Reprise après sinistre gérée
Ce document présente la reprise après sinistre gérée de BigQuery et explique comment la mettre en œuvre pour vos données et vos charges de travail.
Présentation
BigQuery est compatible avec les scénarios de reprise après sinistre en cas de panne régionale totale. La reprise après sinistre de BigQuery repose sur la réplication interrégionale d'ensembles de données pour gérer le basculement du stockage. Après avoir créé une instance répliquée de l'ensemble de données dans une région secondaire, vous pouvez contrôler le comportement de basculement pour le calcul et le stockage afin de maintenir la continuité des activités en cas de panne. Après un basculement, vous pouvez accéder à la capacité de calcul (emplacements) et aux ensembles de données répliqués dans la région promue. La reprise après sinistre n'est disponible qu'avec l'édition Enterprise Plus.
La reprise après sinistre gérée propose deux options de basculement : le basculement forcé et le basculement progressif. Un basculement forcé promeut immédiatement la réservation et les instances répliquées de l'ensemble de données de la région secondaire en tant qu'instances principales. Cette action se poursuit même si la région principale actuelle est hors connexion et n'attend pas la réplication des données non répliquées. De ce fait, des pertes de données peuvent survenir lors du basculement forcé.
Tous les jobs ayant validé des données dans la région source avant la valeur replication_time de l'instance répliquée devront être réexécutés dans la région de destination après le basculement.
Contrairement à un basculement forcé, un basculement progressif attend que toutes les modifications apportées aux réservations et aux ensembles de données dans la région principale soient répliquées dans la région secondaire avant de terminer le processus de basculement. Un basculement progressif nécessite que les régions principale et secondaire soient disponibles.
Le lancement d'un basculement progressif définit softFailoverStartTime pour la réservation. Le softFailoverStartTime est effacé une fois le basculement réversible terminé.
Pour activer la reprise après sinistre, vous devez créer une réservation de l'édition Enterprise Plus dans la région principale, qui correspond à la région dans laquelle se trouve l'ensemble de données avant le basculement. La capacité de calcul de secours dans la région associée est incluse dans la réservation Enterprise Plus. Vous devez ensuite associer un ensemble de données à cette réservation afin d'activer le basculement pour cet ensemble de données. Vous ne pouvez associer un ensemble de données à une réservation que s'il est rempli et s'il possède les mêmes emplacements principal et secondaire associés que la réservation. Une fois qu'un ensemble de données est associé à une réservation de basculement, seules les réservations Enterprise Plus peuvent écrire dans ces ensembles de données, et vous ne pouvez pas effectuer de promotion de la réplication interrégionale sur l'ensemble de données. Vous pouvez lire des ensembles de données associés à une réservation de basculement avec n'importe quel modèle de capacité. Pour en savoir plus sur les réservations, consultez la page Présentation de la gestion des charges de travail.
La capacité de calcul de votre région principale est disponible dans la région secondaire rapidement après un basculement. Cette disponibilité s'applique à votre réservation de référence, qu'elle soit utilisée ou non.
Vous devez choisir activement d'effectuer un basculement lors des tests ou en réponse à un véritable sinistre. Vous ne devez pas effectuer de basculement plus d'une fois dans une fenêtre de 10 minutes. Dans les scénarios de réplication de données, le remplissage fait référence au processus qui consiste à renseigner une instance répliquée d'un ensemble de données à l'aide de données historiques qui existaient avant la création ou l'activation de l'instance répliquée. Les ensembles de données doivent terminer leur remplissage avant de pouvoir basculer vers l'ensemble de données.
Le schéma suivant illustre l'architecture de reprise après sinistre gérée :
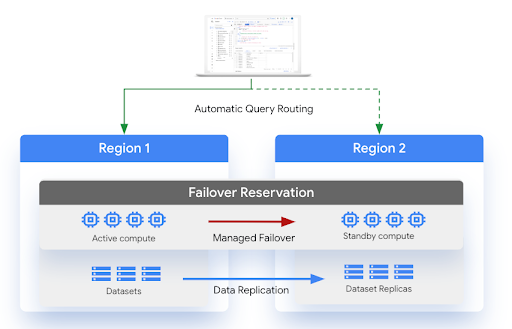
Limites
Les limites suivantes s'appliquent à la reprise après sinistre de BigQuery :
La reprise après sinistre de BigQuery est soumise aux mêmes limites que la réplication interrégionale d'ensembles de données.
L'autoscaling après un basculement dépend de la disponibilité de la capacité de calcul dans la région secondaire. Seule la référence de réservation est disponible dans la région secondaire.
La vue
INFORMATION_SCHEMA.RESERVATIONSne comporte pas de détails sur le basculement.Si vous disposez de plusieurs réservations de basculement avec le même projet d'administration, mais dont les ensembles de données associés utilisent des emplacements secondaires différents, n'utilisez pas une réservation de basculement avec les ensembles de données associés à une autre réservation de basculement.
Si vous souhaitez convertir une réservation existante en réservation de basculement, elle ne peut pas comporter plus de 1 000 attributions de réservation.
Une réservation de basculement ne peut pas comporter plus de 1 000 ensembles de données associés.
Le basculement progressif ne peut être déclenché que si les régions source et de destination sont disponibles.
Le basculement progressif ne peut pas être déclenché si des erreurs temporaires ou autres se produisent lors de la réplication des réservations. Par exemple, si le quota d'emplacements est insuffisant dans la région secondaire pour la mise à jour de la réservation.
La réservation et les ensembles de données associés ne peuvent pas être mis à jour pendant un basculement progressif actif, mais ils peuvent toujours être lus.
Il est possible que les jobs exécutés sur une réservation de basculement pendant un basculement progressif actif ne s'exécutent pas sur la réservation en raison de modifications temporaires du routage des ensembles de données et des réservations pendant l'opération de basculement. Toutefois, ces jobs utiliseront les emplacements de réservation avant et après l'échec partiel.
Emplacements
Les régions suivantes sont disponibles lorsque vous créez une réservation de basculement :
| Code d'emplacement | Nom de la région | Description de la région |
|---|---|---|
ASIA |
||
ASIA-EAST1 |
Taïwan | |
ASIA-SOUTHEAST1 |
Singapour | |
AU |
||
AUSTRALIA-SOUTHEAST1 |
Sydney | |
AUSTRALIA-SOUTHEAST2 |
Melbourne | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
Montréal | |
NORTHAMERICA-NORTHEAST2 |
Toronto | |
DE |
||
EUROPE-WEST3 |
Francfort | |
EUROPE-WEST10 |
Berlin | |
EU |
||
EU |
UE (multirégional) | |
EUROPE-CENTRAL2 |
Varsovie | |
EUROPE-NORTH1 |
Finlande | |
EUROPE-SOUTHWEST1 |
Madrid | |
EUROPE-WEST1 |
Belgique | |
EUROPE-WEST3 |
Francfort | |
EUROPE-WEST4 |
Pays-Bas | |
EUROPE-WEST8 |
Milan | |
EUROPE-WEST9 |
Paris | |
IN |
||
ASIA-SOUTH1 |
Mumbai | |
ASIA-SOUTH2 |
Delhi | |
US |
||
US |
États-Unis (multirégional) | |
US-CENTRAL1 |
Iowa | |
US-EAST1 |
Caroline du Sud | |
US-EAST4 |
Virginie du Nord | |
US-EAST5 |
Columbus | |
US-SOUTH1 |
Dallas | |
US-WEST1 |
Oregon | |
US-WEST2 |
Los Angeles | |
US-WEST3 |
Salt Lake City | |
US-WEST4 |
Las Vegas |
Les paires de régions doivent être sélectionnées dans ASIA, AU, CA, DE, EU, IN ou US. Par exemple, une région de US ne peut pas être associée à une région de EU.
Si votre ensemble de données BigQuery se trouve dans une zone multirégionale, vous ne pouvez pas utiliser les paires de régions suivantes. Cette limitation est nécessaire pour s'assurer que votre réservation de basculement et vos données sont séparées géographiquement après la réplication. Pour en savoir plus sur les régions incluses dans des zones multirégionales, consultez la section Zones multirégionales.
us-central1-us(multirégional)us-west1-us(multirégional)eu-west1-eu(multirégional)eu-west4-eu(multirégional)
Avant de commencer
- Vérifiez que vous disposez de l'autorisation IAM (Identity and Access Management)
bigquery.reservations.updatepour mettre à jour les réservations. - Assurez-vous que vous disposez d'ensembles de données existants configurés pour la réplication. Pour en savoir plus, consultez la page Créer un ensemble de données
Réplication turbo
La reprise après sinistre utilise la réplication turbo pour répliquer plus rapidement les données entre les régions, ce qui réduit le risque d'exposition aux pertes de données, minimise les temps d'arrêt des services et permet d'assurer la continuité des services à la suite d'une panne régionale.
La réplication turbo ne s'applique pas à l'opération de remplissage initial. Une fois l'opération de remplissage initial terminée, la réplication turbo vise à répliquer les ensembles de données dans une seule paire de régions de basculement avec une réplication secondaire dans un délai de 15 minutes, à condition que le quota de bande passante ne soit pas dépassé et qu'il n'y ait pas d'erreurs utilisateur.
Objectif de temps de récupération
Un objectif de temps de récupération (RTO) est le temps cible autorisé pour la récupération dans BigQuery en cas de sinistre. Pour en savoir plus sur le RTO, consultez Principes de base d'un plan de reprise après sinistre.La reprise après sinistre gérée a un RTO de cinq minutes après le lancement d'un basculement. En raison du RTO, la capacité est disponible dans la région secondaire dans les cinq minutes suivant le début du processus de basculement.
Objectif de point de récupération
Un objectif de point de récupération (RPO) correspond au point dans le temps le plus récent à partir duquel les données doivent pouvoir être restaurées. Pour en savoir plus sur le RPO, consultez Principes de base d'un plan de reprise après sinistre. La reprise après sinistre gérée a un RPO défini par ensemble de données. Le RPO vise à maintenir le réplica secondaire à moins de 15 minutes du réplica principal. Pour respecter ce RPO, vous ne devez pas dépasser le quota de bande passante et il ne doit y avoir aucune erreur utilisateur.
Quota
Vous devez disposer de la capacité de calcul choisie dans la région secondaire avant de configurer une réservation de basculement. Si aucun quota n'est disponible dans la région secondaire, vous ne pouvez pas configurer ni modifier la réservation. Pour en savoir plus, consultez la page Quotas et limites.
La bande passante de réplication turbo est soumise à un quota. Pour en savoir plus, consultez la page Quotas et limites.
Tarifs
La configuration de la reprise après sinistre gérée nécessite les forfaits suivants :
Capacité de calcul : vous devez acheter l'édition Enterprise Plus.
Réplication turbo : la reprise après sinistre repose sur la réplication turbo lors de la réplication. Le service vous est facturé en fonction du nombre d'octets physiques et sur une base de tarification par gigaoctet physique répliqué. Pour en savoir plus, consultez Tarifs de transfert de données pour la réplication turbo.
Stockage : les octets de stockage dans la région secondaire sont facturés au même prix que les octets de stockage dans la région principale. Pour en savoir plus, consultez les tarifs de stockage.
Les clients ne doivent payer que la capacité de calcul dans la région principale. La capacité de calcul secondaire (basée sur la référence de réservation) est disponible dans la région secondaire sans frais supplémentaires. Les emplacements inactifs ne peuvent pas utiliser la capacité de calcul secondaire, sauf si la réservation a basculé.
Si vous devez effectuer des lectures non actualisées dans la région secondaire, vous devez acheter de la capacité de calcul supplémentaire.
Créer ou modifier une réservation Enterprise Plus
Avant d'associer un ensemble de données à une réservation, vous devez créer une réservation Enterprise Plus ou modifier une réservation existante et la configurer pour la reprise après sinistre.
Créer une réservation
Sélectionnez l'une des options suivantes :
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Gestion de la capacité, puis sur Créer une réservation.
Dans le champ Nom de la réservation, saisissez un nom pour la réservation.
Dans la liste Emplacement, sélectionnez un emplacement.
Dans la liste Édition, sélectionnez l'édition Enterprise Plus.
Dans la liste Sélecteur de taille de réservation maximale, sélectionnez la taille de réservation maximale.
Facultatif : dans le champ Emplacements de référence, saisissez le nombre d'emplacements de référence pour la réservation.
Le nombre d'emplacements d'autoscaling disponibles est déterminé en soustrayant la valeur Emplacements de référence de la taille maximale de réservation. Par exemple, si vous créez une réservation avec 100 emplacements de référence et une taille de réservation maximale de 400, votre réservation comporte 300 emplacements d'autoscaling. Pour en savoir plus sur les emplacements de référence, consultez la section Utiliser des réservations avec des emplacements de référence et d'autoscaling.
Dans la liste Emplacement secondaire, sélectionnez l'emplacement secondaire.
Pour désactiver le partage d'emplacements inactifs et n'utiliser que la capacité d'emplacements spécifiée, cliquez sur le bouton Ignorer les emplacements inactifs.
Pour développer la section Paramètres avancés, cliquez sur la flèche de développement .
Facultatif : Pour définir la simultanéité de job cible, cliquez sur le bouton Ignorer la simultanéité de job cible automatique, puis saisissez une valeur pour la simultanéité de job cible. La répartition des emplacements est affichée dans le tableau Estimation des coûts. Un résumé de la réservation est affiché dans le tableau Récapitulatif de la capacité.
Cliquez sur Enregistrer.
La nouvelle réservation est visible dans l'onglet Réservations d'emplacements.
SQL
Pour créer une réservation, utilisez l'instruction LDD (langage de définition de données) CREATE RESERVATION.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
Remplacez les éléments suivants :
ADMIN_PROJECT_ID: ID du projet d'administration propriétaire de la ressource de réservation.LOCATION: emplacement de la réservation. Si vous sélectionnez un emplacement BigQuery Omni, votre option d'édition est limitée à l'édition Enterprise.RESERVATION_NAME: nom de la réservation.Le nom doit commencer et se terminer par une lettre minuscule ou un chiffre, et ne contenir que des lettres minuscules, des chiffres et des tirets.
NUMBER_OF_BASELINE_SLOTS: nombre d'emplacements de référence à allouer à la réservation. Vous ne pouvez pas définir les optionsslot_capacityeteditiondans la même réservation.SECONDARY_LOCATION: emplacement secondaire de la réservation. En cas de panne, tous les ensembles de données associés à cette réservation basculeront vers cet emplacement.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Modifier une réservation existante
Sélectionnez l'une des options suivantes :
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Gestion de la capacité.
Cliquez sur l'onglet Réservations d'emplacements.
Recherchez la réservation que vous souhaitez modifier.
Cliquez sur Actions de réservation, puis sur Modifier.
Dans le champ Emplacement secondaire, saisissez l'emplacement secondaire.
Cliquez sur Enregistrer.
SQL
Pour ajouter ou modifier un emplacement secondaire dans une réservation, utilisez l'instruction LDD ALTER RESERVATION SET OPTIONS.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
Remplacez les éléments suivants :
ADMIN_PROJECT_ID: ID du projet d'administration propriétaire de la ressource de réservation.LOCATION: emplacement de la réservation, par exempleeurope-west9.RESERVATION_NAME: nom de la réservation. Le nom doit commencer et se terminer par une lettre minuscule ou un chiffre, et ne contenir que des lettres minuscules, des chiffres et des tirets.SECONDARY_LOCATION: emplacement secondaire de la réservation. En cas de panne, tous les ensembles de données associés à cette réservation basculeront vers cet emplacement.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Associer un ensemble de données à une réservation
Pour activer la reprise après sinistre pour la réservation créée précédemment, procédez comme suit : L'ensemble de données doit déjà être configuré pour la réplication dans les mêmes régions principale et secondaire que la réservation. Pour en savoir plus, consultez la page Réplication interrégionale d'ensembles de données.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Gestion de la capacité, puis sur l'onglet Réservations d'emplacements.
Cliquez sur la réservation à laquelle vous souhaitez associer un ensemble de données.
Cliquez sur l'onglet Reprise après sinistre.
Cliquez sur Ajouter un ensemble de données de basculement.
Saisissez le nom de l'ensemble de données que vous souhaitez associer à la réservation.
Cliquez sur Ajouter.
SQL
Pour associer un ensemble de données à une réservation, utilisez l'instruction LDD ALTER SCHEMA SET OPTIONS.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
Remplacez les éléments suivants :
DATASET_NAME: nom de l'ensemble de données.ADMIN_PROJECT_ID.RESERVATION_NAME: nom de la réservation à laquelle vous souhaitez associer l'ensemble de données.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Dissocier un ensemble de données d'une réservation
Pour arrêter de gérer le comportement de basculement d'un ensemble de données via une réservation, dissociez-le de la réservation. Cette opération ne modifie pas l'instance répliquée principale actuelle de l'ensemble de données et ne supprime aucune instance répliquée existante de l'ensemble de données. Pour en savoir plus sur la suppression des instances répliquées d'un ensemble de données après l'avoir dissocié, consultez Supprimer une instance répliquée d'un ensemble de données.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Gestion de la capacité, puis sur l'onglet Réservations d'emplacements.
Cliquez sur la réservation contenant un ensemble de données que vous souhaitez dissocier.
Cliquez sur l'onglet Reprise après sinistre.
Développez l'option Actions pour l'instance répliquée principale de l'ensemble de données.
Cliquez sur Supprimer.
SQL
Pour dissocier un ensemble de données d'une réservation, utilisez l'instruction LDD ALTER SCHEMA SET OPTIONS.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
Remplacez les éléments suivants :
DATASET_NAME: nom de l'ensemble de données.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Initier un basculement
En cas de panne régionale, vous devez faire basculer manuellement votre réservation vers l'emplacement utilisé par l'instance répliquée. Le basculement de la réservation inclut également tous les ensembles de données associés. Pour basculer manuellement une réservation, procédez comme suit :
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Reprise après sinistre.
Cliquez sur le nom de la réservation vers laquelle vous souhaitez basculer.
Sélectionnez Mode de basculement forcé (par défaut) ou Mode de basculement progressif.
Cliquez sur Basculement.
SQL
Pour ajouter ou modifier un emplacement secondaire dans une réservation, utilisez l'instruction LDD ALTER RESERVATION SET OPTIONS et définissez is_primary sur TRUE.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
Remplacez les éléments suivants :
ADMIN_PROJECT_ID: ID du projet d'administration propriétaire de la ressource de réservation.LOCATION: emplacement principal de la réservation après le basculement (c'est-à-dire l'emplacement secondaire actuel avant le basculement), par exempleeurope-west9.RESERVATION_NAME: nom de la réservation. Le nom doit commencer et se terminer par une lettre minuscule ou un chiffre, et ne contenir que des lettres minuscules, des chiffres et des tirets.PRIMARY_STATUS: état booléen qui déclare si la réservation est l'instance répliquée principale.FAILOVER_MODE: paramètre facultatif utilisé pour décrire le mode de basculement. Peut être défini surHARDouSOFT. Si ce paramètre n'est pas spécifié,HARDest utilisé par défaut.
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Surveillance
Pour déterminer l'état de vos instances répliquées, interrogez la vue INFORMATION_SCHEMA.SCHEMATA_REPLICAS. Exemple :
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
La requête suivante renvoie les jobs des sept derniers jours qui échoueraient si les ensembles de données étaient des ensembles de données de basculement :
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
Remplacez les éléments suivants :
PROJECT_ID: ID du projet.DATASET_ID: ID de l'ensemble de donnéesLOCATION: l'emplacement.
Étapes suivantes
Apprenez-en plus sur la réplication interrégionale d'ensembles de données.
Apprenez-en plus sur la fiabilité.