Gérer les tags avec stratégie dans plusieurs emplacements
Ce document explique comment gérer les tags avec stratégie dans plusieurs emplacements régionaux pour la sécurité au niveau des colonnes et le masquage dynamique des données dans BigQuery.
BigQuery fournit un contrôle des accès précis et un masquage dynamique des données pour les colonnes de table sensibles via des tags avec stratégie, compatibles avec la classification de données basée sur le type.
Après avoir créé une taxonomie de classification des données et appliqué des tags avec stratégie à vos données, vous pouvez gérer encore davantage les tags avec stratégie sur plusieurs emplacements.
Considérations relatives aux zones
Les taxonomies sont des ressources régionales, telles que des tables et des ensembles de données BigQuery. Lorsque vous créez une taxonomie, vous spécifiez la région, ou l'emplacement, pour la taxonomie.
Vous pouvez créer une taxonomie et appliquer des tags avec stratégie aux tables de toutes les régions où BigQuery est disponible. Toutefois, pour appliquer des tags avec stratégie d'une taxonomie à une colonne de table, la taxonomie et la table doivent exister au même emplacement régional.
Bien que vous ne puissiez pas appliquer un tag avec stratégie à une colonne de table qui se trouve à un autre emplacement, vous pouvez copier la taxonomie dans un autre emplacement en le dupliquant explicitement ici.
Utiliser des taxonomies sur plusieurs emplacements
Vous pouvez copier (ou répliquer) explicitement une taxonomie et ses définitions de tags avec stratégie vers des emplacements supplémentaires sans avoir à créer manuellement une taxonomie dans chaque emplacement. Lorsque vous répliquez des taxonomies, vous pouvez utiliser les mêmes tags de stratégie pour la sécurité au niveau des colonnes dans plusieurs emplacements, ce qui simplifie leur gestion.
Lorsque vous les répliquez, la taxonomie ainsi que les tags avec stratégie conservent les mêmes ID dans chaque emplacement.
La taxonomie et les tags avec stratégie peuvent être synchronisés à nouveau afin d'être unifiés dans plusieurs emplacements. La réplication explicite d'une taxonomie est effectuée par un appel à l'API Data Catalog. Les futures synchronisations de la taxonomie répliquée utiliseront la même commande API, qui écrase la taxonomie précédente.
Pour faciliter la synchronisation de la taxonomie, vous pouvez utiliser Cloud Scheduler pour effectuer périodiquement une synchronisation de la taxonomie entre les régions, soit par programmation, soit manuellement. Pour utiliser Cloud Scheduler, vous devez configurer un compte de service.
Répliquer une taxonomie dans un nouvel emplacement
Autorisations requises
Les identifiants utilisateur ou le compte de service répliquant la taxonomie doivent avoir le rôle Administrateur de tags avec stratégie Data Catalog.
Pour savoir comment attribuer le rôle Administrateur de tags avec stratégie, consultez la page Restreindre l'accès avec la sécurité au niveau des colonnes de BigQuery.
Pour en savoir plus sur les rôles et les autorisations IAM dans BigQuery, consultez la page Rôles prédéfinis et autorisations.
Pour répliquer une taxonomie sur plusieurs emplacements:
API
Appelez la méthode projects.locations.taxonomies.import de l'API Data Catalog en fournissant une requête POST ainsi que le nom du projet de destination et l'emplacement dans la chaîne HTTP.
POST https://datacatalog.googleapis.com/{parent}/taxonomies:import
Le paramètre de chemin parent correspond au projet de destination et à l'emplacement dans lesquels vous souhaitez copier la taxonomie. Exemple : projects/MyProject/locations/eu
Synchroniser une taxonomie répliquée
Pour synchroniser une taxonomie qui a déjà été répliquée sur plusieurs emplacements, répétez l'appel d'API Data Catalog, comme décrit dans la section Répliquer une taxonomie dans un nouvel emplacement.
Vous pouvez également utiliser un compte de service et Cloud Scheduler pour synchroniser la taxonomie selon une programmation spécifiée. La configuration d'un compte de service dans Cloud Scheduler vous permet également de déclencher une synchronisation à la demande (non planifiée) via la page Cloud Scheduler de la console Google Cloud ou à l'aide de Google Cloud CLI.
Synchroniser une taxonomie répliquée avec Cloud Scheduler
Pour synchroniser une taxonomie répliquée sur plusieurs emplacements à l'aide de Cloud Scheduler, vous avez besoin d'un compte de service.
Comptes de service
Vous pouvez accorder des autorisations pour la synchronisation de la réplication à un compte de service existant ou créer un compte de service.
Pour créer un compte de service, consultez la section Créer des comptes de service.
Autorisations requises
Le compte de service qui synchronise la taxonomie doit disposer du rôle Administrateur de tags avec stratégie Data Catalog. Pour en savoir plus, consultez la section Attribuer le rôle "Administrateur de tags avec stratégie".
Configurer la synchronisation d'une taxonomie avec Cloud Scheduler
Pour synchroniser une taxonomie répliquée sur plusieurs emplacements à l'aide de Cloud Scheduler, procédez comme suit:
Console
Commencez par créer la tâche de synchronisation et son planning.
Suivez les instructions pour créer une tâche dans Cloud Scheduler.
Pour Target (Cible), consultez les instructions de la section Créer une tâche planifiée avec authentification.
Ensuite, ajoutez l'authentification requise pour la synchronisation planifiée.
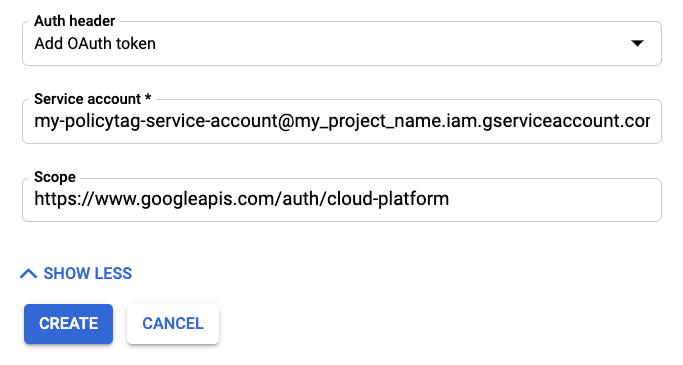
Cliquez sur AFFICHER PLUS pour afficher les champs d'authentification.
Sous Auth header (En-tête de l'authentification), sélectionnez "Add OAuth token" (Ajouter un jeton OAuth).
Ajoutez les informations de votre compte de service.
Pour le Champ d'application, saisissez "https://www.googleapis.com/auth/cloud-platform".
Cliquez sur Créer pour enregistrer la synchronisation planifiée.
Maintenant, vérifiez que la tâche est correctement configurée.
Une fois la tâche créée, cliquez sur Exécuter pour vérifier qu'elle est correctement configurée. Par la suite, Cloud Scheduler déclenche la requête HTTP en fonction de la planification que vous avez spécifiée.
gcloud
Syntaxe :
gcloud scheduler jobs create http "JOB_ID" --schedule="FREQUENCY" --uri="URI" --oath-service-account-email="CLIENT_SERVICE_ACCOUNT_EMAIL" --time-zone="TIME_ZONE" --message-body-from-file="MESSAGE_BODY"
Remplacez l'élément suivant :
${JOB_ID}est un nom pour la tâche. Ce nom doit être unique dans le projet. Notez que vous ne pouvez pas réutiliser un nom de tâche dans un projet, même si vous supprimez la tâche associée.${FREQUENCY}est la planification, également appelée intervalle de tâches, de la fréquence d'exécution de la tâche. Par exemple, "toutes les 3 heures". La chaîne que vous fournissez ici peut être n'importe quelle chaîne compatible avec crontab. Les développeurs qui connaissent l'ancien format Cron App Engine peuvent également utiliser la syntaxe Cron App Engine.${URI}est l'URL complète du point de terminaison.--oauth-service-account-emaildéfinit le type de jeton. Notez que les API Google hébergées sur*.googleapis.comattendent un jeton OAuth.${CLIENT_SERVICE_ACCOUNT_EMAIL}est l'adresse e-mail du compte de service client.${MESSAGE_BODY}est le chemin d'accès au fichier contenant le corps de la requête POST.
D'autres paramètres d'option sont disponibles. Ils sont décrits dans la documentation de référence de Google Cloud CLI.
Exemple :
gcloud scheduler jobs create http cross_regional_copy_to_eu_scheduler --schedule="0 0 1 * *" --uri="https://datacatalog.googleapis.com/v1/projects/my-project/locations/eu/taxonomies:import" --oauth-service-account-email="policytag-manager-service-acou@my-project.iam.gserviceaccount.com" --time-zone="America/Los_Angeles" --message-body-from-file=request_body.json
Étapes suivantes
- Pour en savoir plus sur la sécurité au niveau des colonnes avec des tags avec stratégie, consultez la page Présentation de la sécurité au niveau des colonnes de BigQuery.
- Pour en savoir plus sur la création et l'application de tags avec stratégie, consultez la page Restreindre l'accès avec la sécurité au niveau des colonnes de BigQuery.
- Pour en savoir plus sur l'incidence de l'écriture sur la sécurité au niveau des colonnes de BigQuery, consultez la section Impact sur les écritures avec la sécurité au niveau des colonnes de BigQuery.
- Pour en savoir plus sur les bonnes pratiques concernant l'utilisation des tags avec stratégie, consultez la page Utiliser des tags avec stratégie dans BigQuery.