Evaluación de la migración
La evaluación de la migración de BigQuery te permite planificar y revisar la migración de tu almacén de datos existente en BigQuery. Puedes ejecutar la evaluación de migración de BigQuery a fin de generar un informe para evaluar el costo de almacenamiento de tus datos en BigQuery, ver cómo BigQuery puede optimizar tu carga de trabajo existente en función del ahorro de costos y preparar un plan de migración en el que se describa el tiempo y el esfuerzo necesarios para completar la migración de tu almacén de datos a BigQuery.
En este documento, se describe cómo usar la evaluación de migración de BigQuery y las diferentes formas en que puedes revisar los resultados de la evaluación. Este documento está dirigido a usuarios que estén familiarizados con la consola deGoogle Cloud y el traductor de SQL por lotes.
Antes de comenzar
Para preparar y ejecutar una evaluación de migración de BigQuery, sigue estos pasos:
Extrae metadatos y registros de consultas de tu almacén de datos con la herramienta
dwh-migration-dumper.Sube tus registros de consultas y metadatos a tu bucket de Cloud Storage.
Opcional: Consulta los resultados de la evaluación para encontrar información detallada o específica de la evaluación.
Extrae metadatos y registros de consultas de tu almacén de datos
Se necesitan tanto los metadatos como los registros de consultas para preparar la evaluación con recomendaciones.
A fin de extraer los metadatos y los registros de consultas necesarios para ejecutar la evaluación, selecciona tu almacén de datos:
Teradata
Requisitos
- Una máquina conectada a tu almacén de datos de Teradata de origen (se admiten Teradata 15 y versiones posteriores)
- Una cuenta Google Cloud con un bucket de Cloud Storage para almacenar los datos
- Un conjunto de datos de BigQuery vacío para almacenar los resultados.
- Lee los permisos del conjunto de datos para ver los resultados
- Recomendado: derechos de acceso a nivel de administrador a la base de datos de origen cuando se usa la herramienta de extracción para acceder a tablas del sistema
Requisito: habilitar el registro
La herramienta dwh-migration-dumper extrae tres tipos de registros: registros de consulta, registros de utilidad y registros de uso de recursos. Debes habilitar el registro para los siguientes tipos de registros si deseas ver estadísticas más detalladas:
- Registros de consultas: Se extraen de la vista
dbc.QryLogVy de la tabladbc.DBQLSqlTbl. Especifica la opciónWITH SQLpara habilitar el registro. - Registros de utilidad: Se extraen de la tabla
dbc.DBQLUtilityTbl. Especifica la opciónWITH UTILITYINFOpara habilitar el registro. - Registros de uso de recursos: Se extraen de las tablas
dbc.ResUsageScpuydbc.ResUsageSpma. Habilita el registro de RSS para estas dos tablas.
Ejecuta la herramienta dwh-migration-dumper
Descargue la herramienta dwh-migration-dumper.
Descarga el archivo SHA256SUMS.txt y ejecuta el siguiente comando para verificar la precisión del archivo ZIP:
Bash
sha256sum --check SHA256SUMS.txt
WindowsPowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Reemplaza RELEASE_ZIP_FILENAME por el nombre del archivo ZIP descargado de la versión de la herramienta de extracción de línea de comandos de dwh-migration-dumper, por ejemplo, dwh-migration-tools-v1.0.52.zip.
El resultado True confirma la verificación correcta de la suma de verificación.
El resultado False indica un error de verificación. Asegúrate de que los archivos de suma de comprobación y ZIP se descarguen de la misma versión de actualización y se coloquen en el mismo directorio.
Si deseas obtener detalles sobre cómo configurar y usar la herramienta de extracción, consulta Genera metadatos para la traducción y la evaluación.
Usa la herramienta de extracción para extraer registros y metadatos de tu almacén de datos de Teradata como dos archivos ZIP. Ejecuta los siguientes comandos en una máquina con acceso al almacén de datos de origen para generar los archivos.
Genera el archivo ZIP de metadatos:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: La marca --database es opcional para el conector teradata. Si se omite, se extraen los metadatos de todas las bases de datos. Esta marca solo es válida para el conector teradata y no se puede usar con teradata-logs.
Genera el archivo ZIP que contiene los registros de consultas:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
Nota: La marca --database no se usa cuando se extraen registros de búsqueda con el conector teradata-logs. Los registros de consultas siempre se extraen para todas las bases de datos.
Reemplaza lo siguiente:
PATH: Es la ruta absoluta o relativa al archivo JAR del controlador que se usará para esta conexión.VERSION: La versión de tu controladorHOST: la dirección del hostUSER: el nombre de usuario que se usará para la conexión de la base de datosDATABASES: (Opcional) Es la lista separada por comas de los nombres de las bases de datos que se extraerán. Si no se proporciona, se extraen todas las bases de datos.PASSWORD: (Opcional) Es la contraseña que se usará para la conexión de la base de datos. Si se deja vacía, se le solicita al usuario su contraseña.
De forma predeterminada, los registros de consultas se extraen de la vista dbc.QryLogV y de la tabla dbc.DBQLSqlTbl. Si necesitas extraer los registros de consultas de una ubicación alternativa, puedes especificar los nombres de las tablas o vistas mediante las marcas -Dteradata-logs.query-logs-table y -Dteradata-logs.sql-logs-table.
De forma predeterminada, los registros de utilidad se extraen de la tabla
dbc.DBQLUtilityTbl. Si necesitas extraer los registros de la utilidad de una
ubicación alternativa, puedes especificar el nombre de la tabla con la marca
-Dteradata-logs.utility-logs-table.
De forma predeterminada, los registros de uso de recursos se extraen de las tablas dbc.ResUsageScpu y dbc.ResUsageSpma. Si necesitas extraer los registros de uso de recursos de una ubicación alternativa, puedes especificar los nombres de las tablas con las marcas -Dteradata-logs.res-usage-scpu-table y -Dteradata-logs.res-usage-spma-table.
Por ejemplo:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
WindowsPowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
De forma predeterminada, la herramienta dwh-migration-dumper extrae los últimos siete días de los registros de consulta.
Google recomienda que proporciones al menos dos semanas de registros de consultas para poder ver estadísticas más detalladas. Puedes especificar un intervalo de tiempo personalizado con las marcas --query-log-start y --query-log-end. Por ejemplo:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
También puedes generar varios archivos ZIP que contengan registros de consulta que abarquen diferentes períodos y proporcionarlos todos para su evaluación.
Redshift
Requisitos
- Una máquina conectada a tu almacén de datos de origen de Amazon Redshift
- Una cuenta Google Cloud con un bucket de Cloud Storage para almacenar los datos
- Un conjunto de datos de BigQuery vacío para almacenar los resultados.
- Lee los permisos del conjunto de datos para ver los resultados
- Recomendado: Acceso de superusuario a la base de datos cuando se usa la herramienta de extracción para acceder a tablas del sistema
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de dwh-migration-dumper.
Descarga el archivo SHA256SUMS.txt y ejecuta el siguiente comando para verificar la precisión del archivo ZIP:
Bash
sha256sum --check SHA256SUMS.txt
WindowsPowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Reemplaza RELEASE_ZIP_FILENAME por el nombre del archivo ZIP descargado de la versión de la herramienta de extracción de línea de comandos de dwh-migration-dumper, por ejemplo, dwh-migration-tools-v1.0.52.zip.
El resultado True confirma la verificación correcta de la suma de verificación.
El resultado False indica un error de verificación. Asegúrate de que los archivos de suma de comprobación y ZIP se descarguen de la misma versión de actualización y se coloquen en el mismo directorio.
Para obtener detalles sobre cómo usar la herramienta dwh-migration-dumper, consulta la página Genera metadatos.
Usa la herramienta dwh-migration-dumper para extraer registros y metadatos de tu almacén de datos de Amazon Redshift como dos archivos ZIP.
Ejecuta los siguientes comandos en una máquina con acceso al almacén de datos de origen para generar los archivos.
Genera el archivo ZIP de metadatos:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Genera el archivo ZIP que contiene los registros de consultas:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Reemplaza lo siguiente:
DATABASE: el nombre de la base de datos a la que te conectarás.PATH: Es la ruta absoluta o relativa al archivo JAR del controlador que se usará para esta conexión.VERSION: La versión de tu controladorUSER: el nombre de usuario que se usará para la conexión de la base de datosIAM_PROFILE_NAME: El nombre del perfil de IAM de Amazon Redshift. Se requiere para la autenticación de Amazon Redshift y para el acceso a la API de AWS. Para obtener la descripción de los clústeres de Amazon Redshift, usa la API de AWS.
De forma predeterminada, Amazon Redshift almacena de tres a cinco días de registros de consultas.
De forma predeterminada, la herramienta dwh-migration-dumper extrae los últimos siete días de los registros de consulta.
Google recomienda que proporciones al menos dos semanas de registros de consultas para poder ver estadísticas más detalladas. Es posible que debas ejecutar la herramienta de extracción varias veces durante dos semanas para obtener los mejores resultados. Puedes especificar un rango personalizado con las marcas --query-log-start y --query-log-end.
Por ejemplo:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
También puedes generar varios archivos ZIP que contengan registros de consulta que abarquen diferentes períodos y proporcionarlos todos para su evaluación.
Redshift Serverless
Requisitos
- Una máquina conectada a tu almacén de datos de origen de Amazon Redshift Serverless
- Una cuenta Google Cloud con un bucket de Cloud Storage para almacenar los datos
- Un conjunto de datos de BigQuery vacío para almacenar los resultados.
- Lee los permisos del conjunto de datos para ver los resultados
- Recomendado: Acceso de superusuario a la base de datos cuando se usa la herramienta de extracción para acceder a tablas del sistema
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de dwh-migration-dumper.
Para obtener detalles sobre cómo usar la herramienta dwh-migration-dumper, consulta la página Genera metadatos.
Usa la herramienta dwh-migration-dumper para extraer registros de uso y metadatos de tu espacio de nombres de Amazon Redshift Serverless como dos archivos ZIP. Ejecuta los siguientes comandos en una máquina con acceso al almacén de datos de origen para generar los archivos.
Genera el archivo ZIP de metadatos:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Genera el archivo ZIP que contiene los registros de consultas:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
Reemplaza lo siguiente:
DATABASE: el nombre de la base de datos a la que te conectarás.PATH: Es la ruta absoluta o relativa al archivo JAR del controlador que se usará para esta conexión.VERSION: La versión de tu controladorUSER: el nombre de usuario que se usará para la conexión de la base de datosIAM_PROFILE_NAME: El nombre del perfil de IAM de Amazon Redshift. Se requiere para la autenticación de Amazon Redshift y para el acceso a la API de AWS. Para obtener la descripción de los clústeres de Amazon Redshift, usa la API de AWS.
Amazon Redshift Serverless almacena los registros de uso durante siete días. Si se requiere un rango más amplio, Google recomienda extraer los datos varias veces durante un período más largo.
Snowflake
Requisitos
Debes cumplir con los siguientes requisitos para extraer metadatos y registros de consultas de Snowflake:
- Una máquina que se pueda conectar a tus instancias de Snowflake.
- Una cuenta de Google Cloud con un bucket de Cloud Storage para almacenar los datos.
- Un conjunto de datos de BigQuery vacío para almacenar los resultados. Como alternativa, puedes crear un conjunto de datos de BigQuery cuando creas el trabajo de evaluación con la Google Cloud IU de la consola.
- Usuario de Snowflake con acceso de
IMPORTED PRIVILEGESa la base de datosSnowflake. Te recomendamos que crees un usuarioSERVICEcon autenticación basada en un par de claves. Esto proporciona el método seguro para acceder a la plataforma de datos de Snowflake sin necesidad de generar tokens de MFA.- Para crear un usuario de servicio nuevo, sigue la guía oficial de Snowflake. Deberás generar el par de clave RSA y asignar la clave pública al usuario de Snowflake.
- El usuario del servicio debe tener el rol de
ACCOUNTADMINo un administrador de cuentas le debe otorgar un rol con los privilegios deIMPORTED PRIVILEGESen la base de datosSnowflake. - Como alternativa a la autenticación con par de claves, puedes usar la autenticación basada en contraseña. Sin embargo, a partir de agosto de 2025, Snowflake aplicará la MFA a todos los usuarios que utilicen contraseñas. Esto requiere que apruebes la notificación push de MFA cuando uses nuestra herramienta de extracción.
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de dwh-migration-dumper.
Descarga el archivo SHA256SUMS.txt y ejecuta el siguiente comando para verificar la precisión del archivo ZIP:
Bash
sha256sum --check SHA256SUMS.txt
WindowsPowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Reemplaza RELEASE_ZIP_FILENAME por el nombre del archivo ZIP descargado de la versión de la herramienta de extracción de línea de comandos de dwh-migration-dumper, por ejemplo, dwh-migration-tools-v1.0.52.zip.
El resultado True confirma la verificación correcta de la suma de verificación.
El resultado False indica un error de verificación. Asegúrate de que los archivos de suma de comprobación y ZIP se descarguen de la misma versión de actualización y se coloquen en el mismo directorio.
Para obtener detalles sobre cómo usar la herramienta dwh-migration-dumper, consulta la página Genera metadatos.
Usa la herramienta dwh-migration-dumper para extraer registros y metadatos del almacén de datos de Snowflake en dos archivos ZIP. Ejecuta los siguientes comandos en una máquina con acceso al almacén de datos de origen para generar los archivos.
Genera el archivo ZIP de metadatos:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Genera el archivo ZIP que contiene los registros de consultas:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
Reemplaza lo siguiente:
HOST_NAME: Es el nombre de host de tu instancia de Snowflake.USER_NAME: el nombre de usuario que se usará para la conexión a la base de datos, en la que el usuario debe tener los permisos de acceso que se detallan en la sección de requisitos.PRIVATE_KEY_PATH: Es la ruta de acceso a la clave privada RSA que se usa para la autenticación.PRIVATE_KEY_PASSWORD: (Opcional) Es la contraseña que se usó cuando se creó la clave privada RSA. Solo se requiere si la clave privada está encriptada.ROLE_NAME: (Opcional) el rol de usuario cuando se ejecuta la herramientadwh-migration-dumper, por ejemplo,ACCOUNTADMIN.WAREHOUSE: el almacén que se usa para realizar las operaciones de volcado. Si tienes varios almacenes virtuales, puedes especificar cualquier almacén para realizar esta consulta. La ejecución de esta consulta con los permisos de acceso detallados en la sección de requisitos extrae todos los artefactos del almacén de esta cuenta.STARTING_DATE: (Opcional) Se usa para indicar la fecha de inicio en un período de registros de consultas, escrito en el formatoYYYY-MM-DD.ENDING_DATE: (Opcional) se usa para indicar la fecha de finalización en un período de registros de consultas, escrito en el formatoYYYY-MM-DD.
También puedes generar varios archivos ZIP que contengan registros de consulta que abarquen diferentes períodos y proporcionarlos para su evaluación.
Oracle
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Requisitos
Debes cumplir con los siguientes requisitos para extraer metadatos y registros de consultas de Oracle:
- Tu base de datos de Oracle debe ser la versión 11g R1 o una posterior.
- Una máquina que se pueda conectar a tus instancias de Oracle.
- Java 8 o una versión posterior
- Una cuenta de Google Cloud con un bucket de Cloud Storage para almacenar los datos.
- Un conjunto de datos de BigQuery vacío para almacenar los resultados. Como alternativa, puedes crear un conjunto de datos de BigQuery cuando creas el trabajo de evaluación con la Google Cloud IU de la consola.
- Un usuario común de Oracle con privilegios de SYSDBA
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de dwh-migration-dumper.
Descarga el archivo SHA256SUMS.txt y ejecuta el siguiente comando para verificar la precisión del archivo ZIP:
sha256sum --check SHA256SUMS.txt
Para obtener detalles sobre cómo usar la herramienta dwh-migration-dumper, consulta la página Genera metadatos.
Usa la herramienta dwh-migration-dumper para extraer metadatos y estadísticas de rendimiento al archivo ZIP. De forma predeterminada, las estadísticas se extraen del AWR de Oracle, que requiere el paquete Oracle Tuning and Diagnostics. Si estos datos no están disponibles, dwh-migration-dumper usa STATSPACK en su lugar.
En el caso de las bases de datos de múltiples inquilinos, la herramienta dwh-migration-dumper se debe ejecutar en el contenedor raíz. Si lo ejecutas en una de las bases de datos conectables, faltarán estadísticas de rendimiento y metadatos sobre otras bases de datos conectables.
Genera el archivo ZIP de metadatos:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
Reemplaza lo siguiente:
HOST_NAME: Es el nombre de host de tu instancia de Oracle.PORT: Es el número de puerto de la conexión. El valor predeterminado es 1521.SERVICE_NAME: Es el nombre del servicio de Oracle que se usará para la conexión.JDBC_DRIVER_PATH: Es la ruta de acceso absoluta o relativa al archivo JAR del controlador. Puedes descargar este archivo desde la página de descargas del controlador JDBC de Oracle. Debes seleccionar la versión del controlador que sea compatible con la versión de tu base de datos.USER_NAME: Es el nombre del usuario que se usa para conectarse a la instancia de Oracle. El usuario debe tener los permisos de acceso que se detallan en la sección de requisitos.
Hadoop / Cloudera
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Requisitos
Debes tener lo siguiente para extraer metadatos de Cloudera:
- Una máquina que se pueda conectar a la API de Cloudera Manager
- Una cuenta de Google Cloud con un bucket de Cloud Storage para almacenar los datos.
- Un conjunto de datos de BigQuery vacío para almacenar los resultados. Como alternativa, puedes crear un conjunto de datos de BigQuery cuando crees el trabajo de evaluación.
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de
dwh-migration-dumper.Descarga el archivo
SHA256SUMS.txt.En tu entorno de línea de comandos, verifica la precisión del archivo ZIP:
sha256sum --check SHA256SUMS.txt
Si deseas obtener detalles sobre cómo usar la herramienta
dwh-migration-dumper, consulta Genera metadatos para la traducción y la evaluación.Usa la herramienta
dwh-migration-dumperpara extraer metadatos y estadísticas de rendimiento en el archivo ZIP:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Reemplaza lo siguiente:
USER_NAME: Es el nombre del usuario que se conectará a tu instancia de Cloudera Manager.PASSWORD: Es la contraseña de tu instancia de Cloudera Manager.URL_PATH: Es la ruta de URL a la API de Cloudera Manager, por ejemplo,https://localhost:7183/api/v55/.APP_TYPES(opcional): Son los tipos de aplicaciones de YARN separados por comas que se vuelcan desde el clúster. El valor predeterminado esMAPREDUCE,SPARK,Oozie Launcher.PAGE_SIZE(opcional): Es la cantidad de registros por respuesta de Cloudera. El valor predeterminado es1000.START_DATE(opcional): Es la fecha de inicio de la volcado del historial en formato ISO 8601, por ejemplo,2025-05-29. El valor predeterminado es 90 días antes de la fecha actual.END_DATE(opcional): Es la fecha de finalización de la copia del historial en formato ISO 8601, por ejemplo,2025-05-30. El valor predeterminado es la fecha actual.
Usa Oozie en tu clúster de Cloudera
Si usas Oozie en tu clúster de Cloudera, puedes volcar el historial de trabajos de Oozie con el conector de Oozie. Puedes usar Oozie con la autenticación Kerberos o la autenticación básica.
Para la autenticación Kerberos, ejecuta lo siguiente:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
Reemplaza lo siguiente:
URL_PATH(opcional): Es la ruta de URL del servidor de Oozie. Si no especificas la ruta de URL, se toma de la variable de entornoOOZIE_URL.
Para la autenticación básica, ejecuta lo siguiente:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
Reemplaza lo siguiente:
USER_NAME: Es el nombre del usuario de Oozie.PASSWORD: La contraseña del usuarioURL_PATH(opcional): Es la ruta de URL del servidor de Oozie. Si no especificas la ruta de URL, se toma de la variable de entornoOOZIE_URL.
Usa Airflow en tu clúster de Cloudera
Si usas Airflow en tu clúster de Cloudera, puedes volcar el historial de DAG con el conector de Airflow:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
Reemplaza lo siguiente:
USER_NAME: El nombre del usuario de AirflowPASSWORD: La contraseña del usuarioURL: Cadena de JDBC para la base de datos de AirflowDRIVER_PATH: Es la ruta de acceso al controlador JDBC.START_DATE(opcional): Es la fecha de inicio del volcado del historial en formato ISO 8601.END_DATE(opcional): Es la fecha de finalización de la volcado del historial en formato ISO 8601.
Usa Hive en tu clúster de Cloudera
Para usar el conector de Hive, consulta la pestaña Apache Hive.
Apache Hive
Requisitos
- Una máquina conectada a tu almacén de datos de origen de Apache Hive (la evaluación de migración de BigQuery admite Hive en Tez y MapReduce, y admite versiones de Apache Hive entre 2.2 y 3.1, inclusive)
- Una cuenta Google Cloud con un bucket de Cloud Storage para almacenar los datos
- Un conjunto de datos de BigQuery vacío para almacenar los resultados.
- Lee los permisos del conjunto de datos para ver los resultados
- Acceso a tu almacén de datos de origen de Apache Hive para configurar la extracción de registros de consultas
- Estadísticas de tablas, particiones y columnas actualizadas
La evaluación de migración de BigQuery usa tablas, particiones y estadísticas de columnas para comprender tu almacén de datos de Apache Hive mejor y proporcionar estadísticas detalladas. Si la configuración hive.stats.autogather se establece como false en tu almacén de datos de origen de Apache Hive, Google recomienda habilitarla o actualizar las estadísticas de forma manual antes de ejecutar la herramienta de dwh-migration-dumper.
Ejecuta la herramienta dwh-migration-dumper
Descarga la herramienta de extracción de línea de comandos de dwh-migration-dumper.
Descarga el archivo SHA256SUMS.txt y ejecuta el siguiente comando para verificar la precisión del archivo ZIP:
Bash
sha256sum --check SHA256SUMS.txt
WindowsPowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
Reemplaza RELEASE_ZIP_FILENAME por el nombre del archivo ZIP descargado de la versión de la herramienta de extracción de línea de comandos de dwh-migration-dumper, por ejemplo, dwh-migration-tools-v1.0.52.zip.
El resultado True confirma la verificación correcta de la suma de verificación.
El resultado False indica un error de verificación. Asegúrate de que los archivos de suma de comprobación y ZIP se descarguen de la misma versión de actualización y se coloquen en el mismo directorio.
Si deseas obtener detalles sobre cómo usar la herramienta dwh-migration-dumper, consulta Genera metadatos para la traducción y la evaluación.
Usa la herramienta dwh-migration-dumper para generar metadatos de tu almacén de datos de Hive como un archivo ZIP.
Sin autenticación
Para generar el archivo ZIP de metadatos, ejecuta el siguiente comando en una máquina que tenga acceso al almacén de datos de origen:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
Con autenticación de Kerberos
Para autenticarte en el almacén de metadatos, accede como un usuario que tenga acceso al almacén de metadatos de Apache Hive y genera un ticket de Kerberos. Luego, genera el archivo ZIP de metadatos con el siguiente comando:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
Reemplaza lo siguiente:
DATABASES: Es la lista separada por comas de los nombres de las bases de datos que se extraerán. Si no se proporciona, se extraen todas las bases de datos.PRINCIPAL: Es el principal de Kerberos al que se emite el ticket.HOST: Es el nombre de host de Kerberos para el que se emite el ticket.hadoop.rpc.protection: Es la calidad de protección (QOP) del nivel de configuración de la capa de seguridad y autenticación simple (SASL), igual al valor del parámetrohadoop.rpc.protectiondentro del archivo/etc/hadoop/conf/core-site.xml, con uno de los siguientes valores:authenticationintegrityprivacy
Extrae registros de consultas con el hook de registro hadoop-migration-assessment
Para extraer registros de consultas, sigue estos pasos:
- Sube el hook de registro
hadoop-migration-assessment. - Configura las propiedades del hook de registro.
- Verifica el hook de registro.
Sube el hook de registro hadoop-migration-assessment
Descarga el hook de registro de extracción de registros de consulta
hadoop-migration-assessmentque contiene el archivo JAR del hook de registro de Hive.Extrae el archivo JAR.
Si necesitas auditar la herramienta para asegurarte de que cumpla con los requisitos de cumplimiento, revisa el código fuente del repositorio de GitHub del hook de registro
hadoop-migration-assessmenty compila tu propio objeto binario.Copia el archivo JAR en la carpeta de la biblioteca auxiliar en todos los clústeres en los que planeas habilitar el registro de consultas. Según tu proveedor, debes ubicar la carpeta de la biblioteca auxiliar en la configuración del clúster y transferir el archivo JAR a la carpeta de la biblioteca auxiliar en el clúster de Hive.
Establece las propiedades de configuración para el hook de registro
hadoop-migration-assessment. Según tu proveedor de Hadoop, debes usar la consola de IU para editar la configuración del clúster. Modifica el archivo/etc/hive/conf/hive-site.xmlo aplica la configuración con el administrador de configuración.
Configura propiedades
Si ya tienes otros valores para las siguientes claves de configuración, agrega la configuración mediante una coma (,). A fin de configurar el hook de registro hadoop-migration-assessment, se requiere la siguiente configuración:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path: incluye la ruta al archivo JAR de hook de registro, por ejemplo,file://./HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory: Es la ruta de acceso a la carpeta de salida de los registros de consulta. Por ejemplo,hdfs://tmp/logs/También puedes establecer las siguientes configuraciones opcionales:
dwhassessment.hook.queue.capacity: la capacidad de cola para los subprocesos de registro de eventos de consulta. El valor predeterminado es64.dwhassessment.hook.rollover-interval: la frecuencia con la que se debe realizar la transferencia del archivo. Por ejemplo,600sEl valor predeterminado es 3,600 segundos (1 hora).dwhassessment.hook.rollover-eligibility-check-interval: la frecuencia con la que se activa la verificación de elegibilidad de transferencia de archivos en segundo plano. Por ejemplo,600sEl valor predeterminado es 600 segundos (10 minutos).
Verifica el hook de registro
Después de reiniciar el proceso hive-server2, ejecuta una consulta de prueba y analiza los registros de depuración. Puedes ver el siguiente mensaje:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
El hook de registro crea una subcarpeta particionada por fecha en la carpeta configurada. El archivo Avro con eventos de consulta aparece en esa carpeta después del intervalo dwhassessment.hook.rollover-interval o la finalización del proceso hive-server2. Puedes buscar mensajes similares en tus registros de depuración para ver el estado de la operación de desplazamiento:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
El desplazamiento se produce en los intervalos especificados o cuando cambia el día. Cuando la fecha cambia, el hook de registro también crea una subcarpeta nueva para esa fecha.
Google recomienda que proporciones al menos dos semanas de registros de consultas para poder ver estadísticas más detalladas.
También puedes generar carpetas que contengan registros de consulta de diferentes clústeres de Hive y proporcionarlos a todos para una sola evaluación.
Informatica
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Requisitos
- Acceso al cliente de Informatica PowerCenter Repository Manager
- Una cuenta de Google Cloud con un bucket de Cloud Storage para almacenar los datos.
- Un conjunto de datos de BigQuery vacío para almacenar los resultados. Como alternativa, puedes crear un conjunto de datos de BigQuery cuando creas el trabajo de evaluación con la Google Cloud consola.
Requisito: Exportar archivos de objeto
Puedes usar la GUI de Informatica PowerCenter Repository Manager para exportar tus archivos de objetos. Para obtener más información, consulta Pasos para exportar objetos.
Como alternativa, también puedes ejecutar el comando pmrep para exportar tus archivos de objeto con los siguientes pasos:
- Ejecuta el comando
pmrep connectpara conectarte al repositorio:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
Reemplaza lo siguiente:
REPOSITORY_NAME: Nombre del repositorio al que deseas conectarteDOMAIN_NAME: Nombre del dominio del repositorioUSERNAME: Nombre de usuario para conectarse al repositorioPASSWORD: Contraseña del nombre de usuario
- Una vez que te conectes al repositorio, usa el comando
pmrep objectexportpara exportar los objetos requeridos:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
Reemplaza lo siguiente:
OBJECT_NAME: Nombre de un objeto específico para exportarOBJECT_TYPE: Tipo de objeto del objeto especificadoFOLDER_NAME: Nombre de la carpeta que contiene el objeto que se exportaráOUTPUT_FILE_NAME: Nombre del archivo XML que contendrá la información del objeto
Sube registros de consultas y de metadatos a Cloud Storage
Una vez que hayas extraído los metadatos y los registros de consultas de tu almacén de datos, puedes subir los archivos a un bucket de Cloud Storage para continuar con la evaluación de la migración.
Teradata
Sube los metadatos y uno o más archivos ZIP que contengan registros de consulta a tu bucket de Cloud Storage. Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos. El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP de metadatos es de 50 GB.
Las entradas en todos los archivos ZIP que contienen registros de consultas se dividen en lo siguiente:
- Archivos de historial de consultas con el prefijo
query_history_ - Archivos de series temporales con los prefijos
utility_logs_,dbc.ResUsageScpu_ydbc.ResUsageSpma_
El límite para el tamaño total sin comprimir de todos los archivos del historial de consultas es de 5 TB. El límite para el tamaño total sin comprimir de todos los archivos de series temporales es de 1 TB.
En caso de que los registros de consultas se archiven en una base de datos diferente, consulta la descripción de las marcas -Dteradata-logs.query-logs-tabley -Dteradata-logs.sql-logs-table antes en esta sección, en la que se explica cómo proporcionar una ubicación alternativa para los registros de consultas.
Redshift
Sube los metadatos y uno o más archivos ZIP que contengan registros de consulta a tu bucket de Cloud Storage. Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos. El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP de metadatos es de 50 GB.
Las entradas en todos los archivos ZIP que contienen registros de consultas se dividen en lo siguiente:
- Archivos de historial de consultas con los prefijos
querytext_yddltext_ - Archivos de series temporales con los prefijos
query_queue_info_,wlm_query_yquerymetrics_
El límite para el tamaño total sin comprimir de todos los archivos del historial de consultas es de 5 TB. El límite para el tamaño total sin comprimir de todos los archivos de series temporales es de 1 TB.
Redshift Serverless
Sube los metadatos y uno o más archivos ZIP que contengan registros de consulta a tu bucket de Cloud Storage. Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
Snowflake
Sube los metadatos y los archivos ZIP que contienen registros de consulta y los historiales de uso a tu bucket de Cloud Storage. Cuando subas estos archivos a Cloud Storage, se deben cumplir los siguientes requisitos:
- El tamaño total sin comprimir de todos los archivos dentro del archivo ZIP de metadatos debe ser inferior a 50 GB.
- El archivo ZIP de metadatos y el archivo ZIP que contiene registros de consulta deben subirse a una carpeta de Cloud Storage. Si tienes varios archivos ZIP con registros de consultas no superpuestos, puedes subirlos todos.
- Debes subir todos los archivos a la misma carpeta de Cloud Storage.
- Debes subir todos los archivos ZIP de metadatos y registros de consultas exactamente como los genera la herramienta
dwh-migration-dumper. No los extraigas, combines ni modifiques de ningún modo. - El tamaño total sin comprimir de todos los archivos del historial de consultas debe ser inferior a 5 TB.
Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
Oracle
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Sube el archivo ZIP que contiene metadatos y estadísticas de rendimiento a un bucket de Cloud Storage. De forma predeterminada, el nombre del archivo ZIP es dwh-migration-oracle-stats.zip, pero puedes personalizarlo especificándolo en la marca --output. El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP es de 50 GB.
Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
Hadoop / Cloudera
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Sube el archivo ZIP que contiene metadatos y estadísticas de rendimiento a un bucket de Cloud Storage. De forma predeterminada, el nombre del archivo ZIP es dwh-migration-cloudera-manager-RUN_DATE.zip (por ejemplo, dwh-migration-cloudera-manager-20250312T145808.zip), pero puedes personalizarlo con la marca --output. El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP es de 50 GB.
Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea un bucket y Sube objetos desde un sistema de archivos.
Apache Hive
Sube los metadatos y las carpetas que contienen registros de consultas de uno o varios clústeres de Hive a tu bucket de Cloud Storage. Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP de metadatos es de 50 GB.
Puedes usar el conector de Cloud Storage para copiar registros de consultas directamente a la carpeta de Cloud Storage. Las carpetas que contienen subcarpetas con registros de consultas se deben subir a la misma carpeta de Cloud Storage, en la que se sube el archivo ZIP de metadatos.
Las carpetas de registros de consultas tienen archivos del historial de consultas con el prefijo dwhassessment_. El límite para el tamaño total sin comprimir de todos los archivos del historial de consultas es de 5 TB.
Informatica
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Sube un archivo ZIP que contenga los objetos de tu repositorio XML de Informatica a un bucket de Cloud Storage. Este archivo ZIP también debe incluir un archivo compilerworks-metadata.yaml que contenga lo siguiente:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
El límite para el tamaño total sin comprimir de todos los archivos dentro del archivo ZIP es de 50 GB.
Para obtener más información sobre la creación de buckets y la carga de archivos a Cloud Storage, consulta Crea buckets y Sube objetos desde un sistema de archivos.
Ejecuta una evaluación de migración de BigQuery
Sigue estos pasos para ejecutar la evaluación de migración de BigQuery. En estos pasos, se supone que subiste los archivos de metadatos a un bucket de Cloud Storage, como se describe en la sección anterior.
Permisos necesarios
Para habilitar el Servicio de migración de BigQuery, necesitas los siguientes permisos de Identity and Access Management (IAM):
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
Para acceder al Servicio de migración de BigQuery y usarlo, necesitas los siguientes permisos en el proyecto:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
Para ejecutar el servicio de migración de BigQuery, necesitas los siguientes permisos adicionales.
Permiso para acceder a los buckets de Cloud Storage para archivos de entrada y salida, sigue estos pasos:
storage.objects.geten el bucket de origen de Cloud Storagestorage.objects.listen el bucket de origen de Cloud Storagestorage.objects.createen el bucket de destino de Cloud Storagestorage.objects.deleteen el bucket de destino de Cloud Storagestorage.objects.updateen el bucket de destino de Cloud Storagestorage.buckets.getstorage.buckets.list
Permiso para leer y actualizar el conjunto de datos de BigQuery en el que el Servicio de migración de BigQuery escribe los resultados:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
Para compartir el informe de Looker Studio con un usuario, debes otorgarle los siguientes roles:
roles/bigquery.dataViewerroles/bigquery.jobUser
Si quieres personalizar este documento para usar tu propio proyecto y usuario en los comandos, edita estas variables:
PROJECT,
USER_EMAIL.
Crea un rol personalizado con los permisos necesarios para usar la evaluación de migración de BigQuery:
gcloud iam roles create BQMSrole \ --project=PROJECT \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get
Otórgale el rol personalizado BQMSrole a un usuario:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=projects/PROJECT/roles/BQMSrole
Otorga los roles necesarios a un usuario con el que deseas compartir el informe:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:USER_EMAIL \ --role=roles/bigquery.jobUser
Ubicaciones admitidas
La función de evaluación de migración de BigQuery se admite en dos tipos de ubicaciones:
Una región es un lugar geográfico específico, como Londres.
Una multirregión es un área geográfica grande, como los Estados Unidos, que contiene dos o más regiones. Las ubicaciones multirregionales pueden proporcionar cuotas más grandes que las regiones individuales.
Para obtener más información sobre las regiones y zonas, consulta Geografía y regiones.
Regiones
En la siguiente tabla, se enumeran las regiones de América en las que está disponible la evaluación de la migración de BigQuery.| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Columbus, Ohio | us-east5 |
|
| Dallas | us-south1 |
|
| Iowa | us-central1 |
|
| Carolina del Sur | us-east1 |
|
| Virginia del Norte | us-east4 |
|
| Oregón | us-west1 |
|
| Los Ángeles | us-west2 |
|
| Salt Lake City | us-west3 |
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Singapur | asia-southeast1 |
|
| Tokio | asia-northeast1 |
| Descripción de la región | Nombre de la región | Detalles |
|---|---|---|
| Bélgica | europe-west1 |
|
| Finlandia | europe-north1 |
|
| Fráncfort | europe-west3 |
|
| Londres | europe-west2 |
|
| Madrid | europe-southwest1 |
|
| Países Bajos | europe-west4 |
|
| París | europe-west9 |
|
| Turín | europe-west12 |
|
| Varsovia | europe-central2 |
|
| Zúrich | europe-west6 |
|
Multirregiones
En la siguiente tabla, se enumeran las multirregiones en las que está disponible la evaluación de migración de BigQuery.| Descripción de la multirregión | Nombre de la multirregión |
|---|---|
| Centros de datos dentro de los estados miembros de la Unión Europea | EU |
| Centros de datos en Estados Unidos | US |
Antes de comenzar
Antes de ejecutar la evaluación, debes habilitar la API de BigQuery Migration y crear un conjunto de datos de BigQuery para almacenar los resultados de la evaluación.
Habilita la API de BigQuery Migration
Habilita la API de migración de BigQuery de la siguiente manera:
En la consola de Google Cloud , ve a la página API de BigQuery Migration.
Haga clic en Habilitar.
Crea un conjunto de datos para los resultados de la evaluación
La evaluación de migración de BigQuery escribe los resultados de la evaluación en las tablas de BigQuery. Antes de comenzar, crea un conjunto de datos para conservar estas tablas. Cuando compartes el informe de Looker Studio, también debes otorgar permiso a los usuarios para leer este conjunto de datos. Para obtener más información, consulta Haz que el informe esté disponible para los usuarios.
Ejecuta la evaluación de la migración
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el menú de navegación, haz clic en Assessment.
Haz clic en Iniciar evaluación.
Completa el cuadro de diálogo de configuración de la evaluación.
- En Nombre visible, ingresa el nombre, que puede contener letras, números o guiones bajos. Este nombre solo se usa con fines de visualización y no tiene que ser único.
En la lista Ubicación de los datos, elige una ubicación para el trabajo de evaluación. El trabajo de evaluación debe estar ubicado en la misma ubicación que el bucket de Cloud Storage de entrada de los archivos extraídos y el conjunto de datos de BigQuery de salida. Sin embargo, si el bucket de Cloud Storage o el conjunto de datos de BigQuery se encuentran en una multirregión, el trabajo de evaluación debe estar en cualquiera de las regiones dentro de esta multirregión.
Si la ubicación de la evaluación es una multirregión
USoEU, la ubicación del bucket de Cloud Storage y la ubicación del conjunto de datos de BigQuery deben estar en la misma multirregión o en la ubicación dentro de esta multirregión. Para obtener más información sobre las restricciones de ubicación, consulta Consideraciones sobre la ubicación de los datos de carga de BigQuery.En Fuente de datos de la evaluación, elige tu almacén de datos.
En Ruta de acceso a los archivos de entrada, ingresa la ruta de acceso al bucket de Cloud Storage que contiene los archivos extraídos.
Para elegir cómo se almacenan los resultados de tu evaluación, haz una de las siguientes acciones:
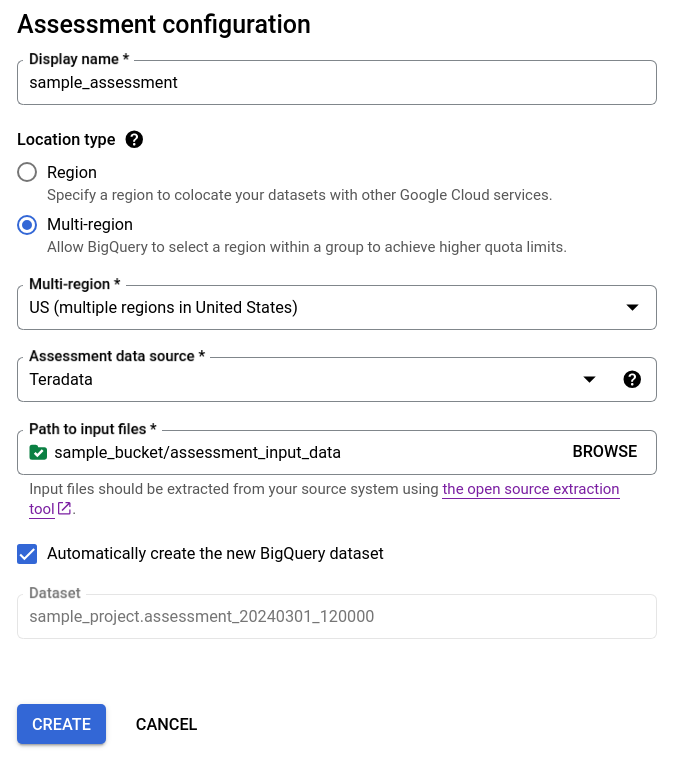
- Mantén seleccionada la casilla de verificación Crea el conjunto de datos de BigQuery nuevo automáticamente para que el conjunto de datos de BigQuery se cree automáticamente. El nombre del conjunto de datos se genera automáticamente.
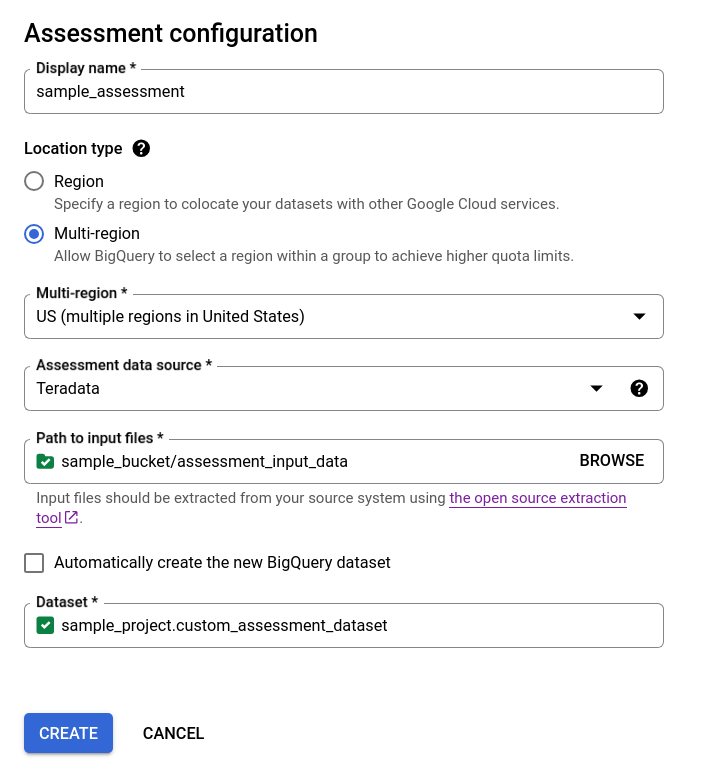
- Desmarca la casilla de verificación Crea el conjunto de datos de BigQuery nuevo automáticamente y elige el conjunto de datos de BigQuery vacío existente con el formato
projectId.datasetIdo crea un nombre de conjunto de datos nuevo. En esta opción, puedes elegir el nombre del conjunto de datos de BigQuery.
Opción 1: Generación automática del conjunto de datos de BigQuery (opción predeterminada)
Opción 2: Creación manual del conjunto de datos de BigQuery:
Haz clic en Crear. Puedes ver el estado del trabajo en la lista de trabajos de evaluación.
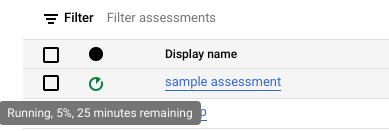
Mientras se ejecuta la evaluación, puedes verificar su progreso y el tiempo estimado para completarla en la sugerencia sobre herramientas del ícono de estado.
Mientras se ejecuta la evaluación, puedes hacer clic en el vínculo Ver informe en la lista de trabajos de evaluación para ver el informe de evaluación con datos parciales en Looker Studio. Es posible que el vínculo Ver informe tarde un poco en aparecer mientras se ejecuta la evaluación. El informe se abrirá en una pestaña nueva.
El informe se actualiza con datos nuevos a medida que se procesan. Actualiza la pestaña con el informe o vuelve a hacer clic en Ver informe para ver el informe actualizado.
Cuando se complete la evaluación, haz clic en Ver informe para ver el informe de evaluación completo en Looker Studio. El informe se abrirá en una pestaña nueva.
API
Llama al método create con un flujo de trabajo definido.
Luego, llama al método start para iniciar el flujo de trabajo de evaluación.
La evaluación crea tablas en el conjunto de datos de BigQuery que creaste antes. Puedes consultar estos metadatos para obtener información sobre las tablas y las consultas que se usan en tu almacén de datos existente. Para obtener información sobre los archivos de salida de la traducción, consulta Traductor de SQL por lotes.
Resultado agregado de la evaluación que se puede compartir
Para las evaluaciones de Amazon Redshift, Teradata y Snowflake, además del conjunto de datos de BigQuery creado anteriormente, el flujo de trabajo crea otro conjunto de datos ligero con el mismo nombre y el sufijo _shareableRedactedAggregate. Este conjunto de datos contiene datos altamente agregados que se derivan del conjunto de datos de salida y no contiene información de identificación personal (PII).
Para encontrar, inspeccionar y compartir de forma segura el conjunto de datos con otros usuarios, consulta Cómo consultar las tablas de resultados de la evaluación de la migración.
La función está activada de forma predeterminada, pero puedes inhabilitarla con la API pública.
Detalles de la evaluación
Para ver la página Detalles de la evaluación, haz clic en el nombre visible en la lista de trabajos de evaluación.

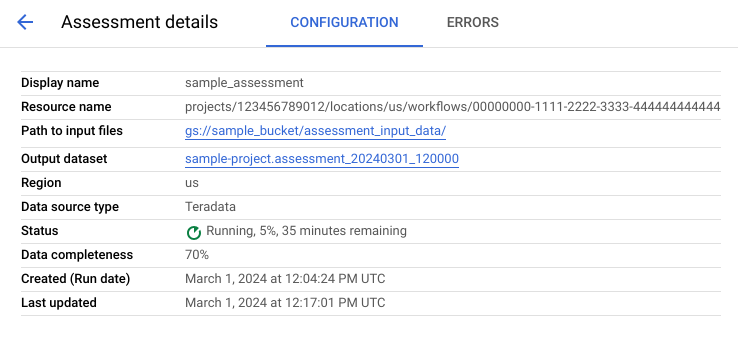
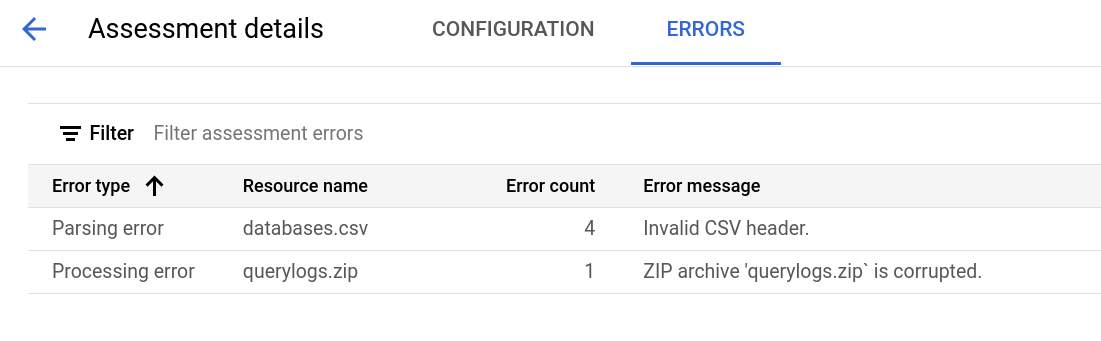
La página de detalles de la evaluación contiene la pestaña Configuración, en la que puedes ver más información sobre un trabajo de evaluación, y la pestaña Errores, en la que puedes revisar los errores que se produjeron durante el procesamiento de la evaluación.
Consulta la pestaña Configuración para ver las propiedades de la evaluación.
Consulta la pestaña Errores para ver los errores que se produjeron durante el procesamiento de la evaluación.
Revisa y comparte el informe de Looker Studio
Una vez que se completa la tarea de evaluación, puedes crear y compartir un informe de Looker Studio de los resultados.
Revisa el informe
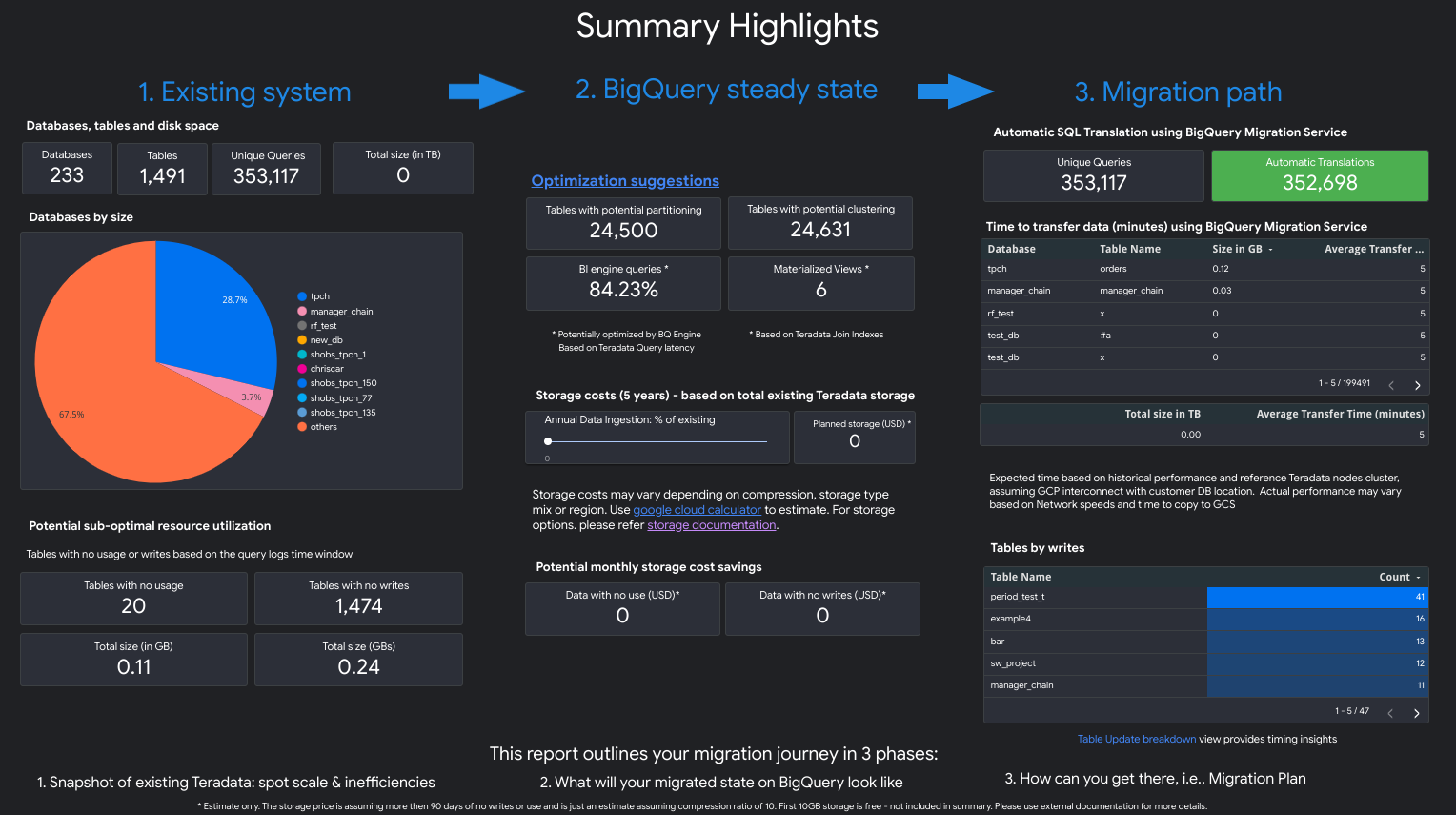
Haz clic en el vínculo Ver informe que se encuentra junto a la tarea de evaluación individual. El informe de Looker Studio se abre en una pestaña nueva, en modo de vista previa. Puedes usar el modo de vista previa para revisar el contenido del informe antes de compartirlo.
El informe es similar a la siguiente captura de pantalla:
Para ver qué vistas se encuentran en el informe, selecciona tu almacén de datos:
Teradata
El informe es una narrativa de tres partes que está precedida por una página de puntos destacados de resumen. Esa página incluye las siguientes secciones:
- Sistema existente. En esta sección, se incluye una instantánea del sistema y el uso de Teradata existentes, incluida la cantidad de bases de datos, esquemas, tablas y el tamaño total en TB. También se enumeran los esquemas por tamaño y se apunta al posible uso de recursos deficientes (tablas sin escrituras o pocas lecturas).
- Transformaciones de estado estable de BigQuery (sugerencias). En esta sección, se muestra cómo se verá el sistema en BigQuery después de la migración. Incluye sugerencias para optimizar las cargas de trabajo en BigQuery (y evitar el desperdicio).
- Plan de migración. En esta sección, se proporciona información sobre el esfuerzo de migración en sí, por ejemplo, pasar del sistema existente al estado estable de BigQuery. En esta sección, se incluye el recuento de las consultas que se tradujeron automáticamente y el tiempo estimado para trasladar cada tabla a BigQuery.
Los detalles de cada sección incluyen lo siguiente:
Sistema existente
- Procesamiento y consultas
- Uso de CPU:
- Mapa de calor del uso promedio de CPU por hora (vista general del uso de recursos del sistema)
- Consultas por hora y día con uso de CPU
- Consultas por tipo (lectura/escritura) con uso de CPU
- Aplicaciones con uso de CPU
- Superposición del uso de CPU por hora con el rendimiento de consultas por hora promedio y el rendimiento promedio de las aplicaciones por hora
- Consulta histogramas por tipo y duración de las consultas
- Vista de detalles de las aplicaciones (app, usuario, consultas únicas, desglose de informes y ETL)
- Uso de CPU:
- Descripción general del almacenamiento
- Bases de datos por volumen, vistas y tasas de acceso
- Tablas con tasas de acceso de los usuarios, consultas, escrituras y creación de tablas temporales
- Aplicaciones: Tasas de acceso y direcciones IP
Transformaciones de estado estable de BigQuery (sugerencias)
- Los índices de unión se convirtieron en vistas materializadas
- Agrupación en clústeres y partición de candidatos según los metadatos y el uso
- Consultas de baja latencia identificadas como candidatas para BigQuery BI Engine
- Columnas configuradas con valores predeterminados que usan la función de descripción de la columna para almacenar valores predeterminados
- Los índices únicos en Teradata (para evitar filas con claves que no sean únicas en una tabla) usan tablas de etapa de pruebas y una instrucción
MERGEpara insertar solo registros únicos en las tablas de destino y, luego, descartar los duplicados. - Consultas restantes y esquema traducido tal como está
Plan de migración
- Vista detallada con consultas traducidas de forma automática
- Recuento de consultas totales con capacidad para filtrar por usuario, aplicación, tablas afectadas, tablas consultadas y tipo de consulta
- Buckets de consultas con patrones similares agrupados y se muestran juntos para que el usuario pueda ver la filosofía de traducción por tipos de consulta
- Consultas que requieren intervención humana
- Consultas con incumplimientos de estructura léxica de BigQuery
- Funciones y procedimientos definidos por el usuario
- Palabras clave reservadas de BigQuery
- Tablas programadas por escrituras y lecturas (para agruparlas a fin de moverlas)
- Migración de datos con el Servicio de transferencia de datos de BigQuery: Tiempo estimado de migración por tabla
La sección Sistema existente contiene las siguientes vistas:
- Descripción general del sistema
- La vista de descripción general del sistema proporciona las métricas de volumen de alto nivel de los componentes clave en el sistema existente durante un período específico. El cronograma que se evalúa depende de los registros que se analizaron en la evaluación de migración de BigQuery. Esta vista te brinda estadísticas rápidas sobre el uso del almacén de datos de origen, que puedes usar para la planificación de la migración.
- Volumen de tablas
- En la vista Volumen de tablas, se proporcionan estadísticas sobre las tablas y bases de datos más grandes que se encuentran en la evaluación de migración de BigQuery. Debido a que las tablas grandes pueden tardar más en extraerse del sistema de almacén de datos de origen, esta vista puede ser útil en la planificación y la secuencia de la migración.
- Uso de tablas
- En la vista Uso de tablas, se proporcionan estadísticas sobre qué tablas se usan mucho dentro del sistema de almacén de datos de origen. Las tablas muy usadas pueden ayudarte a comprender qué tablas pueden tener muchas dependencias y requieren una planificación adicional durante el proceso de migración.
- Aplicaciones
- En las vistas Uso de aplicaciones y Patrones de aplicaciones, se proporcionan estadísticas sobre las aplicaciones que se encontraron durante el procesamiento de los registros. Estas vistas permiten a los usuarios comprender el uso de aplicaciones específicas a lo largo del tiempo y el impacto en el uso de recursos. Durante una migración, es importante visualizar la transferencia y el consumo de datos para comprender mejor las dependencias del almacén de datos y analizar el impacto de mover varias aplicaciones dependientes juntas. La tabla Direcciones IP puede ser útil para identificar la aplicación exacta que usa el almacén de datos a través de conexiones de JDBC.
- Consultas
- La vista Consultas proporciona un desglose de los tipos de instrucciones de SQL ejecutadas y las estadísticas de su uso. Puedes usar el histograma de Tiempo y tipo de consulta para identificar los períodos bajos del uso del sistema y los momentos óptimos del día para transferir datos. También puedes usar esta vista para identificar las consultas que se ejecutan con frecuencia y los usuarios que invocan esas ejecuciones.
- Bases de datos
- La vista de bases de datos proporciona métricas sobre el tamaño, las tablas, las vistas y los procedimientos definidos en el sistema de almacén de datos de origen. Esta vista puede proporcionar estadísticas sobre el volumen de objetos que necesitas migrar.
- Acoplamiento de bases de datos
- La vista de acoplamiento de la base de datos proporciona una vista de alto nivel en las bases de datos y tablas a las que se accede en conjunto en una sola consulta. En esta vista, se puede mostrar a qué tablas y bases de datos se hace referencia con frecuencia y qué puedes usar para la planificación de la migración.
La sección Estado estable de BigQuery contiene las siguientes vistas:
- Tablas sin uso
- En la vista Tablas sin uso, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ningún uso durante el período de registros que se analizó. La falta de uso puede indicar que no necesitas transferir esa tabla a BigQuery durante la migración o que los costos de almacenamiento de datos en BigQuery pueden ser menores. Debes validar la lista de tablas sin usar, ya que podrían tener uso fuera del período de los registros, como una tabla que solo se usa una vez cada tres o seis meses.
- Tablas sin escritura
- En la vista Tablas sin escrituras, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ninguna actualización durante el período de registros que se analizó. La falta de escrituras puede indicar dónde se pueden reducir los costos de almacenamiento en BigQuery.
- Consultas de baja latencia
- La vista Consultas de baja latencia muestra una distribución de entornos de ejecución de consultas en función de los datos de registro analizados. Si el gráfico de distribución de la duración de la consulta muestra una gran cantidad de consultas con menos de 1 segundo en el entorno de ejecución, considera habilitar BigQuery BI Engine para acelerar la IE y otras cargas de trabajo de baja latencia.
- Vistas materializadas
- La vista materializada proporciona sugerencias de optimización adicionales para aumentar el rendimiento en BigQuery.
- Agrupamiento en clústeres y partición
En la vista Partitioning and Clustering, se muestran las tablas que se beneficiarían de la partición, el agrupamiento en clústeres o ambos.
Las sugerencias de metadatos se logran analizando el esquema del almacén de datos de origen (como la partición y la clave principal en la tabla de origen) y buscando el equivalente de BigQuery más cercano para lograr características de optimización similares.
Las sugerencias de cargas de trabajo se obtienen analizando los registros de consultas de origen. La recomendación se determina mediante el análisis de las cargas de trabajo, en especial las cláusulas
WHEREoJOINen los registros de consulta analizados.- Recomendación de agrupamiento en clústeres
En la vista Partición, se muestran las tablas que pueden tener más de 10,000 particiones, según su definición de restricción de partición. Estas tablas suelen ser buenas candidatas para el agrupamiento en clústeres de BigQuery, lo que permite particiones de tabla detalladas.
- Restricciones únicas
En la vista Restricciones únicas, se muestran las tablas
SETy los índices únicos definidos dentro del almacén de datos de origen. En BigQuery, se recomienda usar tablas de etapa de pruebas y una declaraciónMERGEpara insertar solo registros únicos en una tabla de destino. Usa el contenido de esta vista para determinar a qué tablas podrías tener que ajustar el ETL durante la migración.- Valores predeterminados/Restricciones de verificación
En esta vista, se muestran tablas que usan restricciones de verificación para establecer valores de columna predeterminados. En BigQuery, consulta Cómo especificar los valores predeterminados de la columna.
La sección Ruta de la migración del informe contiene las siguientes vistas:
- Traducción de SQL
- En la vista Traducción de SQL, se enumeran la cantidad y los detalles de las consultas que se convirtieron automáticamente con la evaluación de migración de BigQuery y que no requieren intervención manual. Por lo general, la traducción automática de SQL alcanza altas tasas de traducción si se proporcionan metadatos. Esta vista es interactiva y permite el análisis de consultas comunes y cómo se traducen.
- Esfuerzo sin conexión
- La vista Esfuerzo sin conexión captura las áreas que necesitan intervención manual, incluidas las UDF específicas y las posibles infracciones de sintaxis y estructura léxicas para las tablas o columnas.
- Palabras clave reservadas de BigQuery
- La vista Palabras clave reservadas de BigQuery muestra el uso detectado de palabras clave que tienen un significado especial en el lenguaje GoogleSQL y no se pueden usar como identificadores, a menos que estén encerrados entre caracteres de acento grave (
`). - Programa de actualizaciones de la tabla
- En la vista Programa de actualizaciones de tablas, se muestra cuándo y con qué frecuencia se actualizan las tablas para ayudarte a planificar cómo y cuándo moverlas.
- Migración de datos a BigQuery
- La vista Data Migration to BigQuery describe la ruta de migración con el tiempo esperado para migrar tus datos con el Servicio de transferencia de datos de BigQuery. Para obtener más información, consulta la guía del Servicio de transferencia de datos de BigQuery para Teradata.
La sección Apéndice contiene las siguientes vistas:
- Distinción de mayúsculas
- En la vista Distinción entre mayúsculas y minúsculas, se muestran las tablas del almacén de datos de origen que están configuradas para realizar comparaciones que no distinguen mayúsculas de minúsculas. De forma predeterminada, las comparaciones de cadenas en BigQuery distinguen mayúsculas de minúsculas. Para obtener más información, consulta Intercalación.
Redshift
- Aspectos destacados de la migración
- La vista Aspectos destacados de la migración proporciona un resumen ejecutivo de las tres secciones del informe:
- El panel Sistema existente proporciona información sobre la cantidad de bases de datos, esquemas y tablas, y el tamaño total del sistema de Redshift existente. También enumera los esquemas por tamaño y el posible uso de recursos deficientes. Puedes usar esta información para optimizar tus datos quitando, particionando o agrupando en clústeres tus tablas.
- En el panel Estado de Steady de BigQuery, se proporciona información sobre cómo se verán tus datos después de la migración en BigQuery, incluida la cantidad de consultas que se pueden traducir de forma automática mediante el servicio de migración de BigQuery. En esta sección, también se muestran los costos de almacenar tus datos en BigQuery según tu tasa anual de transferencia de datos, junto con sugerencias de optimización para tablas, aprovisionamiento y espacio.
- El panel Ruta de migración proporciona información sobre el esfuerzo de migración. Para cada tabla, se muestra el tiempo esperado de migración, la cantidad de filas y el tamaño.
La sección Sistema existente contiene las siguientes vistas:
- Consultas por tipo y programación
- En la vista Consultas por tipo y programación, se clasifican tus consultas en ETL/escritura y generación de informes/agregación. Ver tu combinación de consultas a lo largo del tiempo te ayuda a comprender tus patrones de uso existentes y a identificar la variabilidad y el posible aprovisionamiento excesivo que pueden afectar el costo y el rendimiento.
- Cola de consultas
- La vista de filas de espera de consultas proporciona detalles adicionales sobre la carga del sistema, incluidos el volumen y la combinación de consultas, y cualquier impacto en el rendimiento debido a las filas de espera, como recursos insuficientes.
- Consultas y ajuste de escala de WLM
- La vista Queries and WLM Scaling identifica el ajuste de la simultaneidad como un costo adicional y una complejidad de configuración. Muestra cómo tu sistema de Redshift enruta las consultas según las reglas que especificaste y los impactos en el rendimiento debido a las colas, el escalamiento de simultaneidad y las consultas expulsadas.
- Cola y espera
- La vista de filas y tiempos de espera ofrece una perspectiva más detallada de las filas y los tiempos de espera de las búsquedas a lo largo del tiempo.
- Clases y rendimiento de WLM
- La vista de clases y rendimiento de WLM proporciona una forma opcional de asignar las reglas a BigQuery. Sin embargo, te recomendamos que permitas que BigQuery enrute tus consultas automáticamente.
- Estadísticas de volumen de búsquedas y tablas
- En la vista de estadísticas de volumen de consultas y tablas, se enumeran las consultas por tamaño, frecuencia y usuarios principales. Esto te ayuda a categorizar las fuentes de carga en el sistema y a planificar cómo migrar tus cargas de trabajo.
- Bases de datos y esquemas
- La vista de bases de datos y esquemas proporciona métricas sobre el tamaño, las tablas, las vistas y los procedimientos definidos en el sistema de almacén de datos de origen. Esto proporciona estadísticas sobre el volumen de objetos que se deben migrar.
- Volumen de tablas
- En la vista Volumen de tablas, se proporcionan estadísticas sobre las tablas y bases de datos más grandes, y se muestra cómo se accede a ellas. Debido a que las tablas grandes pueden tardar más en extraerse del sistema de almacén de datos de origen, esta vista te ayuda con la planificación y la secuencia de la migración.
- Uso de tablas
- En la vista Uso de tablas, se proporcionan estadísticas sobre qué tablas se usan mucho dentro del sistema de almacén de datos de origen. Las tablas muy usadas pueden aprovecharse para comprender qué tablas pueden tener muchas dependencias y requieren una planificación adicional durante el proceso de migración.
- Importadores y exportadores
- La vista Importers & Exporters proporciona información sobre los datos y los usuarios involucrados en la importación de datos (con consultas
COPY) y la exportación de datos (con consultasUNLOAD). Esta vista ayuda a identificar la capa de transferencia y los procesos relacionados con la transferencia y las exportaciones. - Uso de clústeres
- La vista Cluster Utilization proporciona información general sobre todos los clústeres disponibles y muestra el uso de CPU de cada clúster. Esta vista puede ayudarte a comprender la reserva de capacidad del sistema.
La sección Estado estable de BigQuery contiene las siguientes vistas:
- Agrupamiento en clústeres y partición
En la vista Partitioning and Clustering, se muestran las tablas que se beneficiarían de la partición, el agrupamiento en clústeres o ambos.
Las sugerencias de metadatos se logran analizando el esquema del almacén de datos de origen (como la clave de ordenamiento y la clave de distribución en la tabla de origen) y buscando el equivalente de BigQuery más cercano para lograr características de optimización similares.
Las sugerencias de cargas de trabajo se obtienen analizando los registros de consultas de origen. La recomendación se determina mediante el análisis de las cargas de trabajo, en especial las cláusulas
WHEREoJOINen los registros de consulta analizados.En la parte inferior de la página, hay una declaración de creación de tabla traducida con todas las optimizaciones proporcionadas. Todas las sentencias DDL traducidas también se pueden extraer del conjunto de datos. Las sentencias DDL traducidas se almacenan en la tabla
SchemaConversionen la columnaCreateTableDDL.Las recomendaciones del informe solo se proporcionan para las tablas de más de 1 GB, ya que las tablas pequeñas no se benefician del agrupamiento en clústeres ni de la partición. Sin embargo, el DDL de todas las tablas (incluidas las tablas de menos de 1 GB) está disponible en la tabla
SchemaConversion.- Tablas sin uso
En la vista Tablas sin uso, se muestran las tablas en las que la evaluación de migración de BigQuery no identificó ningún uso durante el período de registros analizado. La falta de uso puede indicar que no necesitas transferir esa tabla a BigQuery durante la migración o que los costos de almacenamiento de datos en BigQuery pueden ser menores (se facturan como almacenamiento a largo plazo). Te recomendamos que valides la lista de tablas sin usar, ya que podrían tener uso fuera del período de los registros, como una tabla que solo se usa una vez cada tres o seis meses.
- Tablas sin escritura
En la vista Tablas sin escrituras, se muestran las tablas en las que la evaluación de migración de BigQuery no identificó ninguna actualización durante el período de registros analizado. La falta de escrituras puede indicar dónde se pueden reducir los costos de almacenamiento en BigQuery (que se facturan como almacenamiento a largo plazo).
- BigQuery BI Engine y vistas materializadas
BigQuery BI Engine y las vistas materializadas proporcionan sugerencias de optimización adicionales para aumentar el rendimiento en BigQuery.
La sección Ruta de la migración contiene las siguientes vistas:
- Traducción de SQL
- En la vista Traducción de SQL, se enumeran la cantidad y los detalles de las consultas que se convirtieron automáticamente con la evaluación de migración de BigQuery y que no requieren intervención manual. Por lo general, la traducción automática de SQL logra altas tasas de traducción si se proporcionan metadatos.
- Esfuerzo sin conexión de traducción de SQL
- La vista Esfuerzo sin conexión de traducción de SQL captura las áreas que necesitan intervención manual, incluidas las UDF específicas y las consultas con posibles ambigüedades de traducción.
- Compatibilidad con la operación de agregar a la tabla
- La vista Alter Table Append Support muestra detalles sobre las construcciones comunes de SQL de Redshift que no tienen un equivalente directo en BigQuery.
- Compatibilidad con el comando de copia
- La vista Copy Command Support muestra detalles sobre las construcciones comunes de SQL de Redshift que no tienen un equivalente directo en BigQuery.
- Advertencias de SQL
- La vista Advertencias de SQL captura áreas que se traducen correctamente, pero requieren una revisión.
- Incumplimientos de estructura léxica y sintaxis
- En la vista Lexical Structure & Syntax Violations, se muestran los nombres de las columnas, las tablas, las funciones y los procedimientos que incumplen la sintaxis de BigQuery.
- Palabras clave reservadas de BigQuery
- La vista Palabras clave reservadas de BigQuery muestra el uso detectado de palabras clave que tienen un significado especial en el lenguaje GoogleSQL y no se pueden usar como identificadores, a menos que estén encerrados entre caracteres de acento grave (
`). - Acoplamiento de esquemas
- La vista de acoplamiento del esquema proporciona una vista de alto nivel de las bases de datos, los esquemas y las tablas a los que se accede en conjunto en una sola consulta. En esta vista, se puede mostrar a qué tablas, esquemas y bases de datos se hace referencia con frecuencia y qué puedes usar para la planificación de la migración.
- Programa de actualizaciones de la tabla
- En la vista Programa de actualizaciones de tablas, se muestra cuándo y con qué frecuencia se actualizan las tablas para ayudarte a planificar cómo y cuándo moverlas.
- Escala de la tabla
- En la vista Table Scale, se enumeran las tablas con la mayor cantidad de columnas.
- Migración de datos a BigQuery
- La vista Migración de datos a BigQuery describe la ruta de migración con el tiempo esperado para migrar tus datos con el Servicio de migración de BigQuery o el Servicio de transferencia de datos. Para obtener más información, consulta la guía del Servicio de transferencia de datos de BigQuery para Redshift.
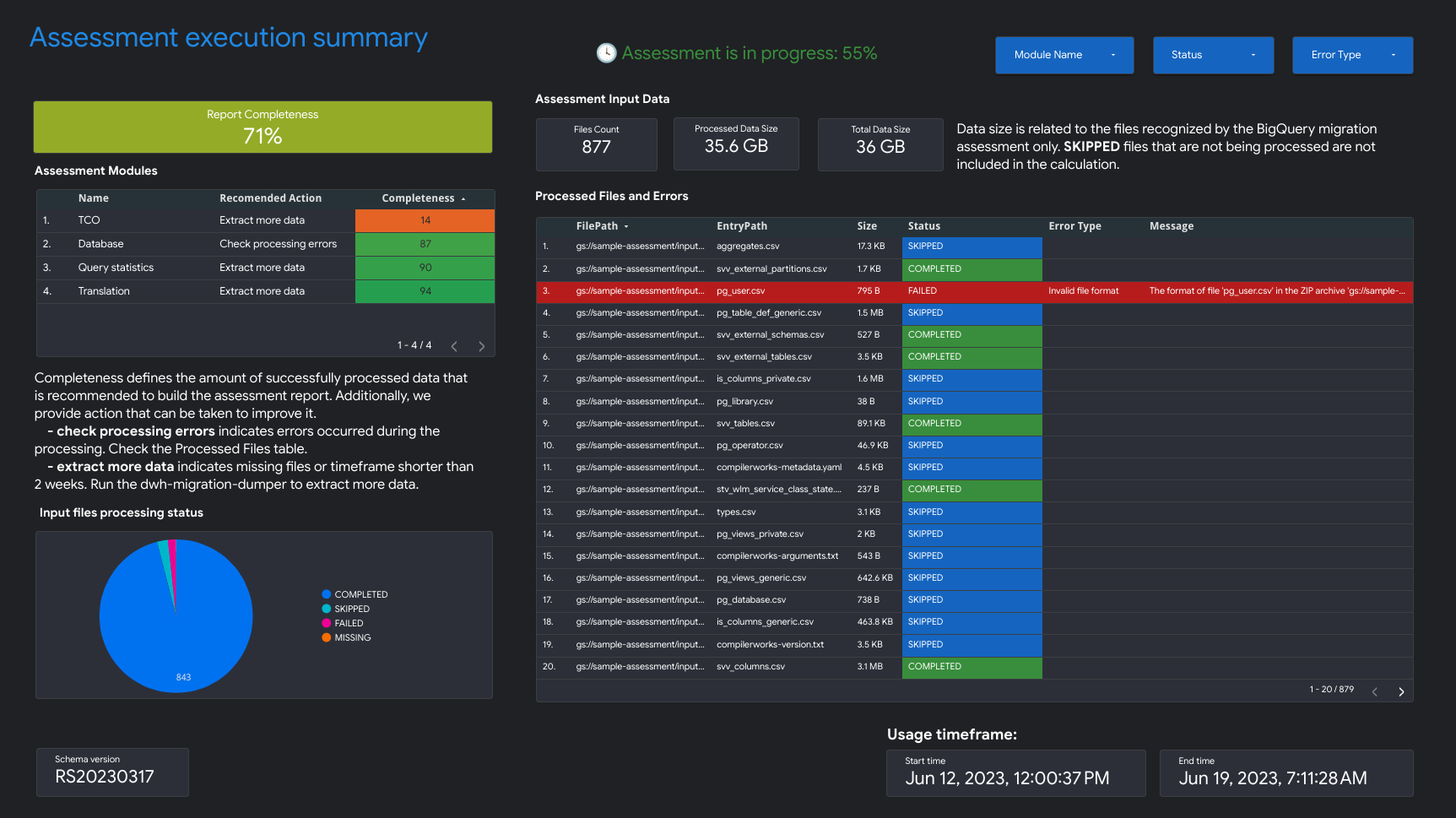
- Resumen de la ejecución de la evaluación
El resumen de ejecución de la evaluación contiene la integridad del informe, el progreso de la evaluación en curso y el estado de los archivos procesados y los errores.
La integridad del informe representa el porcentaje de datos procesados correctamente que se recomienda mostrar para obtener estadísticas significativas en el informe de evaluación. Si faltan los datos de una sección en particular del informe, esta información se muestra en la tabla Módulos de evaluación, debajo del indicador Integridad del informe.
La métrica de progreso indica el porcentaje de datos procesados hasta el momento, junto con la estimación del tiempo restante para procesar todos los datos. Una vez que se completa el procesamiento, no se muestra la métrica de progreso.
Redshift Serverless
- Aspectos destacados de la migración
- En esta página del informe, se muestra el resumen de las bases de datos existentes de Amazon Redshift Serverless, incluidos el tamaño y la cantidad de tablas. Además, proporciona la estimación de alto nivel del valor del contrato anual (ACV), que es el costo de procesamiento y almacenamiento en BigQuery. La vista Aspectos destacados de la migración proporciona un resumen ejecutivo de las tres secciones del informe.
La sección Sistema existente tiene las siguientes vistas:
- Bases de datos y esquemas
- Proporciona un desglose del tamaño total de almacenamiento en GB para cada base de datos, esquema o tabla.
- Bases de datos y esquemas externos
- Proporciona un desglose del tamaño total de almacenamiento en GB para cada base de datos, esquema o tabla externos.
- Uso del sistema
- Proporciona información general sobre el uso histórico del sistema. En esta vista, se muestra el uso histórico de las RPU (unidades de procesamiento de Amazon Redshift) y el consumo de almacenamiento diario. Esta vista puede ayudarte a comprender la reserva de capacidad del sistema.
En la sección Estado de Steady de BigQuery, se proporciona información sobre cómo se verán tus datos después de la migración en BigQuery, incluida la cantidad de consultas que se pueden traducir de forma automática con el servicio de migración de BigQuery. En esta sección, también se muestran los costos de almacenar tus datos en BigQuery según tu tasa anual de transferencia de datos, junto con sugerencias de optimización para tablas, aprovisionamiento y espacio. La sección Estado estable tiene las siguientes vistas:
- Comparación de precios entre Amazon Redshift Serverless y BigQuery
- Proporciona una comparación de los modelos de precios de Amazon Redshift Serverless y BigQuery para ayudarte a comprender los beneficios y los posibles ahorros de costos después de migrar a BigQuery.
- Costo de procesamiento de BigQuery (TCO)
- Te permite estimar el costo de procesamiento en BigQuery. La calculadora tiene cuatro entradas manuales: edición de BigQuery, región, período de compromiso y valor de referencia. De forma predeterminada, la calculadora proporciona compromisos de referencia óptimos y rentables que puedes anular manualmente.
- Costo total de propiedad
- Te permite estimar el valor del contrato anual (ACV), es decir, el costo de procesamiento y almacenamiento en BigQuery. La calculadora también te permite calcular el costo de almacenamiento, que varía para el almacenamiento activo y el almacenamiento a largo plazo, según las modificaciones de la tabla durante el período analizado. Para obtener más información, consulta los precios de almacenamiento.
La sección Apéndice contiene esta vista:
- Resumen de la ejecución de la evaluación
- Proporciona los detalles de la ejecución de la evaluación, incluida la lista de archivos procesados, los errores y la integridad del informe. Puedes usar esta página para investigar los datos faltantes en el informe y comprender mejor su integridad.
Snowflake
El informe consta de diferentes secciones que se pueden usar por separado o juntas. En el siguiente diagrama, se organizan estas secciones en tres objetivos de usuario comunes para ayudarte a evaluar tus necesidades de migración:
Vistas destacadas de migración
La sección Aspectos destacados de la migración contiene las siguientes vistas:
- Modelos de precios de Snowflake en comparación con BigQuery
- Enumera los precios con diferentes ediciones o niveles. También se incluye una ilustración de cómo el ajuste de escala automático de BigQuery puede ayudar a ahorrar más costos en comparación con el de Snowflake.
- Costo total de propiedad
- Tabla interactiva, que permite al usuario definir: edición de BigQuery, compromiso, compromiso de la ranura del modelo de referencia, porcentaje de almacenamiento activo y porcentaje de datos cargados o modificados. Ayuda a estimar mejor el costo de los casos personalizados.
- Aspectos destacados de la traducción automática
- Proporción de traducción agregada, agrupada por usuario o base de datos, ordenada de forma ascendente o descendente. También incluye el mensaje de error más común para la traducción automática con errores.
Vistas del sistema existente
La sección Sistema existente contiene las siguientes vistas:
- Descripción general del sistema
- La vista de descripción general del sistema proporciona las métricas de volumen de alto nivel de los componentes clave en el sistema existente durante un período específico. El cronograma que se evalúa depende de los registros que se analizaron en la evaluación de migración de BigQuery. Esta vista te brinda estadísticas rápidas sobre el uso del almacén de datos de origen, que puedes usar para la planificación de la migración.
- Descripción general de los almacenes virtuales
- Muestra el costo de Snowflake por almacén, así como el reescalamiento basado en nodos durante el período.
- Volumen de tablas
- En la vista Volumen de tablas, se proporcionan estadísticas sobre las tablas y bases de datos más grandes que se encuentran en la evaluación de migración de BigQuery. Debido a que las tablas grandes pueden tardar más en extraerse del sistema de almacén de datos de origen, esta vista puede ser útil en la planificación y la secuencia de la migración.
- Uso de tablas
- En la vista Uso de tablas, se proporcionan estadísticas sobre qué tablas se usan mucho dentro del sistema de almacén de datos de origen. Las tablas muy usadas pueden ayudarte a comprender qué tablas pueden tener muchas dependencias y requieren una planificación adicional durante el proceso de migración.
- Consultas
- La vista Consultas proporciona un desglose de los tipos de instrucciones de SQL ejecutadas y las estadísticas de su uso. Puedes usar el histograma de Tiempo y Tipo de consulta para identificar los períodos bajos del uso del sistema y los momentos óptimos del día para transferir datos. También puedes usar esta vista para identificar las consultas que se ejecutan con frecuencia y los usuarios que invocan esas ejecuciones.
- Bases de datos
- La vista de bases de datos proporciona métricas sobre el tamaño, las tablas, las vistas y los procedimientos definidos en el sistema de almacén de datos de origen. Esta vista proporciona observaciones sobre el volumen de objetos que necesitas migrar.
Vistas de estado estable de BigQuery
La sección Estado estable de BigQuery contiene las siguientes vistas:
- Tablas sin uso
- En la vista Tablas sin uso, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ningún uso durante el período de registros que se analizó. Esto puede indicar qué tablas no necesitan transferirse a BigQuery durante la migración o que los costos de almacenamiento de datos en BigQuery pueden ser menores. Debes validar la lista de tablas sin usar, ya que podrían tener uso fuera del período de registros analizado, como una tabla que solo se usa una vez por trimestre o por semestre.
- Tablas sin escritura
- En la vista Tablas sin escrituras, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ninguna actualización durante el período de registros que se analizó. Esto puede indicar que los costos de almacenamiento de datos en BigQuery podrían ser menores.
Vistas del plan de migración
La sección Plan de migración del informe contiene las siguientes vistas:
- Traducción de SQL
- En la vista Traducción de SQL, se enumeran la cantidad y los detalles de las consultas que se convirtieron automáticamente con la evaluación de migración de BigQuery y que no requieren intervención manual. Por lo general, la traducción automática de SQL alcanza altas tasas de traducción si se proporcionan metadatos. Esta vista es interactiva y permite el análisis de consultas comunes y cómo se traducen.
- Esfuerzo sin conexión de traducción de SQL
- La vista Esfuerzo sin conexión captura las áreas que necesitan intervención manual, incluidas las UDF específicas y las posibles infracciones de sintaxis y estructura léxicas para las tablas o columnas.
- Advertencias de SQL: Revisión
- La vista Advertencias para revisar captura las áreas que se traducen, pero requieren cierta inspección manual.
- Palabras clave reservadas de BigQuery
- La vista Palabras clave reservadas de BigQuery muestra el uso detectado de palabras clave que tienen un significado especial en el lenguaje GoogleSQL y no se pueden usar como identificadores, a menos que estén encerrados entre caracteres de acento grave (
`). - Acoplamiento de bases de datos y tablas
- La vista de acoplamiento de la base de datos proporciona una vista de alto nivel en las bases de datos y tablas a las que se accede en conjunto en una sola consulta. En esta vista, se puede ver a qué tablas y bases de datos se hace referencia a menudo y qué se puede usar para la planificación de la migración.
- Programa de actualizaciones de la tabla
- En la vista Programa de actualizaciones de tablas, se muestra cuándo y con qué frecuencia se actualizan las tablas para ayudarte a planificar cómo y cuándo moverlas.
Vista de prueba de concepto
La sección PoC (prueba de concepto) contiene las siguientes vistas:
- PoC para demostrar los ahorros de estado estable de BigQuery
- Incluye las consultas más frecuentes, las consultas que leen la mayor cantidad de datos, las consultas más lentas y las tablas afectadas por estas consultas.
- PoC para demostrar el plan de migración de BigQuery
- Muestra cómo BigQuery traduce las consultas más complejas y las tablas a las que afectan.
Oracle
Para solicitar comentarios o asistencia para esta función, envía un correo electrónico a bq-edw-migration-support@google.com.
Aspectos destacados de la migración
La sección Aspectos destacados de la migración contiene las siguientes vistas:
- Sistema existente: Es una instantánea del sistema y el uso de Oracle existentes, incluida la cantidad de bases de datos, esquemas, tablas y el tamaño total en GB. También proporciona el resumen de clasificación de la carga de trabajo para cada base de datos, lo que te ayuda a decidir si BigQuery es el destino de migración adecuado.
- Compatibilidad: Proporciona información sobre el esfuerzo de migración. Para cada base de datos analizada, se muestra el tiempo estimado de migración y la cantidad de objetos de base de datos que se pueden migrar automáticamente con las herramientas proporcionadas por Google.
- Estado de Steady de BigQuery: Contiene información sobre cómo se verán tus datos después de la migración en BigQuery, incluidos los costos de almacenamiento de tus datos en BigQuery según tu tasa anual de transferencia de datos y la estimación de costos de procesamiento. Además, proporciona estadísticas sobre las tablas que no se utilizan lo suficiente.
Sistema existente
La sección Sistema existente contiene las siguientes vistas:
- Característica de cargas de trabajo: Describe el tipo de carga de trabajo para cada base de datos según las métricas de rendimiento analizadas. Cada base de datos se clasifica como OLAP, mixta o OLTP. Esta información puede ayudarte a decidir qué bases de datos se pueden migrar a BigQuery.
- Bases de datos y esquemas: Proporciona un desglose del tamaño total de almacenamiento en GB para cada base de datos, esquema o tabla. Además, puedes usar esta vista para identificar vistas materializadas y tablas externas.
- Funciones y vínculos de la base de datos: Muestra la lista de las funciones de Oracle que se usan en tu base de datos, junto con las funciones o los servicios equivalentes de BigQuery que se pueden usar después de la migración. Además, puedes explorar los vínculos de la base de datos para comprender mejor las conexiones entre las bases de datos.
- Conexiones de bases de datos: Proporciona estadísticas sobre las sesiones de bases de datos iniciadas por el usuario o la aplicación. Analizar estos datos puede ayudarte a identificar las aplicaciones externas que pueden requerir un esfuerzo adicional durante la migración.
- Tipos de consultas: Proporciona un desglose de los tipos de instrucciones de SQL ejecutadas y las estadísticas de su uso. Puedes usar el histograma por hora de Ejecuciones de consultas o Tiempo de CPU de consultas para identificar los períodos bajos del uso del sistema y los momentos óptimos del día para transferir datos.
- Código fuente de PL/SQL: Proporciona estadísticas sobre los objetos de PL/SQL, como funciones o procedimientos, y su tamaño para cada base de datos y esquema. Además, el histograma de ejecuciones por hora se puede usar para identificar las horas pico con la mayor cantidad de ejecuciones de PL/SQL.
- Uso del sistema: Proporciona información general sobre el uso histórico del sistema. En esta vista, se muestra el uso por hora de la CPU y el consumo de almacenamiento diario. Esta vista puede ayudarte a comprender la reserva de capacidad del sistema.
Estado estable de BigQuery
La sección Estado estable de BigQuery contiene las siguientes vistas:
- Comparación de precios de Exadata y BigQuery: Proporciona la comparación general de los modelos de precios de Exadata y BigQuery para ayudarte a comprender los beneficios y los posibles ahorros de costos después de la migración a BigQuery.
- Lecturas y escrituras de la base de datos de BigQuery: Proporciona estadísticas sobre las operaciones de disco físico de la base de datos. Analizar estos datos puede ayudarte a encontrar el mejor momento para migrar datos de Oracle a BigQuery.
- Costo de procesamiento de BigQuery: Te permite estimar el costo de procesamiento en BigQuery. Hay cuatro entradas manuales en la calculadora: Edición de BigQuery, Región, Período de compromiso y Referencia. De forma predeterminada, la calculadora proporciona un compromiso de referencia óptimo y rentable que puedes anular manualmente. El valor de Horas de ranura con ajuste de escala automático anuales proporciona la cantidad de horas de ranura que se usaron fuera del compromiso. Este valor se calcula con la utilización del sistema. Al final de la página, se proporciona una explicación visual de las relaciones entre la referencia, el ajuste de escala automático y la utilización. Cada estimación muestra la cantidad probable y un rango de estimación.
- Costo total de propiedad (TCO): Te permite estimar el valor anual del contrato (ACV), es decir, el costo de procesamiento y almacenamiento en BigQuery. La calculadora también te permite calcular el costo de almacenamiento. La calculadora también te permite calcular el costo de almacenamiento, que varía para el almacenamiento activo y el almacenamiento a largo plazo, según las modificaciones de la tabla durante el período analizado. Para obtener más información sobre los precios de almacenamiento, consulta Precios de almacenamiento.
- Tablas subutilizadas: Proporciona información sobre las tablas sin usar y de solo lectura según las métricas de uso del período analizado. La falta de uso puede indicar que no necesitas transferir la tabla a BigQuery durante una migración o que los costos de almacenamiento de datos en BigQuery pueden ser menores (se facturan como almacenamiento a largo plazo). Te recomendamos que valides la lista de tablas sin usar en caso de que tengan uso fuera del período analizado.
Sugerencias de migración
La sección Sugerencias para la migración contiene las siguientes vistas:
- Compatibilidad de objetos de base de datos: Proporciona una descripción general de la compatibilidad de los objetos de base de datos con BigQuery, incluida la cantidad de objetos que se pueden migrar automáticamente con las herramientas proporcionadas por Google o que requieren una acción manual. Esta información se muestra para cada base de datos, esquema y tipo de objeto de base de datos.
- Esfuerzo de migración de objetos de base de datos: Muestra la estimación del esfuerzo de migración en horas para cada base de datos, esquema o tipo de objeto de base de datos. Además, muestra el porcentaje de objetos pequeños, medianos y grandes según el esfuerzo de migración.
- Esfuerzo de migración del esquema de la base de datos: Proporciona la lista de todos los tipos de objetos de la base de datos detectados, su cantidad, la compatibilidad con BigQuery y el esfuerzo de migración estimado en horas.
- Database Schema Migration Effort Detailed: Proporciona información más detallada sobre el esfuerzo de migración del esquema de la base de datos, incluida la información de cada objeto individual.
Vista de prueba de concepto
La sección Vistas de prueba de concepto contiene las siguientes vistas:
- Migración de prueba de concepto: Muestra la lista sugerida de bases de datos con el menor esfuerzo de migración que son buenas candidatas para la migración inicial. Además, muestra las principales consultas que pueden ayudar a demostrar el ahorro de tiempo y costos, y el valor de BigQuery con una prueba de concepto.
Apéndice
La sección Apéndice contiene las siguientes vistas:
- Resumen de ejecución de la evaluación: Proporciona los detalles de la ejecución de la evaluación, incluida la lista de archivos procesados, los errores y la integridad del informe. Puedes usar esta página para investigar los datos faltantes en el informe y comprender mejor su integridad general.
Apache Hive
El informe que consta de una narrativa de tres partes está precedido por una página de puntos destacados de resumen que incluye las siguientes secciones:
Sistema existente: Apache Hive. En esta sección, se incluye una instantánea del sistema y el uso de Apache Hive existentes, incluida la cantidad de bases de datos, tablas, su tamaño total en GB y la cantidad de registros de consultas procesados. En esta sección, también se enumeran las bases de datos por tamaño y se apunta al posible uso de recursos deficientes (tablas sin escrituras o pocas lecturas) y el aprovisionamiento. Los detalles de esta sección incluyen lo siguiente:
- Procesamiento y consultas
- Uso de CPU:
- Consultas por hora y día con uso de CPU
- Consultas por tipo (lectura/escritura)
- Colas y aplicaciones
- Superposición del uso de CPU por hora con el rendimiento de consultas por hora promedio y el rendimiento promedio de las aplicaciones por hora
- Consulta histogramas por tipo y duración de las consultas
- Página en cola y en espera
- Vista detallada de colas (cola, usuario, consultas únicas, desglose de informes y ETL, por métricas)
- Uso de CPU:
- Descripción general del almacenamiento
- Bases de datos por volumen, vistas y tasas de acceso
- Tablas con tasas de acceso de los usuarios, consultas, escrituras y creación de tablas temporales
- Colas y aplicaciones: tasas de acceso y direcciones IP de cliente
- Procesamiento y consultas
Estado estable de BigQuery. En esta sección, se muestra cómo se verá el sistema en BigQuery después de la migración. Incluye sugerencias para optimizar las cargas de trabajo en BigQuery (y evitar el desperdicio). Los detalles de esta sección incluyen lo siguiente:
- Tablas identificadas como candidatas para vistas materializadas.
- Se agrupan en clústeres y se particionan los candidatos en función de los metadatos y el uso.
- Consultas de baja latencia identificadas como candidatas para BigQuery BI Engine
- Tablas sin uso de lectura o escritura
- Tablas particionadas con sesgo de datos
Plan de migración. En esta sección, se proporciona información sobre el esfuerzo de migración. Por ejemplo, pasar del sistema existente al estado estable de BigQuery. En esta sección, se muestran los objetivos de almacenamiento identificados para cada tabla, las tablas identificadas como significativas para la migración y el recuento de consultas que se tradujeron de forma automática. Los detalles de esta sección incluyen lo siguiente:
- Vista detallada con consultas traducidas de forma automática
- Recuento de consultas totales con capacidad para filtrar por usuario, aplicación, tablas afectadas, tablas consultadas y tipo de consulta.
- Buckets de consultas con patrones similares agrupados, lo que permite a los usuarios ver la filosofía de traducción por tipo de consulta
- Consultas que requieren intervención humana
- Consultas con incumplimientos de estructura léxica de BigQuery
- Funciones y procedimientos definidos por el usuario
- Palabras clave reservadas de BigQuery
- Consulta que requiere revisión
- Tablas programadas por escrituras y lecturas (para agruparlas a fin de moverlas)
- Destino de almacenamiento identificado para tablas externas y administradas
- Vista detallada con consultas traducidas de forma automática
La sección Sistema existente - Hive contiene las siguientes vistas:
- Descripción general del sistema
- Esta vista proporciona las métricas de volumen de alto nivel de los componentes clave en el sistema existente durante un período específico. El cronograma que se evalúa depende de los registros que se analizaron en la evaluación de migración de BigQuery. Esta vista te brinda estadísticas rápidas sobre el uso del almacén de datos de origen, que puedes usar para la planificación de la migración.
- Volumen de tablas
- En esta vista, se proporcionan estadísticas sobre las tablas y bases de datos más grandes que se encuentran en la evaluación de migración de BigQuery. Debido a que las tablas grandes pueden tardar más en extraerse del sistema de almacén de datos de origen, esta vista puede ser útil en la planificación y la secuencia de la migración.
- Uso de tablas
- En esta vista, se proporcionan estadísticas sobre qué tablas se usan mucho dentro del sistema de almacén de datos de origen. Las tablas muy usadas pueden ayudarte a comprender qué tablas pueden tener muchas dependencias y requieren una planificación adicional durante el proceso de migración.
- Uso de colas
- En esta vista, se proporcionan estadísticas sobre el uso de las colas de YARN que se encontraron durante el procesamiento de los registros. Estas vistas permiten a los usuarios comprender el uso de colas y aplicaciones específicas a lo largo del tiempo y el impacto en el uso de recursos. Estas vistas también ayudan a identificar y priorizar las cargas de trabajo para la migración. Durante una migración, es importante visualizar la transferencia y el consumo de datos para comprender mejor las dependencias del almacén de datos y analizar el impacto de mover varias aplicaciones dependientes juntas. La tabla Direcciones IP puede ser útil para identificar la aplicación exacta que usa el almacén de datos a través de conexiones de JDBC.
- Métricas de colas
- Esta vista proporciona un desglose de las diferentes métricas en las colas YARN que se encuentran durante el procesamiento de los registros. Esta vista permite a los usuarios comprender los patrones de uso en colas específicas y el impacto en la migración. También puedes usar esta vista para identificar conexiones entre tablas a las que se accede en consultas y colas en las que se ejecutó la consulta.
- Cola y espera
- En esta vista, se proporciona una estadística sobre el tiempo en cola de la consulta en el almacén de datos de origen. Los tiempos en cola indican una degradación del rendimiento debido al aprovisionamiento insuficiente, y el aprovisionamiento adicional requiere mayores costos de hardware y mantenimiento.
- Consultas
- En esta vista, se proporciona un desglose de los tipos de instrucciones de SQL ejecutadas y las estadísticas de su uso. Puedes usar el histograma de Tiempo y tipo de consulta para identificar los períodos bajos del uso del sistema y los momentos óptimos del día para transferir datos. También puedes usar esta vista para identificar los motores de ejecución de Hive más usados y las consultas ejecutadas con frecuencia junto con los detalles del usuario.
- Bases de datos
- En esta vista, se proporcionan métricas sobre el tamaño, las tablas, las vistas y los procedimientos definidos en el sistema de almacén de datos de origen. Esta vista puede proporcionar estadísticas sobre el volumen de objetos que necesitas migrar.
- Acoplamiento de bases de datos y tablas
- Esta vista proporciona una vista de alto nivel de las bases de datos y tablas a las que se accede en una sola consulta. En esta vista, se puede mostrar a qué tablas y bases de datos se hace referencia con frecuencia y qué puedes usar para la planificación de la migración.
La sección Estado estable de BigQuery contiene las siguientes vistas:
- Tablas sin uso
- En la vista Tablas sin uso, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ningún uso durante el período de registros que se analizó. La falta de uso puede indicar que no necesitas transferir esa tabla a BigQuery durante la migración o que los costos de almacenamiento de datos en BigQuery pueden ser menores. Debes validar la lista de tablas sin usar, ya que podrían tener uso fuera del período de los registros, como una tabla que solo se usa una vez cada tres o seis meses.
- Tablas sin escritura
- En la vista Tablas sin escrituras, se muestran las tablas en las que la evaluación de migración de BigQuery no pudo encontrar ninguna actualización durante el período de registros que se analizó. La falta de escrituras puede indicar dónde se pueden reducir los costos de almacenamiento en BigQuery.
- Recomendaciones de agrupamiento en clústeres y partición
En esta vista, se muestran las tablas que se beneficiarían de la partición, el agrupamiento en clústeres o ambos.
Las sugerencias de metadatos se logran analizando el esquema del almacén de datos de origen (como la partición y la clave principal en la tabla de origen) y buscando el equivalente de BigQuery más cercano para lograr características de optimización similares.
Las sugerencias de cargas de trabajo se obtienen analizando los registros de consultas de origen. La recomendación se determina mediante el análisis de las cargas de trabajo, en especial las cláusulas
WHEREoJOINen los registros de consulta analizados.- Particiones convertidas en clústeres
En esta vista, se muestran tablas que tienen más de 10,000 particiones, según su definición de restricción de partición. Estas tablas suelen ser buenas candidatas para el agrupamiento en clústeres de BigQuery, lo que permite particiones de tabla detalladas.
- Particiones sesgadas
La vista de particiones sesgadas muestra tablas que se basan en el análisis de metadatos y tienen sesgo de datos en una o varias particiones. Estas tablas son buenas candidatas para el cambio de esquema, ya que las consultas en particiones sesgadas podrían no tener un buen rendimiento.
- BI Engine y vistas materializadas
La vista Consultas de baja latencia y Vistas materializadas muestran una distribución de entornos de ejecución de consultas en función de los datos de registro analizados y más sugerencias de optimización para aumentar el rendimiento en BigQuery. Si el gráfico de distribución de la duración de la consulta muestra una gran cantidad de consultas con un tiempo de ejecución inferior a 1 segundo, considera habilitar BI Engine para acelerar la IE y otras cargas de trabajo de baja latencia.
La sección Plan de migración del informe contiene las siguientes vistas:
- Traducción de SQL
- En la vista Traducción de SQL, se enumeran la cantidad y los detalles de las consultas que se convirtieron automáticamente con la evaluación de migración de BigQuery y que no requieren intervención manual. Por lo general, la traducción automática de SQL alcanza altas tasas de traducción si se proporcionan metadatos. Esta vista es interactiva y permite el análisis de consultas comunes y cómo se traducen.
- Esfuerzo sin conexión de traducción de SQL
- La vista Esfuerzo sin conexión captura las áreas que necesitan intervención manual, incluidas las UDF específicas y las posibles infracciones de sintaxis y estructura léxicas para las tablas o columnas.
- Advertencias de SQL
- La vista Advertencias de SQL captura áreas que se traducen correctamente, pero requieren una revisión.
- Palabras clave reservadas de BigQuery
- En la vista Palabras clave reservadas de BigQuery, se muestra el uso detectado de las palabras clave que tienen un significado especial en el lenguaje GoogleSQL.
Estas palabras clave no se pueden usar como identificadores, a menos que estén encerradas entre caracteres de acento grave (
`). - Programa de actualizaciones de la tabla
- En la vista Programa de actualizaciones de tablas, se muestra cuándo y con qué frecuencia se actualizan las tablas para ayudarte a planificar cómo y cuándo moverlas.
- Tablas externas de BigLake
- En la vista de tablas externas de BigLake, se describen las tablas que se identifican como destinos de migración a BigLake en lugar de BigQuery.
La sección Apéndice del informe contiene las siguientes vistas:
- Análisis detallado del esfuerzo sin conexión de la traducción de SQL
- La vista Análisis detallado del esfuerzo sin conexión proporciona una estadística adicional de las áreas de SQL que necesitan intervención manual.
- Análisis detallado de advertencias de SQL
- La vista Análisis detallado de las advertencias proporciona una estadística adicional de las áreas de SQL que se traducen de forma correcta, pero requieren una revisión.
Comparte el informe
El informe de Looker Studio es un panel de frontend para la evaluación de la migración. Se basa en los permisos de acceso al conjunto de datos subyacente. Para compartir el informe, el destinatario debe tener acceso al informe de Looker Studio y al conjunto de datos de BigQuery que contiene los resultados de la evaluación.
Cuando abres el informe desde la consola de Google Cloud , lo ves en el modo de vista previa. Para crear y compartir el informe con otros usuarios, realiza los siguientes pasos:
- Haz clic en Editar y compartir. Looker Studio te solicita que adjuntes los conectores de Looker Studio recién creados al informe nuevo.
- Haga clic en Agregar al informe. El informe recibe un ID de informe individual, que puedes usar para acceder al informe.
- Para compartir el informe de Looker Studio con otros usuarios, sigue los pasos proporcionados en Comparte informes con usuarios y editores.
- Otorga permiso a los usuarios para ver el conjunto de datos de BigQuery que se usó a fin de ejecutar la tarea de evaluación. Para obtener más información, consulta Otorga acceso a un conjunto de datos.
Consulta las tablas de resultados de la evaluación de migración
Aunque los informes de Looker Studio son la forma más conveniente de ver los resultados de la evaluación, también puedes consultar los datos subyacentes en el conjunto de datos de BigQuery.
Consulta de ejemplo
En el ejemplo siguiente, se obtiene la cantidad total de consultas únicas, la cantidad de consultas que fallaron en la traducción y el porcentaje de consultas únicas que fallaron.
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
Comparte tu conjunto de datos con usuarios de otros proyectos
Después de inspeccionar el conjunto de datos, si deseas compartirlo con un usuario que no está en tu proyecto, puedes hacerlo con el flujo de trabajo del publicador de BigQuery sharing (anteriormente Analytics Hub).
En la consola de Google Cloud , ve a la página BigQuery.
Haz clic en el conjunto de datos para ver sus detalles.
Haz clic en Compartir > Publicar como ficha.
En el diálogo que se abre, crea una ficha según las indicaciones.
Si ya tienes un intercambio de datos, omite el paso 5.
Crea un intercambio de datos y establece permisos. Para permitir que un usuario vea tus fichas en este intercambio, agrégalo a la lista de Suscriptores.
Ingresa los detalles de la ficha.
Nombre visible es el nombre de esta ficha y es obligatorio. Los demás campos son opcionales.
Haz clic en Publicar.
Se crea una ficha privada.
En tu ficha, selecciona Más acciones en Acciones.
Haz clic en Copiar vínculo para compartir.
Puedes compartir el vínculo con los usuarios que tienen acceso por suscripción a tu intercambio o ficha.
Esquemas de tablas de evaluación
Para ver las tablas y sus esquemas que la evaluación de migración de BigQuery escribe en BigQuery, selecciona tu almacén de datos:
Teradata
AllRIChildren
En esta tabla, se proporciona información de integridad referencial de los elementos secundarios de la tabla.
| Columna | Tipo | Descripción |
|---|---|---|
IndexId |
INTEGER |
Es el número de índice de referencia. |
IndexName |
STRING |
Es el nombre del índice. |
ChildDB |
STRING |
El nombre de la base de datos a la que se hace referencia, convertido en minúsculas. |
ChildDBOriginal |
STRING |
El nombre de la base de datos de referencia, con el caso de mayúsculas preservado. |
ChildTable |
STRING |
El nombre de la tabla de referencia, convertido en minúsculas. |
ChildTableOriginal |
STRING |
El nombre de la tabla de referencia, con el caso preservado. |
ChildKeyColumn |
STRING |
El nombre de una columna en la clave de referencia, convertido en minúsculas. |
ChildKeyColumnOriginal |
STRING |
El nombre de una columna en la clave de referencia con el caso preservado. |
ParentDB |
STRING |
El nombre de la base de datos a la que se hace referencia, convertido en minúsculas. |
ParentDBOriginal |
STRING |
El nombre de la base de datos a la que se hace referencia, con el caso de mayúsculas preservado. |
ParentTable |
STRING |
El nombre de la tabla a la que se hace referencia, convertido en minúsculas. |
ParentTableOriginal |
STRING |
El nombre de la tabla a la que se hace referencia, con el caso preservado. |
ParentKeyColumn |
STRING |
El nombre de la columna en una clave a la que se hace referencia, convertido en minúsculas. |
ParentKeyColumnOriginal |
STRING |
El nombre de la columna en una clave de referencia, con el caso preservado. |
AllRIParents
En esta tabla, se proporciona la información de integridad referencial de los elementos superiores de la tabla.
| Columna | Tipo | Descripción |
|---|---|---|
IndexId |
INTEGER |
Es el número de índice de referencia. |
IndexName |
STRING |
Es el nombre del índice. |
ChildDB |
STRING |
El nombre de la base de datos a la que se hace referencia, convertido en minúsculas. |
ChildDBOriginal |
STRING |
El nombre de la base de datos de referencia, con el caso de mayúsculas preservado. |
ChildTable |
STRING |
El nombre de la tabla de referencia, convertido en minúsculas. |
ChildTableOriginal |
STRING |
El nombre de la tabla de referencia, con el caso preservado. |
ChildKeyColumn |
STRING |
El nombre de una columna en la clave de referencia, convertido en minúsculas. |
ChildKeyColumnOriginal |
STRING |
El nombre de una columna en la clave de referencia con el caso preservado. |
ParentDB |
STRING |
El nombre de la base de datos a la que se hace referencia, convertido en minúsculas. |
ParentDBOriginal |
STRING |
El nombre de la base de datos a la que se hace referencia, con el caso de mayúsculas preservado. |
ParentTable |
STRING |
El nombre de la tabla a la que se hace referencia, convertido en minúsculas. |
ParentTableOriginal |
STRING |
El nombre de la tabla a la que se hace referencia, con el caso preservado. |
ParentKeyColumn |
STRING |
El nombre de la columna en una clave a la que se hace referencia, convertido en minúsculas. |
ParentKeyColumnOriginal |
STRING |
El nombre de la columna en una clave de referencia, con el caso preservado. |
Columns
En esta tabla, se proporciona información sobre las columnas.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. |
TableNameOriginal |
STRING |
El nombre de la tabla con el caso preservado. |
ColumnName |
STRING |
El nombre de la columna, convertido en minúsculas. |
ColumnNameOriginal |
STRING |
El nombre de la columna con el caso preservado. |
ColumnType |
STRING |
Es el tipo de BigQuery de la columna, como STRING. |
OriginalColumnType |
STRING |
El tipo original de la columna, como VARCHAR. |
ColumnLength |
INTEGER |
Es la cantidad máxima de bytes de la columna, como 30 para VARCHAR(30). |
DefaultValue |
STRING |
Es el valor predeterminado, si existe. |
Nullable |
BOOLEAN |
Indica si la columna acepta valores nulos. |
DiskSpace
En esta tabla, se proporciona información sobre el uso del espacio en disco de cada base de datos.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
MaxPerm |
INTEGER |
Es la cantidad máxima de bytes asignados al espacio permanente. |
MaxSpool |
INTEGER |
Es la cantidad máxima de bytes asignados al espacio de cola. |
MaxTemp |
INTEGER |
Es la cantidad máxima de bytes asignados al espacio temporal. |
CurrentPerm |
INTEGER |
Es la cantidad de bytes asignados al espacio permanente. |
CurrentSpool |
INTEGER |
Es la cantidad de bytes asignados al espacio de cola. |
CurrentTemp |
INTEGER |
Es la cantidad de bytes asignados al espacio temporal. |
PeakPerm |
INTEGER |
La cantidad máxima de bytes usados desde el último restablecimiento del espacio permanente. |
PeakSpool |
INTEGER |
La cantidad máxima de bytes usados desde el último restablecimiento del espacio de cola. |
PeakPersistentSpool |
INTEGER |
La cantidad máxima de bytes usados desde el último restablecimiento del espacio persistente. |
PeakTemp |
INTEGER |
La cantidad máxima de bytes usados desde el último restablecimiento del espacio temporal. |
MaxProfileSpool |
INTEGER |
Es el límite de espacio de cola para el usuario. |
MaxProfileTemp |
INTEGER |
Es el límite de espacio temporal para el usuario. |
AllocatedPerm |
INTEGER |
La asignación actual del espacio permanente. |
AllocatedSpool |
INTEGER |
La asignación actual del espacio en cola. |
AllocatedTemp |
INTEGER |
La asignación actual del espacio temporal. |
Functions
En esta tabla, se proporciona información sobre las funciones.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
FunctionName |
STRING |
Es el nombre de la función. |
LanguageName |
STRING |
El nombre del idioma. |
Indices
En esta tabla, se proporciona información sobre los índices.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. |
TableNameOriginal |
STRING |
El nombre de la tabla con el caso preservado. |
IndexName |
STRING |
Es el nombre del índice. |
ColumnName |
STRING |
El nombre de la columna, convertido en minúsculas. |
ColumnNameOriginal |
STRING |
El nombre de la columna con el caso preservado. |
OrdinalPosition |
INTEGER |
Es la posición de la columna. |
UniqueFlag |
BOOLEAN |
Indica si el índice aplica la unicidad. |
Queries
En esta tabla, se proporciona información sobre las consultas extraídas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
QueryText |
STRING |
Es el texto de la consulta. |
QueryLogs
Esta tabla proporciona algunas estadísticas de ejecución sobre las consultas extraídas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. |
QueryHash |
STRING |
El hash de la consulta. |
QueryId |
STRING |
El ID de la consulta. |
QueryType |
STRING |
Es el tipo de consulta, ya sea Query o DDL. |
UserId |
BYTES |
El ID del usuario que ejecutó la consulta. |
UserName |
STRING |
El nombre del usuario que ejecutó la consulta. |
StartTime |
TIMESTAMP |
Es la marca de tiempo del momento en que se envió la consulta. |
Duration |
STRING |
Es la duración de la búsqueda en milisegundos. |
AppId |
STRING |
El ID de la aplicación que ejecutó la consulta. |
ProxyUser |
STRING |
Es el usuario del proxy cuando se usa a través de un nivel intermedio. |
ProxyRole |
STRING |
Es el rol del proxy cuando se usa a través de un nivel intermedio. |
QueryTypeStatistics
En esta tabla, se proporcionan estadísticas sobre los tipos de consultas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
QueryType |
STRING |
El tipo de consulta. |
UpdatedTable |
STRING |
Es la tabla que actualizó la consulta, si la hubiera. |
QueriedTables |
ARRAY<STRING> |
Es una lista de las tablas que se consultaron. |
ResUsageScpu
En esta tabla, se proporciona información sobre el uso de recursos de CPU.
| Columna | Tipo | Descripción |
|---|---|---|
EventTime |
TIMESTAMP |
Es la hora del evento. |
NodeId |
INTEGER |
ID de nodo |
CabinetId |
INTEGER |
Es el número de gabinete físico del nodo. |
ModuleId |
INTEGER |
Es el número de módulo físico del nodo. |
NodeType |
STRING |
Es el tipo de nodo. |
CpuId |
INTEGER |
Es el ID de la CPU dentro de este nodo. |
MeasurementPeriod |
INTEGER |
Es el período de la medición expresado en centisegundos. |
SummaryFlag |
STRING |
S: Fila de resumen; N: Fila que no es de resumen |
CpuFrequency |
FLOAT |
Frecuencia de la CPU en MHz. |
CpuIdle |
FLOAT |
Es el tiempo de inactividad de la CPU expresado en centisegundos. |
CpuIoWait |
FLOAT |
Es el tiempo que la CPU espera la E/S, expresado en centisegundos. |
CpuUServ |
FLOAT |
Es el tiempo que la CPU dedica a ejecutar el código del usuario, expresado en centisegundos. |
CpuUExec |
FLOAT |
Es el tiempo que la CPU ejecuta el código de servicio, expresado en centisegundos. |
Roles
En esta tabla, se proporciona información sobre los roles.
| Columna | Tipo | Descripción |
|---|---|---|
RoleName |
STRING |
El nombre del rol. |
Grantor |
STRING |
El nombre de la base de datos que otorgó el rol. |
Grantee |
STRING |
El usuario al que se le otorga el rol. |
WhenGranted |
TIMESTAMP |
Cuándo se otorgó el rol. |
WithAdmin |
BOOLEAN |
Es la opción de administrador establecida para el rol otorgado. |
Conversión de esquemas
En esta tabla, se proporciona información sobre las conversiones de esquema relacionadas con el agrupamiento en clústeres y la partición.
| Nombre de la columna | Tipo de columna | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos de origen para la que se realiza la sugerencia. Una base de datos se asigna a un conjunto de datos en BigQuery. |
TableName |
STRING |
El nombre de la tabla para la que se realiza la sugerencia. |
PartitioningColumnName |
STRING |
El nombre de la columna de partición sugerida en BigQuery. |
ClusteringColumnNames |
ARRAY |
Los nombres de las columnas de agrupamiento en clústeres sugeridas en BigQuery. |
CreateTableDDL |
STRING |
El CREATE TABLE statement para crear la tabla en BigQuery. |
TableInfo
En esta tabla, se proporciona información sobre las tablas.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. |
TableNameOriginal |
STRING |
El nombre de la tabla con el caso preservado. |
LastAccessTimestamp |
TIMESTAMP |
Es la última vez que se accedió a la tabla. |
LastAlterTimestamp |
TIMESTAMP |
Es la última vez que se modificó la tabla. |
TableKind |
STRING |
El tipo de tabla. |
TableRelations
En esta tabla, se proporciona información sobre las tablas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
Es el hash de la consulta que estableció la relación. |
DatabaseName1 |
STRING |
Nombre de la primera base de datos. |
TableName1 |
STRING |
Es el nombre de la primera tabla. |
DatabaseName2 |
STRING |
Es el nombre de la segunda base de datos. |
TableName2 |
STRING |
El nombre de la segunda tabla. |
Relation |
STRING |
Es el tipo de relación entre las dos tablas. |
TableSizes
En esta tabla, se proporciona información sobre los tamaños de las tablas.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. |
TableNameOriginal |
STRING |
El nombre de la tabla con el caso preservado. |
TableSizeInBytes |
INTEGER |
Es el tamaño de la tabla en bytes. |
Users
En esta tabla, se proporciona información sobre los usuarios.
| Columna | Tipo | Descripción |
|---|---|---|
UserName |
STRING |
Es el nombre del usuario. |
CreatorName |
STRING |
Es el nombre de la entidad que creó este usuario. |
CreateTimestamp |
TIMESTAMP |
Es la marca de tiempo de la creación de este usuario. |
LastAccessTimestamp |
TIMESTAMP |
Es la marca de tiempo de la última vez que este usuario accedió a una base de datos. |
Redshift
Columns
La tabla Columns proviene de una de las siguientes tablas: SVV_COLUMNS, INFORMATION_SCHEMA.COLUMNS o PG_TABLE_DEF, ordenadas por prioridad. La herramienta intenta cargar primero los datos desde la tabla de prioridad más alta. Si esto falla, intenta cargar los datos de la siguiente tabla de prioridad más alta. Consulta la documentación de Amazon Redshift o PostgreSQL para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos. |
SchemaName |
STRING |
Es el nombre del esquema. |
TableName |
STRING |
Es el nombre de la tabla. |
ColumnName |
STRING |
Es el nombre de la columna |
DefaultValue |
STRING |
Es el valor predeterminado, si está disponible. |
Nullable |
BOOLEAN |
Indica si una columna puede tener un valor nulo. |
ColumnType |
STRING |
El tipo de la columna, como VARCHAR. |
ColumnLength |
INTEGER |
Es el tamaño de la columna, como 30 para un VARCHAR(30). |
CreateAndDropStatistic
En esta tabla, se proporciona información sobre cómo crear y borrar tablas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
DefaultDatabase |
STRING |
La base de datos predeterminada. |
EntityType |
STRING |
El tipo de entidad, por ejemplo, TABLA. |
EntityName |
STRING |
Es el nombre de la entidad. |
Operation |
STRING |
La operación: CREATE o DROP. |
Databases
Esta tabla proviene de la tabla PG_DATABASE_INFO directamente de Amazon Redshift. Los nombres de los campos originales de la tabla de PG se incluyen con las descripciones. Consulta la documentación de Amazon Redshift y PostgreSQL para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos. Nombre de la fuente: datname |
Owner |
STRING |
El propietario de la base de datos. Por ejemplo, el usuario que creó la base de datos. Nombre de la fuente: datdba |
ExternalColumns
Esta tabla contiene información de la tabla SVV_EXTERNAL_COLUMNS directamente desde Amazon Redshift. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
SchemaName |
STRING |
Es el nombre del esquema externo. |
TableName |
STRING |
Es el nombre de la tabla externa. |
ColumnName |
STRING |
Es el nombre de la columna externa. |
ColumnType |
STRING |
Es el tipo de la columna. |
Nullable |
BOOLEAN |
Indica si una columna puede tener un valor nulo. |
ExternalDatabases
Esta tabla contiene información de la tabla SVV_EXTERNAL_DATABASES directamente desde Amazon Redshift. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos externa. |
Location |
STRING |
La ubicación de la base de datos. |
ExternalPartitions
Esta tabla contiene información de la tabla SVV_EXTERNAL_PARTITIONS de Amazon Redshift directamente. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
SchemaName |
STRING |
Es el nombre del esquema externo. |
TableName |
STRING |
Es el nombre de la tabla externa. |
Location |
STRING |
Es la ubicación de la partición. El tamaño de la columna se limita a 128 caracteres. Los valores más largos se truncan. |
ExternalSchemas
Esta tabla contiene información de la tabla SVV_EXTERNAL_SCHEMAS de Amazon Redshift directamente. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
SchemaName |
STRING |
Es el nombre del esquema externo. |
DatabaseName |
STRING |
Es el nombre de la base de datos externa. |
ExternalTables
Esta tabla contiene información de la tabla SVV_EXTERNAL_TABLES directamente desde Amazon Redshift. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
SchemaName |
STRING |
Es el nombre del esquema externo. |
TableName |
STRING |
Es el nombre de la tabla externa. |
Functions
Esta tabla contiene información de la tabla PG_PROC de Amazon Redshift directamente. Consulta la documentación de Amazon Redshift y PostgreSQL para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
SchemaName |
STRING |
Es el nombre del esquema. |
FunctionName |
STRING |
Es el nombre de la función. |
LanguageName |
STRING |
El lenguaje de implementación o la interfaz de llamada de esta función. |
Queries
Esta tabla se genera con la información de la tabla QueryLogs. A diferencia de la tabla QueryLogs, cada fila de la tabla de consultas contiene solo una declaración de consulta almacenada en la columna QueryText. En esta tabla, se proporcionan los datos de origen para generar las tablas de estadísticas y los resultados de traducción.
| Columna | Tipo | Descripción |
|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. |
QueryHash |
STRING |
El hash de la consulta. |
QueryLogs
En esta tabla, se proporciona información sobre la ejecución de consultas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. |
QueryHash |
STRING |
El hash de la consulta. |
QueryID |
STRING |
El ID de la consulta. |
UserID |
STRING |
El ID del usuario |
StartTime |
TIMESTAMP |
La hora de inicio. |
Duration |
INTEGER |
Duración en milisegundos. |
QueryTypeStatistics
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
DefaultDatabase |
STRING |
La base de datos predeterminada. |
QueryType |
STRING |
El tipo de consulta. |
UpdatedTable |
STRING |
La tabla actualizada. |
QueriedTables |
ARRAY<STRING> |
Las tablas consultadas. |
TableInfo
Esta tabla contiene información extraída de la tabla SVV_TABLE_INFO en Amazon Redshift.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos. |
SchemaName |
STRING |
Es el nombre del esquema. |
TableId |
INTEGER |
El ID de la tabla |
TableName |
STRING |
Es el nombre de la tabla. |
SortKey1 |
STRING |
Es la primera columna de la clave de ordenamiento. |
SortKeyNum |
INTEGER |
Cantidad de columnas definidas como claves de ordenamiento. |
MaxVarchar |
INTEGER |
Tamaño de la columna más grande que usa un tipo de datos VARCHAR. |
Size |
INTEGER |
Tamaño de la tabla, en bloques de datos de 1 MB |
TblRows |
INTEGER |
Cantidad total de filas en la tabla. |
TableRelations
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
Es el hash de la consulta que estableció la relación (por ejemplo, una consulta JOIN). |
DefaultDatabase |
STRING |
La base de datos predeterminada. |
TableName1 |
STRING |
La primera tabla de la relación. |
TableName2 |
STRING |
La segunda tabla de la relación. |
Relation |
STRING |
El tipo de relación. Acepta uno de los siguientes valores:
COMMA_JOIN, CROSS_JOIN,
FULL_OUTER_JOIN, INNER_JOIN,
LEFT_OUTER_JOIN,
RIGHT_OUTER_JOIN, CREATED_FROM o
INSERT_INTO. |
Count |
INTEGER |
Con qué frecuencia se observó esta relación. |
TableSizes
En esta tabla, se proporciona información sobre los tamaños de las tablas.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos. |
SchemaName |
STRING |
Es el nombre del esquema. |
TableName |
STRING |
Es el nombre de la tabla. |
TableSizeInBytes |
INTEGER |
Es el tamaño de la tabla en bytes. |
Tables
Esta tabla contiene información extraída de la tabla SVV_TABLES en Amazon Redshift. Consulta la documentación de Amazon Redshift para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
Es el nombre de la base de datos. |
SchemaName |
STRING |
Es el nombre del esquema. |
TableName |
STRING |
Es el nombre de la tabla. |
TableType |
STRING |
El tipo de tabla. |
TranslatedQueries
En esta tabla, se proporcionan traducciones de consultas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
TranslatedQueryText |
STRING |
Resultado de la traducción del dialecto de origen a GoogleSQL. |
TranslationErrors
En esta tabla, se proporciona información sobre los errores de traducción de consultas.
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
Severity |
STRING |
La gravedad del error, como ERROR. |
Category |
STRING |
La categoría del error, como AttributeNotFound. |
Message |
STRING |
El mensaje con los detalles sobre el error. |
LocationOffset |
INTEGER |
La posición del carácter de la ubicación del error. |
LocationLine |
INTEGER |
El número de línea del error. |
LocationColumn |
INTEGER |
El número de columna del error. |
LocationLength |
INTEGER |
La longitud de caracteres de la ubicación del error. |
UserTableRelations
| Columna | Tipo | Descripción |
|---|---|---|
UserID |
STRING |
El ID de usuario. |
TableName |
STRING |
Es el nombre de la tabla. |
Relation |
STRING |
La relación. |
Count |
INTEGER |
El recuento |
Users
Esta tabla contiene información extraída de la tabla PG_USER en Amazon Redshift. Consulta la documentación de PostgreSQL para obtener más detalles sobre el esquema y el uso.
| Columna | Tipo | Descripción | |
|---|---|---|---|
UserName |
STRING |
Es el nombre del usuario. | |
UserId |
STRING |
El ID de usuario. |
Snowflake
Warehouses
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
WarehouseName |
STRING |
El nombre del almacén | Siempre |
State |
STRING |
El estado del almacén. Valores posibles: STARTED, SUSPENDED, RESIZING. |
Siempre |
Type |
STRING |
Tipo de almacén. Valores posibles: STANDARD, SNOWPARK-OPTIMIZED. |
Siempre |
Size |
STRING |
Tamaño del almacén. Valores posibles: X-Small, Small, Medium, Large, X-Large, 2X-Large … 6X-Large. |
Siempre |
Databases
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con el caso de mayúsculas preservado. | Siempre |
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. | Siempre |
Schemata
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
El nombre de la base de datos a la que pertenece el esquema, con el caso de mayúsculas preservado. | Siempre |
DatabaseName |
STRING |
El nombre de la base de datos a la que pertenece el esquema, convertido en minúsculas. | Siempre |
SchemaNameOriginal |
STRING |
El nombre del esquema, con el caso de mayúsculas preservado. | Siempre |
SchemaName |
STRING |
El nombre del esquema, convertido en minúsculas. | Siempre |
Tables
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
DatabaseNameOriginal |
STRING |
El nombre de la base de datos a la que pertenece la tabla, con el caso de mayúsculas preservado. | Siempre |
DatabaseName |
STRING |
El nombre de la base de datos a la que pertenece la tabla, convertida en minúsculas. | Siempre |
SchemaNameOriginal |
STRING |
El nombre del esquema al que pertenece la tabla, con el caso de mayúsculas preservado. | Siempre |
SchemaName |
STRING |
El nombre del esquema al que pertenece la tabla, convertido en minúsculas. | Siempre |
TableNameOriginal |
STRING |
El nombre de la tabla, con mayúsculas y minúsculas conservadas. | Siempre |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. | Siempre |
TableType |
STRING |
Tipo de tabla (vista / vista materializada / tabla base). | Siempre |
RowCount |
BIGNUMERIC |
Cantidad de filas en la tabla. | Siempre |
Columns
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, convertido en minúsculas. | Siempre |
DatabaseNameOriginal |
STRING |
El nombre de la base de datos, con el caso de mayúsculas preservado. | Siempre |
SchemaName |
STRING |
El nombre del esquema, convertido en minúsculas. | Siempre |
SchemaNameOriginal |
STRING |
El nombre del esquema, con el caso de mayúsculas preservado. | Siempre |
TableName |
STRING |
El nombre de la tabla, convertido en minúsculas. | Siempre |
TableNameOriginal |
STRING |
El nombre de la tabla con el caso preservado. | Siempre |
ColumnName |
STRING |
El nombre de la columna, convertido en minúsculas. | Siempre |
ColumnNameOriginal |
STRING |
El nombre de la columna con el caso preservado. | Siempre |
ColumnType |
STRING |
Es el tipo de la columna. | Siempre |
CreateAndDropStatistics
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryHash |
STRING |
El hash de la consulta. | Siempre |
DefaultDatabase |
STRING |
La base de datos predeterminada. | Siempre |
EntityType |
STRING |
El tipo de entidad, por ejemplo, TABLE. |
Siempre |
EntityName |
STRING |
Es el nombre de la entidad. | Siempre |
Operation |
STRING |
La operación: CREATE o DROP. |
Siempre |
Queries
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. | Siempre |
QueryHash |
STRING |
El hash de la consulta. | Siempre |
QueryLogs
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. | Siempre |
QueryHash |
STRING |
El hash de la consulta. | Siempre |
QueryID |
STRING |
El ID de la consulta. | Siempre |
UserID |
STRING |
El ID del usuario | Siempre |
StartTime |
TIMESTAMP |
La hora de inicio. | Siempre |
Duration |
INTEGER |
Duración en milisegundos. | Siempre |
QueryTypeStatistics
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryHash |
STRING |
El hash de la consulta. | Siempre |
DefaultDatabase |
STRING |
La base de datos predeterminada. | Siempre |
QueryType |
STRING |
El tipo de consulta. | Siempre |
UpdatedTable |
STRING |
La tabla actualizada. | Siempre |
QueriedTables |
REPEATED STRING |
Las tablas consultadas. | Siempre |
TableRelations
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryHash |
STRING |
El hash de la consulta que estableció la relación (por ejemplo, una consulta de JOIN). |
Siempre |
DefaultDatabase |
STRING |
La base de datos predeterminada. | Siempre |
TableName1 |
STRING |
La primera tabla de la relación. | Siempre |
TableName2 |
STRING |
La segunda tabla de la relación. | Siempre |
Relation |
STRING |
El tipo de relación. | Siempre |
Count |
INTEGER |
Con qué frecuencia se observó esta relación. | Siempre |
TranslatedQueries
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryHash |
STRING |
El hash de la consulta. | Siempre |
TranslatedQueryText |
STRING |
Resultado de la traducción del dialecto de origen a BigQuery SQL. | Siempre |
TranslationErrors
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
QueryHash |
STRING |
El hash de la consulta. | Siempre |
Severity |
STRING |
La gravedad del error, por ejemplo, ERROR. |
Siempre |
Category |
STRING |
La categoría del error, por ejemplo, AttributeNotFound. |
Siempre |
Message |
STRING |
El mensaje con los detalles sobre el error. | Siempre |
LocationOffset |
INTEGER |
La posición del carácter de la ubicación del error. | Siempre |
LocationLine |
INTEGER |
El número de línea del error. | Siempre |
LocationColumn |
INTEGER |
El número de columna del error. | Siempre |
LocationLength |
INTEGER |
La longitud de caracteres de la ubicación del error. | Siempre |
UserTableRelations
| Columna | Tipo | Descripción | Presencia |
|---|---|---|---|
UserID |
STRING |
ID de usuario | Siempre |
TableName |
STRING |
Es el nombre de la tabla. | Siempre |
Relation |
STRING |
La relación. | Siempre |
Count |
INTEGER |
El recuento | Siempre |
Apache Hive
Columns
En esta tabla, se proporciona información sobre las columnas:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla con el caso preservado. |
ColumnName |
STRING |
El nombre de la columna con el caso preservado. |
ColumnType |
STRING |
Es el tipo de BigQuery de la columna, como STRING. |
OriginalColumnType |
STRING |
El tipo original de la columna, como VARCHAR. |
CreateAndDropStatistic
En esta tabla, se proporciona información sobre cómo crear y borrar tablas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
DefaultDatabase |
STRING |
La base de datos predeterminada. |
EntityType |
STRING |
El tipo de entidad, por ejemplo, TABLE. |
EntityName |
STRING |
Es el nombre de la entidad. |
Operation |
STRING |
Es la operación realizada en la tabla (CREATE o DROP). |
Databases
En esta tabla, se proporciona información sobre las columnas:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
Owner |
STRING |
El propietario de la base de datos. Por ejemplo, el usuario que creó la base de datos. |
Location |
STRING |
Ubicación de la base de datos en el sistema de archivos. |
Functions
En esta tabla, se proporciona información sobre las funciones:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
FunctionName |
STRING |
Es el nombre de la función. |
LanguageName |
STRING |
El nombre del idioma. |
ClassName |
STRING |
El nombre de clase de la función. |
ObjectReferences
En esta tabla, se proporciona información sobre los objetos a los que se hace referencia en las consultas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
DefaultDatabase |
STRING |
La base de datos predeterminada. |
Clause |
STRING |
La cláusula donde aparece el objeto. Por ejemplo, SELECT. |
ObjectName |
STRING |
El nombre del objeto. |
Type |
STRING |
Es el tipo de objeto. |
Subtype |
STRING |
El subtipo del objeto. |
PartitionKeys
En esta tabla, se proporciona información sobre las claves de partición:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla con el caso preservado. |
ColumnName |
STRING |
El nombre de la columna con el caso preservado. |
ColumnType |
STRING |
Es el tipo de BigQuery de la columna, como STRING. |
Partitions
En esta tabla, se proporciona información sobre las particiones de tablas:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla con el caso preservado. |
PartitionName |
STRING |
El nombre de la partición. |
CreateTimestamp |
TIMESTAMP |
Es la marca de tiempo de la creación de este usuario. |
LastAccessTimestamp |
TIMESTAMP |
La marca de tiempo de la última vez que se accedió a esta partición. |
LastDdlTimestamp |
TIMESTAMP |
Es la marca de tiempo de la última modificación de esta partición. |
TotalSize |
INTEGER |
El tamaño comprimido de la partición en bytes. |
Queries
Esta tabla se genera con la información de la tabla QueryLogs. A diferencia de la tabla QueryLogs, cada fila de la tabla de consultas contiene solo una instrucción de consulta almacenada en la columna QueryText. En esta tabla, se proporcionan los datos de origen para generar las tablas de estadísticas y los resultados de traducción:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
QueryText |
STRING |
Es el texto de la consulta. |
QueryLogs
Esta tabla proporciona algunas estadísticas de ejecución sobre las consultas extraídas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryText |
STRING |
Es el texto de la consulta. |
QueryHash |
STRING |
El hash de la consulta. |
QueryId |
STRING |
El ID de la consulta. |
QueryType |
STRING |
Es el tipo de consulta, ya sea Query o DDL. |
UserName |
STRING |
El nombre del usuario que ejecutó la consulta. |
StartTime |
TIMESTAMP |
Es la marca de tiempo del momento en que se envió la consulta. |
Duration |
STRING |
La duración de la consulta en milisegundos. |
QueryTypeStatistics
En esta tabla, se proporcionan estadísticas sobre los tipos de consultas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
QueryType |
STRING |
El tipo de consulta. |
UpdatedTable |
STRING |
Es la tabla que actualizó la consulta, si la hubiera. |
QueriedTables |
ARRAY<STRING> |
Es una lista de las tablas que se consultaron. |
QueryTypes
En esta tabla, se proporcionan estadísticas sobre los tipos de consultas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
Category |
STRING |
La categoría de la consulta. |
Type |
STRING |
El tipo de consulta. |
Subtype |
STRING |
El subtipo de la consulta. |
Conversión de esquemas
En esta tabla, se proporciona información sobre las conversiones de esquema relacionadas con el agrupamiento en clústeres y la partición:
| Nombre de la columna | Tipo de columna | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos de origen para la que se realiza la sugerencia. Una base de datos se asigna a un conjunto de datos en BigQuery. |
TableName |
STRING |
El nombre de la tabla para la que se realiza la sugerencia. |
PartitioningColumnName |
STRING |
El nombre de la columna de partición sugerida en BigQuery. |
ClusteringColumnNames |
ARRAY |
Los nombres de las columnas de agrupamiento en clústeres sugeridas en BigQuery. |
CreateTableDDL |
STRING |
El CREATE TABLE statement para crear la tabla en BigQuery. |
TableRelations
En esta tabla, se proporciona información sobre las tablas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
Es el hash de la consulta que estableció la relación. |
DatabaseName1 |
STRING |
Nombre de la primera base de datos. |
TableName1 |
STRING |
Es el nombre de la primera tabla. |
DatabaseName2 |
STRING |
Es el nombre de la segunda base de datos. |
TableName2 |
STRING |
El nombre de la segunda tabla. |
Relation |
STRING |
Es el tipo de relación entre las dos tablas. |
TableSizes
En esta tabla, se proporciona información sobre los tamaños de las tablas:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla con el caso preservado. |
TotalSize |
INTEGER |
Es el tamaño de la tabla en bytes. |
Tables
En esta tabla, se proporciona información sobre las tablas:
| Columna | Tipo | Descripción |
|---|---|---|
DatabaseName |
STRING |
El nombre de la base de datos, con mayúsculas preservadas. |
TableName |
STRING |
El nombre de la tabla con el caso preservado. |
Type |
STRING |
El tipo de tabla. |
TranslatedQueries
En esta tabla, se proporcionan traducciones de consultas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
TranslatedQueryText |
STRING |
Resultado de la traducción del dialecto de origen a GoogleSQL. |
TranslationErrors
En esta tabla, se proporciona información sobre los errores de traducción de consultas:
| Columna | Tipo | Descripción |
|---|---|---|
QueryHash |
STRING |
El hash de la consulta. |
Severity |
STRING |
La gravedad del error, como ERROR. |
Category |
STRING |
La categoría del error, como AttributeNotFound. |
Message |
STRING |
El mensaje con los detalles sobre el error. |
LocationOffset |
INTEGER |
La posición del carácter de la ubicación del error. |
LocationLine |
INTEGER |
El número de línea del error. |
LocationColumn |
INTEGER |
El número de columna del error. |
LocationLength |
INTEGER |
La longitud de caracteres de la ubicación del error. |
UserTableRelations
| Columna | Tipo | Descripción |
|---|---|---|
UserID |
STRING |
El ID de usuario. |
TableName |
STRING |
Es el nombre de la tabla. |
Relation |
STRING |
La relación. |
Count |
INTEGER |
El recuento |
Soluciona problemas
En esta sección, se explican algunos problemas habituales y técnicas de solución de problemas para migrar tu almacén de datos a BigQuery.
Errores de la herramienta dwh-migration-dumper
Para solucionar los errores y las advertencias en el resultado de la terminal de la herramienta de dwh-migration-dumper que se produjeron durante la extracción de metadatos o registros de consultas, consulta solución de problemas de generación de metadatos.
Errores de migración de Hive
En esta sección, se describen problemas comunes con los que puedes encontrarte cuando planeas migrar tu almacén de datos de Hive a BigQuery.
El hook de registro escribe mensajes de registro de depuración en tus registros hive-server2. Si tienes algún problema, revisa los registros de depuración del hook de registro, que contiene la string MigrationAssessmentLoggingHook.
Soluciona el error ClassNotFoundException
El error puede deberse a la pérdida incorrecta del archivo hook de registro. Asegúrate de haber agregado el archivo JAR a la carpeta uxlib en el clúster de Hive. Como alternativa, puedes especificar la ruta de acceso completa al archivo JAR en la propiedad hive.aux.jars.path, por ejemplo, file://.
Las subcarpetas no aparecen en la carpeta configurada
Este problema puede deberse a problemas de configuración o durante la inicialización del hook de registro.
Busca tus registros de depuración hive-server2 para los siguientes mensajes de hook de registro:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
Revisa los detalles del problema y verifica si hay algo que debas corregir para solucionarlo.
Los archivos no aparecen en la carpeta
Este problema puede deberse a los problemas que se encontraron durante el procesamiento de un evento o mientras se escribió en un archivo.
Busca en tus registros de depuración hive-server2 los siguientes mensajes de hook de registro:
Failed to close writer for file
Got exception while processing event
Error writing record for query
Revisa los detalles del problema y verifica si hay algo que debas corregir para solucionarlo.
Faltan algunos eventos de consulta
Este problema puede deberse a la desbordamiento de la cola de subprocesos de hook de registro.
Busca en tus registros de depuración hive-server2 el siguiente mensaje de hook de registro:
Writer queue is full. Ignoring event
Si hay esos mensajes, considera aumentar el parámetro dwhassessment.hook.queue.capacity.
¿Qué sigue?
Para obtener más información sobre la herramienta de dwh-migration-dumper, consulta
dwh-migration-tools.
También puedes obtener más información sobre los siguientes pasos en la migración de almacenes de datos:
- Descripción general de la migración
- Descripción general de transferencia de datos y esquemas
- Canalizaciones de datos
- Traducción de SQL por lotes
- Traducción de SQL interactiva
- Seguridad y administración de los datos
- Herramienta de validación de datos