQuery SQL. | Always |
TranslationErrors
| Colonne | Type | Description | Présence |
|---|---|---|---|
QueryHash |
STRING |
Hachage de la requête. | Always |
Severity |
STRING |
Niveau de gravité de l'erreur (par exemple, ERROR). |
Always |
Category |
STRING |
Catégorie de l'erreur (par exemple, AttributeNotFound). |
Always |
Message |
STRING |
Message avec les détails de l'erreur. | Always |
LocationOffset |
INTEGER |
Position du caractère de l'emplacement de l'erreur. | Always |
LocationLine |
INTEGER |
Numéro de ligne de l'erreur. | Always |
LocationColumn |
INTEGER |
Numéro de colonne de l'erreur. | Always |
LocationLength |
INTEGER |
Longueur du caractère de l'emplacement de l'erreur. | Always |
UserTableRelations
| Colonne | Type | Description | Présence |
|---|---|---|---|
UserID |
STRING |
L'ID utilisateur | Always |
TableName |
STRING |
Nom de la table. | Always |
Relation |
STRING |
Relation. | Always |
Count |
INTEGER |
Nombre. | Toujours |
Apache Hive
Columns
Cette table fournit des informations sur les colonnes :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, avec la casse préservée. |
ColumnName |
STRING |
Nom de la colonne, avec la casse préservée. |
ColumnType |
STRING |
Type BigQuery de la colonne, par exemple STRING. |
OriginalColumnType |
STRING |
Type original de la colonne, par exemple VARCHAR. |
CreateAndDropStatistic
Cette table fournit des informations sur la création et la suppression de tables :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
DefaultDatabase |
STRING |
Base de données par défaut. |
EntityType |
STRING |
Type de l'entité, par exemple, TABLE. |
EntityName |
STRING |
Nom de l'entité. |
Operation |
STRING |
Opération effectuée sur la table (CREATE ou DROP). |
Databases
Cette table fournit des informations sur les bases de données :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
Owner |
STRING |
Propriétaire de la base de données. Par exemple, l'utilisateur qui a créé la base de données. |
Location |
STRING |
Emplacement de la base de données dans le système de fichiers. |
Functions
Cette table fournit des informations sur les fonctions :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
FunctionName |
STRING |
Nom de la fonction. |
LanguageName |
STRING |
Nom de la langue. |
ClassName |
STRING |
Nom de classe de la fonction. |
ObjectReferences
Cette table fournit des informations sur les objets référencés dans les requêtes :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
DefaultDatabase |
STRING |
Base de données par défaut. |
Clause |
STRING |
Clause dans laquelle l'objet apparaît. Par exemple, SELECT. |
ObjectName |
STRING |
Nom de l'objet. |
Type |
STRING |
Type de l'objet. |
Subtype |
STRING |
Sous-type de l'objet. |
PartitionKeys
Cette table fournit des informations sur les clés de partitionnement :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, avec la casse préservée. |
ColumnName |
STRING |
Nom de la colonne, avec la casse préservée. |
ColumnType |
STRING |
Type BigQuery de la colonne, par exemple STRING. |
Partitions
Cette table fournit des informations sur les partitions des tables :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, avec la casse préservée. |
PartitionName |
STRING |
Nom de la partition. |
CreateTimestamp |
TIMESTAMP |
Horodatage de la création de cette partition. |
LastAccessTimestamp |
TIMESTAMP |
Horodatage du dernier accès à cette partition. |
LastDdlTimestamp |
TIMESTAMP |
Horodatage de la dernière modification de cette partition. |
TotalSize |
INTEGER |
Taille compressée de la partition en octets. |
Queries
Cette table est générée à l'aide des informations de la table QueryLogs. Contrairement à la table QueryLogs, chaque ligne de la table Queries ne contient qu'une seule instruction de requête, stockée dans la colonne QueryText. Cette table fournit les données sources permettant de générer les tables de statistiques et les résultats de traduction :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
QueryText |
STRING |
Texte de la requête. |
QueryLogs
Cette table fournit quelques statistiques d'exécution sur les requêtes extraites :
| Colonne | Type | Description |
|---|---|---|
QueryText |
STRING |
Texte de la requête. |
QueryHash |
STRING |
Hachage de la requête. |
QueryId |
STRING |
ID de la requête. |
QueryType |
STRING |
Type de la requête, Query ou DDL. |
UserName |
STRING |
Nom de l'utilisateur qui a exécuté la requête. |
StartTime |
TIMESTAMP |
Horodatage de l'envoi de la requête. |
Duration |
STRING |
Durée de la requête en millisecondes. |
QueryTypeStatistics
Cette table fournit des statistiques sur les types de requêtes :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
QueryType |
STRING |
Type de la requête. |
UpdatedTable |
STRING |
Table mise à jour par la requête, le cas échéant. |
QueriedTables |
ARRAY<STRING> |
Liste des tables interrogées. |
QueryTypes
Cette table fournit des statistiques sur les types de requêtes :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
Category |
STRING |
Catégorie de la requête. |
Type |
STRING |
Type de la requête. |
Subtype |
STRING |
Sous-type de la requête. |
Conversion de schéma
Cette table fournit des informations sur les conversions de schéma liées au clustering et au partitionnement :
| Nom de la colonne | Type de colonne | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données source pour laquelle la suggestion est effectuée. Une base de données est mappée sur un ensemble de données dans BigQuery. |
TableName |
STRING |
Nom de la table pour laquelle la suggestion est effectuée. |
PartitioningColumnName |
STRING |
Nom de la colonne de partitionnement suggérée dans BigQuery. |
ClusteringColumnNames |
ARRAY |
Noms des colonnes de clustering suggérées dans BigQuery. |
CreateTableDDL |
STRING |
Instruction CREATE TABLE statement permettant de créer la table dans BigQuery. |
TableRelations
Cette table fournit des informations sur les tables :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête qui a établi la relation. |
DatabaseName1 |
STRING |
Nom de la première base de données. |
TableName1 |
STRING |
Nom de la première table. |
DatabaseName2 |
STRING |
Nom de la deuxième base de données. |
TableName2 |
STRING |
Nom de la deuxième table. |
Relation |
STRING |
Type de relation entre les deux tables. |
TableSizes
Cette table fournit des informations sur la taille des tables :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, avec la casse préservée. |
TotalSize |
INTEGER |
Taille de la table en octets. |
Tables
Cette table fournit des informations sur les tables :
| Colonne | Type | Description |
|---|---|---|
DatabaseName |
STRING |
Nom de la base de données, avec la casse préservée. |
TableName |
STRING |
Nom de la table, avec la casse préservée. |
Type |
STRING |
Type de table. |
TranslatedQueries
Cette table fournit des traductions de requête :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
TranslatedQueryText |
STRING |
Résultat de la traduction du dialecte source en langage GoogleSQL. |
TranslationErrors
Cette table fournit des informations sur les erreurs de traduction de requête :
| Colonne | Type | Description |
|---|---|---|
QueryHash |
STRING |
Hachage de la requête. |
Severity |
STRING |
Niveau de gravité de l'erreur, par exemple ERROR. |
Category |
STRING |
Catégorie de l'erreur, par exemple AttributeNotFound. |
Message |
STRING |
Message avec les détails de l'erreur. |
LocationOffset |
INTEGER |
Position du caractère de l'emplacement de l'erreur. |
LocationLine |
INTEGER |
Numéro de ligne de l'erreur. |
LocationColumn |
INTEGER |
Numéro de colonne de l'erreur. |
LocationLength |
INTEGER |
Longueur du caractère de l'emplacement de l'erreur. |
UserTableRelations
| Colonne | Type | Description |
|---|---|---|
UserID |
STRING |
ID utilisateur. |
TableName |
STRING |
Nom de la table. |
Relation |
STRING |
Relation. |
Count |
INTEGER |
Nombre. |
Dépannage
Cette section décrit certains problèmes courants et des techniques de dépannage permettant de migrer votre entrepôt de données vers BigQuery.
Erreurs de l'outil dwh-migration-dumper
Pour résoudre les erreurs et les avertissements dans la sortie du terminal de l'outil dwh-migration-dumper survenues lors de l'extraction des métadonnées ou des journaux de requête, consultez la page Résoudre les problèmes liés aux métadonnées.
Erreurs de migration Hive
Cette section décrit les problèmes courants que vous pouvez rencontrer lorsque vous envisagez de migrer votre entrepôt de données de Hive vers BigQuery.
Le hook de journalisation écrit les messages de débogage dans vos journaux hive-server2. Si vous rencontrez des problèmes, consultez les journaux de débogage du hook de journalisation qui contient la chaîne MigrationAssessmentLoggingHook.
Gérer l'erreur ClassNotFoundException.
L'erreur peut être due à une localisation incorrecte du fichier JAR du hook de journalisation. Assurez-vous d'avoir ajouté le fichier JAR dans le dossier auxlib sur le cluster Hive. Vous pouvez également spécifier le chemin d'accès complet au fichier JAR dans la propriété hive.aux.jars.path, par exemple, file://.
Les sous-dossiers n'apparaissent pas dans le dossier configuré
Ce problème peut être dû à une mauvaise configuration ou à des problèmes lors de l'initialisation du hook de journalisation.
Recherchez, parmi vos journaux de débogage hive-server2, les messages suivants du hook de journalisation :
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Examinez les détails du problème et vérifiez si vous devez corriger certains points.
Les fichiers n'apparaissent pas dans le dossier
Ce problème peut être dû à des problèmes rencontrés lors du traitement d'un événement ou lors d'une opération d'écriture dans un fichier.
Recherchez, parmi vos journaux de débogage hive-server2, les messages suivants du hook de journalisation :
Failed to close writer for file
Got exception while processing event
Error writing record for query
Examinez les détails du problème et vérifiez si vous devez corriger certains points.
Il manque certains événements de requête
Ce problème peut être causé par le débordement de la file d'attente des threads du hook de journalisation.
Recherchez, parmi vos journaux de débogage hive-server2, le message suivant du hook de journalisation :
Writer queue is full. Ignoring event
Si vous trouvez de tels messages, envisagez d'augmenter le paramètre dwhassessment.hook.queue.capacity.
Étapes suivantes
Pour en savoir plus sur l'outil dwh-migration-dumper, consultez la page dwh-migration-tools.
Vous pouvez également en apprendre plus sur les étapes suivantes dans la migration d'entrepôts de données :
- Présentation de la migration
- Présentation du transfert de schéma et de données
- Pipelines de données
- Traduction SQL par lot
- Traduction SQL interactive
- Sécurité et gouvernance des données
- Outil de validation des données